iPAS AI應用規劃師 考試重點
L23201 機器學習原理與技術
主題分類
1
機器學習基本概念
2
學習類型 (監督/非監督/強化)
3
模型與演算法基礎
4
特徵工程與數據處理
5
模型訓練原理
6
模型評估基礎
7
核心挑戰 (過擬合/欠擬合)
8
機器學習流程與工具
#1
★★★★★
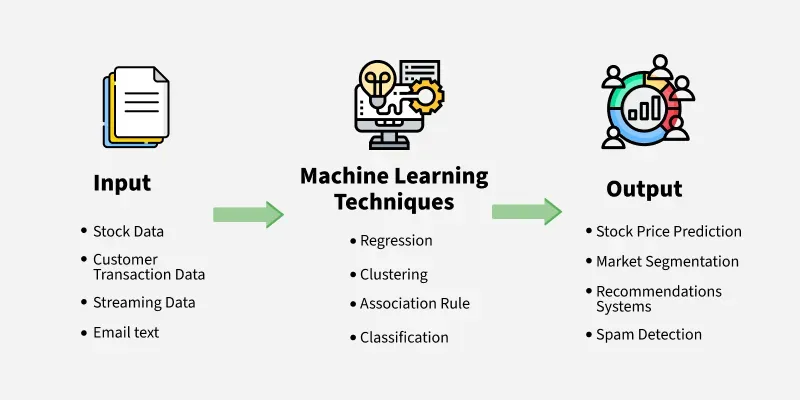
機器學習 (ML, Machine Learning) - 核心定義
核心概念
機器學習是人工智慧 (AI) 的一個分支,其核心目標是讓電腦系統能夠從數據中自動學習模式和規律,並利用這些學習到的知識來做出預測或決策,而無需明確的程式指令來執行特定任務。
#2
★★★★
機器學習與傳統程式設計的區別
核心區別
- 傳統程式設計:人類定義明確的規則和邏輯,電腦依照指令執行。Input + Program -> Output.
- 機器學習:電腦從數據(包含輸入和期望輸出)中學習模式和規則,自動生成「程式」(模型)。Input + Output -> Program (Model).
#3
★★★★
特徵 (Feature) / 屬性 (Attribute) / 自變數 (Independent Variable)
核心術語
指用來描述數據樣本的可測量特性或屬性。機器學習模型使用這些特徵作為輸入來進行預測或分析。例如,預測房價時,房屋大小、房間數量、地點等都是特徵。
#4
★★★★
標籤 (Label) / 目標變數 (Target Variable) / 應變數 (Dependent Variable)
核心術語
在監督式學習中,指我們希望模型預測的輸出值或類別。每個訓練樣本都有一個對應的標籤。例如,在房價預測中,實際的房價就是標籤;在垃圾郵件分類中,「是垃圾郵件」或「不是垃圾郵件」就是標籤。
#5
★★★★
模型 (Model)
核心術語
機器學習模型是透過訓練過程從數據中學習到的數學表示或函數。它捕捉了輸入特徵與輸出標籤之間的關係(監督式學習)或數據本身的結構(非監督式學習)。訓練好的模型可以用來對新的、未見過的數據進行預測或分析。
#6
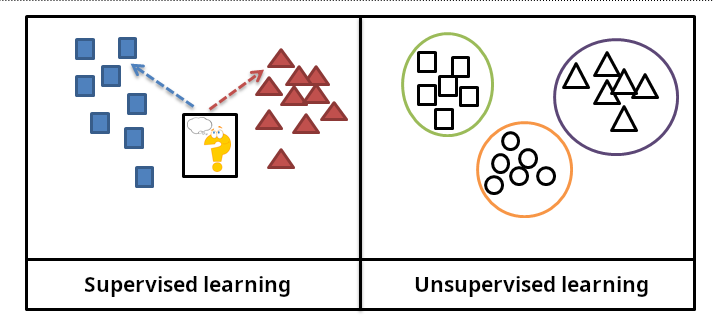
★★★★★
監督式學習 (Supervised Learning)
學習類型 (參考樣題 Q2)
監督式學習使用帶有標籤的數據(即每個輸入樣本都有對應的正確輸出)來訓練模型。模型的目標是學習一個從輸入特徵映射到輸出標籤的函數。就像有老師(標籤)指導學習一樣。
主要任務包括:分類和迴歸。
主要任務包括:分類和迴歸。
#7
★★★★★
非監督式學習 (Unsupervised Learning)
學習類型 (參考樣題 Q2)
非監督式學習使用沒有標籤的數據來訓練模型。模型的目標是發現數據中隱藏的結構、模式或關係。就像在沒有老師指導的情況下自行探索數據。
主要任務包括:分群 (Clustering)、降維 (Dimensionality Reduction)、關聯規則學習 (Association Rule Learning)。
主要任務包括:分群 (Clustering)、降維 (Dimensionality Reduction)、關聯規則學習 (Association Rule Learning)。
#8
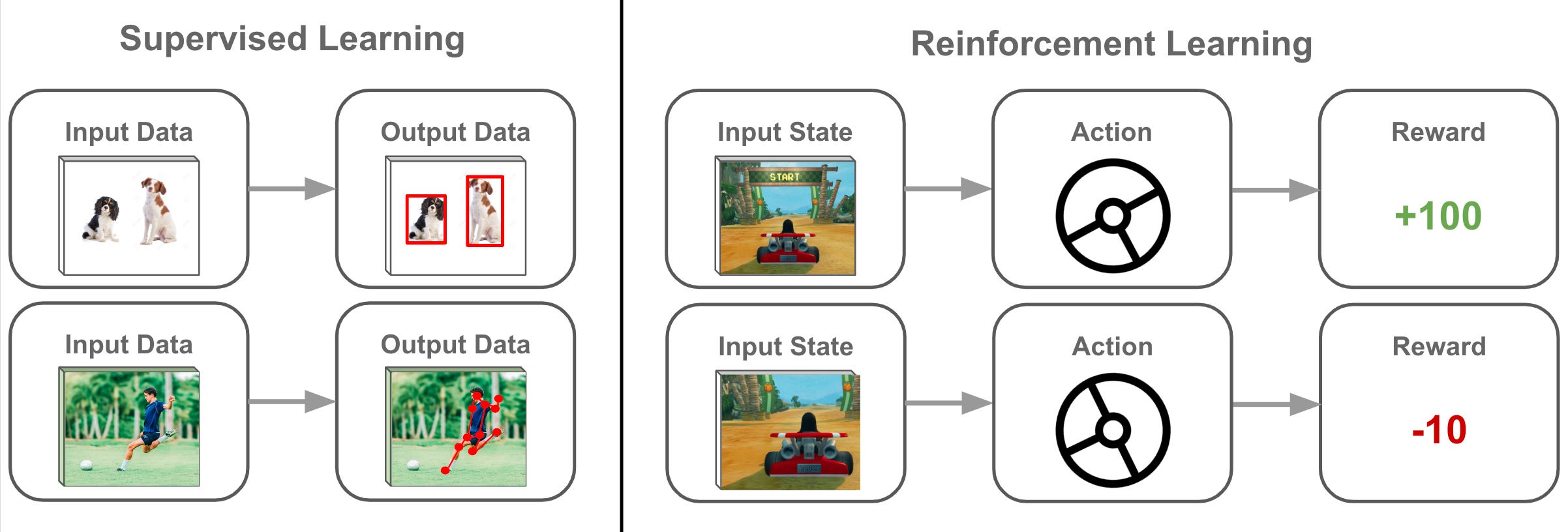
★★★★★
強化學習 (RL, Reinforcement Learning)
學習類型 (參考樣題 Q2)
強化學習涉及一個代理 (Agent) 在一個環境 (Environment) 中透過試誤法 (Trial and Error) 進行學習。代理根據其動作 (Action) 獲得獎勵 (Reward) 或懲罰,目標是學習一個策略 (Policy) 以最大化長期累積獎勵。樣題 Q2 確認其適用於動態互動問題。
#9
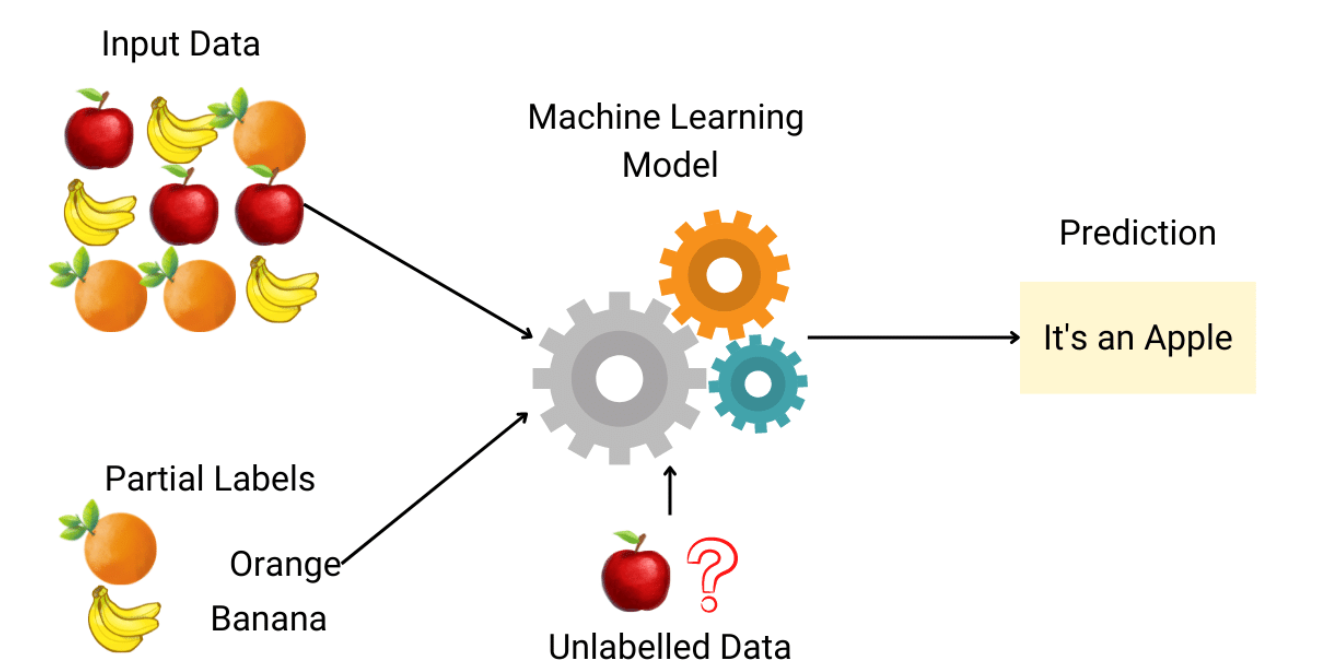
★★★
半監督式學習 (Semi-supervised Learning)
學習類型 (參考樣題 Q2 選項)
介於監督式和非監督式學習之間,使用少量帶標籤的數據和大量未標籤的數據進行訓練。目標是利用未標籤數據來輔助學習過程,提高模型性能,尤其是在標籤數據獲取成本高昂時。
#10
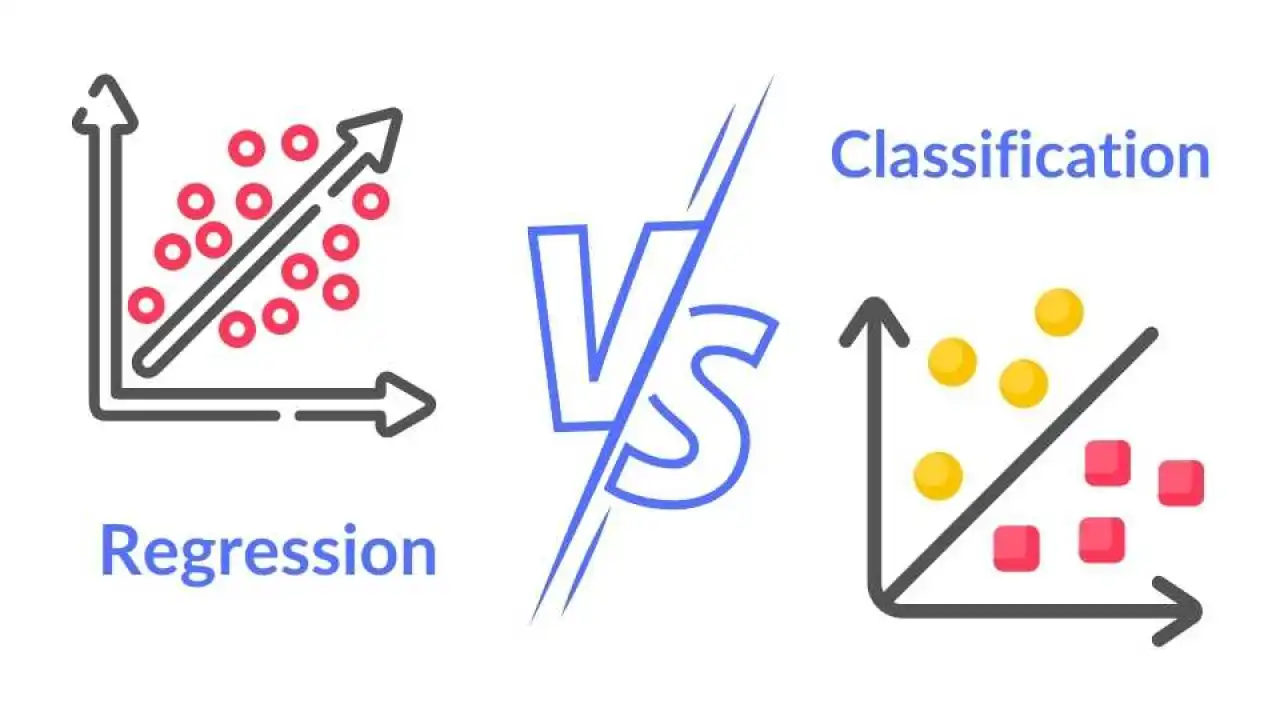
★★★★
分類 (Classification) 任務
監督式學習任務
目標是將輸入樣本分配到預定義的離散類別中的一個。例如:判斷郵件是垃圾郵件還是非垃圾郵件(二元分類),識別圖像中的物體是貓、狗還是鳥(多元分類)。
#11
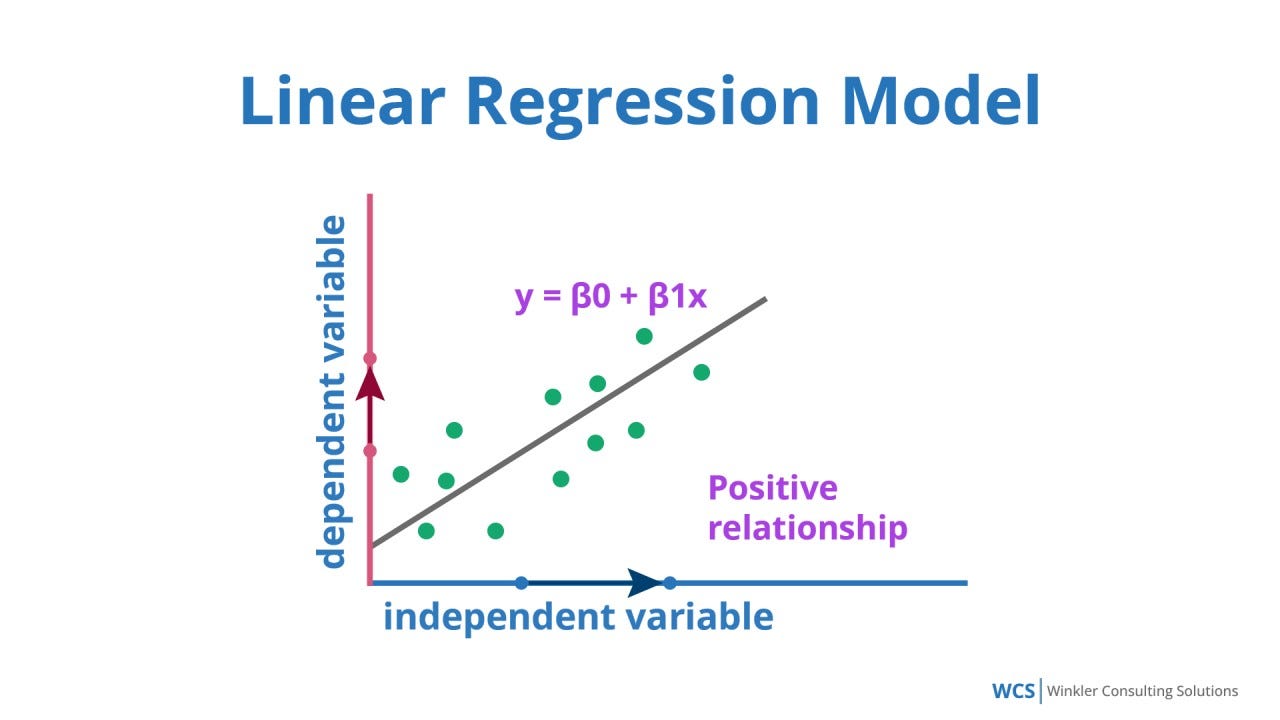
★★★★
迴歸 (Regression) 任務
監督式學習任務 (參考樣題 Q8)
目標是預測一個連續的數值輸出。例如:預測房價、預測股票價格、預測溫度、預測銷售額 (樣題 Q8)。
#12
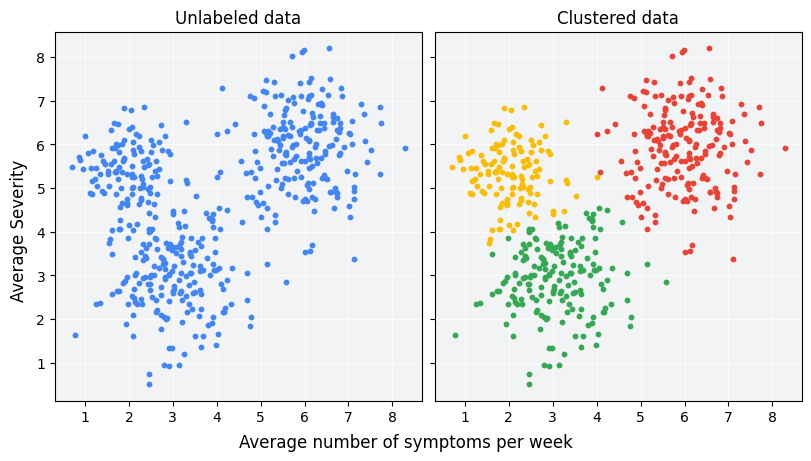
★★★★
分群 (Clustering) 任務
非監督式學習任務 (參考樣題 Q5, Q8 選項)
目標是將數據集中的樣本劃分為若干個群組(群集),使得同一群集內的樣本彼此相似,而不同群集之間的樣本差異較大。沒有預先定義的類別標籤。例如:客戶市場區隔、社交網路分析。樣題 Q5 涉及 K-Means 分群。
#13
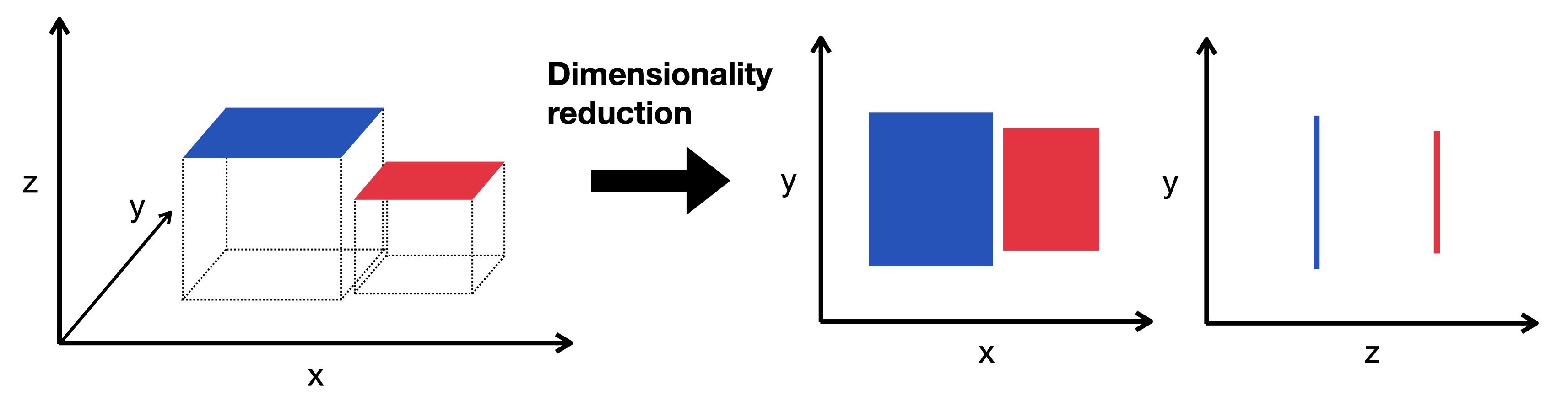
★★★
降維 (Dimensionality Reduction) 任務
非監督式學習任務 (參考樣題 Q9 選項)
目標是在保留數據主要資訊的前提下,減少數據的特徵數量(維度)。有助於數據視覺化、降低計算複雜度、去除冗餘信息、改善後續模型性能。常用方法如 PCA (主成分分析)。
#14
★★★★
演算法 (Algorithm) vs. 模型 (Model)
概念區分
- 演算法:指學習過程本身的方法或程序(例如,梯度下降演算法、決策樹的構建演算法)。
- 模型:指演算法從數據中學習到的結果,是一個可以用來進行預測的具體數學表示(例如,訓練好的線性迴歸方程、訓練好的神經網路權重)。
#15
★★★
參數模型 (Parametric Model) vs. 非參數模型 (Non-parametric Model)
模型分類
- 參數模型:假設數據分佈或函數形式已知,模型由固定數量的參數定義(如線性迴歸、邏輯迴歸)。模型複雜度不隨數據量增加而增加。
- 非參數模型:不對數據分佈做強假設,模型結構或參數數量可以隨數據量增加而變化(如 KNN、決策樹、SVM 使用某些核函數)。通常更靈活,能擬合更複雜的模式,但也更容易過擬合。


#16
★★★★★
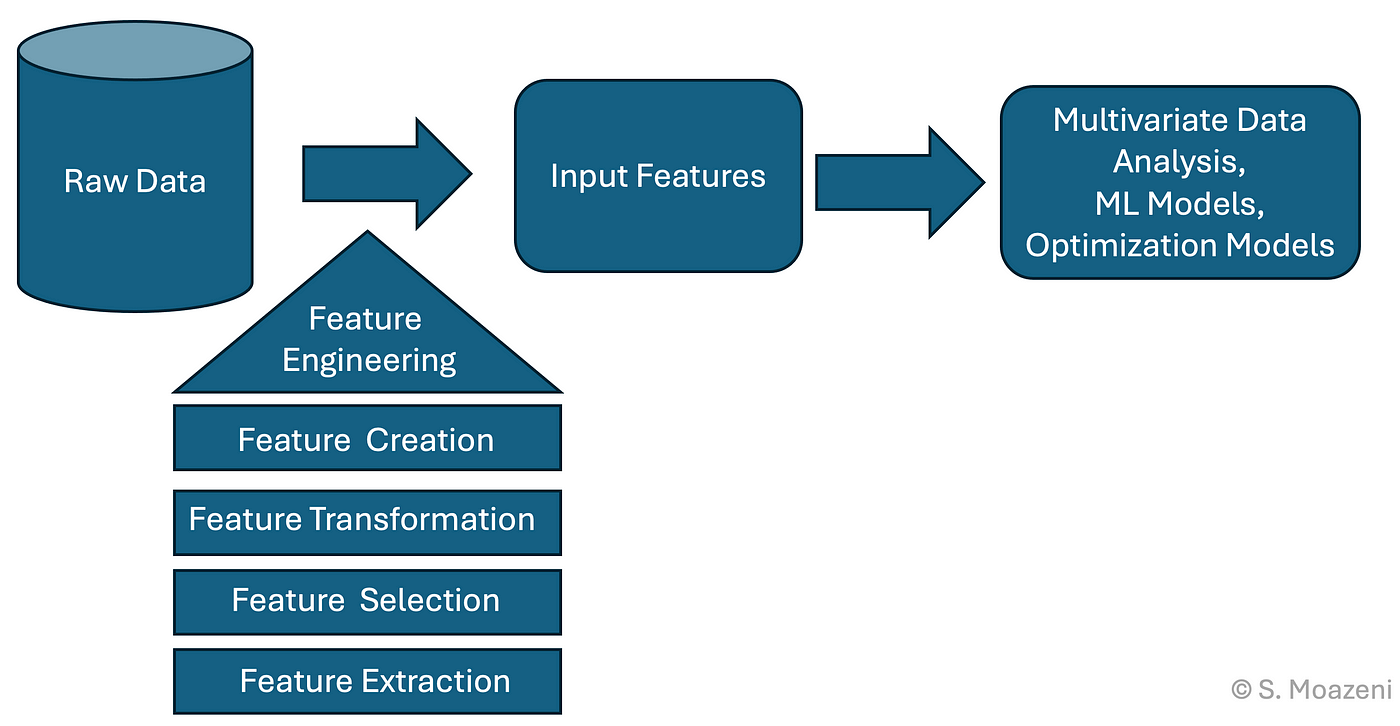
特徵工程 (Feature Engineering) 的重要性 (參考樣題 Q8, Q10)
核心流程環節
特徵工程是利用領域知識和數據分析技術,從原始數據中創建、選擇或轉換出最能代表潛在問題的特徵,以提高機器學習模型性能的過程。是機器學習專案成功的關鍵步驟之一。樣題 Q8 描述了特徵工程的幾種方法。樣題 Q10 強調深度學習可減少手動特徵工程。
#17
★★★★
常見特徵工程技術:特徵創建 (Feature Creation)
技術說明
從現有特徵中衍生出新的、可能更有預測力的特徵。例如:
- 創建交互項(特徵相乘)。
- 創建多項式特徵(特徵的平方、立方等)。
- 根據時間戳提取年、月、日、星期幾等。
- 基於領域知識組合現有特徵。
#18
★★★★
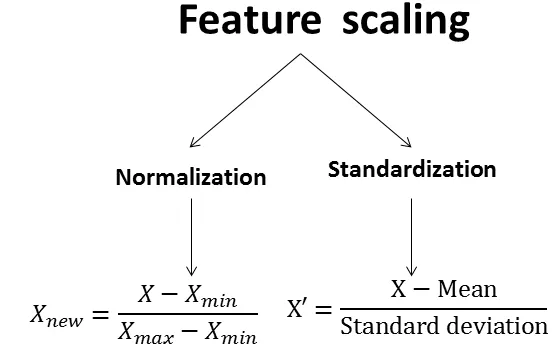
常見特徵工程技術:特徵轉換 (Feature Transformation) (參考樣題 Q8 選項A)
技術說明
對現有特徵進行變換以改變其尺度、分佈或使其更適合模型。例如:
- 標準化 (Standardization): 使數據均值為 0,標準差為 1。
- 正規化 (Normalization / Min-Max Scaling): 將數據縮放到 [0, 1] 或 [-1, 1] 區間。
- 對數轉換 (Log Transform): 處理偏態分佈數據。
- 離散化 (Discretization / Binning): 將連續特徵轉換為離散區間。

#19
★★★★
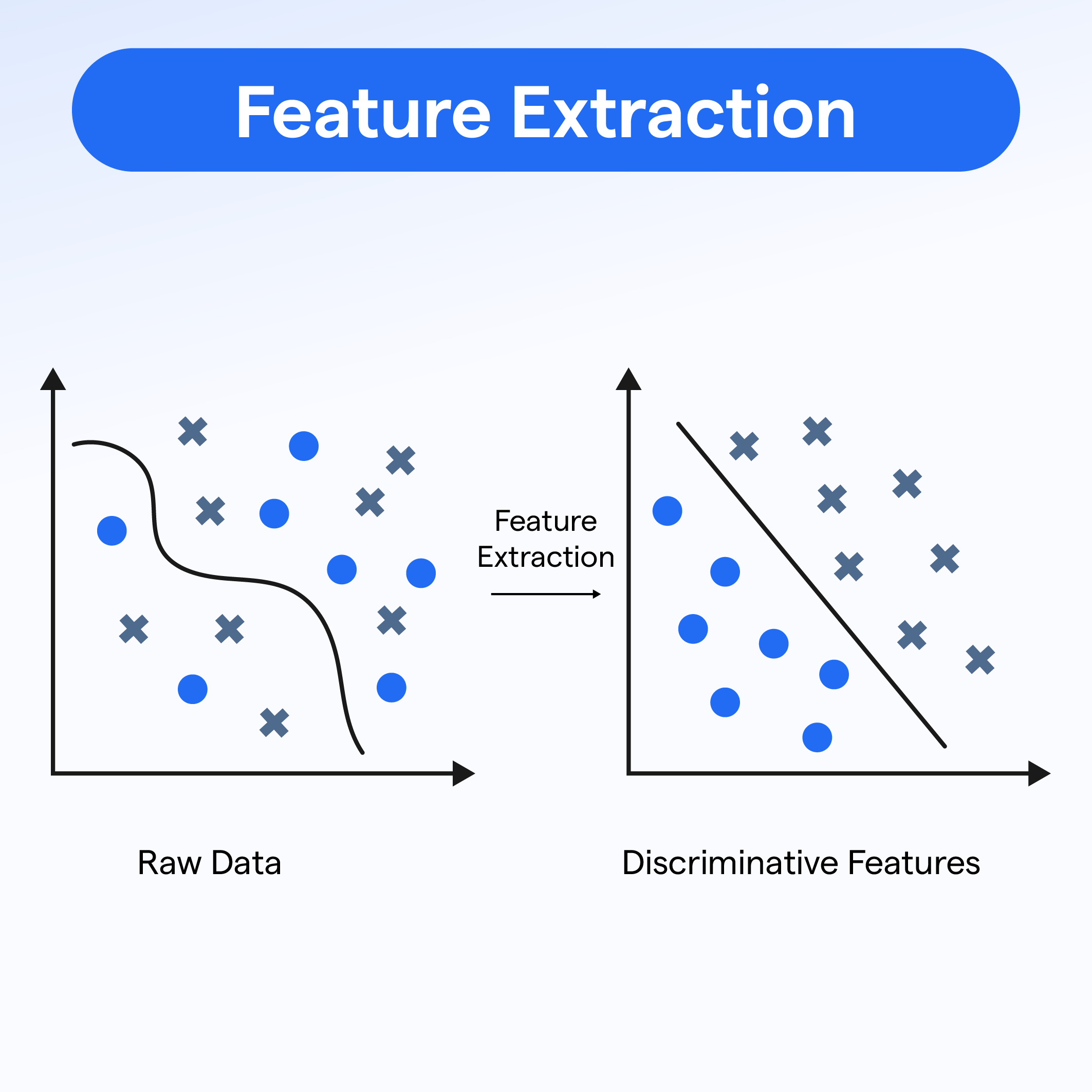
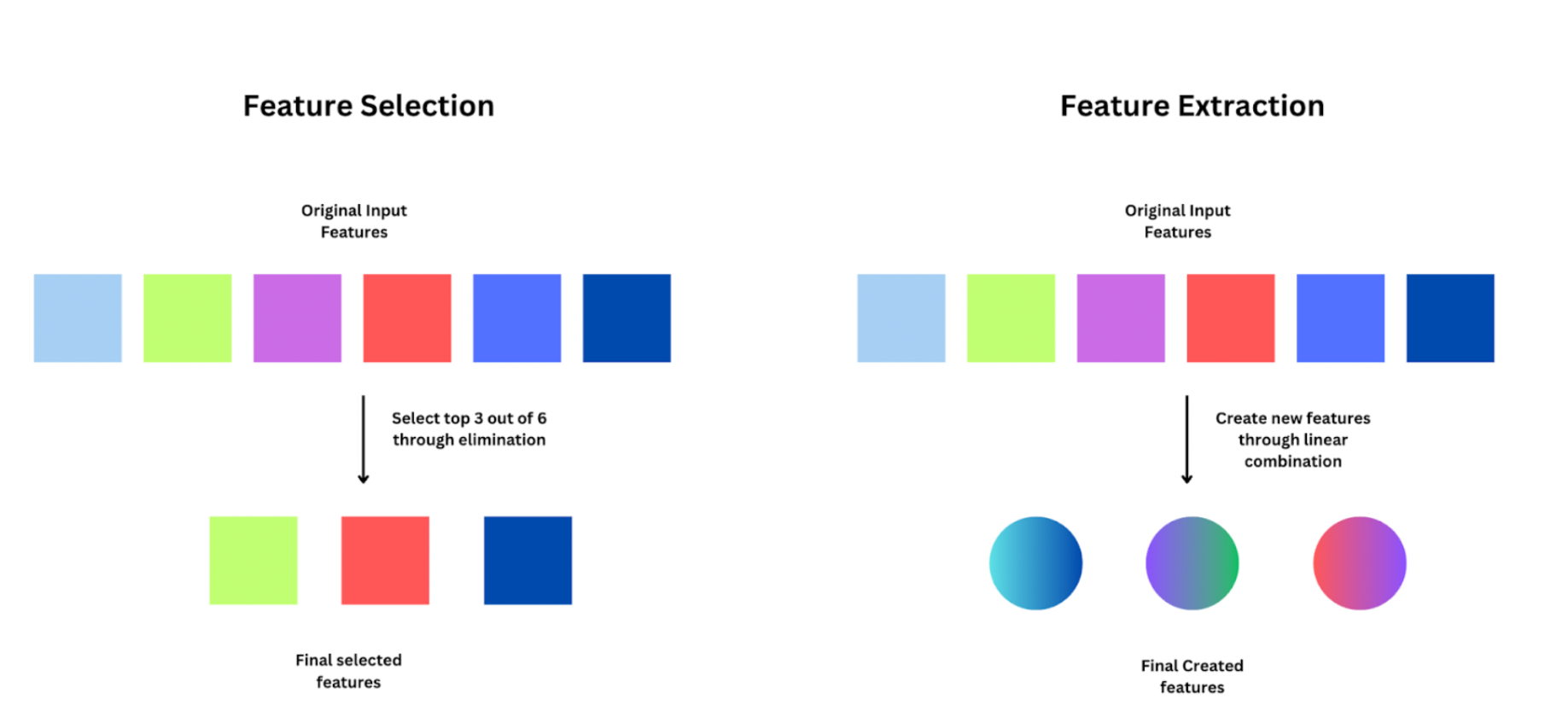
常見特徵工程技術:特徵提取 (Feature Extraction) (參考樣題 Q8 選項B)
技術說明
從原始數據(尤其是高維數據,如圖像、文本)中自動提取出更有代表性的低維特徵。這本質上是一種降維。例如:
- 使用 PCA 提取主成分。
- 使用詞袋模型 (BoW) 或 TF-IDF 從文本中提取特徵。
- 使用 CNN 的中間層輸出作為圖像特徵。
#20
★★★★
常見特徵工程技術:特徵選擇 (Feature Selection) (參考樣題 Q8 選項C)
技術說明
從現有的大量特徵中,選擇出一個與目標變數最相關、冗餘最少的特徵子集。目的是降低模型複雜度、避免維度災難、提高模型性能和可解釋性。方法包括:
- 過濾法 (Filter Methods): 基於統計指標(如相關係數、卡方檢定)獨立評估特徵。
- 包裹法 (Wrapper Methods): 使用特定學習器評估不同特徵子集的性能(如遞迴特徵消除 RFE)。
- 嵌入法 (Embedded Methods): 在模型訓練過程中自動進行特徵選擇(如 Lasso)。
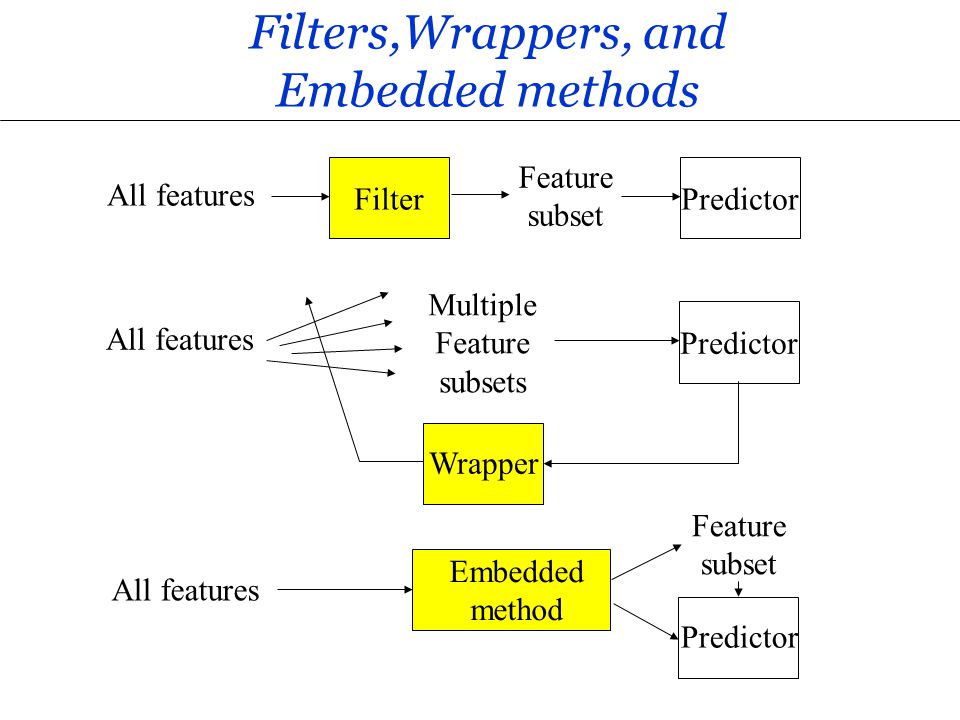
#21
★★★
數據預處理:缺失值處理 (Handling Missing Values)
常見方法
數據中經常存在缺失值,需要進行處理,否則許多模型無法運行。常見方法包括:
- 刪除:刪除包含缺失值的樣本或特徵(可能損失資訊)。
- 填充 (Imputation): 使用統計值(如均值、中位數、眾數)或模型預測值來填充缺失值。
- 使用能處理缺失值的演算法(如某些樹模型)。
#22
★★★
數據預處理:類別特徵編碼 (Encoding Categorical Features)
常見方法
機器學習模型通常需要數值輸入,因此需要將類別特徵(如「紅、綠、藍」或「男、女」)轉換為數值表示。常見方法包括:
- 標籤編碼 (Label Encoding): 將每個類別映射到一個整數(可能引入不存在的順序關係)。
- 獨熱編碼 (One-Hot Encoding): 為每個類別創建一個新的二元(0/1)特徵(維度可能急劇增加)。
- 其他編碼方式:如二進制編碼、目標編碼等。
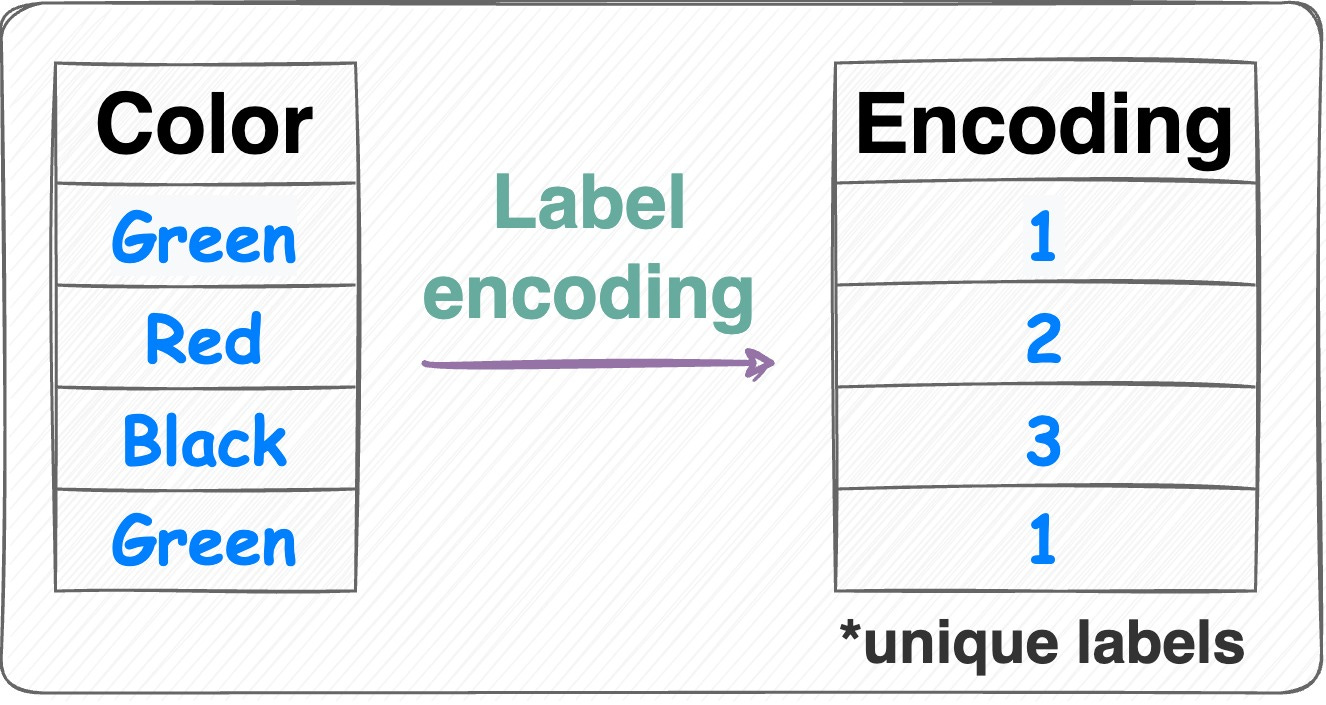
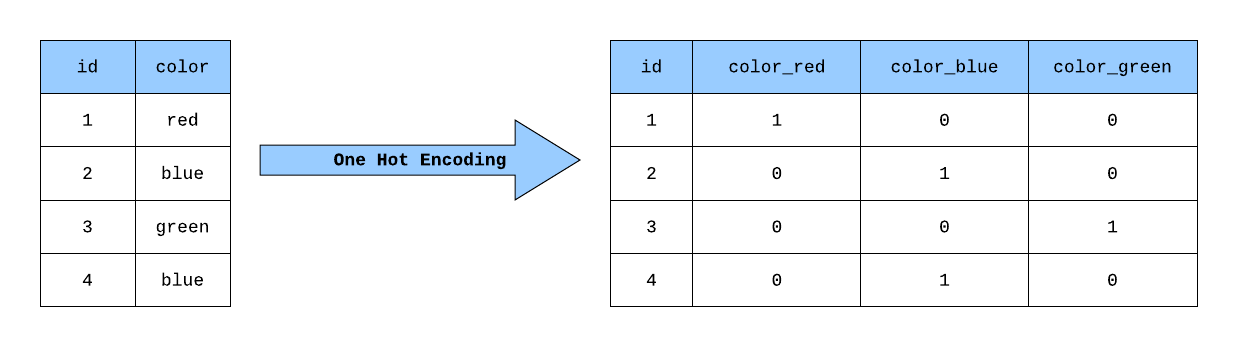
#23
★★★★
模型訓練:損失函數 (Loss Function) 的作用
核心概念
損失函數 用於量化模型預測結果與實際標籤之間的差異或誤差。模型訓練的目標是透過調整模型參數來最小化這個損失函數。損失函數的選擇取決於任務類型(分類/迴歸)。
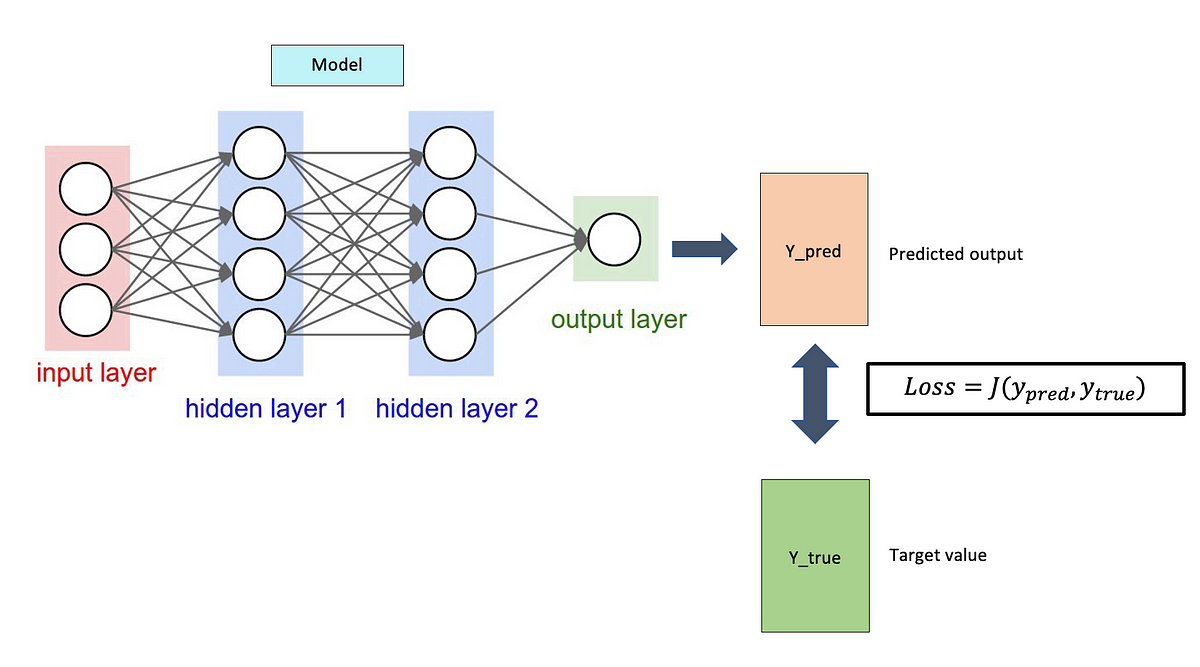
#24
★★★★
模型訓練:優化演算法 (Optimization Algorithm) 的作用
核心概念
優化演算法(最常見的是梯度下降法及其變體)是指導模型參數如何更新以最小化損失函數的具體方法。它計算損失函數對參數的梯度,並沿著梯度下降的方向調整參數。
#25
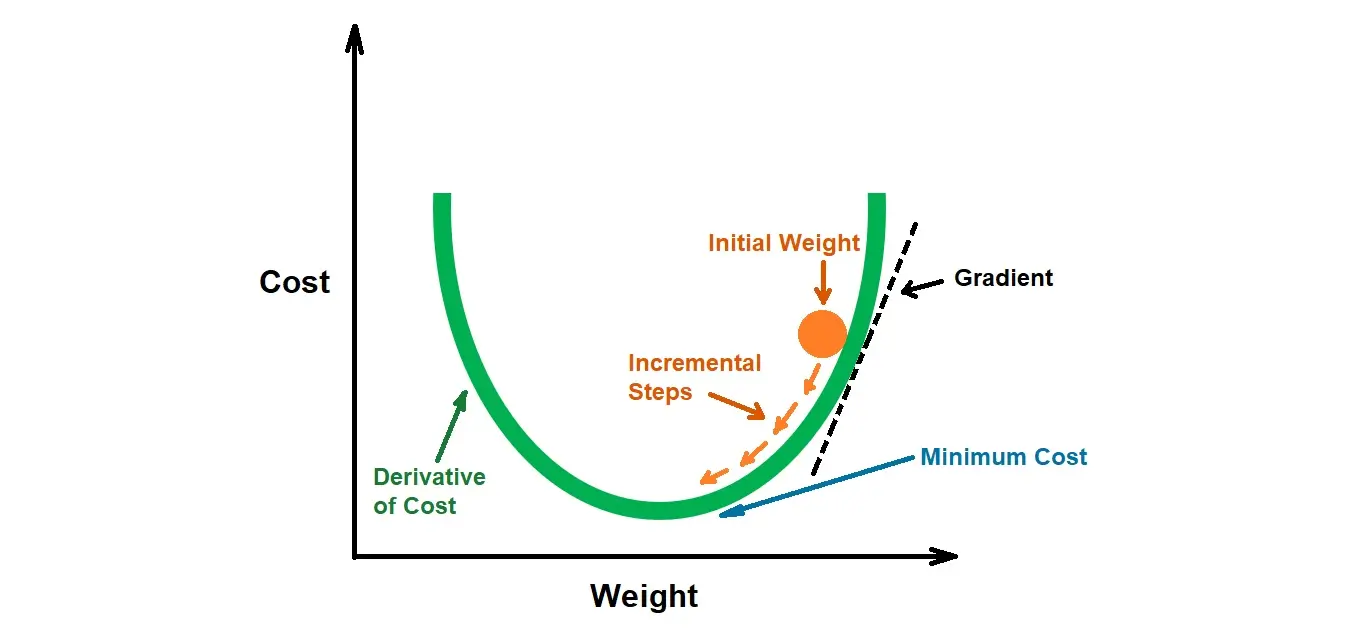
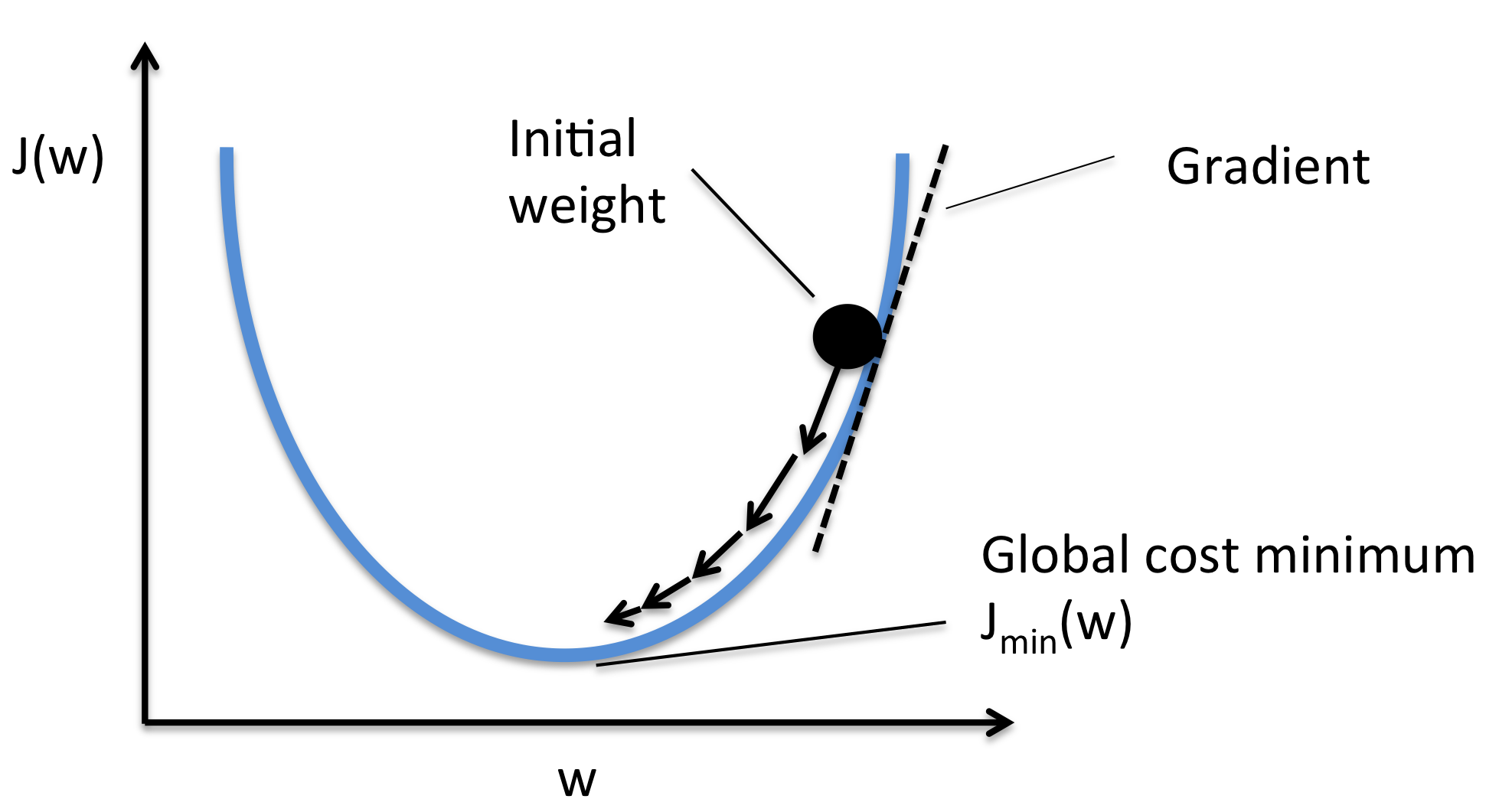
★★★★
梯度下降法 (Gradient Descent) 基本原理
核心原理
一種迭代優化演算法。在每一步,計算當前參數位置的損失函數梯度(表示下降最快的方向),然後沿著梯度的負方向移動一小步(步長由學習率控制),以更新參數。重複此過程直到收斂(損失不再顯著下降)。
#26
★★★
學習率 (Learning Rate)
關鍵超參數
學習率是梯度下降中的一個超參數,控制每次參數更新的步長。
- 學習率過大:可能導致震盪或無法收斂。
- 學習率過小:可能導致收斂速度過慢。
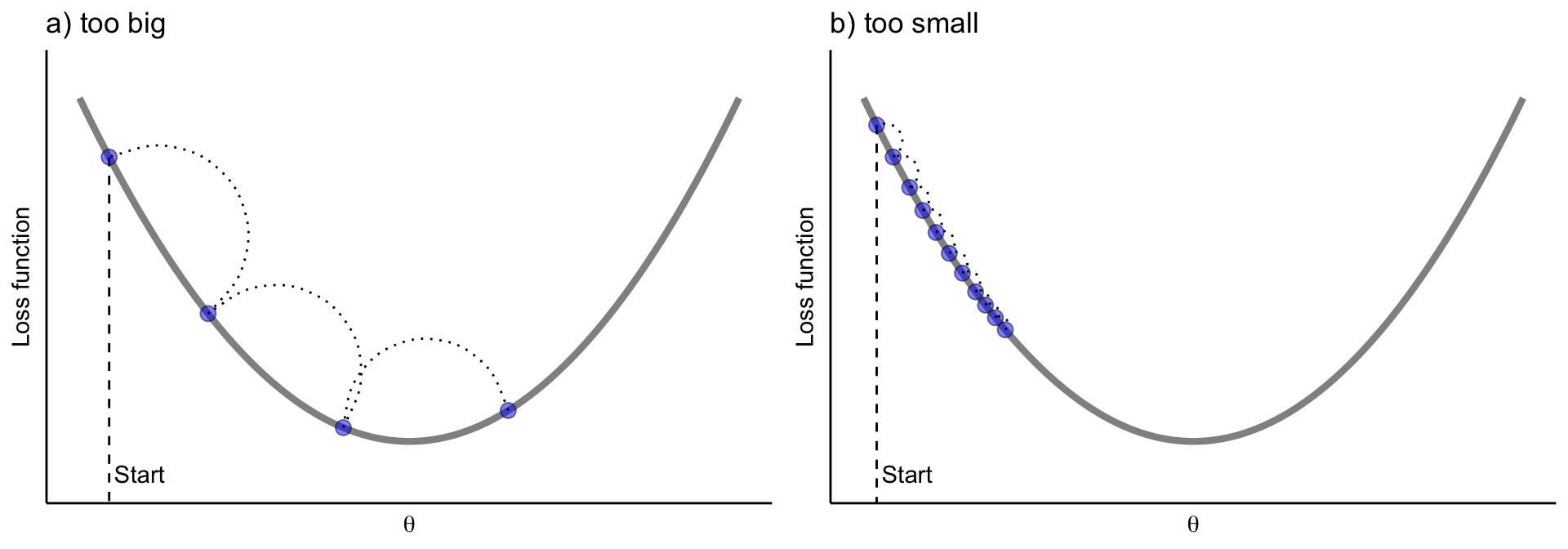
#27
★★★★★
模型評估的目的與重要性
核心概念
模型訓練完成後,需要客觀地評估其性能,判斷模型在未見數據上的表現如何(泛化能力)。評估結果有助於:
- 比較不同模型或不同超參數的效果。
- 診斷模型是否存在問題(如過擬合、欠擬合)。
- 決定模型是否可用於實際部署。
- 向利害關係人報告模型的可信度和預期效果。
#28
★★★★
使用測試集進行最終評估
評估原則
模型的最終性能應使用獨立的測試集進行評估。測試集絕不能用於訓練或調整超參數,以確保評估結果是對模型泛化能力的無偏估計。
#29
★★★★
常見評估指標(分類與迴歸)簡介 (連接 L23303)
指標概覽
需要根據問題類型選擇合適的指標:
- 分類:準確率、精確率、召回率、F1 分數、AUC 等。
- 迴歸:MSE、RMSE、MAE、R² 等。
#30
★★★★★
過擬合 (Overfitting) (參考樣題 Q13)
核心挑戰
模型在訓練數據上表現過好,但在新數據上表現差。模型學習了訓練數據的噪聲和細節,而不是潛在的通用模式。訓練誤差低,測試誤差高是其典型特徵。是機器學習中最常見的問題之一。樣題 Q13 描述此現象。
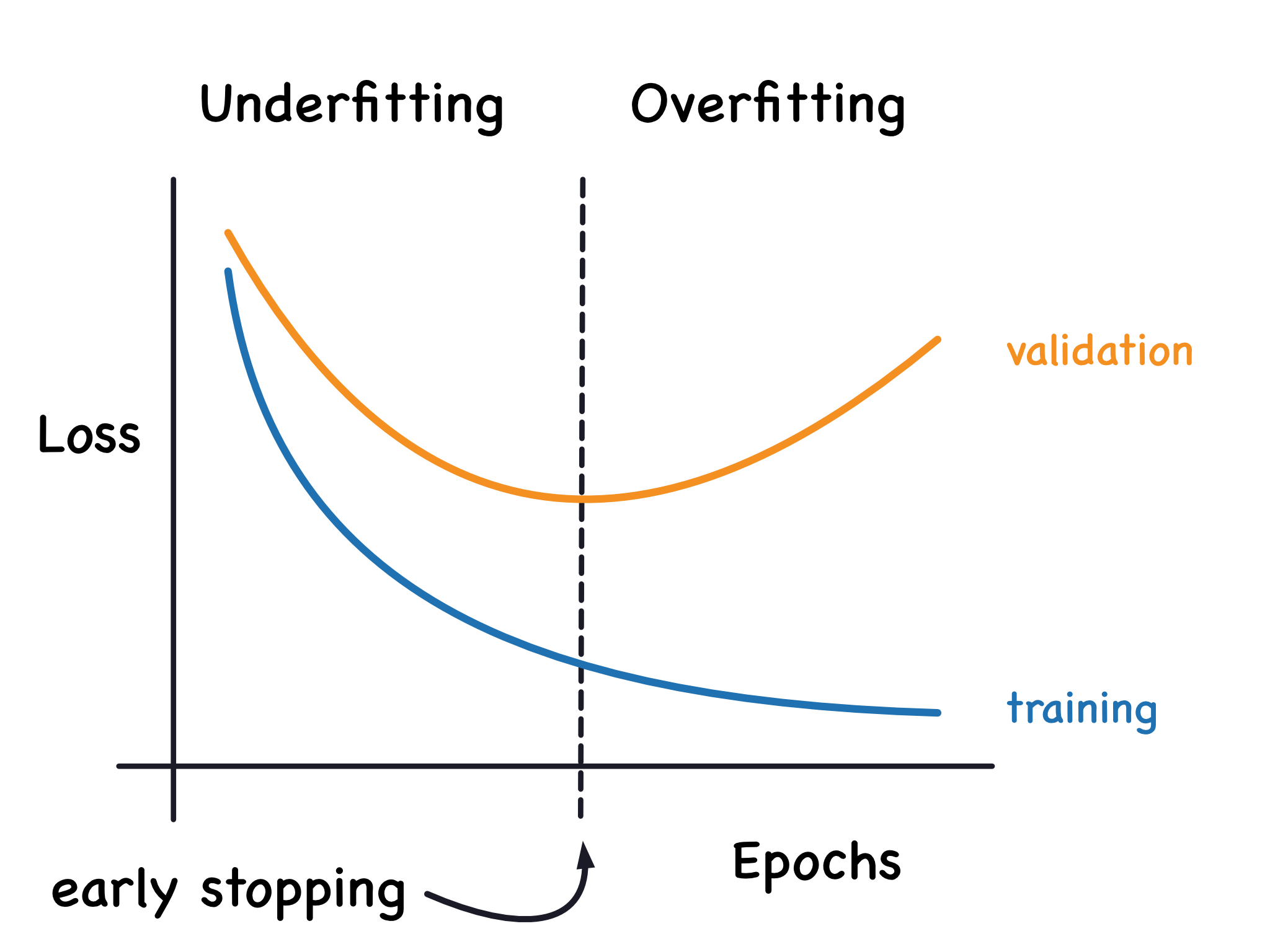
#31
★★★★
欠擬合 (Underfitting)
核心挑戰
模型過於簡單,無法捕捉數據中的基本模式。在訓練集和測試集上表現都不佳。
#32
★★★★★
偏誤-變異數權衡 (Bias-Variance Trade-off)
核心權衡
模型預測誤差的兩個主要來源:偏誤(模型假設與真實情況的差異,高偏誤易欠擬合)和變異數(模型對訓練數據變化的敏感度,高變異數易過擬合)。通常兩者之間存在權衡關係,降低一個可能導致另一個升高。目標是找到平衡點。

#33
★★★★
防止過擬合的常用技術 (參考樣題 Q3)
技術概覽
包括:獲取更多數據、降低模型複雜度、正則化 (L1/L2, Dropout - 樣題 Q3)、交叉驗證、提早停止、數據增強等。
#34
★★★
處理欠擬合的常用技術
技術概覽
包括:增加模型複雜度、添加更多/更好的特徵、減少正則化、延長訓練時間。
#35
★★★★
標準機器學習流程 (ML Workflow)
流程步驟
典型的機器學習專案流程包括:問題定義 -> 數據收集 -> 數據預處理與特徵工程 -> 模型選擇 -> 模型訓練 -> 模型評估 -> 模型調優 -> 模型部署 -> 模型監控與維護。
#36
★★★
常用的機器學習函式庫 (Python)
工具介紹
- Scikit-learn: 提供廣泛的傳統 ML 演算法、預處理工具、評估指標和交叉驗證功能。
- Pandas: 用於數據處理和分析。
- NumPy: 提供數值計算基礎。
- Matplotlib / Seaborn: 用於數據視覺化。
#37
★★★
雲端機器學習平台
工具介紹
各大雲服務商提供機器學習平台,集成了數據儲存、預處理、模型訓練、部署和管理等功能,如 AWS SageMaker, Google Cloud AI Platform, Microsoft Azure Machine Learning。
#38
★★
歸納偏置 (Inductive Bias)
模型假設
學習演算法在遇到未見過的輸入時進行泛化所做出的假設集合。例如,線性迴歸的歸納偏置是假設目標函數是線性的。選擇不同的模型就是選擇不同的歸納偏置。
#39
★★
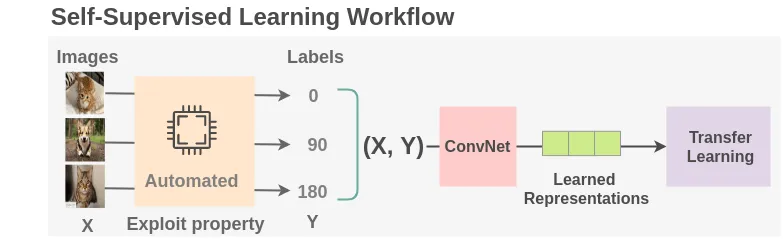
自監督學習 (Self-supervised Learning)
學習類型
一種介於監督與非監督之間的方法,它從未標籤數據中自動生成標籤(例如,預測句子中被遮蓋的詞,或圖像的旋轉角度),然後使用這些自生成的標籤進行監督式訓練。是預訓練大型模型的常用方法。
#40
★★
懶惰學習 (Lazy Learning) vs. 積極學習 (Eager Learning)
學習策略
- 積極學習:在訓練階段就構建好一個明確的模型(如決策樹、線性迴歸)。
- 懶惰學習:訓練階段只是儲存數據,真正的計算(如查找鄰居)發生在預測階段(如 KNN)。
#41
★★
維度災難 (Curse of Dimensionality)
數據挑戰
當數據特徵維度非常高時,數據點會變得非常稀疏,距離度量失去意義,模型訓練需要指數級增長的數據量才能覆蓋空間,導致模型性能下降和計算成本增加。降維和特徵選擇是應對方法。

#42
★★
收斂 (Convergence)
訓練狀態
指模型訓練過程中,損失函數的值達到穩定,不再顯著下降,或者模型參數不再發生大的變化的狀態。表示訓練過程已找到一個(可能是局部的)最優解。
#43
★★
基於成本/效益的評估
評估視角
除了標準指標,還需要從業務角度評估模型的成本和效益。例如,不同預測錯誤類型(假陽性/假陰性)可能對應不同的業務成本,需要納入評估考量。
#44
★★
數據不平衡問題 (Data Imbalance Problem)
數據挑戰
指數據集中不同類別的樣本數量差異懸殊。這會導致模型傾向於預測多數類,而在少數類上表現很差,使得準確率等指標失效。需要使用重抽樣、代價敏感學習或選擇合適的評估指標(如 F1, AUC)來處理。
#45
★★
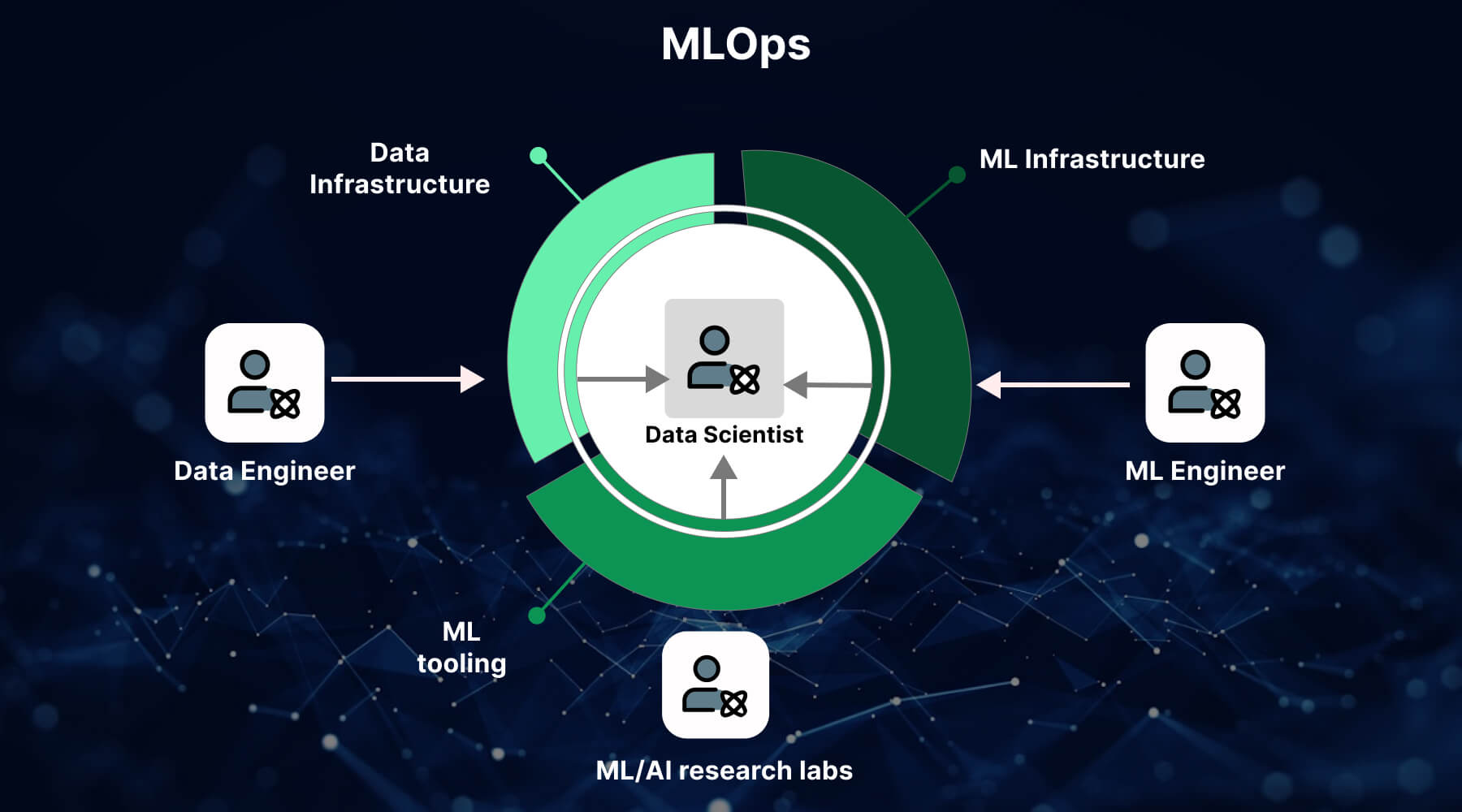
MLOps (Machine Learning Operations)
實踐方法
一套旨在簡化、標準化和自動化機器學習模型開發、部署和維護流程的實踐和工具。強調協作、可重現性、持續整合/持續部署 (CI/CD) 和監控。
#46
★
機器學習與統計學的關係
學科關聯
機器學習大量借鑒了統計學的概念和方法(如機率分佈、假設檢定、迴歸分析)。統計學提供了理論基礎和嚴謹性,而機器學習更側重於預測性能和演算法實現。
#47
★
學習問題的設定
前提步驟
在應用機器學習前,需要清晰地定義問題:是分類、迴歸還是其他?輸入特徵是什麼?期望的輸出是什麼?如何評估成功?
#48
★
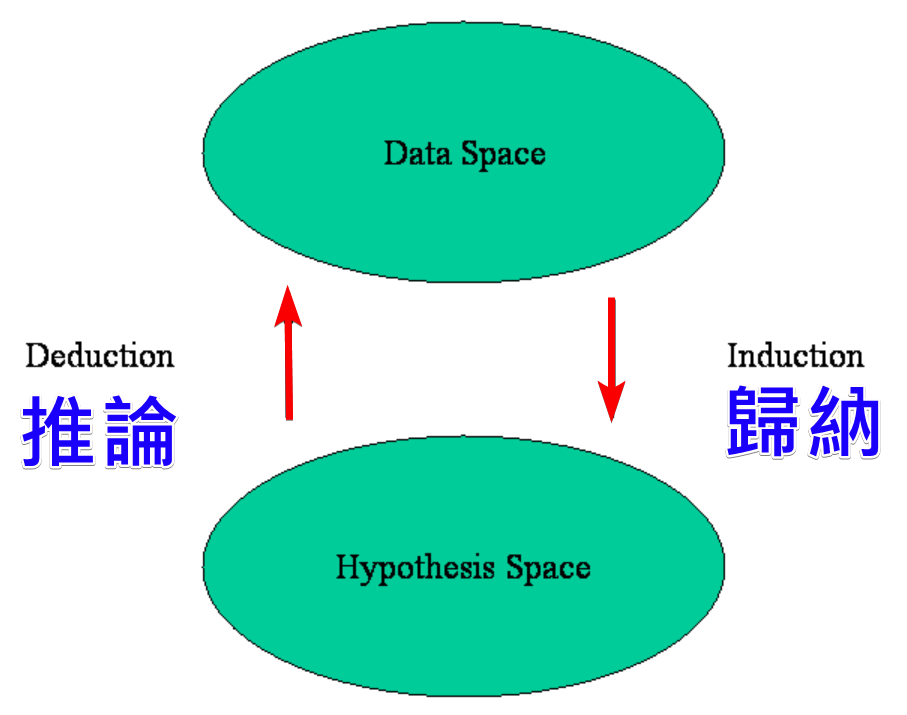
假設空間 (Hypothesis Space)
理論概念
指學習演算法可能學習到的所有可能函數(模型)的集合。演算法的目標是在這個空間中搜索最佳的假設(模型)來擬合數據。
#49
★
特徵縮放 (Feature Scaling) 的必要性
預處理
對於基於距離計算(如 KNN, K-Means, SVM)或使用梯度下降優化(如線性模型、神經網路)的演算法,特徵縮放(標準化或正規化)通常是必要的,以避免數值範圍大的特徵主導計算。基於樹的模型則通常不需要。
#50
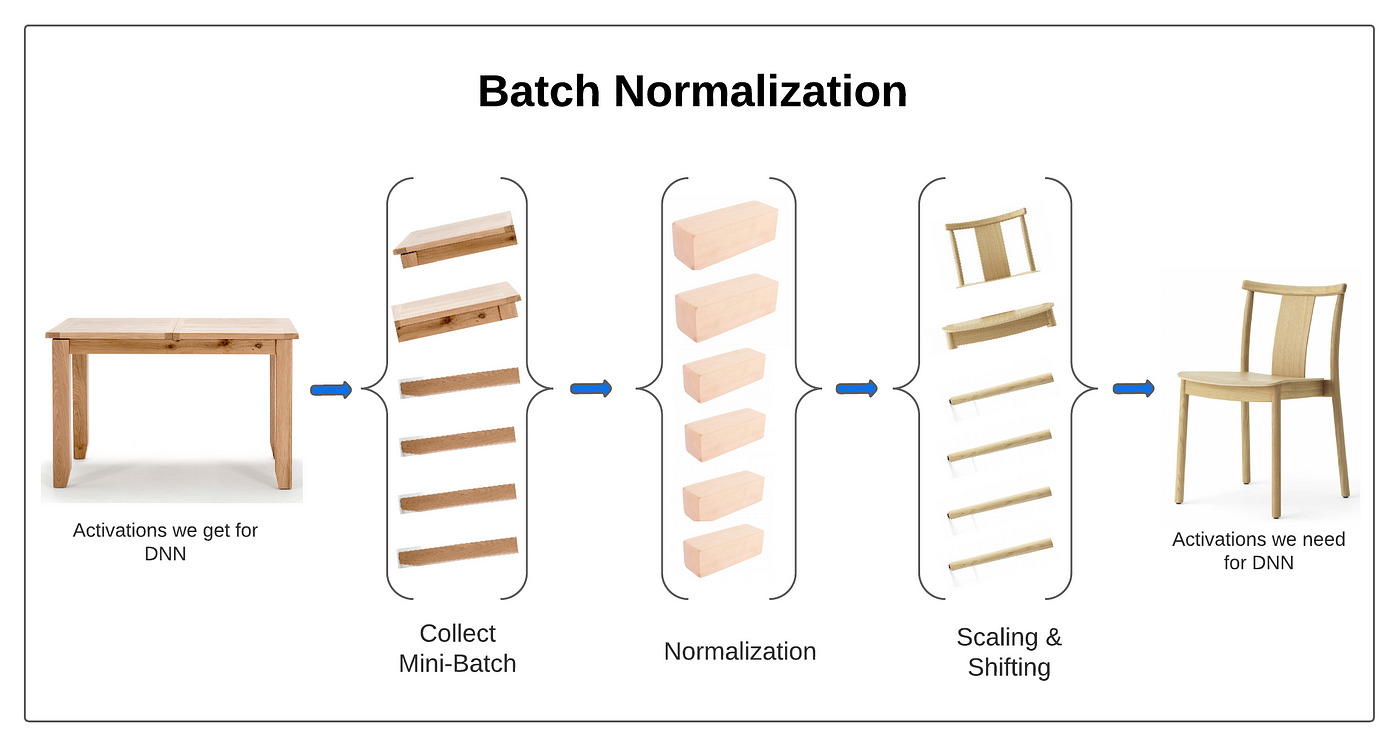
★
批次正規化 (Batch Normalization)
訓練技巧 (深度學習)
在神經網路訓練中,對每個小批次的數據在進入激活函數前進行標準化處理。有助於加速訓練、穩定梯度,並具有一定的正則化效果。
#51
★
模型評估指標的選擇陷阱
注意事項
需要警惕單一指標的局限性,例如在不平衡數據下只看準確率。應結合多個指標和業務背景進行綜合評估。
#52
★
模型容量 (Model Capacity) 控制
核心挑戰
選擇恰當的模型容量是避免欠擬合和過擬合的關鍵。需要在模型的表達能力和泛化能力之間找到平衡。
#53
★
實驗追蹤 (Experiment Tracking)
流程工具
使用工具(如 MLflow, Weights & Biases)記錄模型訓練過程中的超參數、代碼版本、性能指標等,對於可重現性和比較實驗結果非常重要。
#54
★
樣本 (Sample/Instance/Record)
核心術語
數據集中的單個觀測值或數據點,通常由一組特徵和(在監督學習中)一個標籤組成。
#55
★
離線學習 (Offline Learning) vs. 線上學習 (Online Learning)
學習方式
- 離線學習(批次學習):使用所有可用數據一次性訓練模型。
- 線上學習:模型可以逐步地、增量地用新到達的數據進行更新。
#56
★
數據清洗 (Data Cleaning)
預處理
處理數據中的錯誤、不一致、重複或格式問題,以提高數據品質。是數據預處理的重要環節。
#57
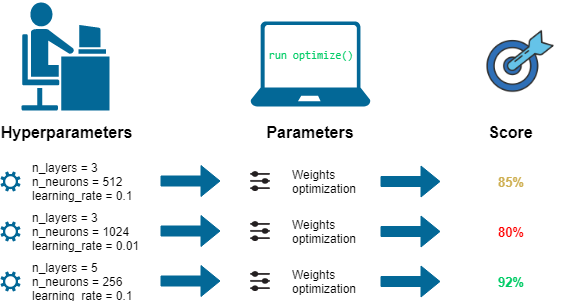
★
超參數 (Hyperparameter)
概念
在訓練開始前設定,用於控制學習過程的參數(如學習率、正則化強度)。需要透過模型調優來選擇最佳值。
#58
★
模型泛化 (Generalization)
核心目標
指訓練好的模型在未見過的新數據上表現良好的能力。是評估模型好壞的最終標準。
#59
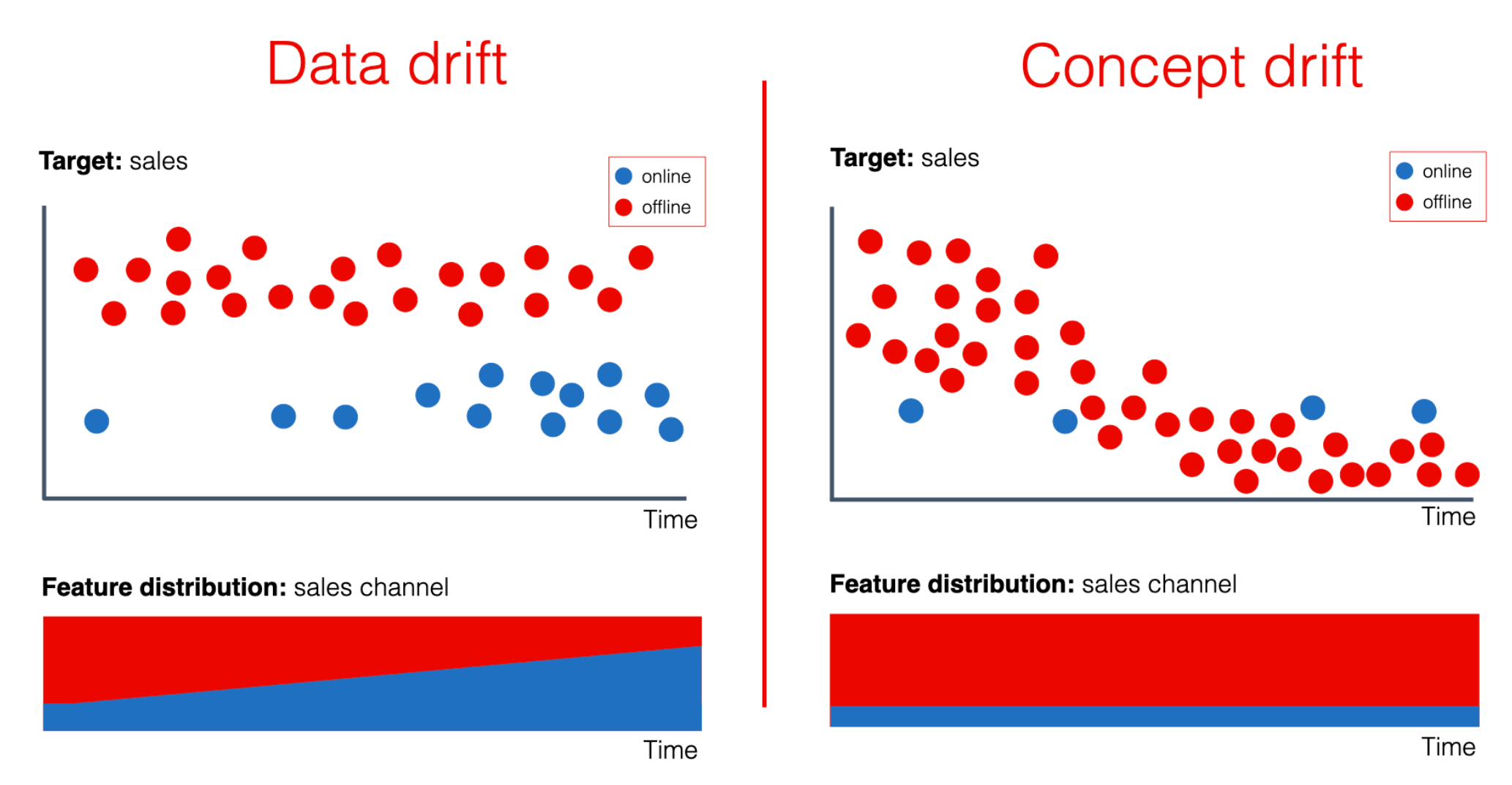
★
數據漂移 (Data Drift)
挑戰
指生產環境中的數據分佈隨時間發生變化,可能導致已部署模型的性能下降。需要模型監控和定期更新。
#60
★
Jupyter Notebook
常用工具
一個交互式計算環境,廣泛用於數據科學和機器學習的探索性分析、代碼編寫、視覺化和結果展示。
沒有找到符合條件的重點。
↑