iPAS AI應用規劃師 考試重點
L23301 數據準備與特徵工程
主題分類
1
數據準備概觀與重要性
2
數據清理 (Data Cleaning)
3
數據轉換 (Data Transformation)
4
特徵工程概觀
5
特徵創建 (Feature Creation)
6
特徵提取 (Feature Extraction)
7
特徵選擇 (Feature Selection)
8
實務考量與工具
#1
★★★★★
數據準備 (Data Preparation) - 定義與重要性 (參考 L21301, L23301)
核心概念
數據準備是指在進行機器學習建模之前,對原始數據進行一系列處理和轉換的過程,使其適用於模型訓練。這是機器學習流程中最耗時但至關重要的階段之一,因為數據的品質直接決定了模型的性能上限 (“Garbage In, Garbage Out” - GIGO)。(樣題 Q15 強調數據品質重要性)
#2
★★★★
數據準備的主要任務
核心任務
數據準備通常包含以下主要任務:
- 數據清理 (Data Cleaning): 處理缺失值、異常值、噪聲、不一致等問題。
- 數據轉換 (Data Transformation): 如特徵縮放、離散化、編碼等。
- 數據整合 (Data Integration): 合併來自不同來源的數據。
- 數據歸約 (Data Reduction): 減少數據量或維度(如特徵選擇、降維、抽樣)。
#3
★★★★
探索性數據分析 (EDA, Exploratory Data Analysis)
基礎步驟
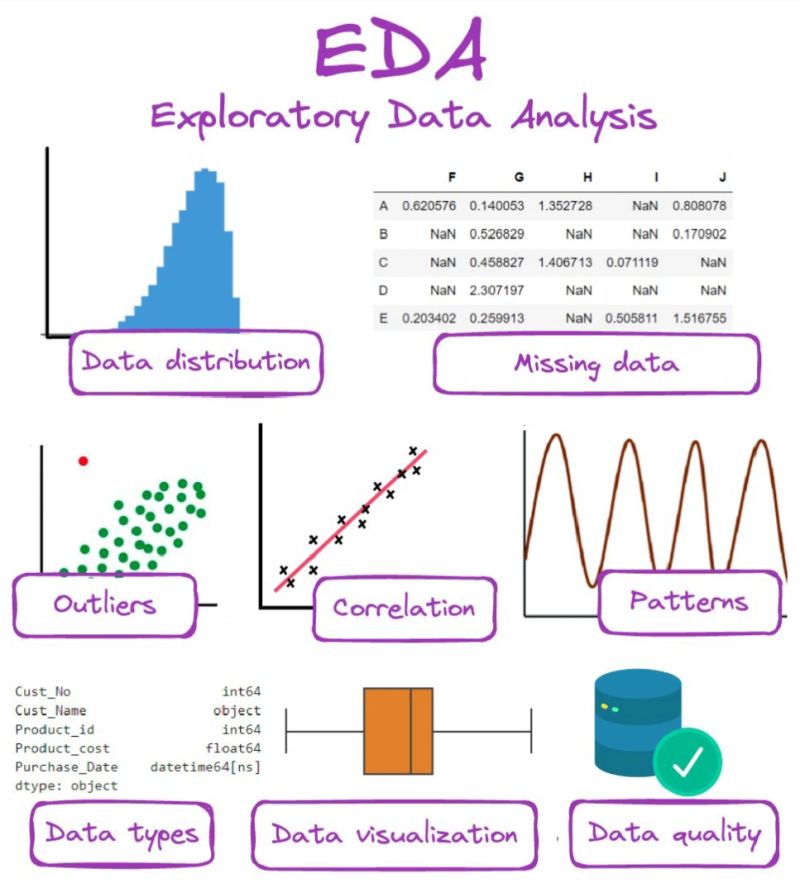
在進行正式的數據準備和建模之前,通常需要進行 EDA。使用描述性統計和數據可視化方法來初步理解數據的特性、分佈、關係和潛在問題(如缺失值、異常值)。EDA 的結果可以指導後續的數據準備策略。(參考 L11202, L22101, L22303)
#4
★★★★★
數據清理:處理缺失值 (Missing Values)
常見策略
處理數據中缺失值的方法:
- 刪除 (Deletion): 刪除含有缺失值的樣本(列表刪除)或特徵(如果該特徵缺失比例過高)。簡單但可能損失訊息。
- 填充 (Imputation): 使用某種策略填充缺失值。
- 數值型:使用平均數 (Mean)、中位數 (Median) 填充。
- 類別型:使用眾數 (Mode) 填充。
- 進階方法:使用迴歸、KNN 等模型預測填充值。
#5
★★★★
數據清理:處理離群值/異常值 (Outliers/Anomalies)
常見策略
離群值是與數據集中大多數點顯著不同的數據點。處理方法:
- 識別:使用統計方法(如標準差法、箱形圖 IQR 法)或模型(如分群、孤立森林)來檢測離群值。
- 處理:
- 刪除:如果確定是錯誤數據。
- 轉換 (Transformation): 如對數轉換,可能減小離群值的影響。
- 蓋帽 (Capping/Winsorization): 將超過特定閾值的極端值替換為閾值。
- 視為特殊值:如果離群值本身有意義。
#6
★★★
數據清理:處理噪聲數據 (Noisy Data)
常見策略
噪聲是指數據中的隨機錯誤或不準確性。處理方法:
- 分箱 (Binning): 將連續數據分組到區間中,用區間均值或中位數平滑。
- 迴歸 (Regression): 使用迴歸模型擬合數據以平滑噪聲。
- 聚類 (Clustering): 檢測並移除不屬於任何簇的離群點(可能視為噪聲)。

#7
★★★
數據清理:處理不一致數據 (Inconsistent Data)
常見問題與策略
指數據中存在矛盾或格式不統一的情況。例如,同一個實體有不同的名稱拼寫、日期格式不一致、數值單位不同等。
處理策略:
處理策略:
- 數據標準化:統一格式、單位、命名約定。
- 利用元數據或業務規則進行驗證和修正。
- 數據去重 (Deduplication)。
#8
★★★★★
數據轉換:特徵縮放 (Feature Scaling) 的目的
核心目的
將不同範圍或單位的數值特徵轉換到相似的尺度上。這對於許多機器學習演算法是非常重要甚至必需的,原因包括:
- 避免數值範圍大的特徵主導基於距離的計算(如 KNN, K-Means, SVM)或梯度下降的優化過程。
- 加速梯度下降的收斂速度。
- 提高某些模型的性能。
#9
★★★★
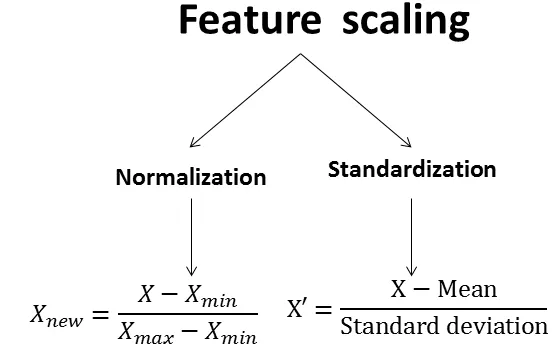
特徵縮放方法:標準化 (Standardization / Z-score Normalization)
縮放技術
將數據轉換為平均值為 0,標準差為 1 的分佈。
公式:z = (x - μ) / σ (μ 是平均值,σ 是標準差)
適用於數據大致符合常態分佈,或演算法假設數據中心化的情況。不受數據範圍限制。
公式:z = (x - μ) / σ (μ 是平均值,σ 是標準差)
適用於數據大致符合常態分佈,或演算法假設數據中心化的情況。不受數據範圍限制。
#10
★★★★
特徵縮放方法:正規化 (Normalization / Min-Max Scaling)
縮放技術
將數據線性地縮放到一個固定的範圍,通常是 [0, 1] 或 [-1, 1]。
公式 (縮放到 [0, 1]):x_scaled = (x - min) / (max - min)
適用於需要將數據限制在特定範圍內(如圖像像素值)或算法對數據範圍敏感的情況。對離群值比較敏感。
公式 (縮放到 [0, 1]):x_scaled = (x - min) / (max - min)
適用於需要將數據限制在特定範圍內(如圖像像素值)或算法對數據範圍敏感的情況。對離群值比較敏感。
#11
★★★
數據轉換:類別特徵編碼 (Categorical Feature Encoding)
轉換技術
將非數值的類別特徵轉換為模型可以處理的數值表示。
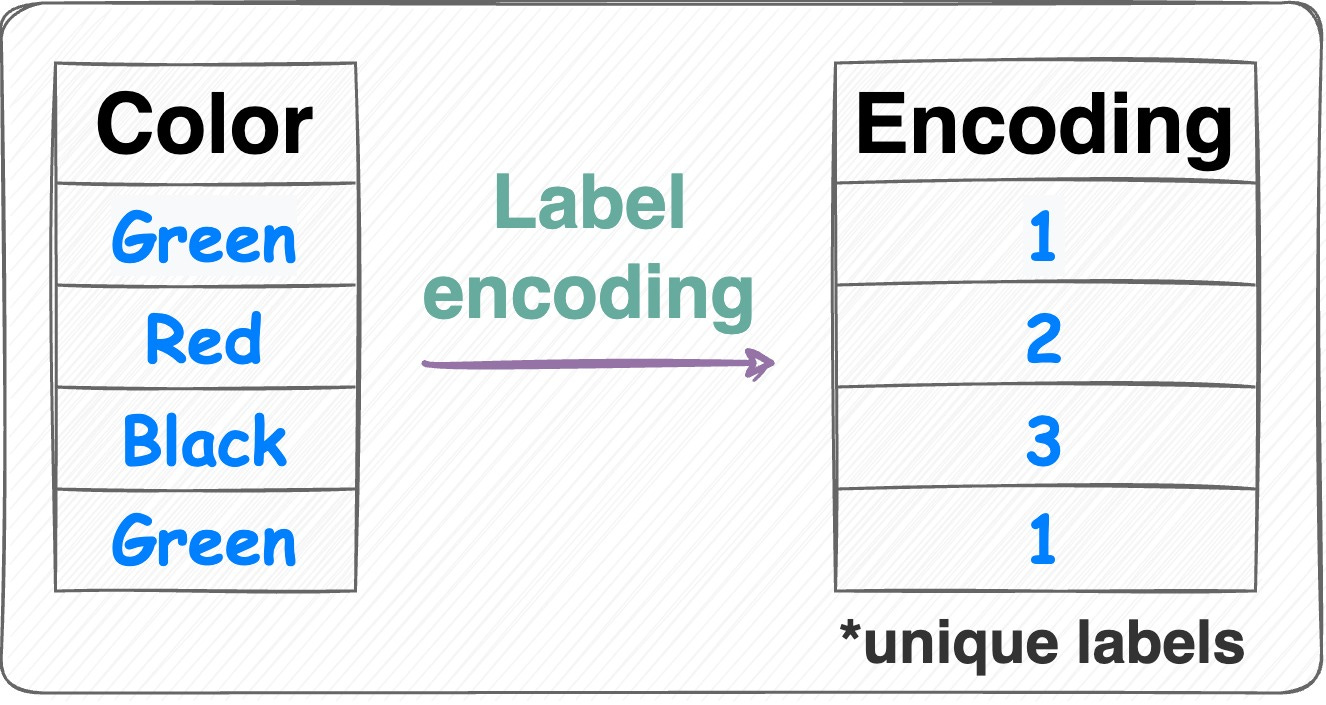
- 標籤編碼 (Label Encoding): 將類別映射為整數 (0, 1, 2...)。適用於有序類別,或某些樹模型。
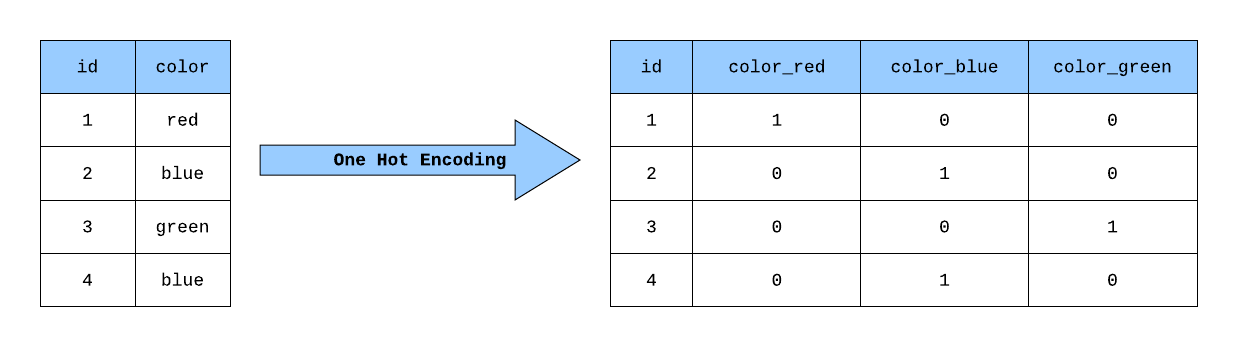
- 獨熱編碼 (One-Hot Encoding): 為每個類別創建新的二元特徵。適用於無序類別,但會增加維度。
 >
>
#12
★★
數據轉換:離散化/分箱 (Discretization/Binning)
轉換技術
將連續的數值特徵轉換為離散的區間(箱子)。例如,將年齡分為「青年」、「中年」、「老年」等區間。
- 原因:某些模型(如決策樹的某些變體)更擅長處理離散特徵;可以處理非線性關係;降低噪聲影響。
- 方法:等寬分箱、等頻分箱等。
#13
★★
數據轉換:處理偏態分佈 (Skewed Distribution)
轉換技術
對於高度偏斜(非對稱)的數據分佈,某些模型(尤其是假設常態性的模型)可能表現不佳。可以使用數學轉換來使其更接近對稱或常態分佈,例如:
- 對數轉換 (Log Transform): 對於右偏(正偏)數據常用。
- 平方根轉換 (Square Root Transform)。
- Box-Cox 轉換。
#14
★★★★★
特徵工程 (Feature Engineering) - 定義與目標 (參考樣題 Q8)
核心概念
特徵工程是利用領域知識和數據洞察,對原始數據進行處理,以創建、提取或選擇最能代表底層問題並提升機器學習模型性能的特徵的過程。其目標是將數據轉換為更適合模型學習的形式。樣題 Q8 直接考查 Feature Engineering 的組成。
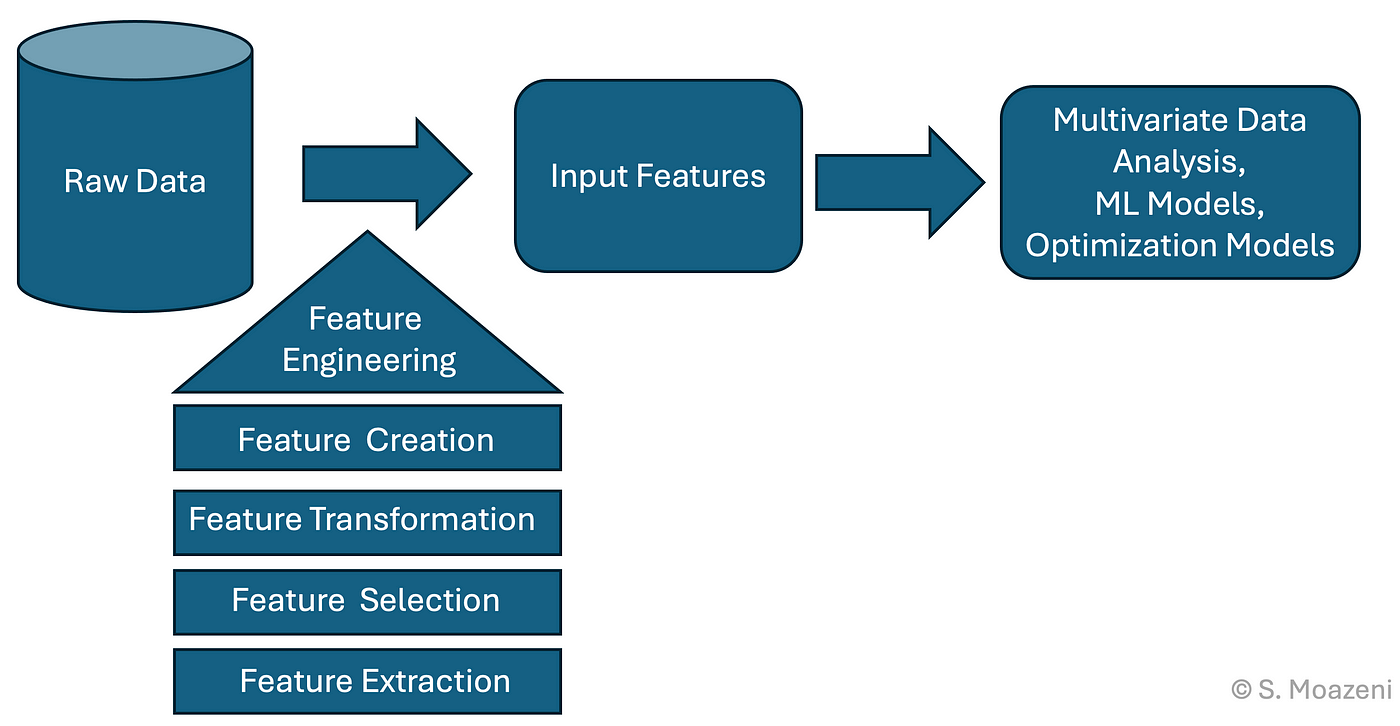
#15
★★★★
特徵工程與數據準備的關係
關係說明
兩者密切相關且常有重疊。數據準備更側重於清理和格式化數據使其可用,而特徵工程則更側重於創造性地構建和選擇能夠最大化模型預測能力的特徵。許多數據轉換技術(如編碼、縮放)既是數據準備也是特徵工程的一部分。
#16
★★★★
領域知識 (Domain Knowledge) 在特徵工程中的作用
重要性
對業務問題或應用領域的深入理解對於進行有效的特徵工程至關重要。領域知識可以幫助:
- 識別哪些原始數據可能包含有價值的信號。
- 創建具有實際意義的新特徵(例如,計算用戶的平均購買間隔)。
- 判斷哪些特徵是相關的,哪些是冗餘或無關的。
- 解釋模型的結果。
#17
★★★
特徵工程的迭代性
流程特性
特徵工程通常不是一次性的過程,而是一個迭代的循環。分析師可能會嘗試創建不同的特徵集,訓練模型,評估結果,然後根據模型的表現回頭改進或重新設計特徵,直到達到滿意的性能。
#18
★★★★
特徵創建 (Feature Creation) - 交互項與多項式特徵
常用技術
- 交互項 (Interaction Terms): 將兩個或多個原始特徵相乘,以捕捉它們之間的交互效應(例如,廣告支出與季節性因素的交互)。
- 多項式特徵 (Polynomial Features): 創建原始特徵的高次方項(如平方、立方)及其交互項,用於捕捉非線性關係。
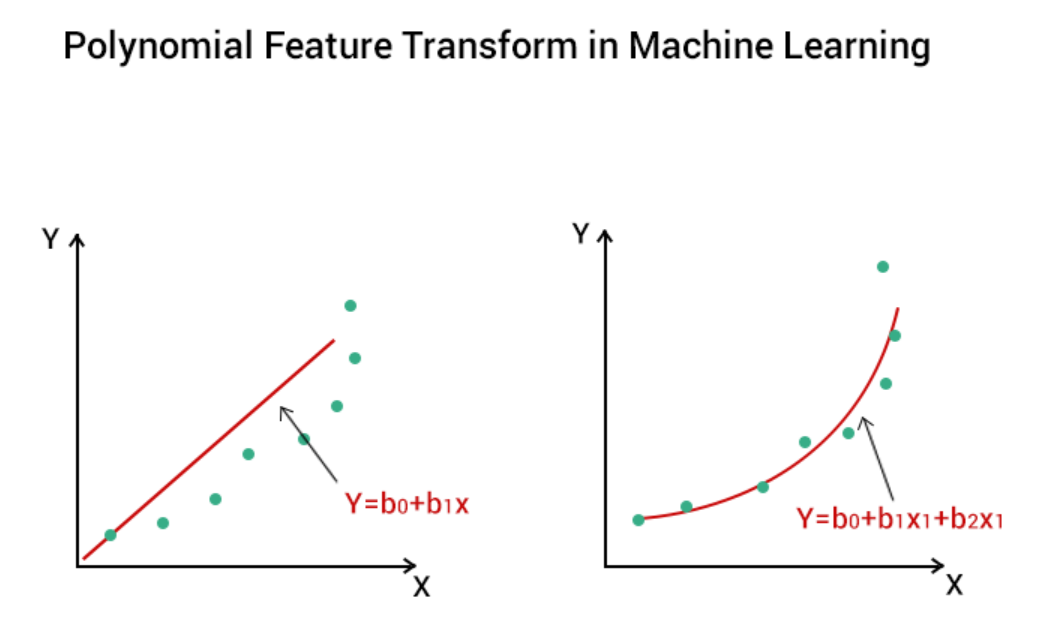
#19
★★★
特徵創建 - 基於時間的特徵
常用技術
如果數據包含時間戳訊息,可以創建許多有用的特徵:
- 提取年、月、日、星期幾、小時等時間單位。
- 計算時間差(例如,距離上次購買的天數)。
- 創建滯後特徵 (Lag Features)(使用過去時間點的值)。
- 計算滾動窗口統計量(如過去 7 天的平均銷售額)。
#20
★★★
特徵創建 - 基於分組的特徵
常用技術
根據某個類別變數(如用戶 ID、產品類別)對數據進行分組,然後計算每個組內的聚合統計量(如平均值、總和、計數、標準差)作為新的特徵。例如,計算每個用戶的平均訂單金額。
#21
★★★★
特徵提取 (Feature Extraction) - 目標 (參考樣題 Q8)
核心目標
從原始數據中自動生成一組新的、維度更低且更具訊息量的特徵。通常用於高維數據(如圖像、文本)或當原始特徵難以直接使用時。樣題 Q8 包含萃取(提取)。
#22
★★★★
主成分分析 (PCA, Principal Component Analysis) 作為特徵提取
降維技術 (參考樣題 Q10)
PCA (Principal Component Analysis) 將原始特徵線性組合成一組新的、不相關的主成分特徵,這些主成分按其解釋的數據變異量大小排序。可以選擇前 k 個主成分作為新的低維特徵。
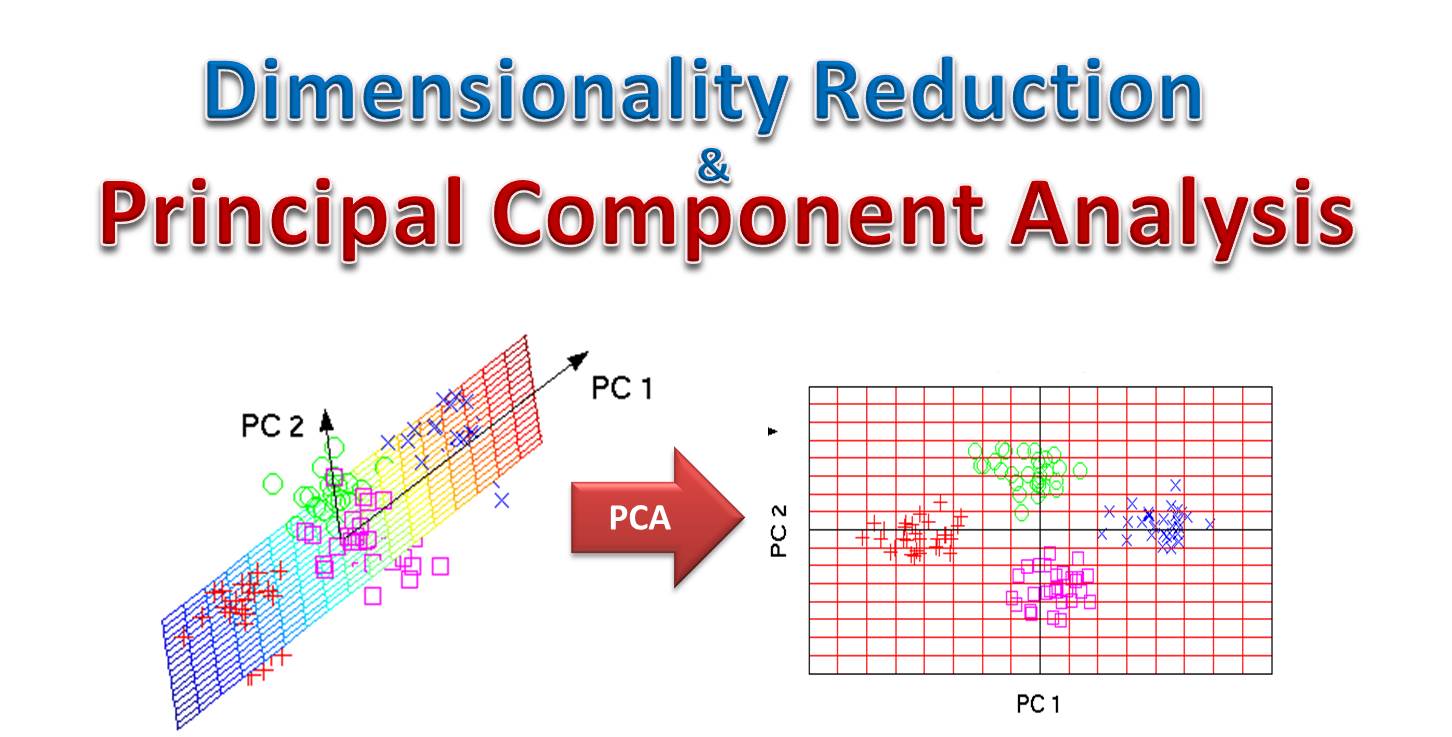 >
>
#23
★★★
文本特徵提取: TF-IDF
文本技術
Term Frequency-Inverse Document Frequency (TF-IDF) 是一種常用的文本特徵提取方法。它計算一個詞語在單個文檔中的頻率 (TF) 和該詞語在整個文檔集合中的逆文檔頻率 (IDF),兩者相乘以評估一個詞語對於一個文檔的重要性。
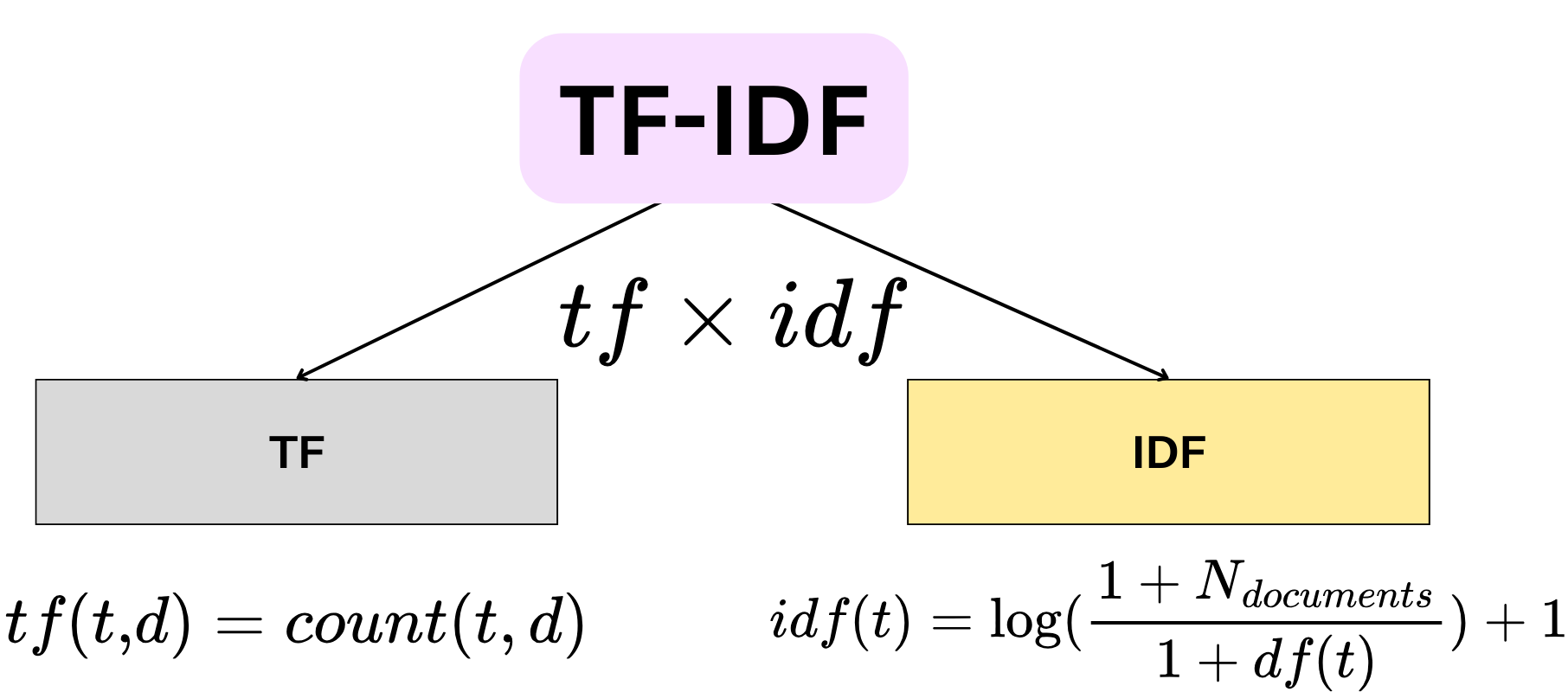 >
>
#24
★★★★
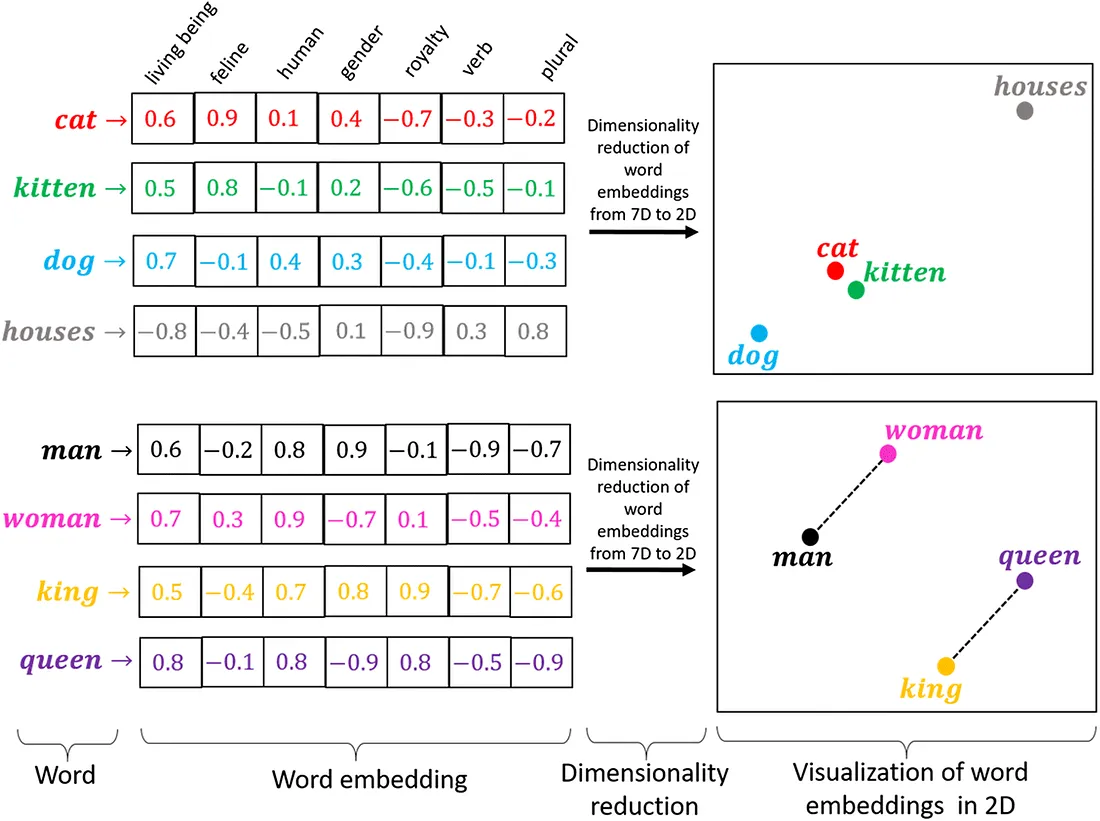
詞嵌入 (Word Embeddings) - Word2Vec, GloVe
文本技術
詞嵌入是將單詞映射到低維、稠密的實數向量的技術。這些向量能夠捕捉單詞之間的語義關係(例如,相似的詞向量也相近)。Word2Vec 和 GloVe 是常用的詞嵌入模型。
#25
★★★★
深度學習用於特徵提取 (參考樣題 Q10)
自動提取
深度學習模型(尤其是 CNN 對圖像,RNN/Transformer 對文本)的中間隱藏層可以被視為自動學習到的特徵提取器。這些層次化的特徵表示通常比手動設計的特徵更有效。可以利用預訓練模型提取通用特徵。樣題 Q10 強調此優點。
#26
★★★★★
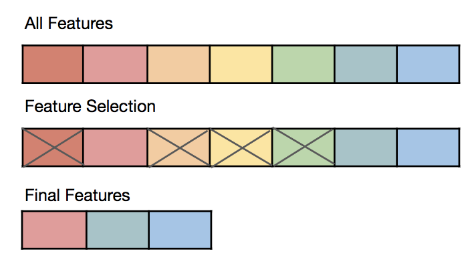
特徵選擇 (Feature Selection) - 目標 (參考樣題 Q8)
核心目標
從原始特徵集中選出一個與目標變數最相關的子集,同時去除冗餘或不相關的特徵。目標是:
- 提高模型泛化能力(減少過擬合)。
- 降低模型複雜度和訓練時間。
- 提高模型可解釋性。
- 避免維度災難。
#27
★★★★
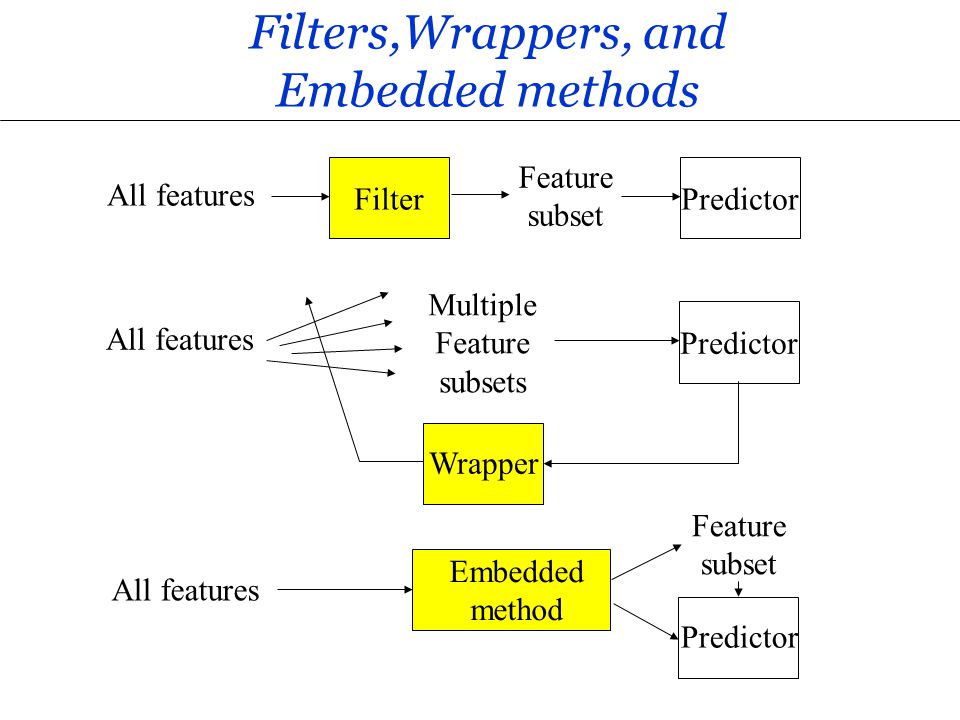
特徵選擇方法:過濾法 (Filter Methods)
方法類型
過濾法在模型訓練之前進行特徵選擇,獨立於任何特定的學習算法。它根據特徵本身的統計特性(如變異數、與目標變數的相關係數、卡方檢定、互訊息等)對特徵進行評分和排序,然後選擇得分最高的特徵。優點是計算速度快。
#28
★★★★
特徵選擇方法:包裹法 (Wrapper Methods)
方法類型
包裹法將特徵選擇過程「包裹」在一個特定的機器學習模型周圍。它嘗試不同的特徵子集,使用該模型評估每個子集的性能(通常透過交叉驗證),然後選擇性能最佳的子集。例如:
- 遞迴特徵消除 (RFE, Recursive Feature Elimination)。
- 前向選擇 (Forward Selection)。
- 後向消除 (Backward Elimination)。
#29
★★★★
特徵選擇方法:嵌入法 (Embedded Methods)
方法類型
嵌入法將特徵選擇過程嵌入到模型訓練過程本身。模型在訓練時會自動學習哪些特徵是重要的。例如:
- L1 正則化 (Lasso): 會將不重要特徵的係數縮減為零。
- 基於樹的模型(如隨機森林、GBDT)可以提供特徵重要性 (Feature Importance) 評分。
#30
★★★
特徵重要性 (Feature Importance)
評估指標
某些模型(特別是樹模型和嵌入法)可以提供每個特徵對模型預測結果的貢獻程度的評分。可以用於理解模型、進行特徵選擇或向業務方解釋。
#31
★★★★
數據準備與特徵工程的工具 (Python)
常用函式庫
在 Python 生態系中:
-
Pandas: 核心數據處理與操作庫,提供 DataFrame。
-
NumPy: 基礎數值計算庫,提供陣列操作。
-
Scikit-learn: 提供了大量的數據預處理(缺失值填充、縮放、編碼)、特徵提取(PCA)和特徵選擇(RFE, 基於模型的選擇)的功能。
#32
★★★
數據準備與特徵工程的工具 (大數據)
大數據工具
處理大規模數據時,常使用分散式計算框架:
- Apache Spark: 其 MLlib 函式庫提供了可擴展的數據處理和特徵工程功能(如 TF-IDF, Word2Vec, PCA, Scaling, OneHotEncoder 等)。

#33
★★
自動化特徵工程 (Automated Feature Engineering)
AutoML 相關
一些 AutoML 工具嘗試自動化特徵創建、轉換和選擇的過程,以減少人工工作量並可能發現意想不到的有效特徵。例如 Featuretools 函式庫。
#34
★★★
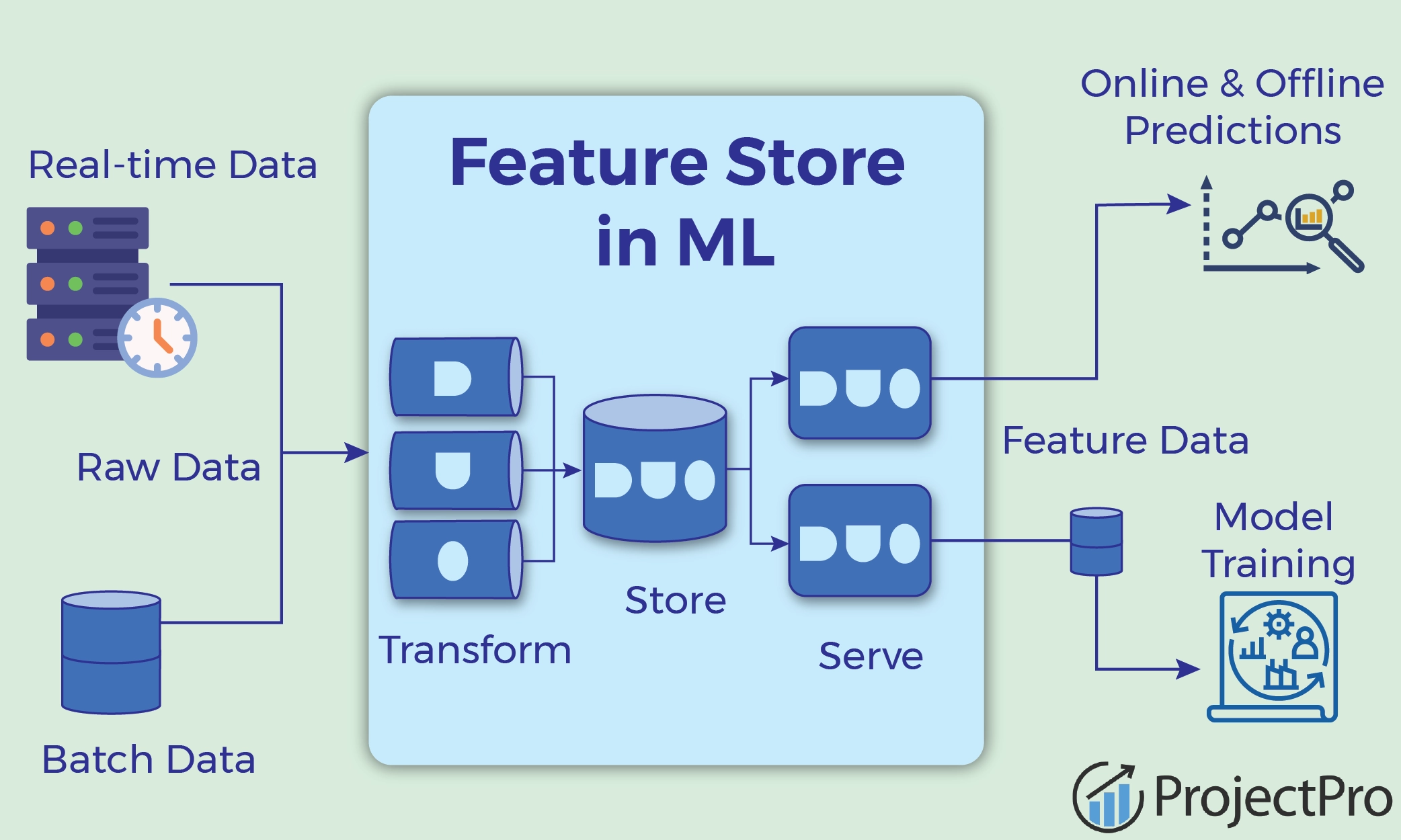
特徵儲存 (Feature Store)
MLOps 組件
一個集中管理、儲存、發現和共享機器學習特徵的平台。有助於確保特徵的一致性(訓練和推論時使用相同邏ย輯)、重用性和協作。
#35
★★
數據準備的目標:適用性
目標
確保數據格式符合所選機器學習演算法的輸入要求(例如,數值輸入、無缺失值)。
#36
★★
數據類型轉換
數據清理
確保數據欄位的數據類型(如整數、浮點數、字串、日期時間)是正確的,並進行必要的轉換。
#37
★★
特徵縮放對不同模型的影響
影響分析
- 受影響大:基於距離的模型 (KNN, K-Means, SVM)、使用梯度下降的模型(線性模型、神經網路)、PCA。
- 影響小/無影響:基於樹的模型(決策樹、隨機森林、GBDT)。
#38
★★
好的特徵的特性
特性
一個好的特徵應該是:相關的(與目標變數有關)、可用的(在預測時能夠獲取)、訊息豐富的、易於理解的(有助於解釋)、且數量適中(避免冗餘和維度災難)。
#39
★★
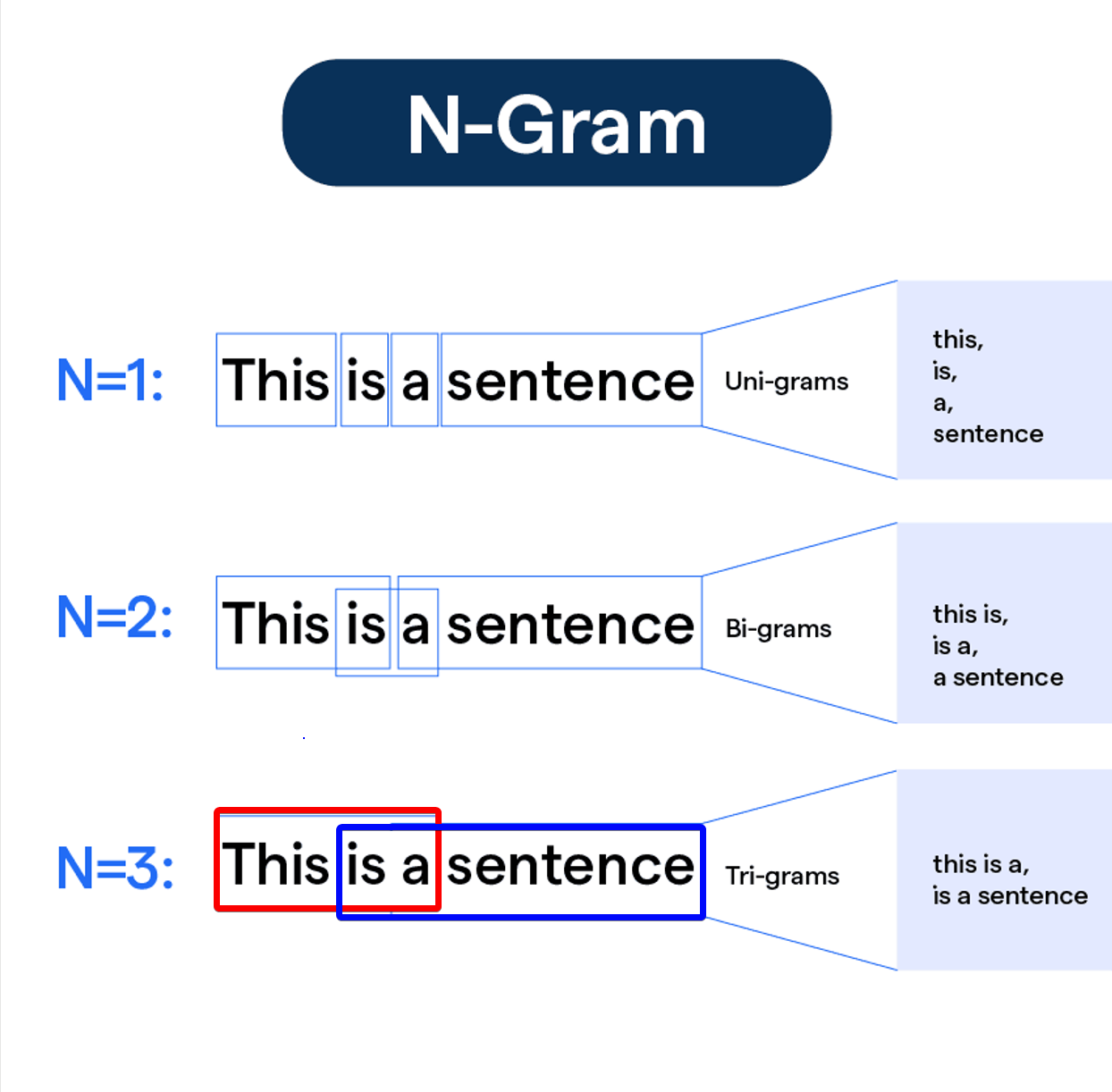
文本數據的特徵創建 (N-grams)
文本技術
N-grams 是文本中連續 N 個詞語的序列。除了單個詞語(unigrams),使用 bigrams(兩個詞)或 trigrams(三個詞)作為特徵可以捕捉一些局部詞序訊息。
#40
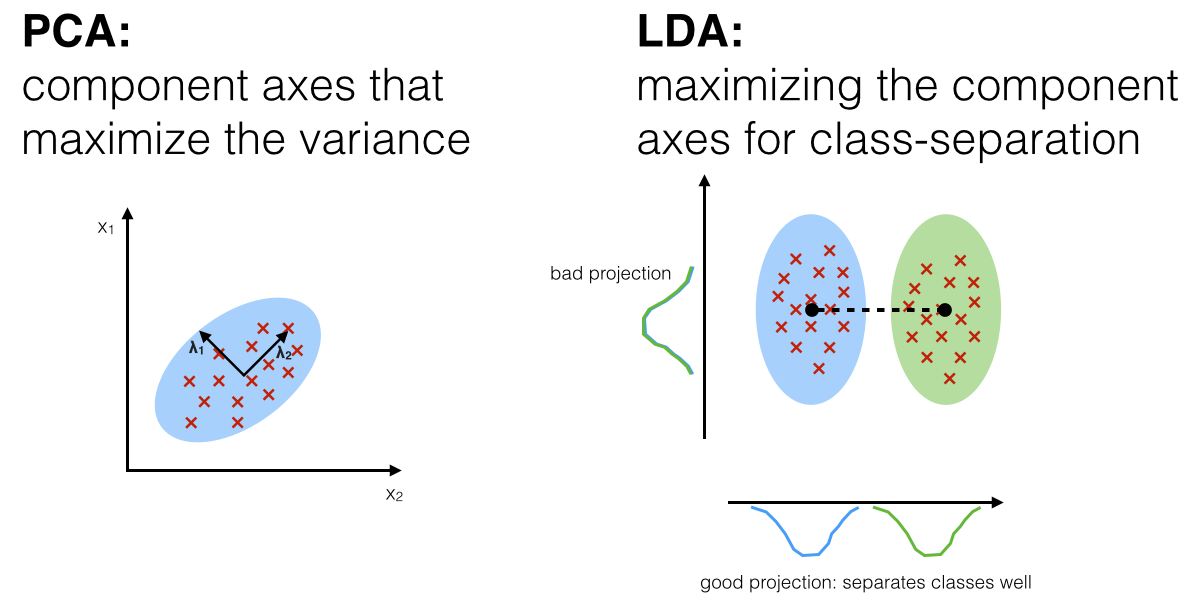
★
線性判別分析 (LDA) 作為特徵提取
降維技術
Linear Discriminant Analysis (LDA) 是一種監督式降維(特徵提取)方法。它尋找能夠最大化類間距離、最小化類內距離的投影方向。與 PCA(非監督)不同,LDA 利用了類別標籤訊息。
#41
★
特徵選擇與模型穩定性
影響
去除不穩定或噪聲較大的特徵有助於提高模型的穩定性和泛化能力。
#42
★
數據管道 (Data Pipeline)
流程自動化
將數據準備和特徵工程的多個步驟串聯起來,形成自動化的數據處理管道。有助於提高效率、確保一致性、方便重用。Scikit-learn 的
Pipeline 是常用工具。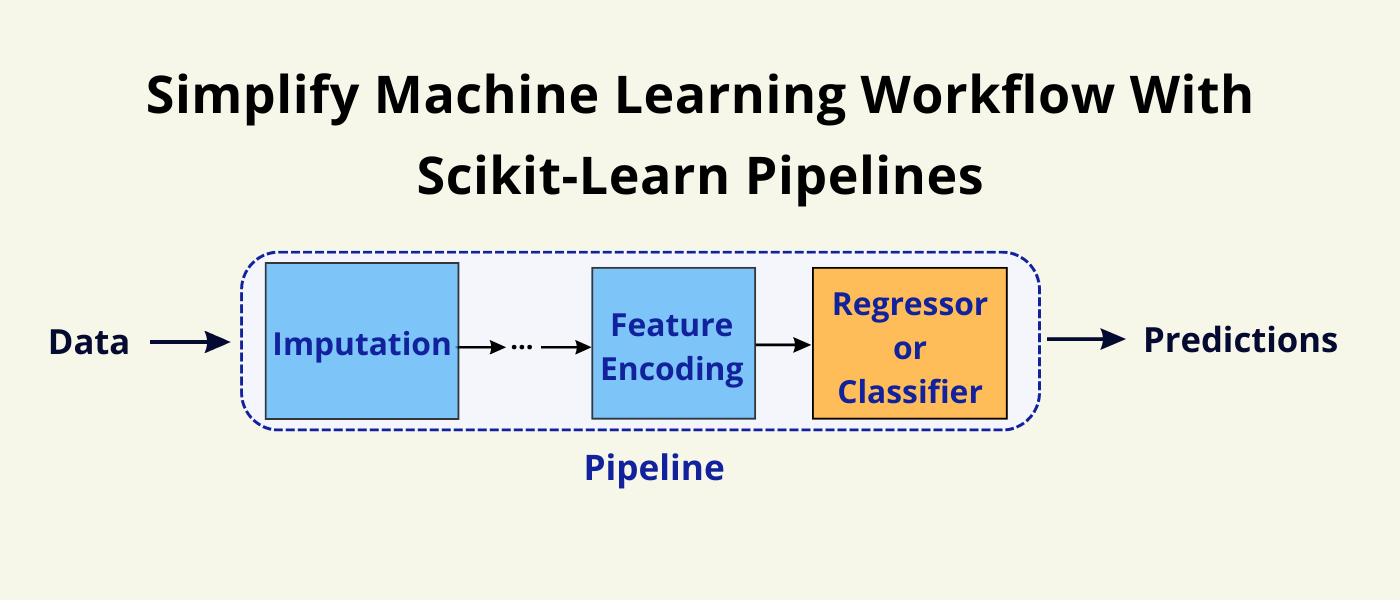
#43
★
數據驗證 (Data Validation)
數據準備
在數據準備過程中,需要驗證數據是否符合預期的格式、範圍、約束條件等。可以使用斷言、模式檢查、統計測試等方法。
#44
★
插補 (Imputation) 方法的選擇
方法比較
簡單的均值/中位數/眾數插補速度快但可能引入偏差;基於模型的插補(如迴歸插補)更準確但計算成本高。需權衡。
#45
★
離散化對資訊損失的影響
轉換考量
將連續變數離散化會損失一部分原始數據的精度和訊息。需要在簡化模型和保留訊息之間取得平衡。
#46
★
特徵工程的 "黑暗藝術"
特性
特徵工程常被認為帶有一定的經驗性和創造性,需要結合領域知識、數據直覺和反覆試驗,沒有固定的最佳方法。
#47
★
針對特定模型的特徵創建
策略
某些特徵可能對特定模型類型更有效。例如,樹模型能自動處理特徵交互,而線性模型可能需要手動創建交互項。
#48
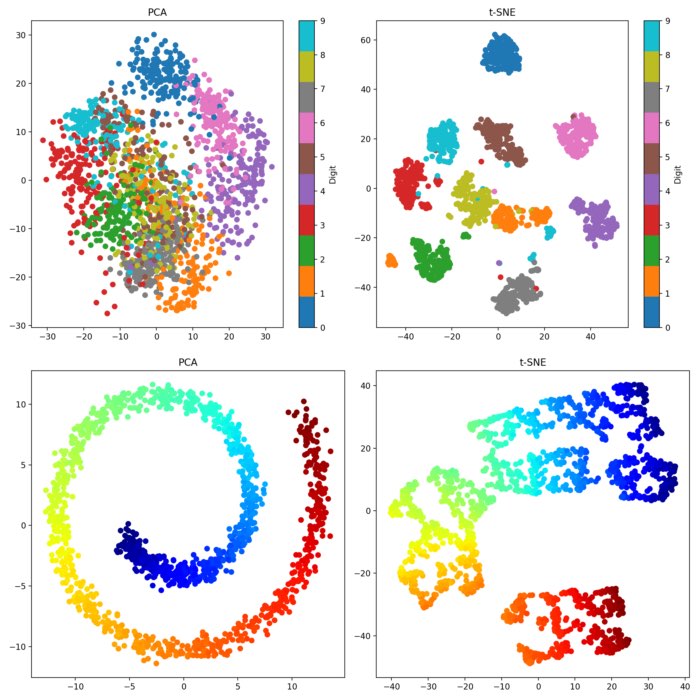
★
非線性降維 (t-SNE, UMAP)
降維技術
除了線性的 PCA,還有非線性降維技術如 t-SNE (t-distributed Stochastic Neighbor Embedding) 和 UMAP (Uniform Manifold Approximation and Projection),主要用於高維數據的視覺化,保留局部結構。
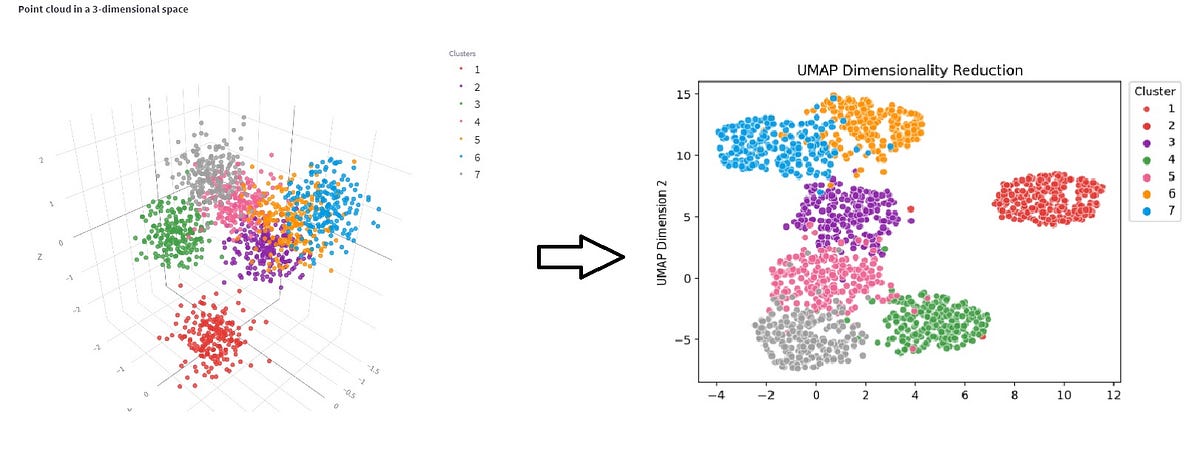
#49
★
共線性 (Collinearity) 對特徵選擇的影響
影響
特徵之間的高度相關性(共線性)可能使得基於模型的特徵重要性評估不穩定。某些特徵選擇方法(如 Lasso)有助於處理共線性。
#50
★
數據準備在 MLOps 中的位置
流程整合
在 MLOps 流程中,數據準備和特徵工程的步驟需要被版本化、自動化和監控,以確保訓練和推論過程的一致性和可重現性。
#51
★
數據生命週期
概念
數據從產生、收集、儲存、處理、分析、使用到最終銷毀的整個過程。數據準備是其中的關鍵環節。
#52
★
數據驗證工具
工具
如 Great Expectations, Pandera 等 Python 庫可以用於定義數據驗證規則並自動檢查數據品質。
#53
★
目標編碼 (Target Encoding)
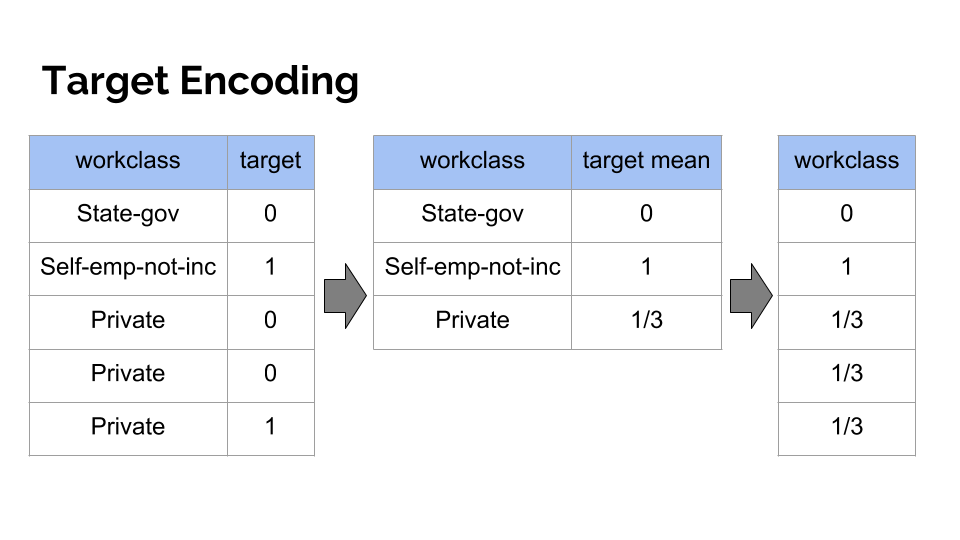
類別編碼
一種將類別特徵替換為其對應目標變數的(平滑化)平均值的編碼方法。可能捕捉更多訊息,但容易導致過擬合或數據洩漏,需謹慎使用(通常配合交叉驗證)。
#54
★
特徵交叉 (Feature Crossing)
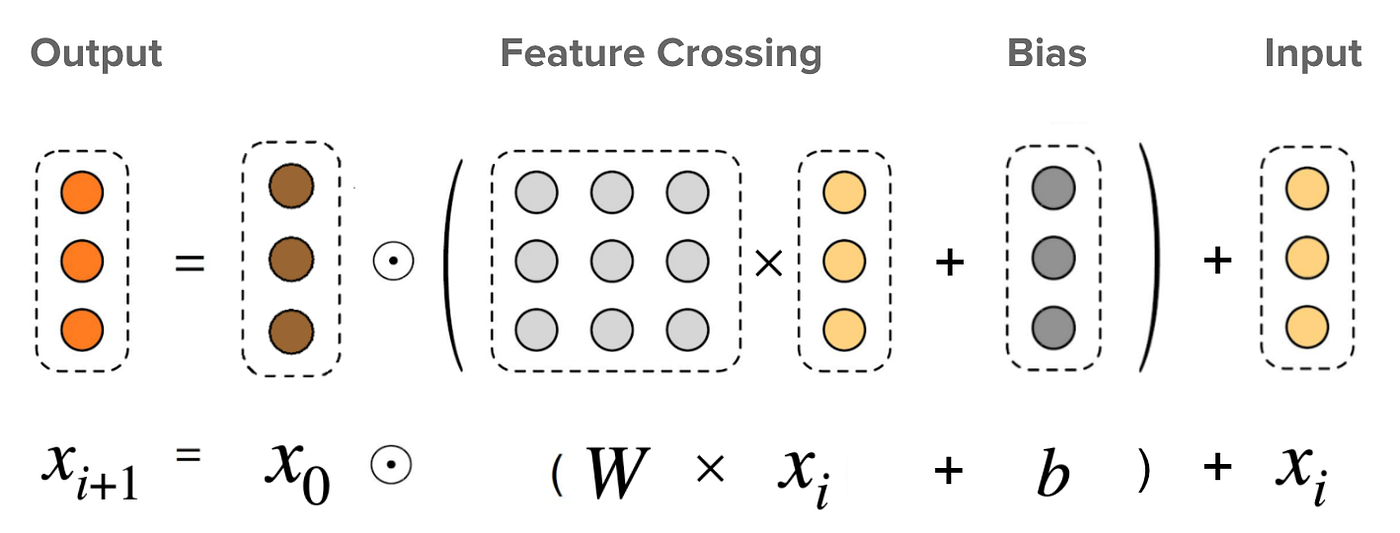
特徵創建
創建多個類別特徵組合的新特徵,用於捕捉它們之間的特定交互。常用於推薦系統和廣告點擊率預測。
#55
★
自編碼器 (Autoencoder) 用於特徵提取
深度學習應用
訓練好的自編碼器的中間瓶頸層(潛在表示)可以作為原始數據的非線性降維結果,用於特徵提取。
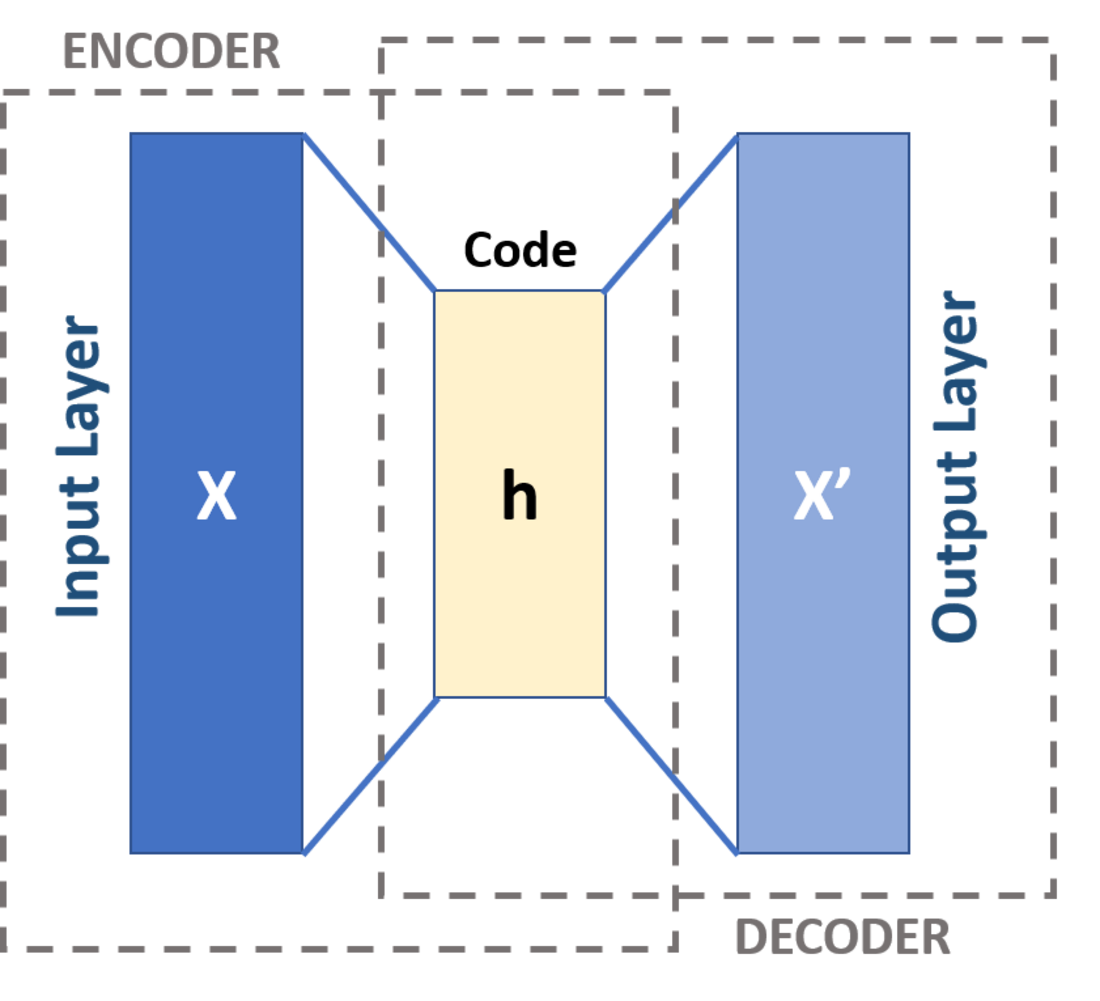
#56
★
置換重要性 (Permutation Importance)
特徵選擇/解釋
一種模型無關的特徵重要性評估方法。透過隨機打亂某個特徵的值,觀察模型性能下降的程度來判斷該特徵的重要性。
#57
★
數據標註平台
工具
用於管理和執行數據標註任務的平台,提供標註介面、品質控制、任務分配等功能。對於需要大量標註數據的監督式學習項目很重要。
#58
★
重複數據處理
數據清理
識別並處理數據集中的重複記錄。重複數據可能扭曲分析結果或導致模型過度自信。
#59
★
數據傾斜 (Data Skew)
數據特性
指訓練數據的分佈與實際應用(推論)數據的分佈存在差異。這可能導致模型在生產環境中性能下降。是數據漂移的一種形式。
#60
★
特徵洩漏 (Feature Leakage)
常見錯誤
在訓練模型時不當地使用了包含目標變數資訊(或未來資訊)的特徵。這會導致模型在訓練/驗證時表現異常好,但在實際預測時無效。需要在特徵工程階段仔細避免。
沒有找到符合條件的重點。
↑