iPAS AI應用規劃師 考試重點
L23302 模型選擇與架構設計
主題分類
1
模型選擇原則
2
常見模型類型與適用場景
3
模型架構設計考量
4
特定模型架構
5
模型複雜度與效能權衡
6
自動化模型選擇 (AutoML)
7
評估指標與模型選擇
8
實務考量與工具
#1
★★★★★
模型選擇 (Model Selection) 的目標
核心目標
模型選擇 的核心目標是根據特定的問題、數據特性、業務需求和資源限制,從眾多可能的機器學習模型中,挑選出最適合、預期泛化能力最強的模型。這不僅僅是選擇性能最高的模型,還需要考慮多方面因素。
#2
★★★★★
模型選擇原則:問題類型 (Problem Type)
核心考量
首要考量是待解決的問題屬於哪種類型。不同的模型適用於不同的任務:
- 監督式學習 (Supervised Learning):
- 分類 (Classification):預測離散類別(如垃圾郵件偵測、圖像分類)。
- 迴歸 (Regression):預測連續數值(如房價預測、銷售額預測 - 參考樣題 Q8)。
- 非監督式學習 (Unsupervised Learning):
- 分群 (Clustering):將相似數據分組(如客戶分群)。
- 降維 (Dimensionality Reduction):減少數據特徵數量(如PCA)。
- 強化學習 (Reinforcement Learning):透過與環境互動學習最佳策略(如遊戲 AI、機器人控制)。
#3
★★★★
模型選擇原則:數據特性 (Data Characteristics)
核心考量
數據的特性會影響模型的適用性:
- 數據量大小 (Volume): 數據量大時,複雜模型(如深度學習)可能表現更好;數據量小時,簡單模型或正則化可能更優。
- 特徵數量/維度 (Dimensionality): 高維度數據可能需要降維或使用能處理高維稀疏數據的模型(如某些線性模型、SVM)。
- 數據類型 (Data Type): 表格數據、圖像數據(常用 CNN - 參考樣題 Q4)、文本數據(常用 RNN, Transformer - 參考樣題 Q4)、時間序列數據等,各有適合的模型架構。
- 數據品質 (Data Quality): 數據中的噪聲、缺失值、離群值等會影響模型選擇和預處理策略。
- 線性可分性 (Linear Separability): 數據是否線性可分影響線性模型與非線性模型的選擇。
#4
★★★★
模型選擇原則:性能指標 (Performance Metrics)
核心考量
基於業務目標選擇合適的性能評估指標至關重要。不同的指標衡量模型的不同方面(如準確率、精確率、召回率、F1、AUC、RMSE、R² 等)。模型選擇應以在目標指標上表現最佳為主要依據之一。(參考 L23303)
#5
★★★
模型選擇原則:計算資源 (Computational Resources)
核心考量
模型的訓練時間、推論時間(預測速度)以及所需的記憶體和硬體(如 GPU)是重要的實務考量。某些複雜模型(如大型深度學習模型)需要大量的計算資源和時間,可能不適用於資源受限的場景。
#6
★★★★
模型選擇原則:可解釋性 (Interpretability) / 可說明性 (Explainability)
核心考量
在某些應用場景(如金融風控、醫療診斷、法律判決),理解模型為何做出特定決策至關重要。簡單的模型(如線性回歸、決策樹)通常具有較好的可解釋性,而複雜的黑盒子模型(Black-box Models,如深度神經網路)則較難解釋。模型選擇需要在性能和可解釋性之間進行權衡。
#7
★★★
模型選擇原則:模型維護與更新 (Maintenance & Update)
核心考量
考慮模型的長期維護成本。某些模型可能需要更頻繁的重新訓練或更新以適應數據變化。模型的複雜度、對新數據的敏感度等都會影響維護的難易程度。
#8
★★★★
常見模型:線性模型 (Linear Models)
類型與適用場景
包括線性迴歸 (Linear Regression)、邏輯迴歸 (Logistic Regression)、SVM (線性核)。
- 適用於:數據量不大、特徵與目標間關係大致線性、需要高可解釋性的場景。
- 優點:簡單、快速、易於解釋。
- 缺點:難以捕捉複雜的非線性關係。
#9
★★★★
常見模型:樹模型 (Tree-based Models)
類型與適用場景
包括決策樹 (Decision Tree)、隨機森林 (Random Forest)、梯度提升樹 (Gradient Boosting Trees, 如 XGBoost, LightGBM, CatBoost)。
- 適用於:表格數據、特徵交互複雜、對特徵縮放不敏感的分類和迴歸問題。
- 優點:能處理非線性關係、對缺失值和異常值相對穩健(集成模型)、性能通常較好。
- 缺點:單棵決策樹易過擬合、集成模型可解釋性較差。
#10
★★★★
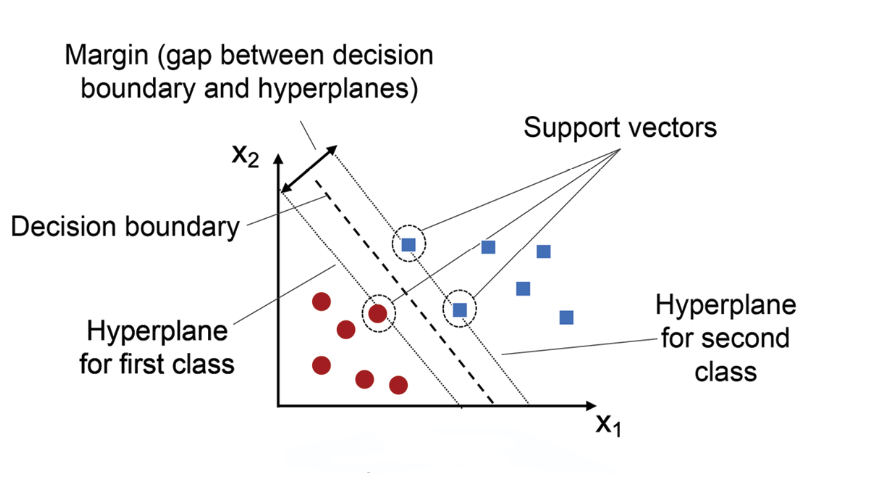
常見模型:支持向量機 (SVM, Support Vector Machine)
類型與適用場景
一種強大的分類(也可迴歸)演算法,透過尋找最大邊界超平面 (Maximum Margin Hyperplane) 來劃分數據。
- 適用於:高維數據、數據量中等、需要處理非線性關係(透過核技巧 Kernel Trick)。
- 優點:在高維空間表現良好、對過擬合相對穩健、核技巧提供靈活性。
- 缺點:對超參數和核函數選擇敏感、計算成本較高(尤其大數據)、可解釋性一般。
#11
★★★★★
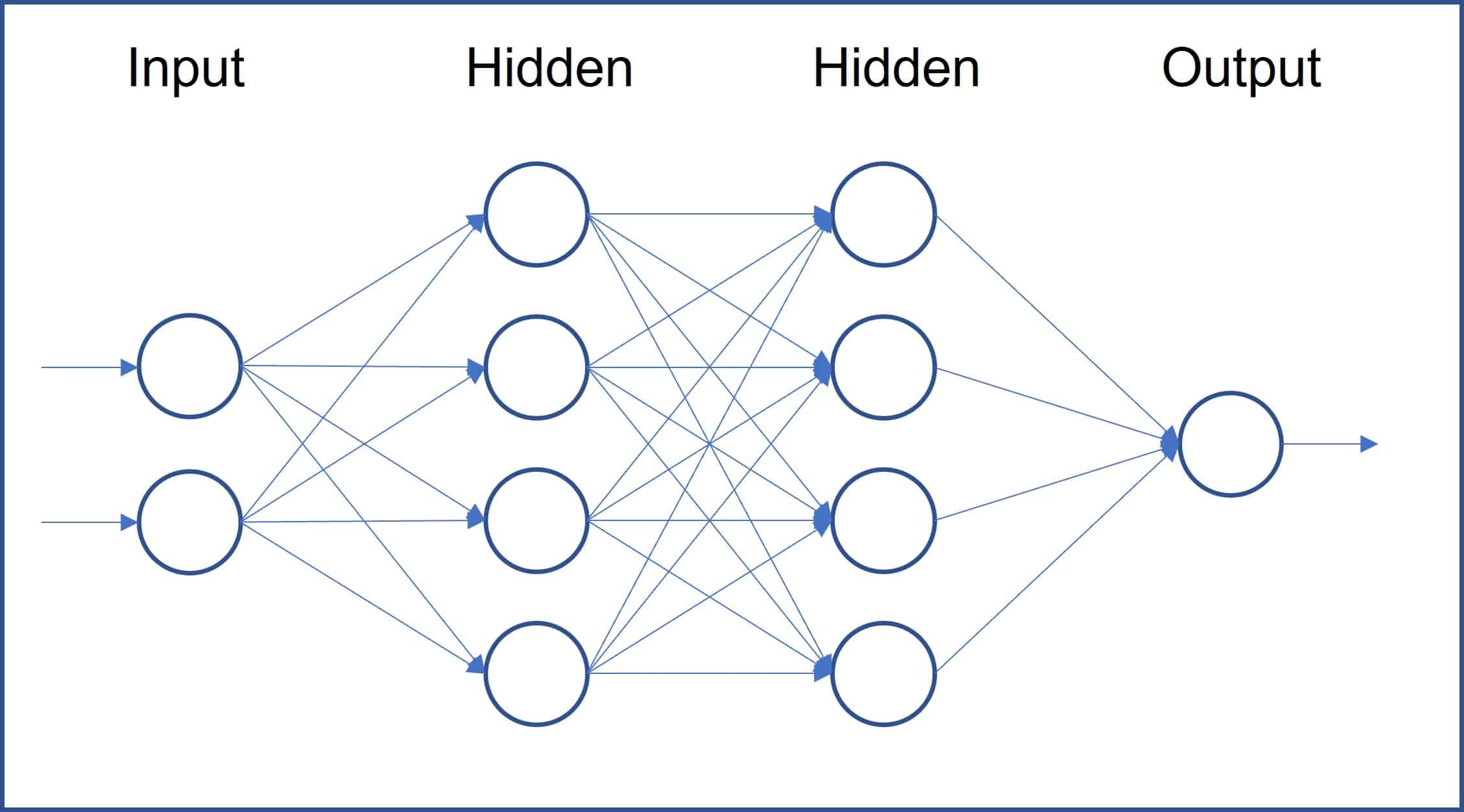
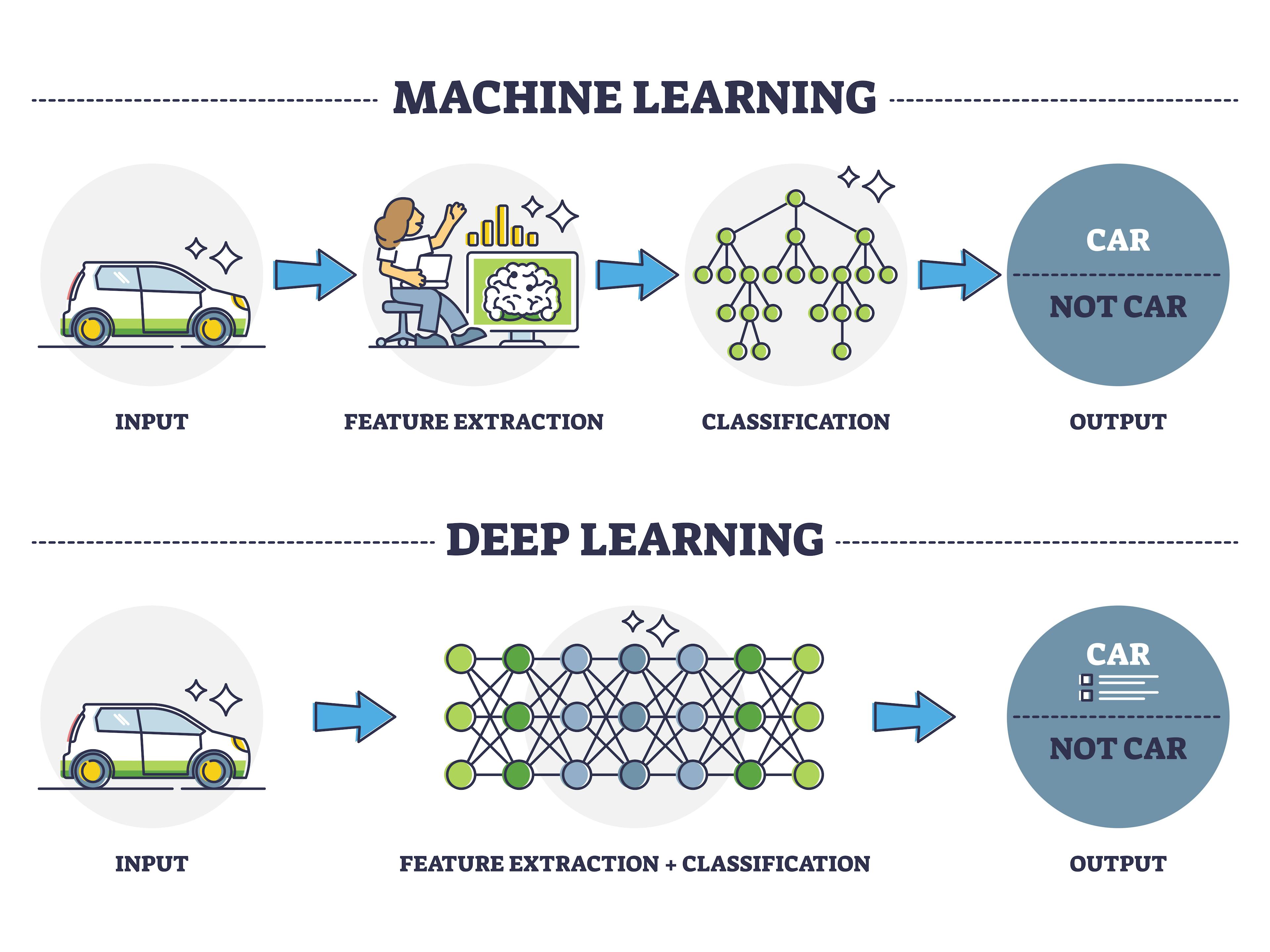
常見模型:神經網路 (NN, Neural Network) / 深度學習 (DL, Deep Learning)
類型與適用場景 (參考樣題 Q10)
模仿人腦神經元結構的模型,深度學習指使用多層神經網路。樣題 Q10 強調神經網路透過多層結構學習複雜特徵。
- 適用於:大規模數據、複雜非線性關係、非結構化數據(圖像、文本、語音)。
- 優點:能學習高度複雜的模式、在圖像/語音/文本等領域取得突破性成果、自動特徵學習(無需過多手動特徵工程)。
- 缺點:需要大量數據和計算資源、易過擬合、可解釋性差(黑盒子)、對超參數敏感。
#12
★★★
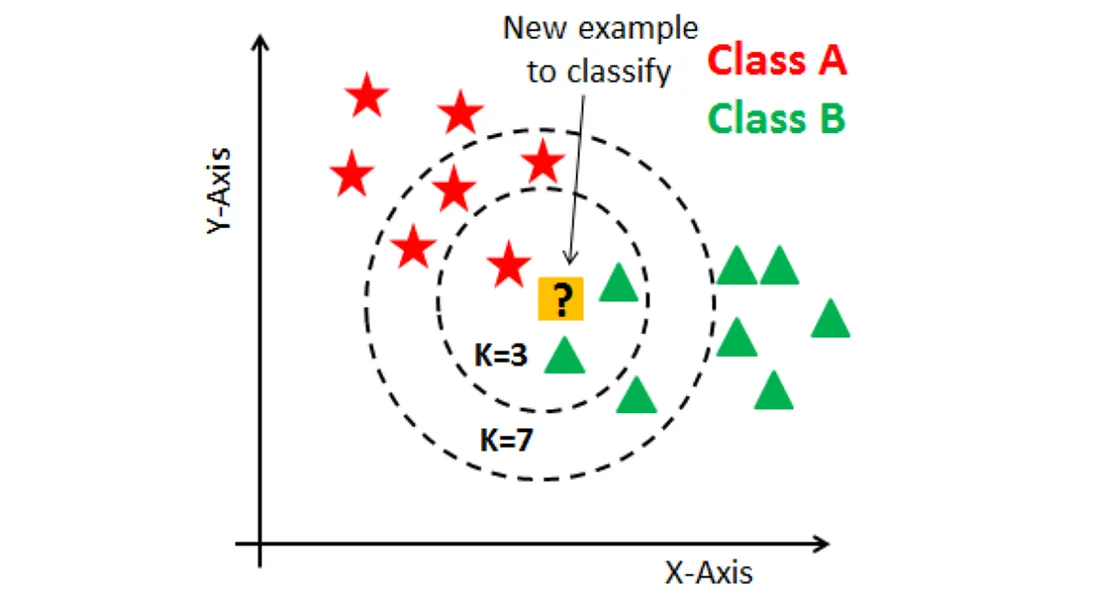
常見模型:K-近鄰 (KNN, K-Nearest Neighbors)
類型與適用場景
一種基於實例 (Instance-based) 的懶惰學習 (Lazy Learning) 演算法。預測新樣本時,查找訓練集中與其最相似的 K 個鄰居,並根據鄰居的類別(分類)或值(迴歸)進行預測。
- 適用於:數據分佈不規則、特徵空間有意義的距離度量。
- 優點:簡單、易於理解、無需訓練階段。
- 缺點:預測成本高(需要計算與所有訓練樣本的距離)、對 K 值和距離度量敏感、對高維數據和數據規模敏感。
#13
★★★
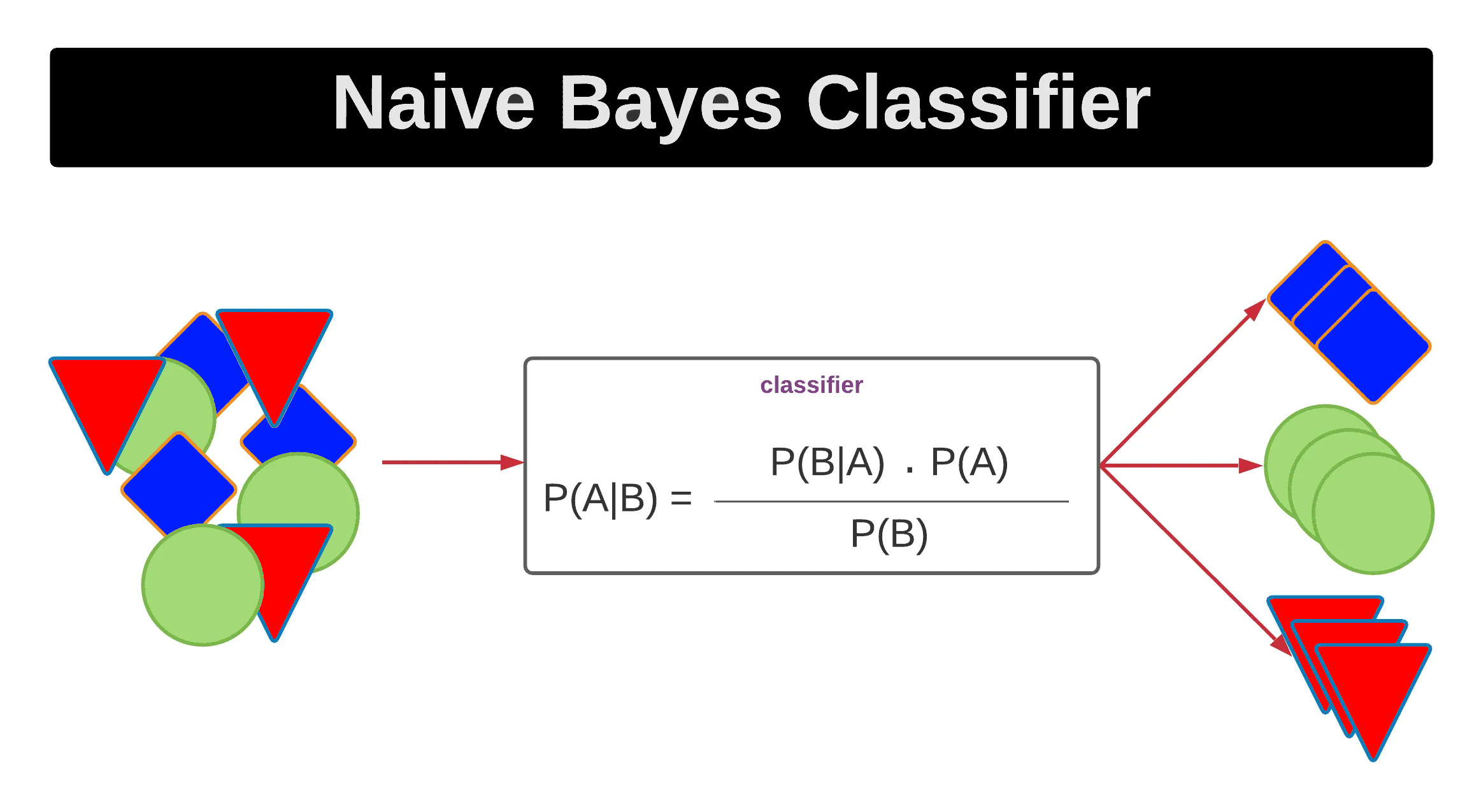
常見模型:貝氏分類器 (Bayesian Classifiers)
類型與適用場景
基於貝氏定理 (Bayes' Theorem) 的一類分類器,最常見的是樸素貝氏 (Naive Bayes)。樸素貝氏假設特徵之間條件獨立。
- 適用於:文本分類(如垃圾郵件過濾)、特徵維度高、需要快速訓練。
- 優點:簡單、快速、對小數據集表現尚可、能處理高維數據。
- 缺點:特徵獨立性假設在現實中通常不成立,可能影響精度。
#14
★★★★
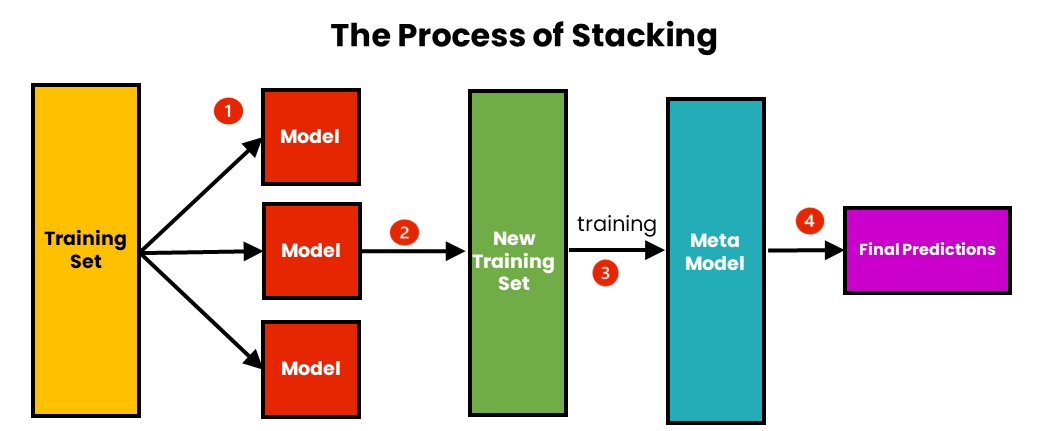
常見模型:集成方法 (Ensemble Methods)
核心思想
結合多個基學習器 (Base Learners) 的預測來獲得比單個學習器更好、更穩健的性能。主要方法包括:
- Bagging (如 隨機森林): 透過自助抽樣構建多個獨立的基學習器,並對其預測進行平均或投票。主要降低變異數。
- Boosting (如 AdaBoost, Gradient Boosting): 串行地構建基學習器,後續學習器重點關注先前學習器預測錯誤的樣本。主要降低偏誤。
- Stacking: 訓練多個不同的基學習器,然後用一個元學習器 (Meta-learner) 來結合它們的預測。
#15
★★★★
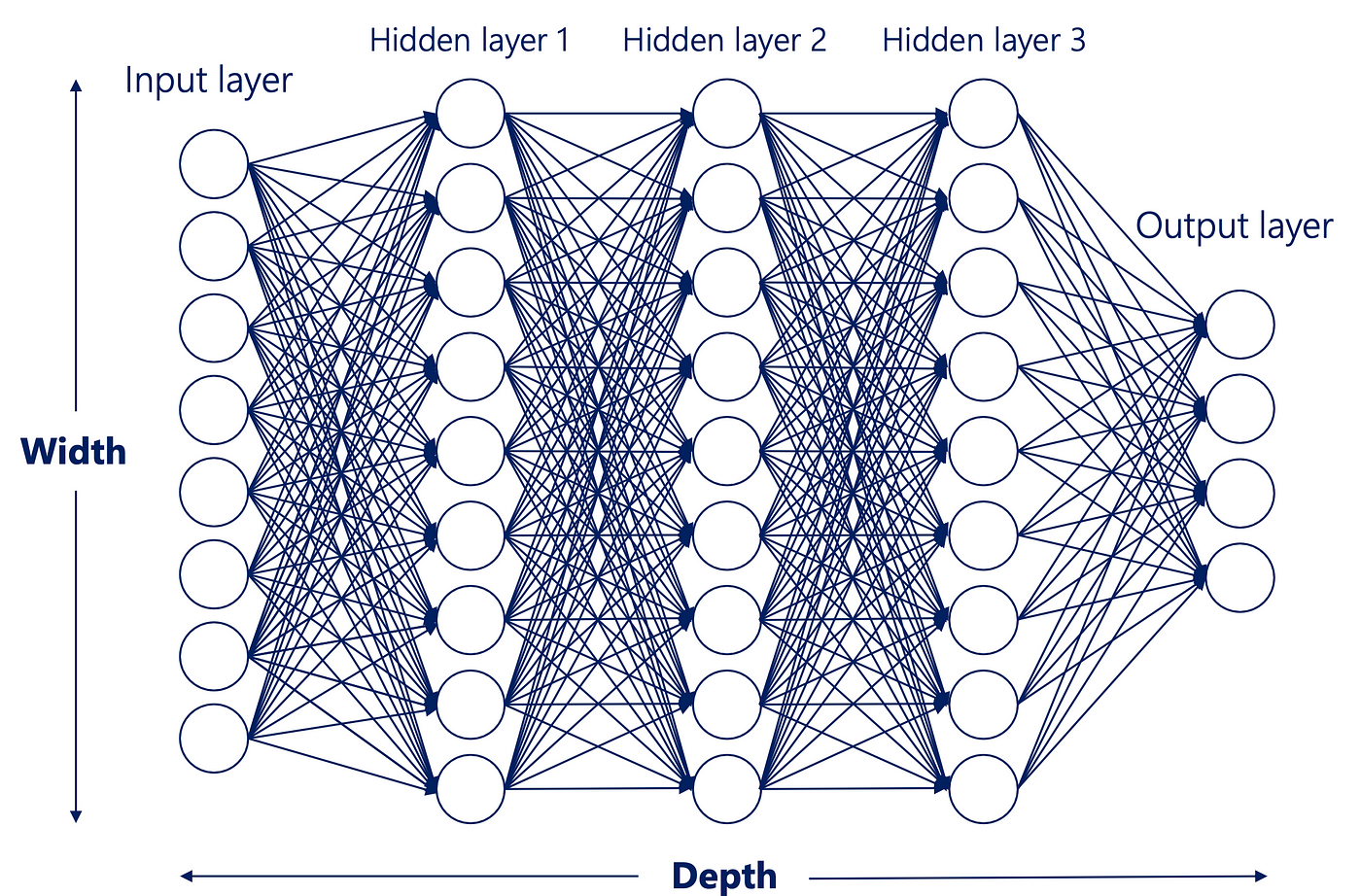
架構設計:層數 (Number of Layers) 與 寬度 (Width) - 神經網路
設計考量 (參考樣題 Q12)
在設計神經網路架構時:
- 層數(深度):增加層數可以讓網路學習更抽象、更複雜的特徵表示。但過深可能導致梯度消失/爆炸和訓練困難。
- 寬度(每層單元數):增加寬度可以讓每層學習更多樣的特徵。但過寬可能增加計算量和過擬合風險。
#16
★★★
架構設計:激活函數 (Activation Function) 的選擇
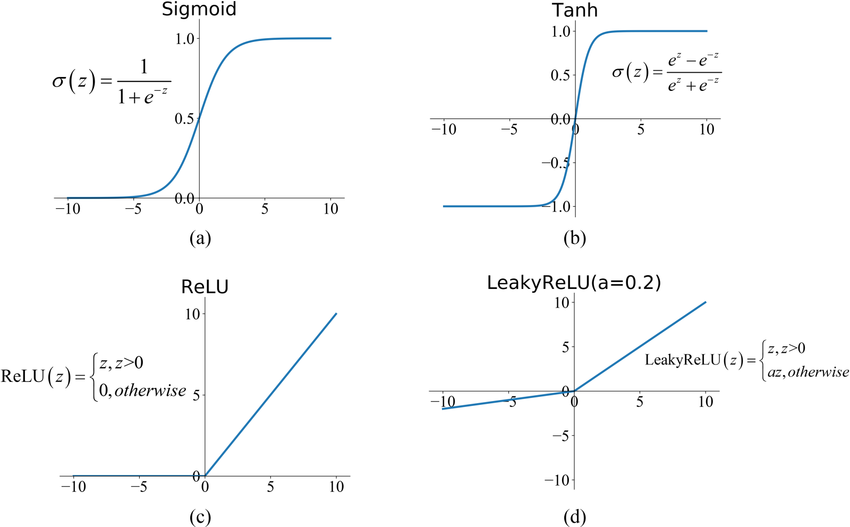
設計考量 (參考樣題 Q4 選項)
激活函數 為神經網路引入非線性,使其能夠學習複雜模式。常見的激活函數包括:
- Sigmoid: 將輸出壓縮到 (0, 1),常用於二分類輸出的機率。缺點是易飽和導致梯度消失。
- Tanh (雙曲正切): 將輸出壓縮到 (-1, 1),通常比 Sigmoid 收斂快。同樣存在梯度飽和問題。
- ReLU (Rectified Linear Unit): f(x) = max(0, x)。計算簡單,有效緩解梯度消失問題(樣題 Q4 提及),是目前最常用的激活函數之一。缺點是可能導致「死亡 ReLU」問題。
- Leaky ReLU, ELU 等:ReLU 的變體,試圖解決死亡 ReLU 問題。
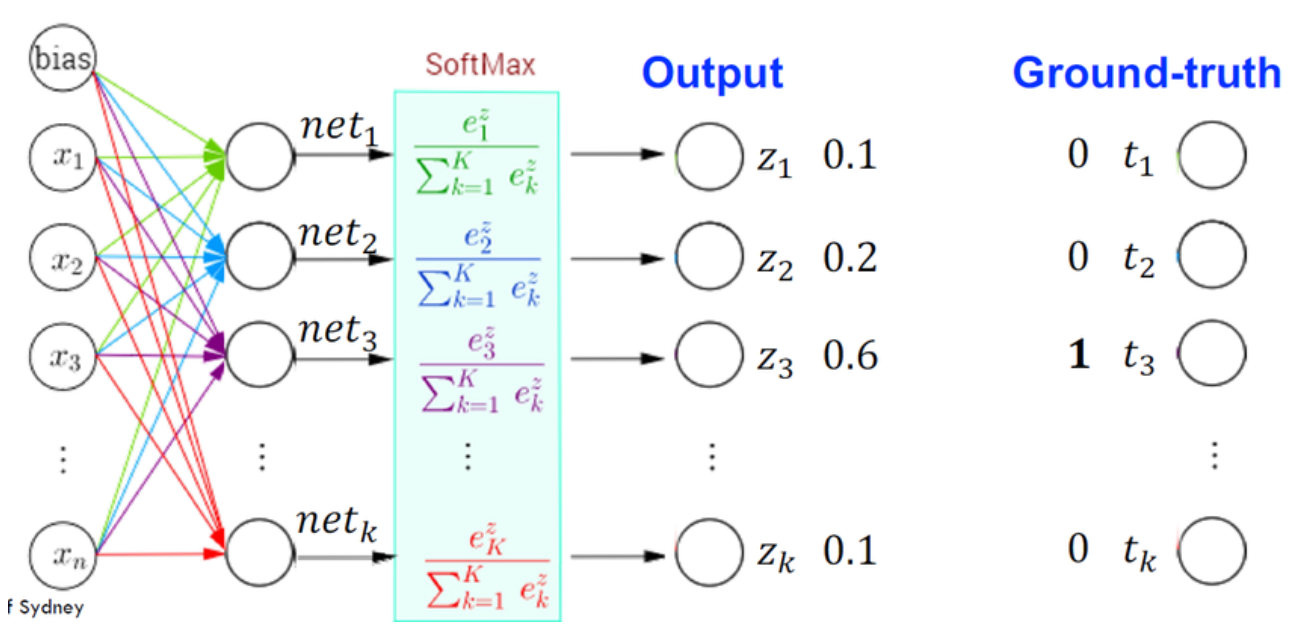
- Softmax: 用於多分類問題的輸出層,將輸出轉換為表示各類別機率的分佈。

#17
★★★
架構設計:連接方式 (Connectivity Patterns)
設計考量
神經網路中層與層之間的連接方式也影響模型特性:
- 全連接層 (Fully Connected Layer): 每個輸入神經元都連接到每個輸出神經元。參數多,易過擬合。
- 卷積層 (Convolutional Layer): 使用卷積核進行局部連接和權重共享,有效提取空間層次特徵(用於圖像)。
- 循環層 (Recurrent Layer): 具有時間上的循環連接,用於處理序列數據。
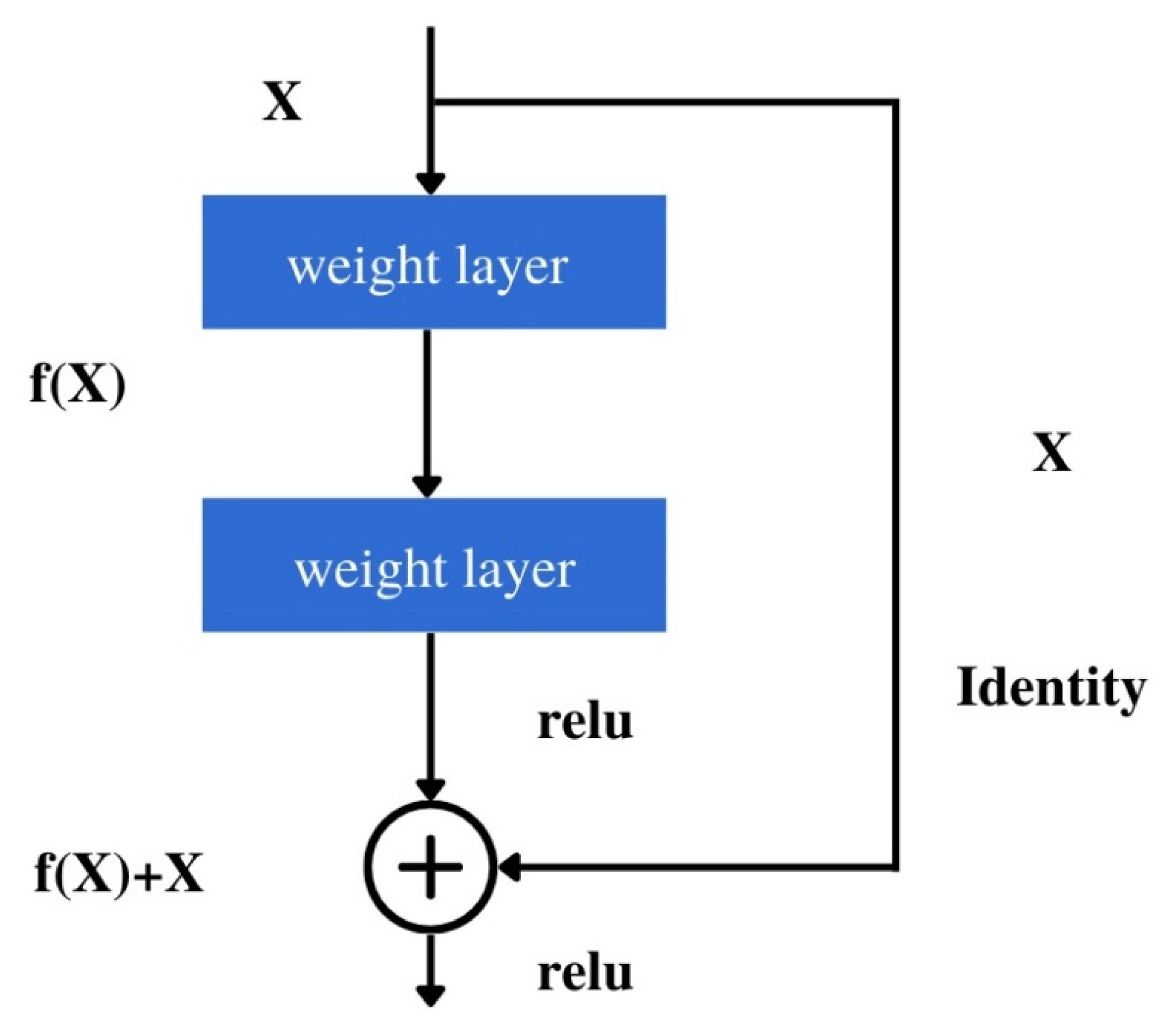
- 殘差連接 (Residual Connections, 如 ResNet): 允許梯度直接流過某些層,有助於訓練非常深的網路。
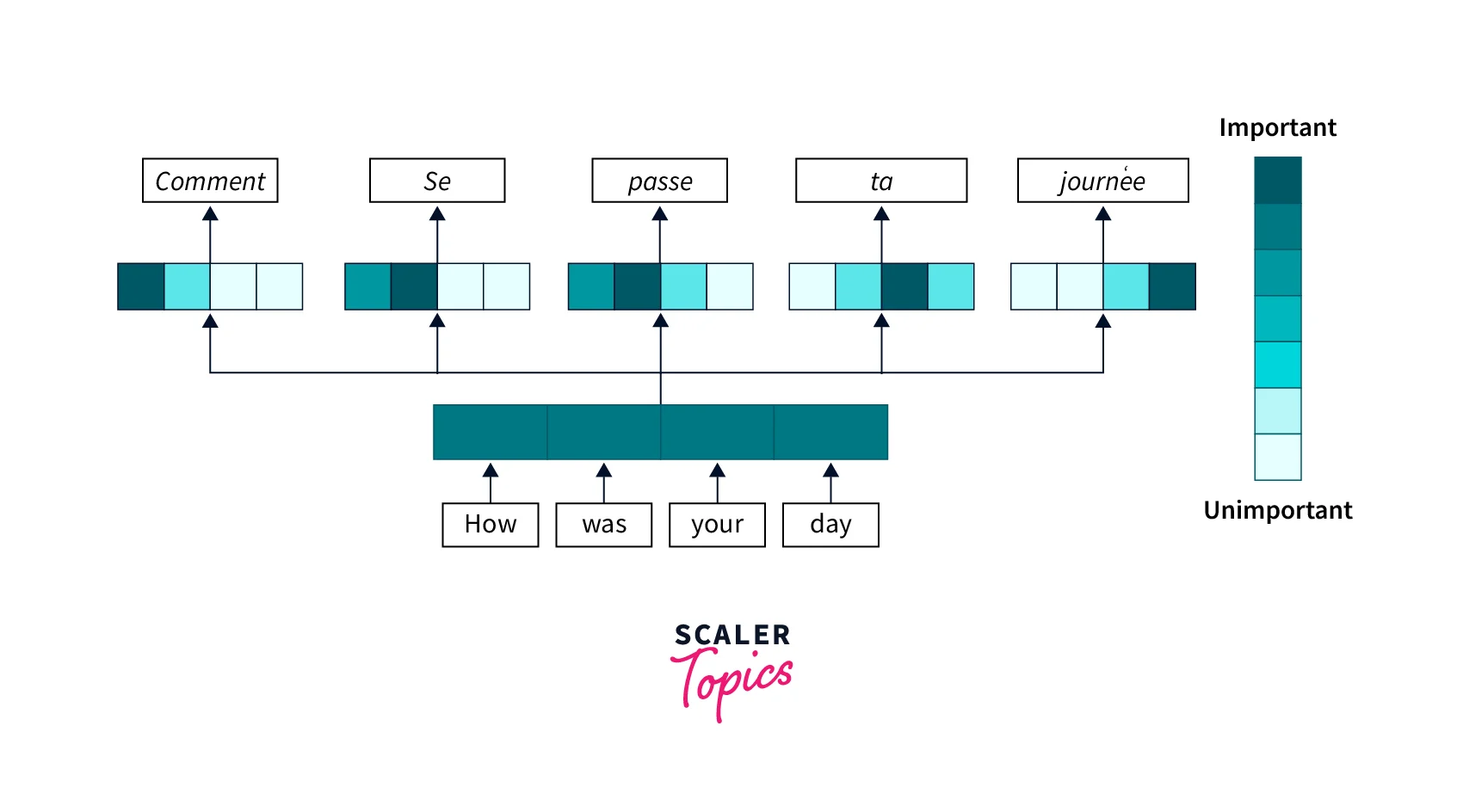
- 注意力機制 (Attention Mechanism): 允許模型在處理輸入時動態地關注不同部分。
#18
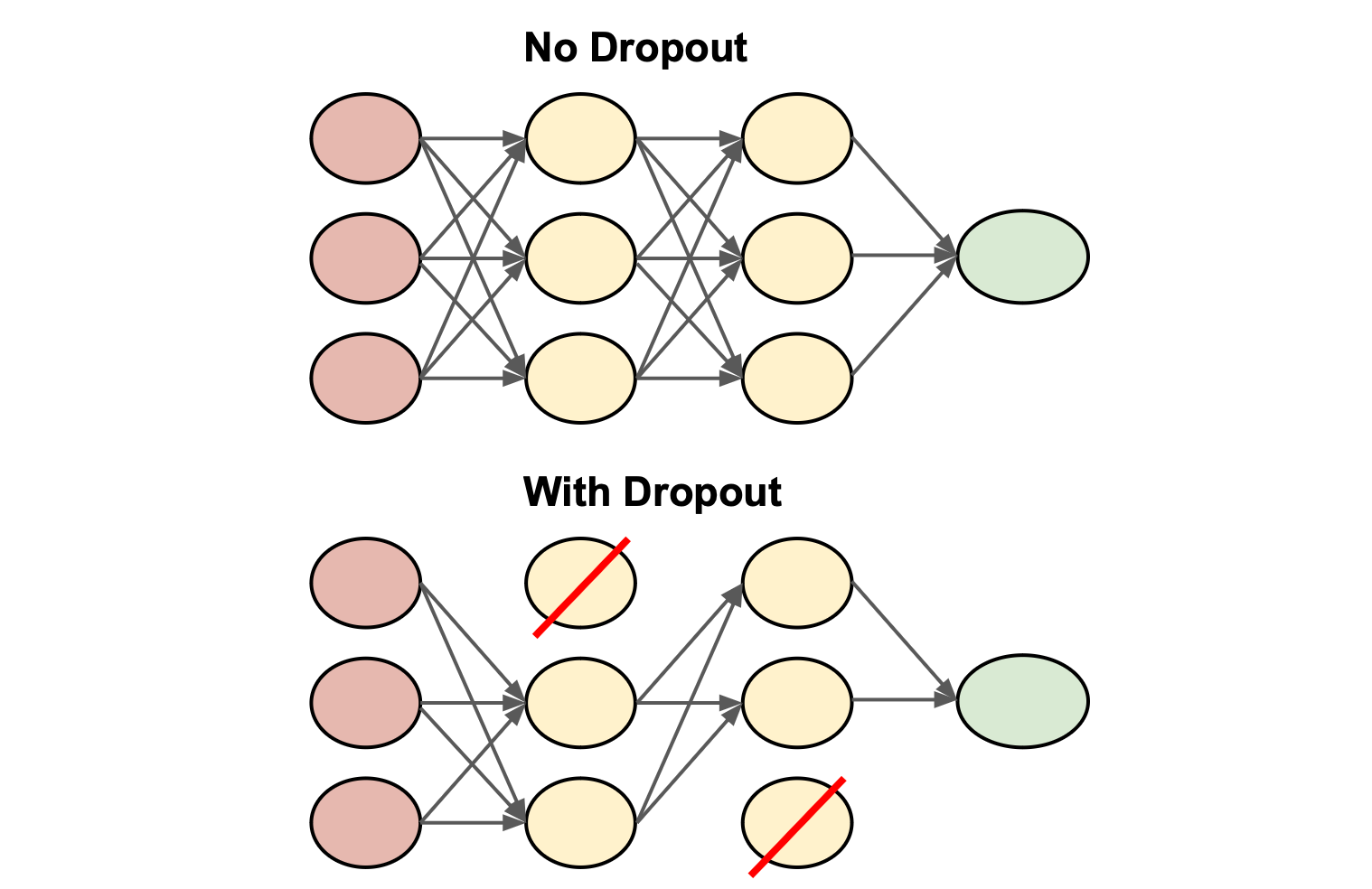
★★
架構設計:正則化層 (Regularization Layers) 的使用
設計考量
除了在損失函數中加入正則化項,也可以在網路架構中直接加入正則化層來防止過擬合,例如:
- Dropout 層
- 批次正規化層 (Batch Normalization)(也具有一定的正則化效果)
#19
★★★★★
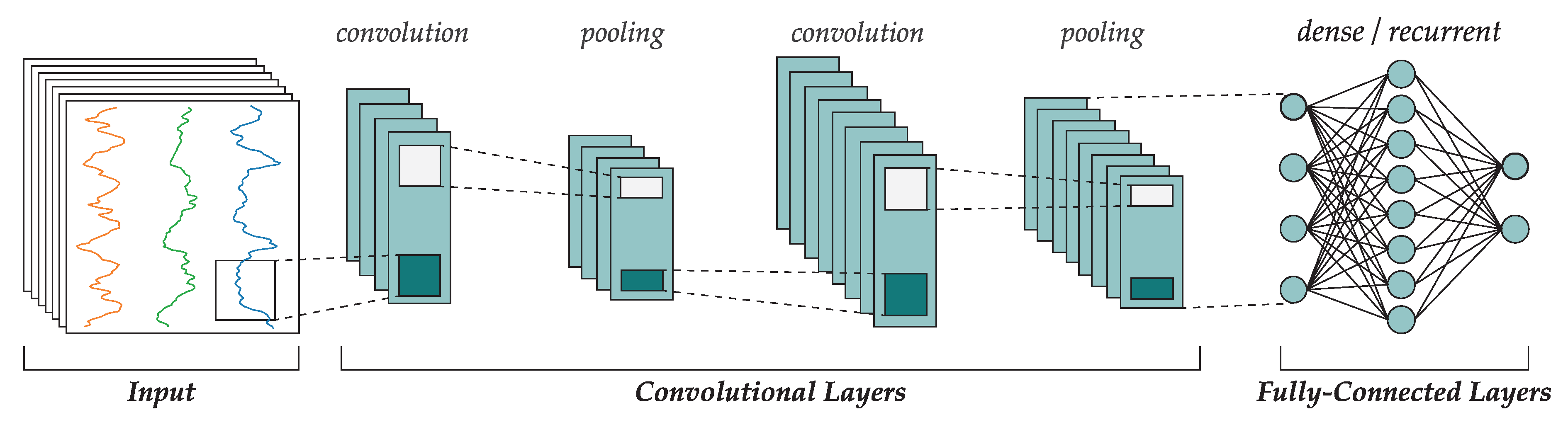
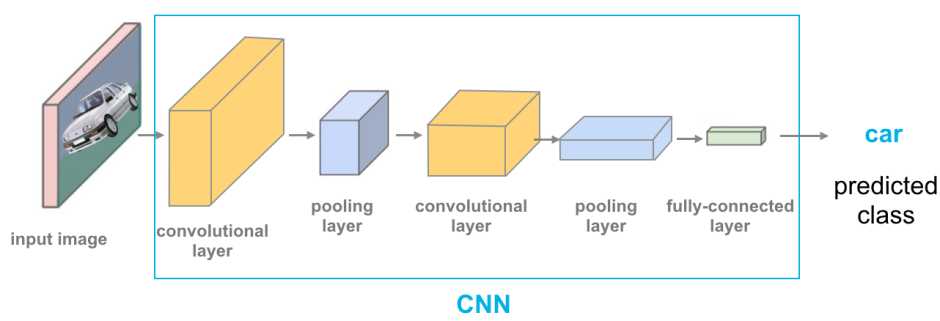
特定架構:卷積神經網路 (CNN, Convolutional Neural Network)
架構特點與應用 (參考樣題 Q4, Q12)
CNN 是處理網格狀數據(如圖像)的標準深度學習架構。關鍵組件包括:
>
- 卷積層 (Convolutional Layer): 使用濾波器(卷積核)提取局部特徵。
- 池化層 (Pooling Layer): 降低特徵圖的空間維度,減少計算量並提供一定的平移不變性(如Max Pooling, Average Pooling)。
- 全連接層 (Fully Connected Layer): 通常在最後幾層,用於整合特徵並進行分類或迴歸。
>
#20
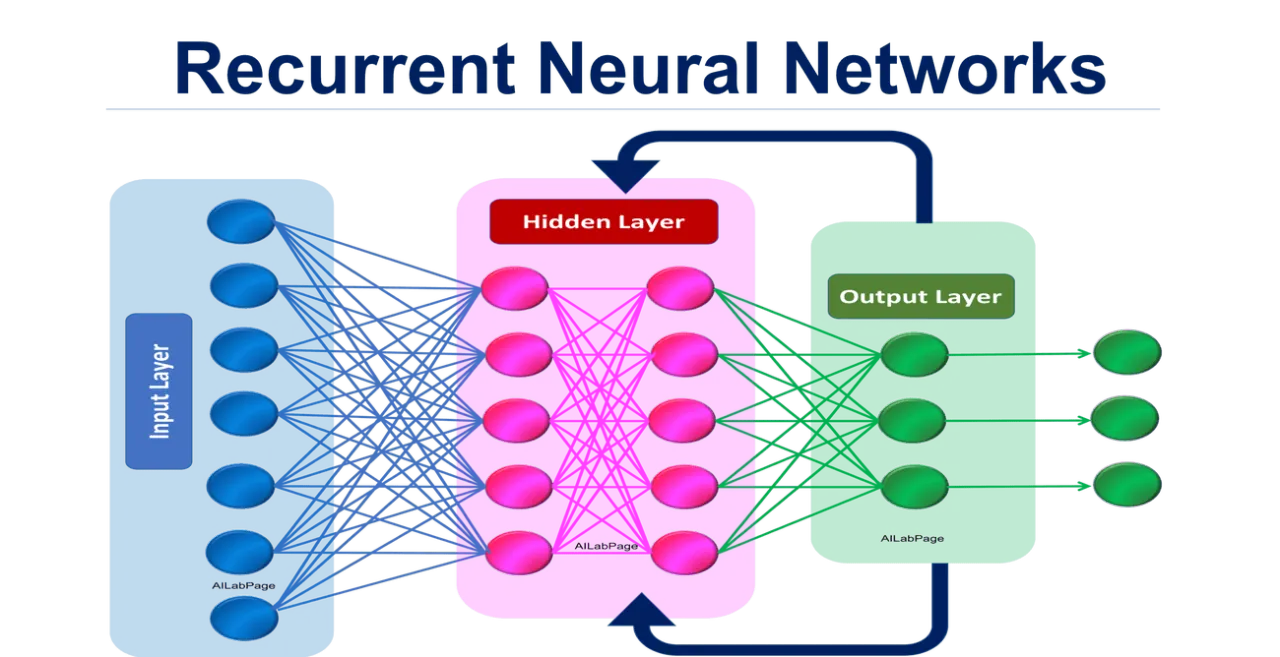
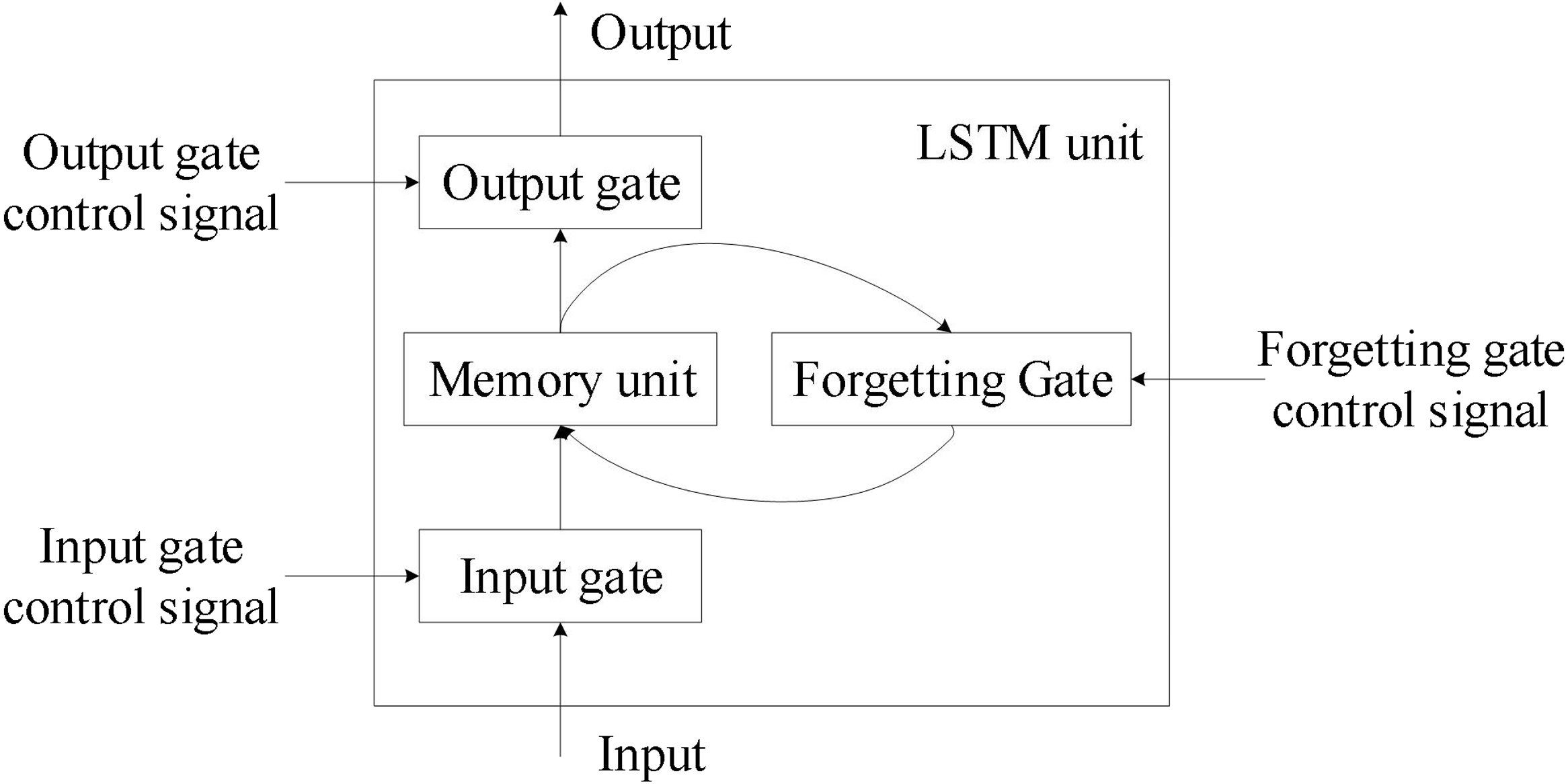
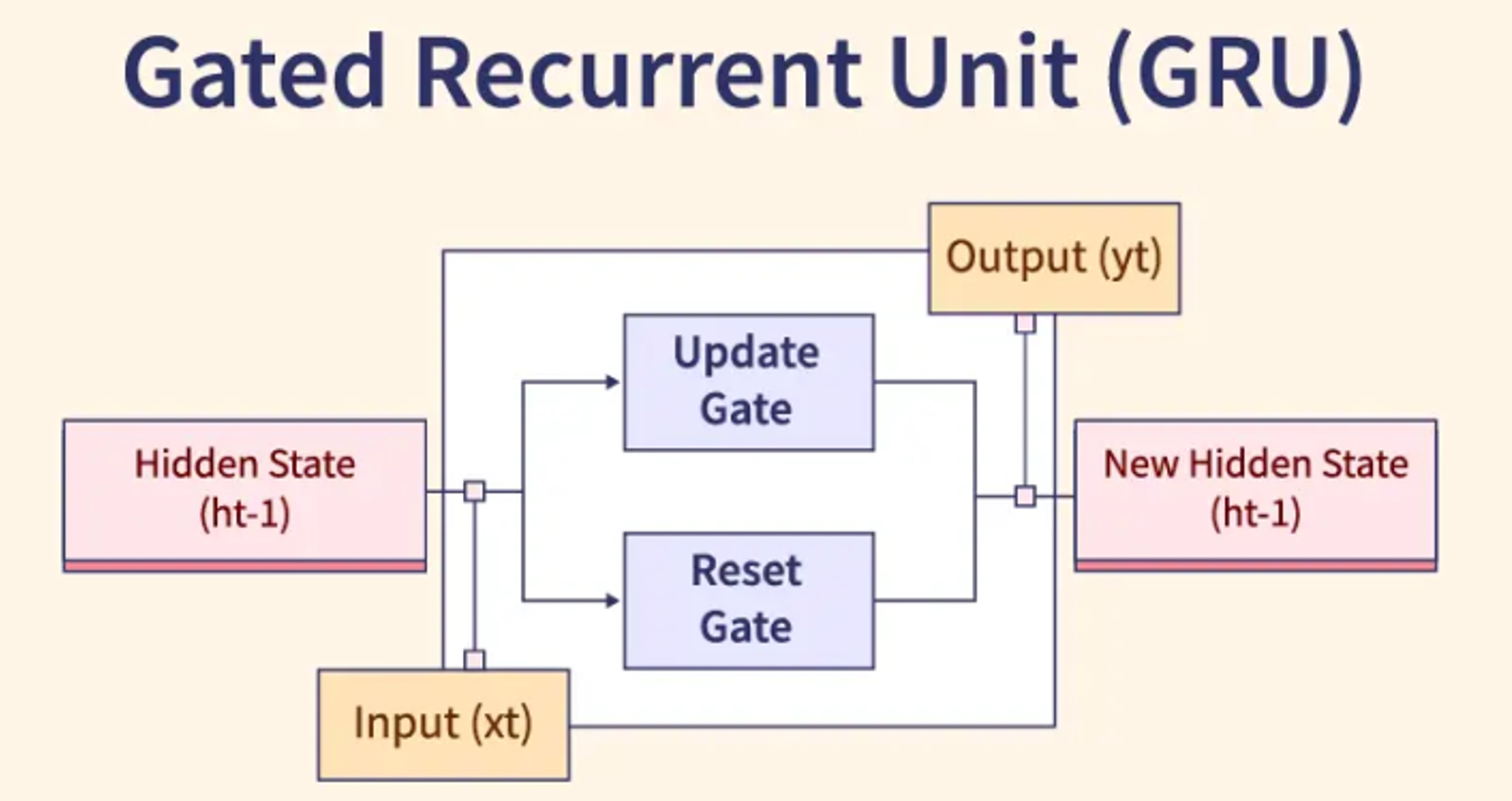
★★★★★
特定架構:循環神經網路 (RNN, Recurrent Neural Network)
架構特點與應用 (參考樣題 Q4)
RNN 專門用於處理序列數據(如文本、時間序列、語音)。其核心特點是具有循環連接,允許資訊在序列的不同時間步之間傳遞和保持(記憶)。
- 標準 RNN 存在梯度消失/爆炸問題,難以處理長序列。
- 常見變體:LSTM (Long Short-Term Memory) 和 GRU (Gated Recurrent Unit) 透過引入門控機制 (Gating Mechanism) 來解決長程依賴問題。
#21
★★★★★
特定架構:Transformer
架構特點與應用
最初為機器翻譯設計,現已成為自然語言處理領域的主流架構,並擴展到圖像、語音等多模態領域。
- 核心機制:自注意力機制 (Self-Attention),允許模型在處理序列時直接權衡序列中所有位置的資訊,捕捉長程依賴關係。
- 並行計算能力強,訓練效率高於傳統 RNN。
- 基於 Transformer 的大型預訓練模型(如 BERT, GPT 系列)在眾多任務上取得了 SOTA (State-of-the-Art) 結果。
#22
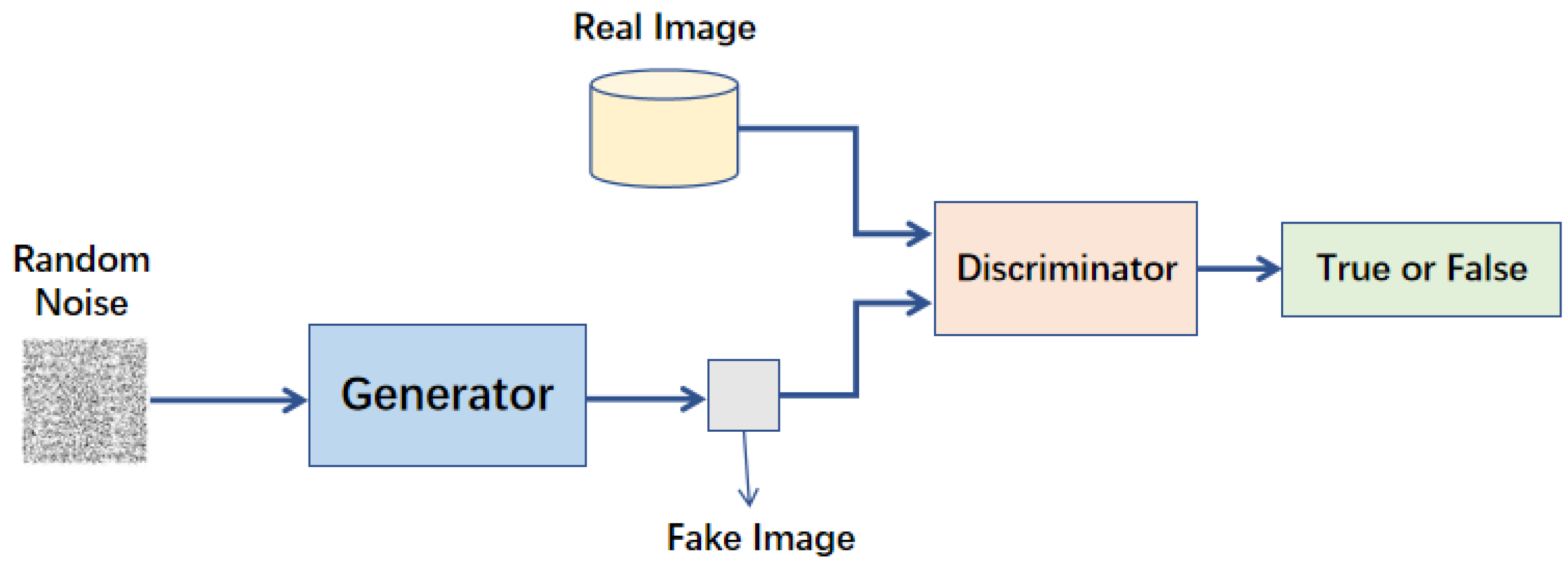
★★★★
特定架構:生成對抗網路 (GAN, Generative Adversarial Network)
架構特點與應用 (參考樣題 Q11)
一種生成模型,由兩個相互競爭的神經網路組成:
- 生成器 (Generator): 學習生成逼近真實數據分佈的假數據(如圖像)。
- 鑑別器 (Discriminator): 學習區分真實數據和生成器產生的假數據。
#23
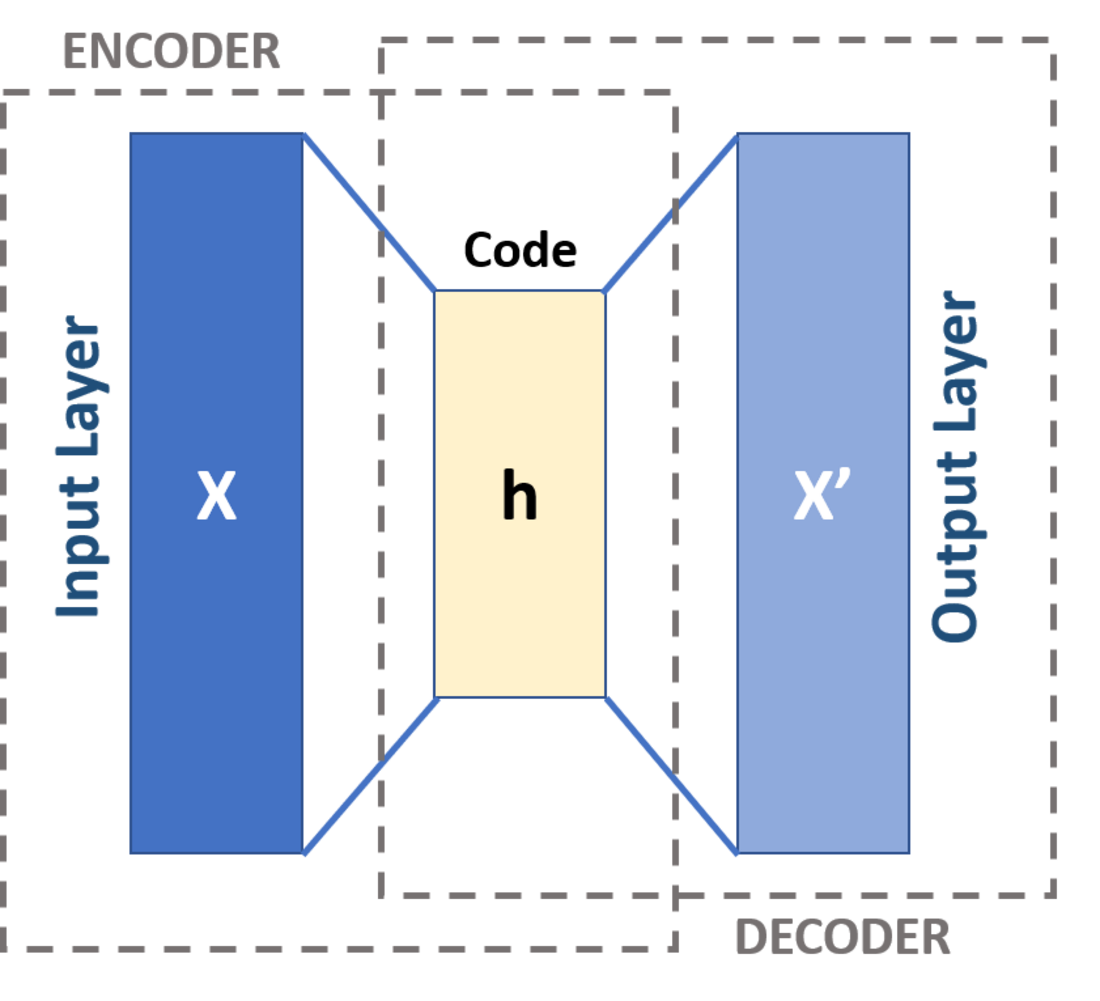
★★★
特定架構:自編碼器 (AE, Autoencoder)
架構特點與應用
一種非監督式神經網路,目標是學習輸入數據的壓縮表示(編碼),然後再從壓縮表示中重構原始輸入(解碼)。
- 由編碼器 (Encoder) 和解碼器 (Decoder) 組成。
- 中間的壓縮表示稱為潛在空間 (Latent Space) 或瓶頸層 (Bottleneck Layer)。
#24
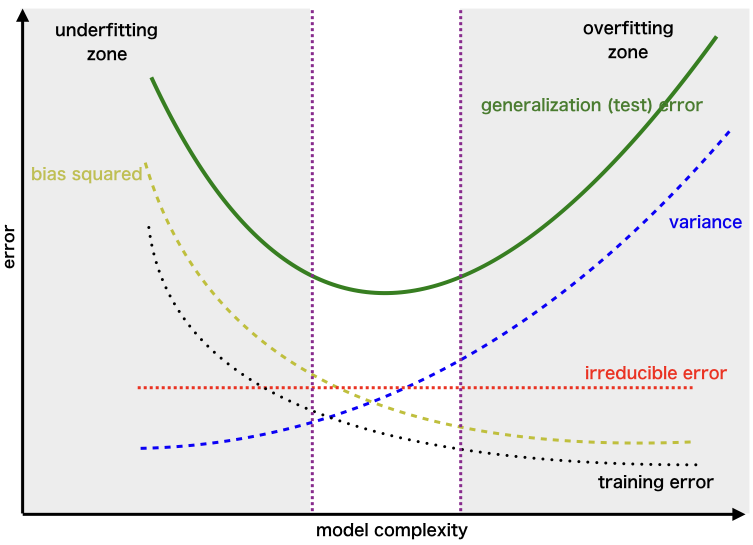
★★★★★
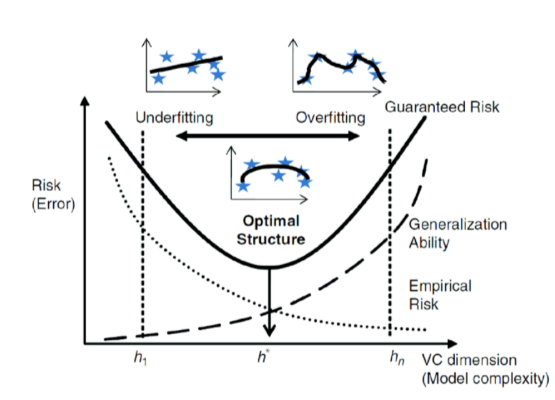
模型複雜度 (Model Complexity) 的概念
核心概念
指模型擬合數據中複雜模式的能力。通常與模型的參數數量、結構(如神經網路的層數和寬度、多項式迴歸的階數)有關。
- 複雜度過高:容易過擬合,學習到噪聲。
- 複雜度過低:容易欠擬合,無法捕捉數據模式。
#25
★★★★★
偏誤-變異數權衡 (Bias-Variance Trade-off)
核心權衡
模型的預期泛化誤差可以分解為偏誤平方、變異數和不可約誤差(數據本身的噪聲)。
- 偏誤 (Bias): 模型預測的平均值與真實值之間的差異(衡量模型的準確性)。高偏誤通常表示欠擬合。
- 變異數 (Variance): 模型預測對於不同訓練數據集的變動程度(衡量模型的穩定性)。高變異數通常表示過擬合。
#26
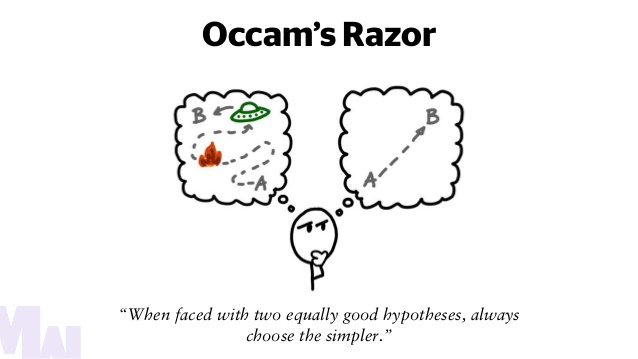
★★★★
奧卡姆剃刀原理 (Occam's Razor) 在模型選擇中的應用
指導原則
奧卡姆剃刀原理 指出「如無必要,勿增實體」(Entities should not be multiplied without necessity)。在模型選擇中,這意味著在性能相近的模型中,應優先選擇結構更簡單的模型。簡單模型通常泛化能力更好、更易於解釋和維護。
#27
★★★
模型容量 (Model Capacity) 的控制方法
控制策略
控制模型容量以避免過擬合的方法包括:
- 選擇更簡單的模型架構(如層數/寬度較少的神經網路)。
- 使用正則化(L1, L2, Dropout)。
- 進行特徵選擇,減少輸入特徵數量。
- 使用參數共享(如 CNN 中的權重共享)。
- 提早停止訓練。
#28
★★★★
自動化機器學習 (AutoML) - 概念與目標 (參考樣題 Q5)
核心概念
AutoML 旨在自動化應用機器學習解決實際問題的端到端流程或其中某些環節。其目標是讓非專家也能使用機器學習,並提高專家構建模型的效率。樣題 Q5 指出 AutoML 是業界部署趨勢。
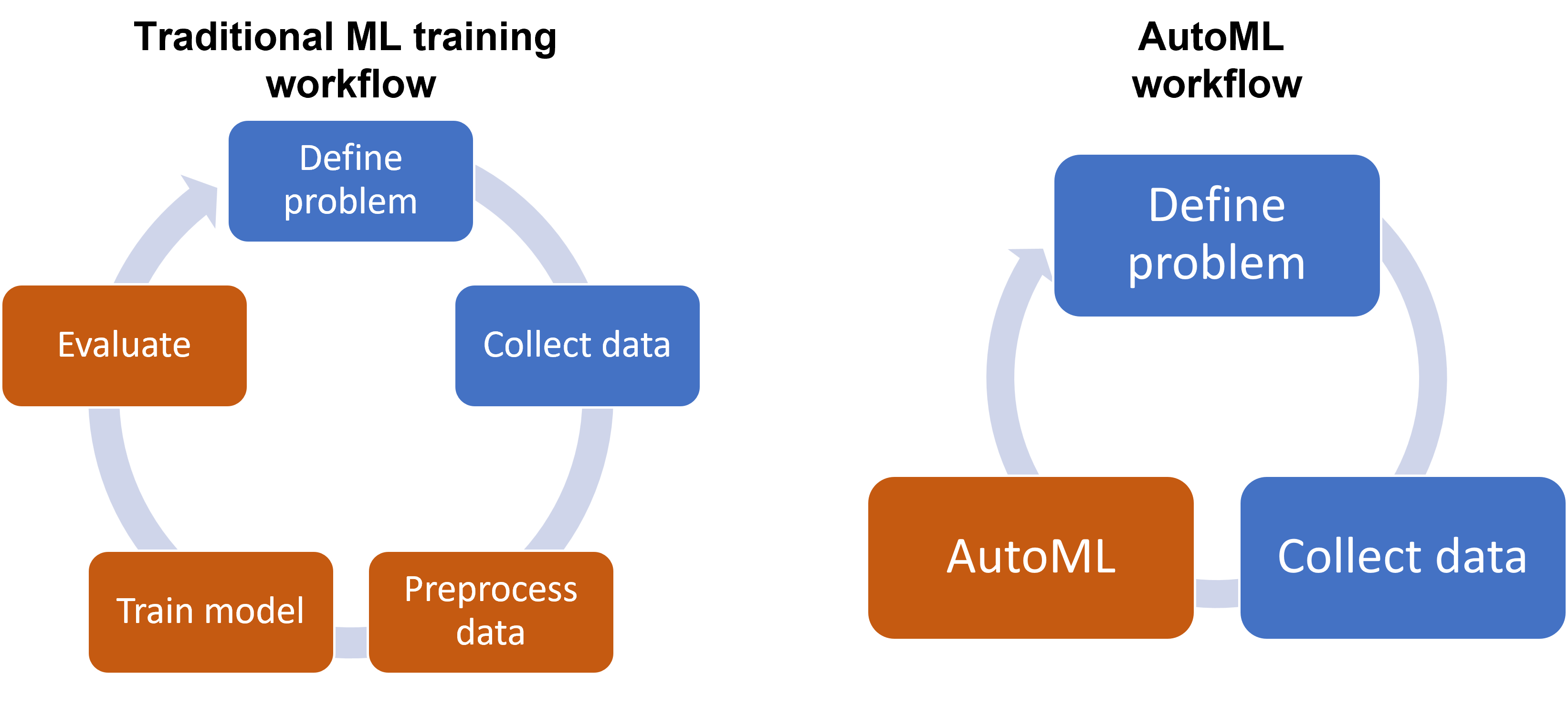
#29
★★★★★
AutoML 的核心技術:神經架構搜尋 (NAS, Neural Architecture Search)
關鍵技術
NAS 是 AutoML 的一個重要子領域,專注於自動設計神經網路的架構(如層類型、連接方式、層數、寬度等)。常用的 NAS 方法包括:
- 基於強化學習 (Reinforcement Learning) 的方法。
- 基於演化演算法 (Evolutionary Algorithms) 的方法。
- 基於梯度的方法(如 DARTS)。
#30
★★★★
AutoML 的核心技術:超參數優化 (HPO, Hyperparameter Optimization)
關鍵技術
AutoML 工具通常內建了自動進行超參數調整的功能。它們會自動探索超參數空間,使用如隨機搜尋、貝氏優化等策略,找到最佳的超參數組合。(參考 L23304)
#31
★★★
AutoML 的應用範圍
應用環節
AutoML 可以涵蓋機器學習流程的多個環節,包括:
- 數據預處理和特徵工程。
- 模型選擇。
- 超參數優化。
- 神經架構搜尋。
- 模型壓縮和部署。
#32
★★★
AutoML 的優缺點
權衡分析
- 優點:提高效率、降低門檻、可能發現意想不到的優良模型/架構、減少人為偏見。
- 缺點:計算成本可能很高、結果可解釋性可能較差、可能需要大量數據、過度擬合搜索空間的風險、可能忽略領域知識的重要性。
#33
★★★★
使用驗證集進行模型選擇
選擇依據
在比較不同的模型(不同演算法、不同架構或不同超參數)時,應使用獨立的驗證集(或透過交叉驗證)來評估它們的性能。選擇在驗證集上表現最好的模型,而不是在訓練集上。這有助於選出泛化能力更強的模型。
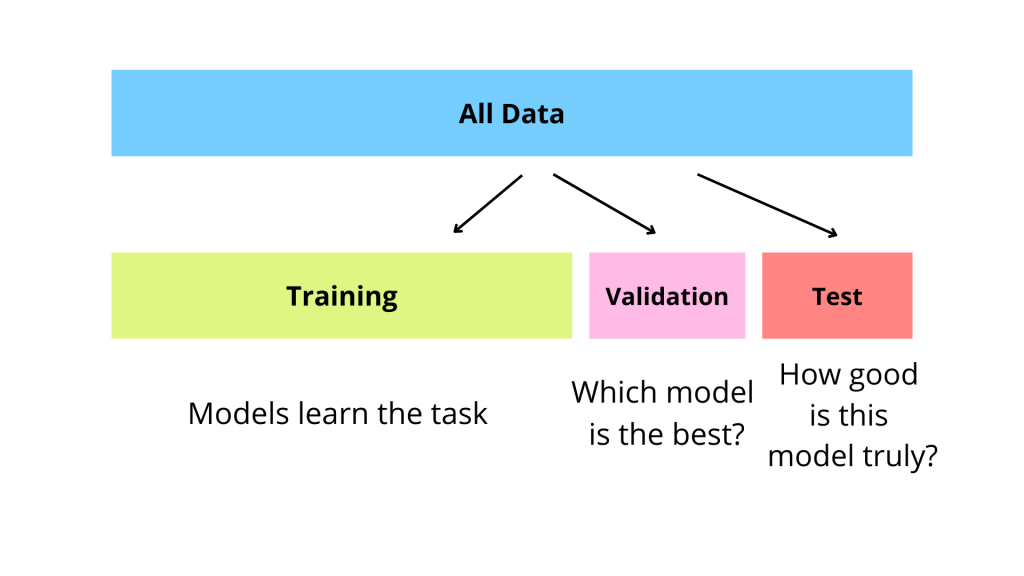
#34
★★★★★
測試集的最終評估角色
最終檢驗
測試集絕對不能用於模型選擇或超參數調整過程。它僅用於在所有選擇和調整完成後,對最終選定的模型進行一次性的性能評估,以獲得對模型在真實世界中表現的無偏估計。這是報告模型最終性能的標準做法。
#35
★★★
模型選擇中的統計顯著性
評估考量
當比較兩個模型在驗證集(或交叉驗證)上的性能差異時,需要考慮這種差異是否具有統計學上的顯著性,而不僅僅是由於數據劃分的隨機性造成的。可以使用統計檢定(如配對 t-檢定)來輔助判斷。
#36
★★★
模型選擇與架構設計工具
常用工具
許多機器學習框架和平台提供了支持模型選擇和架構設計的功能:
- Scikit-learn: 提供多種模型實現和評估工具。
- TensorFlow / Keras, PyTorch: 提供了構建和實驗不同神經網路架構的靈活性。
- AutoML 函式庫/平台: 如 auto-sklearn, TPOT, Google Cloud AutoML, AWS SageMaker, Azure AutoML。
#37
★★★
模型庫 (Model Zoo) 與 預訓練模型 (Pre-trained Models)
實用資源
模型庫 收集了許多針對特定任務(如圖像分類、物體偵測)已經訓練好的模型架構和權重。使用預訓練模型並進行遷移學習 (Transfer Learning) 或微調 (Fine-tuning) 是常見的實踐,可以節省大量訓練時間和數據,並通常能獲得較好的性能。這也是一種模型選擇/架構設計的策略。
#38
★★
架構設計與硬體考量 (CPU/GPU/NPU/TPU)
硬體加速
模型的架構設計應考慮目標部署環境的硬體能力。深度學習模型通常受益於各種加速器的並行計算能力。某些模型或操作在特定硬體上效率更高。
| 處理器類型 | 全名 | 主要特點 | 適用場景 |
|---|---|---|---|
| CPU | 中央處理器 (Central Processing Unit) |
• 通用性強 • 串行處理能力優秀 • 延遲低 |
• 小批量推理 • 複雜邏輯運算 • 序列處理 |
| GPU | 圖形處理器 (Graphics Processing Unit) |
• 大規模並行計算 • 高記憶體頻寬 • 浮點運算強大 |
• 深度學習訓練 • 大批量推理 • 圖像處理 |
| NPU | 神經網路處理器 (Neural Processing Unit) |
• 專為神經網路優化 • 低功耗 • 高能效比 |
• 移動設備推理 • 邊緣計算 • IoT應用 |
| TPU | 張量處理器 (Tensor Processing Unit) |
• 矩陣運算極優 • 專為TensorFlow優化 • 超高能效比 |
• 大規模模型訓練 • 雲端推理服務 • 矩陣計算密集場景 |
#39
★★
無免費午餐定理 (No Free Lunch Theorem)
理論概念
指出沒有任何單一的機器學習演算法能在所有問題上都表現最佳。這強調了根據具體問題和數據進行模型選擇的必要性。
#40
★★
模型假設 (Model Assumptions)
模型基礎
不同的模型基於不同的數學或統計假設(例如,線性迴歸假設線性關係和誤差常態性,樸素貝氏假設特徵獨立性)。理解並驗證這些假設是否符合實際數據,有助於判斷模型的適用性。
#41
★★
模塊化設計 (Modular Design)
設計原則
在設計複雜模型(尤其是深度學習)時,採用模塊化的思想,將模型分解為可重用、可組合的組件(如不同的層、塊),有助於提高開發效率、可維護性和實驗靈活性。
#42
★★
圖神經網路 (GNN, Graph Neural Network)
特定架構
專門用於處理圖結構數據(如社交網路、分子結構、知識圖譜)的深度學習模型。能夠學習節點表示和圖結構中的模式。
#43
★★
模型容量與數據量的關係
關係
通常,更複雜(容量更大)的模型需要更多的訓練數據才能有效學習並避免過擬合。如果數據量有限,選擇容量較小的模型可能更合適。
#44
★★
AutoML 中的搜索空間 (Search Space)
關鍵要素
AutoML 的性能很大程度上取決於定義的搜索空間(即允許自動化工具探索的模型架構、超參數等的範圍)。設計合理的搜索空間是有效應用 AutoML 的關鍵。
#45
★★
模型穩健性 (Robustness) 評估
評估方面
評估模型對輸入數據中的噪聲、擾動或對抗性攻擊的抵抗能力。穩健性是模型在現實世界中可靠運行的重要保證。
#46
★
模型可重現性 (Reproducibility)
實務考量
確保模型訓練和評估的結果能夠被他人或自己在不同時間/環境下重現。需要仔細記錄數據版本、代碼版本、隨機種子、軟硬體環境等。
#47
★
模型組合的可能性
策略
有時最佳方案是組合使用不同類型的模型(例如,使用 CNN 提取圖像特徵,再輸入到 RNN 處理序列信息),以利用各自的優勢。
#48
★
基於規則的系統 (Rule-based Systems)
比較對象
傳統的專家系統或基於規則的系統也是解決某些問題的方法。在模型選擇時,需要評估機器學習模型相對於簡單規則系統的優勢和成本。
#49
★
遷移學習 (Transfer Learning) 中的架構選擇
設計考量
在使用預訓練模型進行遷移學習時,需要決定凍結哪些層的權重,以及如何設計和訓練新的頂層(分類層或迴歸層)以適應目標任務。
#50
★
輕量級模型架構 (Lightweight Architectures)
特定架構
針對移動端或邊緣計算等資源受限環境設計的模型架構,如 MobileNet, SqueezeNet。它們透過深度可分離卷積等技術在保持較好性能的同時顯著減少參數數量和計算量。
#51
★
VC 維度 (Vapnik–Chervonenkis dimension)
理論概念
衡量模型學習能力或複雜度的一種理論指標。雖然在實踐中較少直接計算,但其背後的統計學習理論為理解泛化能力和模型複雜度提供了基礎。
#52
★
AutoML 與 特徵工程 (Feature Engineering)
結合應用
一些 AutoML 工具也嘗試自動化特徵生成、選擇和轉換的過程,進一步減少人工干預。
#53
★
模型校準 (Model Calibration)
評估方面
評估模型的預測機率是否能準確反映真實的可能性。一個校準良好的模型,其預測機率為 0.7 的事件實際發生的頻率也應接近 70%。某些應用(如風險評估)對模型校準度要求較高。

#54
★
領域知識 (Domain Knowledge) 在模型選擇中的作用
重要性
雖然數據驅動很重要,但結合領域專家的知識可以指導模型選擇、特徵工程和結果解釋,有助於構建更有效、更符合實際需求的模型。
#55
★
模型漂移 (Model Drift)
概念
指模型部署後,由於真實世界數據分佈的變化(數據漂移)或目標變數與特徵關係的變化(概念漂移),導致模型性能隨時間下降的現象。模型選擇時需考慮其對漂移的敏感性及監控機制。

#56
★
注意力機制 (Attention Mechanism) 的變體
架構細節
除了基本的自注意力,還有多頭注意力 (Multi-Head Attention)、交叉注意力 (Cross-Attention) 等變體,用於捕捉不同層面或不同來源之間的依賴關係。
#57
★
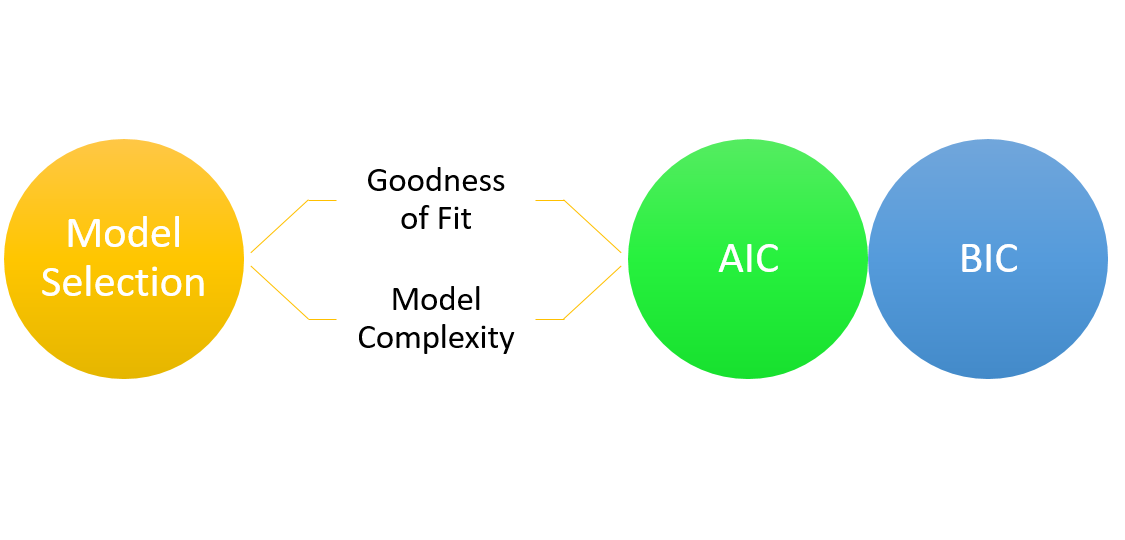
模型選擇的資訊準則 (AIC, BIC)
理論工具
Akaike Information Criterion (AIC) 和 Bayesian Information Criterion (BIC) 是基於資訊理論的模型選擇準則,它們在評估模型擬合度的同時懲罰模型的複雜度(參數數量)。通常選擇 AIC 或 BIC 值較小的模型。
#58
★
離線評估 vs 線上評估
評估階段
離線評估使用歷史數據(驗證集/測試集)評估模型性能;線上評估(如 A/B 測試)則在真實生產環境中評估模型對實際業務指標的影響。兩者都是模型評估的重要環節。
#59
★
模型集成策略的選擇
集成考量
選擇 Bagging、Boosting 還是 Stacking 取決於具體問題。如果基學習器性能差異大,Stacking 可能效果好;如果基學習器易過擬合,Bagging 可能更優;如果基學習器欠擬合,Boosting 可能效果更好。
#60
★★
時間序列模型 (ARIMA, Prophet)
特定模型
除了 RNN/ LSTM,還有傳統的統計時間序列模型如 ARIMA (Autoregressive Integrated Moving Average) 或 Facebook 開發的 Prophet,適用於具有明顯趨勢和季節性的時間序列預測任務。
沒有找到符合條件的重點。
↑