iPAS AI應用規劃師 考試重點
L23402 演算法偏見與公平性
主題分類
1
偏見與公平性基本概念
2
演算法偏見的來源
3
常見偏見類型
4
公平性衡量指標
5
偏見緩解技術
6
公平性相關工具與框架
7
倫理考量與負責任AI
8
實際案例與影響
#1
★★★★★
演算法偏見 (Algorithmic Bias) - 基本定義
核心概念
演算法偏見 指的是 AI 或機器學習系統產生系統性且可重複的錯誤,對特定群體產生不公平的結果或影響。這種偏見可能源於數據、演算法設計或人類互動等多方面因素,並非演算法本身有主觀意圖,而是反映了其學習過程中的模式。
#2
★★★★★
人工智慧公平性 (AI Fairness) - 基本定義
核心概念
人工智慧公平性 關注 AI 系統的輸出或決策不應基於個人的敏感屬性(如種族、性別、年齡、宗教等)而產生歧視或不平等待遇。目標是確保 AI 系統的應用對所有相關群體都是公正和公平的,但「公平」的具體定義會因應用場景和倫理觀點而異。
#3
★★★★
偏見 與 不公平 的關係
核心概念
演算法偏見 是 導致 不公平 結果的 原因之一,但兩者不完全等同。一個有偏見的系統可能產生不公平的結果,但「公平」的定義本身具有多樣性和主觀性。消除所有偏見不一定能保證所有人都認同的公平,需要在特定情境下權衡。
#4
★★★
公平性 的多樣定義
核心概念
「公平」沒有單一、普遍接受的定義。不同的公平性概念可能相互衝突。例如:
- 群體公平 (Group Fairness): 要求不同群體在統計上受到相似的對待。
- 個體公平 (Individual Fairness): 要求相似的個體受到相似的對待。
#5
★★★★★
數據偏見 (Data Bias) - 主要來源
核心概念
數據是演算法偏見最常見的來源。如果訓練數據不能準確代表現實世界或目標應用環境,或者反映了歷史上或社會上的不平等,模型就會學習並放大這些偏見。樣題 Q15 強調了數據品質對模型性能的直接影響。
#6
★★★★
演算法偏見 (Algorithmic Bias) - 設計來源
核心概念
模型本身的設計或選擇也可能引入偏見。例如:
- 選擇的模型類型可能對某些模式更敏感。
- 特徵工程 (Feature Engineering) 的方式可能無意中強化或引入了與敏感屬性的關聯。
- 最佳化目標 (Optimization Objective) 主要關注整體準確率,可能犧牲了少數群體的表現。
#7
★★★★
人類偏見 (Human Bias) - 互動來源
核心概念
開發者、標註者和使用者的主觀判斷和無意識偏見也可能滲透到 AI 系統中。例如:
- 數據標註 (Data Labeling) 過程中的主觀性或偏見。
- 使用者與 AI 系統互動的方式可能形成回饋循環 (Feedback Loop),強化現有偏見。
- 開發團隊的同質性可能導致視野局限,未能考慮到不同群體的需求和潛在影響。
#8
★★★★
歷史偏見 (Historical Bias)
核心概念
數據反映了過去社會中存在的真實偏見或歧視,即使數據收集過程本身是準確的。模型學習這些歷史模式可能導致在當前社會中延續或放大這些不公平。例如,歷史上的招聘數據可能反映了性別或種族歧視。
#9
★★★★
代表性偏見 (Representation Bias)
核心概念
數據收集過程中,某些群體被過度代表或代表不足。這導致模型在代表不足的群體上表現較差,因為模型沒有足夠的數據來學習這些群體的特徵。例如,人臉辨識數據集中淺膚色人臉過多。
#10
★★★
測量偏見 (Measurement Bias)
核心概念
數據收集或測量的方式在不同群體間存在系統性差異。使用的特徵、工具或測量標準可能對某些群體更準確或更相關。例如,使用特定文化背景下的詞彙來評估語言能力,可能對其他文化背景的人不公平。
#11
★★★
評估偏見 (Evaluation Bias)
核心概念
在評估模型性能時使用的基準數據或指標本身存在偏見。如果評估數據集不能代表所有群體,或者評估指標(如總體準確率)掩蓋了不同群體間的性能差異,就可能產生評估偏見。
#12
★★★
聚合偏見 (Aggregation Bias)
核心概念
當模型對所有群體使用單一模型或假設時,可能產生聚合偏見。這種「一刀切」的方法忽略了不同群體之間可能存在的差異,導致模型對某些群體的效果不佳。
#13
★★★★★
群體公平性指標 (Group Fairness Metrics) - 概觀
核心概念
群體公平性指標 旨在衡量模型對不同受保護群體(Protected Groups)的表現是否存在統計上的差異。常見的群體公平性指標包括:
- 人口統計均等 (Demographic Parity / Statistical Parity)
- 機會均等 (Equal Opportunity)
- 均等化賠率 (Equalized Odds)
#14
★★★★
人口統計均等 (Demographic Parity)
定義與目標
要求模型對不同群體的預測結果(通常是正面預測)的比率應該相等。例如,在貸款審批中,不同種族獲得貸款批准的比例應該相似。
目標是確保決策結果的分配不受敏感屬性影響,但不考慮個體是否真正符合條件。
目標是確保決策結果的分配不受敏感屬性影響,但不考慮個體是否真正符合條件。
#15
★★★★
機會均等 (Equal Opportunity)
定義與目標
要求對於實際上屬於「正面類別」的個體,模型對不同群體預測為正面的比率(即 真陽性率, TPR)應該相等。例如,在招聘中,對於所有真正合格的應聘者,不同性別被成功識別(錄用)的比例應該相似。
目標是確保有資格的個體有平等的機會獲得正面結果。
目標是確保有資格的個體有平等的機會獲得正面結果。
#16
★★★★
均等化賠率 (Equalized Odds)
定義與目標
比 機會均等 更嚴格,要求模型對不同群體的 真陽性率(TPR) 和 假陽性率(FPR) 都應該相等。
換句話說,對於實際上屬於「正面類別」的個體,獲得正面預測的機會相等;對於實際上屬於「負面類別」的個體,錯誤地獲得正面預測的機會也相等。
目標是確保模型在正面和負面情況下對不同群體都具有相似的準確性。
換句話說,對於實際上屬於「正面類別」的個體,獲得正面預測的機會相等;對於實際上屬於「負面類別」的個體,錯誤地獲得正面預測的機會也相等。
目標是確保模型在正面和負面情況下對不同群體都具有相似的準確性。
#17
★★★
個體公平性 (Individual Fairness)
核心概念
要求「相似」的個體應該受到「相似」的對待。這需要定義一個衡量個體之間相似性的指標,以及一個衡量模型輸出之間相似性的指標。實現個體公平性通常比群體公平性更具挑戰性,因為需要定義何謂「相似」。
#18
★★★
公平性指標的衝突
核心概念
研究表明,除非在非常特殊的情況下(例如模型完美或各群體基礎比率相同),多個群體公平性指標(如人口統計均等、機會均等、均等化賠率)通常無法同時完全滿足。因此,在實踐中,需要在不同的公平性目標之間進行權衡取捨 (Trade-off)。
#19
★★★★★
偏見緩解技術 - 分類
核心概念
偏見緩解技術 (Bias Mitigation Techniques) 旨在減少 AI 模型中的偏見和不公平性。根據介入機器學習流程 (ML Pipeline) 的階段,主要可分為三類:
- 前處理 (Pre-processing): 在模型訓練之前修改訓練數據。
- 處理中 (In-processing): 在模型訓練期間修改學習演算法或最佳化目標。
- 後處理 (Post-processing): 在模型訓練之後修改模型的預測結果。
#20
★★★★
前處理技術 (Pre-processing Techniques)
方法與目標
目標是修正訓練數據中的偏見。常見方法包括:
- 重抽樣 (Resampling): 調整不同群體的樣本數量,如對少數群體過採樣 (Oversampling) 或對多數群體欠採樣 (Undersampling)。
- 重加權 (Reweighing): 為不同群體或樣本分配不同的權重,以平衡其在模型訓練中的影響。
- 抑制 (Suppression): 移除或修改數據中可能導致偏見的特徵(需謹慎使用)。
- 數據增強 (Data Augmentation): 為代表不足的群體生成合成數據。
#21
★★★★
處理中技術 (In-processing Techniques)
方法與目標
目標是在模型訓練過程中直接納入公平性考量。常見方法包括:
- 公平性約束 (Fairness Constraints): 將公平性指標作為約束條件加入到模型的最佳化目標函數中。
- 對抗性除偏 (Adversarial Debiasing): 訓練一個對抗網路,試圖從模型的預測中推斷出敏感屬性,迫使主模型學習與敏感屬性無關的表示。
- 正則化 (Regularization): 在損失函數中加入懲罰項,以懲罰模型對不同群體產生的不公平預測。
#22
★★★★
後處理技術 (Post-processing Techniques)
方法與目標
目標是在不改變原始模型的情況下,調整模型的輸出預測以滿足公平性要求。常見方法包括:
- 閾值調整 (Threshold Adjusting): 為不同群體設定不同的分類閾值,以平衡不同公平性指標(如 TPR, FPR)。
- 校準 (Calibration): 調整模型的預測機率,使其更好地反映真實的可能性,並可能改善公平性。
- 拒絕選項分類 (Reject Option Classification): 對於模型預測不確定性高或可能導致不公平的案例,選擇不做出預測。
#23
★★★
緩解技術的選擇考量
核心考量
選擇哪種緩解技術取決於多種因素:
- 介入階段:是否能接觸並修改訓練數據或模型訓練過程?
- 公平性目標:希望達成的具體公平性指標是什麼?
- 準確性影響:緩解偏見可能對模型的整體或特定群體的準確性產生何種影響(公平性-準確性權衡, Fairness-Accuracy Trade-off)?
- 計算成本:不同技術的實施複雜度和計算資源需求。
- 可解釋性:緩解後的模型是否仍然易於理解和解釋?
#24
★★★★
IBM AI Fairness 360 (AIF360)
工具介紹
一個由 IBM 開發的開源 Python 工具包。
- 提供全面的公平性指標集合,用於檢測數據集和機器學習模型中的偏見。
- 包含多種先進的偏見緩解演算法(涵蓋前處理、處理中、後處理)。
- 旨在幫助開發者和研究人員理解、衡量和減輕 AI 系統中的不公平性。
#25
★★★★
Microsoft Fairlearn
工具介紹
一個由 Microsoft 開發的開源 Python 工具包,旨在幫助數據科學家和開發者評估和改善 AI 系統的公平性。
- 提供公平性評估儀表板 (Fairness Assessment Dashboard),用於視覺化模型的公平性表現。
- 包含多種偏見緩解演算法,特別是處理中和後處理技術。
- 強調公平性與模型性能之間的權衡。
- 與 Azure Machine Learning 整合。
#26
★★★
Google What-If Tool (WIT)
工具介紹
Google 提供的一個交互式視覺化工具,用於理解黑盒子分類和回歸模型。
- 允許使用者探索模型在數據子集上的性能,包括基於特徵的群體。
- 可以比較不同模型的公平性指標,如人口統計均等和均等化賠率。
- 幫助使用者假設性地修改數據點,觀察對模型預測的影響。
- 通常與 TensorBoard 或 Jupyter/Colab notebooks 一起使用。
#27
★★
其他公平性相關工具
工具列舉
除了上述主流工具外,還有其他專注於 AI 公平性、可解釋性和責任性的工具和框架,例如:
- Themis-ML: 一個專注於測試歧視的 Python 庫。
- Lime (Local Interpretable Model-agnostic Explanations): 雖然主要用於可解釋性,但理解模型為何做出特定預測有助於發現潛在偏見。
- SHAP (SHapley Additive exPlanations): 同樣是可解釋性工具,可分析特徵對預測的貢獻,有助於識別不公平的影響因素。
#28
★★★★★
負責任人工智慧 (Responsible AI)
核心概念
負責任人工智慧 是一個更廣泛的概念框架,旨在確保 AI 系統的開發和部署是合乎道德、透明、公平、可靠且可信賴的。它涵蓋了多個關鍵原則,公平性是其中的核心支柱之一。
#29
★★★★★
負責任AI 的關鍵原則
主要原則
除了公平性 (Fairness) 外,負責任AI 通常還包括:
- 可靠性與安全性 (Reliability and Safety): 系統應按預期穩定運行,並避免造成傷害。
- 隱私與資安 (Privacy and Security): 保護個人數據,防止未經授權的訪問。
- 包容性 (Inclusiveness): 系統應賦能所有人,並尊重多樣性。
- 透明度 (Transparency): 系統的運作方式和決策依據應可被理解。
- 問責制 (Accountability): 開發和部署 AI 的人員應對其系統負責。
#30
★★★★
透明度 與 可解釋性 (Explainable AI, XAI)
核心概念
透明度 指的是 AI 系統的運作機制和決策過程的可見度。可解釋性 (XAI) 則側重於以人類可理解的方式解釋模型為何做出特定預測或決策。
提高透明度和可解釋性有助於:
提高透明度和可解釋性有助於:
- 識別和診斷潛在的偏見。
- 建立使用者對系統的信任。
- 滿足法規要求和問責需求。
#31
★★★
問責制 (Accountability) 在 AI 公平性中的作用
核心概念
問責制 意味著需要明確由誰負責確保 AI 系統的公平性,以及當系統產生不公平結果時,應由誰承擔責任。這涉及到建立清晰的治理結構、開發流程、監控機制和補救措施。
#32
★★★★
AI 倫理準則與法規
重要性
全球各地政府、國際組織和企業都在制定 AI 倫理準則和相關法規(如歐盟的 AI Act),旨在引導 AI 的負責任發展和應用。這些準則和法規通常將公平性、反歧視列為核心要求。了解並遵守這些規範對於 AI 應用規劃至關重要。
#33
★★★★
公平性在招聘與人事中的應用案例
案例說明
AI 被用於篩選履歷、評估候選人或預測員工績效。偏見可能導致對特定性別、種族或年齡群體的歧視。例如,如果模型學習了歷史數據中男性佔據高階職位的模式,可能會在篩選時偏好男性候選人。確保公平性需要仔細檢查數據、模型和評估標準。
#34
★★★★
公平性在金融信貸中的應用案例
案例說明
AI 用於評估信用風險、決定貸款批准和利率。如果數據反映了歷史上對某些社區或族裔群體的信貸歧視(例如 Redlining),模型可能會延續這種不公平。公平性在此領域至關重要,需要滿足反歧視法規,並確保不同群體有平等的信貸機會。
#35
★★★★
公平性在刑事司法中的應用案例
案例說明
AI 被用於預測再犯風險、協助量刑或預測犯罪熱點。這類應用極具爭議,因為歷史犯罪數據本身可能存在嚴重的系統性偏見(例如,針對特定族裔的過度執法)。使用這些數據訓練的模型可能導致對某些群體更嚴厲的判決或更高的風險評分,引發嚴重的公平性問題。
#36
★★★★
公平性在醫療保健中的應用案例
案例說明
AI 用於疾病診斷、治療建議或資源分配。如果臨床數據主要來自特定人群,模型可能對其他人群的診斷不夠準確。例如,某些皮膚癌檢測模型在深色皮膚上表現較差。醫療領域的公平性關係到健康平等權。
#37
★★★
公平性在內容推薦中的應用案例
案例說明
推薦系統(如新聞、商品、影音)可能產生過濾氣泡 (Filter Bubble) 或 回聲室效應 (Echo Chamber),限制用戶接觸多元觀點。此外,推薦演算法可能無意中放大刻板印象或推送歧視性內容。公平性考量包括確保推薦的多樣性和避免有害內容的放大。
#38
★★★★
公平性在人臉辨識中的應用案例
案例說明
許多研究表明,商用人臉辨識系統在識別女性和深色皮膚個體時的錯誤率遠高於淺膚色男性。這主要是由於訓練數據中代表性偏見造成的。這種不公平可能導致錯誤識別、監控歧視等問題。
#39
★★★
偏見 vs 變異數 (Bias vs. Variance)
概念區分
在機器學習中,偏見(Bias)通常指模型預測值與真實值之間的系統性差異(欠擬合),而變異數(Variance)指模型對訓練數據中噪聲的敏感度(過擬合)。這與演算法偏見(公平性意義上的偏見)是不同的概念,後者指對特定群體的不公平對待。但模型的 Bias-Variance 特性可能影響其公平性表現。

#40
★★★
回饋迴路 (Feedback Loops) 作為偏見來源
機制說明
當模型的預測結果影響了未來的數據收集過程時,可能形成回饋迴路,進一步放大現有偏見。例如,預測犯罪熱點的系統可能導致在某些區域加強警力部署,從而發現更多犯罪,使得這些區域在未來的數據中顯得更加危險,形成惡性循環。
#41
★★★
採樣偏見 (Sampling Bias)
核心概念
數據收集的採樣方法本身存在問題,導致樣本不能代表其來源的總體。這與代表性偏見密切相關,但更側重於採樣過程的缺陷。例如,僅在白天對某地區進行調查,可能忽略夜間活動人口的特徵。
#42
★★★
預測均等 (Predictive Parity / Calibration)
定義與目標
要求對於模型給出相同預測分數(或機率)的個體,無論其屬於哪個群體,其真實結果為正面的比例應該相等。換句話說,模型的預測分數對所有群體都具有相同的意義。這是一種基於模型預測值的公平性衡量。
#43
★★★
公平性與準確性的權衡 (Fairness-Accuracy Trade-off)
核心概念
在許多情況下,應用偏見緩解技術以提高公平性,可能會導致模型整體準確性的下降。理解和量化這種權衡關係對於做出負責任的決策至關重要。需要根據具體應用場景和潛在危害來決定可接受的公平性水平和準確性損失。
#44
★★★★
AI 公平性的生命週期管理
核心概念
確保 AI 公平性不是一次性的任務,而是一個貫穿 AI 系統整個生命週期(從問題定義、數據收集、模型開發、部署到監控和維護)的持續過程。需要在每個階段都考慮潛在的偏見和公平性影響,並採取相應措施。
#45
★★★
利害關係人參與 (Stakeholder Engagement)
重要性
在定義公平性目標、評估潛在影響和設計緩解策略時,讓受 AI 系統影響的各方利害關係人(包括開發者、使用者、受影響群體、監管機構等)參與進來至關重要。這有助於確保公平性的定義和實施能反映多方觀點和需求。
#46
★★
敏感屬性 (Sensitive Attributes)
定義
指那些在法律或倫理上不應作為決策依據的個人特徵,例如種族、性別、宗教、年齡、性取向、殘疾狀況等。AI 公平性主要關注模型輸出是否會因這些屬性而產生差異對待。
#47
★★
代理變數 (Proxy Variables)
概念
即使從數據中移除了敏感屬性,其他看似中性的變數(代理變數)可能與敏感屬性高度相關,從而間接引入偏見。例如,郵遞區號可能與種族或收入水平相關。識別和處理代理變數是實現公平性的挑戰之一。
#48
★★
混淆矩陣 (Confusion Matrix) 與公平性指標
關係
許多群體公平性指標(如機會均等、均等化賠率)是基於混淆矩陣中的值(真陽性 TP, 假陽性 FP, 真陰性 TN, 假陰性 FN)計算得出的。例如:
- TPR (True Positive Rate) = TP / (TP + FN)
- FPR (False Positive Rate) = FP / (FP + TN)
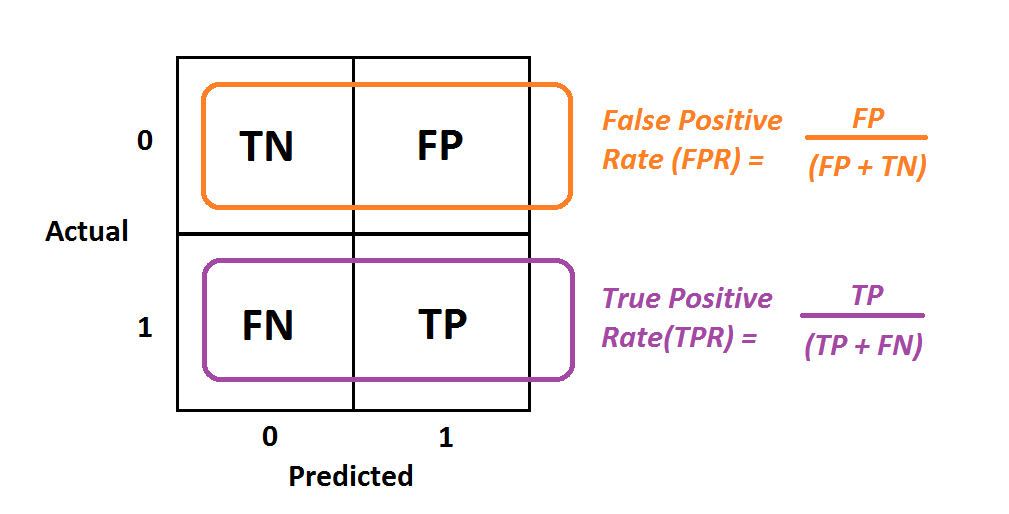
#49
★★
公平性干預的潛在風險
風險說明
雖然目標是提高公平性,但不當的偏見緩解措施也可能帶來負面影響,例如:
- 顯著降低模型效用或準確性。
- 引入新的、未預見的偏見。
- 增加模型的複雜性,降低可解釋性。
- 可能違反其他法律或倫理原則(例如,過度干預可能被視為反向歧視)。
#50
★★★
公平性稽核 (Fairness Audit)
概念與目的
公平性稽核 是指定期或在關鍵節點對 AI 系統進行系統性的檢查和評估,以識別潛在的偏見和不公平性,並驗證是否符合預定的公平性標準和法規要求。這是確保問責制和持續改進的重要機制。
#51
★★★
公平性的不同層次
層次區分
公平性可以在不同層次上討論:
- 程序公平 (Procedural Fairness): 關注決策過程本身是否公平、無偏。
- 分配公平 (Distributive Fairness): 關注資源或結果的分配是否公平。
- 代表性公平 (Representational Fairness): 關注系統是否準確、無刻板印象地代表不同群體。
#52
★★
確認偏見 (Confirmation Bias) 在 AI 中的體現
概念
人類傾向於尋找、解釋和回憶支持自己先前信念或假設的資訊。在 AI 開發中,這可能體現在數據選擇、模型設計或結果解釋上,開發者可能無意中偏好那些符合其預期的模型或結果,從而忽略或淡化了潛在的偏見問題。
#53
★★
反事實公平性 (Counterfactual Fairness)
概念
一種個體公平性的概念,認為一個決策是公平的,如果即使某個個體的敏感屬性發生了反事實的改變(例如,性別從男變為女),模型的預測結果保持不變。這需要建立因果模型來評估屬性改變的影響。
#54
★★
公平性 Gerrmandering
概念
指一種操縱模型或數據以滿足特定公平性指標,但實際上可能掩蓋或轉移了不公平性的現象。例如,通過調整閾值使得某個群體達到了機會均等,但可能在其他方面(如校準度)表現更差,或者只是將不公平性轉移到其他子群體。
#55
★★
模型卡 (Model Cards)
概念與目的
由 Google 提出的標準化文件,旨在提高模型的透明度。模型卡應包含模型的預期用途、性能指標(包括在不同群體上的表現)、公平性評估結果、限制、倫理考量以及訓練數據等資訊,幫助使用者了解模型的特性和潛在風險。
#56
★★★
公平性與隱私的關係
相互影響
公平性和隱私之間可能存在緊張關係。例如:
- 評估和緩解偏見通常需要訪問敏感屬性數據,這可能引發隱私擔憂。
- 應用某些隱私保護技術(如差分隱私)可能會影響模型的準確性,進而對公平性產生間接影響。
#57
★★
演算法偏見的社會影響
影響層面
演算法偏見可能導致系統性的歧視,加劇社會不平等,影響個人的機會(教育、就業、信貸)、資源分配、甚至人身自由。它可能侵蝕公眾對技術和機構的信任,並引發法律和倫理挑戰。
#58
★★
公平性的主觀性與文化差異
考量因素
對「公平」的理解可能因文化、社會背景和個人價值觀而異。在一個社會中被認為是公平的標準或做法,在另一個社會中可能不適用。在設計和部署跨文化或全球性的 AI 系統時,必須考慮到這種公平性的相對性和情境性。
#59
★
條件性人口統計均等 (Conditional Demographic Parity)
概念
人口統計均等的一個變體,要求在控制某些「合法」或「相關」的特徵後,不同受保護群體獲得正面預測的比例應該相等。試圖在群體平等和基於資質的個體差異之間取得平衡。
#60
★
公平性感知 (Fairness Perception)
概念
除了客觀的公平性指標外,使用者或受影響者如何主觀感知 AI 系統的公平性也很重要。即使系統在技術上滿足了某些公平性指標,如果使用者感覺不公平,也可能影響其接受度和信任度。這涉及到人機互動和心理學層面的考量。
沒有找到符合條件的重點。
↑