iPAS AI應用規劃師 經典題庫
L22303 數據可視化工具
出題方向
1
數據視覺化基本概念與原則
2
常見視覺化圖表類型與適用場景
3
主流數據視覺化工具介紹
4
Tableau 操作與應用
5
Power BI 操作與應用
6
Python 視覺化函式庫
7
互動式視覺化與儀表板設計
8
視覺化最佳實踐與常見錯誤
#1
★★★★★
數據視覺化的主要目的是什麼?
答案解析
數據視覺化是將數據轉換成圖形或圖像形式的過程。其核心目標是利用人類視覺系統的強大模式識別能力,使複雜的數據更容易被理解、分析和溝通。透過視覺化,可以快速發現數據中的模式、趨勢、關聯性、異常值等,從而獲得有價值的洞察,輔助決策。雖然美觀也很重要,但並非主要目的。視覺化是溝通工具,通常輔助而非取代文字報告,也不能自動執行分析,而是呈現分析結果。
#2
★★★★
若要比較不同產品類別在某一季度的銷售額,哪種圖表類型最為適合?
答案解析
長條圖非常適合用來比較不同類別(產品類別)之間的數值大小(銷售額)。每個長條代表一個類別,長條的高度或長度對應其數值,便於直觀比較。折線圖常用於展示數據隨時間變化的趨勢。散佈圖用於觀察兩個連續變數之間的關係。圓餅圖雖然也能展示各類別佔比,但在比較精確數值大小方面不如長條圖清晰,尤其當類別較多或佔比接近時。
#3
★★★★★
Tableau 和 Power BI 是市面上常見的兩種數據視覺化工具,它們主要屬於哪種類型的工具?
答案解析
Tableau 和 Microsoft Power BI 是領先的商業智慧 (Business Intelligence, BI) 和數據視覺化平台。它們提供了強大的功能,讓使用者可以連接多種數據源,進行數據清理、轉換、分析,並創建互動式的視覺化圖表和儀表板,以探索數據和分享洞察。它們通常具有圖形化使用者介面 (Graphical User Interface, GUI),降低了使用的技術門檻。選項 A 指的是像 Python 的 Matplotlib 或 JavaScript 的 D3.js。選項 B 指的是 Excel 或 Google Sheets。選項 D 指的是 SQL Server 或 MySQL 等。
#4
★★★★
想要展示某公司產品銷售額隨時間(例如,按月)變化的趨勢,應優先選擇哪種圖表?
答案解析
折線圖特別適合用來展示連續數據隨時間或其他有序變數變化的趨勢。將時間(月份)放在橫軸,銷售額放在縱軸,用線條連接各個時間點的數據,可以清晰地看出銷售額的上升、下降、季節性波動等趨勢。盒鬚圖展示數據分佈。長條圖比較類別。散佈圖看變數關係。
#5
★★★
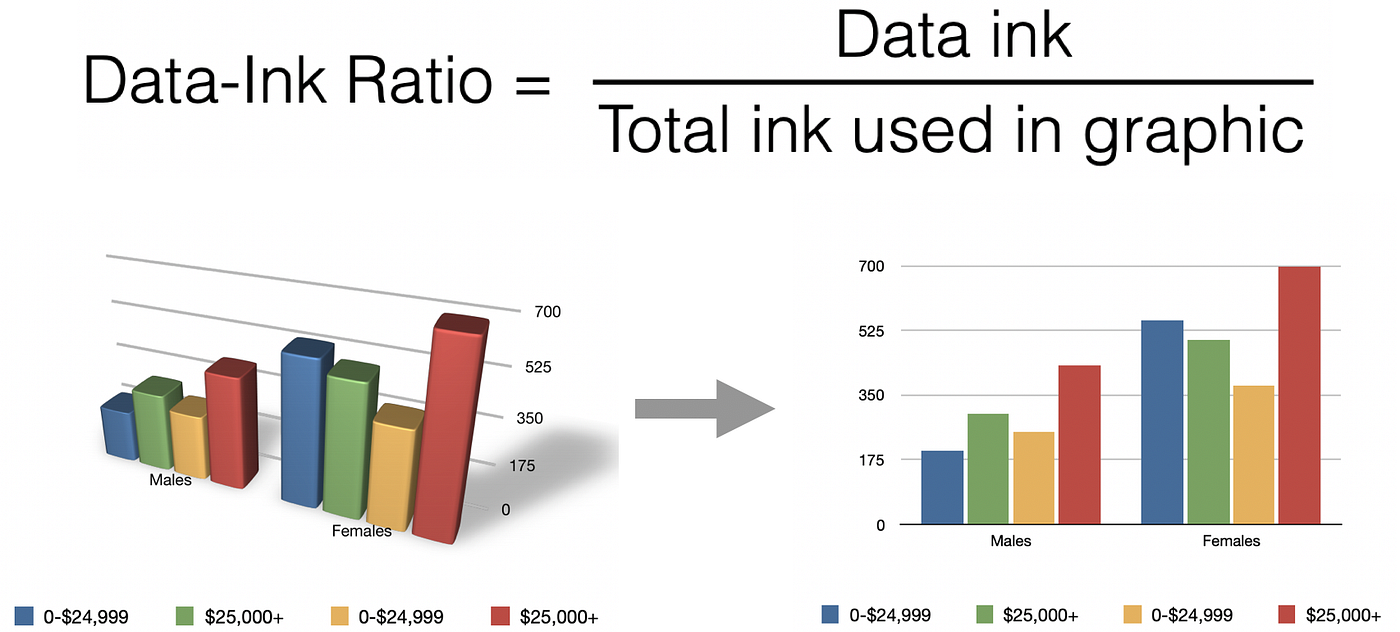
數據墨水比 (Data-Ink Ratio) 是由 Edward Tufte 提出的概念,其核心思想是什麼?
答案解析
數據墨水比 (Data-Ink Ratio) 強調視覺化設計應聚焦於數據本身。其計算方式是:(用於顯示數據的墨水量) / (圖表總墨水量)。Tufte 主張應最大化這個比例,意味著圖表中大部分的「墨水」(或像素)都應該直接用於呈現數據資訊,而應盡量去除或減少不必要的圖形元素,如過多的格線、邊框、背景、裝飾性圖片、陰影、非必要的顏色變化等,這些被稱為「圖表垃圾」(Chartjunk)。目標是讓圖表簡潔、清晰、高效地傳達數據。
#6
★★★★
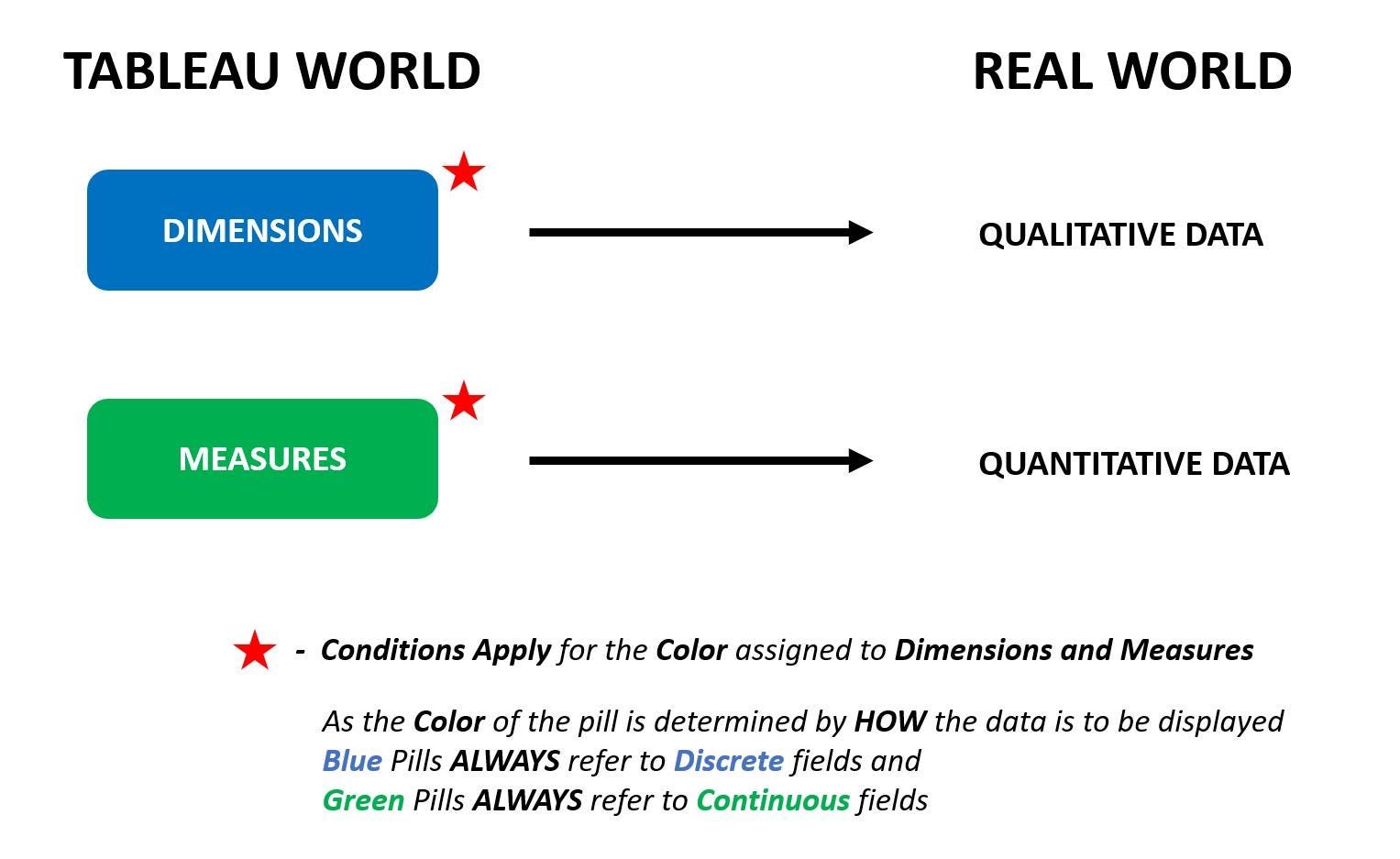
在 Tableau 中,通常將需要進行聚合計算的數值欄位(例如銷售額、利潤)歸類為什麼?
答案解析
Tableau 將數據欄位分為兩大類:
維度 (Dimensions): 通常是定性的、分類的欄位,用來定義數據的粒度或進行分組,例如產品類別、地區、日期。拖曳到工作表中時,通常會產生標頭或標籤。
度量 (Measures): 通常是定量的、數值的欄位,可以進行數學運算(如求和、平均、計數),例如銷售額、利潤、數量。拖曳到工作表中時,通常會產生軸或數值標記。
因此,銷售額、利潤等可聚合的數值欄位屬於度量。
維度 (Dimensions): 通常是定性的、分類的欄位,用來定義數據的粒度或進行分組,例如產品類別、地區、日期。拖曳到工作表中時,通常會產生標頭或標籤。
度量 (Measures): 通常是定量的、數值的欄位,可以進行數學運算(如求和、平均、計數),例如銷售額、利潤、數量。拖曳到工作表中時,通常會產生軸或數值標記。
因此,銷售額、利潤等可聚合的數值欄位屬於度量。
#7
★★★★
Power BI 中的 DAX (Data Analysis Expressions) 主要用途是什麼?
答案解析
DAX (Data Analysis Expressions) 是 Power BI (以及 SQL Server Analysis Services 和 Excel Power Pivot) 中使用的一種公式語言。它包含一系列函數、運算子和常數,可以用來在數據模型中執行進階計算和查詢。使用者可以利用 DAX 創建新的資訊(如計算欄位 Calculated Columns、量值 Measures),這些新資訊基於模型中已有的數據,從而實現更複雜的分析邏輯,例如計算年同比增長率 (Year-over-Year Growth)、移動平均 (Moving Average) 等。
.jpg)
#8
★★★
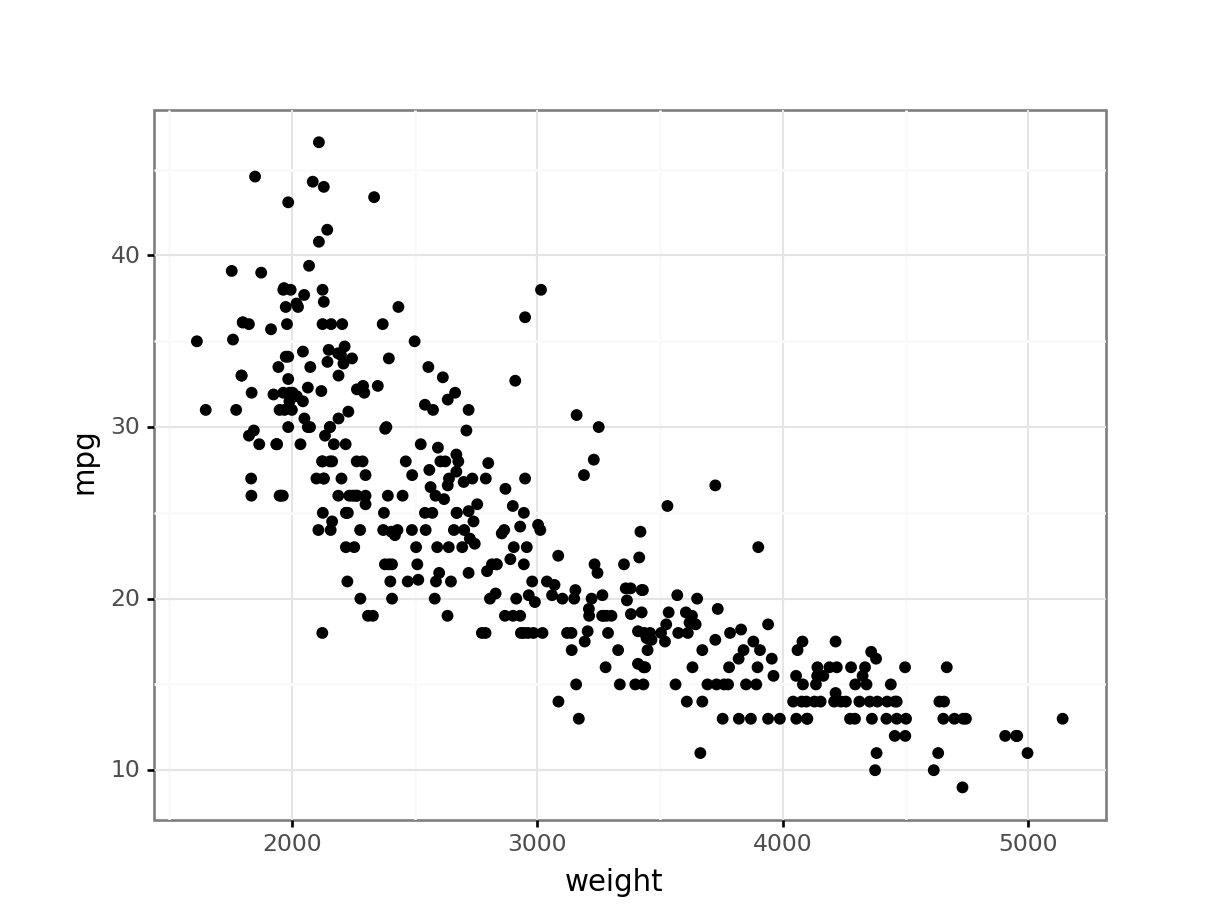
若要視覺化兩個連續變數之間的關係,並觀察是否存在線性相關、群集或異常值,哪種圖表最適合?
答案解析
散佈圖是視覺化兩個連續變數關係的標準方法。每個數據點在圖上對應一個 (x, y) 座標,x 值來自一個變數,y 值來自另一個變數。通過觀察點的分佈模式,可以判斷變數間是否存在正相關、負相關、非線性關係,或者是否存在明顯的群集或遠離主要群體的異常值。
#9
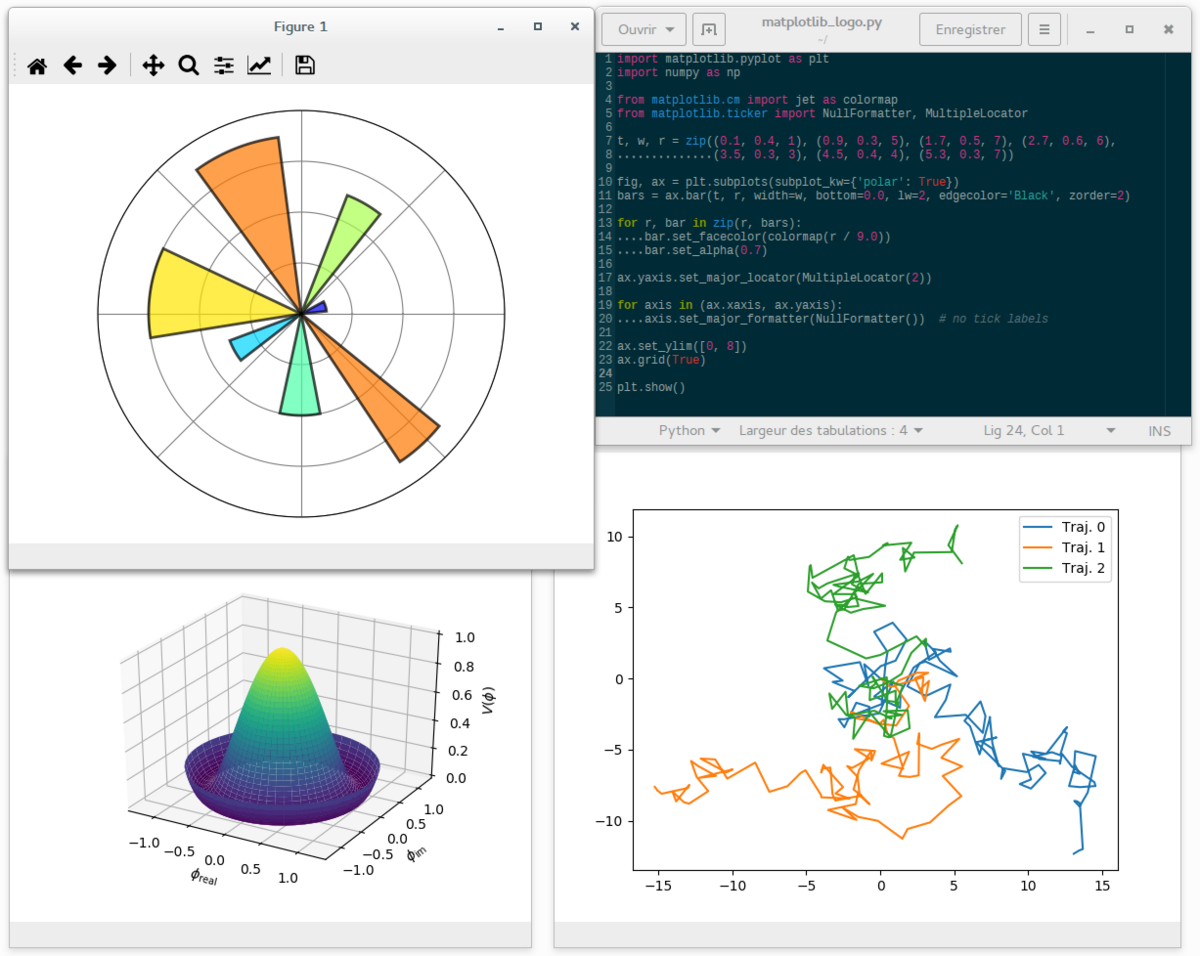
★★★★
在 Python 中,哪個函式庫是數據視覺化的基礎,提供了類似 MATLAB 的繪圖介面,且被許多其他高階視覺化函式庫(如 Seaborn)所依賴?
答案解析
Matplotlib 是 Python 生態系統中最基礎、最廣泛使用的繪圖函式庫。其名稱源自「MATLAB-style Plotting Library」,意在為 Python 提供類似 MATLAB 的繪圖功能。它提供了一個靈活的物件導向 API,可以創建各種類型的靜態、動態和互動式視覺化圖表。許多其他 Python 視覺化函式庫,例如 Seaborn(提供更美觀、更高級的統計圖形)和 Pandas 內建的繪圖功能,底層都是基於 Matplotlib 構建的。NumPy 是數值計算的基礎函式庫。Pandas 是數據處理和分析的函式庫。Scikit-learn 是機器學習的函式庫。
#10
★★★★
設計數據儀表板 (Dashboard) 時,最重要的原則之一是什麼?
答案解析
有效的儀表板設計應該以清晰傳達關鍵資訊為首要目標。這意味著:
1.了解受眾:儀表板是為誰設計的?他們關心哪些指標?他們的數據素養如何?
2.聚焦關鍵指標 (KPIs):不應堆砌過多資訊,而應突出最重要的指標,避免資訊過載。
3.選擇合適的圖表:根據要傳達的資訊選擇最有效的圖表類型。
4.保持簡潔與一致:版面配置清晰,視覺風格一致,易於理解。
5.提供上下文:僅有數字是不夠的,需要比較(例如與目標、與上期比較)和趨勢來賦予數字意義。
包含過多圖表、使用不必要的複雜圖表,或僅僅頻繁刷新數據都可能降低儀表板的有效性。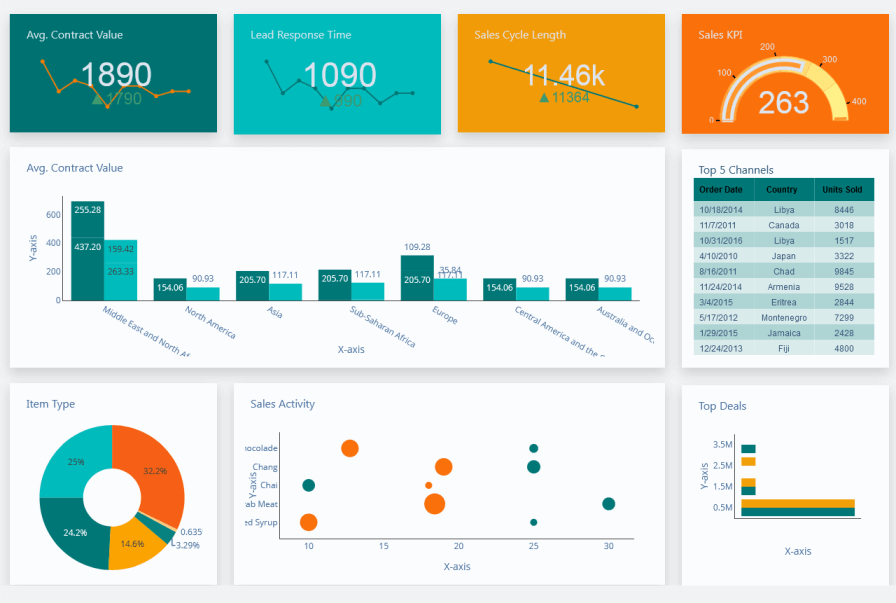 >
>
1.了解受眾:儀表板是為誰設計的?他們關心哪些指標?他們的數據素養如何?
2.聚焦關鍵指標 (KPIs):不應堆砌過多資訊,而應突出最重要的指標,避免資訊過載。
3.選擇合適的圖表:根據要傳達的資訊選擇最有效的圖表類型。
4.保持簡潔與一致:版面配置清晰,視覺風格一致,易於理解。
5.提供上下文:僅有數字是不夠的,需要比較(例如與目標、與上期比較)和趨勢來賦予數字意義。
包含過多圖表、使用不必要的複雜圖表,或僅僅頻繁刷新數據都可能降低儀表板的有效性。
>
#11
★★★
在視覺化中使用 3D 圖表(例如 3D 長條圖、3D 圓餅圖)通常會帶來什麼問題?
答案解析
雖然 3D 圖表看起來可能比較酷炫,但在數據視覺化中通常不被推薦,因為它們引入的透視效果會導致視覺失真。例如,在 3D 圓餅圖中,靠近觀察者的扇區會顯得比實際佔比更大;在 3D 長條圖中,比較不同長條的高度會變得很困難。這違反了清晰準確傳達數據的原則。大多數情況下,對應的 2D 圖表是更好的選擇。
#12
★★★
熱力圖 (Heatmap) 主要用於視覺化哪種數據?
答案解析
熱力圖是一種將矩陣數據視覺化的方法。它使用顏色的變化(例如,從淺到深或冷色到暖色)來表示矩陣中每個單元格的數值大小。顏色越深或越暖通常代表數值越大。熱力圖常用於顯示相關係數矩陣、基因表達數據、網站點擊熱區分析等,可以快速識別矩陣中的模式和高低值區域。
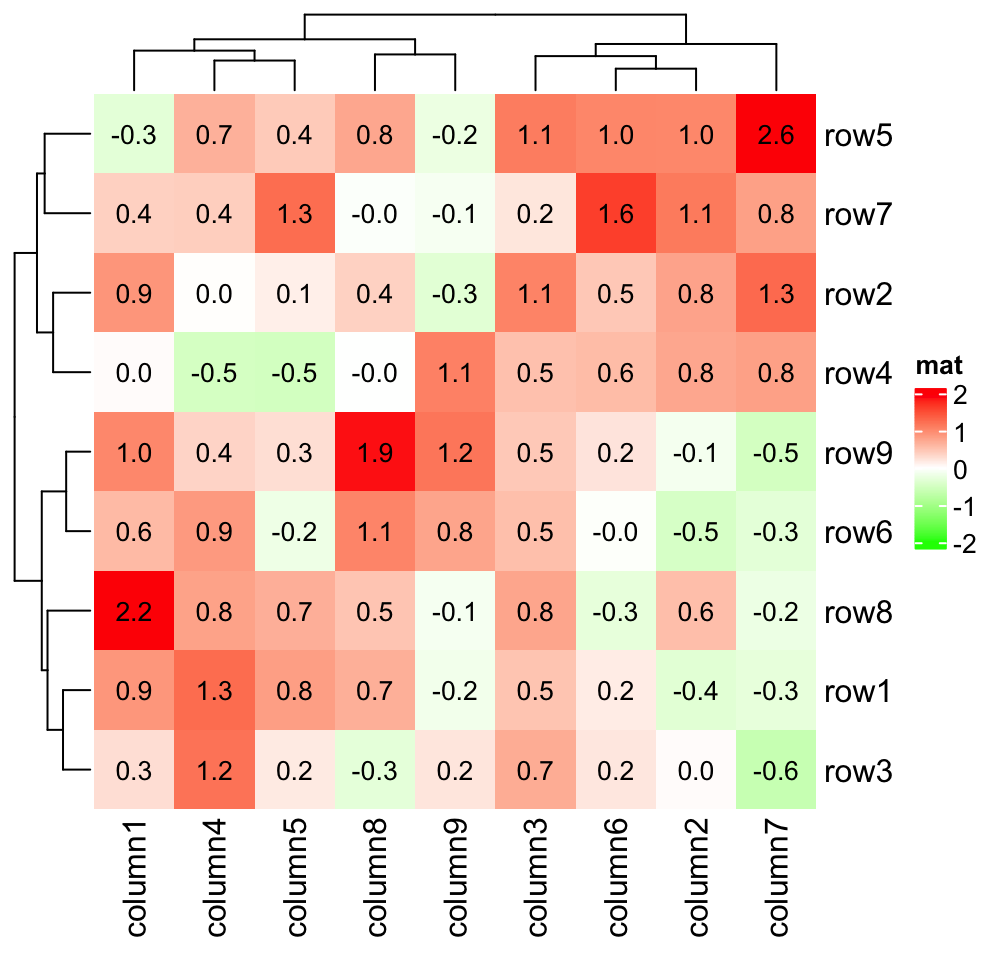
#13
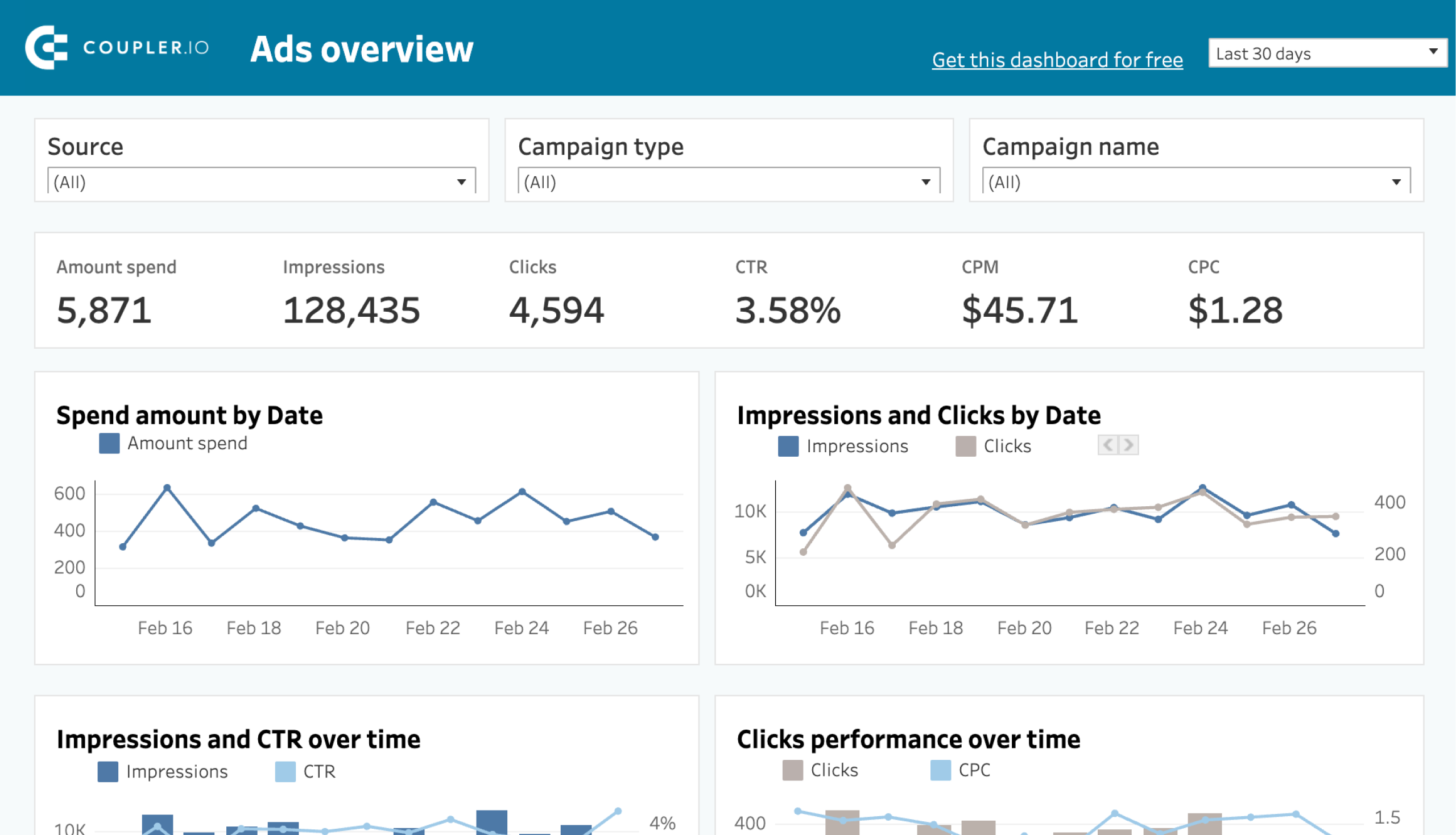
★★★
在 Tableau 中,"儀表板" (Dashboard) 的主要功能是什麼?
答案解析
Tableau 的儀表板是一個可以容納和排列多個視覺化(來自不同的工作表)、文字、圖像和網頁等物件的畫布。它的主要目的是將相關的數據洞察整合在一起,提供一個全面的、互動式的視圖,讓使用者可以快速概覽關鍵資訊,並深入探索細節。使用者可以在儀表板上添加篩選器、參數等互動元素,讓多個視覺化連動。
#14
★★★
在 Power BI Desktop 中,哪個視圖主要用於建立視覺效果和報表頁面佈局?
答案解析
Power BI Desktop 主要有三個核心視圖:
報表檢視 (Report view): 這是創建視覺效果(圖表、地圖、卡片等)和設計報表頁面佈局的主要工作區域。
資料檢視 (Data view): 用於查看、排序、篩選和檢查模型中的數據表格。
模型檢視 (Model view): 用於查看和管理數據模型中的資料表之間的關聯性。
查詢編輯器 (Power Query Editor) 是用於數據導入、清理和轉換的獨立視窗。
報表檢視 (Report view): 這是創建視覺效果(圖表、地圖、卡片等)和設計報表頁面佈局的主要工作區域。
資料檢視 (Data view): 用於查看、排序、篩選和檢查模型中的數據表格。
模型檢視 (Model view): 用於查看和管理數據模型中的資料表之間的關聯性。
查詢編輯器 (Power Query Editor) 是用於數據導入、清理和轉換的獨立視窗。
#15
★★★
Python 的 Seaborn 函式庫相較於 Matplotlib,其主要優勢通常在於?
答案解析
Seaborn 是基於 Matplotlib 的 Python 數據視覺化函式庫。它提供了更高級的介面,專注於繪製有吸引力且資訊豐富的統計圖形。相較於 Matplotlib,Seaborn 的主要優勢包括:
更美觀的預設主題和調色盤。
簡化了許多常見統計圖形(如散佈圖、盒鬚圖、小提琴圖、熱力圖等)的繪製過程。
與 Pandas 的 DataFrame 整合良好。
雖然 Seaborn 底層依賴 Matplotlib,但它封裝了許多細節,讓使用者可以用更少的程式碼創建更複雜、更專業的統計視覺化。Matplotlib 則提供了更多底層控制的靈活性。
更美觀的預設主題和調色盤。
簡化了許多常見統計圖形(如散佈圖、盒鬚圖、小提琴圖、熱力圖等)的繪製過程。
與 Pandas 的 DataFrame 整合良好。
雖然 Seaborn 底層依賴 Matplotlib,但它封裝了許多細節,讓使用者可以用更少的程式碼創建更複雜、更專業的統計視覺化。Matplotlib 則提供了更多底層控制的靈活性。
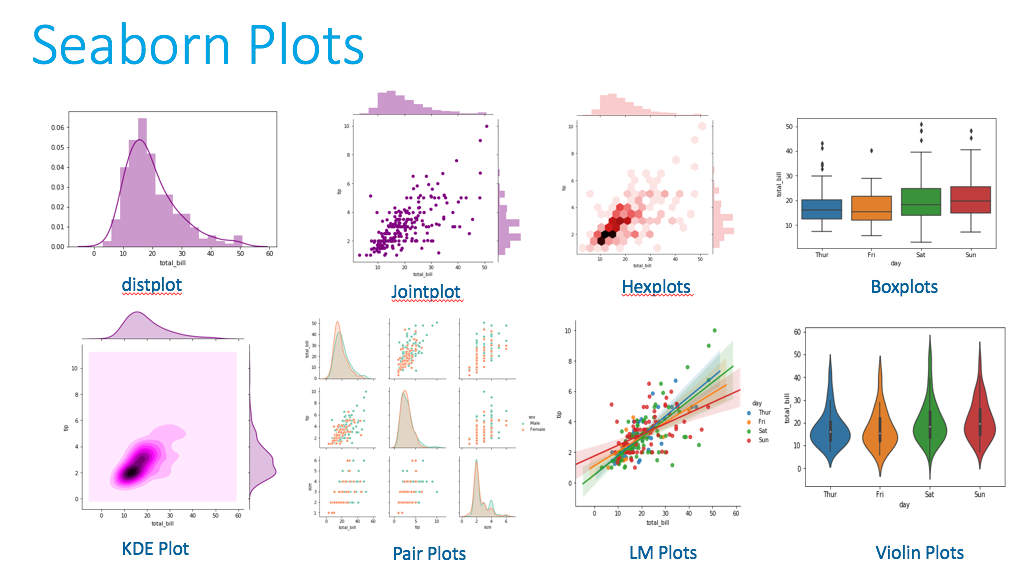
#16
★★★
在儀表板設計中,使用「交叉篩選」(Cross-filtering) 或「高亮」(Highlighting) 功能的主要目的是什麼?
答案解析
交叉篩選和高亮是提升儀表板互動性的重要功能。當使用者在儀表板上點擊某個圖表中的數據點或類別時(例如,點擊長條圖中的某個區域),啟用了交叉篩選或高亮的儀表板會自動更新其他相關的圖表,只顯示或突顯與所選項目相關的數據。這使得使用者能夠更方便地探索不同維度之間的關係,深入了解數據。
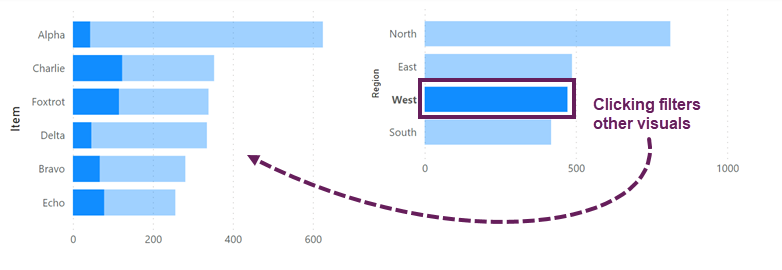
#17
★★★★
在設計視覺化圖表時,為了避免誤導觀眾,應該避免下列哪種做法?
答案解析
視覺化的目標是誠實、清晰地呈現數據。截斷 Y 軸(尤其是在比較數值的長條圖中,不從 0 開始)是一種常見的誤導性做法,因為它會不成比例地放大數據之間的視覺差異,讓小的差異看起來很大,從而扭曲觀眾對數據的感知。最佳實踐通常要求表示數量的長條圖或其他基線圖表的數值軸應從 0 開始,以確保視覺比例與實際數值比例一致。清晰標籤、一致用色和選擇合適圖表都是良好的實踐。
#18
★★★
格式塔原則 (Gestalt Principles) 在數據視覺化中的應用,主要是利用人類視覺感知的哪些傾向來組織資訊?
答案解析
格式塔心理學提出了一系列關於人類如何感知視覺元素的原則。在數據視覺化中應用這些原則,可以幫助設計者創建更容易被理解和解釋的圖表。例如:
鄰近性 (Proximity): 彼此靠近的物體會被視為一組。
相似性 (Similarity): 外觀相似(如顏色、形狀、大小相同)的物體會被視為一組。
連續性 (Continuity): 視覺傾向於感知連續的線條或模式,而不是斷裂的。
閉合性 (Closure): 視覺傾向于將不完整的圖形感知為完整的。
共同命運 (Common Fate): 朝同一方向移動的物體會被視為一組。
利用這些原則可以有效地對視覺元素進行分組和組織,引導觀眾的注意力。
鄰近性 (Proximity): 彼此靠近的物體會被視為一組。
相似性 (Similarity): 外觀相似(如顏色、形狀、大小相同)的物體會被視為一組。
連續性 (Continuity): 視覺傾向於感知連續的線條或模式,而不是斷裂的。
閉合性 (Closure): 視覺傾向于將不完整的圖形感知為完整的。
共同命運 (Common Fate): 朝同一方向移動的物體會被視為一組。
利用這些原則可以有效地對視覺元素進行分組和組織,引導觀眾的注意力。
#19
★★★
哪種圖表類型適合用來視覺化數值數據的分佈情況,例如數據的集中趨勢、分散程度和是否存在偏態?
答案解析
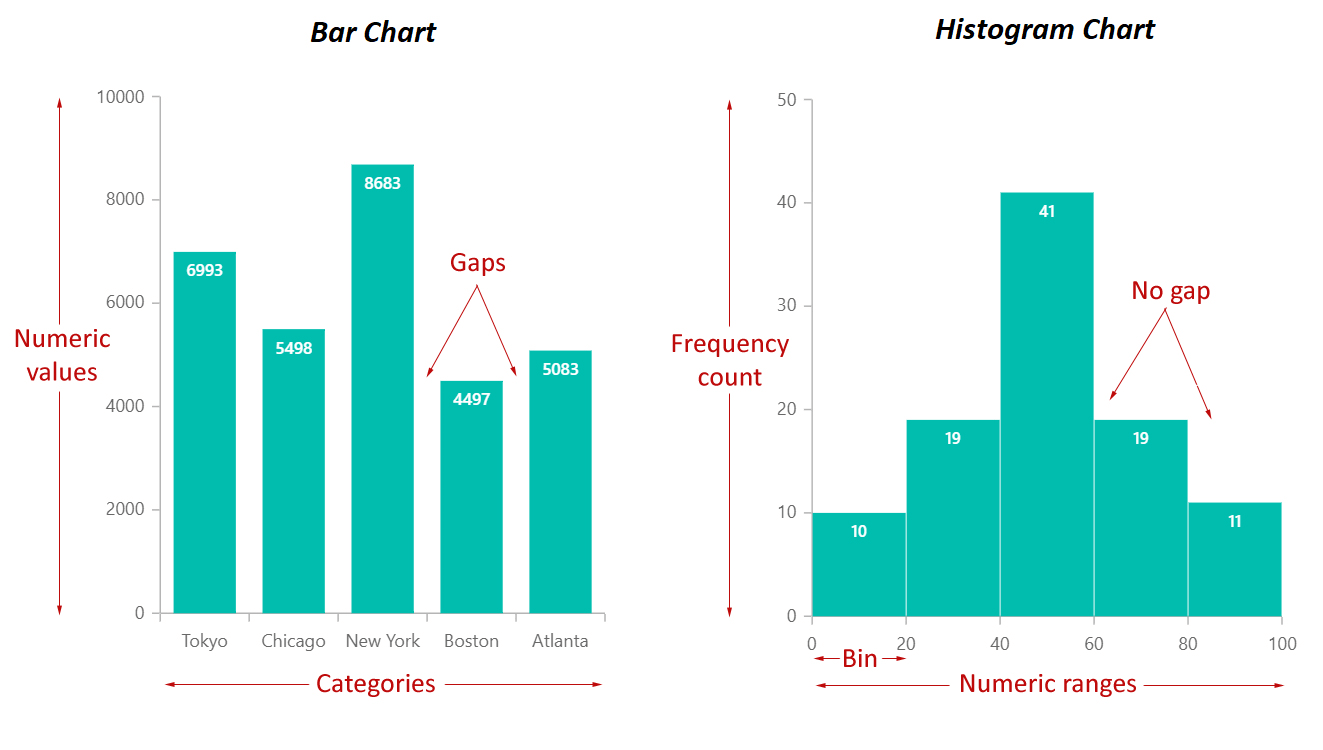
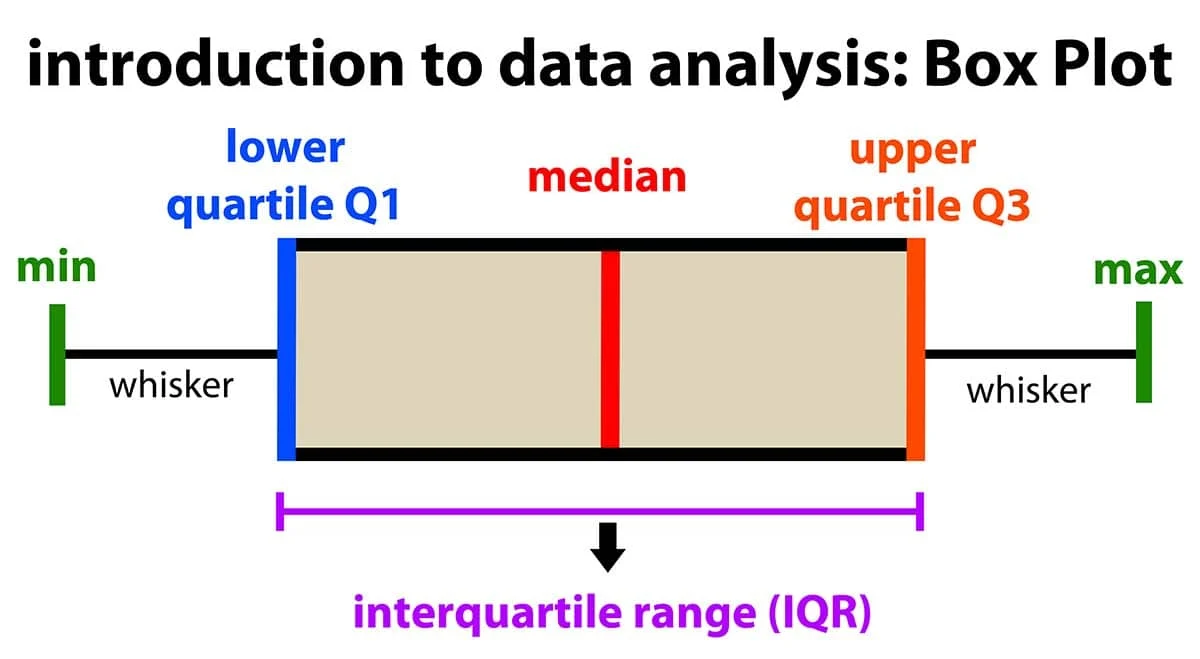
直方圖和盒鬚圖都是視覺化單一數值變數分佈的常用工具。
直方圖 (Histogram): 將數值範圍劃分成若干個區間(bins),然後計算落入每個區間的數據點數量,並以長條圖形式展示。它可以顯示數據的峰值、分佈形狀(對稱、左偏、右偏)和大致範圍。
盒鬚圖 (Box Plot): 展示數據的五數摘要(最小值、第一四分位數 Q1、中位數 Q2、第三四分位數 Q3、最大值)以及可能的異常值。
圓餅圖用於部分佔比。散佈圖用於雙變數關係。折線圖用於時間趨勢。
直方圖 (Histogram): 將數值範圍劃分成若干個區間(bins),然後計算落入每個區間的數據點數量,並以長條圖形式展示。它可以顯示數據的峰值、分佈形狀(對稱、左偏、右偏)和大致範圍。
盒鬚圖 (Box Plot): 展示數據的五數摘要(最小值、第一四分位數 Q1、中位數 Q2、第三四分位數 Q3、最大值)以及可能的異常值。
圓餅圖用於部分佔比。散佈圖用於雙變數關係。折線圖用於時間趨勢。
#20
★★
Google Data Studio (現已更名為 Looker Studio) 是 Google 提供的一項什麼服務?
答案解析
Looker Studio (原 Google Data Studio) 是 Google 提供的一個免費的線上工具,允許使用者連接各種數據源(包括 Google Analytics, Google Sheets, Google Ads, BigQuery 等以及其他數據庫和平台),創建可自訂的、互動式的數據視覺化報表和儀表板,並方便地進行分享和協作。
#21
★★
在 Tableau 中,若想創建一個顯示各區域銷售額佔總銷售額百分比的圖表,哪種類型的計算欄位或表計算會很有用?
答案解析
Tableau 提供了許多快速表計算 (Quick Table Calculations) 功能,可以方便地對已有的度量進行二次計算。要計算每個部分(如區域銷售額)佔整體的百分比,可以使用「總額百分比」的表計算。這會自動計算每個標記的值除以視圖中所有標記的總和。
#22
★★★
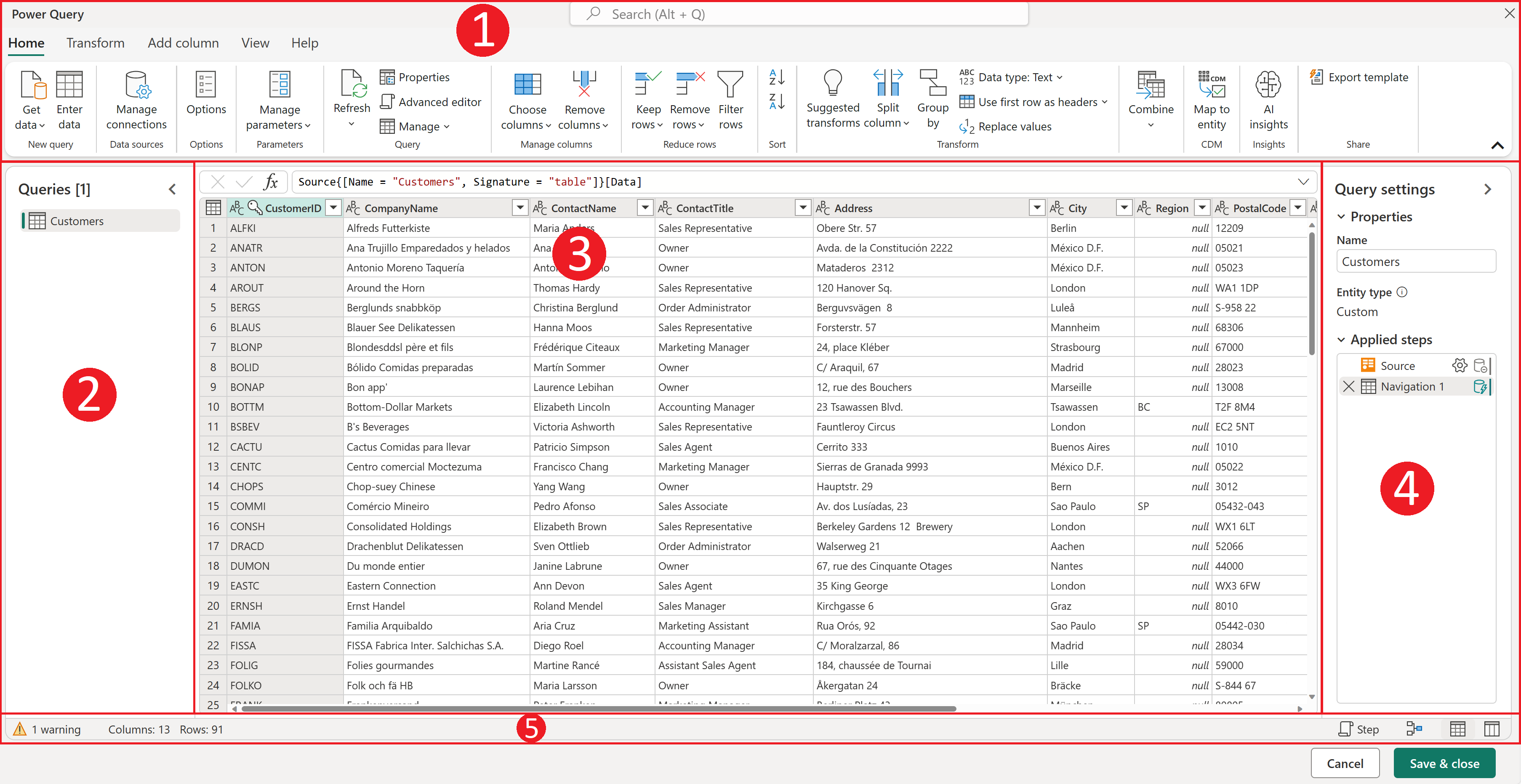
Power BI 中的 Power Query 主要用於執行哪些任務?
答案解析
Power Query (在 Power BI Desktop 中稱為 Power Query 編輯器) 是一個強大的數據提取、轉換和載入 (Extract, Transform, Load - ETL) 工具。它提供了一個圖形化介面,讓使用者可以輕鬆地連接到各種數據源,然後執行各種數據清理和轉換操作,例如移除列/欄、更改數據類型、分割欄、合併查詢、添加自訂欄等,最終將整理好的數據載入到 Power BI 數據模型中。
#23
★★★★
若想在 Python 中創建互動式、可在網頁瀏覽器中展示的視覺化圖表(例如,滑鼠懸停顯示資訊、縮放、平移),哪個函式庫是常見的選擇?
答案解析
雖然 Matplotlib 和 Seaborn 很常用,但它們主要生成靜態圖表。若要創建互動式的、基於網頁的視覺化,Plotly 和 Bokeh 是 Python 中兩個流行的選擇。它們利用 JavaScript 技術 (如 Plotly.js, BokehJS) 在後端生成圖表,可以在 Jupyter Notebook、網頁應用或獨立的 HTML 檔案中實現縮放、平移、懸停提示、點擊事件等互動功能。Pillow 是圖像處理函式庫。
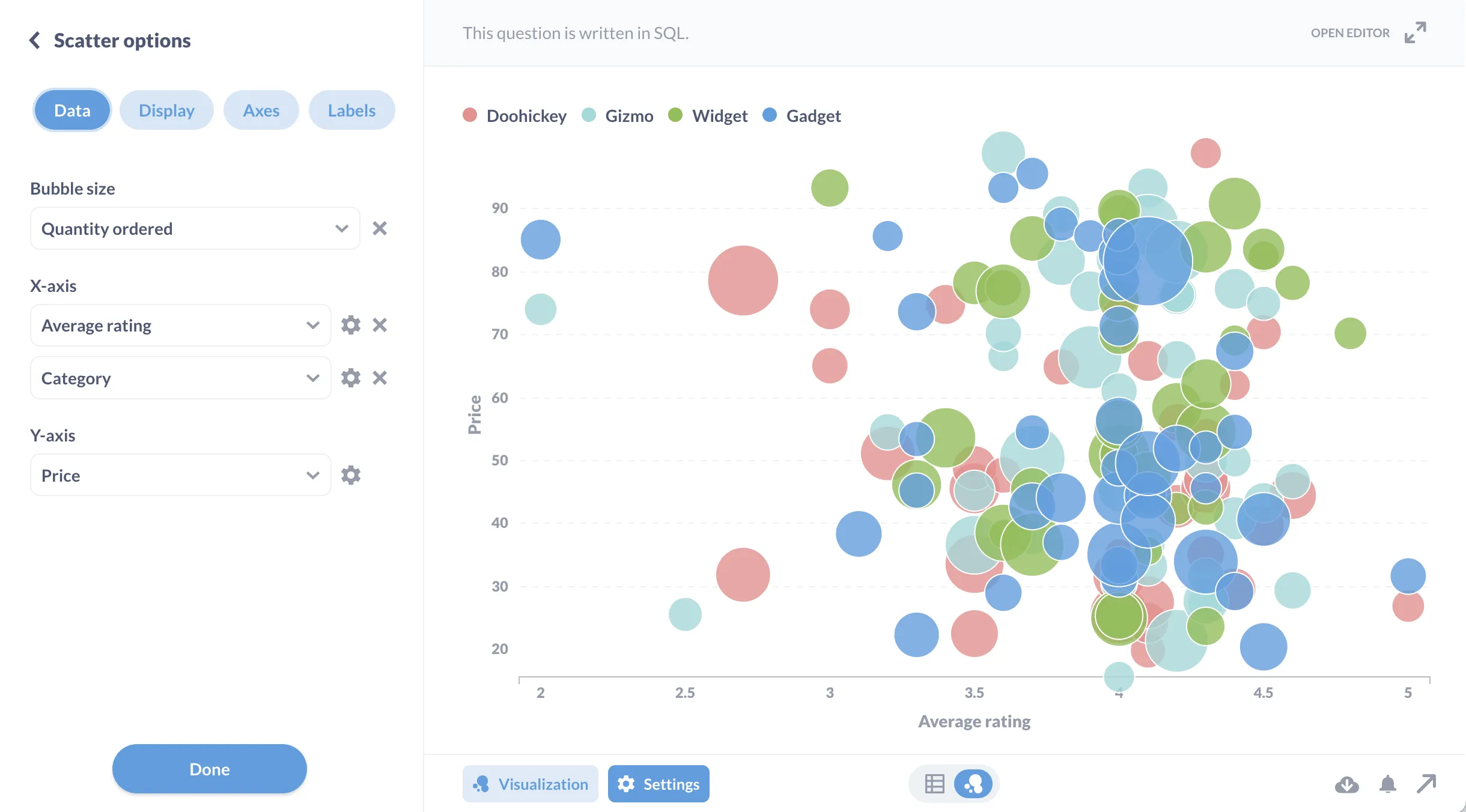
#24
★★★
在設計儀表板佈局時,將最重要的資訊或 KPI 放置在哪個位置通常最能吸引觀眾的注意力?
答案解析
根據西方閱讀習慣(從左到右,從上到下),以及許多使用者介面設計的研究,觀眾的視線通常首先落在畫面的左上角區域。因此,在設計儀表板時,將最關鍵的指標 (KPIs) 或最重要的摘要資訊放置在左上角,可以確保它們最先被看到,最能吸引注意力。
#25
★★★★
使用過多飽和度過高的顏色或不和諧的顏色組合,會違反數據視覺化的哪個基本原則?
答案解析
顏色是數據視覺化中強大的工具,但使用不當會適得其反。過於鮮豔、飽和度過高的顏色組合容易造成視覺疲勞,而不和諧的顏色搭配(例如,紅綠色對色盲人士不友好,或缺乏對比度)會使得圖表難以閱讀和區分。選擇恰當、和諧且具有良好對比度的配色方案,對於確保視覺的清晰度和觀眾的閱讀舒適度至關重要。同時,顏色的使用應具有意義,例如用不同顏色區分類別,或用顏色深淺表示數值大小。
#26
★★★★
當需要同時展示三個數值變數之間的關係時(例如,產品的成本、價格和銷售量),哪種圖表可能是一種選擇?
答案解析
氣泡圖是散佈圖的一種變體,它可以在二維平面上表示三個變數。其中兩個變數由點的 X 軸和 Y 軸位置表示(如同散佈圖),而第三個變數則由點的大小(氣泡的大小)來表示。例如,可以用 X 軸表示成本,Y 軸表示價格,氣泡大小表示銷售量,從而同時觀察這三個變數之間的關係。
#27
★★★
在 Tableau 中,可以使用「故事」(Story) 功能來做什麼?
答案解析
Tableau 的故事功能允許使用者創建一個包含一系列「故事點」(Story Points) 的敘事流程。每個故事點可以是一個工作表、一個儀表板或一段文字描述。使用者可以按順序排列這些故事點,並添加註解或標題,像講故事一樣引導觀眾瀏覽數據發現的過程、分析的步驟或最終的結論。這是一種有效的數據溝通方式。
#28
★★
Power BI Service 是 Power BI 的哪個組成部分?
答案解析
Power BI 主要包含幾個組件:
Power BI Desktop: 免費的 Windows 桌面應用程式,用於連接數據、建立數據模型和設計報表。 (選項 A)
Power BI Service: 基於雲端的 SaaS (Software as a Service) 服務 (app.powerbi.com),用於發佈來自 Desktop 的報表、創建儀表板、與他人分享和協作。 (選項 B)
Power BI Mobile: 用於在 iOS 和 Android 裝置上查看和互動報表與儀表板的行動應用程式。 (選項 C)
Power BI Gateway: 用於讓 Power BI Service 安全地連接到位於內部網路的數據源。 (選項 D)
Power BI Desktop: 免費的 Windows 桌面應用程式,用於連接數據、建立數據模型和設計報表。 (選項 A)
Power BI Service: 基於雲端的 SaaS (Software as a Service) 服務 (app.powerbi.com),用於發佈來自 Desktop 的報表、創建儀表板、與他人分享和協作。 (選項 B)
Power BI Mobile: 用於在 iOS 和 Android 裝置上查看和互動報表與儀表板的行動應用程式。 (選項 C)
Power BI Gateway: 用於讓 Power BI Service 安全地連接到位於內部網路的數據源。 (選項 D)
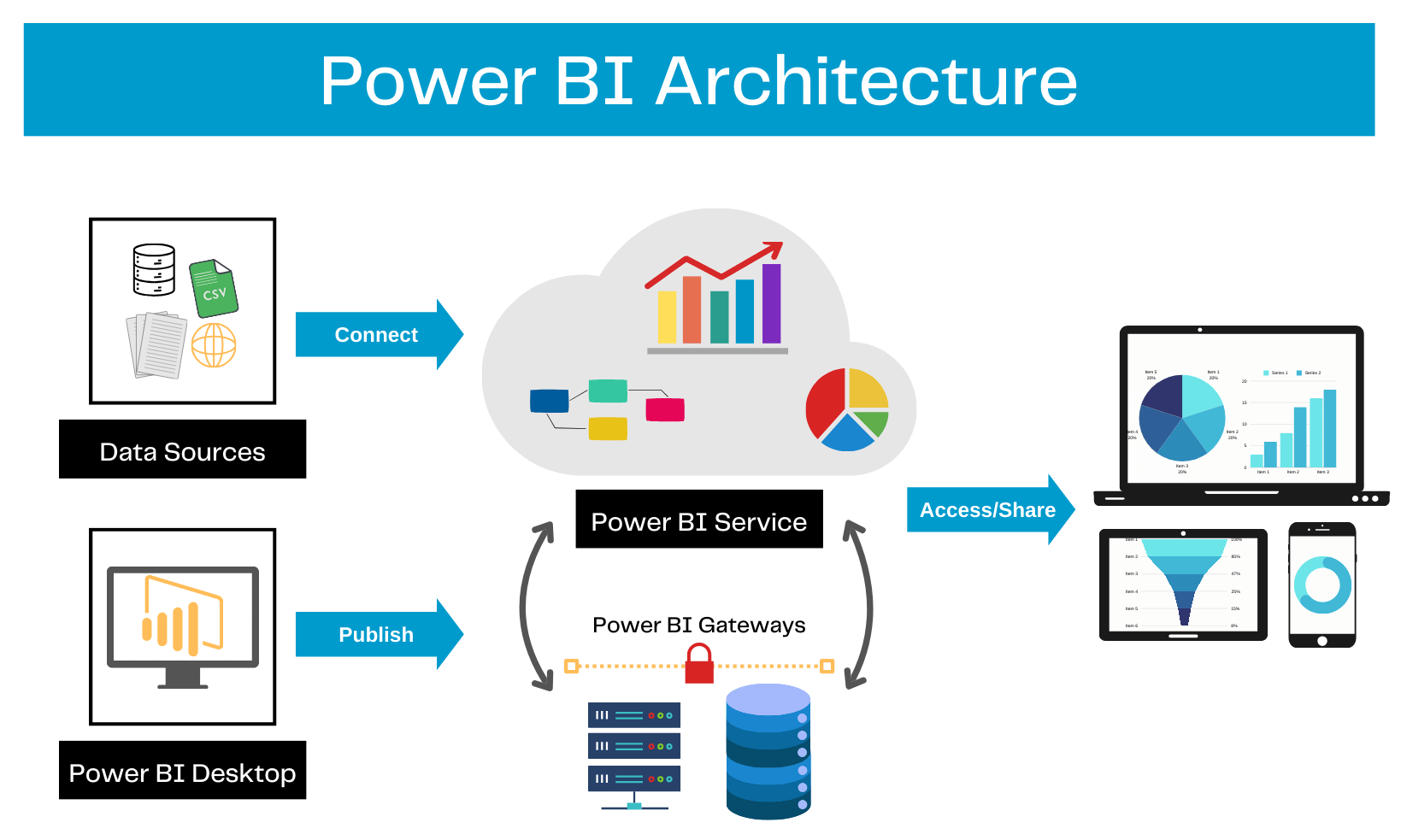
#29
★★
在 Python 中使用 Matplotlib 繪圖時,通常使用哪個子模組來進行快速繪圖或取得目前的圖形與座標軸?
答案解析
`matplotlib.pyplot` 是 Matplotlib 提供的一個狀態機介面 (state-based interface),它模仿了 MATLAB 的繪圖方式。它包含了一系列方便的函數,用於快速創建圖形 (figure)、座標軸 (axes) 以及繪製各種圖表,並會自動管理當前的圖形和座標軸。開發者通常會 `import matplotlib.pyplot as plt` 來使用它。
#30
★★★
視覺化設計中的「視覺層次」(Visual Hierarchy) 是指什麼?
答案解析
視覺層次是指在設計中有意識地安排視覺元素,以突顯某些元素的重要性,並引導觀眾的閱讀順序。設計師可以利用大小(更大的元素更醒目)、顏色(更亮或對比更強的顏色更醒目)、位置(頂部或左上角通常先被看到)、對比度、留白等技巧來建立視覺層次。一個具有良好視覺層次的設計能讓觀眾快速抓住重點,並更容易地理解資訊結構。

#31
★★
哪種類型的視覺編碼(將數據值映射到視覺屬性)對於表示定量數據(數值大小)通常最不精確?
答案解析
根據 Cleveland 和 McGill 等人的研究,人類視覺系統對不同視覺編碼的感知精確度不同。一般認為,判斷基於共同標尺的位置(如長條圖、散佈圖)是最精確的,其次是長度、角度/斜率、面積、體積,而顏色飽和度/亮度(常用於熱力圖)和色調 (Hue) 對於精確判斷數值大小來說,其感知精確度相對較低。因此,應優先使用位置和長度來編碼最重要的定量資訊。
#32
★★★
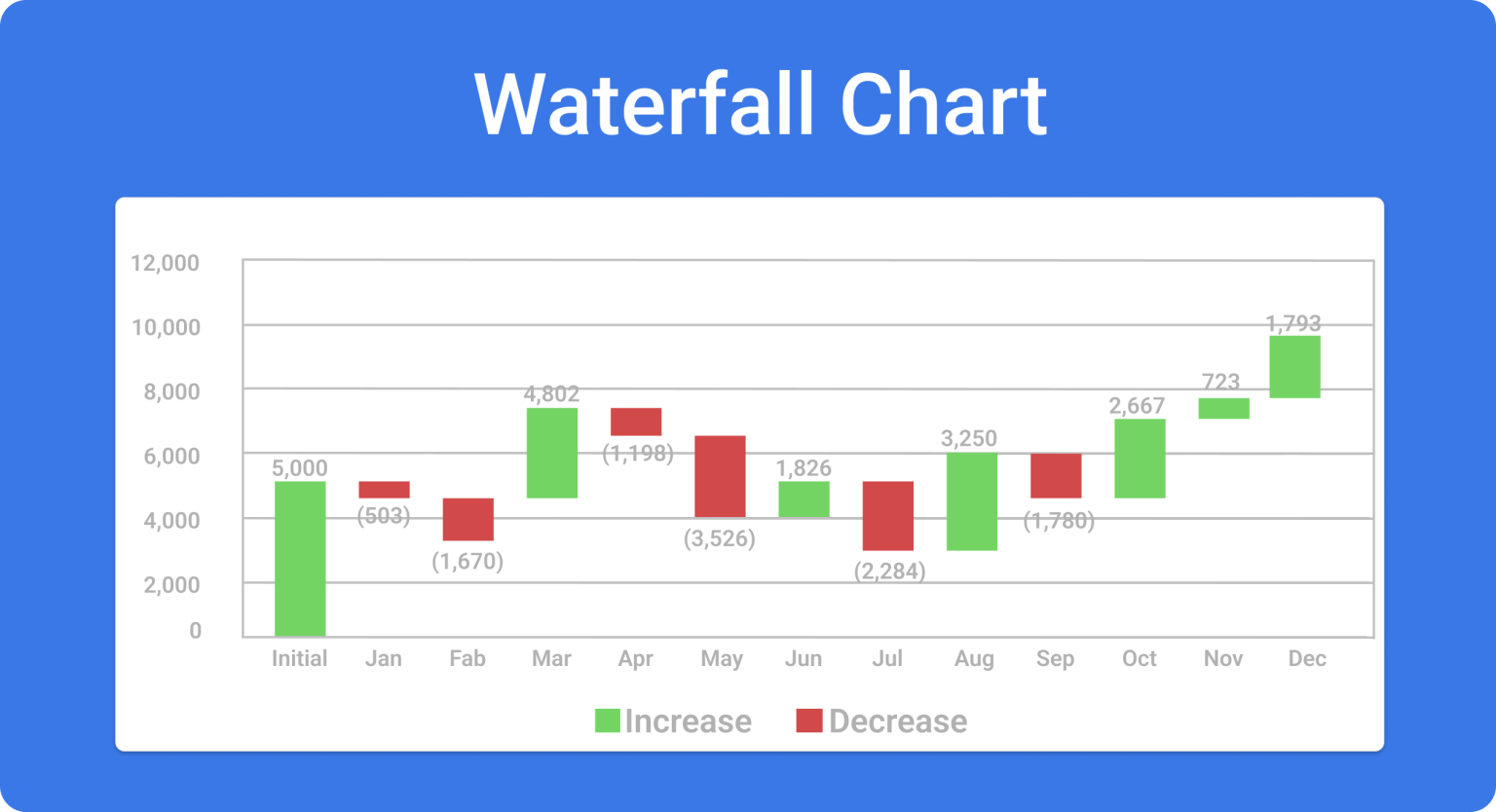
瀑布圖 (Waterfall Chart) 通常用於視覺化什麼?
答案解析
瀑布圖(也稱橋樑圖 Bridge Chart)非常適合用來展示一個數值如何從一個起始點,經過一系列正向(增加)和負向(減少)的變動,最終達到一個終點。它常被用於財務分析,例如顯示淨收入如何從總收入開始,減去各種成本和費用得到;或者分析某項指標(如銷售額、客戶數)隨時間的增減變化及其構成因素。
#33
★★★
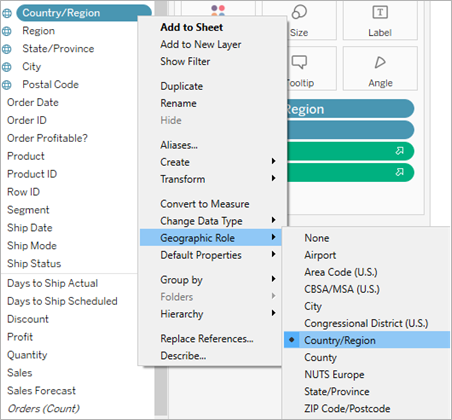
在 Tableau 中,將地理資訊欄位(如國家、城市、郵遞區號)用於創建地圖視覺化時,這些欄位通常需要被賦予什麼「地理角色」(Geographic Role)?
答案解析
為了讓 Tableau 能夠識別數據中的地理位置並在地圖上繪製出來,需要為包含地理資訊的欄位(通常是維度)指定正確的地理角色。Tableau 內建了許多地理角色,如國家/地區、州/省、城市、郵遞區號、機場等。當欄位被賦予地理角色後,Tableau 會自動生成對應的經緯度資訊(如果能識別),並允許使用者將其拖放到工作表中以創建地圖視覺效果。
#34
★★★★
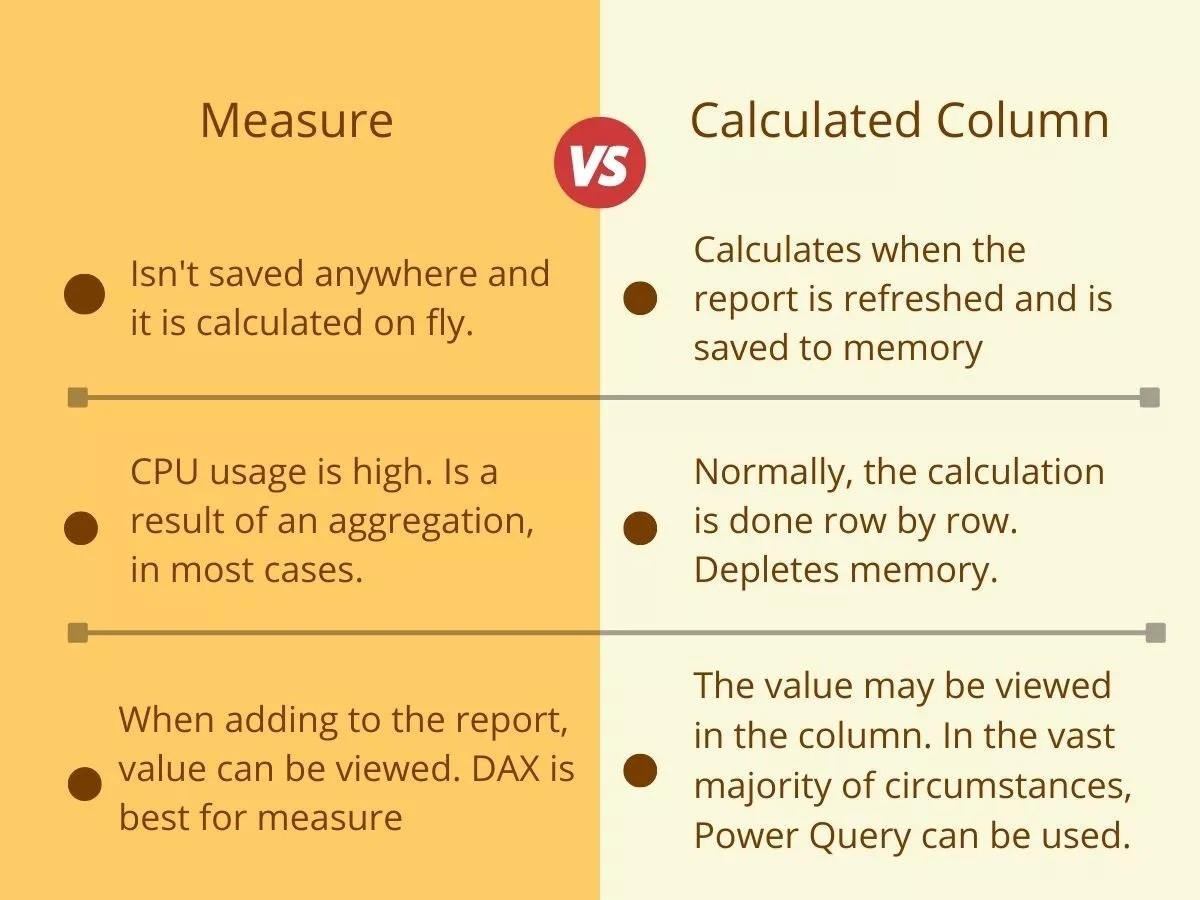
在 Power BI 中,建立「量值」(Measure) 和「計算結果資料行」(Calculated Column) 的主要區別是什麼?
答案解析
量值 (Measure) 和計算結果資料行 (Calculated Column) 都是使用 DAX 公式創建的,但它們的計算方式和儲存方式不同:
計算結果資料行:其值在數據加載或刷新時,針對資料表的每一行進行計算,並像普通資料行一樣物理儲存在模型中,佔用記憶體。它可以使用當前行的上下文進行計算。
量值:其值不會預先計算並儲存。它是在報表進行互動(例如,使用者應用篩選器、選擇圖表元素)時,根據當前的篩選上下文 (Filter Context) 動態計算出來的聚合結果(如總和、平均值、計數)。量值通常用於視覺效果的值區域。
理解這個區別對於高效能的 Power BI 模型設計至關重要。
計算結果資料行:其值在數據加載或刷新時,針對資料表的每一行進行計算,並像普通資料行一樣物理儲存在模型中,佔用記憶體。它可以使用當前行的上下文進行計算。
量值:其值不會預先計算並儲存。它是在報表進行互動(例如,使用者應用篩選器、選擇圖表元素)時,根據當前的篩選上下文 (Filter Context) 動態計算出來的聚合結果(如總和、平均值、計數)。量值通常用於視覺效果的值區域。
理解這個區別對於高效能的 Power BI 模型設計至關重要。
#35
★★
儀表板中的 KPI (Key Performance Indicator,關鍵績效指標) 卡片通常用於顯示什麼?
答案解析
KPI 卡片(或稱指標卡、大數字卡)是儀表板中常見的視覺元素,用於突出顯示最重要的績效指標。它通常只顯示一個關鍵的匯總數值(例如,總銷售額、平均訂單價值、網站轉換率),並可能包含與目標值的比較、與上一期的變化百分比、或一個小的趨勢指示符(如迷你圖 Sparkline),讓使用者能夠一目了然地掌握核心業務狀況。
#36
★★★
在比較不同大小群體(例如,不同規模的部門)的某項比率(例如,員工滿意度得分)時,直接比較原始得分可能會產生誤導。為了更公平地比較,視覺化時可以考慮加入哪個元素?
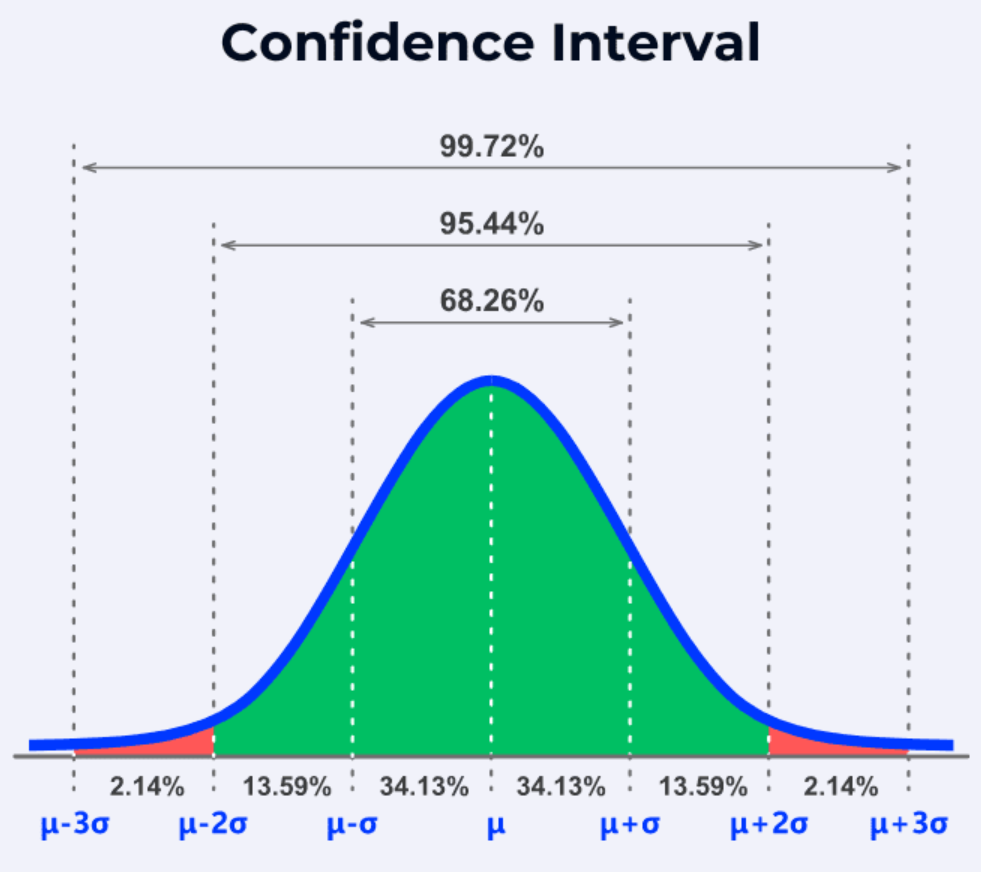
答案解析
當比較基於不同樣本大小計算出的比率或平均值時,較小樣本的結果通常具有更大的隨機波動性或不確定性。直接比較點估計值(如平均分)可能忽略了這一點。在視覺化中加入信賴區間或誤差線,可以表示每個估計值的不確定性範圍。如果兩個群體的誤差線有很大重疊,則它們之間的差異可能不是統計顯著的。這有助於更謹慎地解釋比較結果。雖然顯示樣本大小也有幫助,但誤差線更直接地體現了統計不確定性。
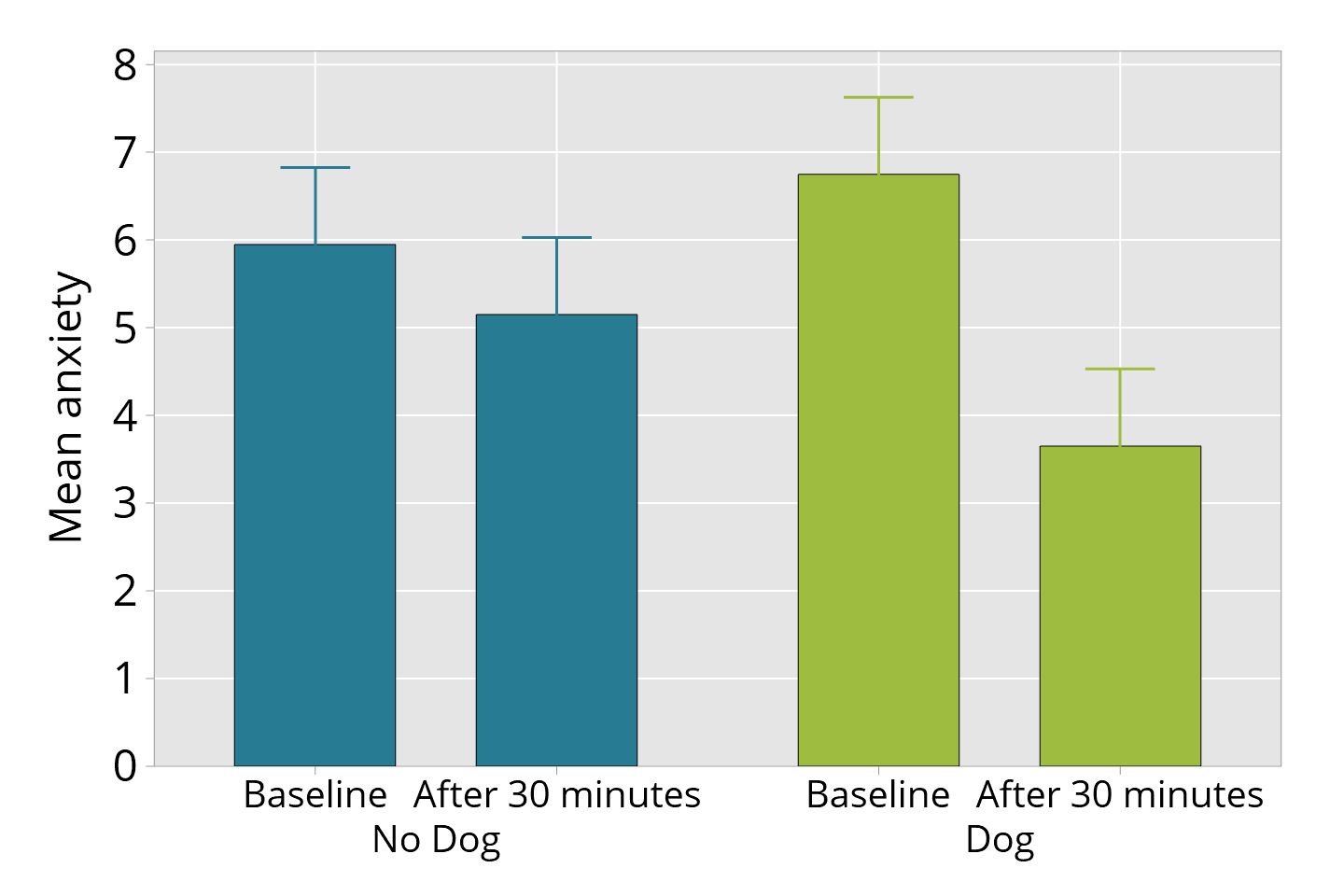
#37
★★★
「數據說故事」(Data Storytelling) 是指將數據、視覺化與什麼結合,以更有效地傳達洞察並影響決策?
答案解析
數據說故事不僅僅是展示圖表,而是將數據 (Data)、視覺化 (Visuals) 和敘事 (Narrative) 結合起來的過程。它需要理解觀眾、設定清晰的背景脈絡 (Context)、構建引人入勝的敘事結構(例如,提出問題、展示發現、得出結論、提出建議),並使用有效的視覺化來支持故事情節。目標是將冰冷的數據轉化為有意義、易於理解且具有說服力的故事,從而驅動行動或改變看法。
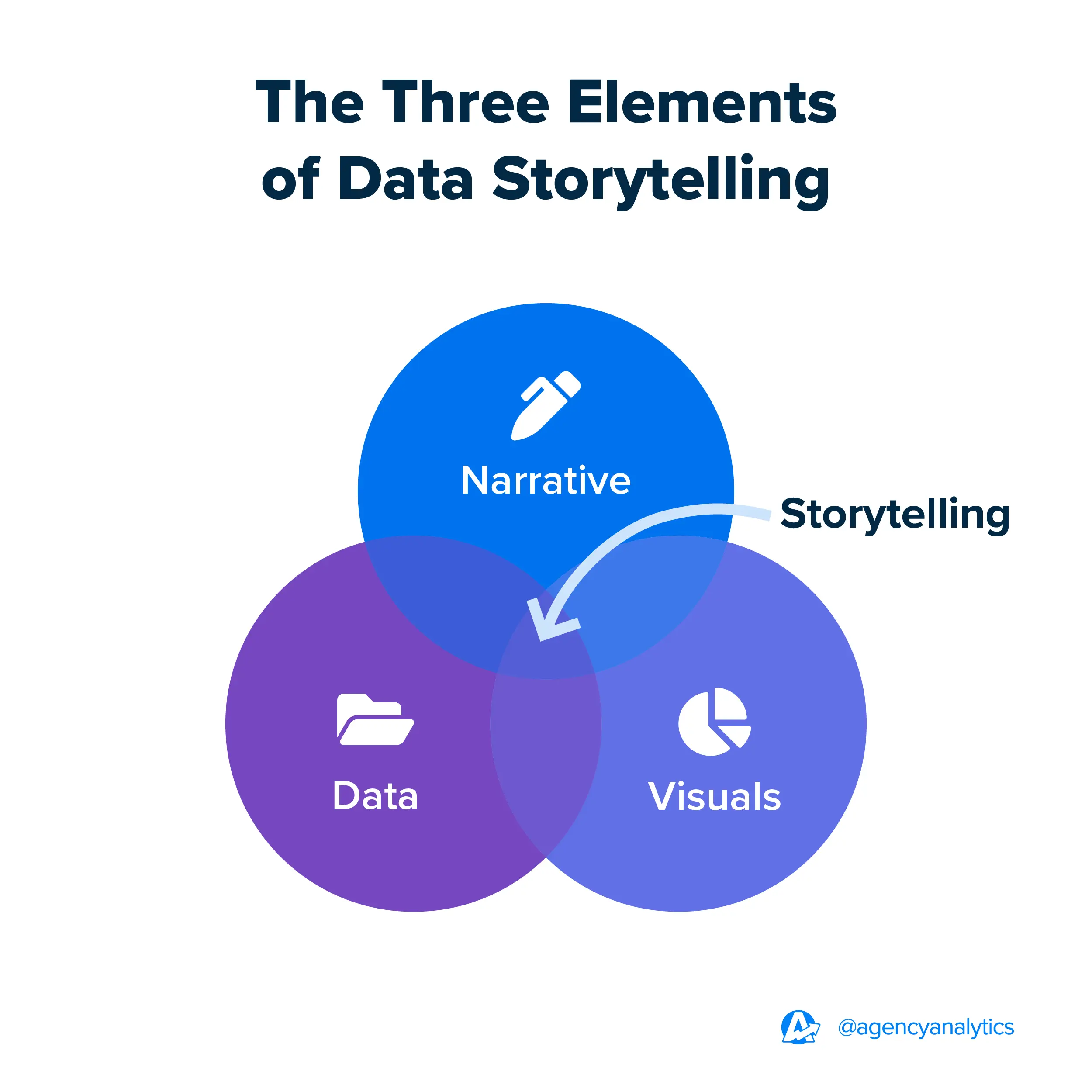
#38
★★
樹狀圖 (Treemap) 適合用來視覺化哪種數據結構?
答案解析
樹狀圖使用嵌套的矩形來表示具有層次結構的數據。每個矩形的面積通常代表一個數值(例如,銷售額、文件大小),而矩形的嵌套關係則反映了數據的層次結構(例如,產品大類 -> 子類 -> 單品)。它可以在有限的空間內有效地展示大量層級數據的相對大小和結構。
#39
★
在 Python 的 Pandas 函式庫中,可以直接在 DataFrame 或 Series 物件上呼叫哪個方法來快速生成基本的圖表(底層通常使用 Matplotlib)?
答案解析
Pandas 提供了內建的繪圖功能,可以方便地對 DataFrame 或 Series 中的數據進行快速視覺化。通過在物件後面加上
.plot() 方法,並可以指定 kind 參數(如 'line', 'bar', 'hist', 'scatter', 'box' 等)來選擇圖表類型,即可快速生成圖表。例如,df['column'].plot(kind='hist') 會繪製該欄位的直方圖。

#40
★★★
在互動式視覺化中,提供「工具提示」(Tooltip) 的主要作用是什麼?
答案解析
工具提示是一種常見的互動式視覺化功能。當使用者將滑鼠指標移動到圖表上的某個數據點、長條、扇區或其他元素上時,會彈出一個小視窗或標籤,顯示與該元素相關的更詳細的資訊,例如確切的數值、類別名稱、日期等。這使得圖表可以在保持整體簡潔的同時,提供使用者按需查看細節的能力。
#41
★★★
Qlik Sense 是另一個知名的商業智慧與視覺化工具,它以其哪種技術或特性而聞名?
答案解析
Qlik Sense (以及其前身 QlikView) 的核心技術是其「關聯引擎」。與傳統基於查詢 (query-based) 的 BI 工具不同,Qlik 的關聯引擎會將所有載入的數據關聯起來。當使用者在儀表板上進行選擇或篩選時,引擎會即時計算並顯示所有欄位中與該選擇相關(綠色)、不相關(灰色)和可能相關(淺灰色)的值。這種「關聯體驗」讓使用者可以像人腦一樣自由地探索數據,不受預設路徑或查詢的限制,更容易發現意想不到的洞察。
#42
★★
在視覺化中使用過多的「圖表垃圾」(Chartjunk) 會導致什麼主要問題?
答案解析
圖表垃圾是指圖表中與數據資訊傳達無關或干擾資訊傳達的裝飾性元素,例如不必要的背景圖案、過多的格線、陰影效果、3D效果、冗餘的標籤等。這些元素會增加視覺噪音,分散觀眾的注意力,使得他們更難以快速準確地讀取和理解數據本身,從而降低了視覺化的溝通效率。根據數據墨水比原則,應盡量減少圖表垃圾。
#43
★★
在 Tableau 中,可以將度量從「連續」(Continuous) 轉換為「離散」(Discrete) 以達到什麼效果?
答案解析
在 Tableau 中,欄位可以是連續的(綠色藥丸)或離散的(藍色藥丸)。連續欄位在拖放到工作表時會創建連續的軸,而離散欄位會創建獨立的標籤或標頭。將一個度量(通常預設為連續)轉換為離散,可以將其數值視為單獨的類別。例如,如果想將年份(一個數值度量)作為表格的列標頭,而不是作為連續的時間軸,就可以將其轉換為離散維度。
#44
★★★
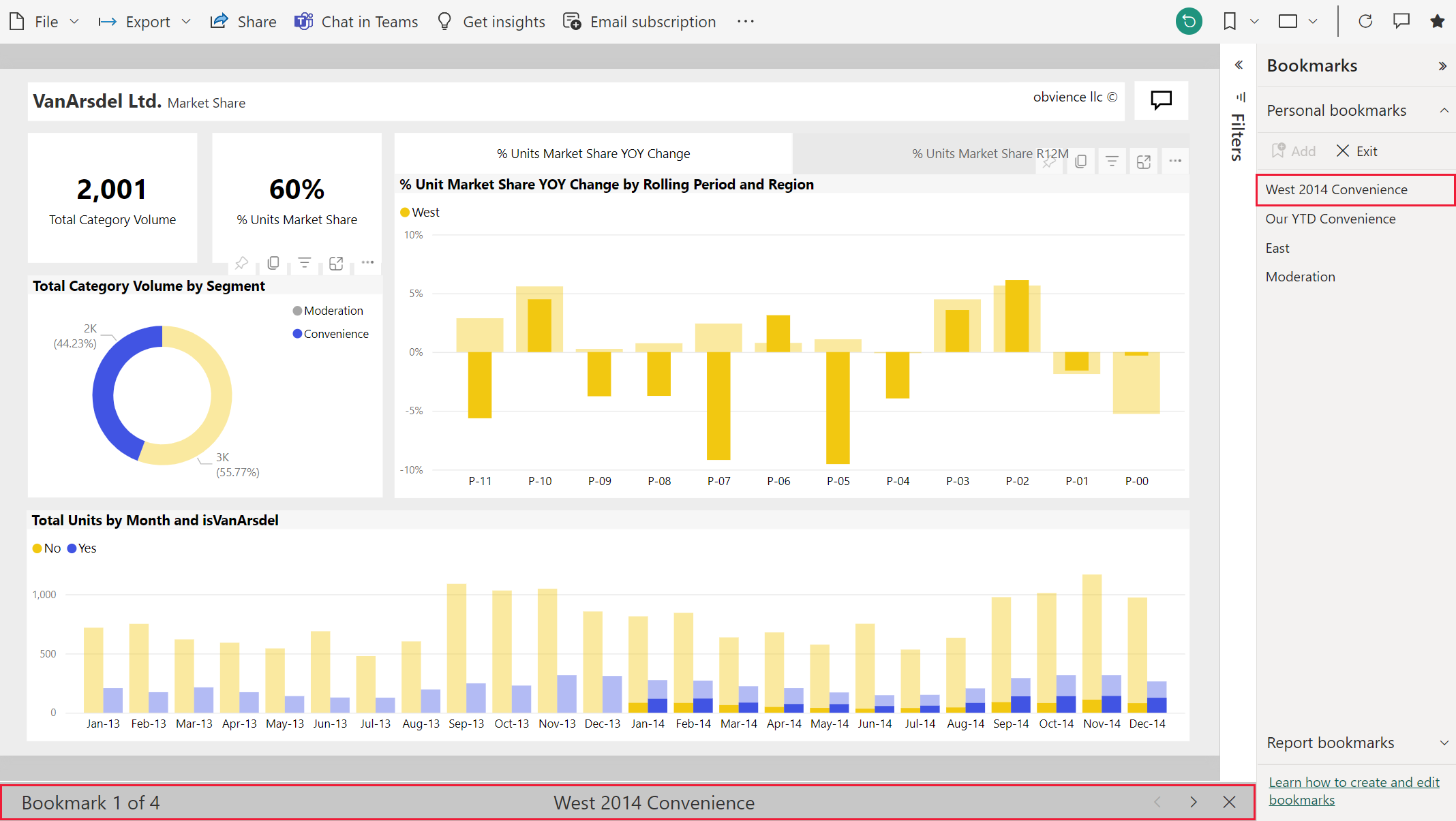
Power BI 中的「書籤」(Bookmarks) 功能允許使用者做什麼?
答案解析
Power BI 的書籤功能非常實用,它允許報表設計者或使用者捕捉並儲存報表頁面的當前檢視狀態。這個狀態可以包括已應用的篩選器、交叉分析篩選器 (Slicers) 的選擇、視覺效果的排序、鑽取狀態,甚至特定視覺效果的顯示或隱藏。儲存的書籤可以讓使用者快速跳轉回特定的分析視圖,或者被用來創建類似應用程式的導覽體驗(例如,透過按鈕切換不同的書籤狀態)和數據故事。
#45
★★
在選擇視覺化圖表時,考量「數據類型」(例如,類別、數值、時間序列、地理空間)為何重要?
答案解析
選擇合適的圖表類型是有效數據視覺化的基礎。不同的圖表有其特定的設計目的和適用場景,通常取決於你想要展示的數據類型以及你想要傳達的訊息類型(例如,比較、分佈、組成、關係、趨勢)。例如,長條圖適合比較類別數據,折線圖適合展示時間趨勢,散佈圖適合觀察兩個數值變數的關係,地圖適合展示地理空間數據。錯誤地使用圖表類型會導致資訊難以理解甚至被誤解。
#46
★★★
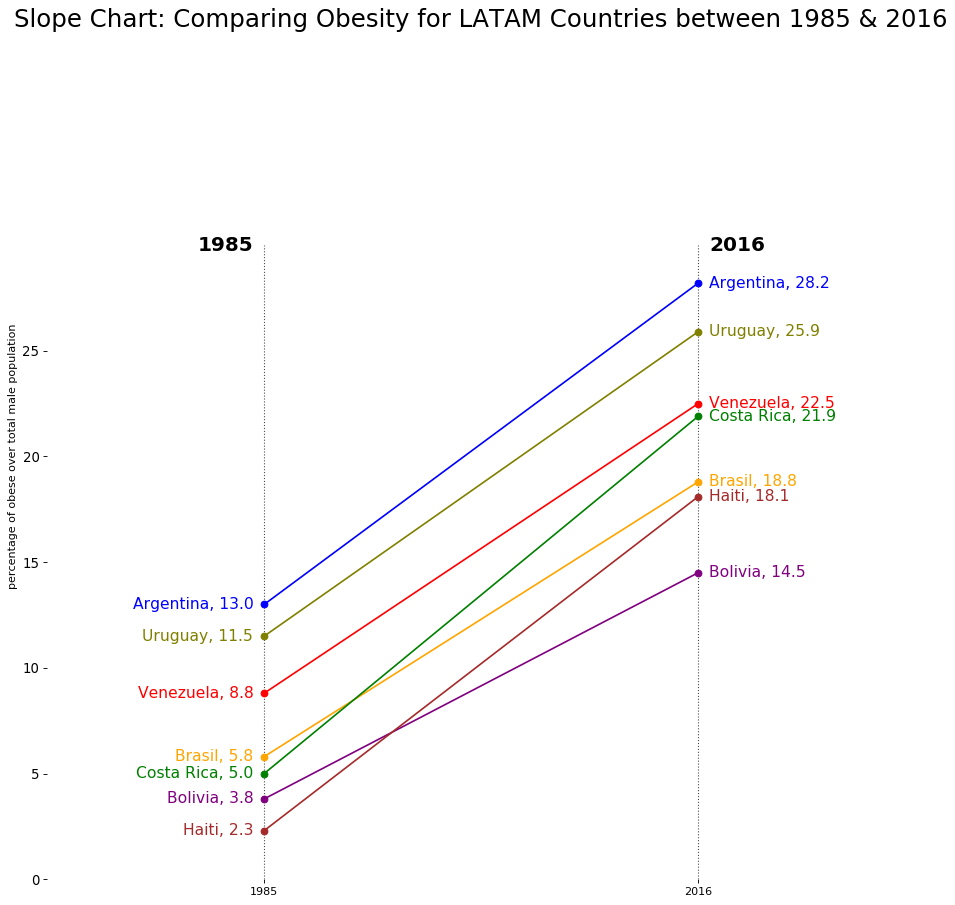
哪種圖表適合用來比較多個類別在兩個不同時間點的數值變化?
答案解析
要比較多個類別在兩個時間點的變化:
分組長條圖 (Grouped Bar Chart): 可以在每個類別下並列顯示兩個時間點的長條,方便直接比較每個類別的數值變化。
斜率圖 (Slope Chart): 用線條連接每個類別在兩個時間點的數值點,線條的斜率直觀地顯示了變化的方向和幅度,特別適合比較多個類別的變化趨勢。
雷達圖用於比較多個變數的數值。圓餅圖不適合比較變化。散佈圖用於兩個連續變數關係。
分組長條圖 (Grouped Bar Chart): 可以在每個類別下並列顯示兩個時間點的長條,方便直接比較每個類別的數值變化。
斜率圖 (Slope Chart): 用線條連接每個類別在兩個時間點的數值點,線條的斜率直觀地顯示了變化的方向和幅度,特別適合比較多個類別的變化趨勢。
雷達圖用於比較多個變數的數值。圓餅圖不適合比較變化。散佈圖用於兩個連續變數關係。
#47
★★★★
設計有效的數據儀表板時,應該優先考慮?
答案解析
設計任何有效的溝通工具(包括儀表板)的第一步都應該是明確其目的和受眾。你需要了解這個儀表板是為了達成什麼目標?誰會使用它?他們需要透過這個儀表板了解哪些資訊、回答哪些問題、做出哪些決策?只有明確了這些,才能選擇合適的指標、設計有效的視覺化、組織合理的佈局,從而創建一個真正有價值的儀表板。技術或美觀是次要的考量,響應式設計(選項D)也很重要,但不是最優先的。包含所有數據(選項C)通常會導致資訊過載。
#48
★★★
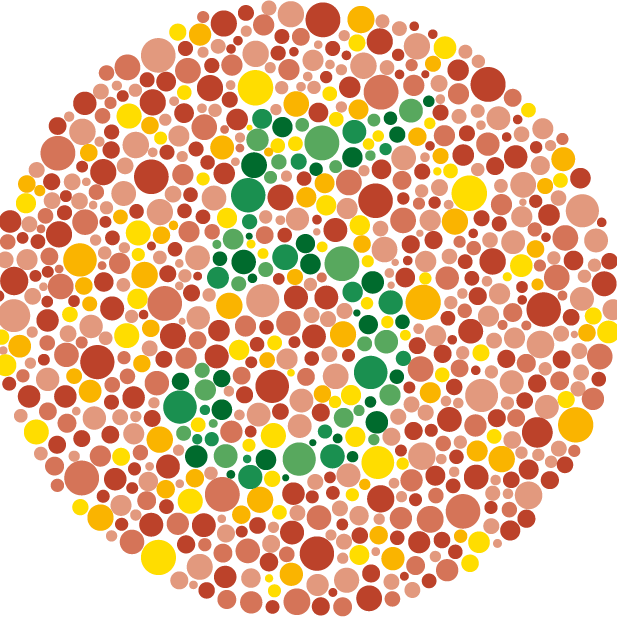
在為視覺化選擇顏色時,需要注意色盲用戶的可及性 (Accessibility)。最常見的色盲類型(紅綠色盲)會對哪兩種顏色的區分造成困難?
答案解析
紅綠色盲是最常見的色覺辨認障礙類型。對於紅綠色盲的人來說,區分紅色和綠色非常困難,它們看起來可能很相似。因此,在數據視覺化中,應避免僅使用紅色和綠色來區分重要的資訊(例如,用紅色表示差,綠色表示好),因為這會讓部分觀眾無法有效接收訊息。建議使用對色盲友好的調色盤,或者除了顏色之外,也使用其他視覺線索(如形狀、圖案、標籤)來區分數據。藍黃色盲較少見。
#49
★★
下列哪項工具更側重於透過程式設計(例如 Python)來創建自訂和複雜的數據視覺化?
答案解析
Excel, Tableau, Power BI 主要提供圖形化使用者介面 (GUI) 來創建視覺化,雖然它們也提供一定的自訂性,但對於高度自訂或非標準的視覺化需求,其能力可能受限。而 Python 的視覺化函式庫(如 Matplotlib, Seaborn, Plotly, Bokeh 等)提供了透過程式碼控制圖表各個細節的能力,給予開發者極大的靈活性來創建各種標準或非標準的、靜態或互動式的視覺化圖形,更適合需要深度自訂和整合到數據分析流程中的場景。
#50
★★★
探索性數據分析 (Exploratory Data Analysis, EDA) 中,視覺化扮演什麼重要角色?
答案解析
探索性數據分析 (EDA) 是在正式建模之前,對數據進行初步探索和理解的過程。視覺化在 EDA 中是不可或缺的工具,因為它能:
直觀展示數據分佈:使用直方圖、密度圖、盒鬚圖等了解單一變數的特性。
發現變數間關係:使用散佈圖、熱力圖等觀察變數間的相關性或模式。
識別異常值或錯誤:視覺化能更容易地發現偏離常規的數據點。
引導後續分析方向:探索性的發現可以幫助形成假設或選擇合適的分析方法。
視覺化與統計摘要相輔相成,不能完全取代,也不能自動選擇模型,它在分析的早期探索階段尤為重要。
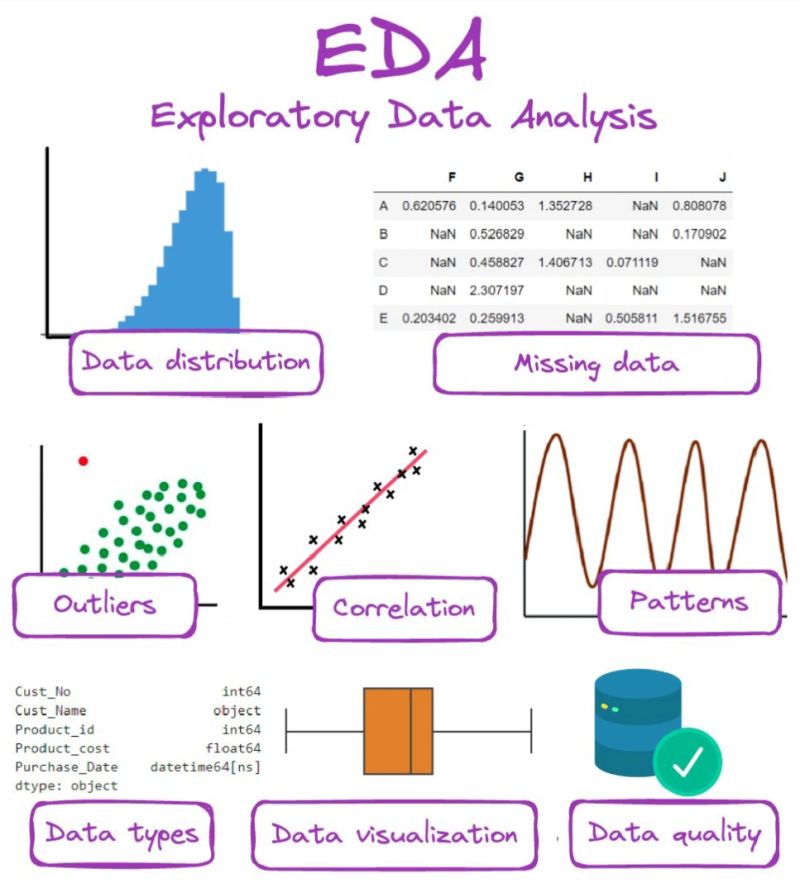
直觀展示數據分佈:使用直方圖、密度圖、盒鬚圖等了解單一變數的特性。
發現變數間關係:使用散佈圖、熱力圖等觀察變數間的相關性或模式。
識別異常值或錯誤:視覺化能更容易地發現偏離常規的數據點。
引導後續分析方向:探索性的發現可以幫助形成假設或選擇合適的分析方法。
視覺化與統計摘要相輔相成,不能完全取代,也不能自動選擇模型,它在分析的早期探索階段尤為重要。