iPAS AI應用規劃師 考試重點
L23203 深度學習原理與框架
主題分類
1
深度學習基礎概念
2
神經網路構成要素
3
常見深度學習架構
4
訓練原理與優化
5
損失函數與激活函數
6
過擬合與正則化
7
深度學習框架
8
應用與挑戰
#1
★★★★★
深度學習 (DL, Deep Learning) - 基本定義
核心概念
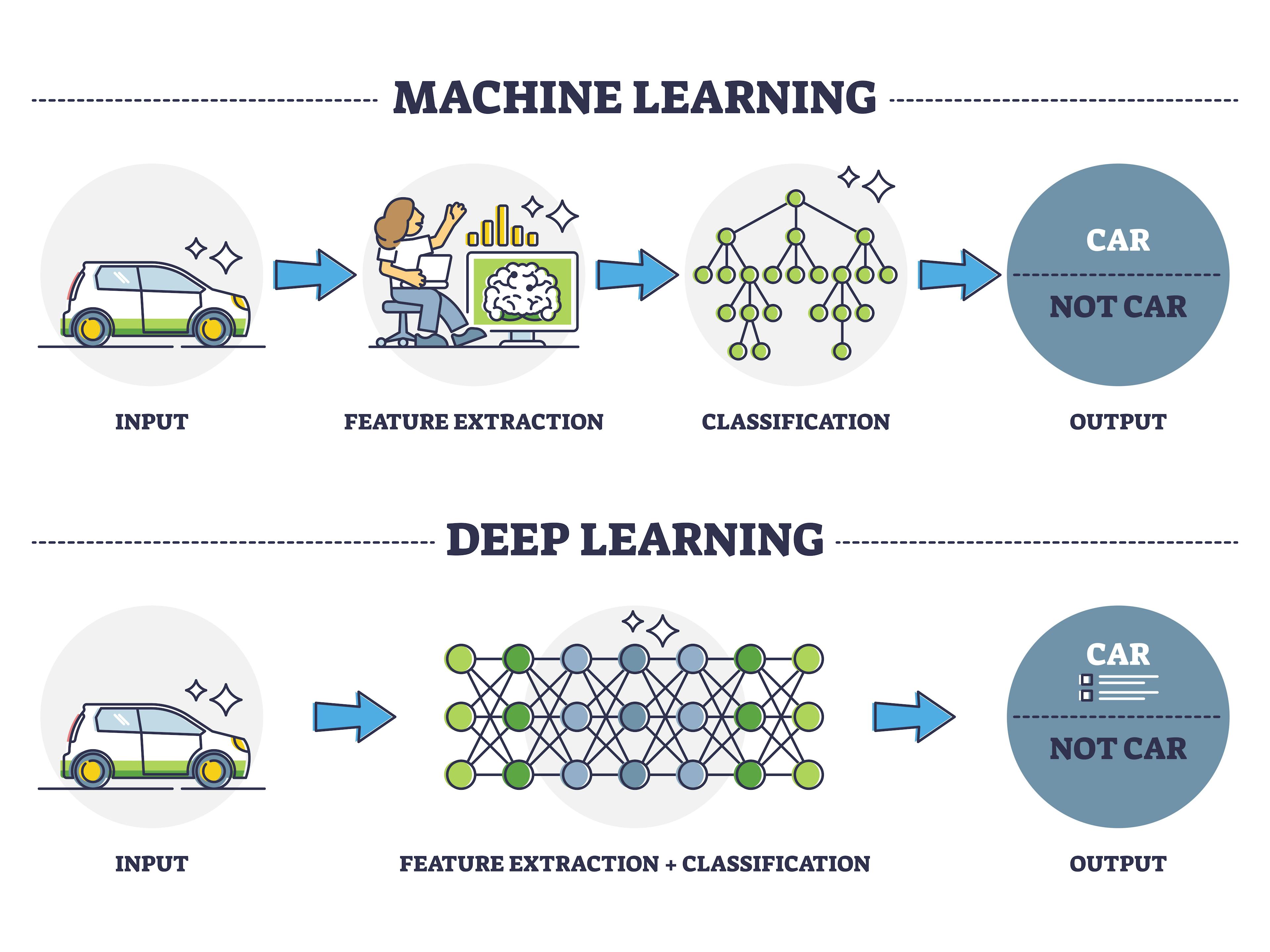
深度學習 是機器學習 (ML) 的一個分支,其核心是使用具有多個處理層(通常是隱藏層)的人工神經網路 (ANN) 來學習數據的分層表示 (Hierarchical Representation)。「深度」指的是網路層數的增加。
#2
★★★★
深度學習 vs. 傳統機器學習
主要區別 (參考樣題 Q10)
- 特徵工程 (Feature Engineering): 傳統 ML 通常需要手動設計和提取特徵;DL 的深層結構使其能夠自動學習相關的、層次化的特徵 (樣題 Q10)。
- 數據量需求: DL 模型通常需要更大規模的數據集才能表現良好。
- 計算資源: DL 模型訓練通常需要更強大的計算資源(如 GPU)。
- 適用場景: DL 在處理非結構化數據(圖像、文本、語音)方面表現尤為突出。
#3
★★★
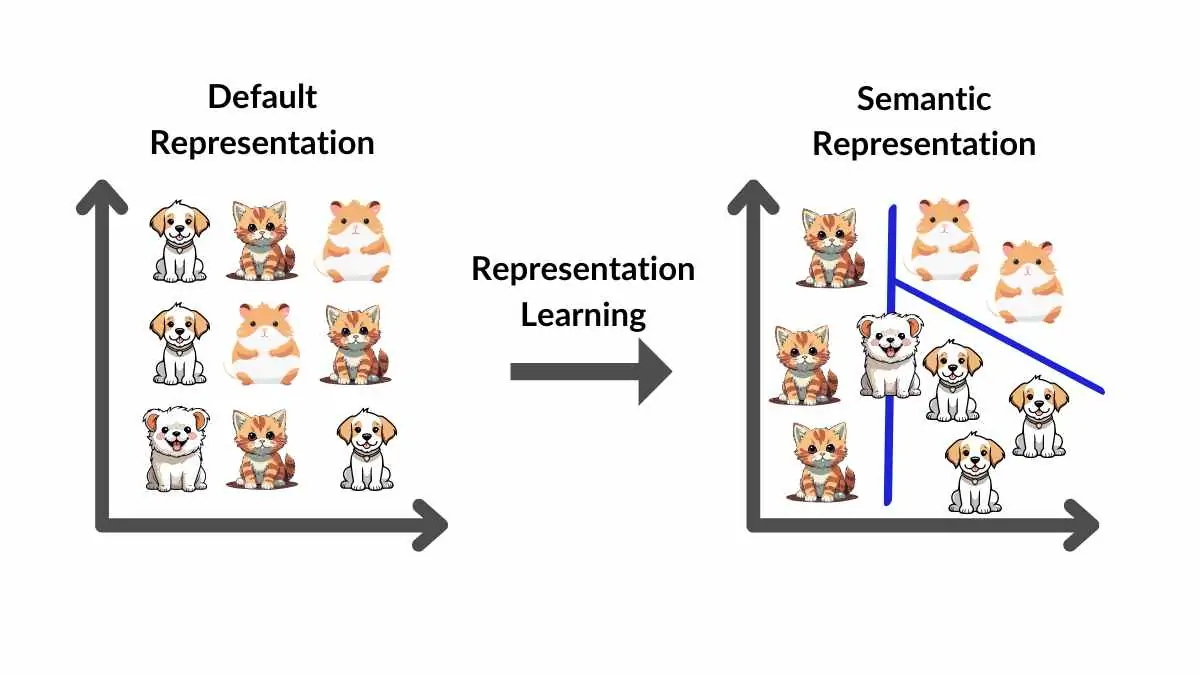
表徵學習 (Representation Learning)
核心思想
深度學習 的一個核心思想是自動地從原始數據中學習有用的表示或特徵。網路的每一層學習輸入數據的不同抽象級別的表示,從低級特徵(如邊緣、紋理)到高級特徵(如物體部件、概念)。
#4
★★★★★
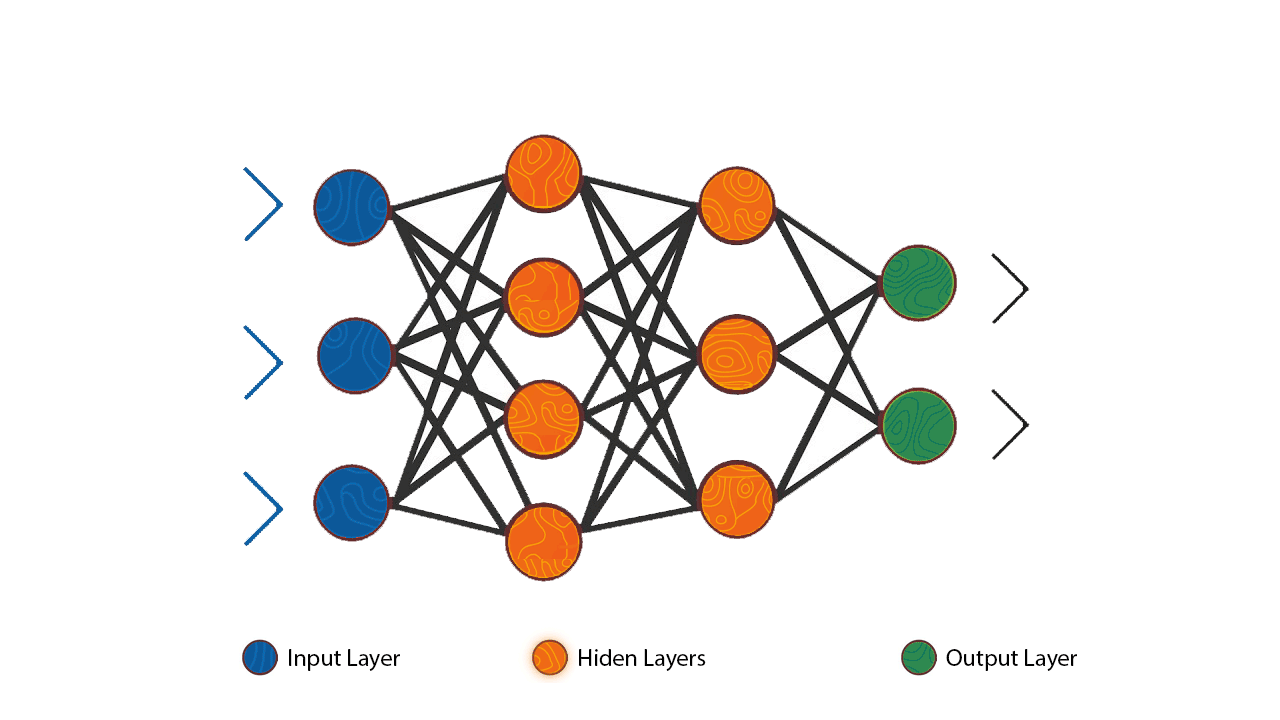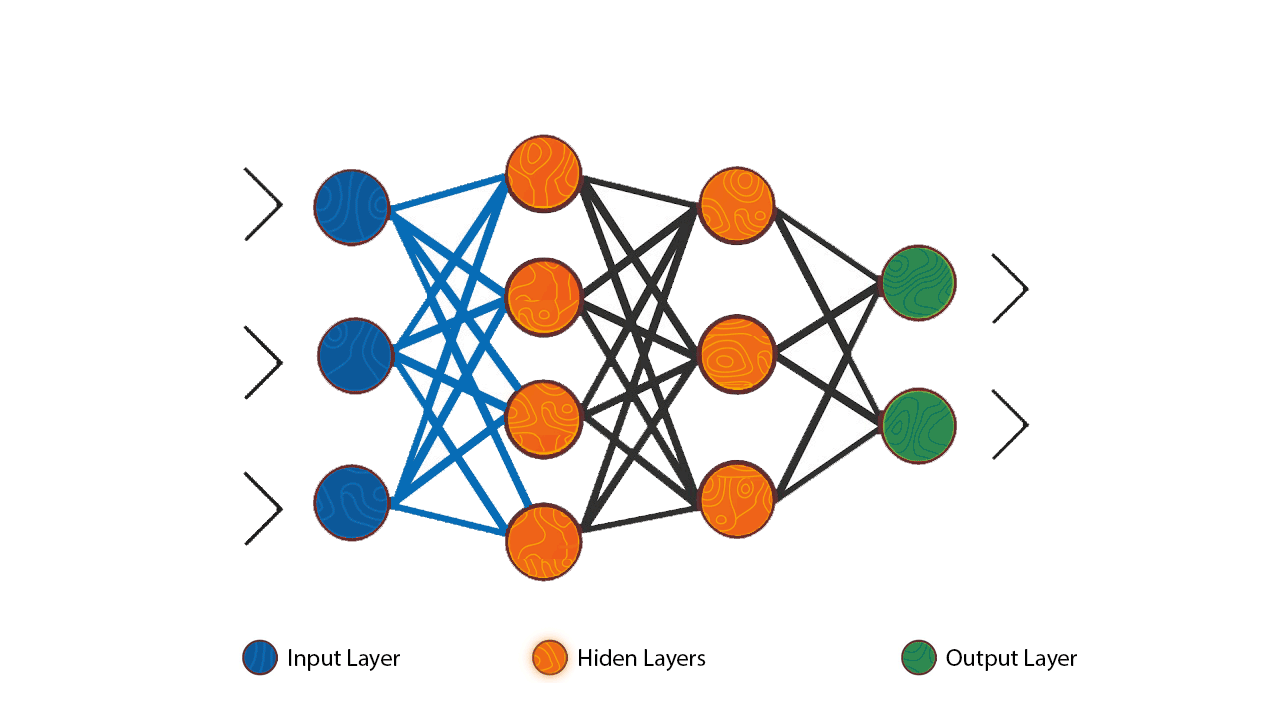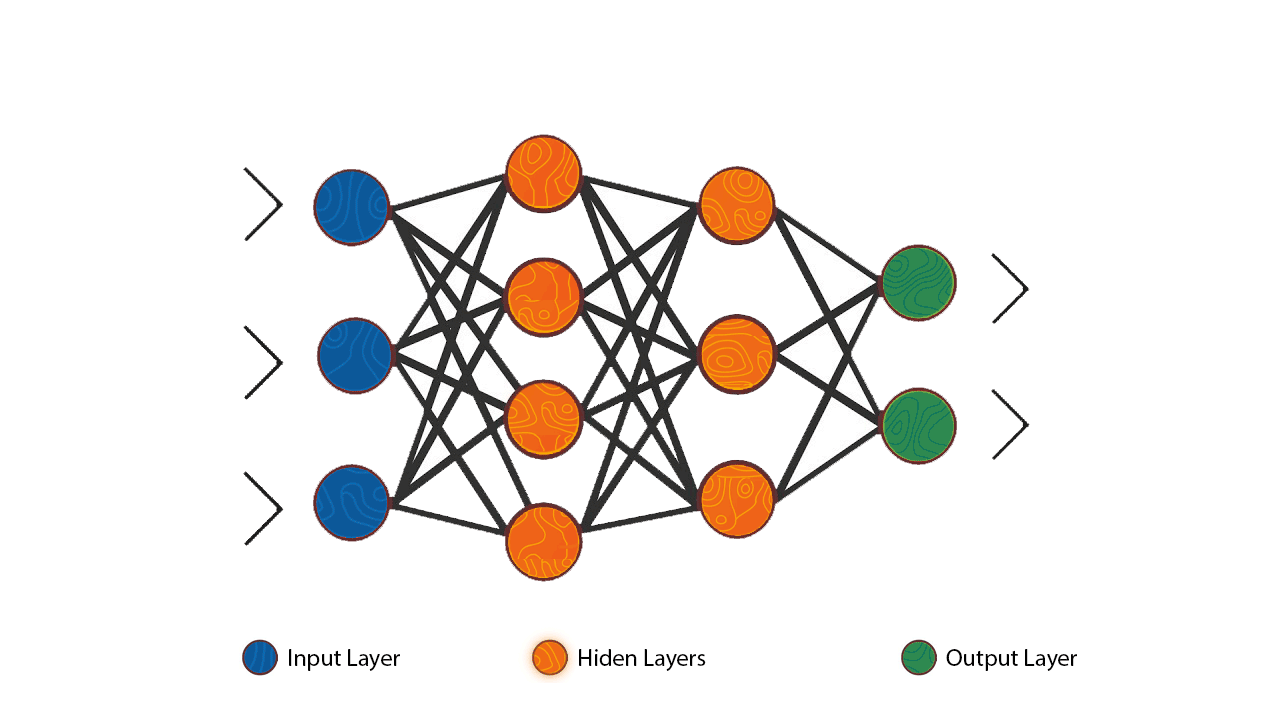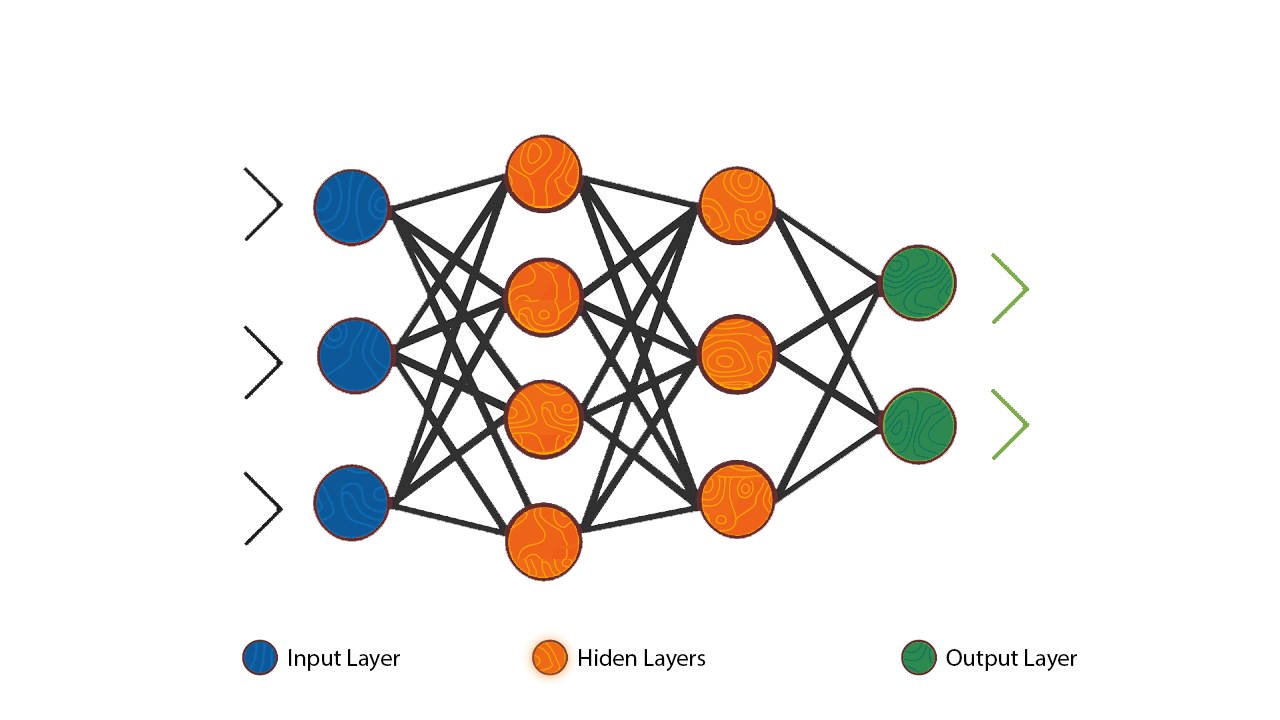
人工神經網路 (ANN, Artificial Neural Network) 基本結構
核心組件
ANN 通常由多個層組成:
- 輸入層 (Input Layer): 接收原始輸入數據。
- 隱藏層 (Hidden Layer(s)): 進行特徵提取和轉換,深度學習通常有多個隱藏層。
- 輸出層 (Output Layer): 產生最終的預測結果。
#5
★★★★★
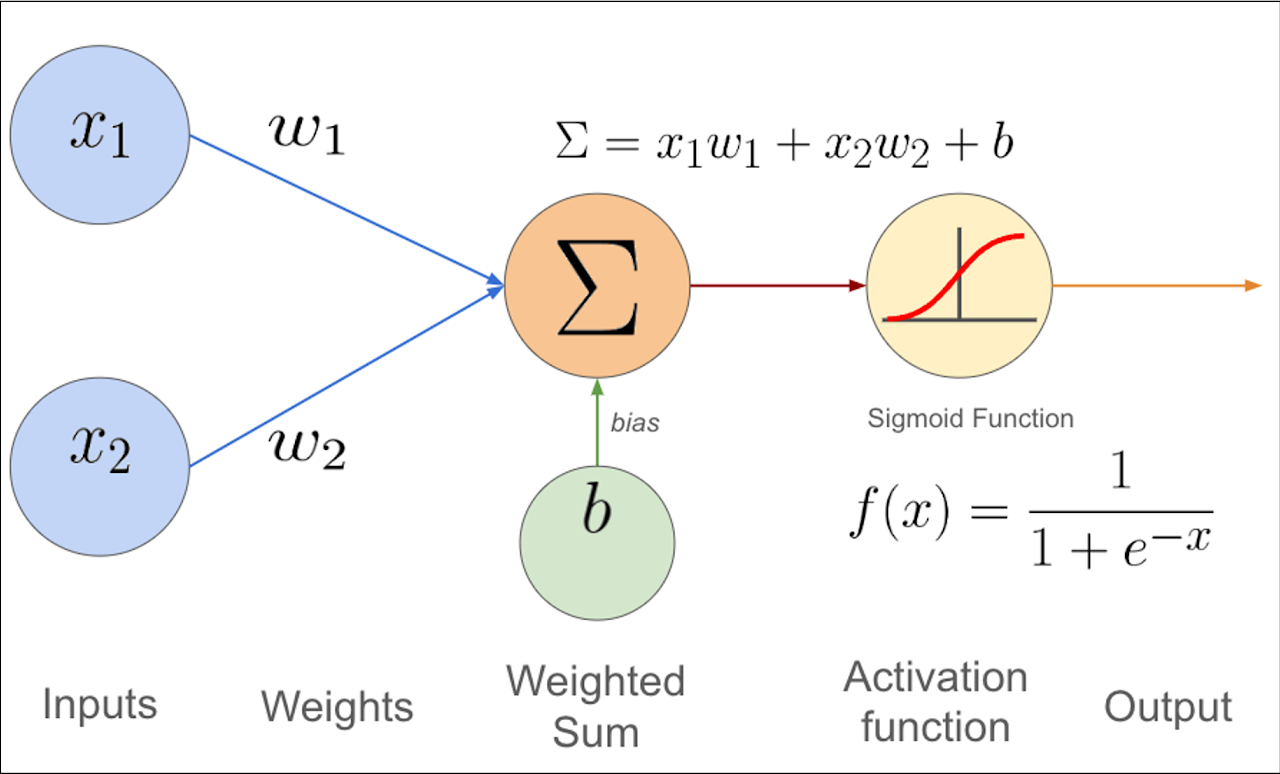
神經元 (Neuron) / 感知器 (Perceptron)
基本計算單元
神經元 是網路的基本計算單元。它接收來自前一層神經元的多個輸入,每個輸入乘以一個權重 (Weight),將加權後的輸入求和,加上一個偏置項 (Bias),然後通過一個激活函數 (Activation Function) 產生輸出。
Output = Activation(Σ(Weightᵢ * Inputᵢ) + Bias)
Output = Activation(Σ(Weightᵢ * Inputᵢ) + Bias)
#6
★★★★★
權重 (Weights) 與 偏置 (Biases)
模型參數
權重和偏置是神經網路的可學習參數。
- 權重:表示輸入信號的重要性或連接強度。
- 偏置:提供一個額外的可調參數,允許激活函數的輸出進行平移,增加模型的靈活性。
#7
★★★★★
激活函數 (Activation Function)
核心作用
激活函數應用於神經元的加權輸入和偏置之和上,其主要作用是為神經網路引入非線性 (Non-linearity)。如果沒有非線性激活函數,多層神經網路本質上等同於單層線性模型,無法學習複雜模式。常見激活函數見主題五。(參考樣題 Q4)
#8
★★★★★
多層感知器 (MLP, Multi-Layer Perceptron)
基本架構
最基礎的神經網路類型,由一個輸入層、一個或多個全連接 (Fully Connected) 的隱藏層和一個輸出層組成。適用於表格數據的分類和迴歸問題。
#9
★★★★★
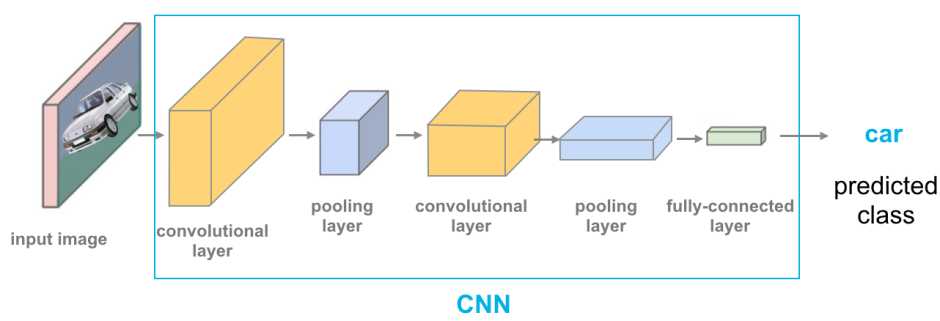
卷積神經網路 (CNN, Convolutional Neural Network) - 原理
核心原理 (參考樣題 Q4, Q12)
CNN 特別擅長處理具有網格結構的數據(如圖像)。關鍵思想包括:
- 局部感受野 (Local Receptive Fields): 神經元只連接到輸入的一個小區域。
- 權重共享 (Weight Sharing): 同一個卷積核 (Kernel) 或濾波器 (Filter) 在整個輸入上滑動,共享相同的權重,大大減少了參數數量。
- 池化 (Pooling): 降低空間維度,增強對微小變化的不變性。
#10
★★★★★
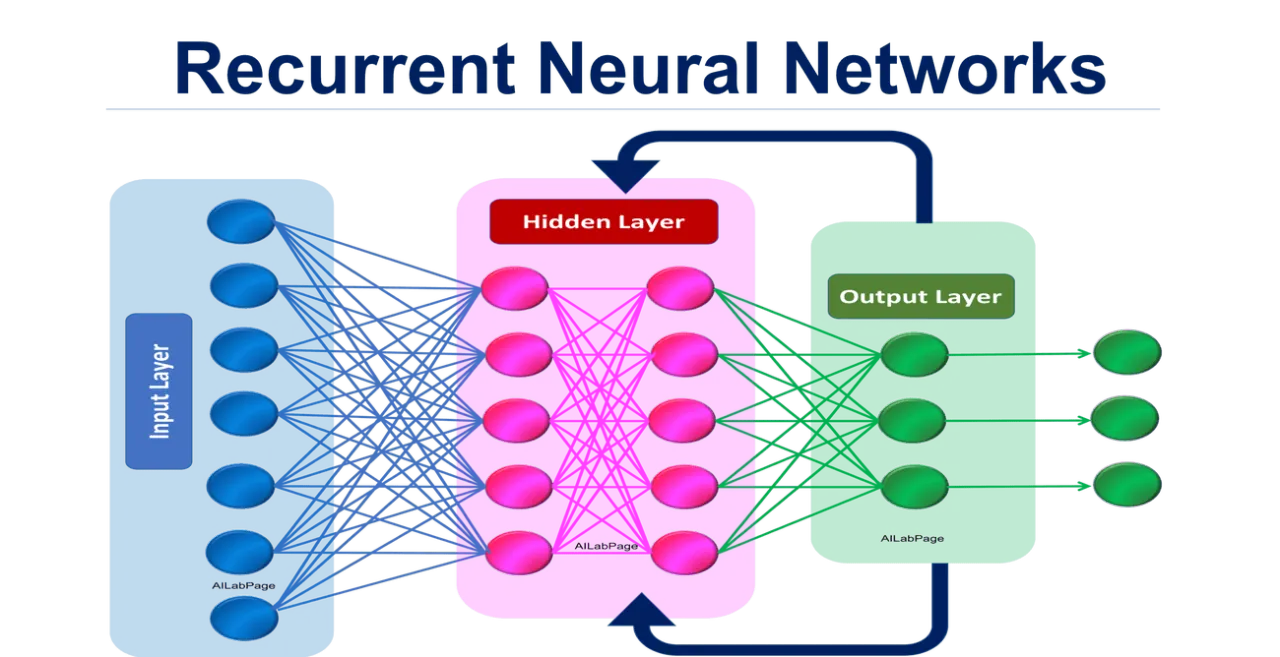
循環神經網路 (RNN, Recurrent Neural Network) - 原理
核心原理 (參考樣題 Q4)
RNN 專為處理序列數據設計。其核心是隱藏狀態 (Hidden State) 的循環連接,允許資訊從序列的前一個時間步傳遞到下一個時間步,從而捕捉序列中的時間依賴性。樣題 Q4 確認 RNN 適合處理序列相關資料。
#11
★★★★
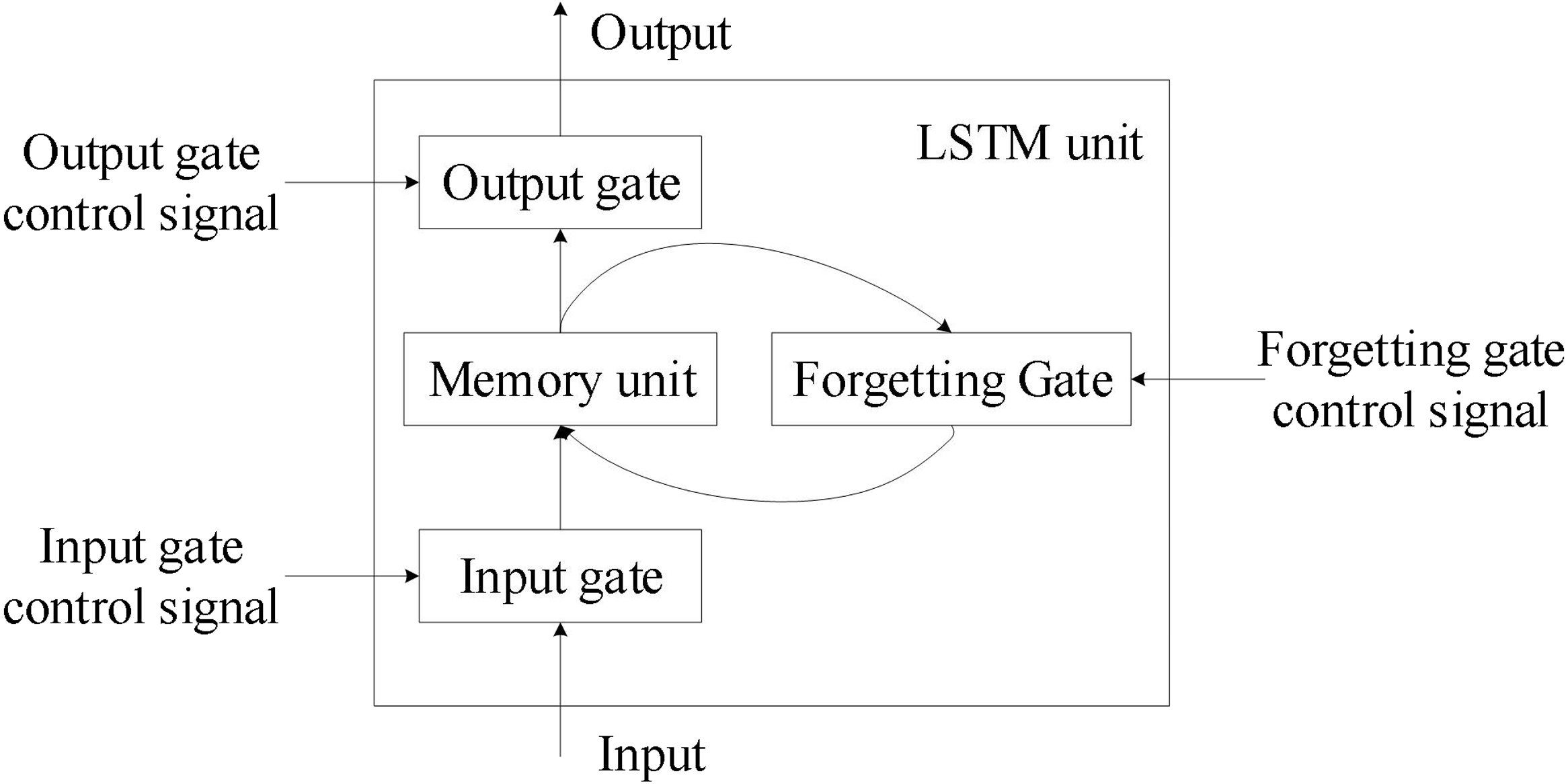
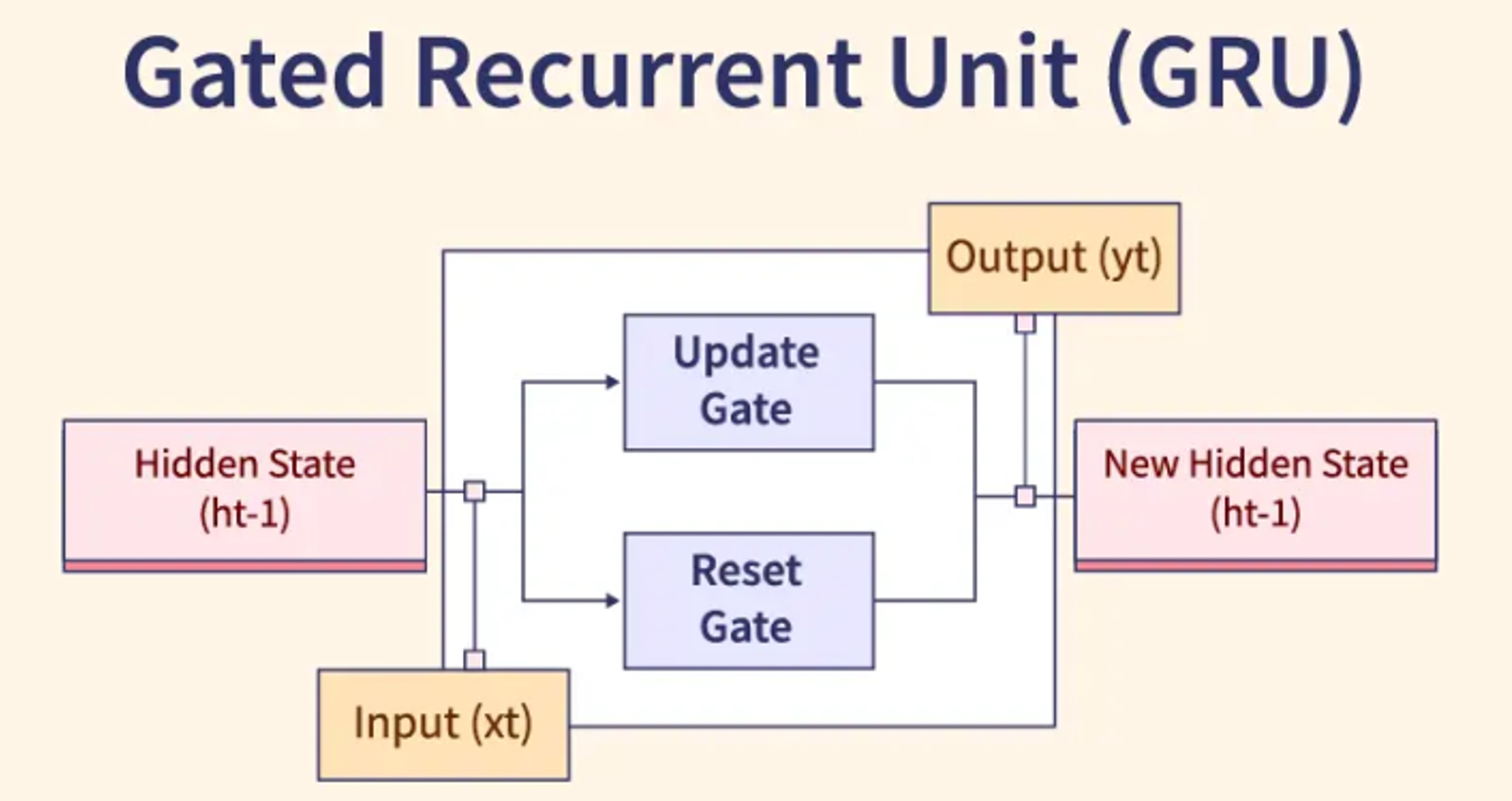
LSTM (Long Short-Term Memory) 與 GRU (Gated Recurrent Unit)
RNN 變體
為了解決標準 RNN 的梯度消失/爆炸問題以及難以捕捉長期依賴 (Long-term Dependencies) 的問題,引入了 LSTM 和 GRU。它們都使用門控機制 (包括遺忘門、輸入門、輸出門等) 來控制資訊在序列中的流動和保留,能夠更好地處理長序列。
#12
★★★★★
Transformer 架構 - 原理
核心原理
Transformer 完全基於注意力機制 (Attention Mechanism),特別是自注意力 (Self-Attention),摒棄了 RNN 的循環結構。
- 自注意力允許模型在處理序列中的某個元素時,直接計算該元素與序列中所有其他元素的相關性權重,從而有效捕捉長程依賴。
- 具有高度並行化的能力,訓練速度快。
- 已成為 NLP 領域的基礎架構。
#13
★★★★
生成對抗網路 (GAN, Generative Adversarial Network) - 原理
核心原理 (參考樣題 Q11)
GAN 包含一個生成器 (Generator) 和一個鑑別器 (Discriminator)。生成器試圖生成假數據來欺騙鑑別器,鑑別器試圖區分真假數據。兩者進行對抗性訓練,如同一個二人零和賽局 (Two-player Zero-sum Game),最終目標是生成非常逼真的數據。樣題 Q11 確認其組成。
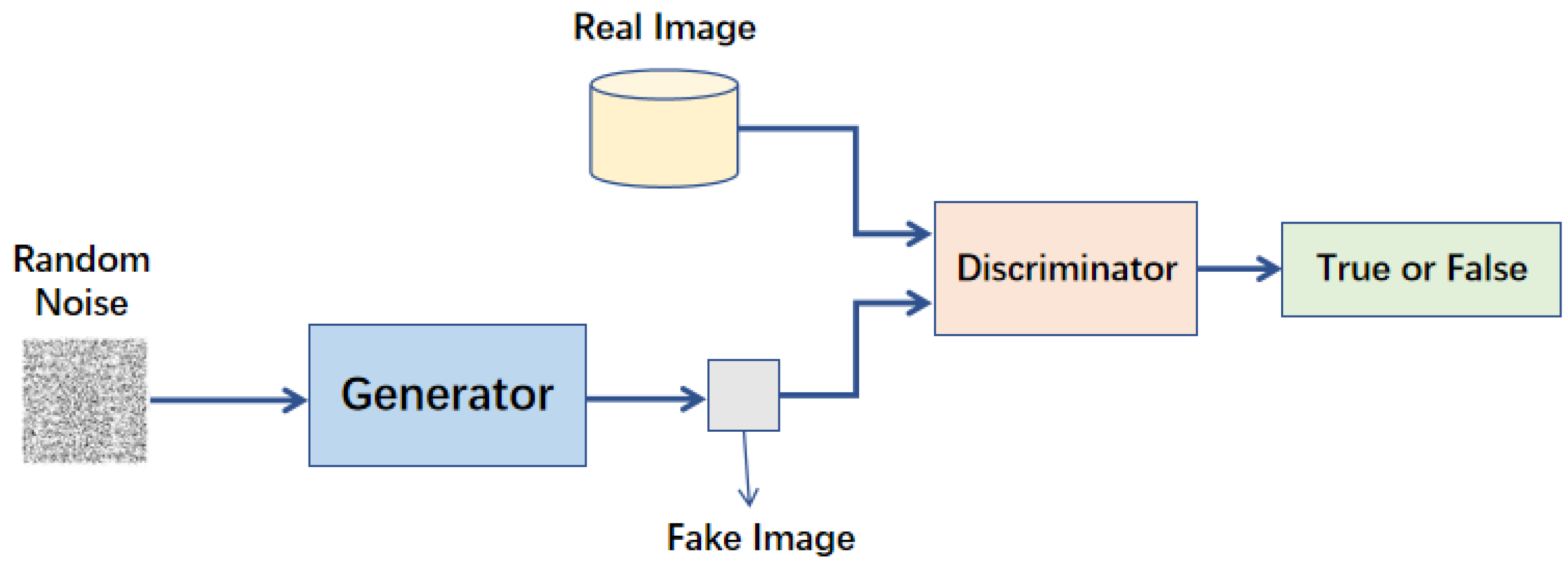
#14
★★★
自編碼器 (AE, Autoencoder) - 原理
核心原理
AE 是一種非監督式學習模型,包含編碼器 (Encoder) 和解碼器 (Decoder)。編碼器將輸入壓縮到一個低維的潛在表示 (Latent Representation),解碼器再從潛在表示重構原始輸入。訓練目標是最小化重構誤差 (Reconstruction Error)。常用於降維、特徵學習和異常檢測。
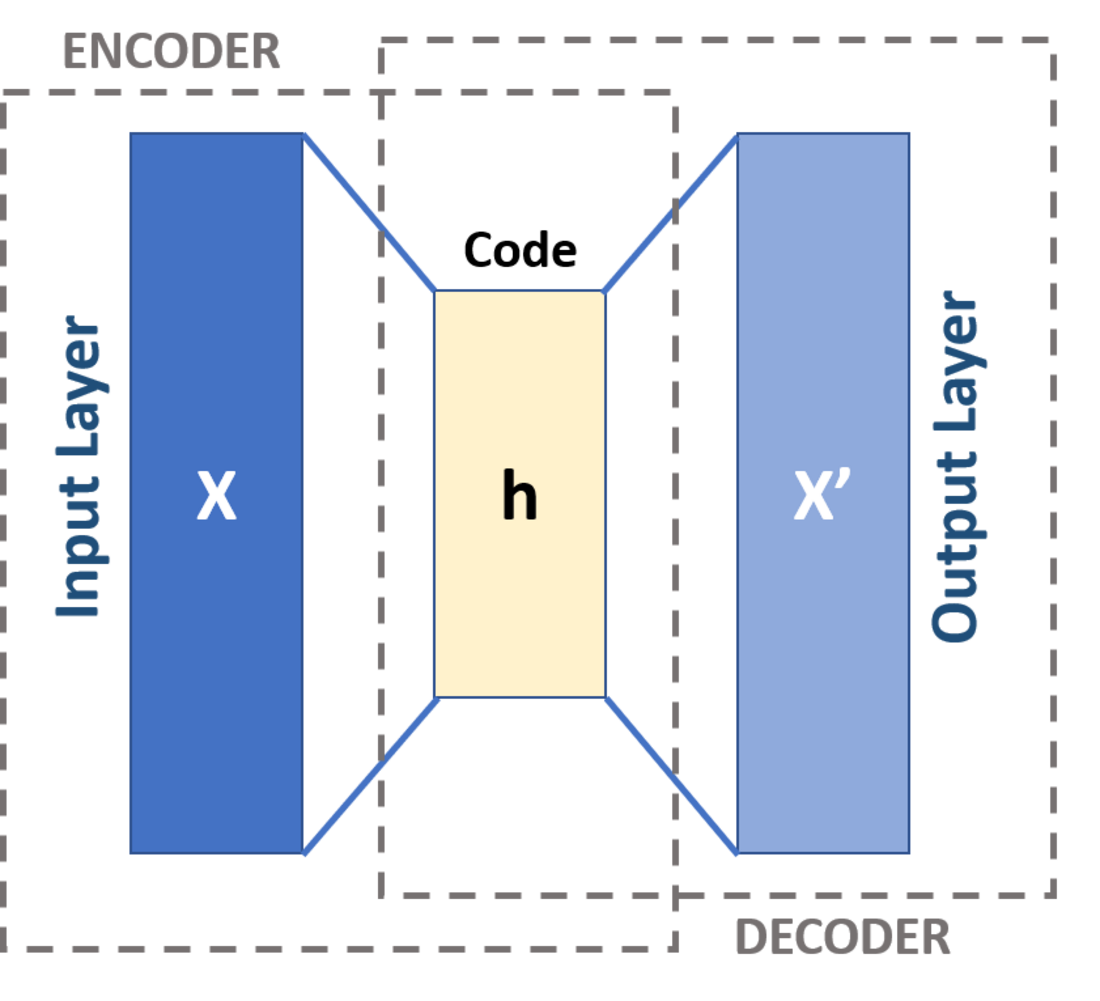
#15
★★★★★
反向傳播演算法 (Backpropagation Algorithm)
核心訓練算法
反向傳播是訓練多層神經網路的標準算法。它透過鏈式法則 (Chain Rule) 有效地計算損失函數相對於網路中每個權重和偏置的梯度。計算出的梯度隨後被優化演算法(如梯度下降)用來更新模型參數。
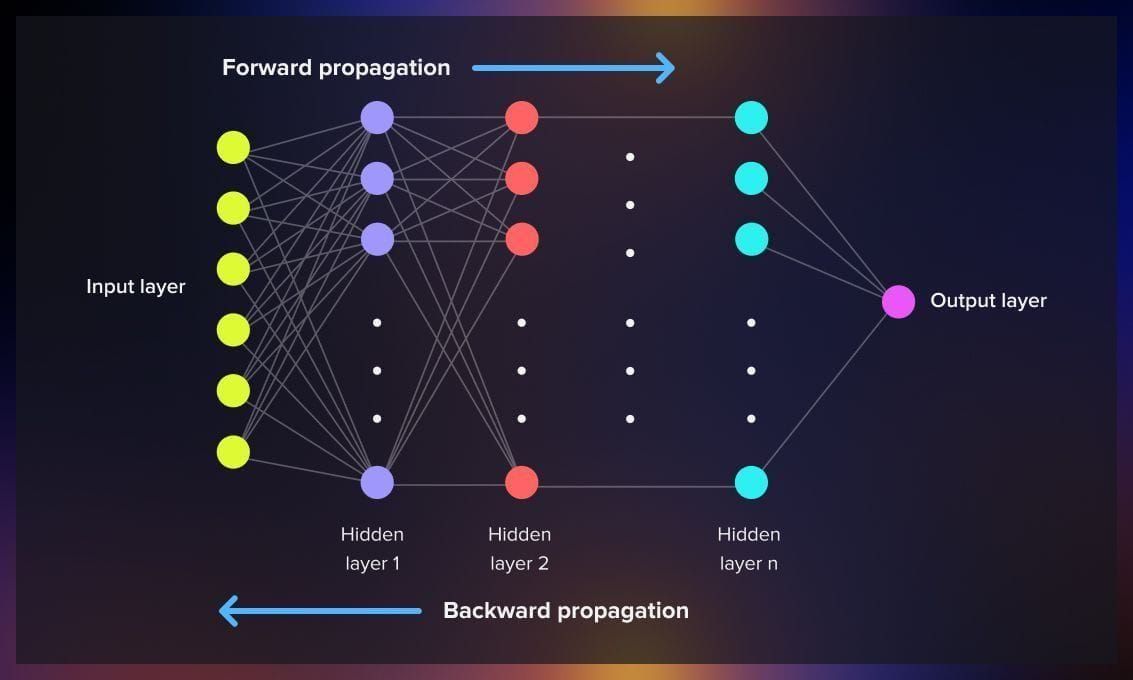
#16
★★★★
梯度下降法 (Gradient Descent) 及其變體 (SGD, Mini-batch)
優化基礎
梯度下降法是神經網路訓練中最常用的優化演算法。
- 基本思想:沿著損失函數梯度的負方向更新參數。
- SGD (隨機梯度下降): 每次用單一樣本估計梯度。速度快但噪音大。
- Mini-batch GD (小批量梯度下降): 每次用一小批樣本估計梯度。兼顧效率和穩定性,最常用。
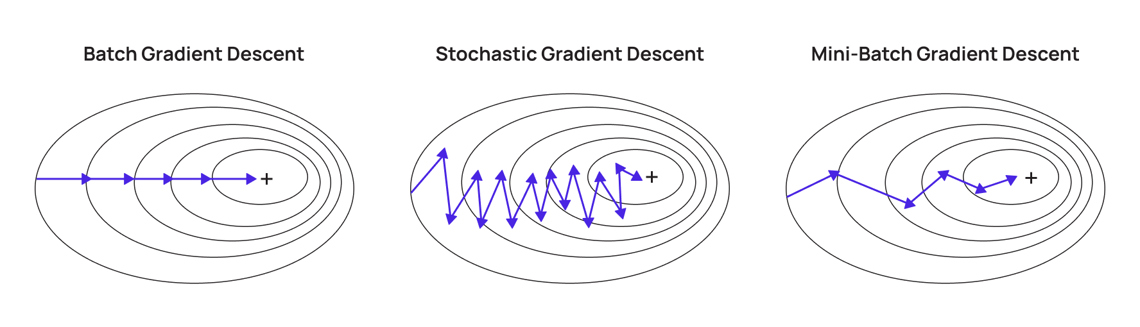
#17
★★★★
自適應優化演算法 (Adaptive Optimizers) - Adam, RMSprop
進階優化器
如 Adagrad, RMSprop, Adam 等優化器能夠自動調整每個參數的學習率。
- Adam (Adaptive Moment Estimation) 結合了動量 (Momentum) 和 RMSprop 的思想,是目前深度學習中最流行和常用的優化器之一。
#18
★★★
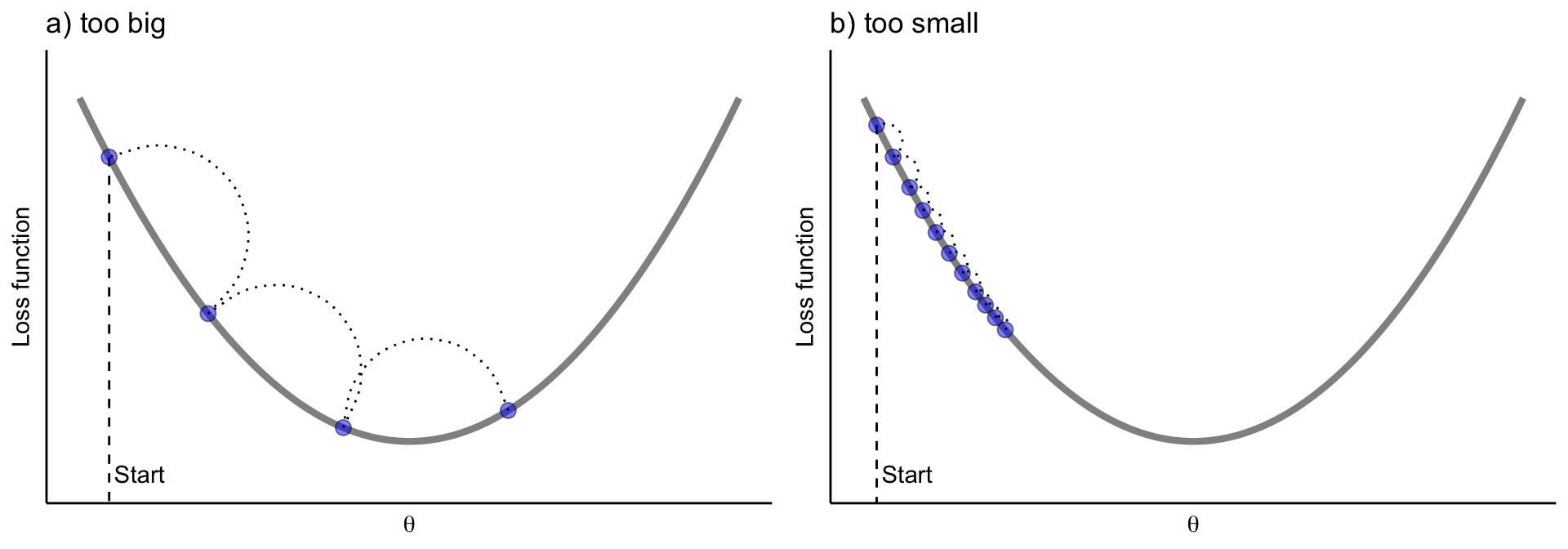
學習率 (Learning Rate) 與學習率衰減 (Learning Rate Decay)
訓練調整
學習率是影響訓練效果的關鍵超參數。設定過高可能導致不收斂,過低則收斂緩慢。學習率衰減(或學習率排程 Scheduling)是一種常見策略,即在訓練過程中逐漸降低學習率,有助於模型在訓練後期更穩定地收斂到最優點附近。
#19
★★★
權重初始化 (Weight Initialization)
訓練技巧
合適的權重初始化對於深度神經網路的成功訓練至關重要。不當的初始化可能導致梯度消失/爆炸或收斂緩慢。常用的初始化方法包括Xavier/Glorot 初始化和He 初始化,它們會根據層的輸入和輸出單元數量來設定初始權重的分佈。
#20
★★★★
損失函數 (Loss Function) 的選擇原則
選擇依據
損失函數的選擇應與問題類型和模型輸出層的激活函數相匹配。
- 二元分類 (Sigmoid 輸出): 常選用二元交叉熵 (Binary Cross-Entropy)。
- 多元分類 (Softmax 輸出): 常選用分類交叉熵 (Categorical Cross-Entropy)。
- 迴歸 (線性輸出): 常選用 MSE 或 MAE。

#21
★★★★★
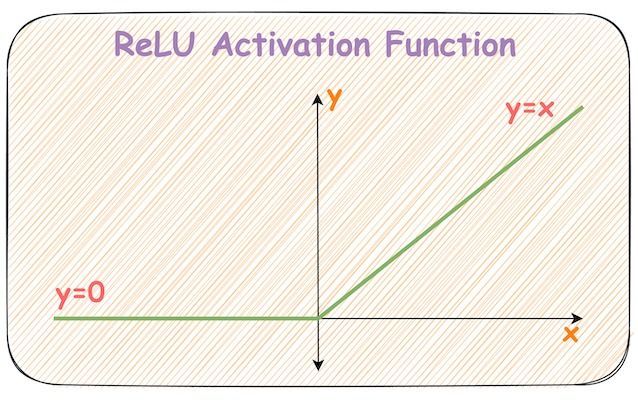
激活函數:ReLU (Rectified Linear Unit)
常用激活函數 (參考樣題 Q4)
f(x) = max(0, x)。目前最常用的激活函數之一。
- 優點:計算簡單、有效緩解梯度消失問題(在正區間梯度為1)。
- 缺點:可能導致「死亡 ReLU」問題(如果神經元輸出恆為0,梯度也將恆為0,無法再更新)。
#22
★★★
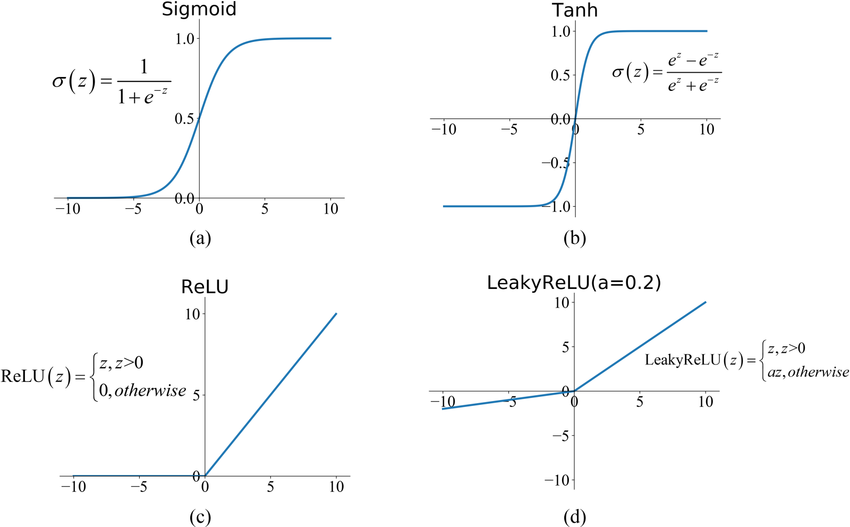
激活函數:Sigmoid 與 Tanh
其他激活函數 (參考樣題 Q4)
- Sigmoid: 將輸出壓縮到 (0, 1)。常用於二分類輸出層。缺點是梯度飽和(兩端梯度接近0),易導致梯度消失。
- Tanh (雙曲正切): 將輸出壓縮到 (-1, 1)。通常比 Sigmoid 收斂更快,但也存在梯度飽和問題。
#23
★★★
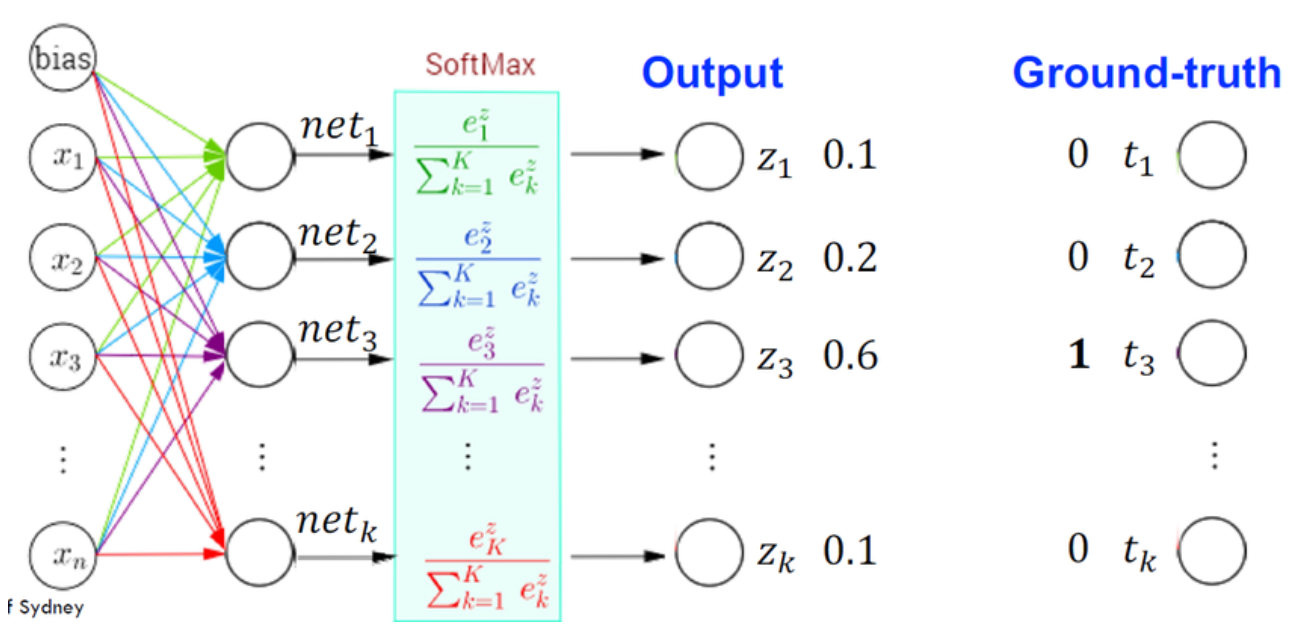
激活函數:Softmax
輸出層激活
Softmax 函數通常用於多分類問題的輸出層。它將一個向量轉換為機率分佈,使得所有輸出的和為 1,每個輸出可以解釋為對應類別的預測機率。
#24
★★★★★
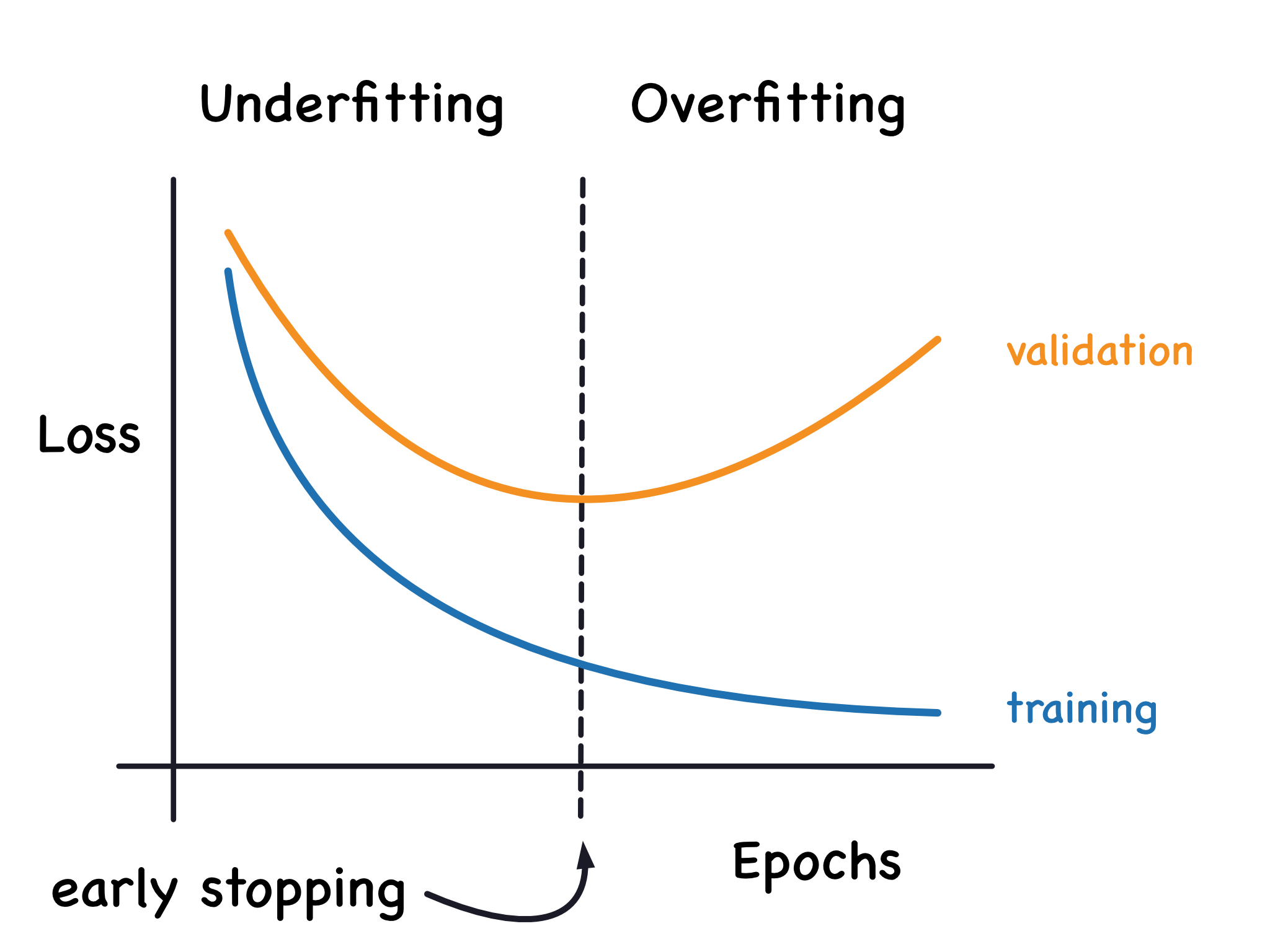
過擬合 (Overfitting) 的原因與後果 (參考樣題 Q13)
核心問題
原因:模型過於複雜(相對於數據量)、數據量不足、訓練時間過長、數據中噪聲過多。
後果:模型在訓練集上誤差低,但在新數據上泛化能力差,無法做出可靠的預測(測試誤差高)。樣題 Q13 描述的就是過擬合現象。
後果:模型在訓練集上誤差低,但在新數據上泛化能力差,無法做出可靠的預測(測試誤差高)。樣題 Q13 描述的就是過擬合現象。
#25
★★★★★
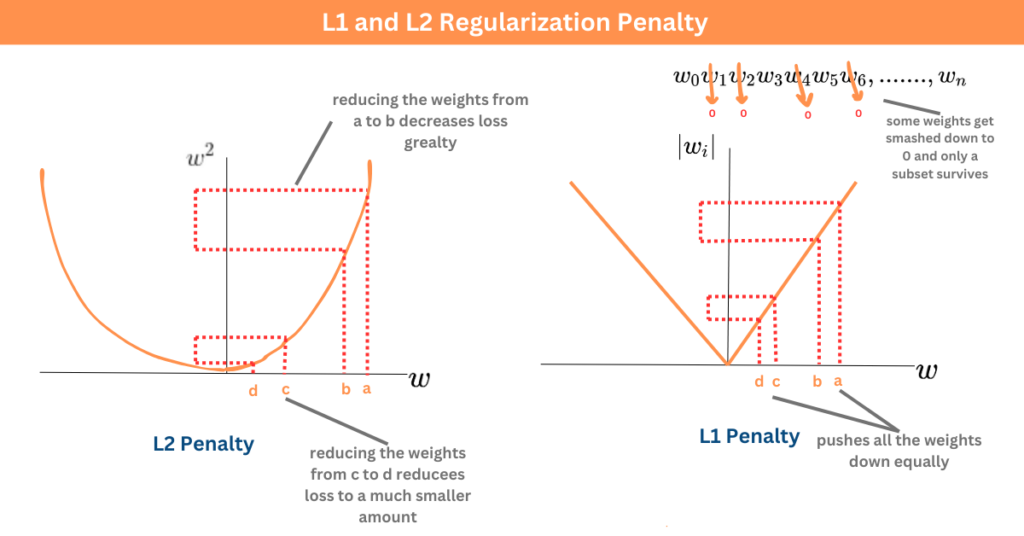
正則化 (Regularization) 的目的 (參考樣題 Q3)
核心目的
正則化 是一系列用於防止模型過擬合、提高模型泛化能力的技術。其核心思想是在模型優化過程中加入對模型複雜度的懲罰。樣題 Q3 確認增加正則化項是降低過擬合的常用方法。
#26
★★★★
L1 / L2 正則化
常用技術
在損失函數中加入懲罰項:
- L1 正則化 (Lasso): 懲罰權重絕對值之和。傾向於產生稀疏權重(部分權重為零),可用於特徵選擇。
- L2 正則化 (Ridge / 權重衰減 Weight Decay): 懲罰權重平方和之和。傾向於使權重值變小,但通常不為零。
#27
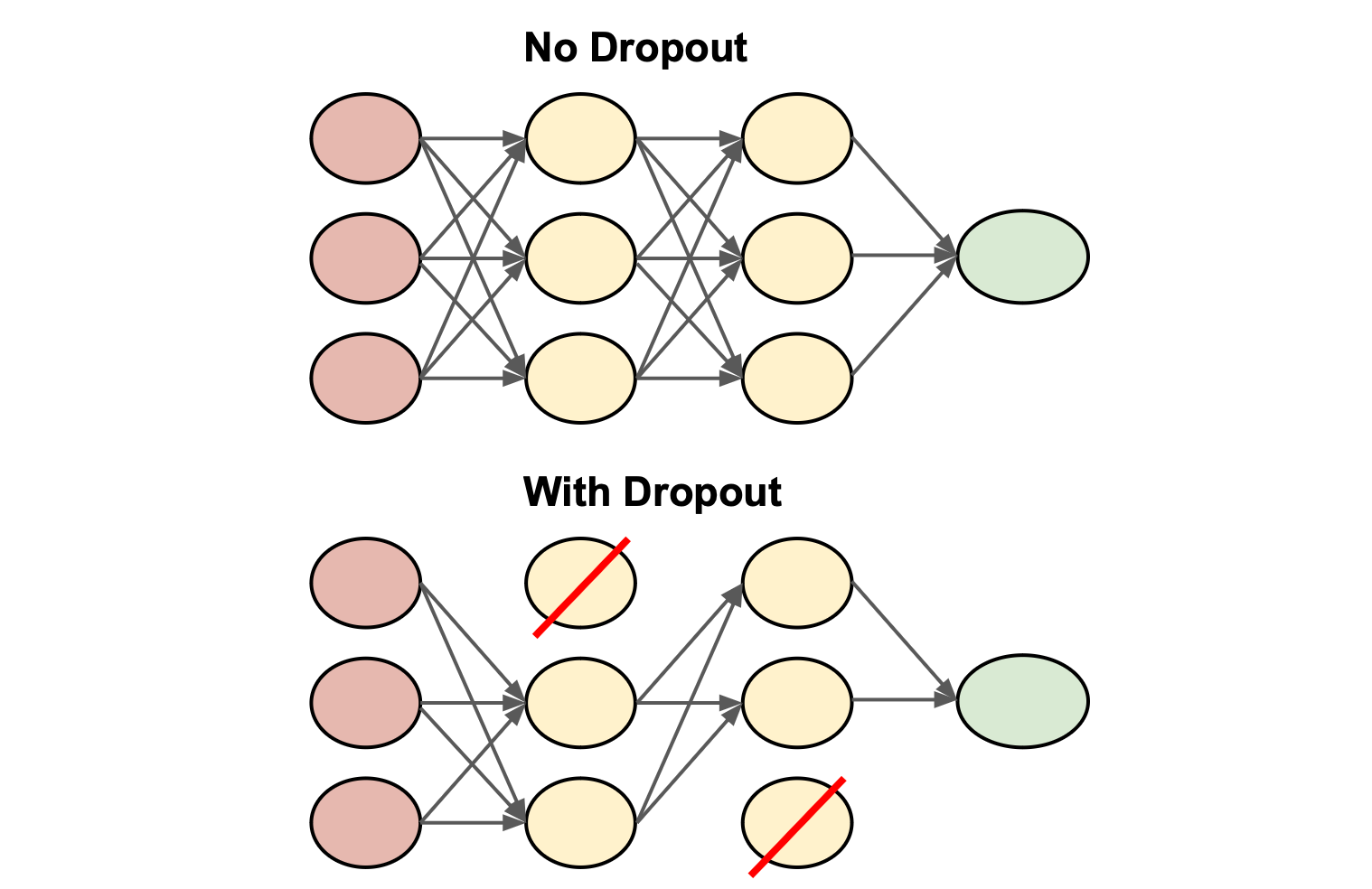
★★★★
Dropout 正則化
常用技術 (神經網路)
在訓練過程中,隨機將一部分神經元的輸出設置為零。強迫網路學習更冗餘、更穩健的表示,減少神經元間的依賴,有效防止過擬合。
#28
★★★
提早停止 (Early Stopping)
常用技術
在訓練過程中監控驗證集上的性能,當性能不再提升或開始下降時提前停止訓練。是一種簡單有效的防止過度訓練導致過擬合的方法。
#29
★★★
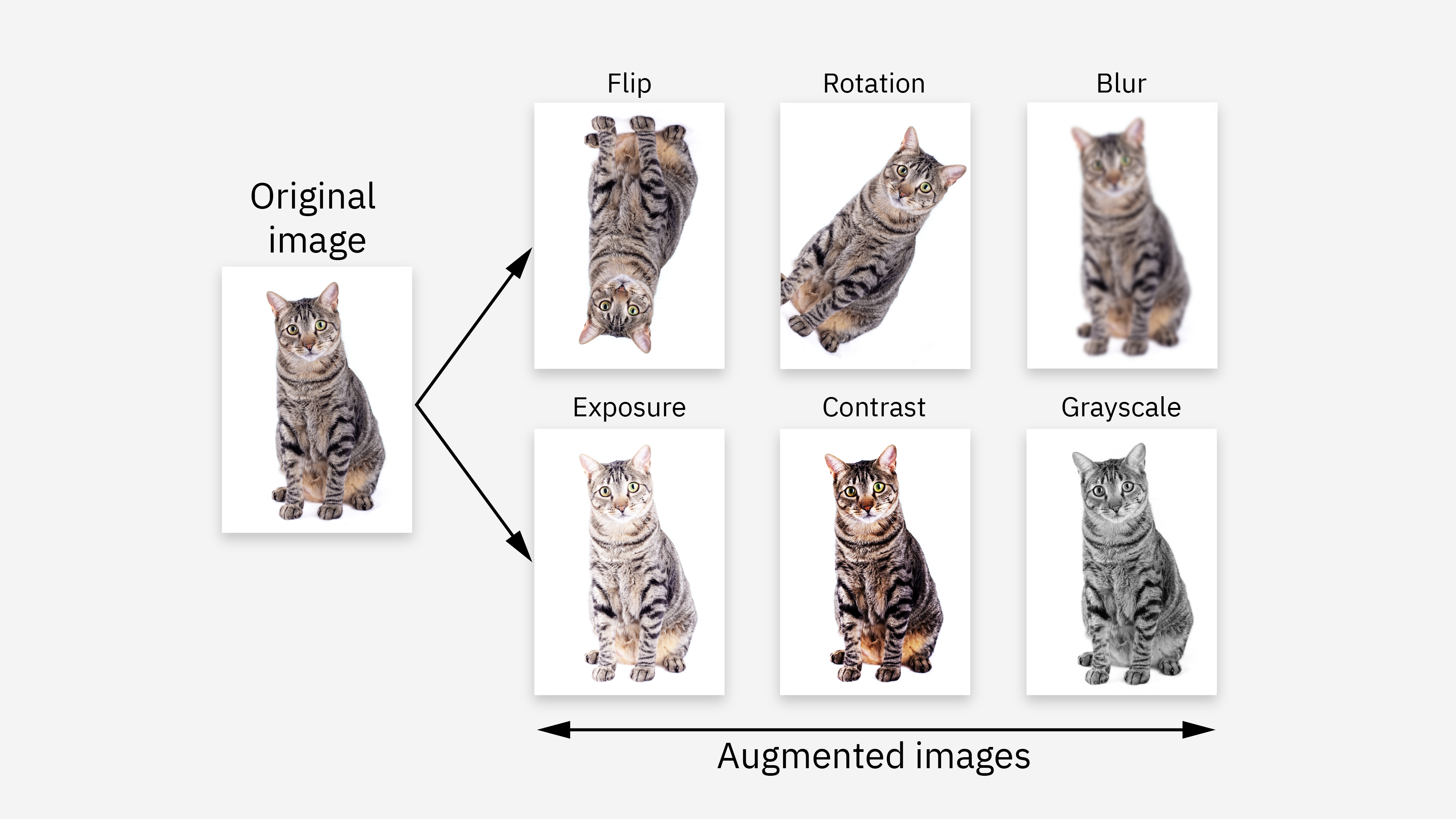
數據增強 (Data Augmentation)
常用技術
透過對現有訓練數據進行微小的、隨機的變換(如圖像旋轉、裁剪、顏色抖動;文本替換同義詞等)來人工增加訓練數據的多樣性和數量。有助於提高模型的泛化能力和穩健性,間接起到正則化效果。
#30
★★★★
主流深度學習框架 (Deep Learning Frameworks)
常用框架
提供了構建、訓練和部署深度學習模型的工具和函式庫,大大簡化了開發流程。主流框架包括:
- TensorFlow: 由 Google 開發,生態系統完善,支持生產部署。
- PyTorch: 由 Facebook (Meta) 開發,以其靈活性和 Pythonic 的特性在學術界和研究領域非常流行,近年在工業界也廣泛應用。
- 其他:如 MXNet, Caffe, Theano (較舊) 等。
 Keras: 作為 TensorFlow 的高階 API,以易用性著稱。
Keras: 作為 TensorFlow 的高階 API,以易用性著稱。
#31
★★★
深度學習框架的選擇考量
考量因素
選擇框架時需考慮:易用性、靈活性、社區支持、文檔完善度、性能、生產部署能力、與其他工具的整合等。TensorFlow 和 PyTorch 是目前最主要的選擇。
#32
★★
框架中的自動微分 (Automatic Differentiation)
核心功能
深度學習框架的核心功能之一是自動計算複雜函數的梯度,這是實現反向傳播的基礎,極大地方便了模型訓練。
#33
★★
框架對 GPU 加速的支持
硬體整合
主流框架都內建了對 NVIDIA GPU (使用 CUDA) 的支持,能夠利用 GPU 強大的並行計算能力來加速深度學習模型的訓練和推論。
#34
★★★★
深度學習的主要應用領域
應用範圍
深度學習在許多領域取得了顯著成功:計算機視覺(圖像分類、物體偵測、人臉辨識)、自然語言處理(機器翻譯、文本生成、情感分析)、語音識別、推薦系統、醫療影像分析、強化學習(遊戲、機器人)等。
#35
★★★★
深度學習的挑戰:數據需求
挑戰
深度學習模型通常需要大量標註好的數據才能達到良好性能。獲取和標註大規模數據集成本高昂且耗時,是應用深度學習的主要挑戰之一。樣題 Q15 也暗示數據標註品質是潛在問題。
#36
★★★★
深度學習的挑戰:計算成本
挑戰
訓練大型深度學習模型需要強大的計算資源(尤其是 GPU/TPU)和較長的訓練時間。模型部署時的推論成本也是需要考慮的因素。
#37
★★★★★
深度學習的挑戰:可解釋性 (Interpretability)
挑戰
深度學習模型通常被視為「黑盒子」,其內部決策過程難以理解和解釋。這在需要高可靠性、高風險或需要符合法規的應用場景(如醫療、金融)中是一個重大挑戰。可解釋 AI (XAI, Explainable Artificial Intelligence) 是一個活躍的研究領域。
#38
★★★★
深度學習的挑戰:模型穩健性 (Robustness)
挑戰
深度學習模型可能對輸入數據的微小擾動或對抗性攻擊 (Adversarial Attacks) 非常敏感,導致預測結果發生巨大變化。提高模型的穩健性是重要的研究方向。
#39
★★★★
深度學習的挑戰:倫理問題 (偏見、公平性)
挑戰
深度學習模型可能從訓練數據中學習並放大社會偏見,導致不公平或歧視性的結果。確保模型的公平性 (Fairness) 和符合倫理規範是一個關鍵挑戰。(參考 L234)
#40
★★
深度學習與大數據的關係
相互促進
大數據為深度學習提供了豐富的訓練材料,而深度學習則為從大數據中提取複雜模式和洞見提供了強大的工具。兩者相輔相成。(參考 L224)
#41
★★
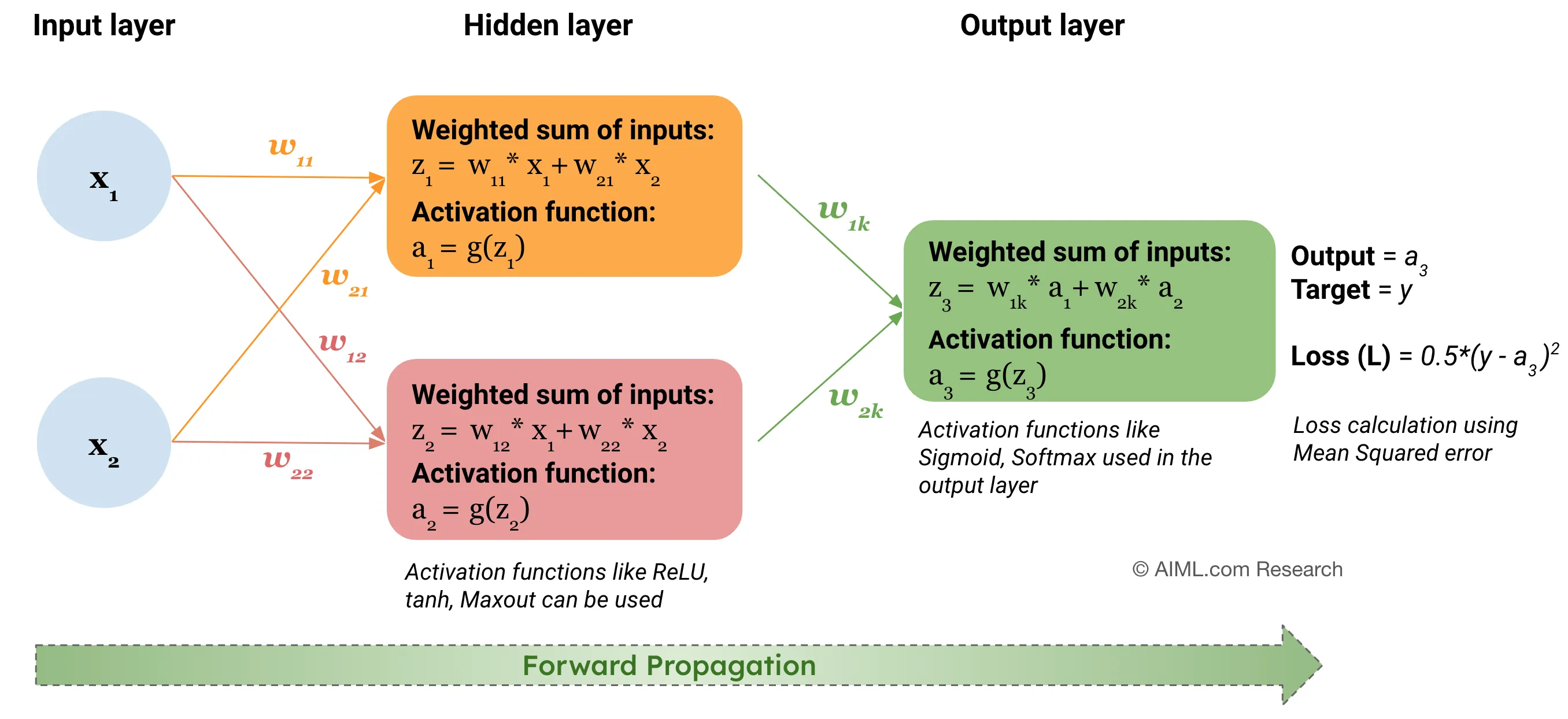
前向傳播 (Forward Propagation)
計算過程
在神經網路中,資訊從輸入層開始,逐層向前計算,經過加權、求和、激活函數處理,最終到達輸出層產生預測結果的過程。
#42
★★
殘差網路 (ResNet)
CNN 架構 (參考樣題 Q12 選項)
一種深度 CNN 架構,引入了殘差連接 (Residual Connections) 或捷徑連接 (Shortcut Connections),允許梯度更容易地流過深層網路,有效解決了深度網路訓練困難(退化)的問題,使得訓練非常深的網路成為可能。
#43
★★
局部最小值 (Local Minima) 問題
優化挑戰
梯度下降等優化算法可能陷入損失函數的局部最小值而非全局最小值。雖然在高維空間中,局部最小值問題可能不如鞍點 (Saddle Points) 問題嚴重,但仍是優化中的一個考量。動量和自適應優化器有助於緩解此問題。

#44
★
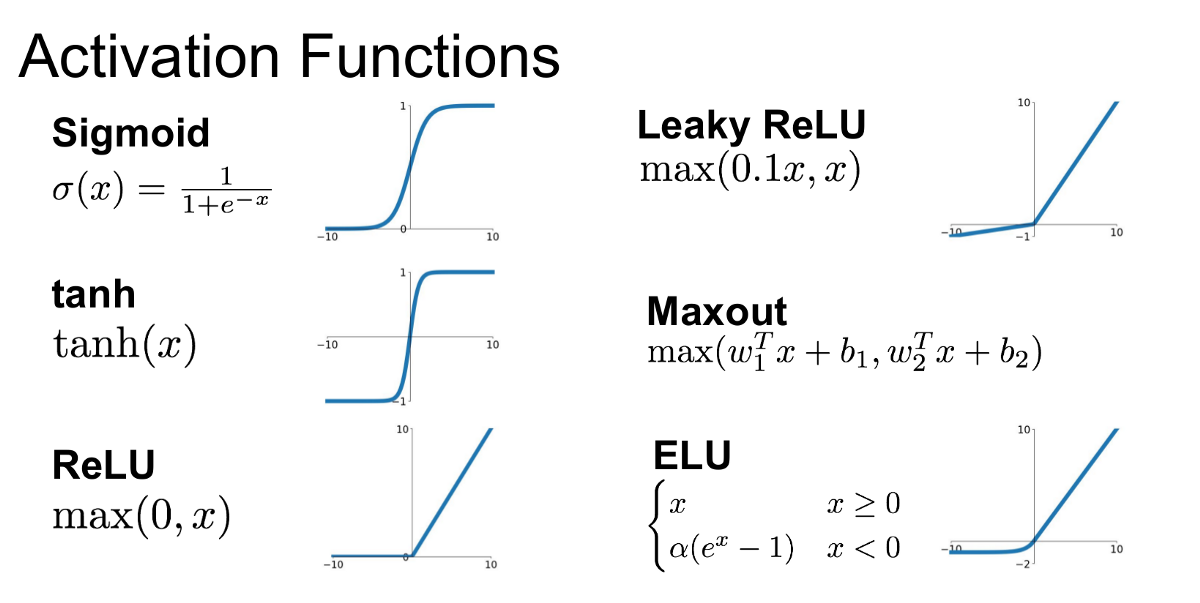
ReLU 的變體 (Leaky ReLU, ELU)
激活函數
Leaky ReLU 在負區間給予一個小的非零斜率;ELU (Exponential Linear Unit) 在負區間使用指數函數。這些變體旨在解決「死亡 ReLU」問題。
#45
★★
驗證集 (Validation Set) 在防止過擬合中的作用
作用機制
透過監控模型在獨立驗證集上的性能,可以在模型開始對訓練數據過擬合(驗證性能下降)時及早發現,並採取措施(如提早停止、調整超參數)。
#46
★
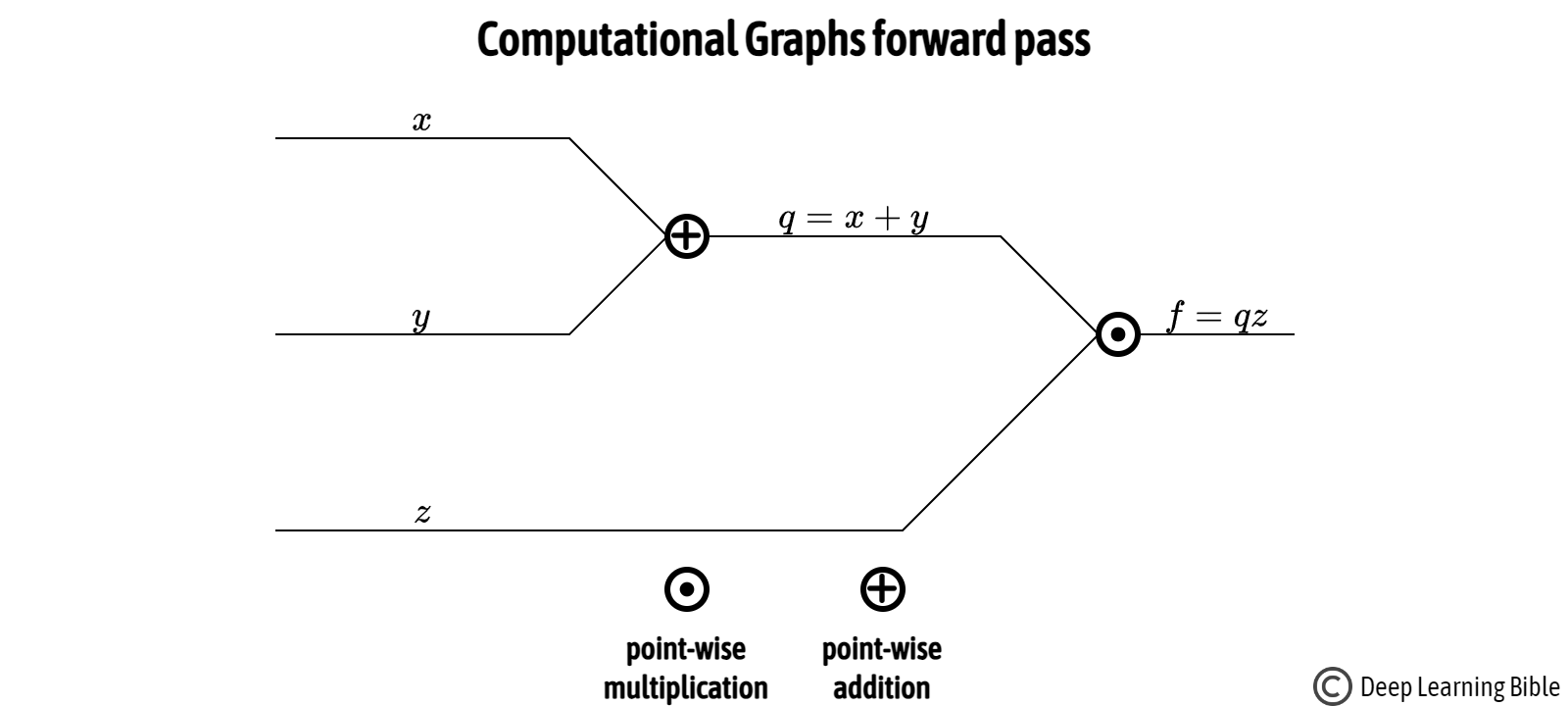
計算圖 (Computational Graph)
框架基礎
深度學習框架通常使用計算圖來表示模型中的計算流程。節點代表操作(如矩陣乘法、激活函數),邊代表數據(張量)。這使得自動微分和跨設備(CPU/GPU)分發計算更加容易。
#47
★★
遷移學習 (Transfer Learning)
應用策略
將在大規模數據集上預訓練好的模型(特別是其學到的特徵表示)應用到一個新的、相關但數據量較少的任務上。通常只需要微調模型的最後幾層或在其基礎上添加新的分類/迴歸層。是解決數據稀疏問題的有效方法。
#48
★
連接主義 (Connectionism)
思想基礎
人工神經網路的思想基礎之一,認為智能行為可以從大量簡單、相互連接的處理單元的集體活動中湧現出來。
| 人工智慧學派 (發展年代) |
核心理念 | 代表方法 |
|---|---|---|
| 符號主義 (Symbolism) (1950s-1980s) |
認為智能源於符號操作與邏輯推理,強調知識的明確表示與規則運算 | 專家系統、邏輯程式設計 |
| 連接主義 (Connectionism) (1980s-現今) |
認為智能來自於神經元之間的連接與互動,強調分散式表示與平行處理 | 類神經網路、深度學習 |
| 行為主義 (Behaviorism) (1990s-現今) |
強調智能體與環境的互動,認為智能表現在感知-動作的映射關係上 | 強化學習、行為機器人 |
#49
★
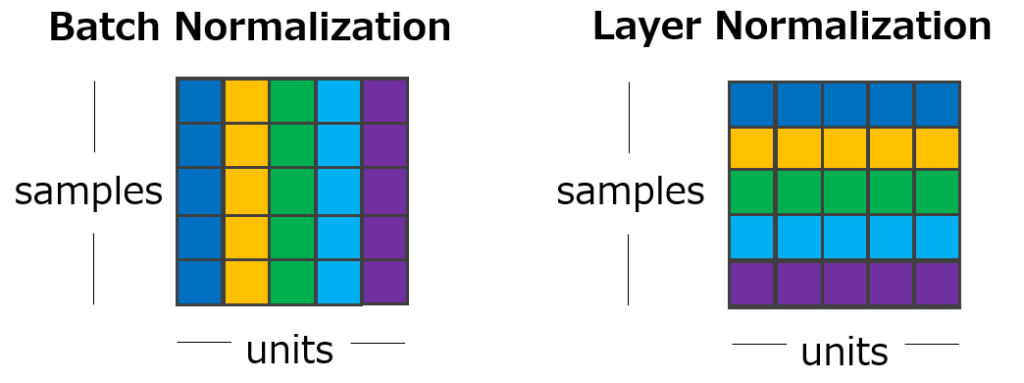
層正規化 (Layer Normalization)
正規化技術
與批次正規化類似,但在單個樣本的單個層內進行正規化,不受批次大小影響。常用於 RNN 和 Transformer。
#50
★
膠囊網路 (Capsule Network)
新興架構
一種試圖克服 CNN 缺點(如對視角變化敏感)的新型架構,使用「膠囊」來表示實體的不同屬性。
#51
★
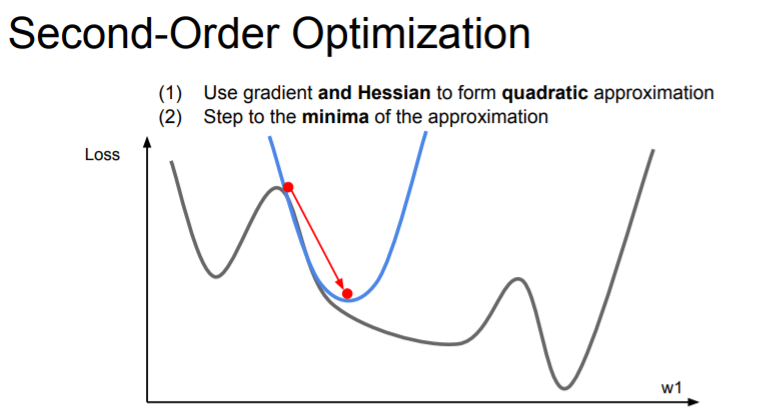
二階優化方法 (Second-order Optimization)
優化方法
除了基於一階梯度的方法,還有利用二階導數(Hessian 矩陣)資訊的優化方法(如牛頓法)。理論上收斂更快,但計算 Hessian 矩陣及其逆矩陣的成本非常高,在大規模深度學習中較少直接使用。
#52
★
Focal Loss
損失函數
交叉熵損失的一種變體,旨在解決類別極度不平衡問題(特別是在物體偵測中)。它會降低容易分類樣本的權重,讓模型更專注於困難樣本。
#53
★
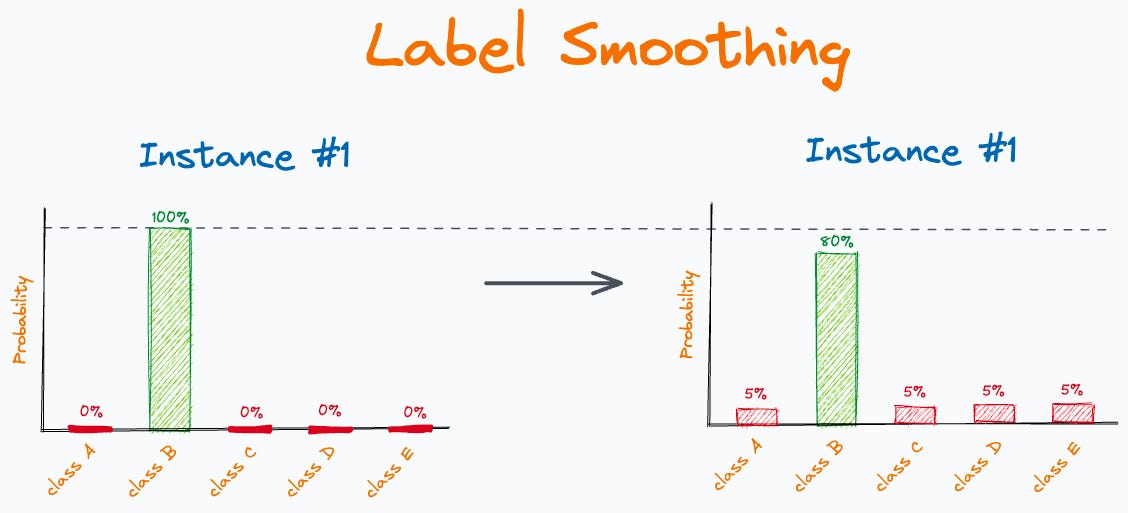
標籤平滑 (Label Smoothing)
正則化技術
一種用於分類問題的正則化技術。將原本的硬標籤(one-hot 編碼,如 [0, 1, 0])替換為軟標籤(如 [0.05, 0.9, 0.05]),即在正確類別上分配稍低的機率,其他類別分配一個小的正機率。有助於防止模型過於自信,提高泛化能力。
#54
★
ONNX (Open Neural Network Exchange)
模型交換格式
一個開放的模型表示格式,旨在實現不同深度學習框架之間的模型互操作性。可以將一個框架訓練的模型轉換為 ONNX 格式,然後在另一個支持 ONNX 的框架或推論引擎中運行。
#55
★
對抗性訓練 (Adversarial Training)
訓練策略
一種提高模型穩健性的方法,在訓練過程中加入由對抗性攻擊生成的樣本,迫使模型學習對抗這些擾動。
#56
★
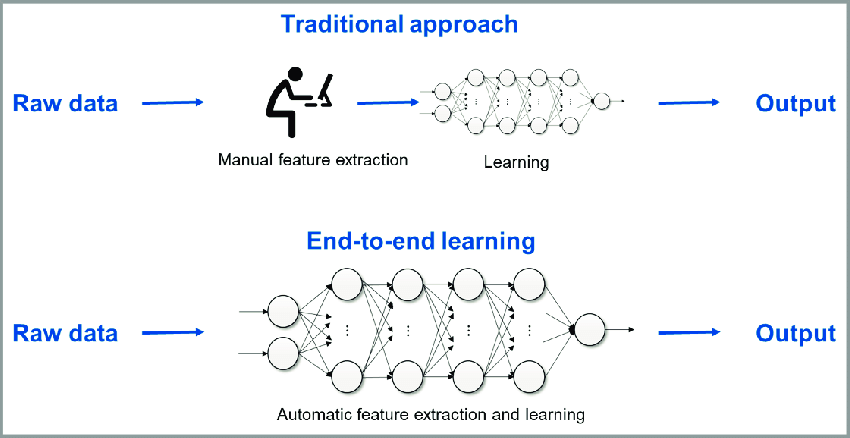
端到端學習 (End-to-End Learning)
學習範式
深度學習常採用端到端學習,即直接從原始輸入學習到最終輸出,中間的特徵提取和轉換過程都由網路自動完成,減少了對手動特徵工程的依賴。
#57
★
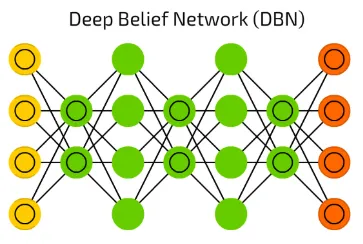
深度信念網路 (DBN, Deep Belief Network)
早期架構
一種早期的深度學習生成模型,由多層受限波茲曼機 (RBM) 堆疊而成,常使用逐層貪婪預訓練。
#58
★
梯度裁剪 (Gradient Clipping)
訓練技巧
為了防止梯度爆炸問題,在反向傳播過程中,如果梯度的範數超過某個閾值,就將其縮放到該閾值。常用於訓練 RNN。
#59
★
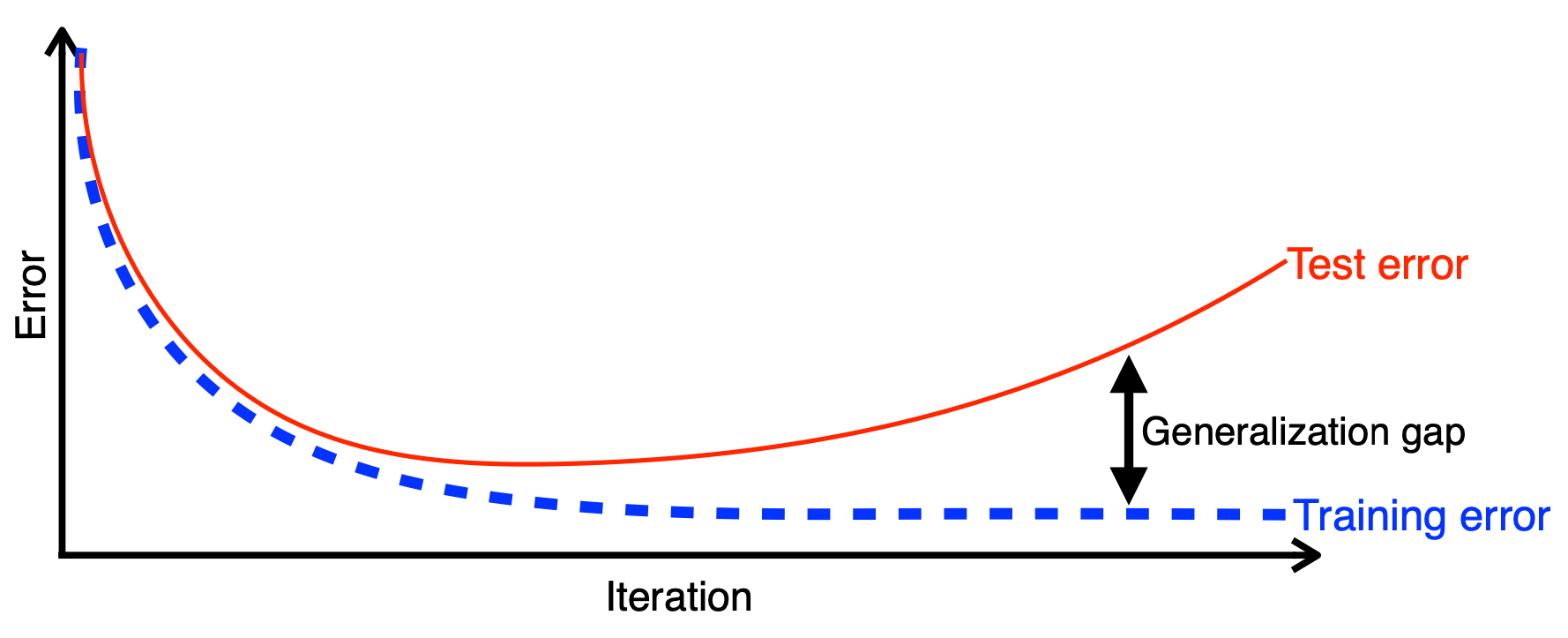
模型容量與泛化差距 (Generalization Gap)
概念
泛化差距指模型在訓練集上的誤差與在測試集上的誤差之間的差異。過擬合時,泛化差距會很大。模型容量過高是導致泛化差距增大的原因之一。
#60
★
模型伺服 (Model Serving) 框架
部署工具
用於將訓練好的深度學習模型部署到生產環境並提供預測服務的專用框架,例如 TensorFlow Serving, TorchServe, Triton Inference Server。它們提供了高性能推論、模型版本管理、批處理等功能。
沒有找到符合條件的重點。
↑