iPAS AI應用規劃師 考試重點
L22401 大數據與機器學習
主題分類
1
大數據對機器學習的影響
2
大數據環境下的機器學習流程
3
分散式機器學習概念
4
常用分散式機器學習框架
5
數據儲存與ML模型整合
6
模型訓練與評估的挑戰
7
可擴展性與效能考量
8
特定ML算法在大數據的應用
#1
★★★★★
大數據 (Big Data) 的機器學習 (ML) 驅動力
核心概念
大數據的海量資料為機器學習模型提供了豐富的訓練樣本,使得模型能夠學習到更複雜、更細微的模式和關係。
許多複雜模型,尤其是深度學習 (Deep Learning) 模型,其性能會隨著訓練數據量的增加而顯著提升。大數據使得這些數據密集型模型的應用成為可能。
許多複雜模型,尤其是深度學習 (Deep Learning) 模型,其性能會隨著訓練數據量的增加而顯著提升。大數據使得這些數據密集型模型的應用成為可能。
#2
★★★★
大數據特性 (Volume, Velocity, Variety) 對ML的挑戰
核心概念
大數據的 "3V" 特性給傳統機器學習帶來挑戰:
- 數據量 (Volume):數據太大,無法在單機記憶體中處理,需要分散式儲存和計算。
- 數據速度 (Velocity):數據快速生成,需要流處理 (Stream Processing) 和線上學習 (Online Learning) 能力。
- 數據多樣性 (Variety):數據來源和格式多樣(結構化、半結構化、非結構化),需要更複雜的數據預處理和特徵工程技術。

#3
★★★★
大數據環境下的機器學習流程調整
核心概念
相比傳統 ML 流程,大數據環境下的 ML 流程需要特別考量:
- 數據獲取與儲存:使用 HDFS, 數據湖 (Data Lake) 等分散式儲存。
- 數據預處理:使用 Spark, MapReduce 等工具進行分散式數據清理、轉換、特徵工程。
- 模型訓練:採用分散式機器學習算法和框架(如 Spark MLlib)。
- 模型評估:可能需要在抽樣數據或使用分散式評估方法。
- 模型部署與監控:考慮模型的可擴展性和即時預測需求。
#4
★★★★★
分散式機器學習 (Distributed Machine Learning) - 基本概念
核心概念
分散式機器學習是指將數據和/或計算任務分佈到多台計算機(節點)組成的集群上進行機器學習模型訓練和推斷的過程。
主要動機:處理單機無法處理的大規模數據集,或加速複雜模型的訓練過程。
主要動機:處理單機無法處理的大規模數據集,或加速複雜模型的訓練過程。
#5
★★★★
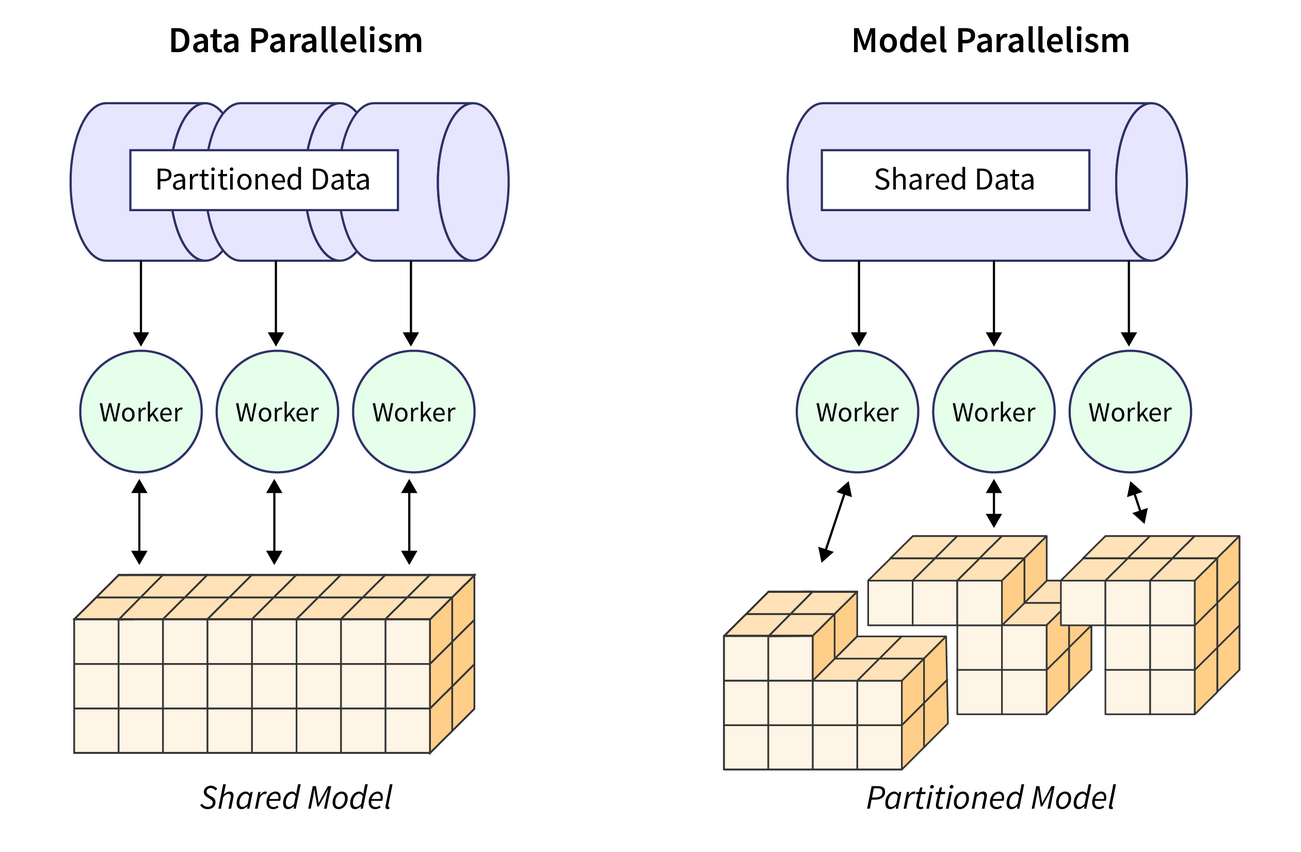
分散式訓練策略:數據並行 vs 模型並行
核心概念
兩種主要的分散式訓練策略:
- 數據並行 (Data Parallelism):將數據集分割成多個子集,每個節點上都有一份完整的模型副本,各節點處理自己的數據子集計算梯度,然後通過參數伺服器 (Parameter Server) 或 AllReduce 等方式匯總梯度並更新模型參數。是最常用的策略。
- 模型並行 (Model Parallelism):當模型本身非常大,無法放入單個節點的記憶體時,將模型的不同部分(如神經網路的不同層)分配到不同的節點上進行計算。通常更複雜,用於超大規模模型。
#6
★★★★★
分散式框架:Apache Spark MLlib
核心概念
MLlib 是 Spark 的原生機器學習函式庫,構建在 Spark 核心之上,旨在簡化大規模機器學習流程。
主要組件:
主要組件:
- ML 算法:提供常用分類、迴歸、聚類、推薦等算法的分散式實現。
- 特徵工程:包括特徵提取、轉換、降維、選擇等工具。
- 管道 (Pipelines):用於構建、評估和調優端到端的 ML 工作流程。
- 持久化:保存和加載算法、模型和管道。

#7
★★★★
Spark MLlib - DataFrame-based API
核心概念
新版本的 MLlib 主要使用基於 DataFrame 的 API (位於 `spark.ml` 套件),相比舊的基於 RDD 的 API (`spark.mllib`) 提供了更統一、更易用的接口。
核心概念:
核心概念:
- Transformer:實現 `transform()` 方法,將一個 DataFrame 轉換為另一個 DataFrame(通常是添加新列),如特徵轉換器、訓練好的模型。
- Estimator:實現 `fit()` 方法,接收一個 DataFrame 並訓練(擬合)出一個 Transformer(模型)。如分類器、迴歸器。
- Pipeline:將多個 Transformer 和 Estimator 串聯起來,組成一個工作流程。
- Parameter:算法的參數,可通過統一接口設置。
#8
★★★
其他分散式 ML 框架 (提及)
核心概念
除了 Spark MLlib,還有其他用於分散式機器學習的框架:
- TensorFlow / Keras:支持分散式深度學習訓練(數據並行、模型並行)。
- PyTorch:也提供分散式訓練功能 (DistributedDataParallel)。
- Horovod:由 Uber 開源的分散式深度學習訓練框架,可與 TensorFlow, Keras, PyTorch 配合使用。
- Dask-ML:類似 Spark MLlib,但基於 Dask 分散式計算框架。
#9
★★★★
數據儲存選擇對ML的影響
核心概念
數據的儲存方式會影響 ML 流程的效率和可行性:
- 檔案系統 (File Systems - 如 HDFS, S3):適合儲存大規模、各種格式的原始數據或中間結果。與 Spark 等分散式處理框架集成良好。
- 數據倉儲 (Data Warehouses - 如 Snowflake, BigQuery):適合儲存結構化、已處理的數據,提供 SQL 查詢接口,但可能不適合直接用於大規模模型訓練的原始數據訪問。
- NoSQL 資料庫:根據類型(鍵值、文檔、列式、圖形)適用於特定場景,如特徵儲存 (Feature Store)。
#10
★★★
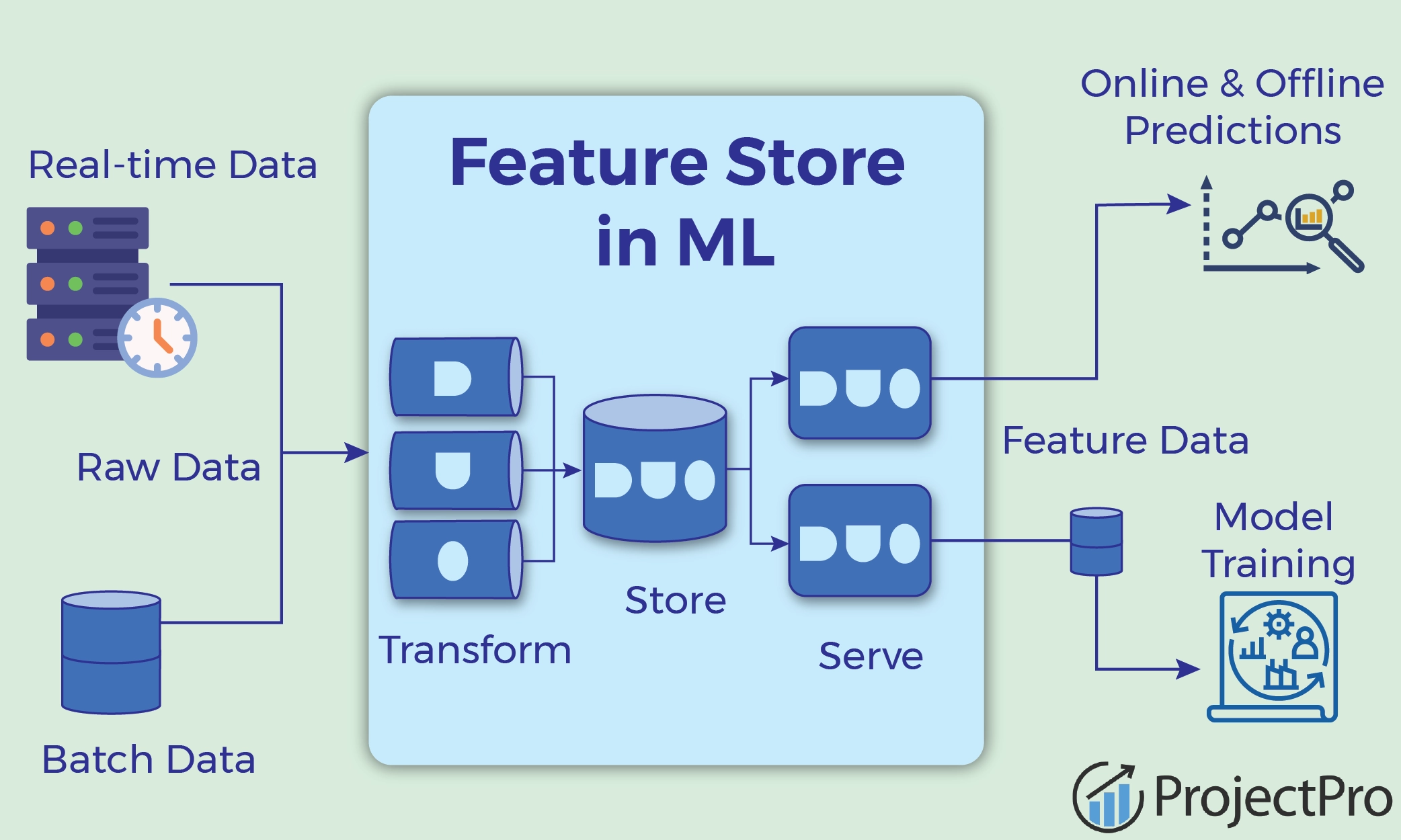
特徵儲存 (Feature Store)
核心概念
特徵儲存是一個集中管理、發現、共享和服務機器學習特徵的系統。
目的:
目的:
- 解決特徵工程中的重複工作。
- 確保訓練和推斷時使用的特徵一致性(避免 Training-Serving Skew)。
- 提供標準化的特徵訪問接口。
- 監控特徵質量和漂移。
#11
★★★★
大數據下的模型訓練挑戰:時間與資源
核心概念
使用大數據訓練模型的主要挑戰:
- 訓練時間長:即使使用分散式框架,處理大量數據和複雜模型也可能需要數小時甚至數天。
- 計算資源需求高:需要大量的 CPU/GPU、記憶體和網路帶寬,導致成本增加。
- 超參數調優困難:由於單次訓練時間長,進行網格搜索 (Grid Search) 或隨機搜索 (Random Search) 等超參數調優變得非常耗時。
#12
★★★★
大數據下的模型評估挑戰
核心概念
在大數據環境中評估模型性能也面臨挑戰:
- 評估時間:對整個大型測試集進行預測和評估可能很耗時。
- 代表性抽樣:如果使用抽樣數據進行評估,需要確保樣本能夠代表整體數據的分佈。
- 指標選擇:對於不平衡數據集,準確率 (Accuracy) 可能具有誤導性,需要關注 AUC, Precision-Recall Curve, F1-Score 等指標。
- 分散式評估:需要使用支持分散式計算的評估工具。
#13
★★★★★
可擴展性 (Scalability) 的重要性
核心概念
可擴展性是指系統(包括數據處理和 ML 流程)處理不斷增長的數據量或計算負載的能力。
在大數據環境下,ML 系統必須設計成可擴展的,以便:
在大數據環境下,ML 系統必須設計成可擴展的,以便:
- 處理未來數據量的增長。
- 通過增加計算資源(如添加更多節點)來提高處理速度或容量(水平擴展 Horizontal Scaling / Scale Out)。
#14
★★★
效能考量:記憶體管理與磁碟 I/O
核心概念
在分散式系統中,效能優化至關重要:
- 記憶體管理:Spark 等框架利用記憶體計算加速處理,但記憶體是有限資源。需要有效管理記憶體使用,避免記憶體不足 (Out of Memory, OOM) 錯誤。策略包括數據分區、序列化、緩存管理。
- 磁碟 I/O:雖然記憶體計算快,但數據通常需要從磁碟讀取或寫入磁碟(尤其是中間結果或最終輸出)。減少不必要的磁碟讀寫、選擇高效的文件格式(如 Parquet, ORC)可以提高效能。
- 網路傳輸:數據在節點間的傳輸(Shuffle)是主要的效能瓶頸之一。優化數據分區、減少 Shuffle 操作是關鍵。
#15
★★★
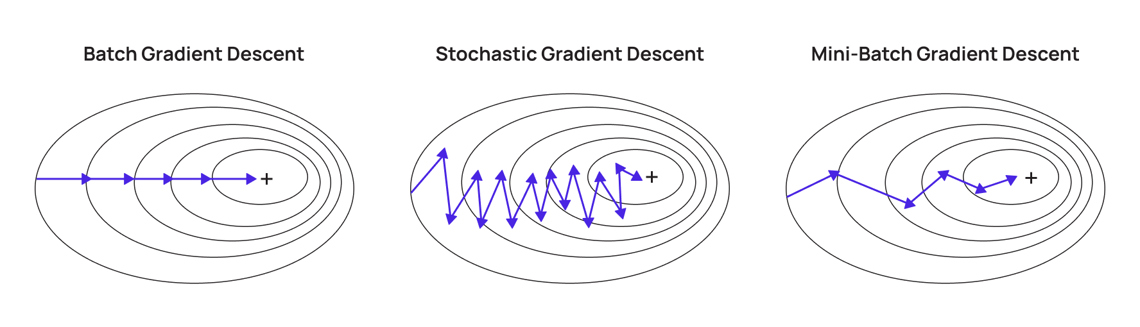
梯度下降法 (GD) 在大數據下的變種
核心概念
梯度下降法是許多 ML 模型的優化基礎。在大數據下,標準的批次梯度下降 (Batch GD) 需要計算整個數據集的梯度,成本高昂。
常用變種:
常用變種:
- 隨機梯度下降 (SGD, Stochastic Gradient Descent):每次迭代只使用一個樣本計算梯度並更新參數。速度快,但梯度變異大,收斂不穩定。
- 小批次梯度下降 (Mini-batch GD):每次迭代使用一小批樣本計算梯度。是最常用的方法,平衡了計算效率和收斂穩定性。
#16
★★★
決策樹 (Decision Tree) 算法在大數據下的考慮
核心概念
分散式框架(如 Spark MLlib)通常提供分散式決策樹和基於樹的集成算法(如隨機森林 Random Forest, 梯度提升樹 GBT)的實現。
挑戰:
挑戰:
- 尋找最佳分裂點需要在所有節點上進行數據掃描和通信,成本較高。
- 需要有效處理數據分區和節點間的統計信息匯總。
#17
★★
聚類算法 (Clustering) 在大數據下的應用
核心概念
將大量數據點分組成相似的群體。
Spark MLlib 提供了常用聚類算法的分散式實現:
Spark MLlib 提供了常用聚類算法的分散式實現:
- K-均值 (K-Means):簡單高效,但對初始中心敏感且假設簇為球狀。
- 高斯混合模型 (GMM, Gaussian Mixture Model):基於機率的模型,可以處理更複雜的簇形狀。
- LDA (Latent Dirichlet Allocation):常用於文本主題建模。
#18
★★★
大數據與模型泛化能力
核心概念
更多的數據通常有助於提高模型的泛化能力 (Generalization Ability),即模型在未見數據上的表現。
原因:
原因:
- 大數據更能覆蓋數據的真實分佈,減少因訓練數據偏差導致的過擬合。
- 允許訓練更複雜的模型來捕捉細微模式,而不過度擬合噪聲(前提是數據量足夠大)。
#19
★★★
迭代式 (Iterative) 算法在大數據下的挑戰
核心概念
許多機器學習算法(如梯度下降、K-Means、期望最大化 EM)都是迭代式的,需要多次遍歷數據集。
在大數據環境下,每次迭代都可能涉及大量的磁碟 I/O 或網路通信,導致效能瓶頸。
Spark 等記憶體計算框架通過將數據緩存在記憶體中,顯著加速了迭代式算法的執行效率。
在大數據環境下,每次迭代都可能涉及大量的磁碟 I/O 或網路通信,導致效能瓶頸。
Spark 等記憶體計算框架通過將數據緩存在記憶體中,顯著加速了迭代式算法的執行效率。
#20
★★★★
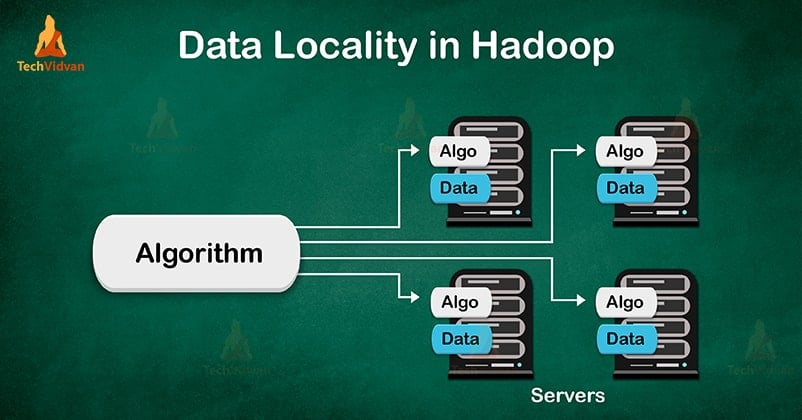
數據局部性 (Data Locality)
核心概念
數據局部性是指將計算移動到數據所在的節點,而不是將數據移動到計算節點的原則。
在分散式計算中,網路傳輸通常是最大的瓶頸。最大化數據局部性可以顯著減少網路開銷,提高處理效率。
像 Hadoop 和 Spark 這樣的框架會盡力將任務調度到存儲有所需數據塊的節點上執行。
在分散式計算中,網路傳輸通常是最大的瓶頸。最大化數據局部性可以顯著減少網路開銷,提高處理效率。
像 Hadoop 和 Spark 這樣的框架會盡力將任務調度到存儲有所需數據塊的節點上執行。
沒有找到符合條件的重點。
↑