📚 HTML 考題小舖
📖 iPAS AI應用規劃師-初級能力鑑定 精選模擬試題/重點整理(免費試閱)
📖 iPAS AI應用規劃師-中級能力鑑定 精選模擬試題/重點整理(免費試閱)
📖 2025年最新版 Azure AI900 微軟中文版題庫【免費試閱】
📖 2025年最新版微軟證照題庫系列【AZ-900】【AI-102】【AI-900】【DP-900】【PL-900】等
📖 iPAS AI應用規劃師-初級能力鑑定 精選模擬試題/重點整理(免費試閱)
📖 iPAS AI應用規劃師-中級能力鑑定 精選模擬試題/重點整理(免費試閱)
📖 2025年最新版 Azure AI900 微軟中文版題庫【免費試閱】
📖 2025年最新版微軟證照題庫系列【AZ-900】【AI-102】【AI-900】【DP-900】【PL-900】等
🧠 iPAS AI應用規劃師 中級能力鑑定
📋 考試樣題 (114年9月版v2)
📖 樣題科目
一
🧠 人工智慧技術應用與規劃
二
📊 大數據處理分析與應用
三
🔬 機器學習技術與應用
🧠 科目一: 人工智慧技術應用與規劃
#1
★★★★
下列何者並未使用人工智慧(Artificial Intelligence, AI)或機器學習(Machine Learning, ML)技術?
💡 答案解析
正確答案:A
人工智慧(Artificial Intelligence, AI)和機器學習(Machine Learning, ML)的核心特徵是能夠從數據中學習並改進性能,而不是僅僅依賴預定義的規則。
各選項分析:
選項 (A) 使用一組預定義規則來確定最佳移動做法的象棋遊戲:正確答案
這是傳統的基於規則的系統(Rule-based System),使用預定義的算法和評估函數來決定最佳移動,但沒有學習能力。
System),它完全依賴開發者預先設定好的邏輯和策略,不具備從數據中學習或適應新情況的能力。這與 AI/ML 的核心思想相反。
選項 (B) 使用深度神經網路來提高其準確性的語音識別系統:
這是典型的深度學習(Deep Learning)應用,深度神經網路(Deep Neural Networks)能夠從大量語音數據中學習特徵並自動改進識別準確性。
選項 (C) 使用感測器和預定義的自動駕駛汽車-定義導航規則:
這是傳統的規則-based自動駕駛,依賴預定義的導航規則和感測器數據進行決策,缺乏學習和適應能力。
雖然題目提到了「預定義的導航規則」(例如:導航路線、速度限制),但「自動駕駛汽車」或任何需要與複雜現實環境互動的自主移動系統 (Autonomous System),其核心功能必須仰賴 AI/ML:
選項 (D) 使用自然語言處理算法來理解和反應用戶查詢的聊天機器人:
現代聊天機器人通常使用自然語言處理(Natural Language Processing, NLP)和機器學習技術來理解和生成回應。
AI/ML vs 傳統規則系統的區別:
• 學習能力:AI/ML系統能夠從數據中學習和改進
• 適應性:能夠處理新的、未見過的情況
• 模式識別:能夠識別複雜的模式和關係
• 自動化特徵提取:無需手動定義所有規則
人工智慧(Artificial Intelligence, AI)和機器學習(Machine Learning, ML)的核心特徵是能夠從數據中學習並改進性能,而不是僅僅依賴預定義的規則。
各選項分析:
選項 (A) 使用一組預定義規則來確定最佳移動做法的象棋遊戲:正確答案
這是傳統的基於規則的系統(Rule-based System),使用預定義的算法和評估函數來決定最佳移動,但沒有學習能力。
System),它完全依賴開發者預先設定好的邏輯和策略,不具備從數據中學習或適應新情況的能力。這與 AI/ML 的核心思想相反。
選項 (B) 使用深度神經網路來提高其準確性的語音識別系統:
這是典型的深度學習(Deep Learning)應用,深度神經網路(Deep Neural Networks)能夠從大量語音數據中學習特徵並自動改進識別準確性。
選項 (C) 使用感測器和預定義的自動駕駛汽車-定義導航規則:
這是傳統的規則-based自動駕駛,依賴預定義的導航規則和感測器數據進行決策,缺乏學習和適應能力。
雖然題目提到了「預定義的導航規則」(例如:導航路線、速度限制),但「自動駕駛汽車」或任何需要與複雜現實環境互動的自主移動系統 (Autonomous System),其核心功能必須仰賴 AI/ML:
- 感知 (Perception): 汽車如何識別路上的行人、紅綠燈、路牌、摩托車?這必須使用深度學習(Deep Learning)或機器學習來進行影像識別和物件偵測。
- 決策 (Decision-making): 在未預期的情況下(例如突然有車插入),汽車如何做出反應?這往往需要複雜的AI模型來進行預測和即時規劃。
選項 (D) 使用自然語言處理算法來理解和反應用戶查詢的聊天機器人:
現代聊天機器人通常使用自然語言處理(Natural Language Processing, NLP)和機器學習技術來理解和生成回應。
AI/ML vs 傳統規則系統的區別:
• 學習能力:AI/ML系統能夠從數據中學習和改進
• 適應性:能夠處理新的、未見過的情況
• 模式識別:能夠識別複雜的模式和關係
• 自動化特徵提取:無需手動定義所有規則
#2
★★★★★
在文本資料處理過程中,通常會需要「將接續的文本轉換為詞彙單位」,以便後續的處理。請問上述所指的是文本資料處理中的哪一個方法?
💡 答案解析
正確答案:C
斷詞(Tokenization)是自然語言處理(Natural Language Processing, NLP)中最基礎且重要的步驟之一。
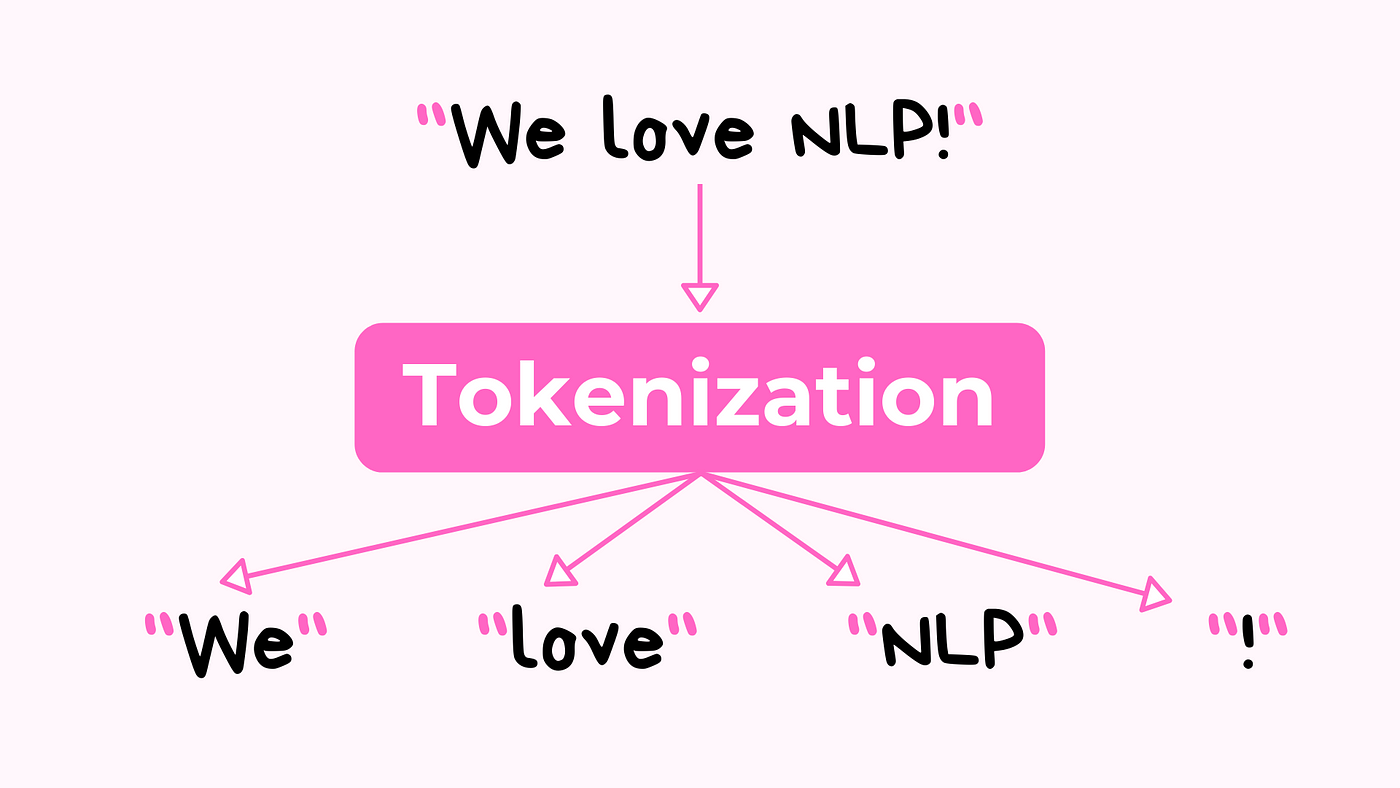
斷詞的定義與功能:
• 將連續的文本分割成詞彙單位(tokens)
• 為後續的詞形還原、詞性標註等處理做準備
• 處理不同語言的斷詞規則和特殊情況
斷詞的類型:
其他選項的區別:
• 詞形還原:將詞彙轉換為詞典中的基本形式
• 停用詞移除:移除常見但無意義的詞彙
• TF-IDF:計算詞彙在文檔中的重要性權重
斷詞在NLP管道中的位置:
1. 原始文本
2. 斷詞(Tokenization)
3. 詞形還原(Lemmatization)
4. 停用詞移除(Stopword Removal)
5. 特徵提取(Feature Extraction)
斷詞(Tokenization)是自然語言處理(Natural Language Processing, NLP)中最基礎且重要的步驟之一。
斷詞的定義與功能:
• 將連續的文本分割成詞彙單位(tokens)
• 為後續的詞形還原、詞性標註等處理做準備
• 處理不同語言的斷詞規則和特殊情況
斷詞的類型:
| 斷詞類型 | 說明 | 範例 |
|---|---|---|
| 詞語級斷詞 | 將文本分割為單詞 | "I am happy" → ["I", "am", "happy"] |
| 子詞級斷詞 | 將單詞進一步分割為子詞單位 | "unhappiness" → ["un", "happi", "ness"] |
| 字元級斷詞 | 將文本分割為單個字元 | "Hello" → ["H", "e", "l", "l", "o"] |
其他選項的區別:
• 詞形還原:將詞彙轉換為詞典中的基本形式
• 停用詞移除:移除常見但無意義的詞彙
• TF-IDF:計算詞彙在文檔中的重要性權重
斷詞在NLP管道中的位置:
1. 原始文本
2. 斷詞(Tokenization)
3. 詞形還原(Lemmatization)
4. 停用詞移除(Stopword Removal)
5. 特徵提取(Feature Extraction)
#3
★★★★
下列何者為自然語言處理(Natural Language Processing, NLP)在機器學習應用中的主要用途?
💡 答案解析
正確答案:A
情緒分析(Sentiment Analysis)是自然語言處理(Natural Language Processing, NLP)在機器學習中最典型和廣泛的應用之一。

情緒分析的定義與應用:
• 識別和提取文本中的情緒傾向
• 判斷文本是正面、負面還是中性的
• 廣泛應用於社交媒體監控、產品評論分析、市場研究等
情緒分析的技術方法:
其他選項為何不正確:
• 圖像識別:屬於電腦視覺領域
• 預測性維護:屬於工業物聯網和機器學習的應用
• 供應鏈優化:屬於運籌學和優化算法的應用
NLP在機器學習中的其他主要用途:
• 文本分類:將文本歸類到預定義的類別
• 命名實體識別:識別文本中的專有名詞
• 機器翻譯:將一種語言翻譯成另一種語言
• 文本摘要:自動生成文本的簡潔摘要
情緒分析(Sentiment Analysis)是自然語言處理(Natural Language Processing, NLP)在機器學習中最典型和廣泛的應用之一。
情緒分析的定義與應用:
• 識別和提取文本中的情緒傾向
• 判斷文本是正面、負面還是中性的
• 廣泛應用於社交媒體監控、產品評論分析、市場研究等
情緒分析的技術方法:
| 方法類型 | 說明 | 優缺點 |
|---|---|---|
| 基於規則的方法 | 使用預定義的情緒詞典和規則 | 準確性高,但覆蓋面有限 |
| 機器學習方法 | 使用分類算法學習情緒模式 | 準確性好,可處理複雜情況 |
| 深度學習方法 | 使用神經網路自動學習特徵 | 準確性最高,但需要大量資料 |
其他選項為何不正確:
• 圖像識別:屬於電腦視覺領域
• 預測性維護:屬於工業物聯網和機器學習的應用
• 供應鏈優化:屬於運籌學和優化算法的應用
NLP在機器學習中的其他主要用途:
• 文本分類:將文本歸類到預定義的類別
• 命名實體識別:識別文本中的專有名詞
• 機器翻譯:將一種語言翻譯成另一種語言
• 文本摘要:自動生成文本的簡潔摘要
#4
★★★★★
關於深度學習模型,下列敘述何者不正確?
💡 答案解析
正確答案:D
Elman 神經網路(Elman Neural Networks)是遞迴神經網路(Recurrent Neural Networks, RNN)的一種變體,主要用於處理序列資料,而不是影像辨識。
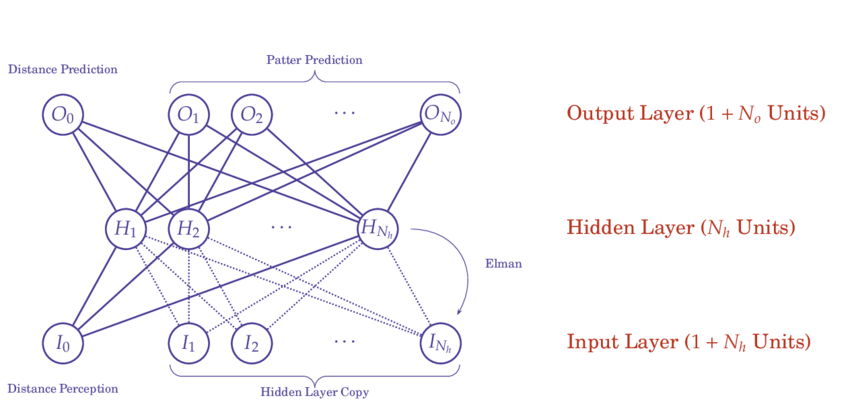
各神經網路類型的應用領域:
Elman神經網路的特點:
• 上下文層:記住前一步的隱藏層狀態
• 簡單循環結構:比標準RNN更容易訓練
• 適用於序列任務:如語言建模、時間序列預測
其他選項的正確性:
• CNN確實適合影像辨識
• ReLU確實能減緩梯度消失問題
• RNN確實適合處理序列資料
不同神經網路的適用場景:
• 影像辨識:CNN、視覺Transformer
• 序列資料:RNN、LSTM、GRU、Transformer
• 結構化資料:MLP、決策樹、隨機森林
Elman 神經網路(Elman Neural Networks)是遞迴神經網路(Recurrent Neural Networks, RNN)的一種變體,主要用於處理序列資料,而不是影像辨識。
各神經網路類型的應用領域:
| 神經網路類型 | 主要應用領域 | 核心特點 |
|---|---|---|
| 卷積神經網路 (CNN) | 影像辨識、電腦視覺 | 局部感受野、權重共享 |
| 遞迴神經網路 (RNN) | 序列資料、自然語言處理 | 記憶功能、序列建模 |
| Elman 神經網路 | 時間序列預測、語言建模 | 上下文層、簡單循環結構 |
Elman神經網路的特點:
• 上下文層:記住前一步的隱藏層狀態
• 簡單循環結構:比標準RNN更容易訓練
• 適用於序列任務:如語言建模、時間序列預測
其他選項的正確性:
• CNN確實適合影像辨識
• ReLU確實能減緩梯度消失問題
• RNN確實適合處理序列資料
不同神經網路的適用場景:
• 影像辨識:CNN、視覺Transformer
• 序列資料:RNN、LSTM、GRU、Transformer
• 結構化資料:MLP、決策樹、隨機森林
#5
★★★★
下列何者為機器學習模型在業界部署的主要趨勢?
💡 答案解析
正確答案:A
自動化機器學習(Automated Machine Learning, AutoML)是當前機器學習領域最重要的发展趨勢之一。
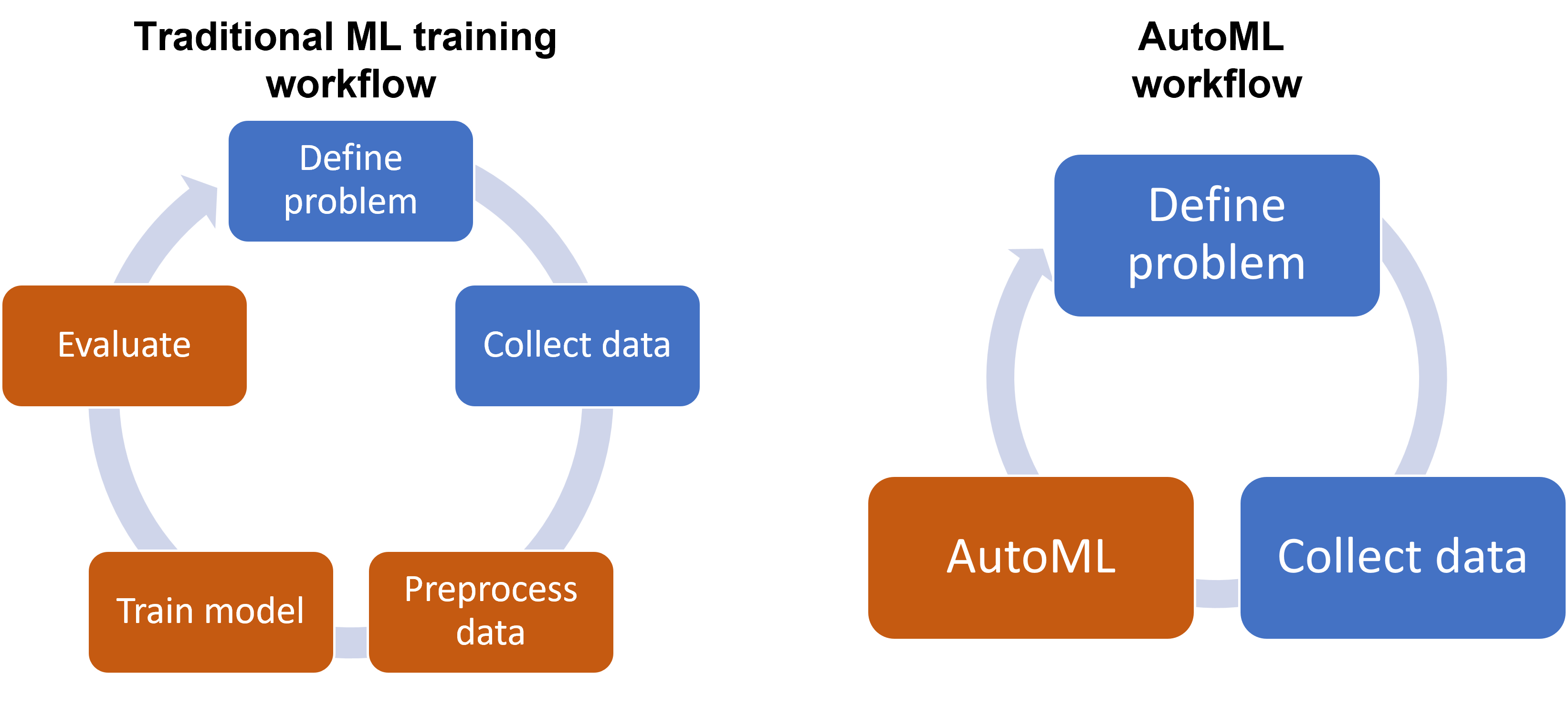 AutoML的核心價值:
AutoML的核心價值:
• 降低技術門檻:使非專家也能使用機器學習
• 提升開發效率:自動化模型選擇和調優過程
• 保證模型品質:系統化地尋找最佳模型配置
• 加速創新:讓更多人專注於問題解決而非技術細節
AutoML的主要功能:
其他選項為何不正確:
• 轉向更簡單算法:實際趨勢是使用更複雜但自動化的模型
• 雲平台使用率下降:雲平台使用率實際上在上升
• 手動超參數調整:趨勢是朝向自動化優化
AutoML在業界的應用:
• Google Cloud AutoML:圖像、視頻、語言等領域
• Microsoft Azure AutoML:端到端機器學習管道
• Amazon SageMaker Autopilot:自動化模型訓練
• H2O.ai AutoML:開源AutoML平台
自動化機器學習(Automated Machine Learning, AutoML)是當前機器學習領域最重要的发展趨勢之一。
AutoML的核心價值:• 降低技術門檻:使非專家也能使用機器學習
• 提升開發效率:自動化模型選擇和調優過程
• 保證模型品質:系統化地尋找最佳模型配置
• 加速創新:讓更多人專注於問題解決而非技術細節
AutoML的主要功能:
| 功能模組 | 說明 | 效益 |
|---|---|---|
| 自動特徵工程 | 自動生成和選擇相關特徵 | 提升模型準確性 |
| 自動模型選擇 | 從多種算法中選擇最佳模型 | 節省開發時間 |
| 自動超參數優化 | 自動調整模型參數 | 提升模型性能 |
| 自動模型評估 | 自動評估和比較不同模型 | 客觀決策依據 |
其他選項為何不正確:
• 轉向更簡單算法:實際趨勢是使用更複雜但自動化的模型
• 雲平台使用率下降:雲平台使用率實際上在上升
• 手動超參數調整:趨勢是朝向自動化優化
AutoML在業界的應用:
• Google Cloud AutoML:圖像、視頻、語言等領域
• Microsoft Azure AutoML:端到端機器學習管道
• Amazon SageMaker Autopilot:自動化模型訓練
• H2O.ai AutoML:開源AutoML平台
#6
★★★★★
下列何者「最適合」使用迴歸(Regression)模型進行預測?
💡 答案解析
正確答案:D
迴歸(Regression)模型主要用於預測連續數值,而非分類或推薦任務。
 迴歸模型的適用場景:
迴歸模型的適用場景:
• 預測連續數值:如價格、銷售額、溫度等
• 數值估計:預測具體的數量或金額
• 趨勢分析:分析變數間的關係和趨勢
各選項的任務類型分析:
迴歸模型的類型:
• 線性迴歸:簡單線性關係
• 多項式迴歸:非線性關係
• 嶺迴歸:處理多重共線性
• 套索迴歸:特徵選擇
銷售額預測的適合性:
• 連續數值輸出:銷售額是連續的數值
• 歷史數據可用:有歷年銷售數據作為訓練資料
• 可量化影響因素:價格、促銷、季節等因素可量化
• 業務價值高:準確預測對庫存管理和財務規劃很重要
迴歸(Regression)模型主要用於預測連續數值,而非分類或推薦任務。
迴歸模型的適用場景:• 預測連續數值:如價格、銷售額、溫度等
• 數值估計:預測具體的數量或金額
• 趨勢分析:分析變數間的關係和趨勢
各選項的任務類型分析:
| 選項 | 任務類型 | 輸出類型 | 適合的模型 |
|---|---|---|---|
| A. 商品類別預測 | 分類任務 | 類別標籤 | 分類模型 |
| B. 疾病診斷 | 分類任務 | 疾病類別 | 分類模型 |
| C. 電影推薦 | 推薦任務 | 推薦列表 | 推薦系統 |
| D. 銷售額預測 | 迴歸任務 | 連續數值 | 迴歸模型 |
迴歸模型的類型:
• 線性迴歸:簡單線性關係
• 多項式迴歸:非線性關係
• 嶺迴歸:處理多重共線性
• 套索迴歸:特徵選擇
銷售額預測的適合性:
• 連續數值輸出:銷售額是連續的數值
• 歷史數據可用:有歷年銷售數據作為訓練資料
• 可量化影響因素:價格、促銷、季節等因素可量化
• 業務價值高:準確預測對庫存管理和財務規劃很重要
#7
★★★★
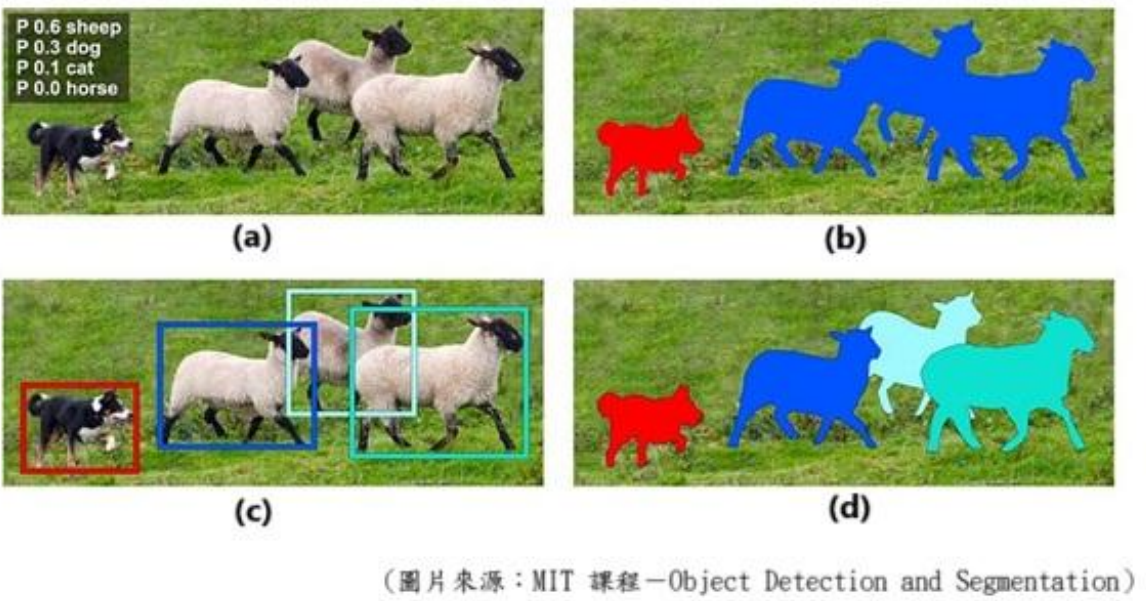
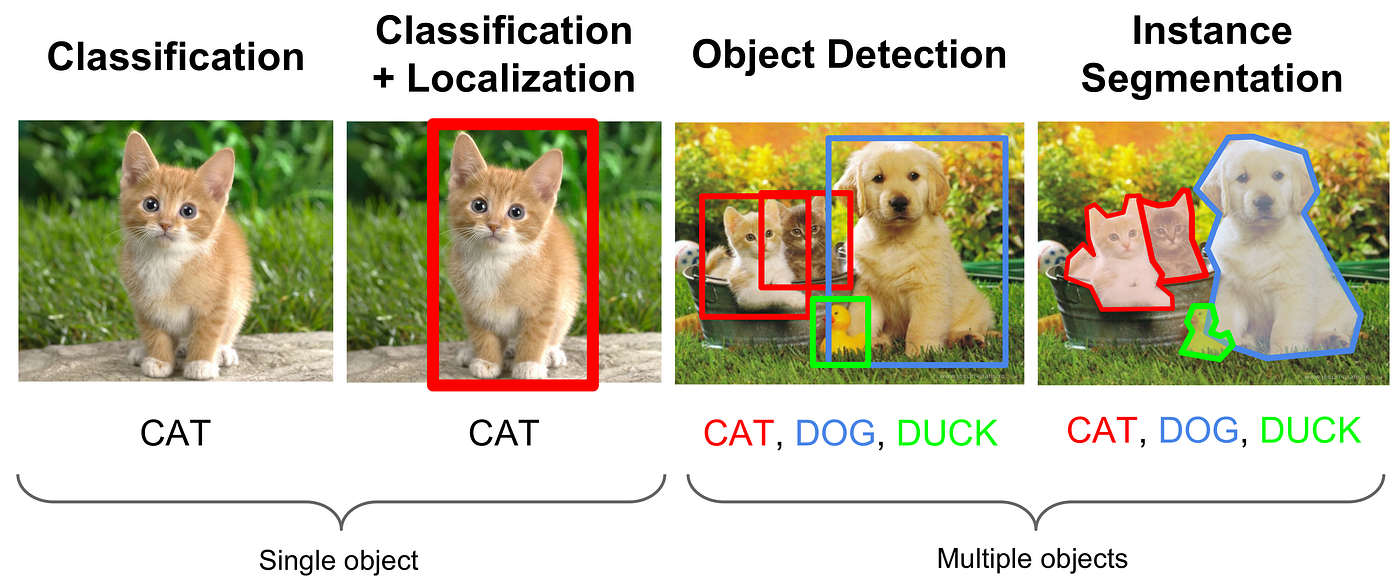
附圖中,展示了電腦視覺辨識的幾項技術。請問下列選項中,何者正確配對了圖中(a)、(b)、(c)、(d)所代表的技術名稱?
💡 答案解析
正確答案:B
根據圖片分析,圖中展示了四種不同的電腦視覺技術:
圖片分析:
• (a) 圖像分類:顯示類別概率標籤(如 P 0.6 sheep, P 0.3 dog),這是典型的圖像分類結果
• (b) 語義分割:動物們被著色(狗紅色,羊藍色),同類別實例未區分,這是語義分割的特徵
• (c) 物件偵測:顯示邊界框(狗紅框,羊藍框),這是物件偵測的典型輸出
• (d) 實例分割:每隻羊有不同顏色(淺藍、深藍、綠),狗是紅色,區分了不同實例
各技術的定義與特點:

技術發展的層次關係:
• 圖像分類:最基礎的視覺任務
• 物件偵測:在分類基礎上增加定位能力
• 語義分割:像素級的類別理解
• 實例分割:在語義分割基礎上區分實例
各技術的應用領域:
• 圖像分類:相片整理、內容審核
• 物件偵測:自動駕駛、安全監控
• 語義分割:場景理解、機器人導航
• 實例分割:醫學影像分析、工業品質控制
根據圖片分析,圖中展示了四種不同的電腦視覺技術:
圖片分析:
• (a) 圖像分類:顯示類別概率標籤(如 P 0.6 sheep, P 0.3 dog),這是典型的圖像分類結果
• (b) 語義分割:動物們被著色(狗紅色,羊藍色),同類別實例未區分,這是語義分割的特徵
• (c) 物件偵測:顯示邊界框(狗紅框,羊藍框),這是物件偵測的典型輸出
• (d) 實例分割:每隻羊有不同顏色(淺藍、深藍、綠),狗是紅色,區分了不同實例
各技術的定義與特點:
| 技術名稱 | 功能描述 | 輸出結果 |
|---|---|---|
| 圖像分類 | 判斷整張圖像屬於哪個類別 | 類別標籤和概率 |
| 物件偵測 | 找出圖像中的物件位置和類別 | 邊界框 + 類別標籤 |
| 語義分割 | 為圖像中每個像素分配語義類別 | 整張圖像的像素級分類 |
| 實例分割 | 為每個物件實例生成精確的像素級分割 | 每個物件實例的分割遮罩 |
技術發展的層次關係:
• 圖像分類:最基礎的視覺任務
• 物件偵測:在分類基礎上增加定位能力
• 語義分割:像素級的類別理解
• 實例分割:在語義分割基礎上區分實例
各技術的應用領域:
• 圖像分類:相片整理、內容審核
• 物件偵測:自動駕駛、安全監控
• 語義分割:場景理解、機器人導航
• 實例分割:醫學影像分析、工業品質控制
#8
★★★★
企業在生成式 AI導入中,可選擇下列哪一種模型壓縮(Model Compression)技術以減少記憶體使用?
💡 答案解析
正確答案:A
參數剪枝(Parameter Pruning)是模型壓縮技術中最常用和有效的方法之一。
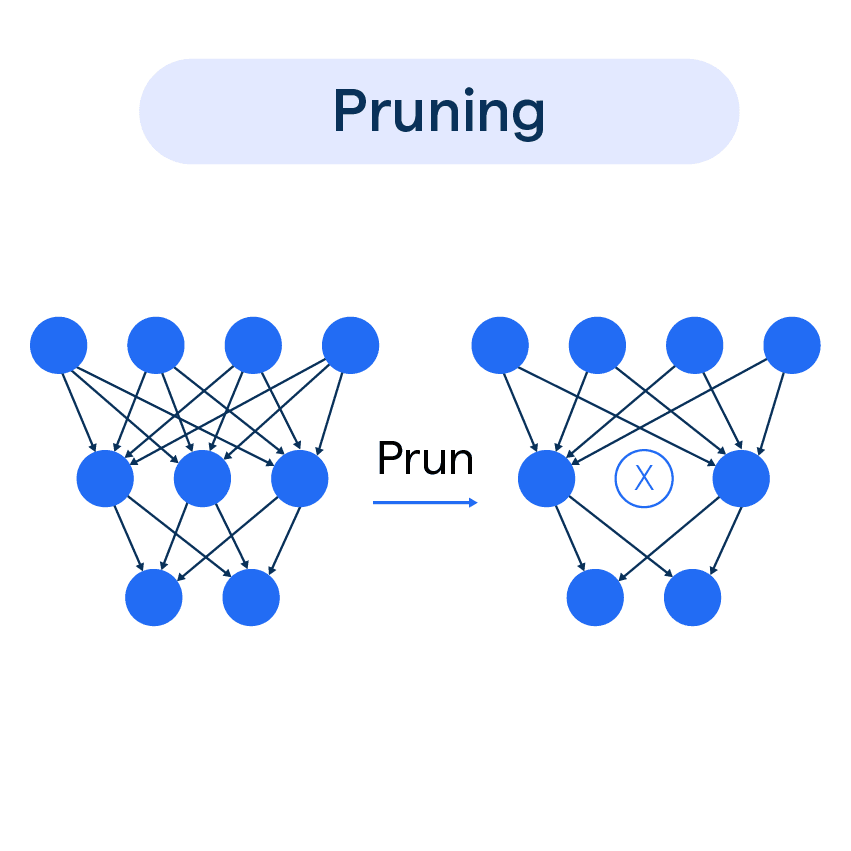 參數剪枝的原理:
參數剪枝的原理:
• 移除不重要的權重參數
• 保留對模型性能影響較大的參數
• 顯著減少模型大小和記憶體使用
參數剪枝的類型:
其他選項為何不正確:
• 增加訓練數據量:會增加記憶體使用而非減少
• 增加模型層數:會增加模型大小和記憶體需求
• 使用更高維數據:會增加計算和記憶體負擔
模型壓縮的其他技術:
• 量化:降低權重精度
• 知識蒸餾:將大模型知識轉移到小模型
• 低秩分解:矩陣分解降低參數量
• 參數共享:不同層共享參數
參數剪枝(Parameter Pruning)是模型壓縮技術中最常用和有效的方法之一。
參數剪枝的原理:• 移除不重要的權重參數
• 保留對模型性能影響較大的參數
• 顯著減少模型大小和記憶體使用
參數剪枝的類型:
| 剪枝類型 | 說明 | 壓縮效果 |
|---|---|---|
| 非結構化剪枝 | 隨機移除個別權重 | 壓縮率高,但需要特殊硬體 |
| 結構化剪枝 | 移除整個神經元或濾波器 | 壓縮率中等,但通用性好 |
| 動態剪枝 | 在運行時動態決定保留的權重 | 壓縮率高,運行時自適應 |
其他選項為何不正確:
• 增加訓練數據量:會增加記憶體使用而非減少
• 增加模型層數:會增加模型大小和記憶體需求
• 使用更高維數據:會增加計算和記憶體負擔
模型壓縮的其他技術:
• 量化:降低權重精度
• 知識蒸餾:將大模型知識轉移到小模型
• 低秩分解:矩陣分解降低參數量
• 參數共享:不同層共享參數
#9
★★★★
供應鏈攻擊(Supply
Chain Attacks)如何影響企業內部 AI 系統安全?
💡 答案解析
正確答案:B
供應鏈攻擊對AI系統的威脅主要來自於依賴的第三方組件和資料。
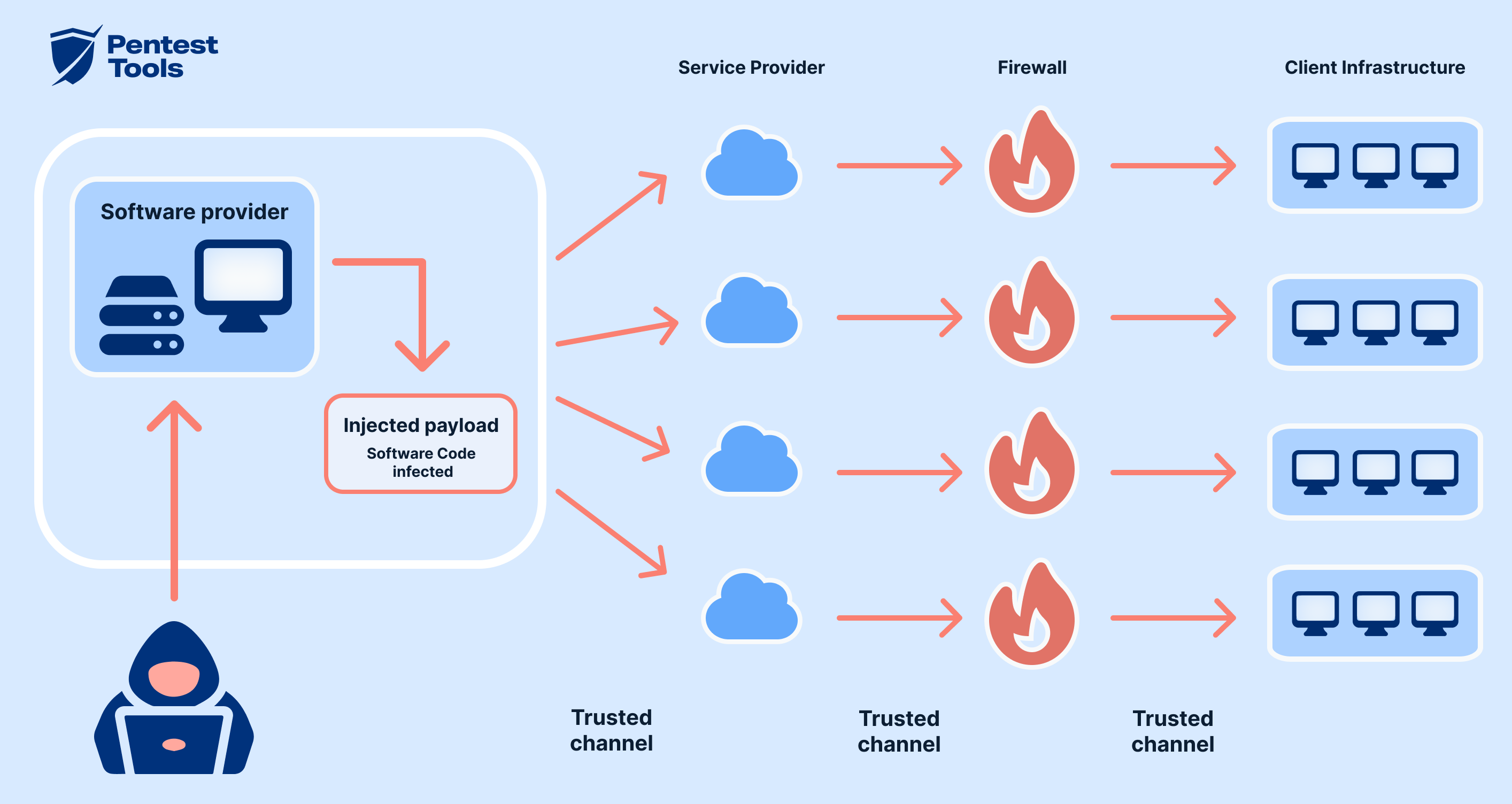
供應鏈攻擊在AI系統中的表現形式:
• 污染的訓練數據:攻擊者植入惡意數據影響模型學習
• 惡意模型更新:透過更新機制注入後門
• 開源庫漏洞:利用開源組件的已知漏洞
• 第三方服務風險:雲服務或API的安全問題
AI供應鏈攻擊的典型案例:
其他選項為何不正確:
• 釣魚郵件攻擊:屬於社會工程攻擊而非供應鏈攻擊
• DDoS攻擊:屬於網路層攻擊而非供應鏈攻擊
• 硬體層影響:供應鏈攻擊確實會影響軟體和模型層
AI供應鏈安全的防護措施:
• 供應商審核:評估第三方組件的安全性
• 資料驗證:檢查訓練數據的完整性
• 模型審計:定期檢查模型行為
• 多樣化供應:避免依賴單一供應商
供應鏈攻擊對AI系統的威脅主要來自於依賴的第三方組件和資料。
供應鏈攻擊在AI系統中的表現形式:
• 污染的訓練數據:攻擊者植入惡意數據影響模型學習
• 惡意模型更新:透過更新機制注入後門
• 開源庫漏洞:利用開源組件的已知漏洞
• 第三方服務風險:雲服務或API的安全問題
AI供應鏈攻擊的典型案例:
| 攻擊類型 | 攻擊方式 | 影響 |
|---|---|---|
| 資料污染 | 在公開數據集中植入惡意樣本 | 模型學習到錯誤的行為模式 |
| 模型中毒 | 修改預訓練模型的權重 | 模型產生預期的惡意輸出 |
| 依賴污染 | 攻擊開源庫或第三方服務 | 影響所有使用該組件的系統 |
其他選項為何不正確:
• 釣魚郵件攻擊:屬於社會工程攻擊而非供應鏈攻擊
• DDoS攻擊:屬於網路層攻擊而非供應鏈攻擊
• 硬體層影響:供應鏈攻擊確實會影響軟體和模型層
AI供應鏈安全的防護措施:
• 供應商審核:評估第三方組件的安全性
• 資料驗證:檢查訓練數據的完整性
• 模型審計:定期檢查模型行為
• 多樣化供應:避免依賴單一供應商
#10
★★★★
下列何者為自然語言處理(Natural Language Processing, NLP)中的詞嵌入技術,能將文字轉換為向量以利機器學習處理?
💡 答案解析
正確答案:B
Word2Vec是詞嵌入(Word Embedding)技術的經典代表,能夠將文字轉換為稠密向量表示。
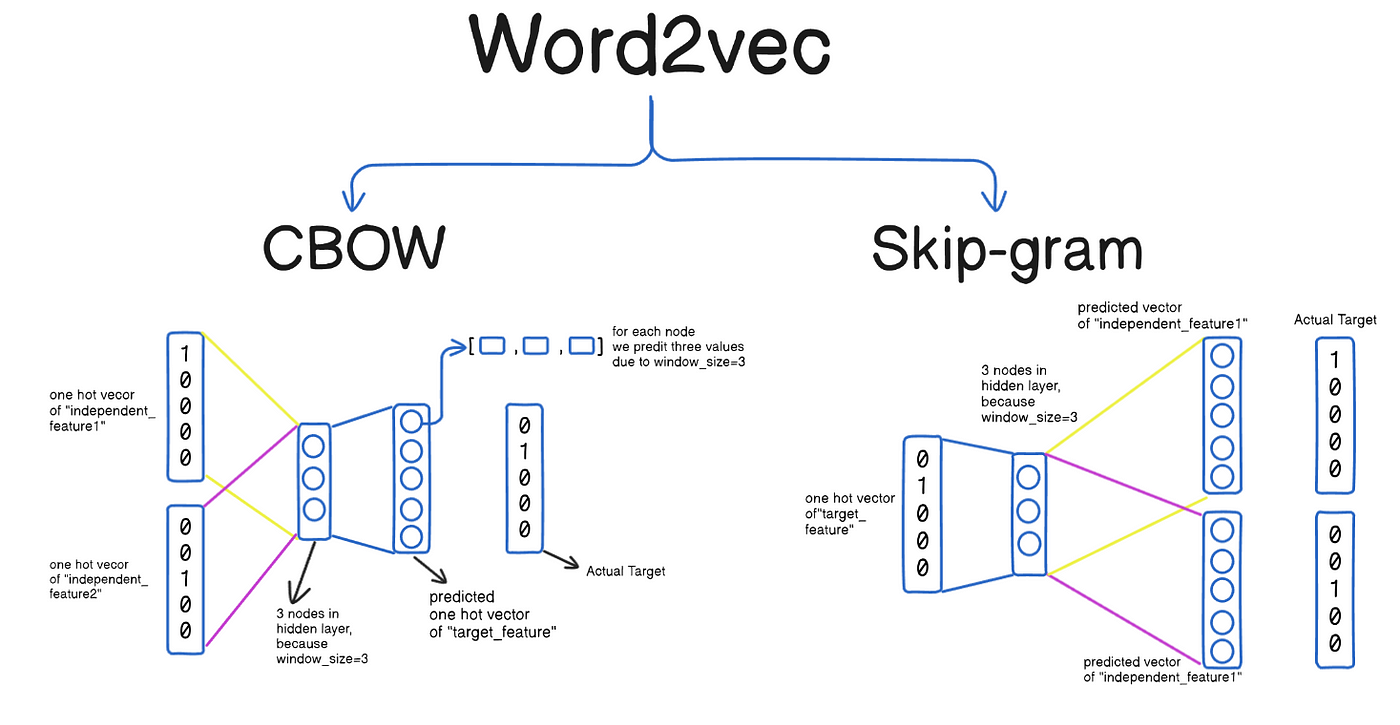
Word2Vec的核心特點:
• 將詞彙映射到連續向量空間
• 捕捉詞彙間的語義關係
• 支援向量運算(如:king - man + woman = queen)
Word2Vec的訓練方法:
其他選項的區別:
• TF-IDF:統計方法,產生稀疏向量
• Stop Words:停用詞清單,用於預處理
• Bag-of-Words:詞袋模型,忽略詞序
詞嵌入技術的演進:
• Word2Vec:基於神經網路的詞嵌入
• GloVe:基於全局詞共現統計
• FastText:支援子詞嵌入
• BERT:基於Transformer的上下文嵌入
Word2Vec是詞嵌入(Word Embedding)技術的經典代表,能夠將文字轉換為稠密向量表示。
Word2Vec的核心特點:
• 將詞彙映射到連續向量空間
• 捕捉詞彙間的語義關係
• 支援向量運算(如:king - man + woman = queen)
Word2Vec的訓練方法:
| 方法 | 原理 | 優點 |
|---|---|---|
| CBOW | 根據上下文詞彙預測中心詞 | 訓練速度快,適合常見詞 |
| Skip-gram | 根據中心詞預測上下文詞 | 適合生僻詞,語義更準確 |
其他選項的區別:
• TF-IDF:統計方法,產生稀疏向量
• Stop Words:停用詞清單,用於預處理
• Bag-of-Words:詞袋模型,忽略詞序
詞嵌入技術的演進:
• Word2Vec:基於神經網路的詞嵌入
• GloVe:基於全局詞共現統計
• FastText:支援子詞嵌入
• BERT:基於Transformer的上下文嵌入
#11
★★★★
在多模態學習中,早期融合(Early Fusion)方法的主要特徵為何?
💡 答案解析
正確答案:B
早期融合(Early Fusion)是在多模態學習中最早進行模態整合的方法。
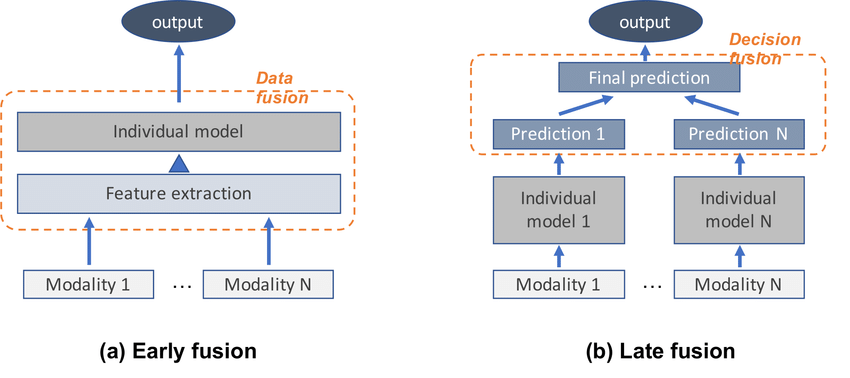
早期融合的特徵:
• 在資料處理的早期階段進行融合
• 整合發生在特徵層面而非決策層面
• 允許不同模態間的深度互動
多模態融合方法的比較:
其他選項為何不正確:
• 決策合併:屬於晚期融合方法
• 單一來源處理:不是多模態學習
• 深層注意力融合:屬於混合融合方法
早期融合的應用場景:
• 視覺-語言理解:圖像和文本的聯合理解
• 語音識別:音頻和視覺信息的結合
• 多感官機器人:整合多種感測器數據
早期融合(Early Fusion)是在多模態學習中最早進行模態整合的方法。
早期融合的特徵:
• 在資料處理的早期階段進行融合
• 整合發生在特徵層面而非決策層面
• 允許不同模態間的深度互動
多模態融合方法的比較:
| 融合階段 | 說明 | 優缺點 |
|---|---|---|
| 早期融合 | 在輸入或特徵層面整合 | 能深度互動,但計算複雜 |
| 晚期融合 | 在決策層面整合結果 | 計算簡單,但互動有限 |
| 混合融合 | 結合早期和晚期融合 | 平衡效果與複雜度 |
其他選項為何不正確:
• 決策合併:屬於晚期融合方法
• 單一來源處理:不是多模態學習
• 深層注意力融合:屬於混合融合方法
早期融合的應用場景:
• 視覺-語言理解:圖像和文本的聯合理解
• 語音識別:音頻和視覺信息的結合
• 多感官機器人:整合多種感測器數據
#12
★★★★★
下列哪項技術最有助於強化醫療多模態 AI 系統在處理影像與文本數據時的整合能力?
💡 答案解析
正確答案:D
Transformer架構在多模態學習中表現卓越,特別適合整合醫療影像與臨床文本資訊。
Transformer在醫療多模態AI的優勢:
• 自注意力機制:能夠捕捉不同模態間的複雜關係
• 並行處理能力:同時處理影像和文本特徵
• 長距離依賴建模:理解影像區域與文本描述的對應關係
• 可解釋性:注意力權重提供診斷依據的可視化
醫療多模態AI的應用場景:
其他選項為何不正確:
• 預定義規則:缺乏學習能力,無法處理複雜多模態關係
• 僅使用CNN:CNN主要處理影像,對文本處理能力有限
• 單一模態模型:無法利用多模態間的互補資訊
Transformer在醫療AI的技術優勢:
• Vision Transformer (ViT):處理醫療影像
• BERT/GPT:理解臨床文本
• 跨模態注意力:建立影像-文本對應關係
Transformer架構在多模態學習中表現卓越,特別適合整合醫療影像與臨床文本資訊。
Transformer在醫療多模態AI的優勢:
• 自注意力機制:能夠捕捉不同模態間的複雜關係
• 並行處理能力:同時處理影像和文本特徵
• 長距離依賴建模:理解影像區域與文本描述的對應關係
• 可解釋性:注意力權重提供診斷依據的可視化
醫療多模態AI的應用場景:
| 應用領域 | 影像模態 | 文本模態 |
|---|---|---|
| 放射科診斷 | X光、CT、MRI影像 | 放射科報告、病史 |
| 病理診斷 | 組織切片影像 | 病理報告、臨床資料 |
| 皮膚科診斷 | 皮膚病變照片 | 症狀描述、病史記錄 |
其他選項為何不正確:
• 預定義規則:缺乏學習能力,無法處理複雜多模態關係
• 僅使用CNN:CNN主要處理影像,對文本處理能力有限
• 單一模態模型:無法利用多模態間的互補資訊
Transformer在醫療AI的技術優勢:
• Vision Transformer (ViT):處理醫療影像
• BERT/GPT:理解臨床文本
• 跨模態注意力:建立影像-文本對應關係
#13
★★★★
某線上音樂平台希望根據用戶的聽歌與查詢行為,將用戶劃分為不同的類型。若事前沒有定義用戶類型,下列哪一種模型最適合用於此任務?
💡 答案解析
正確答案:C
由於事前沒有定義用戶類型,這是典型的無監督學習(Unsupervised Learning)問題,需要使用聚類算法。

DBSCAN的優勢:
• 無需預設聚類數量:自動發現用戶群體數量
• 處理噪音數據:能識別異常用戶行為
• 發現任意形狀聚類:適合複雜的用戶行為模式
• 密度導向:根據行為相似度自然分群
聚類算法比較:
其他選項為何不正確:
• 邏輯迴歸:監督學習,需要預先標記的用戶類型
• 決策樹:監督學習,需要已知的分類標籤
• 線性迴歸:用於預測連續數值,不適合分類任務
音樂平台用戶聚類的應用:
• 音樂偏好分群:古典、流行、搖滾愛好者
• 使用習慣分群:重度、輕度、週末用戶
• 探索行為分群:保守型、探索型用戶
• 個性化推薦:針對不同群體提供客製化服務
由於事前沒有定義用戶類型,這是典型的無監督學習(Unsupervised Learning)問題,需要使用聚類算法。
DBSCAN的優勢:
• 無需預設聚類數量:自動發現用戶群體數量
• 處理噪音數據:能識別異常用戶行為
• 發現任意形狀聚類:適合複雜的用戶行為模式
• 密度導向:根據行為相似度自然分群
聚類算法比較:
| 算法 | 優點 | 缺點 |
|---|---|---|
| K-Means | 計算效率高 | 需預設K值,假設球形聚類 |
| DBSCAN | 自動決定聚類數,處理噪音 | 參數敏感,密度變化大時效果差 |
| 層次聚類 | 提供聚類樹狀結構 | 計算複雜度高 |
其他選項為何不正確:
• 邏輯迴歸:監督學習,需要預先標記的用戶類型
• 決策樹:監督學習,需要已知的分類標籤
• 線性迴歸:用於預測連續數值,不適合分類任務
音樂平台用戶聚類的應用:
• 音樂偏好分群:古典、流行、搖滾愛好者
• 使用習慣分群:重度、輕度、週末用戶
• 探索行為分群:保守型、探索型用戶
• 個性化推薦:針對不同群體提供客製化服務
#14
★★★★★
在訓練模型時,若數據中出現特徵尺度差異極大(例如:年齡為 0–100、收入為
0–1,000,000),容易導致模型偏向特定特徵。為提升模型效能與穩定性,以下哪一種預處理方式最能有效解決此問題?
💡 答案解析
正確答案:B
Z-score 標準化是處理特徵尺度差異的最佳方法,能將所有特徵轉換為相同的統計分布。

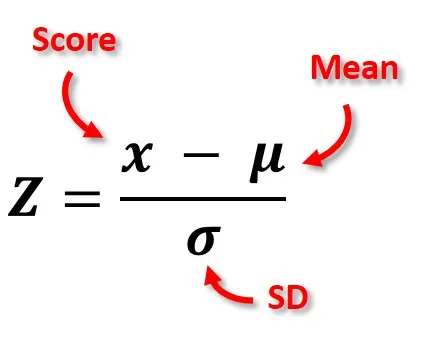
Z-score標準化的優勢:
• 統一分布:將所有特徵轉換為均值0、標準差1的分布
• 保持相對關係:維持原始數據的統計特性
• 適用性廣:適合大多數機器學習算法
• 處理異常值:相對於Min-Max更能處理極值
特徵縮放方法比較:
為什麼選擇Z-score而非Min-Max:
• 異常值處理:收入數據可能有極端值,Z-score更穩健
• 分布假設:不假設數據有固定的最小最大值
• 算法適配:多數ML算法假設特徵呈常態分布
其他選項為何不正確:
• 移除小尺度欄位:會丟失重要資訊,年齡可能很重要
• Min-Max正規化:對異常值敏感,收入極值會影響縮放
• 加常數:無法解決尺度差異問題
實際應用範例:
• 原始數據:年齡(25)、收入(50000)
• 標準化後:年齡(-0.5)、收入(0.2)
• 效果:兩個特徵在相同尺度上,模型不會偏向收入特徵
Z-score 標準化是處理特徵尺度差異的最佳方法,能將所有特徵轉換為相同的統計分布。
Z-score標準化的優勢:
• 統一分布:將所有特徵轉換為均值0、標準差1的分布
• 保持相對關係:維持原始數據的統計特性
• 適用性廣:適合大多數機器學習算法
• 處理異常值:相對於Min-Max更能處理極值
特徵縮放方法比較:
| 方法 | 公式 | 適用場景 |
|---|---|---|
| Z-score標準化 | (x - μ) / σ | 數據呈常態分布,有異常值 |
| Min-Max正規化 | (x - min) / (max - min) | 數據分布均勻,無異常值 |
| Robust Scaling | (x - median) / IQR | 數據有大量異常值 |
為什麼選擇Z-score而非Min-Max:
• 異常值處理:收入數據可能有極端值,Z-score更穩健
• 分布假設:不假設數據有固定的最小最大值
• 算法適配:多數ML算法假設特徵呈常態分布
其他選項為何不正確:
• 移除小尺度欄位:會丟失重要資訊,年齡可能很重要
• Min-Max正規化:對異常值敏感,收入極值會影響縮放
• 加常數:無法解決尺度差異問題
實際應用範例:
• 原始數據:年齡(25)、收入(50000)
• 標準化後:年齡(-0.5)、收入(0.2)
• 效果:兩個特徵在相同尺度上,模型不會偏向收入特徵
#15
★★★★
某企業即將部署 AI
模型至現有營運系統,進入系統整合測試階段。測試工程師需確認所有模組在實際環境中能正確協同運作。下列哪項驗證最應優先執行?
💡 答案解析
正確答案:B
在系統整合測試階段,最優先的是確保AI模型能與現有系統正確連接和資料交換。
資料介面相容性驗證的重要性:
• 基礎連接:確保模型能接收系統輸入資料
• 資料格式:驗證資料型態、結構、編碼一致性
• 通訊協定:確認API、訊息佇列等介面正常
• 錯誤處理:測試異常情況的處理機制
系統整合測試的優先順序:
其他選項為何不是優先項目:
• 離線準確率驗證:應在模型開發階段完成
• 硬體效能測試:在介面連接確認後進行
• 學習能力評估:屬於模型優化階段的工作
資料介面相容性檢查清單:
• 資料格式:JSON、XML、CSV等格式一致性
• 欄位對應:確保所有必要欄位正確映射
• 資料型態:數值、字串、日期格式相容
• 編碼方式:UTF-8、ASCII等編碼統一
• API版本:確保使用相容的API版本
常見的介面問題:
• 資料遺失:欄位名稱不匹配
• 型態錯誤:字串與數值混淆
• 編碼問題:中文字元顯示異常
• 時區差異:時間戳記不一致
在系統整合測試階段,最優先的是確保AI模型能與現有系統正確連接和資料交換。
資料介面相容性驗證的重要性:
• 基礎連接:確保模型能接收系統輸入資料
• 資料格式:驗證資料型態、結構、編碼一致性
• 通訊協定:確認API、訊息佇列等介面正常
• 錯誤處理:測試異常情況的處理機制
系統整合測試的優先順序:
| 優先級 | 測試項目 | 目的 |
|---|---|---|
| 1. 最高 | 資料介面相容性 | 確保基本連接和資料交換 |
| 2. 高 | 功能整合測試 | 驗證端到端業務流程 |
| 3. 中 | 效能與負載測試 | 確保系統穩定性 |
| 4. 低 | 模型準確率驗證 | 確認業務價值 |
其他選項為何不是優先項目:
• 離線準確率驗證:應在模型開發階段完成
• 硬體效能測試:在介面連接確認後進行
• 學習能力評估:屬於模型優化階段的工作
資料介面相容性檢查清單:
• 資料格式:JSON、XML、CSV等格式一致性
• 欄位對應:確保所有必要欄位正確映射
• 資料型態:數值、字串、日期格式相容
• 編碼方式:UTF-8、ASCII等編碼統一
• API版本:確保使用相容的API版本
常見的介面問題:
• 資料遺失:欄位名稱不匹配
• 型態錯誤:字串與數值混淆
• 編碼問題:中文字元顯示異常
• 時區差異:時間戳記不一致
📊 科目二: 大數據處理分析與應用
#1
★★★★
在巨量資料分析班中,共有一年級至四年級,每個年級有 50 個學生,且學生身高呈常態分佈。下列敘述何者不正確?
💡 答案解析
正確答案:D
卡方檢定主要用於檢定類別資料的獨立性或適合度,而非用於檢定平均值是否等於特定數值。

各檢定方法的適用場合:
• t 檢定:用於比較兩個群體的平均值差異,或單一群體平均值與特定值的差異
• F 檢定:用於比較三個或以上群體的平均值差異(ANOVA)
• 卡方檢定:用於類別資料的獨立性檢定或適合度檢定
正確的檢定方法:
檢測一年級的平均身高是否等於 170 公分,應該使用 單一樣本 t 檢定(One-sample t-test)。
卡方檢定主要用於檢定類別資料的獨立性或適合度,而非用於檢定平均值是否等於特定數值。
各檢定方法的適用場合:
• t 檢定:用於比較兩個群體的平均值差異,或單一群體平均值與特定值的差異
• F 檢定:用於比較三個或以上群體的平均值差異(ANOVA)
• 卡方檢定:用於類別資料的獨立性檢定或適合度檢定
正確的檢定方法:
檢測一年級的平均身高是否等於 170 公分,應該使用 單一樣本 t 檢定(One-sample t-test)。
#2
★★★★
關於接受者操作特徵(ROC)曲線,下列敘述何者正確?
💡 答案解析
正確答案:A
ROC 曲線(Receiver Operating Characteristic curve)是評估二元分類模型性能的重要工具。
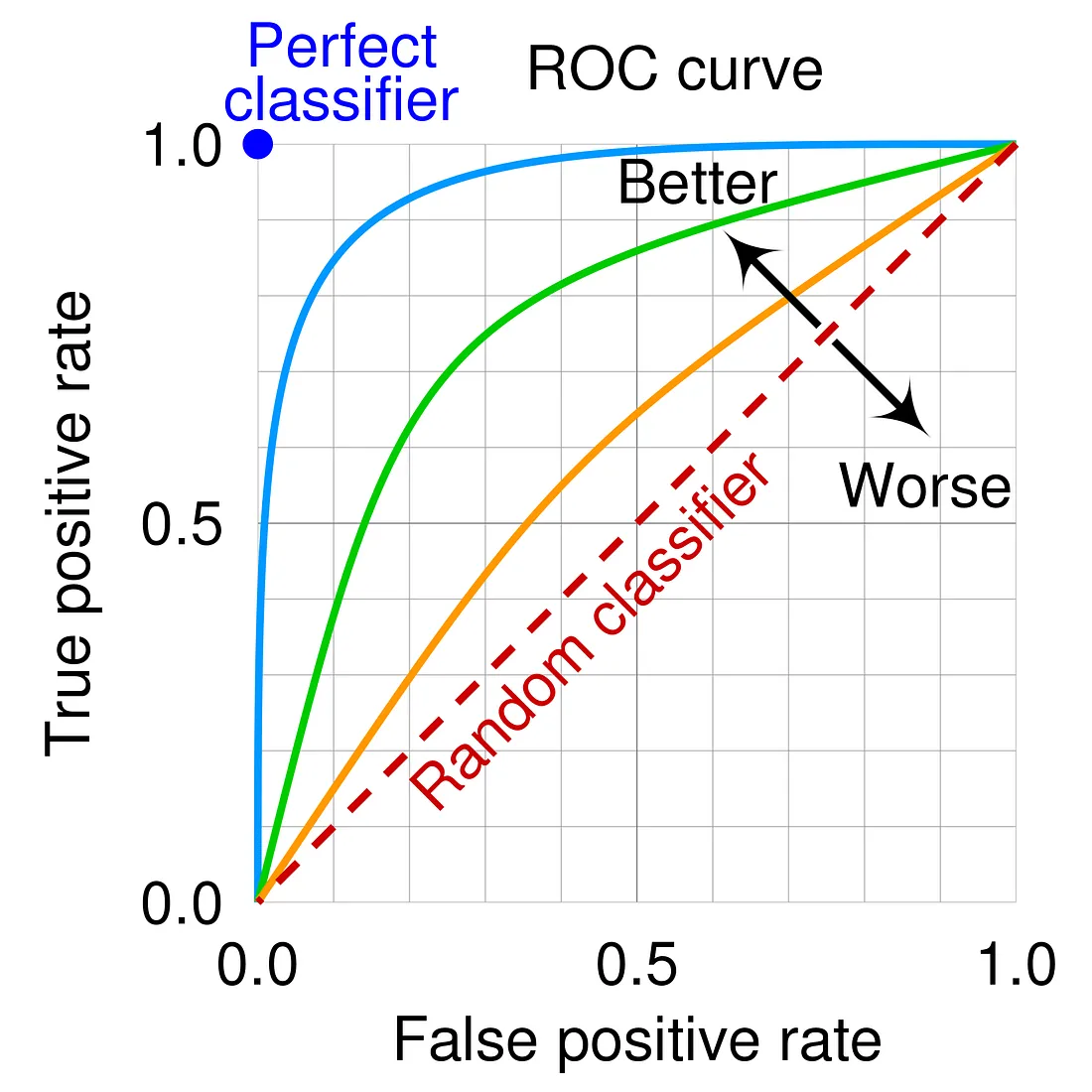
ROC 曲線的構成:
• 橫軸:假陽性率(False Positive Rate, FPR)
• 縱軸:真陽性率(True Positive Rate, TPR)
• 曲線:顯示在不同分類閾值下模型的性能表現
ROC 曲線的應用:
• 模型比較:比較不同模型的性能
• 閾值選擇:選擇最適當的分類閾值
• AUC 計算:計算曲線下面積評估整體性能
ROC 曲線(Receiver Operating Characteristic curve)是評估二元分類模型性能的重要工具。
ROC 曲線的構成:
• 橫軸:假陽性率(False Positive Rate, FPR)
• 縱軸:真陽性率(True Positive Rate, TPR)
• 曲線:顯示在不同分類閾值下模型的性能表現
ROC 曲線的應用:
• 模型比較:比較不同模型的性能
• 閾值選擇:選擇最適當的分類閾值
• AUC 計算:計算曲線下面積評估整體性能
#3
★★★★
下列何者不屬於特徵工程(Feature Engineering)?
💡 答案解析
正確答案:D
特徵工程是機器學習中最重要的步驟之一,主要包括資料預處理和特徵構建,但不包括模型預測。
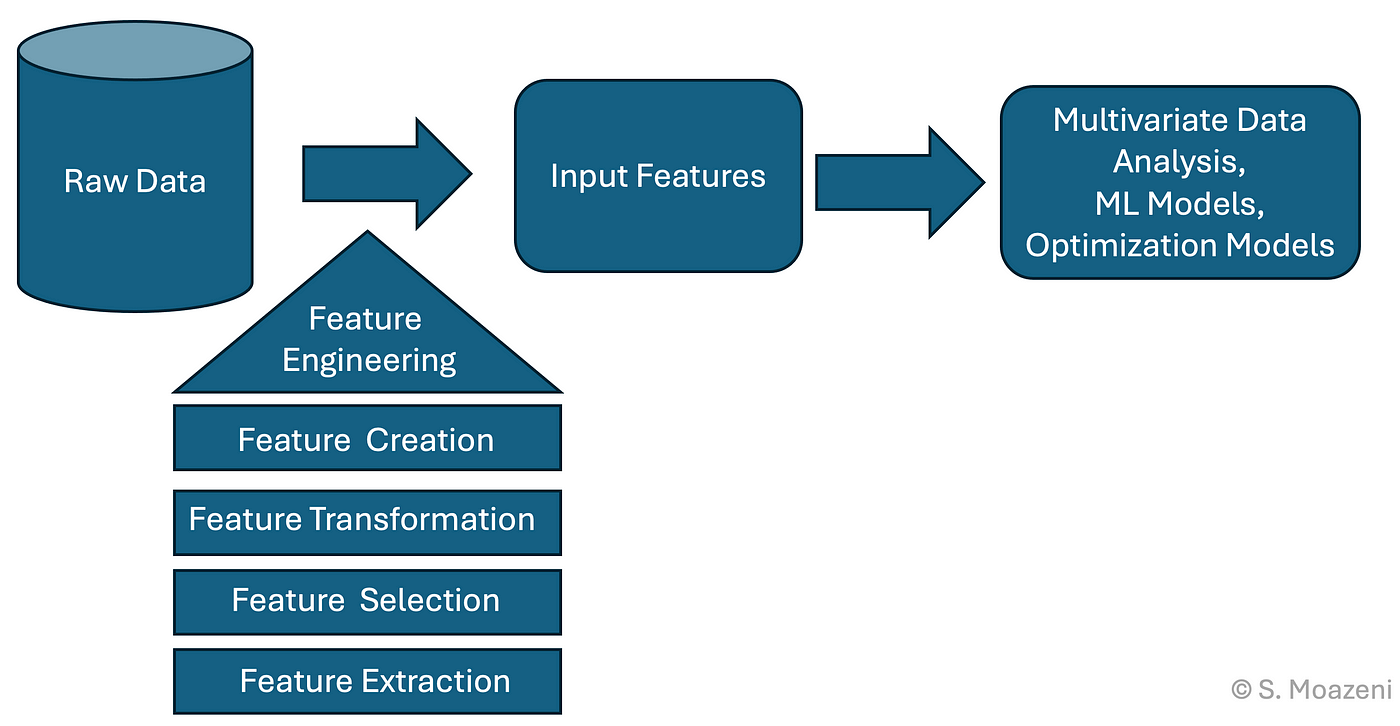
特徵工程的主要階段:
• 特徵轉換:將原始特徵轉換為更適合模型的形式
• 特徵萃取:從原始資料中提取有用的特徵
• 特徵挑選:選擇最相關和重要的特徵
預測是模型訓練和評估階段的工作:
• 使用訓練好的模型進行預測
• 屬於模型應用而非特徵工程
特徵工程是機器學習中最重要的步驟之一,主要包括資料預處理和特徵構建,但不包括模型預測。
特徵工程的主要階段:
• 特徵轉換:將原始特徵轉換為更適合模型的形式
• 特徵萃取:從原始資料中提取有用的特徵
• 特徵挑選:選擇最相關和重要的特徵
預測是模型訓練和評估階段的工作:
• 使用訓練好的模型進行預測
• 屬於模型應用而非特徵工程
#4
★★★★
拉拉網路商城的老闆擬透過機器學習的方式,利用過往的產品銷售資料,預測下一季的產品銷售數量,以調整現有的庫存水位。下列哪一個類型的模型,比較適合應用在老闆期望的預測目標?
💡 答案解析
正確答案:D
銷售數量預測是一個典型的迴歸問題,需要預測連續數值。
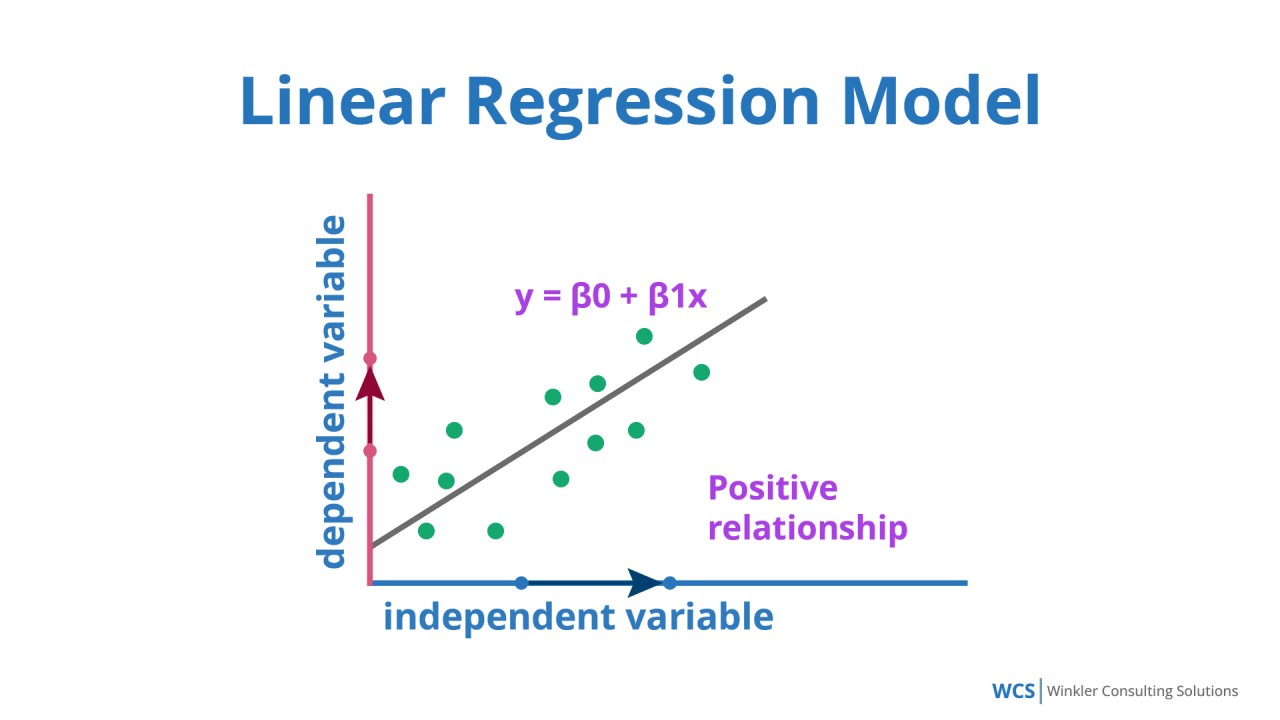
各模型類型的適用場景:
• 線性迴歸:預測連續數值,如銷售額、價格等
• 決策樹分類器:分類問題,如客戶類型識別
• K-means 分群:無監督學習,發現資料中的群體結構
• 主成分分析:降維技術,減少特徵數量
銷售預測的特點:
• 連續數值輸出
• 基於歷史資料預測未來趨勢
• 適合使用時間序列分析或迴歸模型
銷售數量預測是一個典型的迴歸問題,需要預測連續數值。
各模型類型的適用場景:
• 線性迴歸:預測連續數值,如銷售額、價格等
• 決策樹分類器:分類問題,如客戶類型識別
• K-means 分群:無監督學習,發現資料中的群體結構
• 主成分分析:降維技術,減少特徵數量
銷售預測的特點:
• 連續數值輸出
• 基於歷史資料預測未來趨勢
• 適合使用時間序列分析或迴歸模型
#5
★★★★
對於低結構化的文本或圖像資料,下列哪一種特徵工程(Feature Engineering)方法最為適用?
💡 答案解析
正確答案:C
對於低結構化的文本或圖像資料,手動設計特徵非常困難,需要使用特徵學習方法自動從資料中學習特徵。
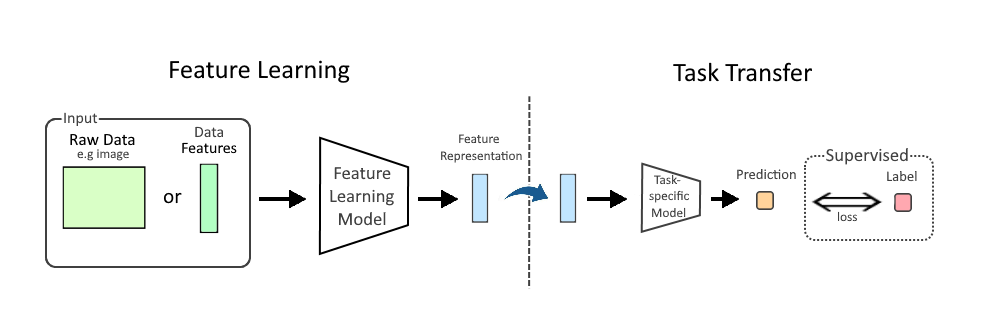
特徵學習的優勢:
• 自動特徵提取:無需手動設計特徵
• 處理複雜資料:適合圖像、文本、語音等非結構化資料
• 深度學習應用:CNN、RNN 等深度學習模型的核心能力
不同特徵工程方法的適用資料類型:
• 特徵學習:圖像、文本、語音等非結構化資料
• 特徵建構:結構化資料,需要領域知識
• 特徵選擇:已有特徵集合,需要篩選重要特徵
對於低結構化的文本或圖像資料,手動設計特徵非常困難,需要使用特徵學習方法自動從資料中學習特徵。
特徵學習的優勢:
• 自動特徵提取:無需手動設計特徵
• 處理複雜資料:適合圖像、文本、語音等非結構化資料
• 深度學習應用:CNN、RNN 等深度學習模型的核心能力
不同特徵工程方法的適用資料類型:
• 特徵學習:圖像、文本、語音等非結構化資料
• 特徵建構:結構化資料,需要領域知識
• 特徵選擇:已有特徵集合,需要篩選重要特徵
#6
★★★★
下列哪種方法屬於非監督式學習中的降維技術?
💡 答案解析
正確答案:D
主成分分析(PCA)是無監督學習中最常用的降維技術。
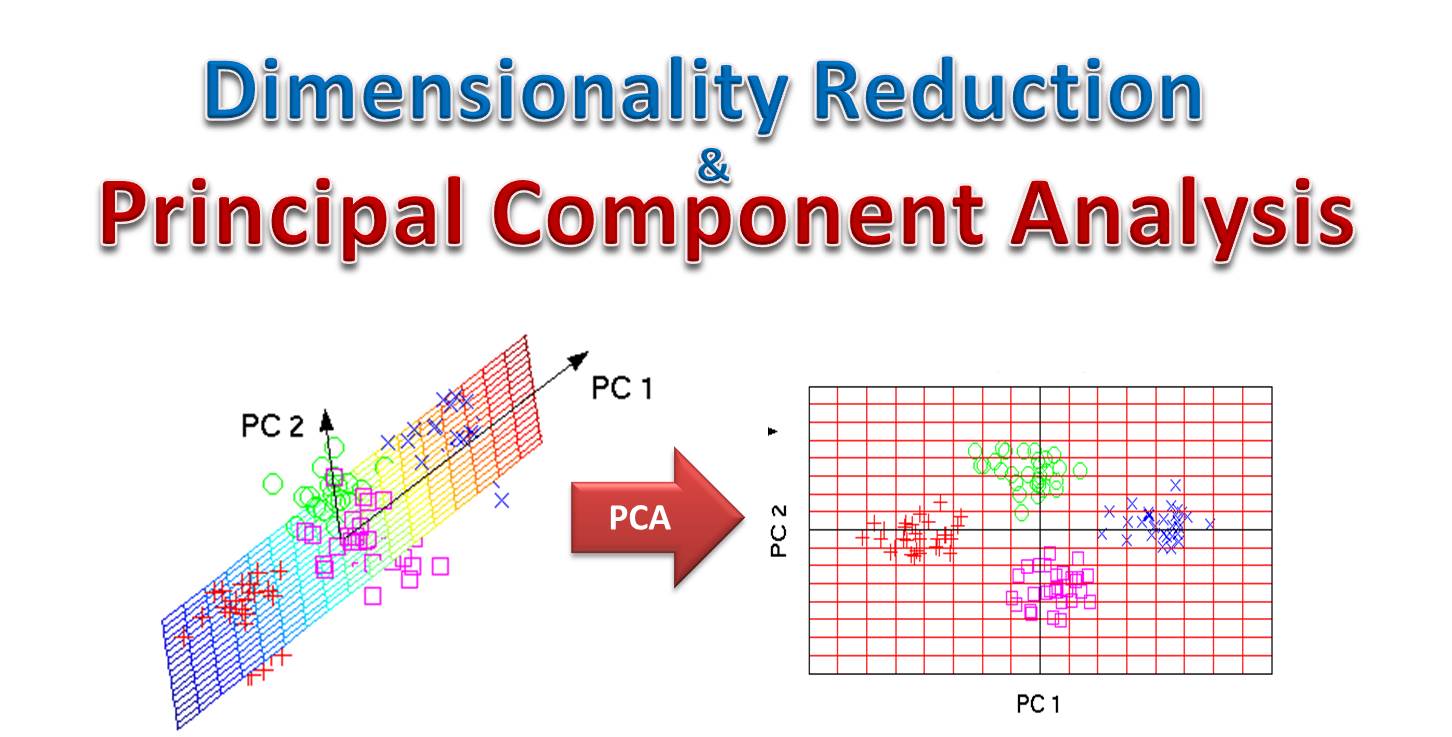
PCA 的工作原理:
• 尋找最大變異方向:找到資料變異最大的方向作為主成分
• 線性轉換:將高維資料投影到低維空間
• 保留重要資訊:盡可能保留原始資料的變異性
其他方法的類型:
• K-means:聚類算法
• 隨機森林:監督式學習的分類/迴歸算法
• 支持向量機:監督式學習的分類/迴歸算法
主成分分析(PCA)是無監督學習中最常用的降維技術。
PCA 的工作原理:
• 尋找最大變異方向:找到資料變異最大的方向作為主成分
• 線性轉換:將高維資料投影到低維空間
• 保留重要資訊:盡可能保留原始資料的變異性
其他方法的類型:
• K-means:聚類算法
• 隨機森林:監督式學習的分類/迴歸算法
• 支持向量機:監督式學習的分類/迴歸算法
#7
★★★★
異常值偵測使用 IQR(Interquartile Range)法時,下列哪一種範圍外的數值會被視為異常?
💡 答案解析
正確答案:D
IQR 方法使用四分位距來定義異常值的範圍,標準是 1.5 倍 IQR。
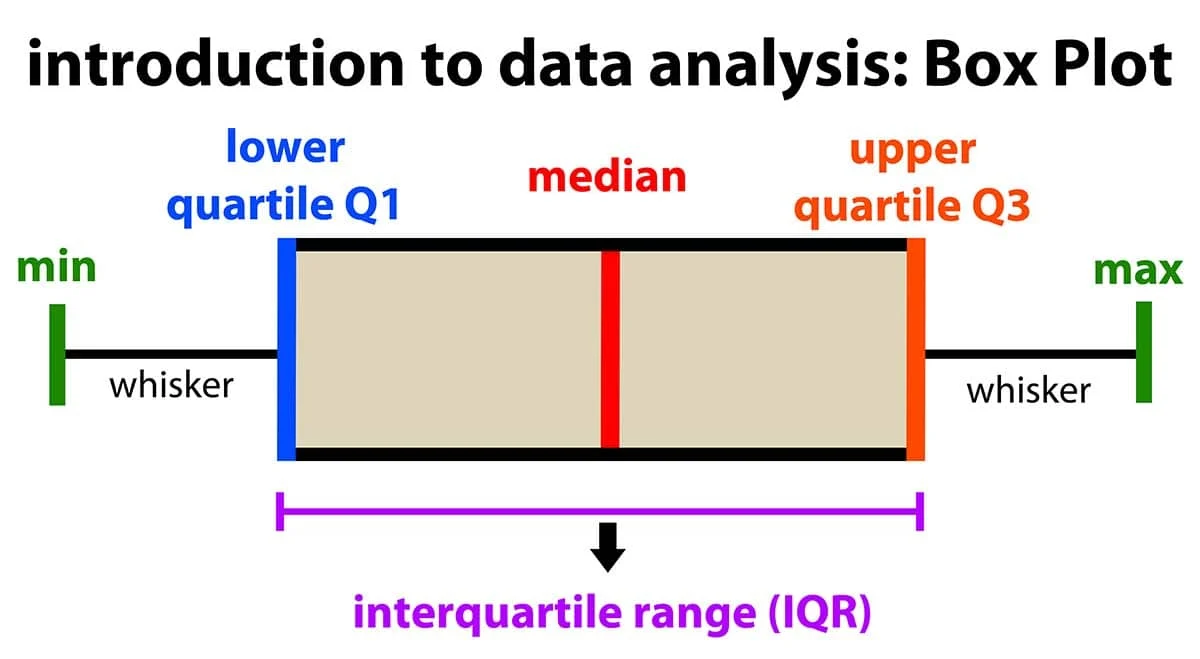
IQR 異常值偵測公式:
• 下界:Q1 - 1.5 × IQR
• 上界:Q3 + 1.5 × IQR
• 異常值:小於下界或大於上界的數值
其他方法的比較:
• 3σ 法則:μ ± 3σ(適用於常態分佈)
• 2σ 法則:μ ± 2σ(較寬鬆的標準)
IQR 方法使用四分位距來定義異常值的範圍,標準是 1.5 倍 IQR。
IQR 異常值偵測公式:
• 下界:Q1 - 1.5 × IQR
• 上界:Q3 + 1.5 × IQR
• 異常值:小於下界或大於上界的數值
其他方法的比較:
• 3σ 法則:μ ± 3σ(適用於常態分佈)
• 2σ 法則:μ ± 2σ(較寬鬆的標準)
#8
★★★★
差分隱私(Differential Privacy)在數據應用中的目的為何?
💡 答案解析
正確答案:A
差分隱私的核心思想是在統計結果中添加適當的隨機噪聲,使得攻擊者無法確定特定個體是否在資料集中。
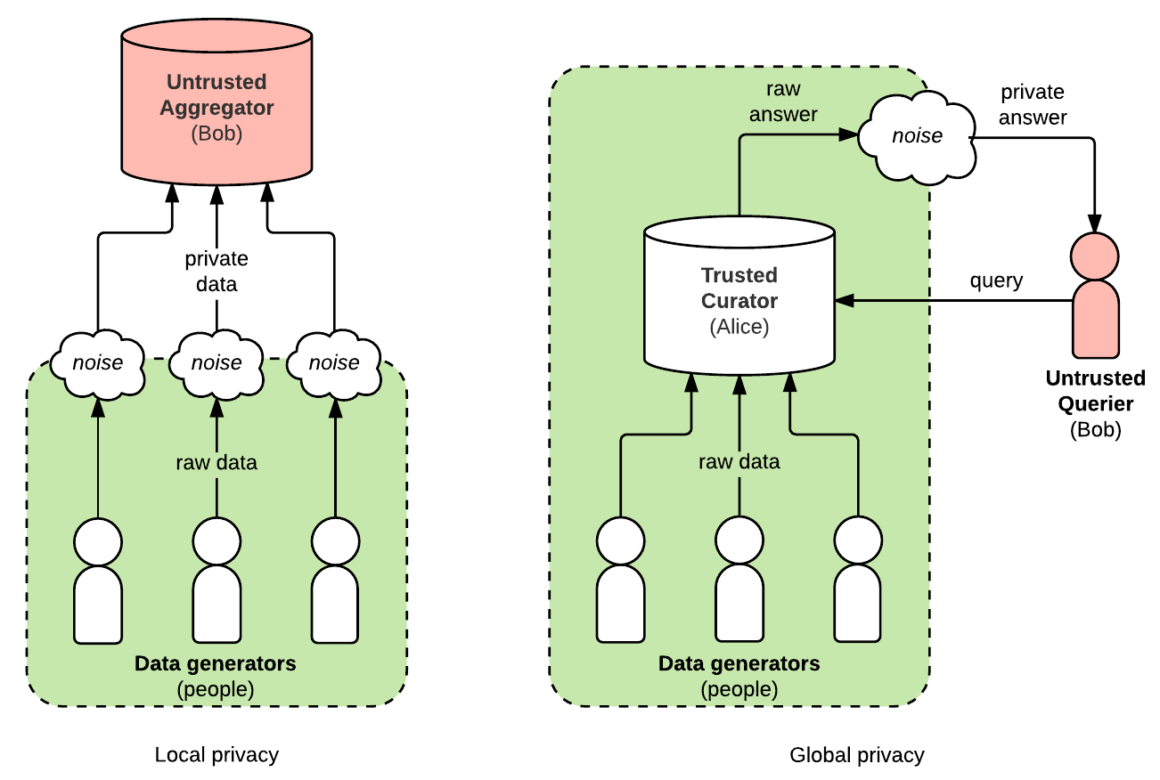
差分隱私的關鍵特性:
• 形式化隱私保護:提供數學證明的隱私保證
• 量化隱私損失:使用 ε 參數量化隱私保護程度
• 實用性平衡:在隱私保護和資料實用性間取得平衡
差分隱私的應用:
• 政府統計:人口普查、經濟統計
• 醫療數據:病患資料分析
• 位置數據:用戶位置軌跡分析
差分隱私的核心思想是在統計結果中添加適當的隨機噪聲,使得攻擊者無法確定特定個體是否在資料集中。
差分隱私的關鍵特性:
• 形式化隱私保護:提供數學證明的隱私保證
• 量化隱私損失:使用 ε 參數量化隱私保護程度
• 實用性平衡:在隱私保護和資料實用性間取得平衡
差分隱私的應用:
• 政府統計:人口普查、經濟統計
• 醫療數據:病患資料分析
• 位置數據:用戶位置軌跡分析
#9
★★★★
若使用主成分分析(PCA)將資料降維至兩個主成分,這表示哪一種情況?
💡 答案解析
正確答案:B
PCA 通過線性轉換將高維資料投影到由主成分構成的新的坐標系統中。
PCA 的降維過程:
• 計算協方差矩陣:分析特徵間的關係
• 特徵值分解:找到主成分的方向
• 選擇主成分:保留最重要的 k 個主成分
• 投影轉換:將原始資料投影到新的主成分空間
PCA 的特點:
• 無監督方法:不需要標籤資訊
• 線性轉換:保持線性關係
• 最大化變異性:保留最多的資訊
PCA 通過線性轉換將高維資料投影到由主成分構成的新的坐標系統中。
PCA 的降維過程:
• 計算協方差矩陣:分析特徵間的關係
• 特徵值分解:找到主成分的方向
• 選擇主成分:保留最重要的 k 個主成分
• 投影轉換:將原始資料投影到新的主成分空間
PCA 的特點:
• 無監督方法:不需要標籤資訊
• 線性轉換:保持線性關係
• 最大化變異性:保留最多的資訊
#10
★★★★
假設有一組成績資料呈現常態分配,平均數為 70,標準差為 10,若某位學生的成績為 90,該學生的 Z 分數約為多少?
💡 答案解析
正確答案:C
Z 分數的計算公式為:Z = (X - μ) / σ
計算過程:
• X = 90(學生成績)
• μ = 70(平均數)
• σ = 10(標準差)
• Z = (90 - 70) / 10 = 20 / 10 = 2
Z 分數的意義:
• Z = 0:成績等於平均數
• Z = 1:成績高於平均數一個標準差
• Z = 2:成績高於平均數兩個標準差
• Z = -1:成績低於平均數一個標準差
Z 分數的計算公式為:Z = (X - μ) / σ
計算過程:
• X = 90(學生成績)
• μ = 70(平均數)
• σ = 10(標準差)
• Z = (90 - 70) / 10 = 20 / 10 = 2
Z 分數的意義:
• Z = 0:成績等於平均數
• Z = 1:成績高於平均數一個標準差
• Z = 2:成績高於平均數兩個標準差
• Z = -1:成績低於平均數一個標準差
#11
★★★★
在 AI 倫理治理的背景下,「透明性(Transparency)」通常是指什麼?
💡 答案解析
正確答案:C
AI 透明性強調的是決策過程的可理解性和可解釋性。
AI 透明性的核心要素:
• 決策依據:清楚說明 AI 做出決策的理由
• 可解釋性:提供決策過程的邏輯解釋
• 責任歸屬:明確決策責任的歸屬
• 審計能力:能夠追蹤和審查決策過程
透明性的重要性:
• 信任建立:增加用戶對 AI 系統的信任
• 責任追究:明確決策責任
• 倫理監督:便於進行倫理審查和監督
AI 透明性強調的是決策過程的可理解性和可解釋性。
AI 透明性的核心要素:
• 決策依據:清楚說明 AI 做出決策的理由
• 可解釋性:提供決策過程的邏輯解釋
• 責任歸屬:明確決策責任的歸屬
• 審計能力:能夠追蹤和審查決策過程
透明性的重要性:
• 信任建立:增加用戶對 AI 系統的信任
• 責任追究:明確決策責任
• 倫理監督:便於進行倫理審查和監督
#12
★★★★
若企業希望即時監控交易異常,應選擇下列哪一類數據處理架構?
💡 答案解析
正確答案:C
即時監控需要能夠處理連續數據流的系統。
串流處理的特點:
• 即時處理:處理數據到達時立即進行處理
• 低延遲:從數據產生到結果輸出的時間很短
• 連續處理:持續處理源源不斷的數據流
串流處理的應用場景:
• 交易監控:即時偵測異常交易
• 系統監控:即時監控系統性能
• 推薦系統:即時推薦內容
其他架構的適用場景:
• 批次處理:定期批量處理歷史數據
• 資料湖:存儲大量原始數據
• 冷資料備援:長期存儲不常訪問的數據
即時監控需要能夠處理連續數據流的系統。
串流處理的特點:
• 即時處理:處理數據到達時立即進行處理
• 低延遲:從數據產生到結果輸出的時間很短
• 連續處理:持續處理源源不斷的數據流
串流處理的應用場景:
• 交易監控:即時偵測異常交易
• 系統監控:即時監控系統性能
• 推薦系統:即時推薦內容
其他架構的適用場景:
• 批次處理:定期批量處理歷史數據
• 資料湖:存儲大量原始數據
• 冷資料備援:長期存儲不常訪問的數據
#13
★★★★
為了分析社群網路使用者之間的互動結構,應使用下列哪種分析方法?
💡 答案解析
正確答案:C
社群網路本質上是圖結構,適合使用圖論分析方法。
圖論分析在社群網路中的應用:
• 中心性分析:識別關鍵用戶(度中心性、介數中心性)
• 社群偵測:發現用戶群體和社區結構
• 路徑分析:分析用戶間的影響路徑
• 結構洞分析:發現網路中的橋樑用戶
其他方法的適用性:
• 文字探勘:分析文本內容而非結構
• 主成分分析:降維分析,適用於數值數據
• 分群分析:發現相似用戶群體,但不考慮網路結構
社群網路本質上是圖結構,適合使用圖論分析方法。
圖論分析在社群網路中的應用:
• 中心性分析:識別關鍵用戶(度中心性、介數中心性)
• 社群偵測:發現用戶群體和社區結構
• 路徑分析:分析用戶間的影響路徑
• 結構洞分析:發現網路中的橋樑用戶
其他方法的適用性:
• 文字探勘:分析文本內容而非結構
• 主成分分析:降維分析,適用於數值數據
• 分群分析:發現相似用戶群體,但不考慮網路結構
#14
★★★★
為了加速大數據環境下的 AI 模型訓練,以下哪一項為常見技術?
💡 答案解析
正確答案:C
混合精度訓練通過使用 16 位浮點數(半精度)來加速訓練並減少記憶體使用。
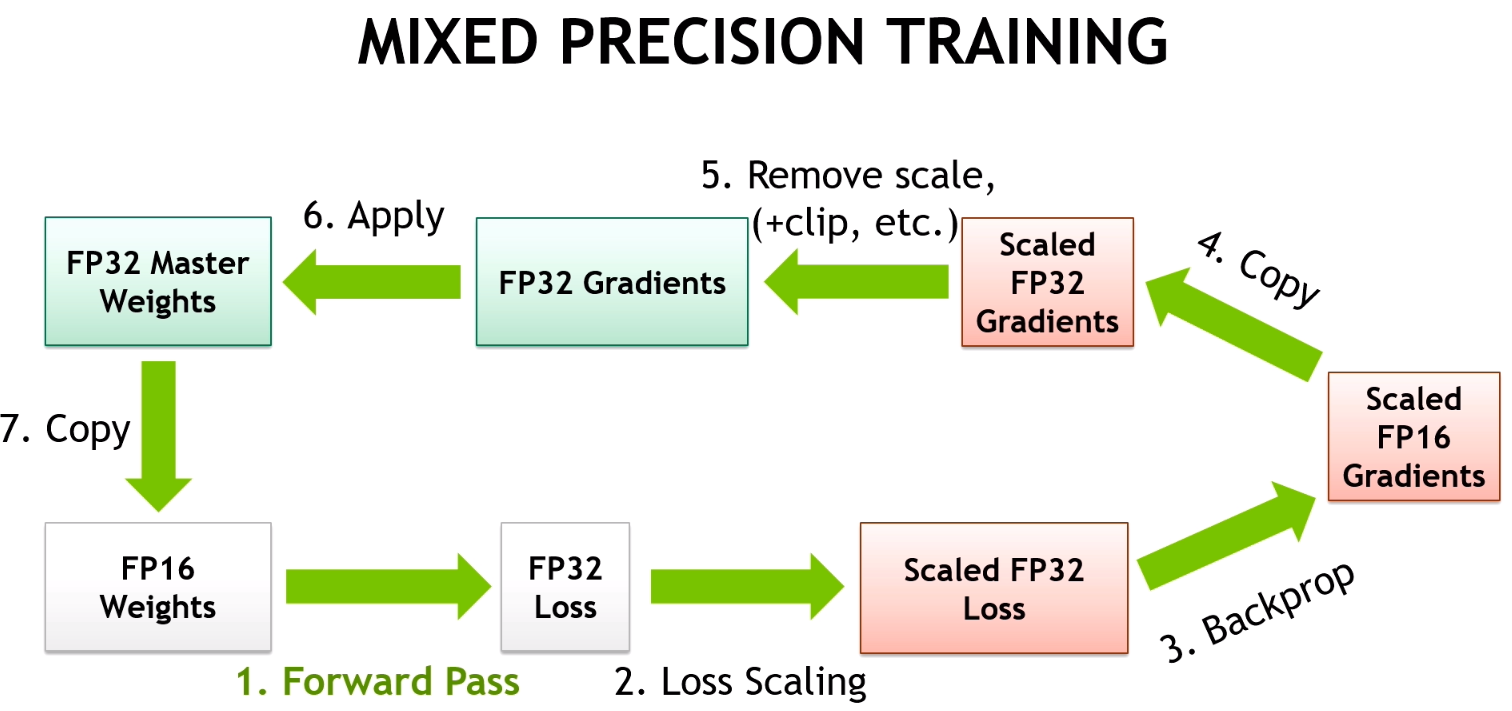
混合精度訓練的優勢:
• 加速訓練:16 位浮點運算更快
• 減少記憶體使用:模型參數佔用記憶體更少
• 維持精度:通過損失縮放等技術保持數值穩定性
其他技術的比較:
• 早期停止:防止過擬合,但不加速訓練
• 批次分群:提高訓練穩定性,但不直接加速
• 主成分分析:降維技術,用於特徵處理而非訓練加速
混合精度訓練通過使用 16 位浮點數(半精度)來加速訓練並減少記憶體使用。
混合精度訓練的優勢:
• 加速訓練:16 位浮點運算更快
• 減少記憶體使用:模型參數佔用記憶體更少
• 維持精度:通過損失縮放等技術保持數值穩定性
其他技術的比較:
• 早期停止:防止過擬合,但不加速訓練
• 批次分群:提高訓練穩定性,但不直接加速
• 主成分分析:降維技術,用於特徵處理而非訓練加速
#15
★★★★
考慮使用 CIFAR-10 資料集進行資料處理,資料包括 32×32 像素的多筆彩色照片。下列程式碼的資料處理,請選出正確的選項。
[1]: from tensorflow.keras import
datasets, utils
import pandas as pd
[2]: (x_train, y_train), (x_test, y_test) = datasets.cifar10.load_data()
[3]: type(x_train)
[3]: numpy.ndarray
[4]: print(x_train.shape,
y_train.shape, x_test.shape, y_test.shape)
(50000, 32, 32, 3) (50000, 1) (10000, 32, 32, 3) (10000, 1)
[5]: print(x_train.min())
0
[6]: print(x_train.max())
255
💡 答案解析
正確答案:B
CIFAR-10 資料集的標準配置為 50,000 筆訓練資料和 10,000 筆測試資料。
CIFAR-10 資料集規格:
• 訓練集:50,000 張 32×32×3 的彩色圖片
• 測試集:10,000 張 32×32×3 的彩色圖片
• 類別數:10 個類別(飛機、汽車、鳥等)
• 像素值:0-255 的整數
其他選項的錯誤:
• 訓練集 100,000 筆:實際為 50,000 筆
• Pandas DataFrame:實際為 NumPy 陣列
• astype('int32'):像素值已經是整數,無需轉換
CIFAR-10 資料集的標準配置為 50,000 筆訓練資料和 10,000 筆測試資料。
CIFAR-10 資料集規格:
• 訓練集:50,000 張 32×32×3 的彩色圖片
• 測試集:10,000 張 32×32×3 的彩色圖片
• 類別數:10 個類別(飛機、汽車、鳥等)
• 像素值:0-255 的整數
其他選項的錯誤:
• 訓練集 100,000 筆:實際為 50,000 筆
• Pandas DataFrame:實際為 NumPy 陣列
• astype('int32'):像素值已經是整數,無需轉換
🔬 科目三: 機器學習技術與應用
#1
★★★★
在 MapReduce 計算框架中,關於 Map 和 Reduce 所負責處理資料的問題,下列敘述何者正確?
💡 答案解析
正確答案:A
MapReduce 框架的核心思想是「分而治之」,Map 階段負責資料映射轉換,Reduce 階段負責結果統合。
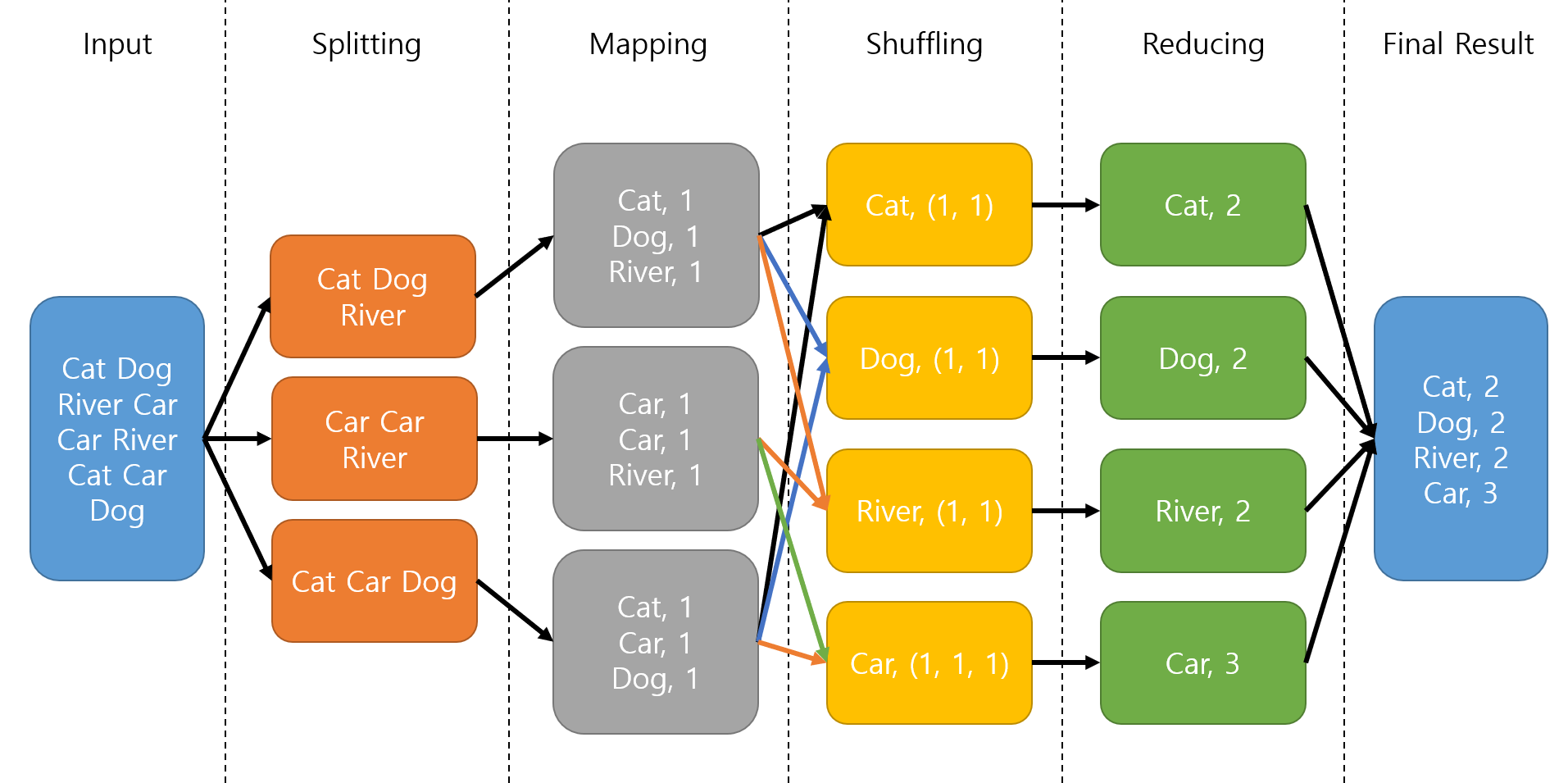
MapReduce 的工作流程:
• Map 階段:將輸入資料分割並映射為鍵值對
• Shuffle 階段:將相同鍵的資料聚合
• Reduce 階段:對聚合後的資料進行歸納處理
MapReduce 的特點:
• 可擴展性:能夠處理大規模資料
• 容錯性:自動處理節點故障
• 易用性:提供簡單的程式設計模型
MapReduce 框架的核心思想是「分而治之」,Map 階段負責資料映射轉換,Reduce 階段負責結果統合。
MapReduce 的工作流程:
• Map 階段:將輸入資料分割並映射為鍵值對
• Shuffle 階段:將相同鍵的資料聚合
• Reduce 階段:對聚合後的資料進行歸納處理
MapReduce 的特點:
• 可擴展性:能夠處理大規模資料
• 容錯性:自動處理節點故障
• 易用性:提供簡單的程式設計模型
#2
★★★★
下列何種卷積神經網路(Convolution Neural Networks, CNN)是將卷積層加寬而非加深?
💡 答案解析
正確答案:B
Inception 系列(GoogleNet)採用多分支結構,在同一層使用不同大小的卷積核來增加網路的寬度。
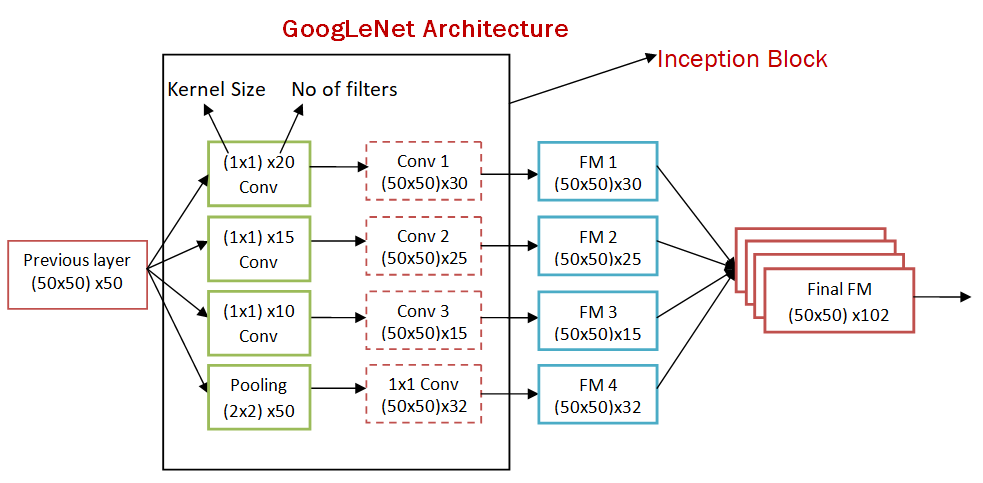
Inception 模組的特點:
• 多尺度處理:同時使用 1×1、3×3、5×5 卷積核
• 寬度優化:增加網路寬度而非深度
• 計算效率:使用 1×1 卷積進行降維
其他架構的比較:
• VGG:注重深度,層數較多
• ResNet:注重深度,引入殘差連接
• R-CNN:物件偵測系列,不是純粹的 CNN 架構
Inception 系列(GoogleNet)採用多分支結構,在同一層使用不同大小的卷積核來增加網路的寬度。
Inception 模組的特點:
• 多尺度處理:同時使用 1×1、3×3、5×5 卷積核
• 寬度優化:增加網路寬度而非深度
• 計算效率:使用 1×1 卷積進行降維
其他架構的比較:
• VGG:注重深度,層數較多
• ResNet:注重深度,引入殘差連接
• R-CNN:物件偵測系列,不是純粹的 CNN 架構
#3
★★★★
當模型的訓練誤差(Training Error)低、但測試誤差(Test Error)很大時,這通常是在訓練過程中產生下列哪一種情況?
💡 答案解析
正確答案:B
過度擬合是指模型在訓練資料上表現很好,但在未見過的測試資料上表現很差。
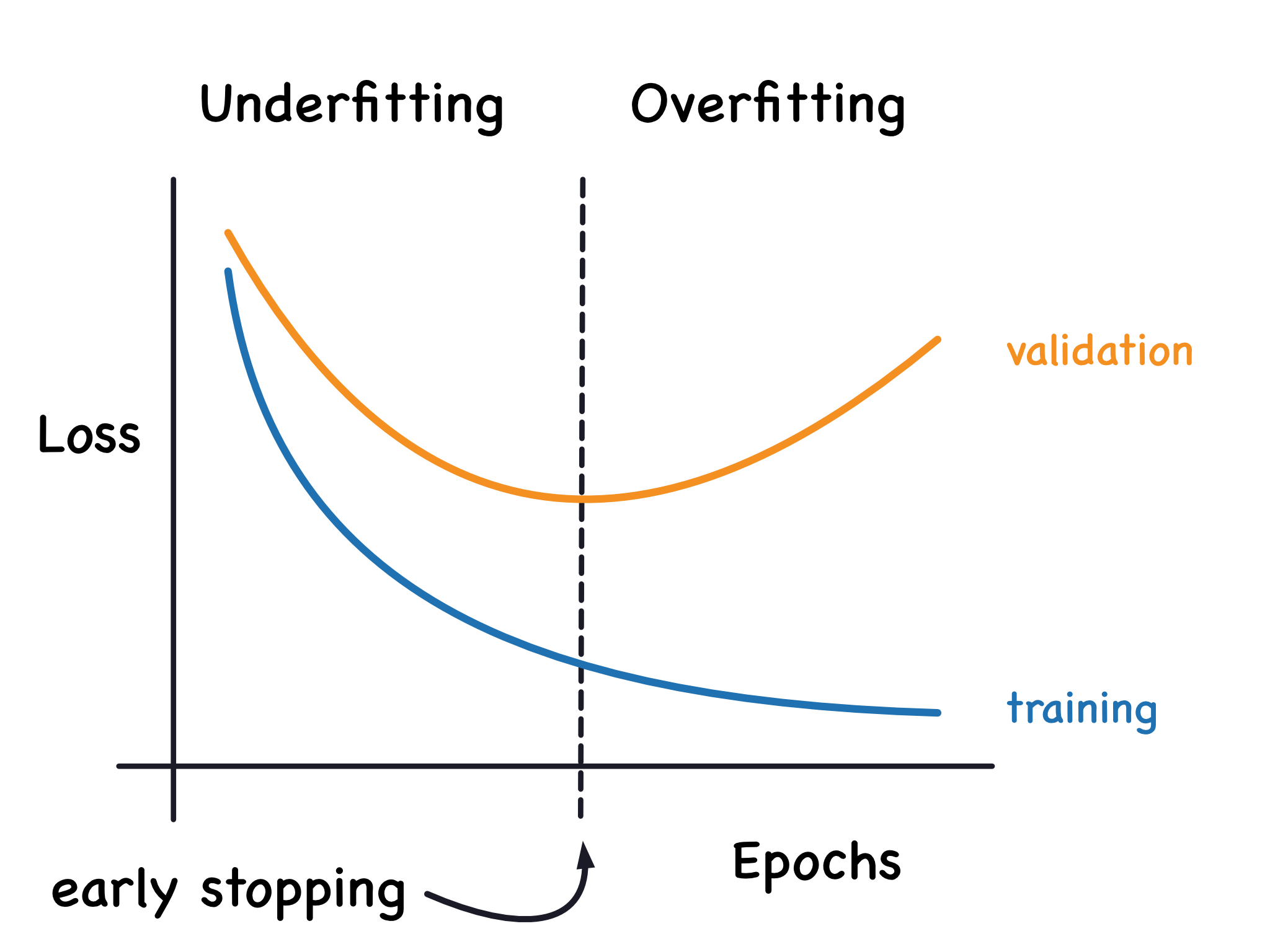
過度擬合的徵兆:
• 訓練誤差持續降低
• 測試誤差開始上升
• 模型複雜度過高
預防過度擬合的方法:
• 正則化:L1、L2 正則化
• Dropout:隨機丟棄神經元
• Early Stopping:監控驗證集誤差
• 資料增強:增加訓練資料多樣性
過度擬合是指模型在訓練資料上表現很好,但在未見過的測試資料上表現很差。
過度擬合的徵兆:
• 訓練誤差持續降低
• 測試誤差開始上升
• 模型複雜度過高
預防過度擬合的方法:
• 正則化:L1、L2 正則化
• Dropout:隨機丟棄神經元
• Early Stopping:監控驗證集誤差
• 資料增強:增加訓練資料多樣性
#4
★★★★
下列哪一種指標通常用於評估迴歸模型的效能?
💡 答案解析
正確答案:A
R²(決定係數)是評估迴歸模型最常用的指標,表示模型解釋變異性的比例。
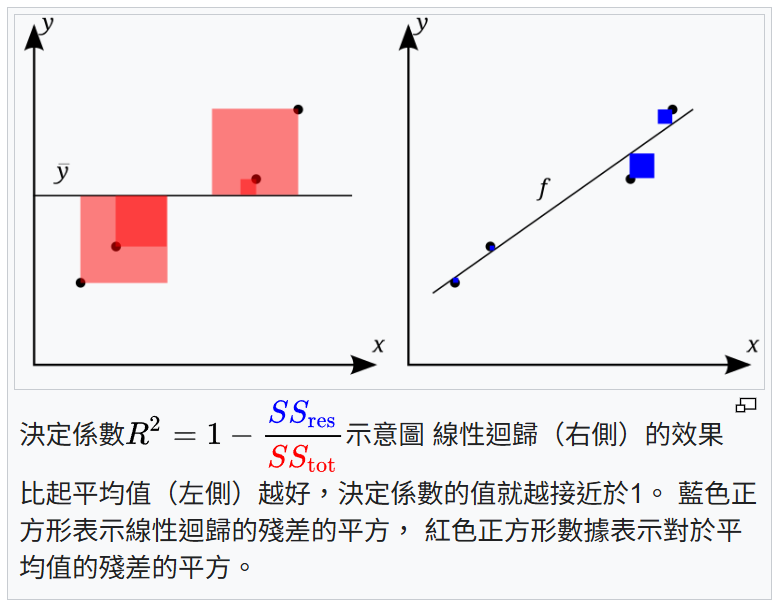
R² 的計算公式:
R² = 1 - (SS_res / SS_tot)
其中 SS_res 是殘差平方和,SS_tot 是總平方和
R² 的意義:
• R² = 1:模型完美擬合
• R² = 0:模型等同於使用平均值預測
• R² < 0:模型比平均值預測還差
其他指標的適用場景:
• F1-分數:分類模型的調和平均
• AUC:二元分類模型的性能
• Precision:分類模型的精確率
R²(決定係數)是評估迴歸模型最常用的指標,表示模型解釋變異性的比例。
R² 的計算公式:
R² = 1 - (SS_res / SS_tot)
其中 SS_res 是殘差平方和,SS_tot 是總平方和
R² 的意義:
• R² = 1:模型完美擬合
• R² = 0:模型等同於使用平均值預測
• R² < 0:模型比平均值預測還差
其他指標的適用場景:
• F1-分數:分類模型的調和平均
• AUC:二元分類模型的性能
• Precision:分類模型的精確率
#5
★★★★
近年來,深度學習研究與應用蓬勃發展,但數據本身可能存在什麼潛在問題?
💡 答案解析
正確答案:A
數據標註品質是深度學習中經常被忽視但極其重要的問題。
數據標註問題的影響:
• 標註錯誤:會誤導模型學習錯誤的模式
• 標註不一致:不同標註者對同一資料有不同標註
• 標註偏差:標註者主觀偏見影響標註結果
提高標註品質的方法:
• 多重標註:多個標註者對同一資料進行標註
• 標註指南:制定詳細的標註標準和指南
• 品質檢查:定期檢查和驗證標註品質
• 主動學習:選擇最有價值的資料進行標註
數據標註品質是深度學習中經常被忽視但極其重要的問題。
數據標註問題的影響:
• 標註錯誤:會誤導模型學習錯誤的模式
• 標註不一致:不同標註者對同一資料有不同標註
• 標註偏差:標註者主觀偏見影響標註結果
提高標註品質的方法:
• 多重標註:多個標註者對同一資料進行標註
• 標註指南:制定詳細的標註標準和指南
• 品質檢查:定期檢查和驗證標註品質
• 主動學習:選擇最有價值的資料進行標註
#6
★★★★
在分類任務中,深度學習模型通常搭配哪一種輸出函數?
💡 答案解析
正確答案:C
Sigmoid 和 Softmax 是深度學習中分類任務最常用的輸出層激活函數。
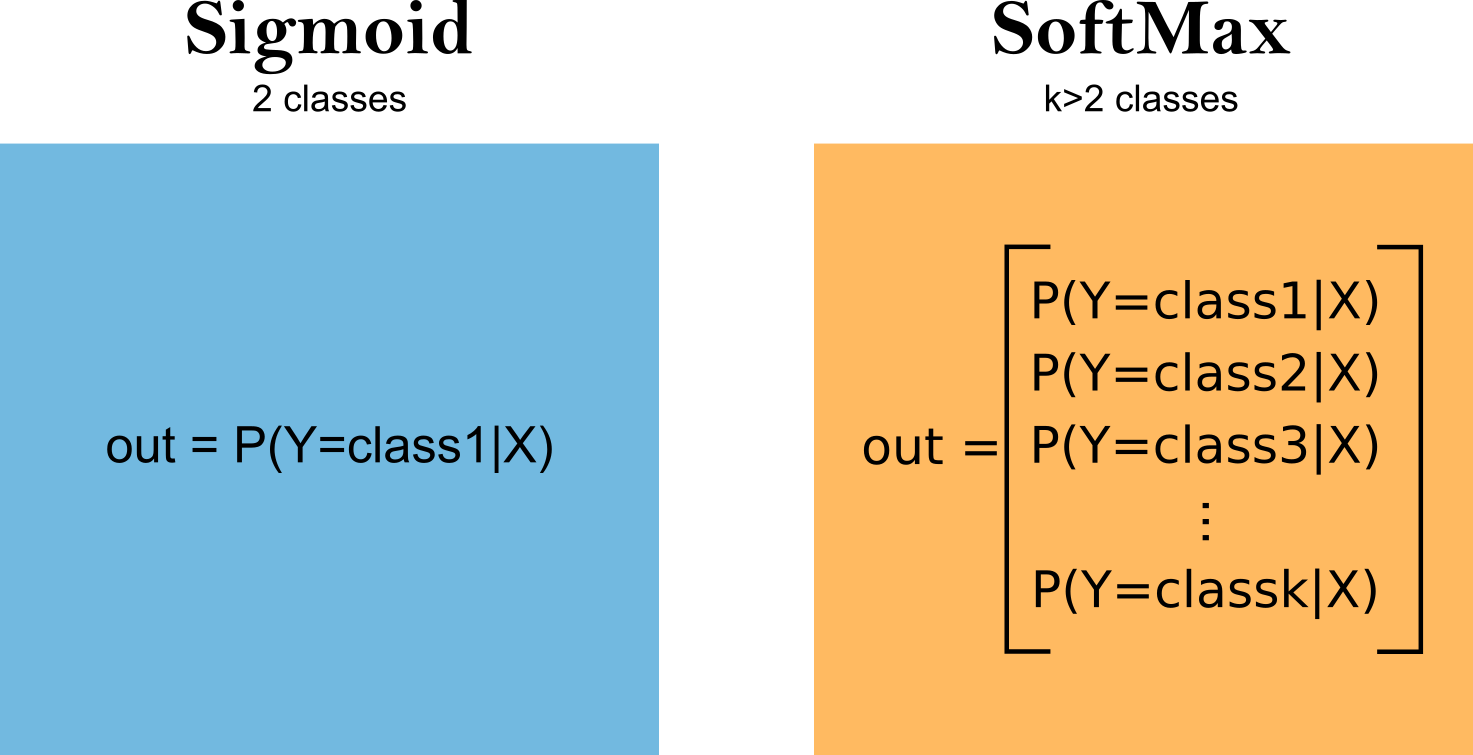
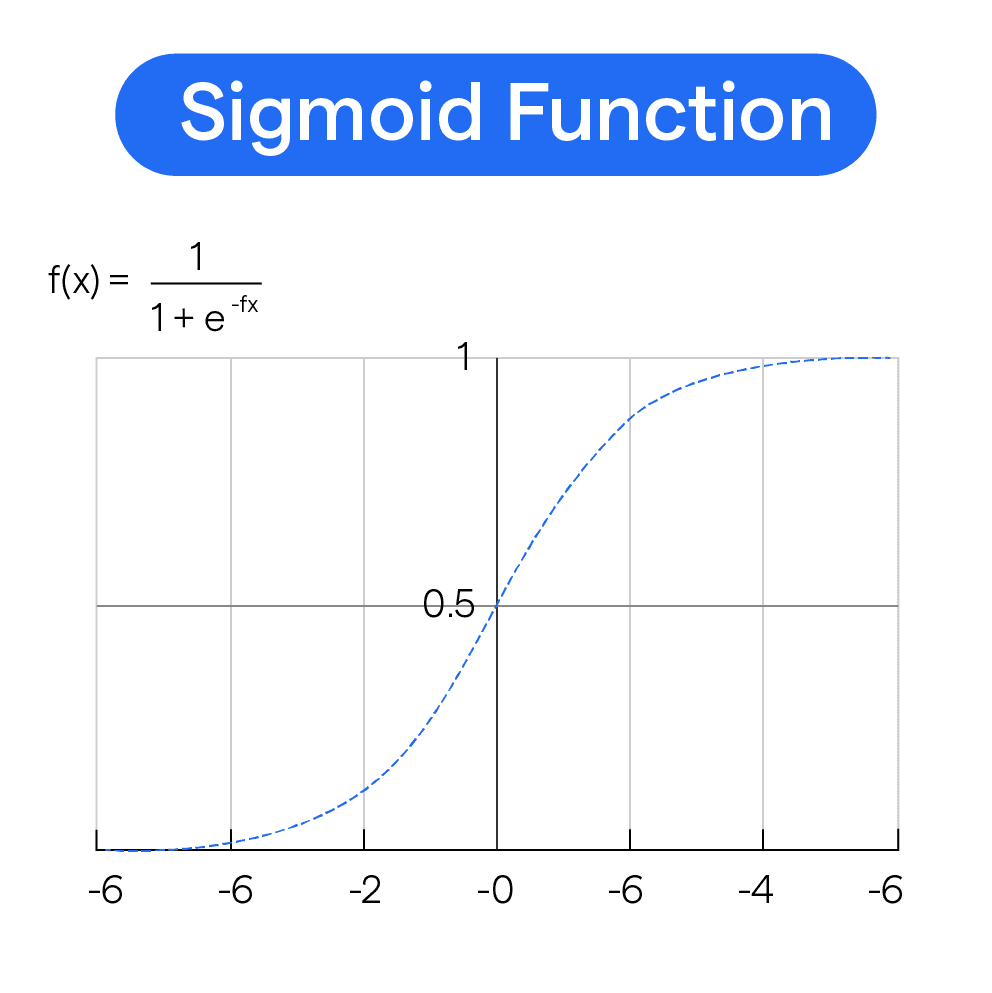
Sigmoid 函數:
• 二元分類:輸出值域為 (0, 1)
• 公式:σ(x) = 1 / (1 + e^(-x))
• 解釋:表示樣本屬於正類的概率
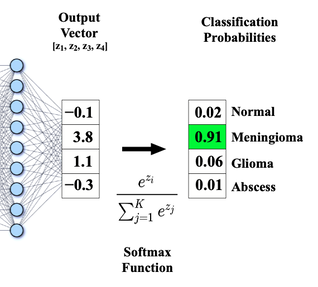
Softmax 函數:
• 多元分類:輸出各類別的概率分佈
• 公式:softmax(x_i) = e^(x_i) / Σ e^(x_j)
• 解釋:將輸出轉換為概率分佈,各類別概率和為 1
Sigmoid 和 Softmax 是深度學習中分類任務最常用的輸出層激活函數。
Sigmoid 函數:
• 二元分類:輸出值域為 (0, 1)
• 公式:σ(x) = 1 / (1 + e^(-x))
• 解釋:表示樣本屬於正類的概率
Softmax 函數:
• 多元分類:輸出各類別的概率分佈
• 公式:softmax(x_i) = e^(x_i) / Σ e^(x_j)
• 解釋:將輸出轉換為概率分佈,各類別概率和為 1
#7
★★★★
下列哪一種學習任務不適合使用監督式學習方法處理?
💡 答案解析
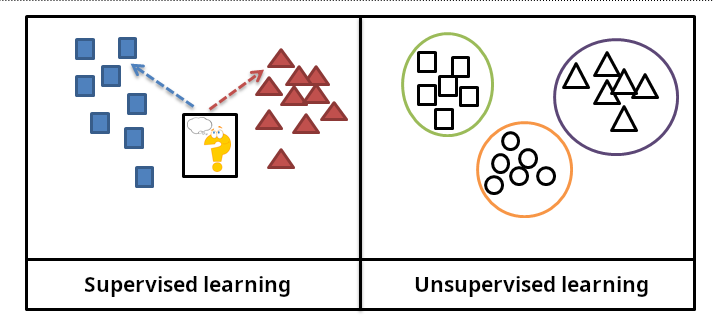
正確答案:C
找出資料中的潛在群集是典型的無監督學習任務,不需要預先標記的資料。
監督式學習 vs 無監督學習:
• 監督式學習:需要標記資料,學習輸入到輸出的映射
• 無監督學習:沒有標記資料,發現資料中的模式和結構
各任務的學習類型:
• 客戶信用風險分類:監督式學習(分類)
• 預測未來銷售額:監督式學習(迴歸)
• 找出潛在群集:無監督學習(聚類)
• 判斷影像類別:監督式學習(分類)
找出資料中的潛在群集是典型的無監督學習任務,不需要預先標記的資料。
監督式學習 vs 無監督學習:
• 監督式學習:需要標記資料,學習輸入到輸出的映射
• 無監督學習:沒有標記資料,發現資料中的模式和結構
各任務的學習類型:
• 客戶信用風險分類:監督式學習(分類)
• 預測未來銷售額:監督式學習(迴歸)
• 找出潛在群集:無監督學習(聚類)
• 判斷影像類別:監督式學習(分類)
#8
★★★★
在神經網路中,前向傳播(Forward Propagation)主要依賴下列哪一種數學操作?
💡 答案解析
正確答案:B
前向傳播是神經網路計算預測結果的過程,主要涉及線性變換和激活函數。
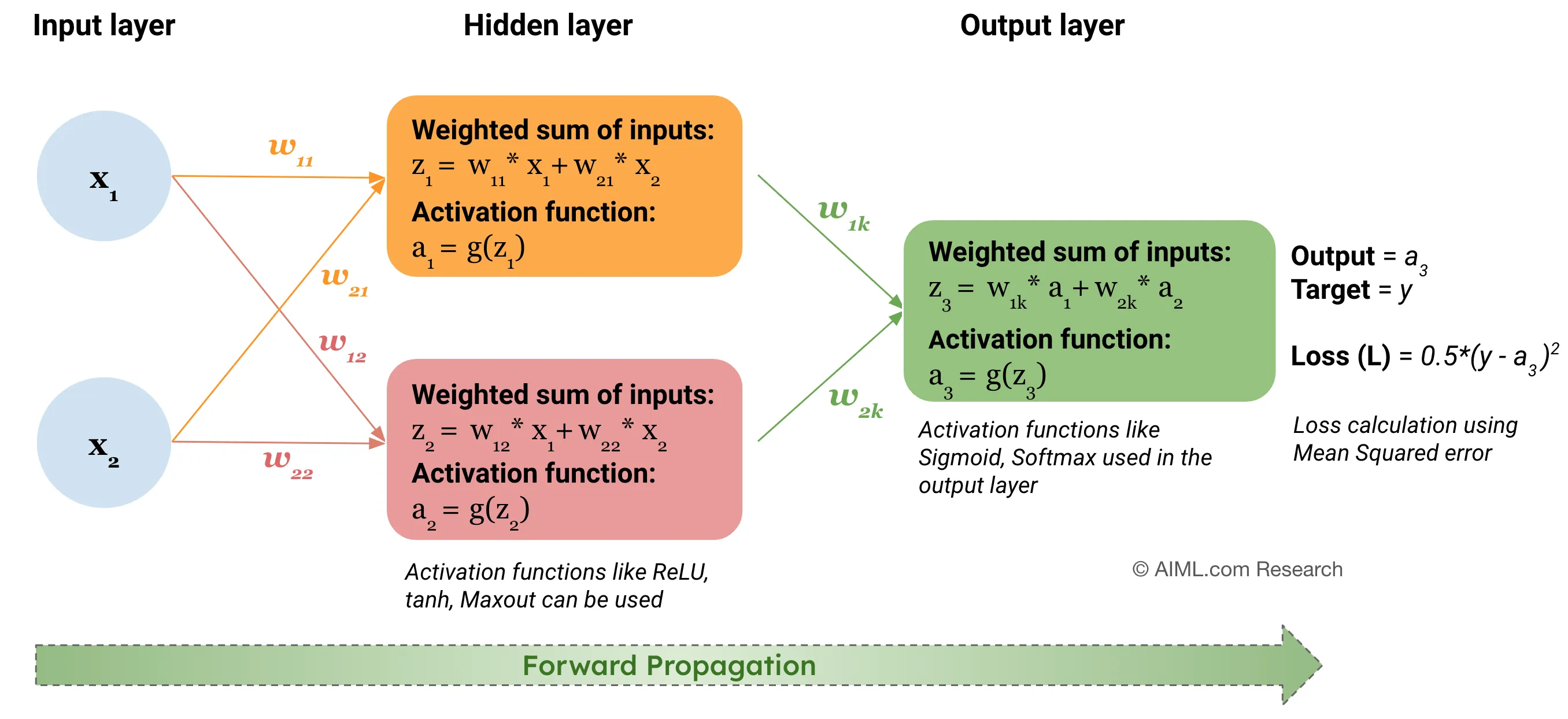 前向傳播的數學運算:
前向傳播的數學運算:
• 線性變換:z = Wx + b(矩陣乘法和向量加法)
• 激活函數:a = f(z)(非線性變換)
• 層間傳播:將上一層的輸出作為下一層的輸入
前向傳播的意義:
• 預測階段:使用訓練好的模型進行預測
• 損失計算:計算預測值與真實值的差異
• 梯度計算:為反向傳播準備梯度信息
前向傳播是神經網路計算預測結果的過程,主要涉及線性變換和激活函數。
前向傳播的數學運算:• 線性變換:z = Wx + b(矩陣乘法和向量加法)
• 激活函數:a = f(z)(非線性變換)
• 層間傳播:將上一層的輸出作為下一層的輸入
前向傳播的意義:
• 預測階段:使用訓練好的模型進行預測
• 損失計算:計算預測值與真實值的差異
• 梯度計算:為反向傳播準備梯度信息
#9
★★★★
特徵縮放(Feature Scaling)中,下列何者為標準化(Standardization)的主要作用?
💡 答案解析
正確答案:B
標準化(Z-score 標準化)將資料轉換為平均值 0、標準差 1 的標準常態分佈。
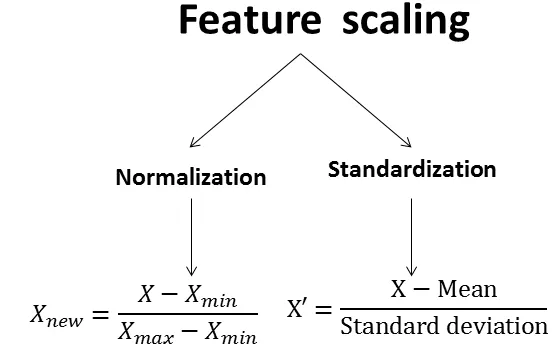
標準化的公式:
z = (x - μ) / σ
其中 μ 是平均值,σ 是標準差
標準化的優點:
• 消除尺度差異:不同特徵在相同尺度上
• 加速收斂:梯度下降更快收斂
• 處理異常值:相對於 Min-Max 更能處理極端值
與 Min-Max 正規化的區別:
• 標準化:基於平均值和標準差
• Min-Max:基於最小值和最大值
標準化(Z-score 標準化)將資料轉換為平均值 0、標準差 1 的標準常態分佈。
標準化的公式:
z = (x - μ) / σ
其中 μ 是平均值,σ 是標準差
標準化的優點:
• 消除尺度差異:不同特徵在相同尺度上
• 加速收斂:梯度下降更快收斂
• 處理異常值:相對於 Min-Max 更能處理極端值
與 Min-Max 正規化的區別:
• 標準化:基於平均值和標準差
• Min-Max:基於最小值和最大值
#10
★★★★
關於準確率(Accuracy)的計算方式,下列何者正確?
💡 答案解析
正確答案:B
準確率(Accuracy)是分類模型最直觀的評估指標,表示正確預測的樣本佔總樣本的比例。
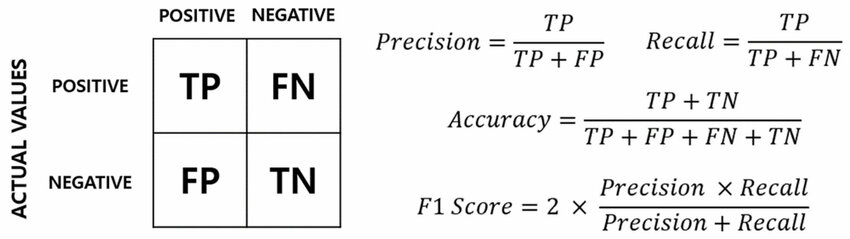
混淆矩陣的符號說明:
• TP(True Positive):真正例,正確預測為正類
• TN(True Negative):真負例,正確預測為負類
• FP(False Positive):假正例,錯誤預測為正類
• FN(False Negative):假負例,錯誤預測為負類
準確率的計算:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
準確率的局限性:
• 類別不平衡:在不平衡資料集上可能誤導
• 成本敏感:不同錯誤類型的成本可能不同
準確率(Accuracy)是分類模型最直觀的評估指標,表示正確預測的樣本佔總樣本的比例。
混淆矩陣的符號說明:
• TP(True Positive):真正例,正確預測為正類
• TN(True Negative):真負例,正確預測為負類
• FP(False Positive):假正例,錯誤預測為正類
• FN(False Negative):假負例,錯誤預測為負類
準確率的計算:
Accuracy = (TP + TN) / (TP + TN + FP + FN)
準確率的局限性:
• 類別不平衡:在不平衡資料集上可能誤導
• 成本敏感:不同錯誤類型的成本可能不同
#11
★★★★
關於損失函數(Loss Function)的主要功能,下列何者正確?
💡 答案解析
正確答案:D
損失函數是機器學習優化過程的核心,用於量化模型預測與真實值之間的差異。
損失函數的主要功能:
• 誤差量化:計算預測值與真實值的差異程度
• 優化目標:為優化算法提供優化方向
• 模型評估:評估模型在訓練過程中的性能
常見的損失函數:
• 均方誤差 (MSE):迴歸任務
• 交叉熵 (Cross-Entropy):分類任務
• 鉸鏈損失 (Hinge Loss):支持向量機
• 絕對值誤差 (MAE):迴歸任務,對異常值不敏感
損失函數是機器學習優化過程的核心,用於量化模型預測與真實值之間的差異。
損失函數的主要功能:
• 誤差量化:計算預測值與真實值的差異程度
• 優化目標:為優化算法提供優化方向
• 模型評估:評估模型在訓練過程中的性能
常見的損失函數:
• 均方誤差 (MSE):迴歸任務
• 交叉熵 (Cross-Entropy):分類任務
• 鉸鏈損失 (Hinge Loss):支持向量機
• 絕對值誤差 (MAE):迴歸任務,對異常值不敏感
#12
★★★★
關於歐盟《一般資料保護規則(GDPR)》,所謂的被遺忘權(Right to be Forgotten)主要賦予資料主體哪一項權利?
💡 答案解析
正確答案:B
被遺忘權允許資料主體要求企業刪除其個人資料,特別是在資料處理缺乏合法依據時。
 被遺忘權的適用條件:
被遺忘權的適用條件:
• 資料處理目的已達成
• 資料主體撤回同意
• 資料處理違法
• 資料處理基於兒童同意
被遺忘權的例外:
• 言論自由:新聞報導和學術表達
• 法律義務:企業需遵守的法律要求
• 公共利益:公共衛生、科學研究等
• 法律主張:司法程序中的證據
被遺忘權允許資料主體要求企業刪除其個人資料,特別是在資料處理缺乏合法依據時。
被遺忘權的適用條件:• 資料處理目的已達成
• 資料主體撤回同意
• 資料處理違法
• 資料處理基於兒童同意
被遺忘權的例外:
• 言論自由:新聞報導和學術表達
• 法律義務:企業需遵守的法律要求
• 公共利益:公共衛生、科學研究等
• 法律主張:司法程序中的證據
#13
★★★★
在進行模型訓練前,若針對資料中不同群體(例如分類標籤)之間樣本數量不平衡的情況進行比例調整,此方法通常屬於下列哪一種技術?
💡 答案解析
正確答案:A
資料重抽樣是處理類別不平衡問題最直接的方法,通過調整不同類別的樣本數量來平衡資料分佈。
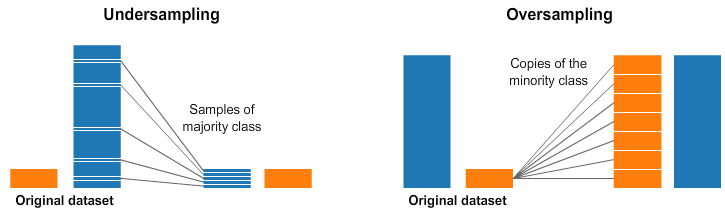
資料重抽樣的方法:
• 過抽樣 (Oversampling):增加少數類別的樣本數量
• 欠抽樣 (Undersampling):減少多數類別的樣本數量
• 合成抽樣 (SMOTE):生成新的少數類別樣本
類別不平衡的影響:
• 偏向多數類別:模型傾向於預測多數類別
• 少數類別識別差:對少數類別的識別能力較弱
• 評估指標誤導:準確率等指標可能無法真實反映模型性能
資料重抽樣是處理類別不平衡問題最直接的方法,通過調整不同類別的樣本數量來平衡資料分佈。
資料重抽樣的方法:
• 過抽樣 (Oversampling):增加少數類別的樣本數量
• 欠抽樣 (Undersampling):減少多數類別的樣本數量
• 合成抽樣 (SMOTE):生成新的少數類別樣本
類別不平衡的影響:
• 偏向多數類別:模型傾向於預測多數類別
• 少數類別識別差:對少數類別的識別能力較弱
• 評估指標誤導:準確率等指標可能無法真實反映模型性能
#14
★★★★
在優化器中,哪一個方法會自動調整每個參數的學習率,特別適用於稀疏資料?
💡 答案解析
正確答案:B
Adagrad 為每個參數自適應地調整學習率,對於稀疏特徵特別有效。
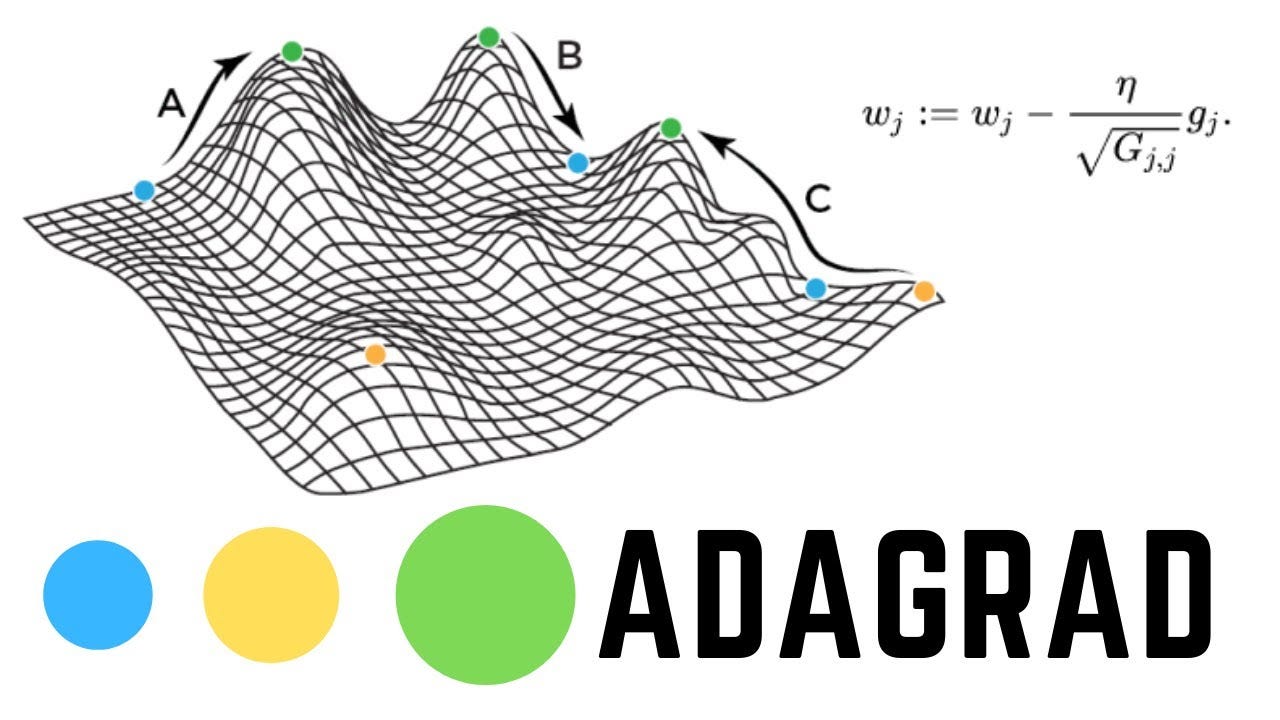
Adagrad 的特點:
• 自適應學習率:根據參數的歷史梯度調整學習率
• 稀疏資料友好:頻繁出現的特徵學習率較小,稀疏特徵學習率較大
• 無需手動調參:自動調整學習率衰減
Adagrad 的公式:
θ_{t+1} = θ_t - (η / √(G_t + ε)) * g_t
其中 G_t 是歷史梯度平方的累積和
Adagrad 的局限性:
• 學習率衰減過快:後期學習率可能變得過小
• 記憶體需求:需要存儲所有歷史梯度
Adagrad 為每個參數自適應地調整學習率,對於稀疏特徵特別有效。
Adagrad 的特點:
• 自適應學習率:根據參數的歷史梯度調整學習率
• 稀疏資料友好:頻繁出現的特徵學習率較小,稀疏特徵學習率較大
• 無需手動調參:自動調整學習率衰減
Adagrad 的公式:
θ_{t+1} = θ_t - (η / √(G_t + ε)) * g_t
其中 G_t 是歷史梯度平方的累積和
Adagrad 的局限性:
• 學習率衰減過快:後期學習率可能變得過小
• 記憶體需求:需要存儲所有歷史梯度
#15
★★★★
某零售公司希望利用顧客的年齡與每月消費金額,預測顧客是否為高價值顧客。提供相關資料 data.csv,包含欄位
Age、Spending、HighValue。請將下列程式碼片段依正確順序排序,以完成模型的建立與預測。
# a.
from sklearn.model_selection import
train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# b.
from sklearn.linear_model import
LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
# c.
import pandas as pd
data = pd.read_csv("data.csv")
X = data[['Age', 'Spending']]
y = data['HighValue']
# d.
y_pred = model.predict(X_test)
print("Predictions:", y_pred[:5])
💡 答案解析
正確答案:A (c → a → b → d)
機器學習專案的標準工作流程必須遵循邏輯順序,確保每個步驟都有前置條件滿足。
程式碼片段:
正確執行順序分析:
為什麼其他選項不正確:
• 選項A (c→a→b→d):正確順序
• 選項B (a→c→b→d):在載入資料前就分割資料,X和y未定義
• 選項D (b→a→c→d):在載入資料前就訓練模型,缺少必要資料
邏輯迴歸在此問題的適用性:
• 二元分類:預測顧客是否為高價值顧客(是/否)
• 線性可分:年齡和消費金額與高價值顧客可能存在線性關係
• 機率輸出:提供顧客為高價值的機率,便於業務決策
程式碼執行流程:
1. 資料載入:讀取CSV檔案,提取特徵和標籤
2. 資料分割:80%訓練,20%測試,確保評估公正性
3. 模型訓練:使用訓練集學習年齡和消費與高價值的關係
4. 預測評估:在測試集上預測,評估模型實際效能
機器學習專案的標準工作流程必須遵循邏輯順序,確保每個步驟都有前置條件滿足。
程式碼片段:
# c.
import pandas as pd
data = pd.read_csv("data.csv")
X = data[['Age', 'Spending']]
y = data['HighValue']
# a.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=42)
# b.
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
# d.
y_pred = model.predict(X_test)
print("Predictions:", y_pred[:5])
正確執行順序分析:
| 順序 | 步驟 | 程式碼片段 | 目的 |
|---|---|---|---|
| 1. c | 資料載入與準備 | 載入CSV檔案,定義特徵X和目標y | 準備訓練所需的資料 |
| 2. a | 資料分割 | 將資料分為訓練集和測試集 | 避免過擬合,評估模型泛化能力 |
| 3. b | 模型訓練 | 建立並訓練邏輯迴歸模型 | 學習資料中的模式 |
| 4. d | 模型預測 | 使用訓練好的模型進行預測 | 驗證模型效能 |
為什麼其他選項不正確:
• 選項A (c→a→b→d):正確順序
• 選項B (a→c→b→d):在載入資料前就分割資料,X和y未定義
• 選項D (b→a→c→d):在載入資料前就訓練模型,缺少必要資料
邏輯迴歸在此問題的適用性:
• 二元分類:預測顧客是否為高價值顧客(是/否)
• 線性可分:年齡和消費金額與高價值顧客可能存在線性關係
• 機率輸出:提供顧客為高價值的機率,便於業務決策
程式碼執行流程:
1. 資料載入:讀取CSV檔案,提取特徵和標籤
2. 資料分割:80%訓練,20%測試,確保評估公正性
3. 模型訓練:使用訓練集學習年齡和消費與高價值的關係
4. 預測評估:在測試集上預測,評估模型實際效能