iPAS AI應用規劃師 經典題庫
L23201 機器學習原理與技術
出題方向
1
機器學習概論與類型
2
監督式學習:回歸
3
監督式學習:分類
4
非監督式學習:分群
5
非監督式學習:降維
6
模型評估、選擇與調校
7
特徵工程與資料預處理
8
系集學習與進階概念
#1
★★★★★
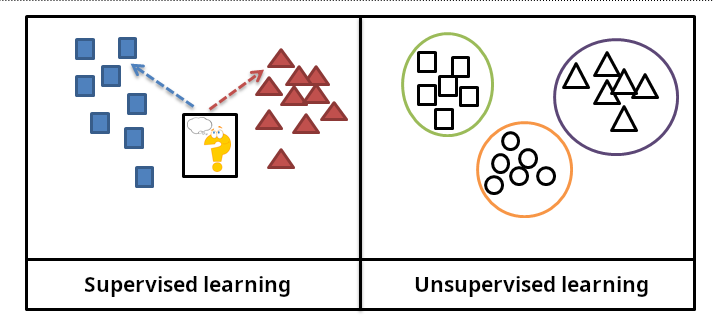
下列哪項最能描述監督式學習(Supervised Learning)的特點?
答案解析
監督式學習是機器學習最主要的類型之一。其核心特徵是訓練數據包含成對的輸入(特徵)和對應的正確輸出(標籤或目標值)。模型的目標是學習一個從輸入到輸出的映射函數 f,使得對於新的、未見過的輸入 x,模型能夠預測出接近真實輸出的 y。根據輸出的類型,監督式學習可以分為:
- 分類 (Classification):輸出是離散的類別標籤(如「貓」、「狗」;「垃圾郵件」、「非垃圾郵件」)。
- 迴歸 (Regression):輸出是連續的數值(如房價、溫度、銷售額)。
#2
★★★★
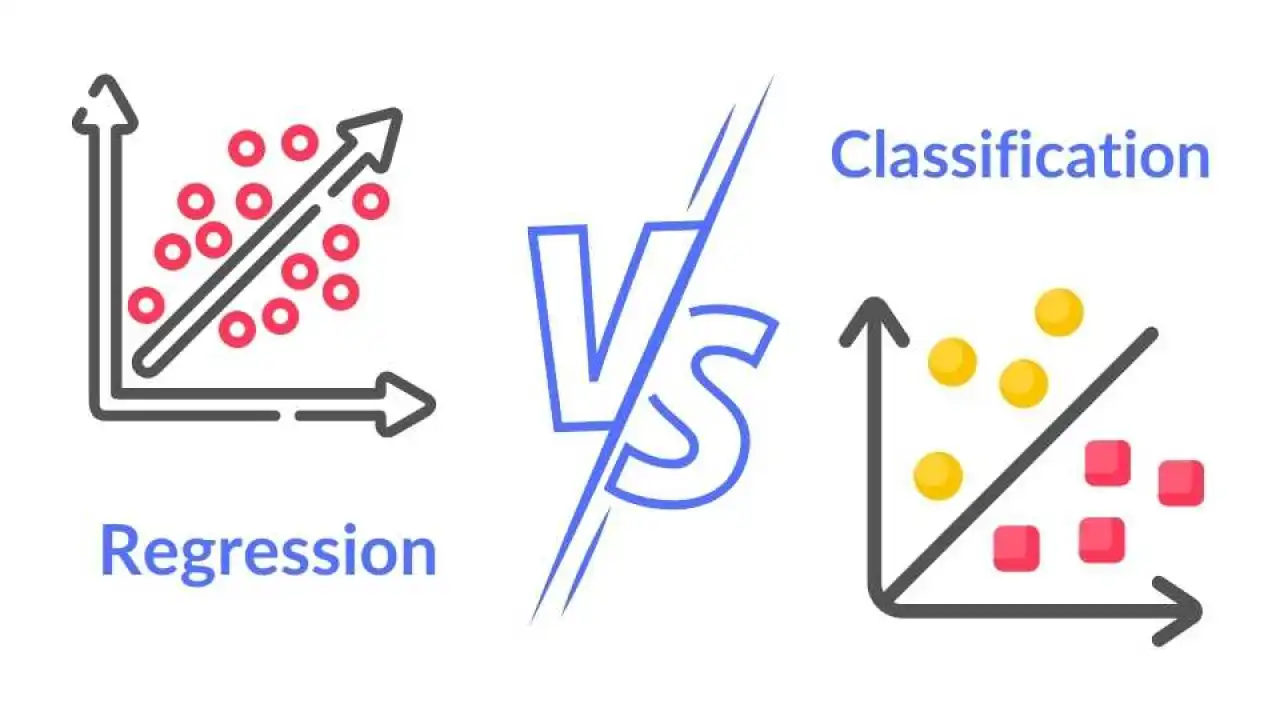
預測房屋的價格(一個連續數值),根據房屋的大小、位置、屋齡等特徵,這屬於哪種類型的機器學習問題?
答案解析
迴歸問題的目標是預測一個連續的數值輸出。在這個例子中,房屋價格是一個連續變數,我們希望根據輸入的特徵(大小、位置、屋齡等)來預測這個數值。因此,這是一個典型的迴歸問題。分類問題的目標是預測離散的類別標籤(例如,預測房屋是「豪華」還是「普通」)。分群和降維屬於非監督式學習,不需要標籤。
#3
★★★★
判斷一封電子郵件是否為垃圾郵件(是/否),這屬於哪種類型的機器學習問題?
答案解析
分類問題的目標是將輸入數據分配到預定義的離散類別中。在這個例子中,我們需要將每封電子郵件歸類為兩個類別之一:「垃圾郵件」或「非垃圾郵件」。由於輸出是離散的類別標籤,這是一個典型的二元分類 (Binary Classification) 問題。
#4
★★★★
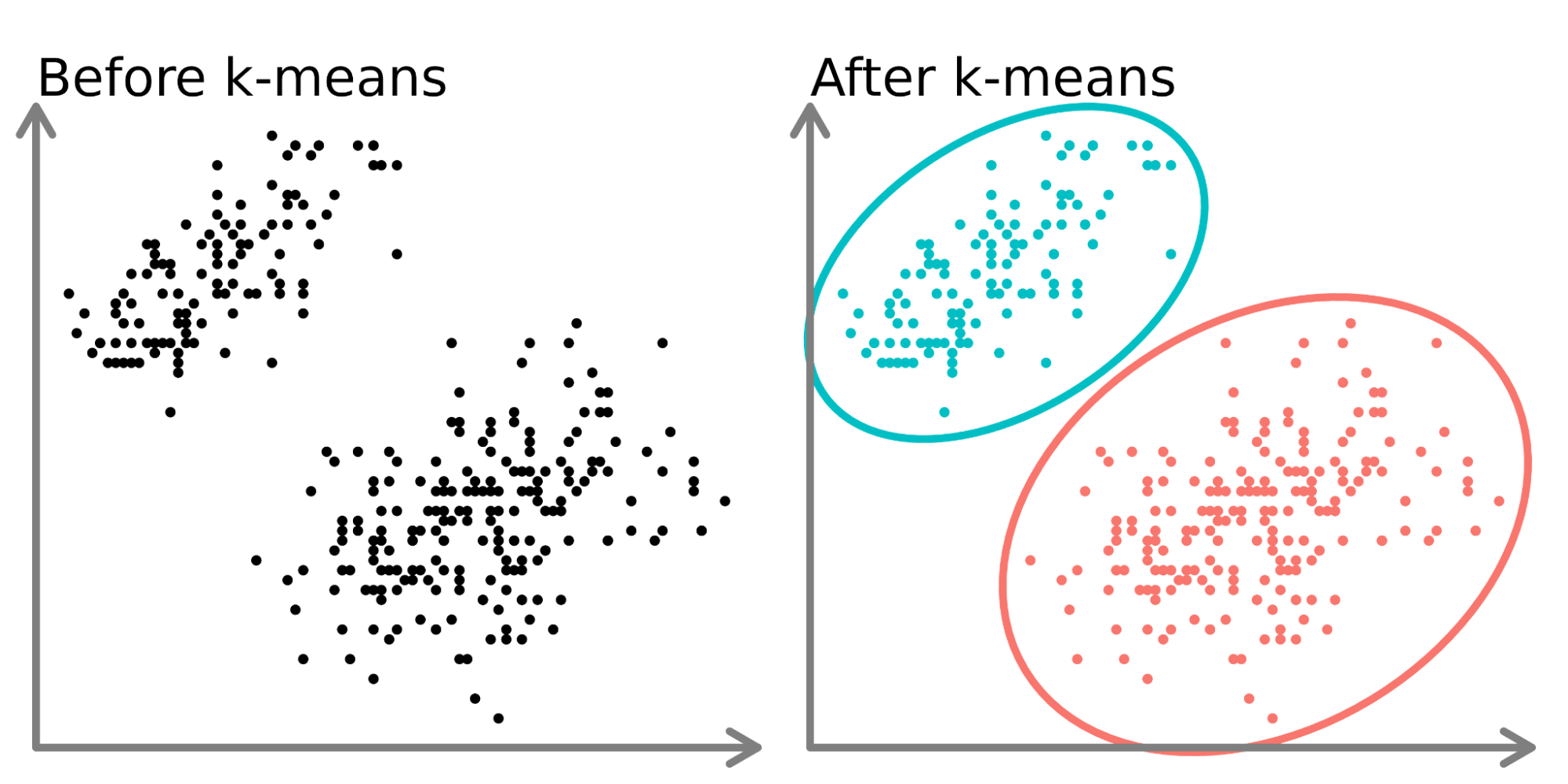
K-means 演算法是一種常用的機器學習技術,主要用於解決哪類問題?
答案解析
K-means 是一種非監督式學習算法,其目標是將未標註的數據點劃分成 K 個不同的群集 (Clusters)。它通過迭代地將每個數據點分配給最近的群集中心(質心 Centroid),然後重新計算每個群集的中心,直到群集分配不再變化或達到最大迭代次數。由於它不需要預先標註的數據,而是試圖從數據本身中發現潛在的群組結構,因此屬於非監督式分群。
#5
★★★★★
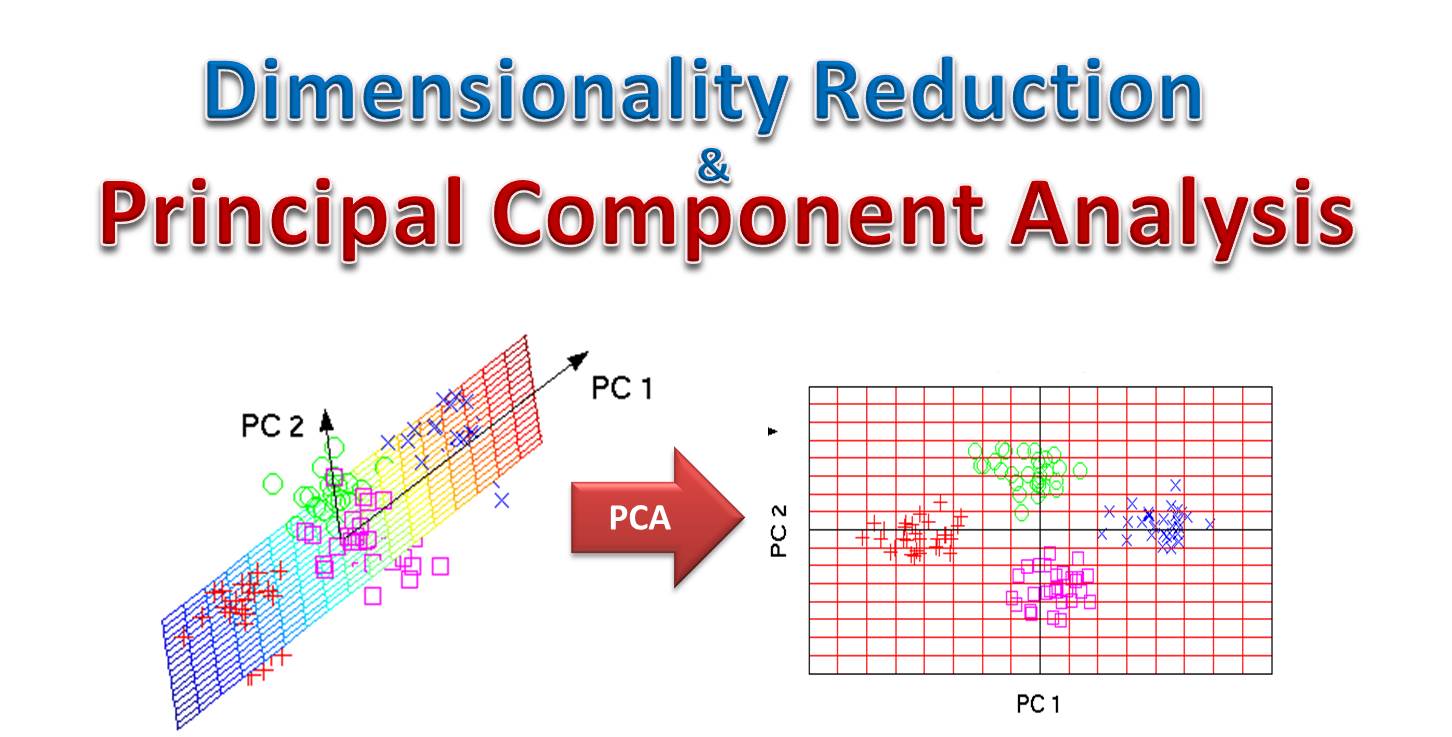
主成分分析 (Principal Component Analysis, PCA) 主要用於機器學習中的哪個目的?
答案解析
PCA 是一種非監督式學習技術,主要用於降維。它通過找到一組新的正交座標軸(主成分),這些座標軸能夠捕捉數據中最大變異的方向。通過只保留前幾個最重要的主成分,可以將高維數據投影到一個低維空間,同時損失盡可能少的信息(變異)。PCA 常被用作數據預處理步驟,以減少特徵數量、去除冗餘、壓縮數據、方便視覺化或提高後續模型的性能。預測標籤是分類(A),預測數值是迴歸(B),分群是聚類(D)。
#6
★★★★★
在機器學習中,將數據集劃分為訓練集 (Training Set)、驗證集 (Validation Set) 和測試集 (Test Set) 的主要目的是什麼?
答案解析
為了客觀地評估模型性能並避免過擬合,通常需要將數據集進行劃分:
- 訓練集 (Training Set):用於訓練模型,即調整模型的內部參數(如權重、偏置)。
- 驗證集 (Validation Set):用於在模型訓練過程中或訓練後,評估不同模型架構或不同超參數(如學習率、正規化強度、隱藏層單元數)組合的性能,以便選擇最佳的模型配置。它模擬了未見數據,幫助檢測過擬合。
- 測試集 (Test Set):在模型選擇和超參數調整完成後,使用測試集對最終選定的模型進行一次性的評估,得到模型在完全未見過的數據上的泛化性能的最終估計。測試集不應參與任何訓練或調優過程,以保證評估的公正性。
#7
★★★★
獨熱編碼 (One-Hot Encoding) 是一種常用的數據預處理技術,主要用於處理哪種類型的特徵?
答案解析
許多機器學習算法(尤其是基於距離或線性模型的算法)無法直接處理類別型特徵。獨熱編碼是一種將名目類別特徵(即類別之間沒有內在順序關係,如「顏色:紅、綠、藍」或「城市:台北、台中、高雄」)轉換為數值形式的方法。對於一個具有 k 個可能類別的特徵,獨熱編碼會創建 k 個新的二元(0或1)特徵。對於每個樣本,只有對應其原始類別的新特徵值為 1,其餘 k-1 個新特徵值都為 0。例如,「顏色」特徵,「紅」可能被編碼為 [1, 0, 0],「綠」為 [0, 1, 0],「藍」為 [0, 0, 1]。這種表示方式避免了算法錯誤地假設類別之間存在數值大小或順序關係。對於有序類別特徵(如「滿意度:低、中、高」),有時會使用標籤編碼 (Label Encoding) 或其他方法。
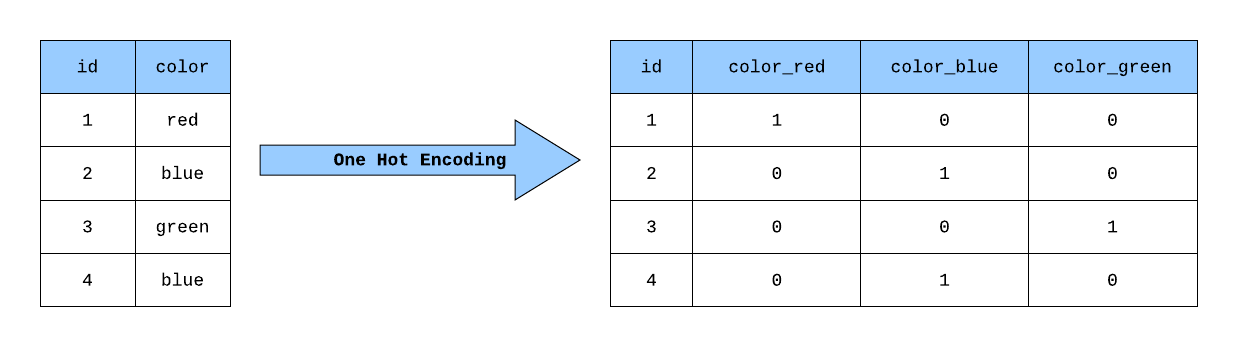
#8
★★★★
隨機森林 (Random Forest) 是一種系集學習 (Ensemble Learning) 方法,它通過結合多個什麼基學習器 (Base Learner) 來進行預測?
答案解析
隨機森林是基於 Bagging (Bootstrap Aggregating) 思想的系集學習算法,其基學習器是決策樹。它構建多個決策樹,每棵樹的訓練過程引入了兩種隨機性:
- 樣本隨機性:每棵樹使用通過自助法 (Bootstrap) 從原始訓練集中隨機抽樣得到的樣本子集進行訓練。
- 特徵隨機性:在每個節點分裂時,不是考慮所有特徵,而是從中隨機選擇一部分特徵(例如,總特徵數的平方根)來尋找最佳分裂點。
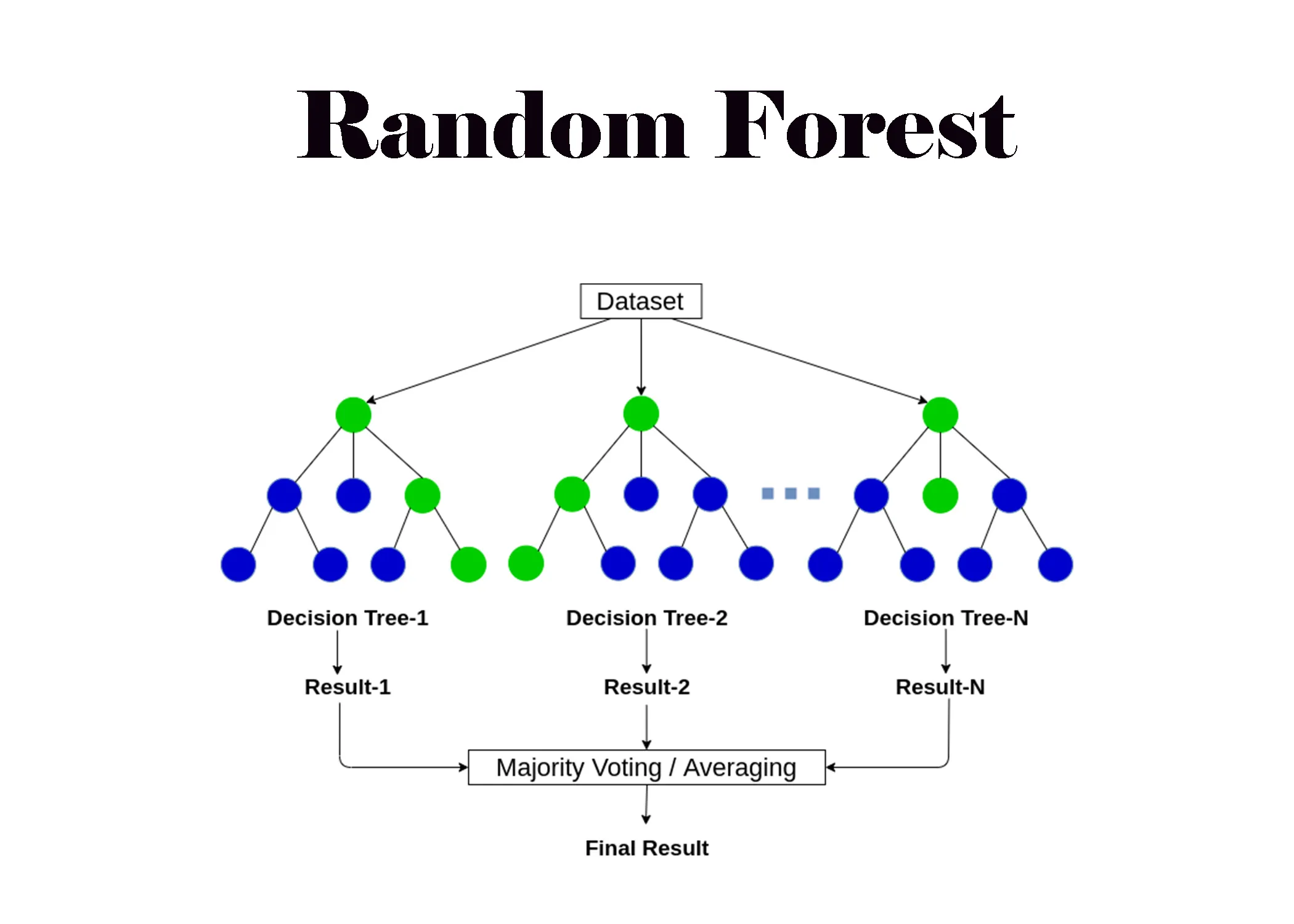
#9
★★★★
過擬合 (Overfitting) 指的是機器學習模型在哪個數據集上表現良好,但在哪個數據集上表現較差?
答案解析
過擬合是機器學習中常見的問題。當模型過於複雜或訓練數據不足時,模型可能會學習到訓練數據中特有的噪聲或隨機模式,而不是潛在的、具有泛化性的規律。這導致模型在訓練集上能夠取得非常低的誤差(表現很好),但當遇到新的、未在訓練中出現過的數據時,其預測性能會顯著下降(表現很差)。這表明模型未能很好地泛化 (Generalize) 到新數據。相對應的是欠擬合 (Underfitting),指模型過於簡單,連訓練數據中的基本模式都未能很好地捕捉,導致在訓練集和測試集上表現都不佳。
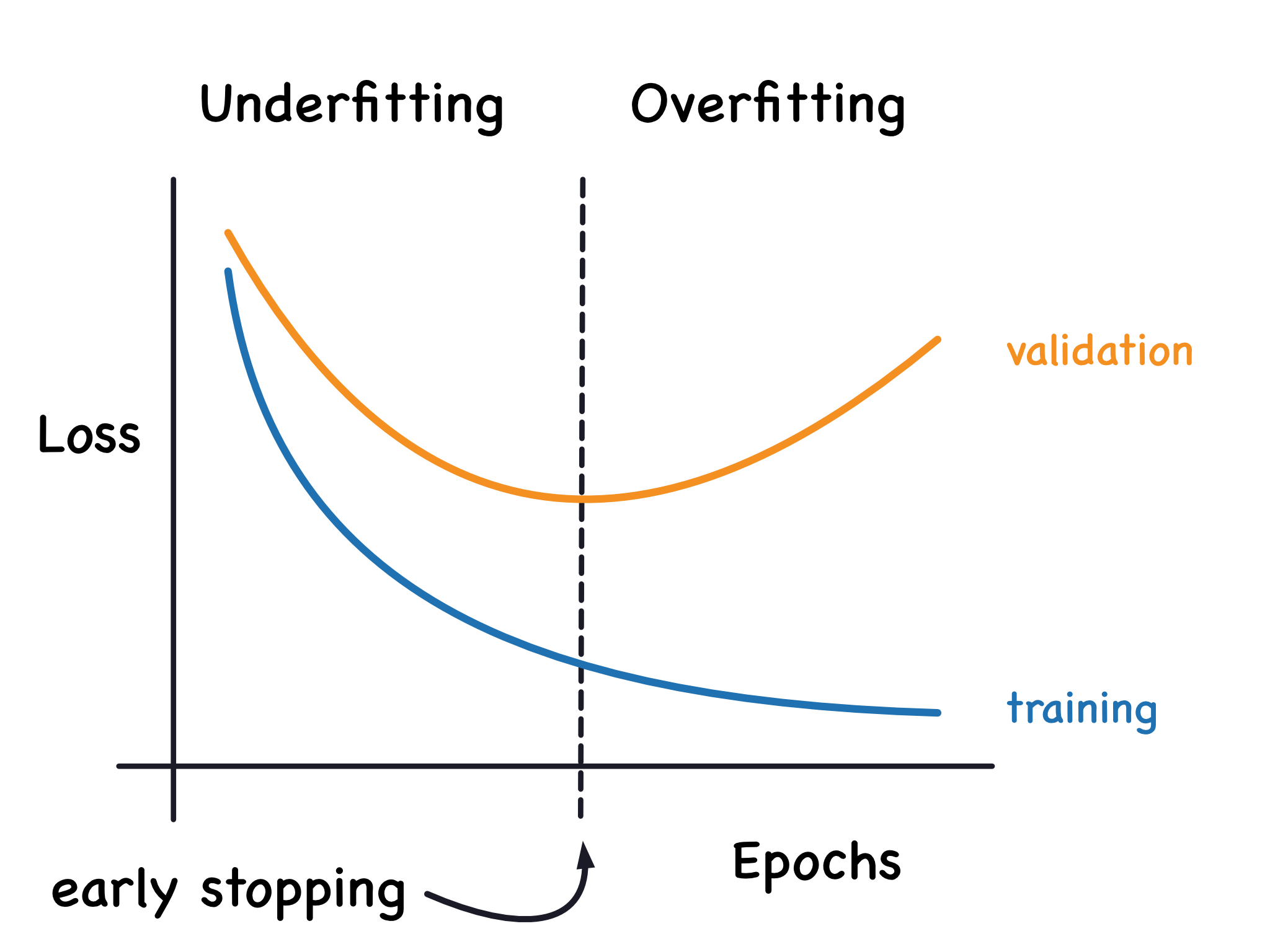
#10
★★★
特徵縮放 (Feature Scaling),例如標準化 (Standardization) 或歸一化 (Normalization),在應用於某些機器學習算法之前通常是必要的,主要原因是?
答案解析
許多機器學習算法對輸入特徵的尺度敏感,特別是:
- 基於距離的算法:如 K-近鄰 (KNN)、K-means、支持向量機 (SVM) 等,距離計算會被數值範圍大的特徵所主導。
- 基於梯度下降的算法:如線性迴歸、邏輯迴歸、神經網路等,不同尺度的特徵可能導致損失函數的等高線圖呈橢圓形,使得梯度下降收斂緩慢或困難。
- 標準化 (Standardization):將特徵轉換為均值為 0,標準差為 1 的分佈 (Z-score: (x - μ) / σ)。
- 歸一化 (Normalization) / 最小-最大縮放 (Min-Max Scaling):將特徵縮放到 [0, 1] 或 [-1, 1] 的區間(例如:(x - min) / (max - min))。
#11
★★★★
強化學習 (Reinforcement Learning, RL) 與監督式和非監督式學習的主要區別在於其學習方式基於?
答案解析
強化學習關注的是智能代理 (Agent) 如何在一個環境 (Environment) 中學習做出一系列決策(動作 Actions),以最大化其獲得的長期累積獎勵。代理不是被告知「正確」的動作(像監督學習那樣),而是通過試錯 (Trial-and-Error) 來學習。代理執行一個動作後,環境會轉移到一個新的狀態 (State),並給予代理一個立即的回饋信號(獎勵 Reward 或懲罰 Penalty)。代理的目標是學習一個策略 (Policy),即在特定狀態下選擇哪個動作,才能使得從長遠來看獲得的總獎勵最大化。這種通過與環境互動和獎勵信號來學習的方式是強化學習的獨特之處,適用於遊戲(如 AlphaGo)、機器人控制、資源調度等問題。
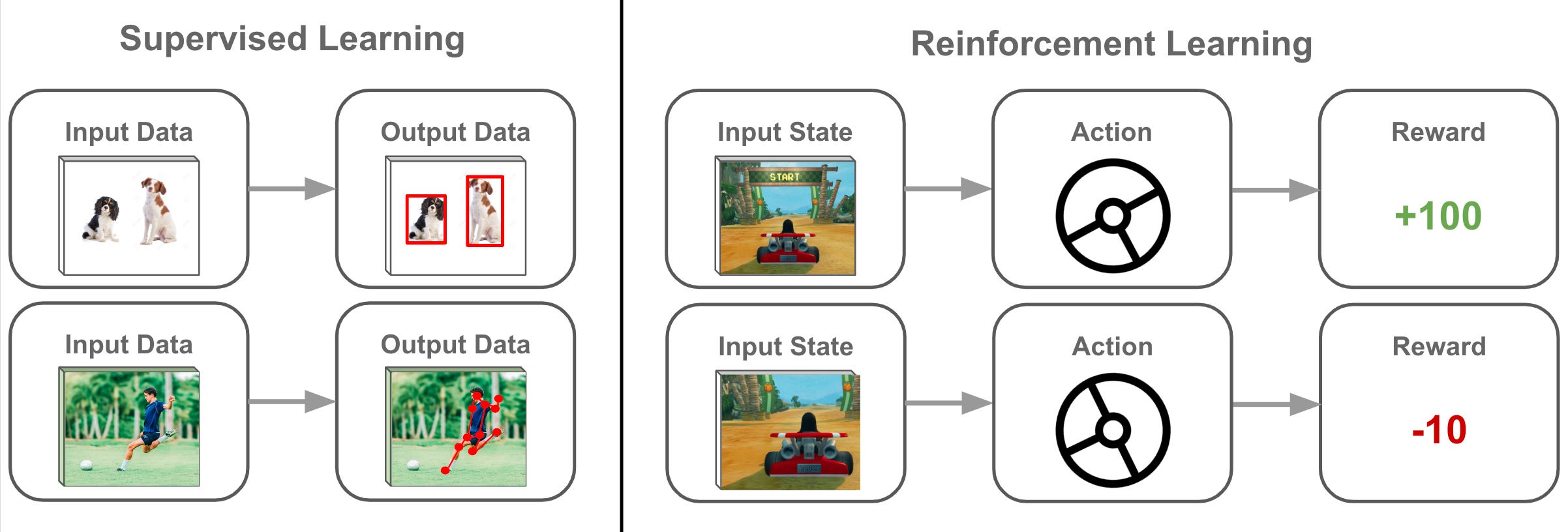
#12
★★★
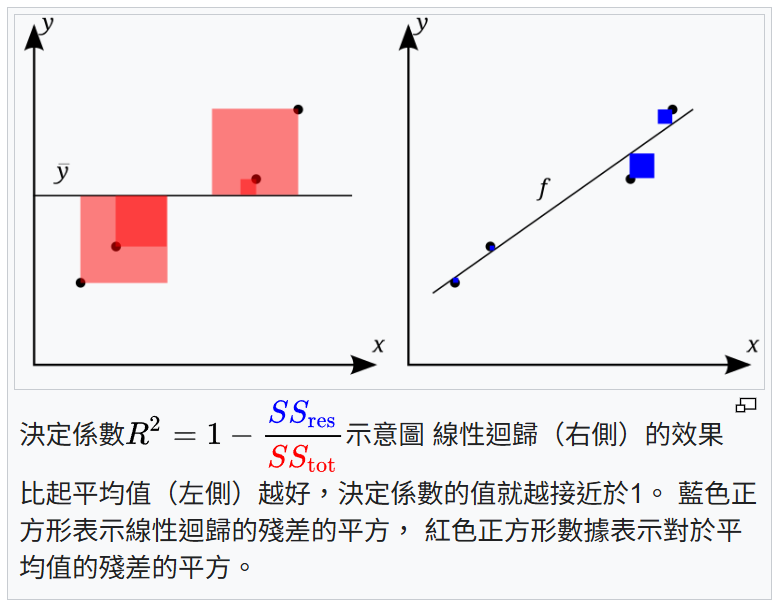
在線性回歸中,常用來評估模型擬合優度 (Goodness of Fit) 的一個指標是 R 平方 (R-squared) 或稱決定係數 (Coefficient of Determination)。R 平方的值越接近 1 代表什麼?
答案解析
R 平方衡量的是迴歸模型對應變數 y 的總變異能夠解釋的百分比。其計算公式為 R² = 1 - (SSR / SST),其中 SSR (Sum of Squared Residuals) 是殘差平方和(模型未能解釋的變異),SST (Total Sum of Squares) 是總平方和(y 的總變異,相對於其平均值)。R 平方的取值範圍通常在 0 到 1 之間(也可能為負,如果模型比簡單預測平均值還差)。R² 越接近 1,表示模型解釋了 y 的大部分變異性,擬合效果越好;R² 越接近 0,表示模型幾乎沒有解釋 y 的變異。需要注意的是,R² 會隨著模型中自變數數量的增加而增加(即使增加的變數不相關),因此在比較不同模型時,調整後的 R 平方 (Adjusted R-squared) 可能是一個更合適的指標,它對模型參數數量進行了懲罰。
#13
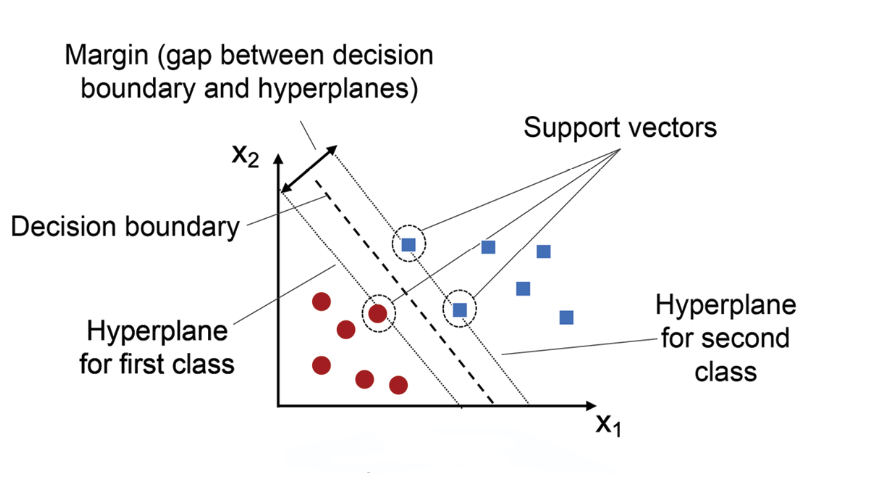
★★★
支持向量機 (Support Vector Machine, SVM) 最初是為了解決哪類問題而設計的?
答案解析
SVM 最早被提出是用於解決二元分類問題。其核心思想是找到一個能夠將兩類數據點分開,並且使得兩類之間間隔 (Margin) 最大化的決策邊界(超平面 Hyperplane)。對於線性不可分的數據,SVM 可以通過引入核技巧 (Kernel Trick) 將數據映射到更高維的特徵空間,在該空間中尋找線性分隔超平面,從而實現非線性分類。雖然 SVM 後來也被擴展到解決迴歸問題(支持向量迴歸, SVR)和多類分類問題,但其最基礎和最經典的應用是二元分類。
#14
★★★
階層式分群 (Hierarchical Clustering) 與 K-means 分群的主要區別在於?
答案解析
K-means 是一種劃分式分群 (Partitional Clustering) 方法,它將數據點直接劃分成 K 個互斥的群集,需要用戶事先指定群集的數量 K。而階層式分群則不同,它會構建一個群集的層次結構。有兩種主要方式:
- 凝聚式 (Agglomerative) / 由下而上 (Bottom-up):開始時每個數據點自成一群,然後逐步合併最相似(距離最近)的兩個群集,直到所有點合併為一個大群或達到某個停止條件。
- 分裂式 (Divisive) / 由上而下 (Top-down):開始時所有數據點在一個大群中,然後逐步將群集分裂成更小的群集,直到每個點自成一群或達到某個停止條件。

#15
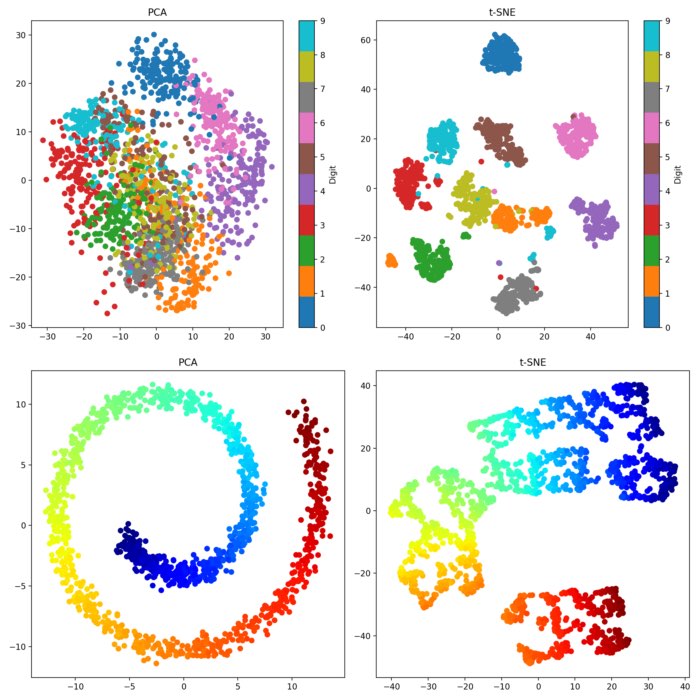
★★★
t-分佈隨機鄰近嵌入 (t-Distributed Stochastic Neighbor Embedding, t-SNE) 是一種常用的非線性降維技術,特別擅長用於什麼目的?
答案解析
t-SNE 是一種非線性降維算法,其主要目標是將高維數據點之間的相似性關係(在高維空間中,點 i 將以某個機率選擇點 j 作為其鄰居)在低維空間(通常是 2D 或 3D)中進行建模和再現(在低維空間中,點 i 也以某個機率選擇點 j 作為鄰居,這個機率使用 t-分佈來計算)。它特別擅長揭示高維數據中存在的局部結構和聚類模式,並將其以視覺上分離的形式展現出來。因此,t-SNE 最常用於高維數據集的探索性視覺化分析。但需要注意:(1) t-SNE 的計算成本相對較高。(2) 它主要關注保留局部結構,可能無法很好地保留全局結構。(3) 不同的超參數(如 Perplexity)設置會影響結果。(4) 它通常不適合用於後續的密度估計或異常檢測,主要用於視覺探索。
#16
★★★
超參數 (Hyperparameter) 與模型參數 (Model Parameter) 的主要區別是?
答案解析
這是機器學習中的一個基礎區分:
- 模型參數 (Model Parameters):這些是模型內部用來進行預測的變數,它們的值是通過學習算法在訓練數據上學習得到的。例如,線性迴歸的係數 β,神經網路的權重 W 和偏置 b。模型參數的數量可以非常多。
- 超參數 (Hyperparameters):這些是學習算法本身的參數,它們的值需要在訓練開始之前由用戶設定,而不是從數據中學習。超參數控制著學習過程的行為和模型的結構。例如,梯度下降的學習率 η,正規化的強度 λ,SVM 的懲罰係數 C 和核函數參數,決策樹的最大深度,K-means 的群數 K,神經網路的層數和每層單元數等。
#17
★★
處理數據中的缺失值 (Missing Values) 時,下列哪種方法最不推薦直接使用,尤其是在缺失比例較高時?
答案解析
處理缺失值有多種方法:
- 刪除法:可以直接刪除包含缺失值的樣本(行)或整個特徵(列)。刪除樣本 (Listwise Deletion) 是最簡單的方法,但如果缺失值廣泛存在(比例較高),會導致丟失大量有價值的信息,減少可用樣本量,甚至可能引入偏見(如果缺失不是完全隨機的)。刪除特徵則會丟失該特徵的所有信息。
- 填充法 (Imputation):用一個估計值來替換缺失值。簡單的方法是用該特徵的均值、中位數(對抗離群值更魯棒)或眾數(用於類別特徵)填充。更複雜的方法包括使用其他特徵通過迴歸模型預測缺失值,或者使用 K-近鄰算法找到相似樣本的值來填充 (KNN Imputer)。
#18
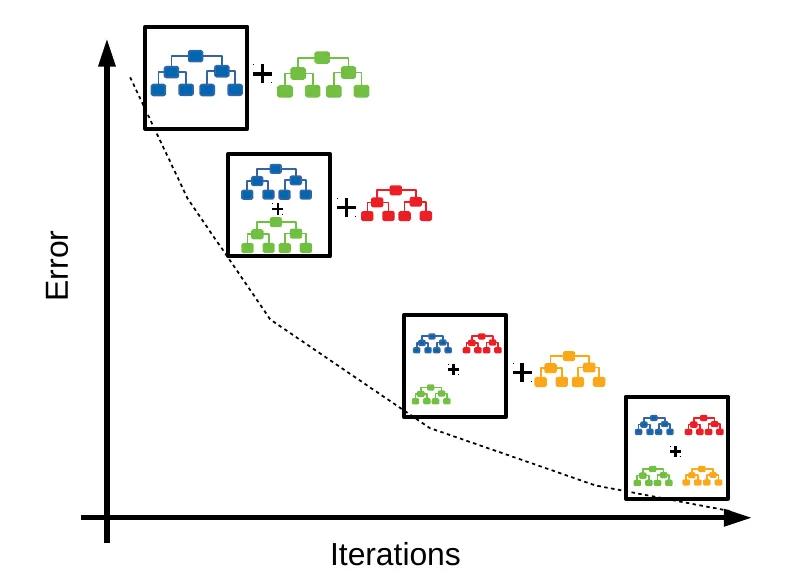
★★★
梯度提升決策樹 (Gradient Boosting Decision Tree, GBDT) 是一種強大的系集學習算法。它與隨機森林的主要區別在於其構建樹的方式是?
答案解析
隨機森林(基於 Bagging)是並行地訓練多棵獨立的決策樹,然後將它們的結果匯總。而梯度提升 (Gradient Boosting) 則是一種循序漸進的系集方法。它從一個簡單的初始模型(例如,預測平均值)開始,然後迭代地添加新的基學習器(通常是決策樹),每一棵新樹的目標是擬合前面模型預測結果的殘差(對於平方損失)或者更一般地說是損失函數的負梯度。通過逐步修正錯誤,梯度提升模型能夠構建出非常強大的預測模型。由於是循序構建,GBDT 通常比隨機森林更容易過擬合,需要仔細調整超參數(如樹的數量、深度、學習率)。XGBoost、LightGBM 和 CatBoost 是 GBDT 的高效實現和改進版本。
#19
★★
機器學習中常提到的「沒有免費的午餐定理」(No Free Lunch Theorem) 指的是什麼?
答案解析
「沒有免費的午餐定理」在優化和機器學習領域指出,如果考慮所有可能的問題(或數據生成分佈),那麼沒有任何一種特定的算法能夠在平均性能上優於其他所有算法。換句話說,不存在一個「萬能」的、在所有情況下都表現最好的機器學習模型或算法。一個算法在某類問題上表現出色,可能在另一類問題上表現平平或很差。這強調了理解問題特性、數據分佈以及不同算法的假設、優缺點的重要性,並需要根據具體情況選擇或定製合適的算法。
#20
★★★
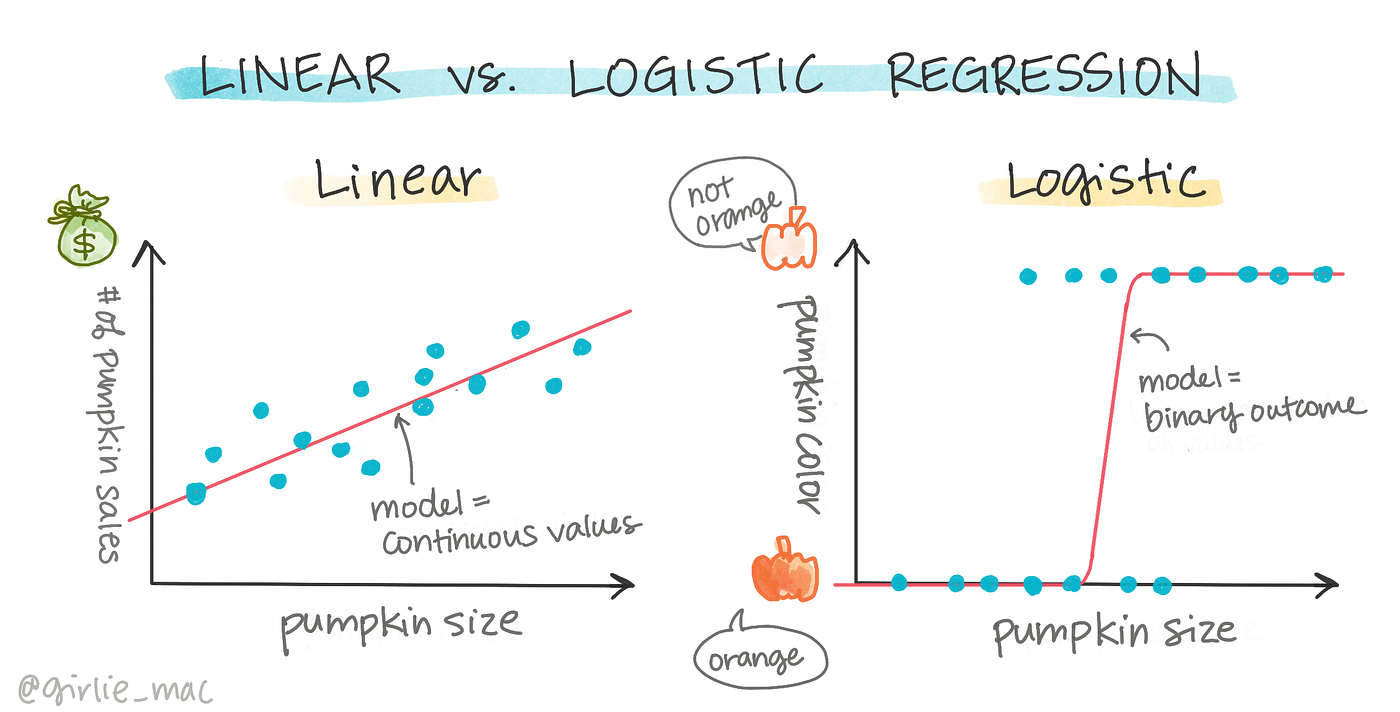
邏輯回歸 (Logistic Regression) 雖然名字中帶有「回歸」,但它主要用於解決哪類問題?
答案解析
儘管名稱包含「回歸」,邏輯回歸實際上是一種廣泛使用的分類算法。它通過 Sigmoid 函數將線性模型的輸出映射到 (0, 1) 區間,得到樣本屬於正類的機率。然後可以設定一個閾值(例如 0.5),將機率大於閾值的樣本預測為正類,小於閾值的預測為負類。因此,它的最終輸出是離散的類別標籤,用於解決分類問題,尤其是二元分類。它也可以擴展到多類分類(例如通過 One-vs-Rest 或 Softmax 回歸)。
#21
★★
在評估分群 (Clustering) 結果的品質時,如果我們沒有真實的類別標籤(非監督式場景),可以使用哪類指標?
答案解析
由於分群是非監督式學習,通常沒有「正確答案」(真實標籤)來直接比較。因此,評估分群結果需要使用不同的指標:
- 內部指標 (Internal Indices):僅基於分群結果本身的數據(不需要外部標籤)來評估群集的品質。它們通常衡量群集內部的緊密度 (Intra-cluster Cohesion) 和群集之間的分離度 (Inter-cluster Separation)。例如:
- 輪廓係數 (Silhouette Coefficient):衡量每個樣本與其自身群集的緊密度以及與最近的其他群集的分離度。值域 [-1, 1],越接近 1 越好。
- Calinski-Harabasz (CH) 指數:計算類間散度與類內散度之比,值越大越好。
- Davies-Bouldin (DB) 指數:計算任意兩個類別內樣本平均距離之和除以類別中心點距離,值越小越好。
- 外部指標 (External Indices):如果存在真實的類別標籤(例如,作為評估基準),則可以使用外部指標來比較分群結果與真實類別的一致性。例如:調整後蘭德指數 (Adjusted Rand Index, ARI)、調整後互信息 (Adjusted Mutual Information, AMI)、同質性 (Homogeneity)、完整性 (Completeness)、V-measure 等。
#22
★★
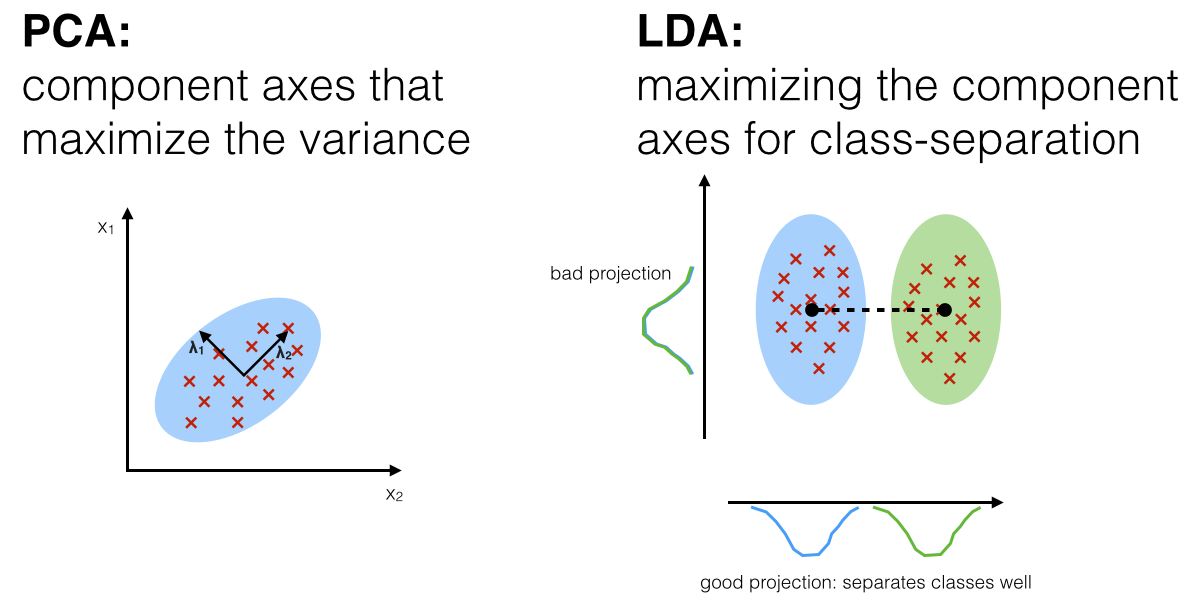
線性判別分析 (Linear Discriminant Analysis, LDA) 除了用於分類,也常被用作一種什麼技術?
答案解析
LDA 的主要目標是找到一個低維投影空間,使得投影後不同類別的數據能夠最大程度地分開(最大化類間散度/類內散度比)。因此,LDA 不僅可以直接用於分類(例如,將樣本投影到低維空間後,根據其位置判斷類別),也常被用作一種有監督的降維技術。與無監督的 PCA 不同,LDA 在降維過程中利用了類別標籤信息,旨在找到最有利於區分類別的低維表示。降維後的維度最多為 C-1(其中 C 是類別數量)或原始特徵維度(取較小者)。
#23
★★★★
在進行模型選擇或超參數調優時,網格搜索 (Grid Search) 和隨機搜索 (Random Search) 是常用的方法。隨機搜索相比網格搜索的主要優勢通常是什麼?
答案解析
網格搜索會窮舉所有預定義的超參數組合,如果某些超參數對模型性能影響不大,網格搜索會在這些不重要的維度上浪費大量計算資源。而隨機搜索則是在預定義的範圍內隨機抽取超參數組合進行嘗試。研究和實踐表明,對於許多機器學習問題,模型性能通常只對少數幾個超參數比較敏感。隨機搜索更有可能在這些重要的超參數維度上採樣到更多不同的值,因此在相同的嘗試次數下,往往比網格搜索更容易找到接近最優的組合。雖然兩者都不保證找到全局最優解,但隨機搜索通常在計算效率上更優。
#24
★★★
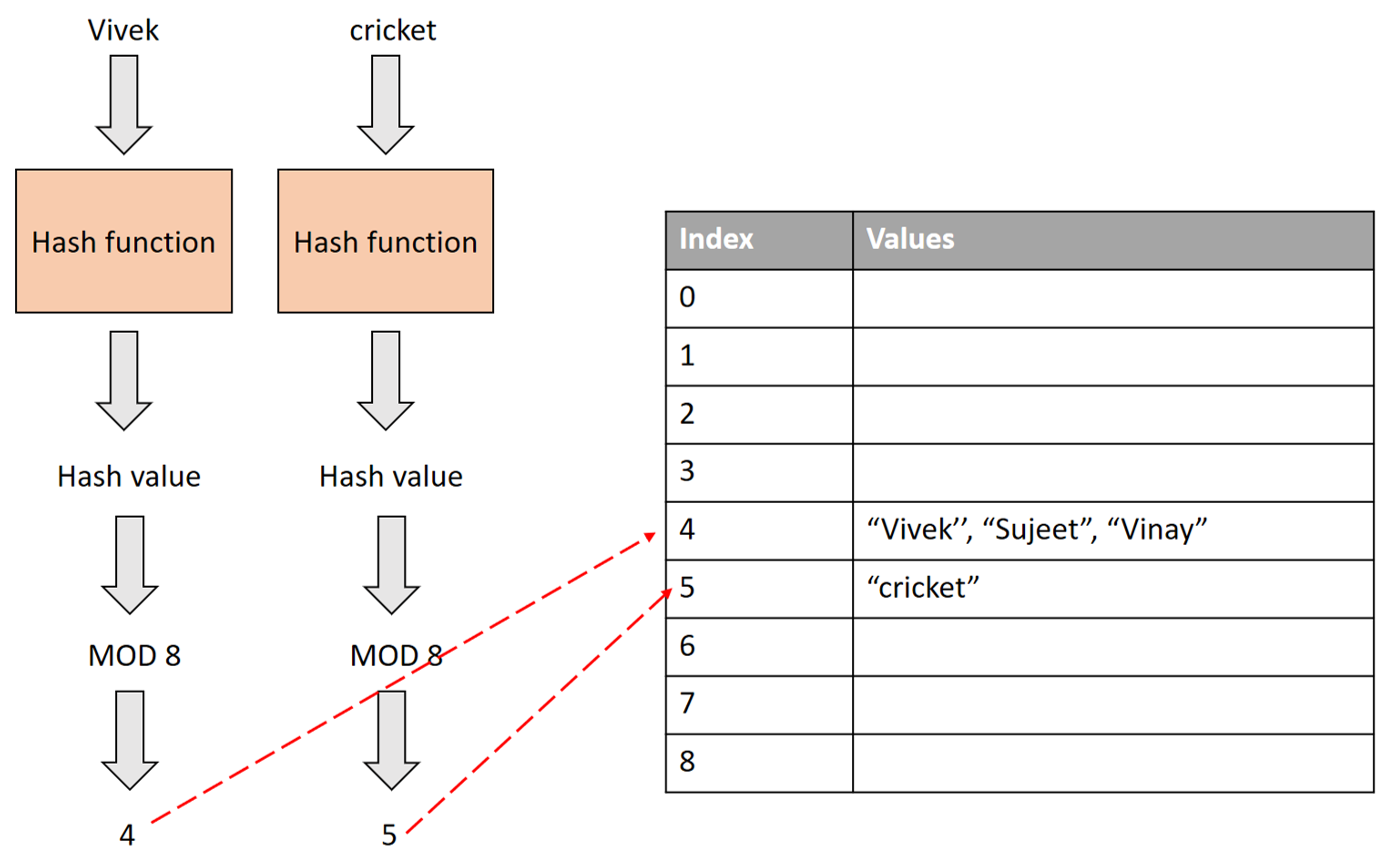
特徵哈希 (Feature Hashing) 或稱哈希技巧 (Hashing Trick) 是一種處理高維度稀疏特徵(特別是類別特徵)的方法,其主要優點是?
答案解析
當處理具有極高基數 (Cardinality) 的類別特徵時(例如,用戶ID、詞語),使用獨熱編碼會產生非常高維且稀疏的向量,佔用大量內存。特徵哈希提供了一種替代方法:它使用一個哈希函數 (Hash Function) 將原始的特徵(如詞語字符串)直接映射到一個固定長度的向量的某個索引位置(通常是從 0 到 N-1,N 是預設的哈希空間大小)。然後可以在這個位置上記錄特徵的計數或 TF-IDF 值等。這樣,無論原始特徵空間有多大,最終的特徵向量維度都是固定的 N。優點是無需構建和存儲龐大的詞彙表,內存效率高,且容易處理新出現的未知特徵(直接哈希即可),適合流式數據或在線學習。缺點是可能發生哈希碰撞,即不同的原始特徵被映射到同一個索引位置,可能損失一部分信息,但如果 N 設置得足夠大,碰撞的影響通常可以接受。
#25
★★★
AdaBoost (Adaptive Boosting) 算法在訓練過程中會如何調整樣本的權重?
答案解析
AdaBoost 是 Boosting 系集學習算法的代表之一。它循序地訓練一系列弱學習器(通常是決策樁 Decision Stumps 或淺層決策樹)。在每一輪迭代中,AdaBoost 會根據前一輪學習器的表現來更新訓練樣本的權重分佈。那些被前一個弱學習器錯誤分類的樣本,在下一輪訓練中會獲得更高的權重,使得下一個弱學習器更加關注這些「難分」的樣本。而被正確分類的樣本權重則會降低。最終的模型是所有弱學習器的加權組合,其中表現較好(錯誤率較低)的弱學習器會獲得更高的權重。這種機制使得 AdaBoost 能夠逐步聚焦於困難樣本,構建出強大的分類器。
#26
★
機器學習模型訓練的最終目標是?
答案解析
雖然我們希望模型在訓練集上表現良好,但機器學習的真正目標是讓模型在遇到新的、從未見過的數據時也能做出準確的預測或判斷。這種能力被稱為模型的泛化能力。僅僅在訓練集上達到高精度(甚至100%)可能意味著模型發生了過擬合,它只是「死記硬背」了訓練數據,而沒有學到潛在的規律。因此,評估和優化模型的泛化能力(通常通過驗證集和測試集來衡量)才是模型訓練的最終目標。
#27
★★
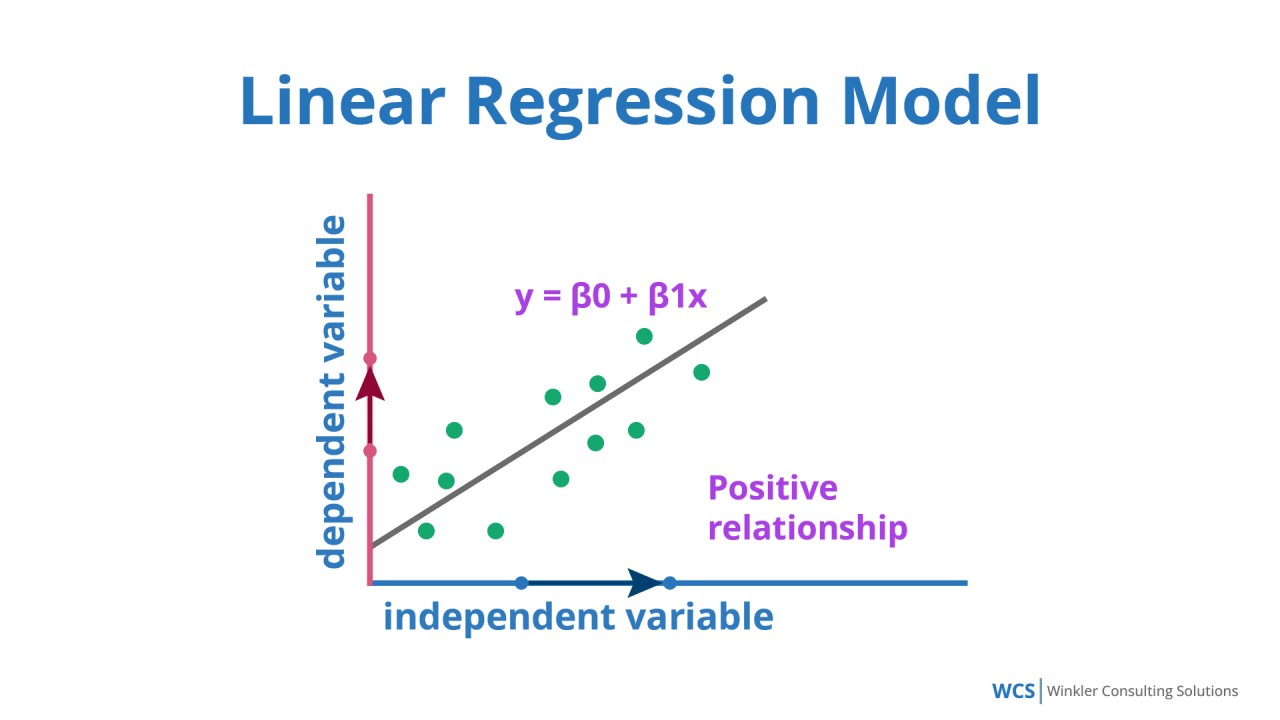
簡單線性回歸假設自變數 X 和應變數 Y 之間存在什麼樣的關係?
答案解析
簡單線性回歸模型的基本形式是 y = β₀ + β₁x + ε。這個模型假設應變數 y 的期望值 E[y] 與自變數 x 之間存在直線關係,即 E[y] = β₀ + β₁x。如果數據點大致散佈在一條直線周圍,則線性回歸是一個合適的模型。如果關係明顯是非線性的,則可能需要使用多項式迴歸、非線性迴歸或更複雜的模型。
#28
★★★
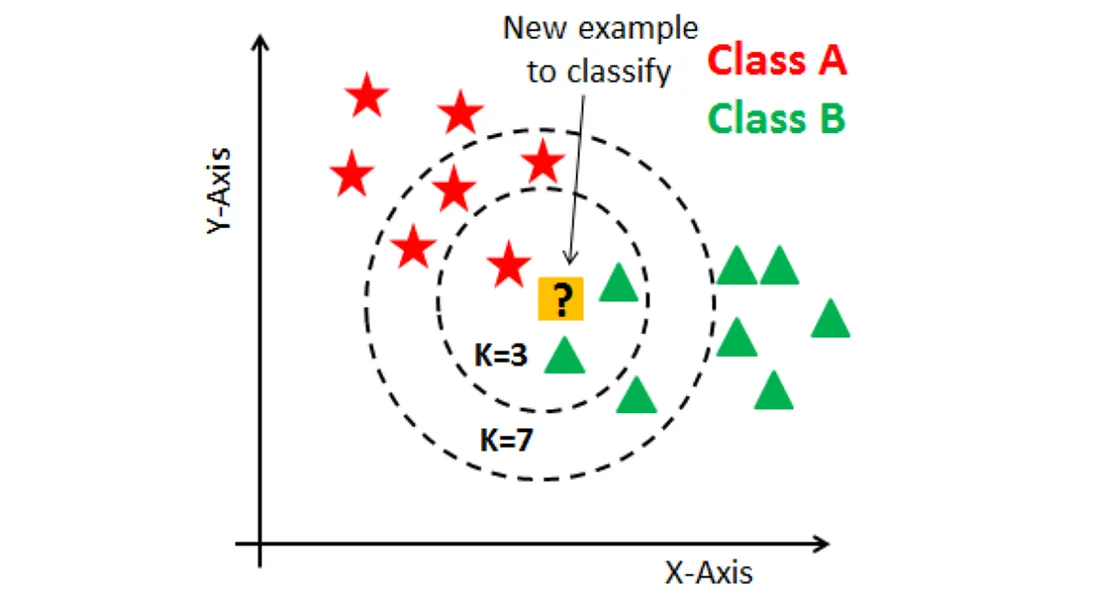
K-近鄰 (K-Nearest Neighbors, KNN) 分類算法是如何預測一個新樣本的類別的?
答案解析
KNN 是一種基於實例的學習 (Instance-based Learning) 或惰性學習 (Lazy Learning) 算法。它不做顯式的模型訓練,而是直接利用訓練數據進行預測。對於一個新的、未標註的樣本點,KNN 的預測步驟如下:
- 計算新樣本與訓練集中所有樣本之間的距離(常用歐幾里得距離)。
- 找出距離最小(即最相似)的 K 個訓練樣本(稱為 K 個最近鄰)。K 是一個需要用戶指定的超參數。
- 對於分類問題,查看這 K 個鄰居的類別標籤,採用多數投票 (Majority Voting) 的方式,將出現次數最多的那個類別賦予新樣本。
- 對於迴歸問題,通常是計算這 K 個鄰居目標值的平均值或加權平均值作為新樣本的預測值。
#29
★
非監督式學習與監督式學習最根本的區別在於訓練數據是否包含?
答案解析
監督式學習需要使用帶有「正確答案」(即標籤或目標值)的數據進行訓練,模型學習的是從輸入到已知輸出的映射。非監督式學習的訓練數據是沒有標籤的,算法需要自行從數據中發現潛在的結構、模式或關係,例如將相似的數據點歸為一類(分群),或者找到數據的主要變化方向以降低維度(降維)。
#30
★
下列哪項是降維 (Dimensionality Reduction) 技術的潛在好處?
答案解析
如第 #5 和 #39 題所述,降維的主要好處包括:(1) 克服維度災難;(2) 降低後續模型訓練和預測的計算複雜度;(3) 減少數據儲存空間;(4) 可能通過去除噪聲或冗餘信息來提高模型的泛化性能;(5) 將數據降至 2 維或 3 維以便進行視覺化探索。當然,降維也可能損失一部分信息,需要在維度降低程度和信息保留之間進行權衡。選項 A 可能對,但不是好處。
#31
★★★
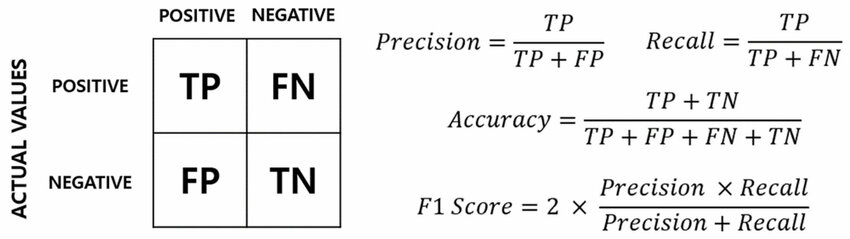
F1 分數 (F1 Score) 是綜合考慮了哪兩個分類評估指標的調和平均數?
答案解析
F1 分數是精確率 (Precision) 和召回率 (Recall) 的調和平均數 (Harmonic Mean),計算公式為 F1 = 2 * (Precision * Recall) / (Precision + Recall)。它試圖在精確率和召回率之間取得平衡。當兩者都很重要,或者當數據存在類別不平衡時,F1 分數通常被認為是比準確率更合適的評估指標。F1 分數的取值範圍也是 [0, 1],值越接近 1 表示性能越好。
#32
★★★★
對於包含文本數據的特徵,在將其輸入機器學習模型前,通常需要將文本轉換為數值表示。下列哪項「不」是常用的文本數值化方法?
答案解析
將文本轉換為機器可處理的數值形式是自然語言處理 (NLP) 的基礎步驟。常用方法包括:
- 詞袋模型 (BoW):忽略詞序和語法,將文檔表示為一個向量,向量的每個維度對應詞彙表中的一個詞,值通常是該詞在文檔中出現的次數(詞頻)。
- TF-IDF:對 BoW 的改進,不僅考慮詞頻 (TF),還考慮該詞在整個文檔集合中的逆文檔頻率 (IDF),以降低常見詞的權重,突出具有區分性的詞語。
- 詞嵌入 (Word Embeddings):將每個詞語映射到一個低維(通常幾十到幾百維)的稠密實數向量,使得語義相似的詞語在向量空間中距離更近。如 Word2Vec, GloVe, FastText 等。近年來,基於 Transformer 的模型(如 BERT)產生的上下文相關詞嵌入效果更好。
#33
★★★★
系集學習 (Ensemble Learning) 方法的基本思想是?
答案解析
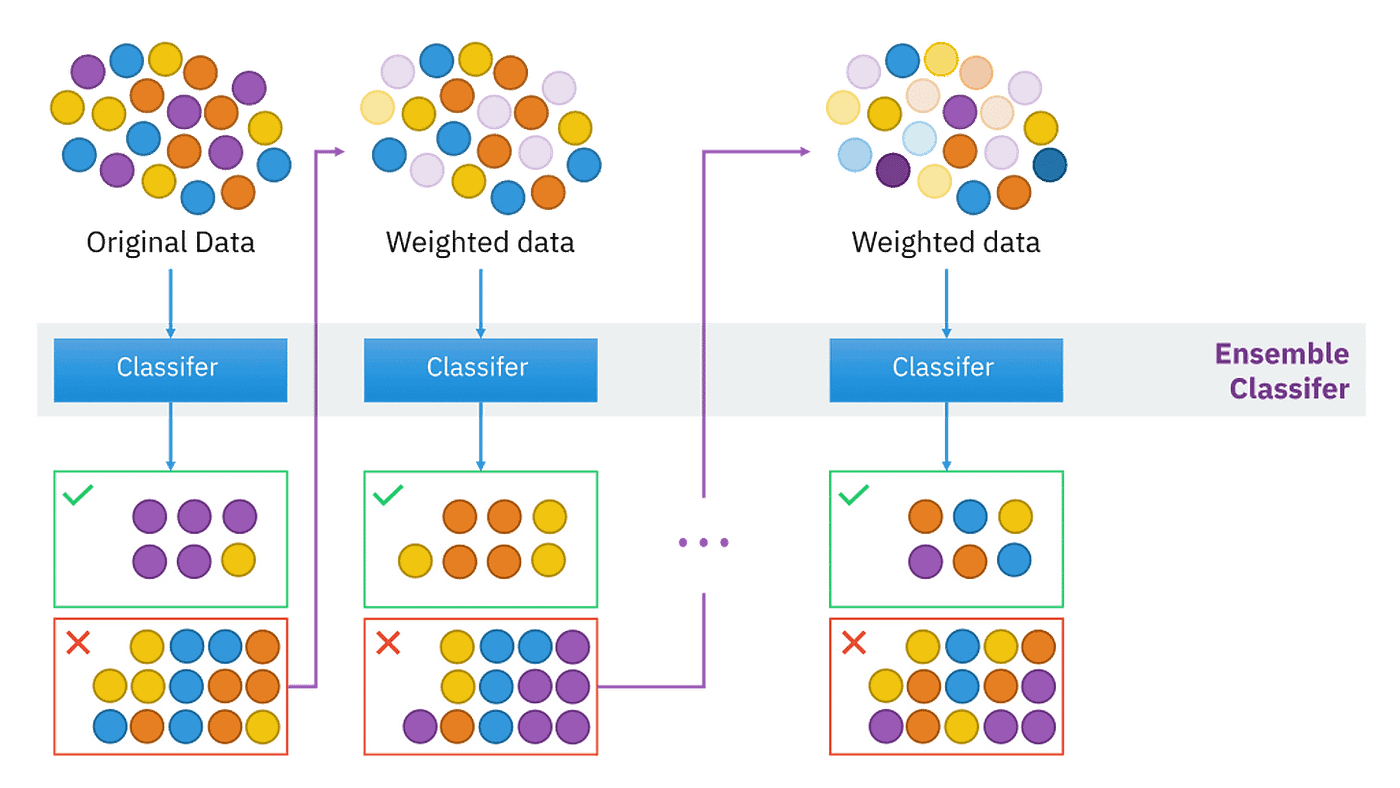
系集學習的核心思想是「三個臭皮匠,勝過一個諸葛亮」。它不是依賴單一的模型來做決策,而是構建多個模型(稱為基學習器或弱學習器),然後將它們的預測結果以某種方式結合起來(例如,投票、平均、加權平均),形成最終的預測。如果基學習器之間具有一定的差異性 (Diversity),並且每個基學習器的性能都比隨機猜測好,那麼系集模型的性能通常會優於任何單個基學習器,並且更加穩定和魯棒。常見的系集方法包括 Bagging(如隨機森林)、Boosting(如 AdaBoost, GBDT)和 Stacking。
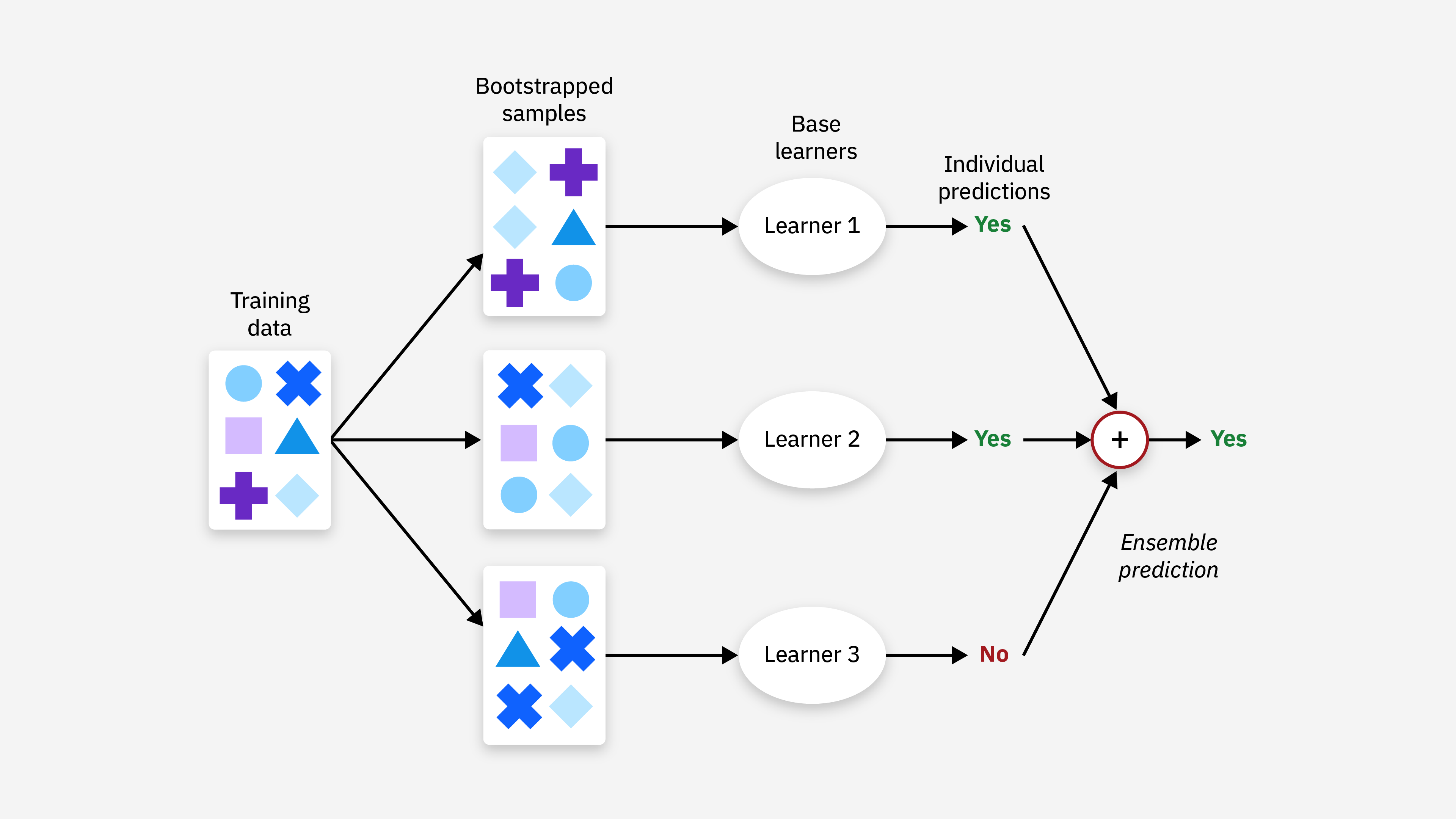
#34
★★★
在機器學習流程中,「特徵」 (Feature) 指的是什麼?
答案解析
特徵,也稱為屬性 (Attribute)、預測變數 (Predictor Variable) 或自變數 (Independent Variable),是從原始數據中提取出來的、用於表示每個數據樣本的可量化特性。機器學習模型利用這些特徵來進行學習和預測。例如,在預測房價的任務中,房屋的大小、房間數量、位置經緯度、建造年份等都可以作為特徵。選擇和構建好的特徵(特徵工程)對於模型的性能至關重要。
#35
★
線性回歸模型屬於哪種機器學習類型?
答案解析
線性回歸模型用於預測一個連續的目標變數,其訓練過程需要使用帶有已知目標值的輸入數據(即帶標籤數據)。模型學習輸入特徵與目標值之間的線性關係。由於它依賴於帶標籤的數據來學習映射關係,因此線性回歸屬於監督式學習的範疇。
#36
★★
決策樹 (Decision Tree) 分類器是如何進行預測的?
答案解析
決策樹是一種樹狀結構的模型,其中每個內部節點代表對一個特徵的測試(例如,「年齡 < 30?」),每個分支代表測試的一個結果(例如,「是」或「否」),每個葉節點代表一個類別標籤(對於分類樹)或一個預測值(對於迴歸樹)。要對一個新樣本進行預測,我們從根節點開始,根據樣本的特徵值執行節點上的測試,然後沿著對應的分支向下走,重複這個過程直到到達一個葉節點。該葉節點所代表的類別或值就是模型的預測結果。
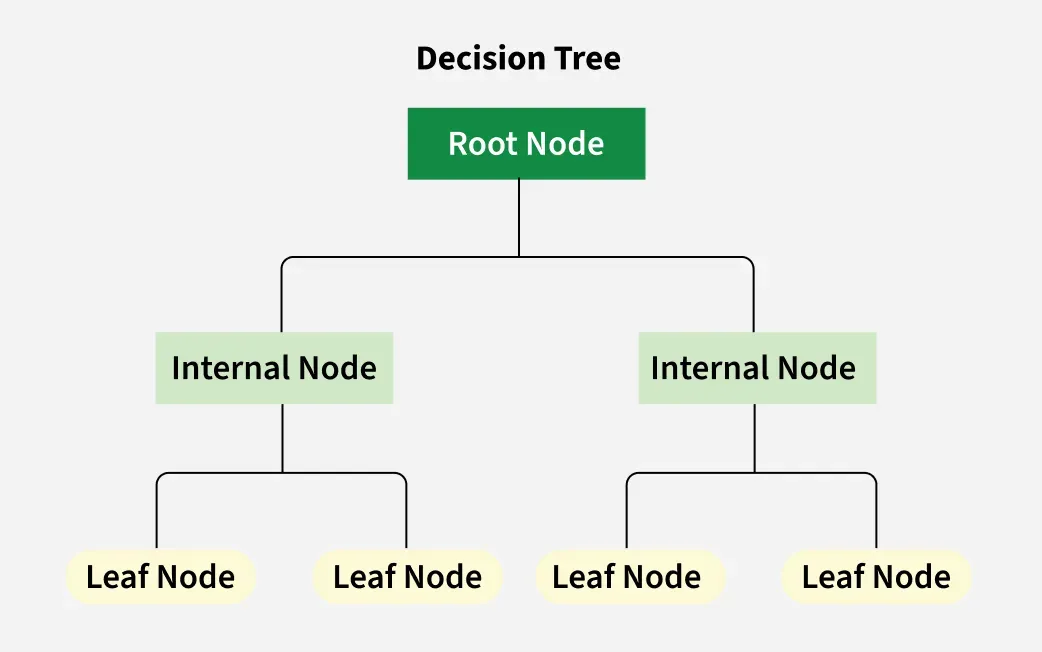
#37
★★
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 是一種基於密度的分群算法,它與 K-means 的主要不同之處在於?
答案解析
DBSCAN 與 K-means 不同,它基於密度的概念來定義群集:群集被定義為由高密度區域分隔開的連續區域。它有兩個關鍵參數:鄰域半徑 ε (eps) 和形成核心點所需的最小鄰居數 MinPts。算法從任意點開始,如果該點在其 ε 鄰域內有至少 MinPts 個鄰居,則它是一個核心點,並開始擴展一個群集;如果一個點不是核心點但位於某個核心點的鄰域內,則它是邊界點;如果既不是核心點也不是邊界點,則它是噪聲點。DBSCAN 的優點包括:(1) 不需要預先指定群集數量 K。(2) 能夠發現任意形狀(非球形)的群集。(3) 對噪聲點不敏感,可以將其識別出來。缺點是對參數 ε 和 MinPts 的選擇比較敏感,且對於密度變化較大的數據集可能效果不佳。

#38
★★
均方誤差 (Mean Squared Error, MSE) 是評估哪類機器學習模型性能的常用指標?
答案解析
均方誤差 (MSE) 計算的是模型預測值與實際目標值之間差值的平方的平均值。公式為 MSE = (1/N) * Σ (yᵢ - ŷᵢ)²,其中 N 是樣本數量,yᵢ 是第 i 個樣本的真實值,ŷᵢ 是模型對第 i 個樣本的預測值。由於它衡量的是預測值與連續真實值之間的平均平方差異,因此 MSE 是評估迴歸模型性能的標準指標之一。MSE 越小,表示模型的預測越接近真實值。其他常用的迴歸指標還包括平均絕對誤差 (MAE)、均方根誤差 (RMSE) 和 R 平方等。分類模型通常使用準確率、精確率、召回率、F1 分數、AUC 等指標。
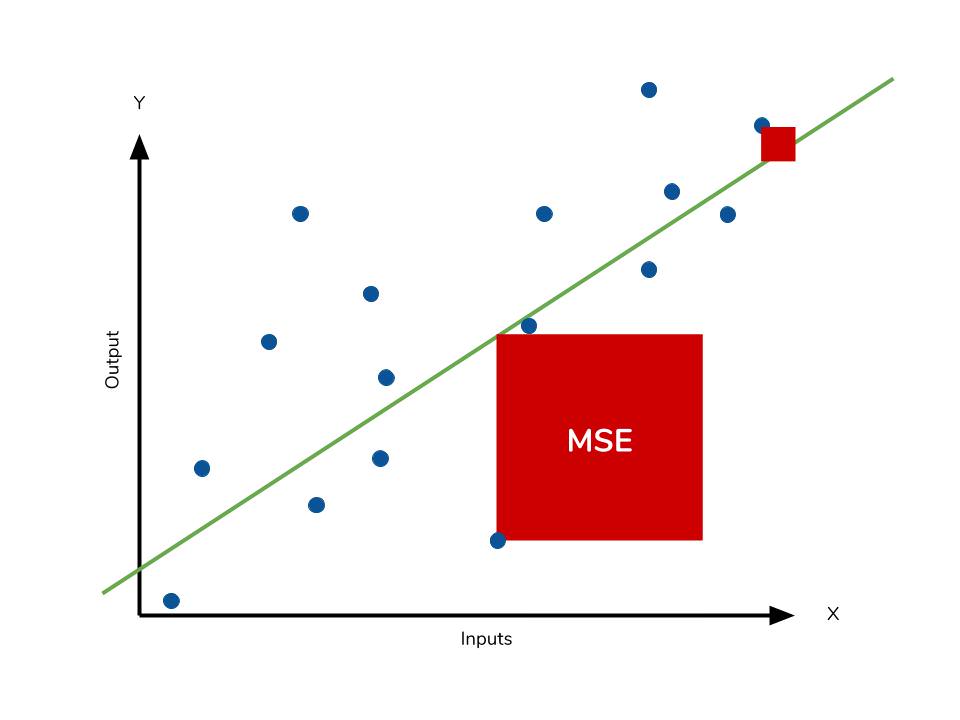
#39
★
為什麼在將原始數據輸入機器學習模型前,通常需要進行資料預處理 (Data Preprocessing)?
答案解析
原始的真實世界數據通常是「骯髒」的,直接用於訓練模型效果往往不佳。資料預處理是機器學習流程中非常關鍵的一步,旨在將原始數據轉換為更適合模型學習的格式。常見的預處理任務包括:
- 數據清洗 (Data Cleaning):處理缺失值、處理異常值 (離群值)、修正不一致的數據等。
- 數據轉換 (Data Transformation):特徵縮放 (標準化、歸一化)、類別特徵編碼 (獨熱編碼、標籤編碼)、數據變換(如對數變換)等。
- 數據歸約 (Data Reduction):降維 (PCA、LDA)、特徵選擇等。
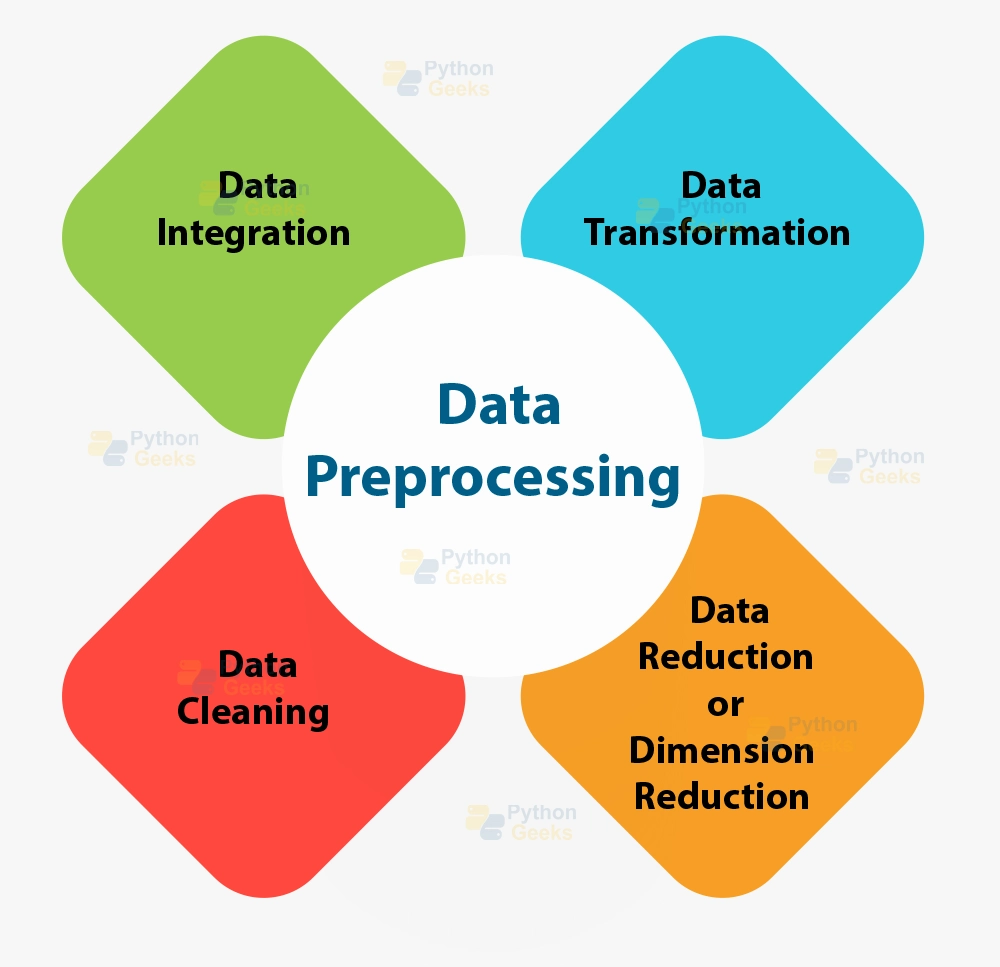
#40
★★
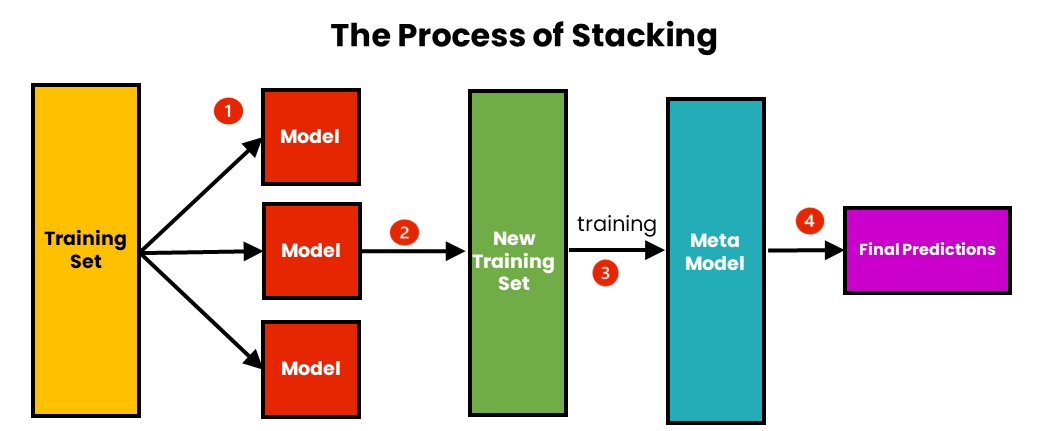
Stacking (堆疊泛化) 是一種系集學習方法,它的基本流程是?
答案解析
Stacking 是一種較為複雜但可能獲得更高性能的系集方法。它包含兩個層級的學習器:
- 第一層 (Level 0):訓練多個不同的基學習器(例如,邏輯回歸、SVM、隨機森林、KNN 等)在原始訓練數據上。為了避免過擬合,通常使用交叉驗證的方式來生成基學習器對訓練數據的「樣本外」 (Out-of-Fold) 預測。
- 第二層 (Level 1):將第一層所有基學習器生成的(樣本外)預測結果作為新的特徵,連同原始的目標標籤一起,用來訓練一個「元學習器」 (Meta-learner,例如邏輯回歸、神經網路等)。元學習器的任務是學習如何最好地結合第一層基學習器的預測。
#41
★
機器學習模型通常從什麼中學習模式和規律?
答案解析
機器學習的核心是讓計算機系統能夠從數據中自動學習和改進,而不需要進行明確的編程。數據是機器學習模型的「養分」,模型通過分析大量的數據樣本來識別其中存在的模式、趨勢和關聯性,並將這些學習到的知識用於對新的、未見過的數據進行預測或決策。數據的品質和數量直接影響模型的學習效果。
#42
★★★
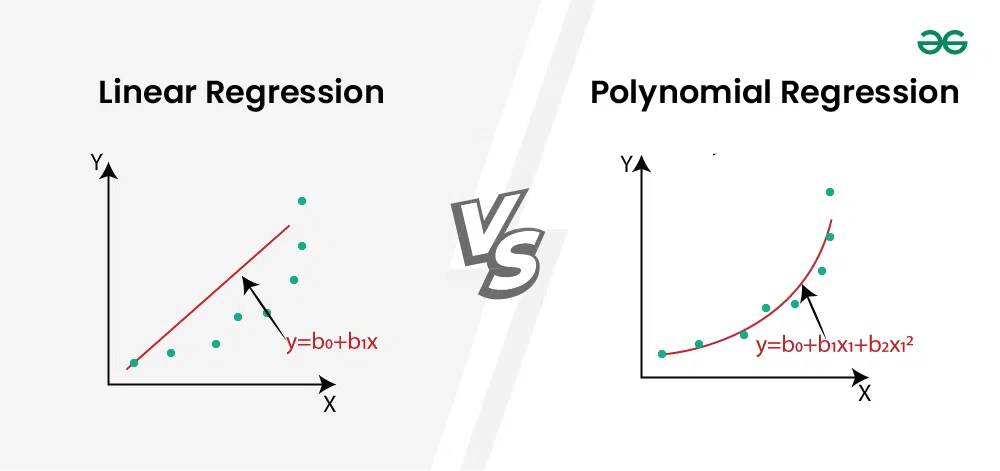
多項式回歸 (Polynomial Regression) 是線性回歸的一種擴展,它允許模型擬合什麼樣的數據關係?
答案解析
標準線性回歸假設應變數和自變數之間是直線關係。然而,現實中的關係往往更複雜。多項式回歸通過在原始自變數 x 的基礎上,添加其高次冪(如 x², x³, ...)作為新的特徵,然後對這些擴展後的特徵應用線性回歸模型。例如,二次多項式回歸模型為 y = β₀ + β₁x + β₂x² + ε。雖然模型對於擴展後的特徵(1, x, x²)仍然是線性的,但它能夠擬合原始變數 x 和 y 之間的非線性曲線關係。通過選擇合適的多項式次數,可以擬合更複雜的數據模式,但次數過高也可能導致過擬合。
#43
★★
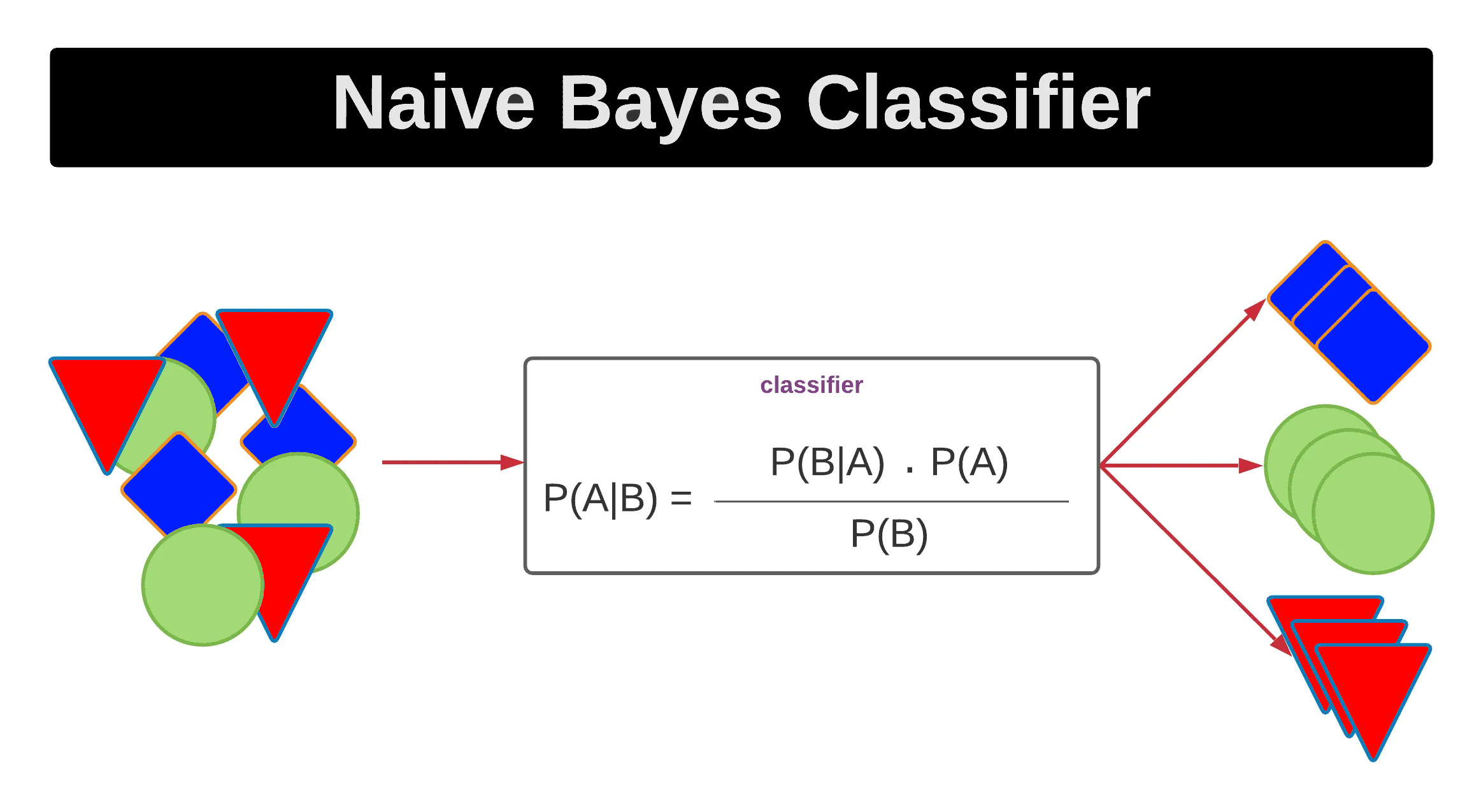
哪種分類算法是基於計算樣本屬於各個類別的後驗機率,並選擇後驗機率最大的那個類別作為預測結果?
答案解析
樸素貝氏分類器直接應用貝氏定理來進行分類。對於給定的輸入樣本 x(包含特徵 F1, ..., Fn),它計算該樣本屬於每個類別 Ck 的後驗機率 P(Ck | x) = P(Ck | F1, ..., Fn)。根據貝氏定理,P(Ck | x) ∝ P(x | Ck) * P(Ck) = P(F1, ..., Fn | Ck) * P(Ck)。利用樸素的條件獨立性假設,P(F1, ..., Fn | Ck) ≈ Π P(Fi | Ck)。因此,算法計算每個類別的後驗機率(或其正比值),並選擇具有最大後驗機率的那個類別作為最終的預測結果。這種基於最大後驗機率的決策準則被稱為貝氏最優分類器(在假設準確的前提下)。邏輯回歸也輸出機率,但其模型形式不同。
#44
★★★
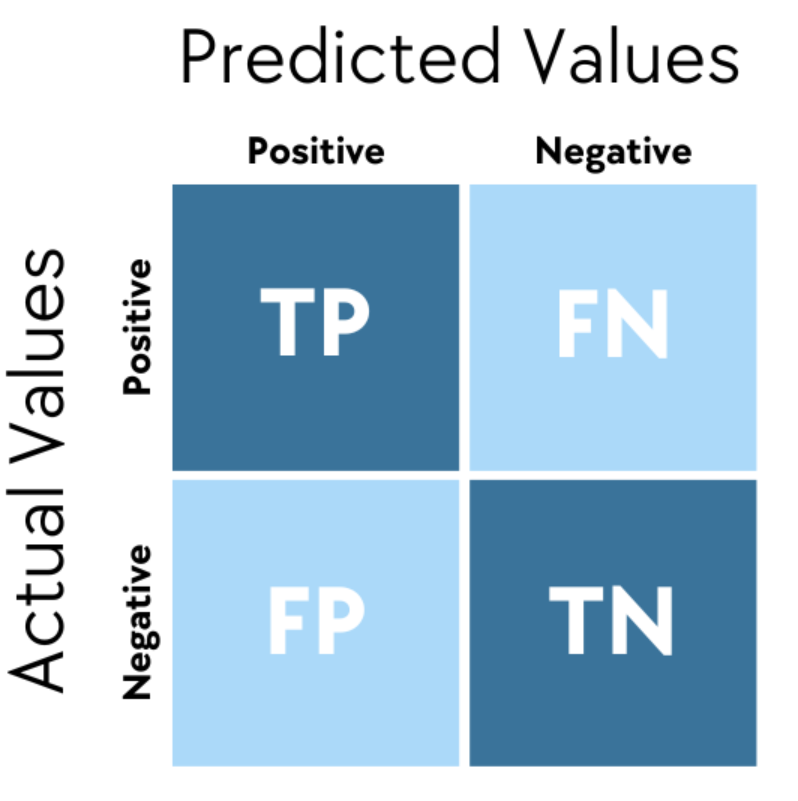
混淆矩陣 (Confusion Matrix) 主要用於評估哪類機器學習模型的性能?
答案解析
混淆矩陣是一個表格,用於視覺化和總結分類模型的預測結果與實際類別標籤之間的關係。對於二元分類,它是一個 2x2 的矩陣,顯示了 TP, FP, TN, FN 的數量。對於多元分類,它是一個 C x C 的矩陣(C 是類別數),顯示了每個實際類別被預測為各個類別的樣本數量。混淆矩陣是計算各種分類評估指標(如準確率、精確率、召回率、F1 分數等)的基礎。
#45
★★
特徵選擇 (Feature Selection) 的目的是從原始特徵集合中選出一個子集,這個子集應該具有什麼特性?
答案解析
特徵選擇是特徵工程的一部分,旨在從原始的大量特徵中挑選出一個最佳的子集,用於模型訓練。理想的特徵子集應該:(1) 與目標變數(預測的輸出)高度相關。(2) 特徵之間盡量相互獨立,減少冗餘信息。(3) 數量盡可能少,以降低模型複雜度。有效的特徵選擇可以帶來多種好處:簡化模型、縮短訓練時間、降低過擬合風險、提高模型的可解釋性,有時甚至能提高預測精度(通過移除噪聲或無關特徵)。常用的特徵選擇方法包括過濾法 (Filter Methods,基於統計指標)、包裹法 (Wrapper Methods,基於模型性能評估) 和嵌入法 (Embedded Methods,模型訓練過程中自動選擇特徵,如 LASSO)。
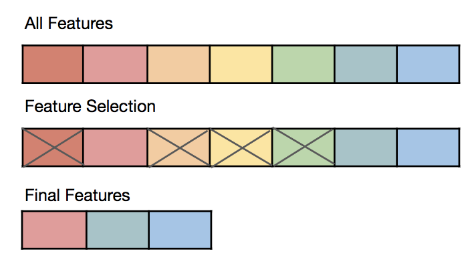
#46
★★
自適應提升 (Adaptive Boosting, AdaBoost) 中的「弱學習器」(Weak Learner) 通常指的是什麼樣的模型?
答案解析
Boosting 算法的核心思想是將多個「弱」學習器組合成一個「強」學習器。弱學習器的定義是,其預測性能(例如,分類準確率)僅僅比隨機猜測好一點點(例如,對於二元分類,準確率略高於 50%)。AdaBoost 理論證明,只要基學習器是弱學習器,通過 Boosting 的方式循序訓練並加權組合,最終可以得到性能任意接近完美的強學習器(只要弱學習器足夠多)。在實踐中,AdaBoost 常用的弱學習器是決策樁 (Decision Stump),即只有一個分裂節點的決策樹。
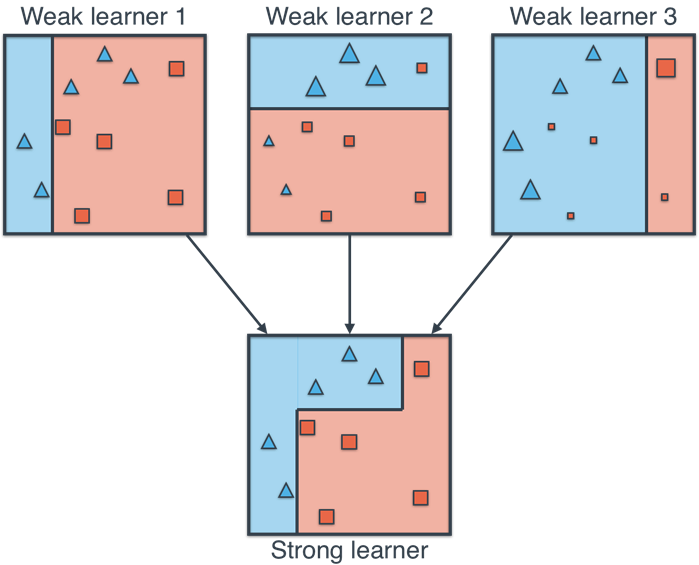
#47
★★
半監督式學習 (Semi-supervised Learning) 指的是使用哪種類型的數據進行訓練?
答案解析
在許多實際應用中,獲取大量帶標籤的數據成本高昂,而未標註的數據則相對容易獲得。半監督式學習旨在利用這種情況,結合使用少量的帶標籤數據和大量的未標註數據來訓練模型。其基本假設是未標註的數據中也包含了有助於學習任務(通常是分類或迴歸)的結構信息(例如,數據的分佈、聚類結構等)。通過利用未標註數據,半監督學習有望在標籤數據有限的情況下,獲得比僅使用少量標籤數據的純監督學習更好的性能。常見的半監督學習方法包括自訓練 (Self-training)、協同訓練 (Co-training)、生成模型方法、基於圖的方法等。
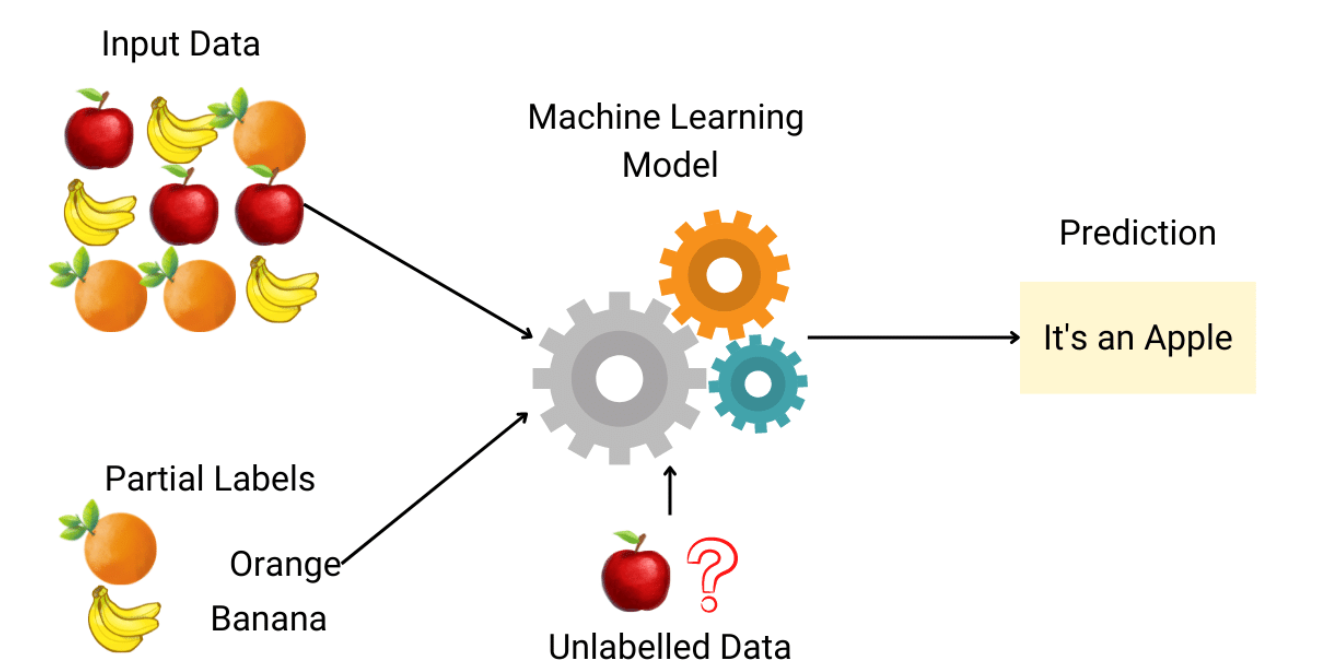
#48
★
交叉熵損失 (Cross-Entropy Loss) 通常用於優化哪類機器學習模型?
答案解析
交叉熵損失衡量的是模型預測的類別機率分佈與真實的類別分佈(通常是 one-hot 向量)之間的差異。因此,它特別適用於分類問題的場景,尤其是當模型的輸出是各個類別的機率時(例如,通過 Softmax 或 Sigmoid 函數得到)。最小化交叉熵損失可以驅使模型輸出的機率分佈盡可能地接近真實的類別分佈。例如,邏輯回歸和深度學習中的分類任務普遍使用交叉熵作為損失函數。
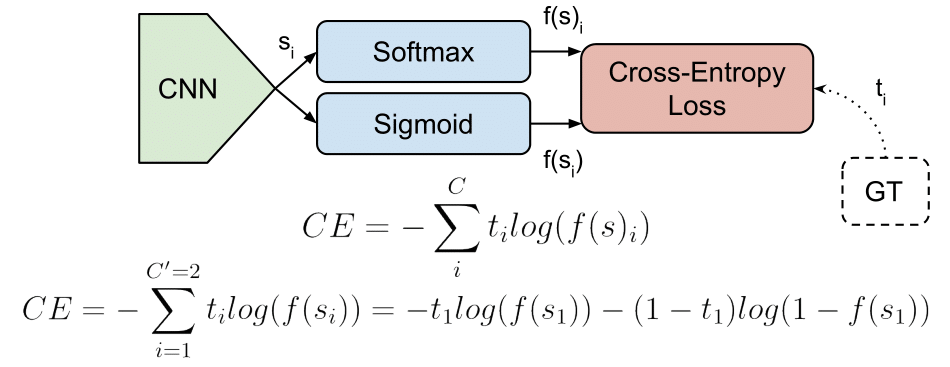
#49
★
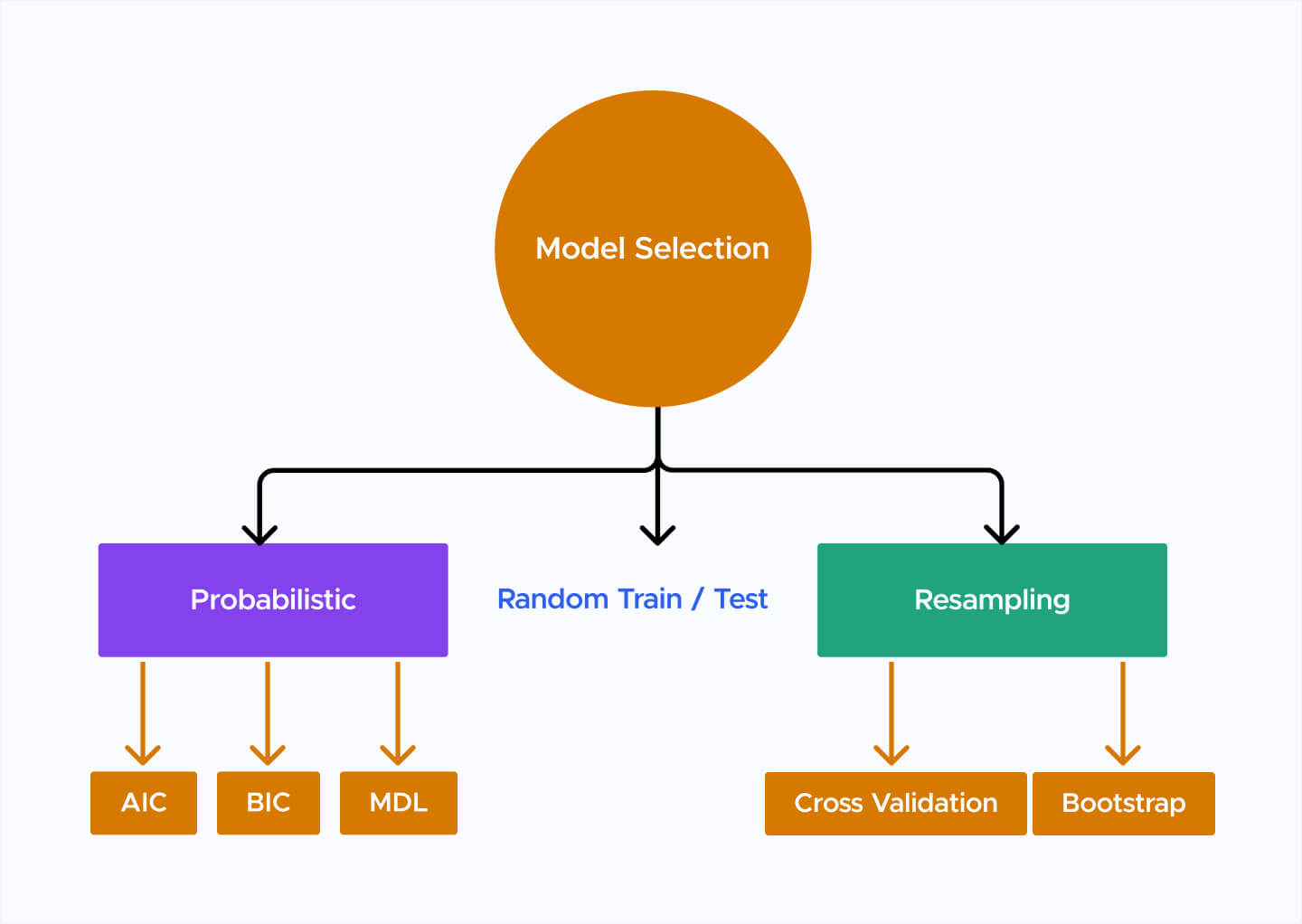
模型選擇 (Model Selection) 的目的是?
答案解析
在解決一個機器學習問題時,通常有多種不同的算法或模型架構可供選擇(例如,線性模型、決策樹、SVM、神經網路等),或者同一種模型可以有不同的超參數配置。模型選擇的過程就是比較這些不同的候選模型,並選出那個預期在未來的新數據上能夠表現最好的模型。這通常通過在驗證集上評估各個模型的泛化性能(例如,使用交叉驗證)來完成,而不是僅僅基於訓練集上的性能(因為那可能導致選擇過擬合的模型)。模型選擇需要在模型的複雜度(可能導致過擬合)和簡單度(可能導致欠擬合)之間找到平衡。
#50
★
將日期時間特徵(例如 "2023-10-27 10:30:00")轉換為多個數值特徵(如年、月、日、星期幾、小時等)的過程屬於?
答案解析
特徵工程是指利用領域知識和數據分析技術,從原始數據中創建、轉換或選擇最能代表潛在問題的特徵,以提高機器學習模型性能的過程。原始的日期時間戳通常不適合直接作為模型的輸入。將其分解為更具體的、可能有預測意義的數值或類別特徵(如年份、月份、星期幾、是否為週末、小時等)是一種常見的特徵工程手段,使得模型能夠更容易地捕捉時間相關的模式(如季節性、週期性)。
↑