iPAS AI應用規劃師 經典題庫
L22302 常見的大數據分析方法
出題方向
1
大數據分析基本概念與流程
2
描述性分析方法
3
診斷性分析方法
4
預測性分析方法 (監督式)
5
預測性分析方法 (非監督式與關聯)
6
處方性分析與其他方法
#1
★★★★★
大數據分析的四個主要類型依序回答「發生了什麼?」、「為什麼發生?」、「未來可能發生什麼?」以及「應該怎麼做?」請問「未來可能發生什麼?」對應的是哪種類型分析?
答案解析
大數據分析的四種類型各有側重:
1. 描述性分析:回答「發生了什麼?」,總結過去數據,例如銷售報表。
2. 診斷性分析:回答「為什麼發生?」,探究事件發生的原因,例如分析銷售下降的原因。
3. 預測性分析:回答「未來可能發生什麼?」,利用歷史數據預測未來趨勢,例如預測下季度的銷售額。
4. 處方性分析:回答「應該怎麼做?」,基於預測結果提出最佳行動建議,例如建議調整行銷策略以提升銷售。
因此,回答「未來可能發生什麼?」的是預測性分析。
1. 描述性分析:回答「發生了什麼?」,總結過去數據,例如銷售報表。
2. 診斷性分析:回答「為什麼發生?」,探究事件發生的原因,例如分析銷售下降的原因。
3. 預測性分析:回答「未來可能發生什麼?」,利用歷史數據預測未來趨勢,例如預測下季度的銷售額。
4. 處方性分析:回答「應該怎麼做?」,基於預測結果提出最佳行動建議,例如建議調整行銷策略以提升銷售。
因此,回答「未來可能發生什麼?」的是預測性分析。
#2
★★★★
某零售商想要了解過去一年中最暢銷的產品類別,應該使用哪種分析方法?
答案解析
描述性分析旨在總結和呈現過去的數據,以了解發生了什麼。分析「過去一年中最暢銷的產品類別」是典型的描述性分析應用,透過彙總銷售數據來找出銷售量最高的類別。預測性分析是預測未來,處方性分析是提供建議,診斷性分析是探究原因。
#3
★★★★★
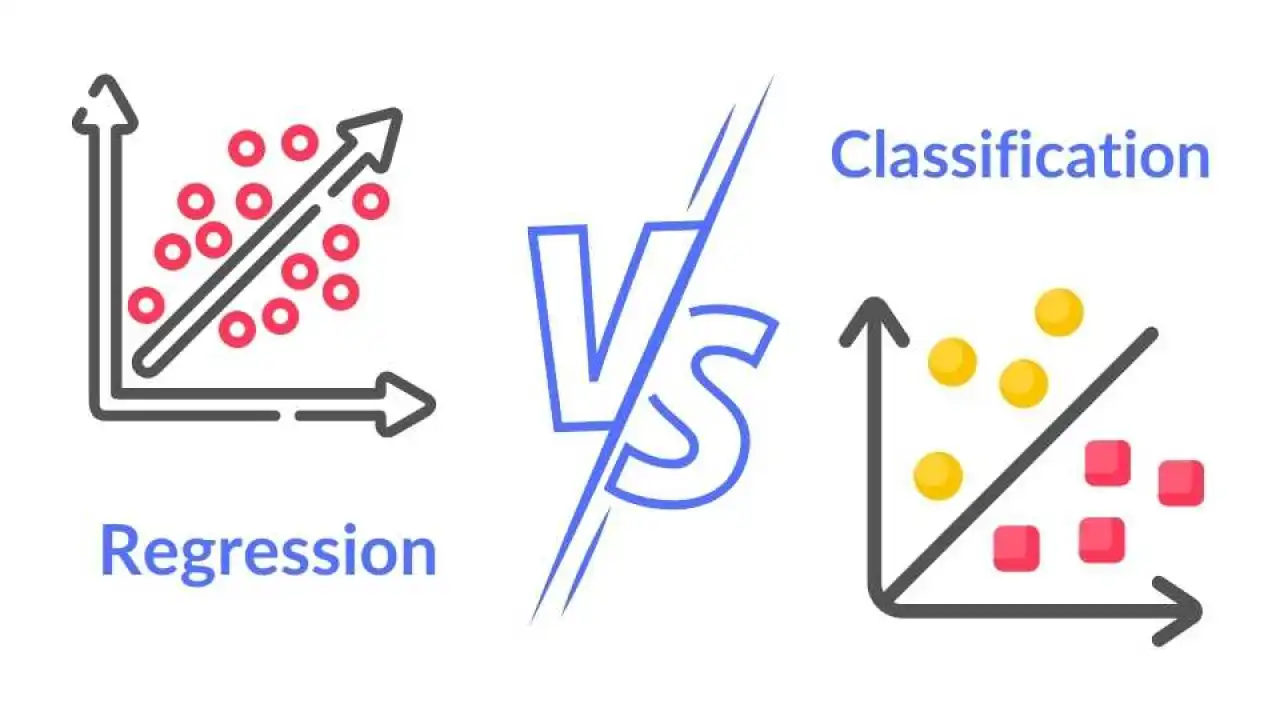
欲建立一個模型來預測客戶是否會流失(是/否),這屬於哪一種機器學習任務?
答案解析
分類任務是預測一個樣本屬於哪個預先定義好的類別。在這個案例中,目標是預測客戶屬於「會流失」或「不會流失」這兩個類別之一,因此是典型的分類問題。迴歸是預測連續數值(如房價、溫度)。分群是在沒有預先定義類別的情況下將相似的樣本分組。關聯規則探勘是找出數據項之間的關聯性(如購買A的人也常購買B)。
#4
★★★★
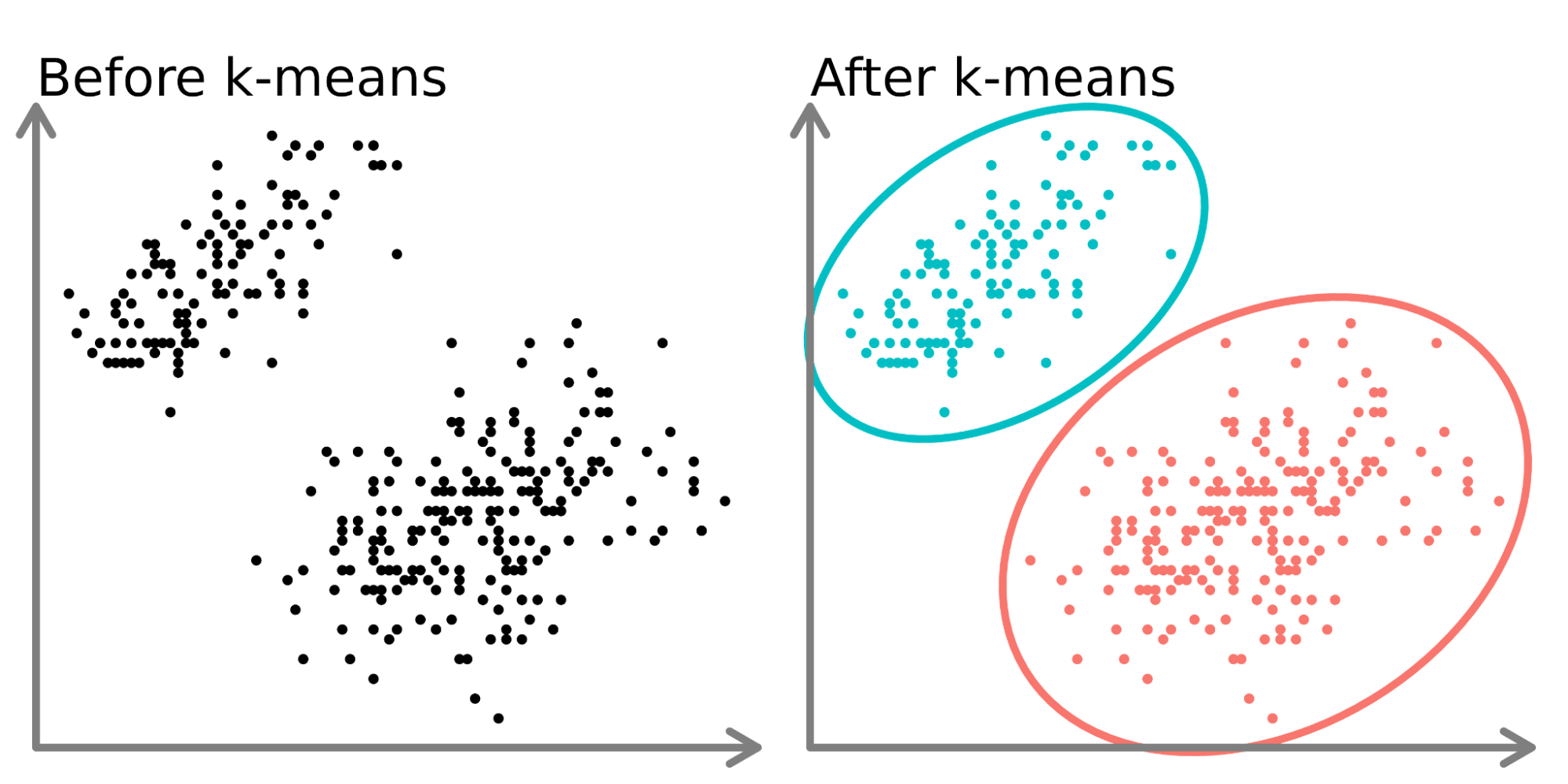
K-means (K-平均演算法) 是一種常見的哪種分析技術?
答案解析
K-means是一種非常流行的分群演算法,屬於非監督式學習。它的目標是將數據集劃分為 K 個互斥的群組(clusters),使得同一群組內的數據點彼此相似度高,而不同群組間的數據點相似度低。它並非用於預測類別(分類)、預測數值(迴歸)或減少特徵數量(降維)。
#5
★★★
下列哪個指標最適合用來衡量一組數值數據的分散程度?
答案解析
平均數、中位數和眾數都是衡量數據集中趨勢(central tendency)的指標,代表數據的中心位置。標準差(以及變異數 Variance)則是衡量數據分散程度(dispersion or variability)的指標,表示數據點偏離平均數的平均距離。標準差越大,表示數據越分散;標準差越小,表示數據越集中。

#6
★★★★
分析師發現某產品的銷售額突然下降,試圖找出可能的原因,例如是否因為競爭對手降價、或是季節性因素。這個過程屬於哪種分析?
答案解析
診斷性分析旨在深入探究「為什麼」某個現象會發生。當分析師看到銷售額下降(描述性分析的結果)後,開始尋找背後的原因(競爭、季節性等),這就是在進行診斷性分析。其目的是找出問題的根本原因,以便後續採取行動。
#7
★★★★★
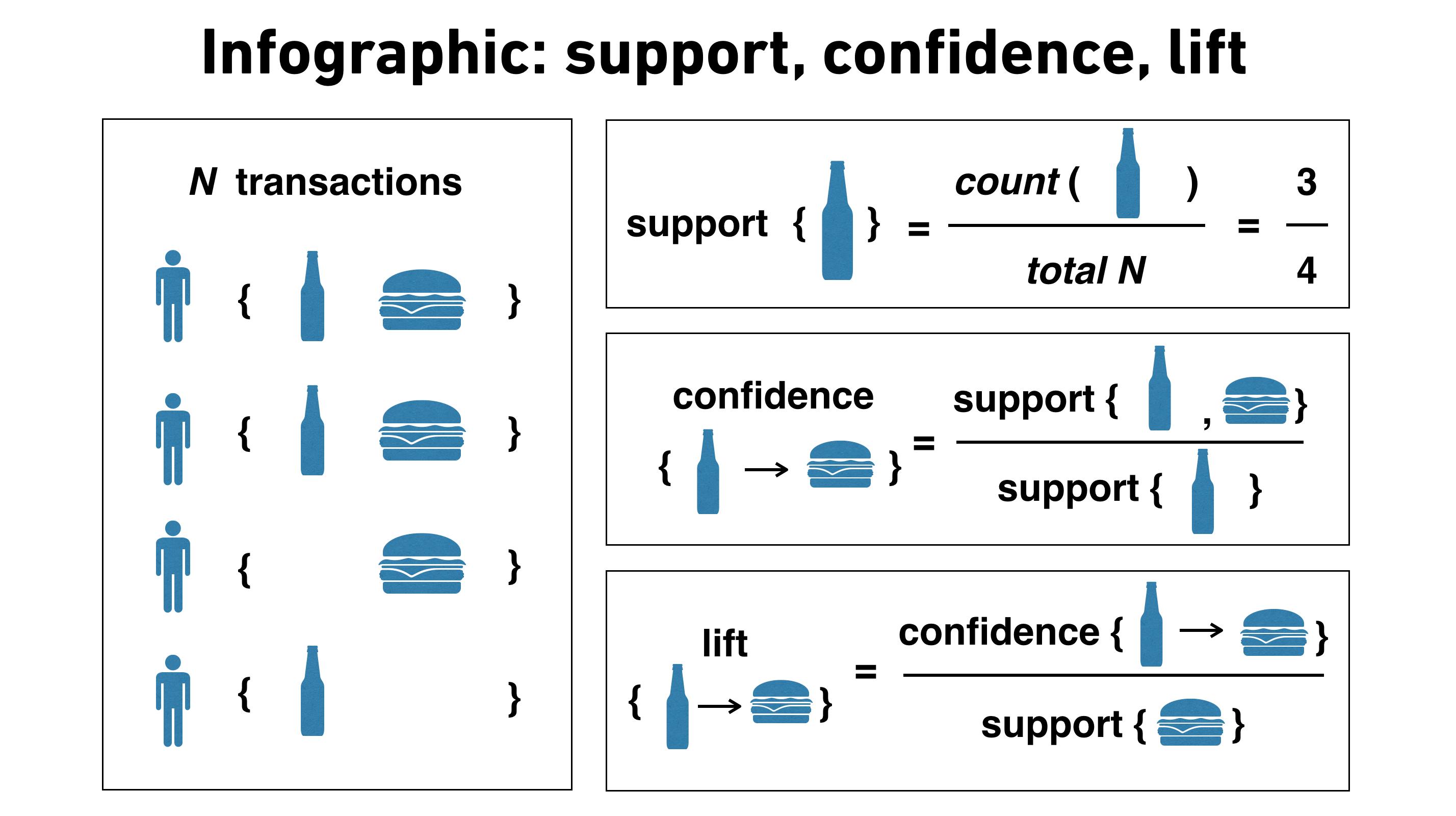
在購物籃分析 (Market Basket Analysis) 中,用來衡量「購買了商品 A 的顧客中,有多大比例也購買了商品 B」的指標是?
答案解析
關聯規則 (Association Rule) 分析中的常用指標:
支持度 (Support): 指項目集 {A, B} 在所有交易中出現的頻率。Support({A, B}) = P(A ∩ B)。
信賴度 (Confidence): 指規則 A → B 的信賴度,表示購買了 A 的交易中,同時也包含 B 的比例。Confidence(A → B) = P(B | A) = Support({A, B}) / Support({A})。這正是題目所描述的指標。
提升度 (Lift): 指規則 A → B 的提升度,衡量購買 A 對於購買 B 的概率提升了多少。Lift(A → B) = Confidence(A → B) / Support({B}) = P(B | A) / P(B)。Lift > 1 表示正相關,Lift < 1 表示負相關,Lift = 1 表示獨立。
覆蓋率 (Coverage) 通常指規則前項 (A) 的支持度 Support({A})。
支持度 (Support): 指項目集 {A, B} 在所有交易中出現的頻率。Support({A, B}) = P(A ∩ B)。
信賴度 (Confidence): 指規則 A → B 的信賴度,表示購買了 A 的交易中,同時也包含 B 的比例。Confidence(A → B) = P(B | A) = Support({A, B}) / Support({A})。這正是題目所描述的指標。
提升度 (Lift): 指規則 A → B 的提升度,衡量購買 A 對於購買 B 的概率提升了多少。Lift(A → B) = Confidence(A → B) / Support({B}) = P(B | A) / P(B)。Lift > 1 表示正相關,Lift < 1 表示負相關,Lift = 1 表示獨立。
覆蓋率 (Coverage) 通常指規則前項 (A) 的支持度 Support({A})。
 >
>
#8
★★★★
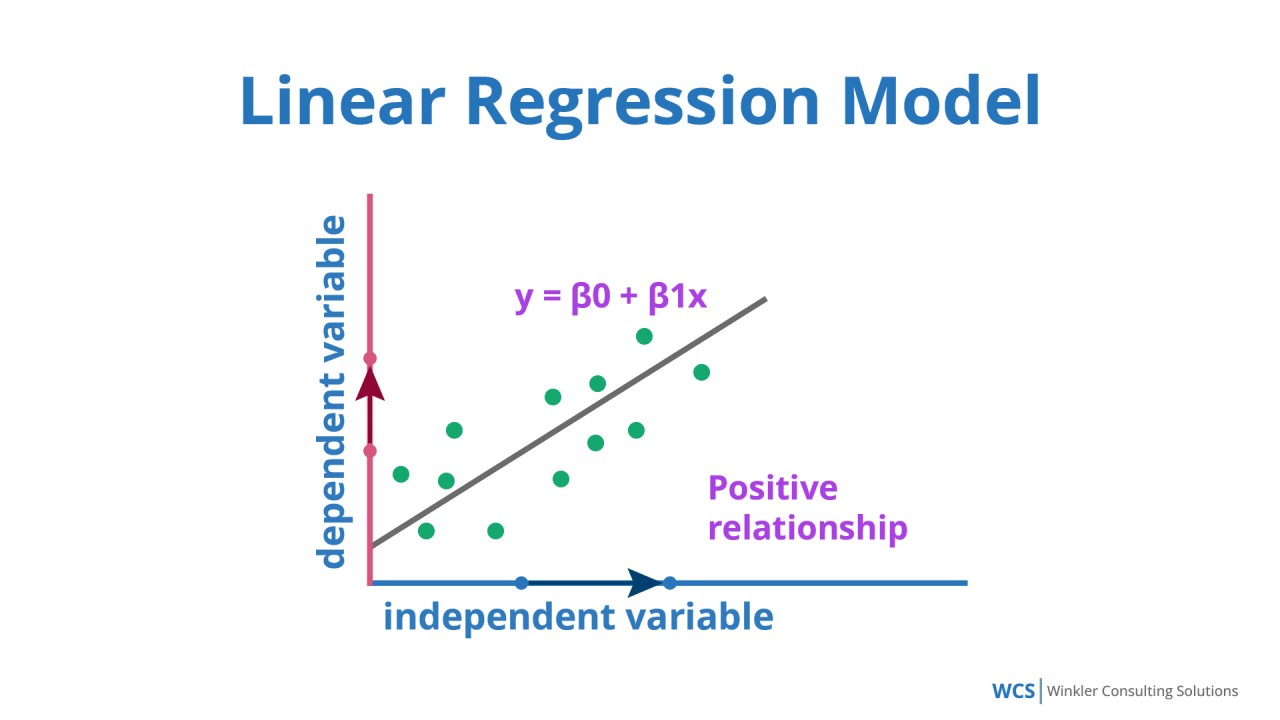
下列哪種演算法常用於解決迴歸 (Regression) 問題?
答案解析
迴歸問題的目標是預測一個連續的數值輸出。線性迴歸是最基本也是最常用的迴歸演算法之一,它試圖找到一個線性關係來擬合輸入特徵和輸出變數。K-means是用於分群。Apriori是用於關聯規則探勘。決策樹雖然可以用於迴歸(稱為迴歸樹),但選項 D 明確指出是分類器 (Classifier),因此是用於分類問題。
#9
★★★★
A/B 測試 (A/B Testing) 最主要的目的為何?
答案解析
A/B 測試是一種實驗方法,常用於比較兩個版本(版本 A 和版本 B)的效果優劣。例如,網站設計師想知道新的按鈕顏色是否比舊的更能吸引點擊,就可以將使用者隨機分配到看到版本 A(舊顏色)或版本 B(新顏色)的組別,然後比較兩組的點擊率是否有顯著差異。這有助於基於數據做出決策,屬於廣義的處方性分析或優化過程。
#10
★★★
大數據的 3V 特性通常指的是 Volume (量)、Velocity (速) 和哪個 V?
答案解析
大數據最初由 Gartner 公司定義的 3V 特性是:
Volume (資料量): 指數據規模巨大。
Velocity (資料速度): 指數據產生和處理的速度快。
Variety (資料多樣性): 指數據類型多樣,包括結構化、半結構化和非結構化數據。
後來又有人擴展了更多 V,如 Veracity (真實性,指數據的準確度和可信度) 和 Value (價值,指從數據中提取有價值的資訊)。但最核心、最常被提及的 3V 是 Volume, Velocity, Variety。
Volume (資料量): 指數據規模巨大。
Velocity (資料速度): 指數據產生和處理的速度快。
Variety (資料多樣性): 指數據類型多樣,包括結構化、半結構化和非結構化數據。
後來又有人擴展了更多 V,如 Veracity (真實性,指數據的準確度和可信度) 和 Value (價值,指從數據中提取有價值的資訊)。但最核心、最常被提及的 3V 是 Volume, Velocity, Variety。

#11
★★★★
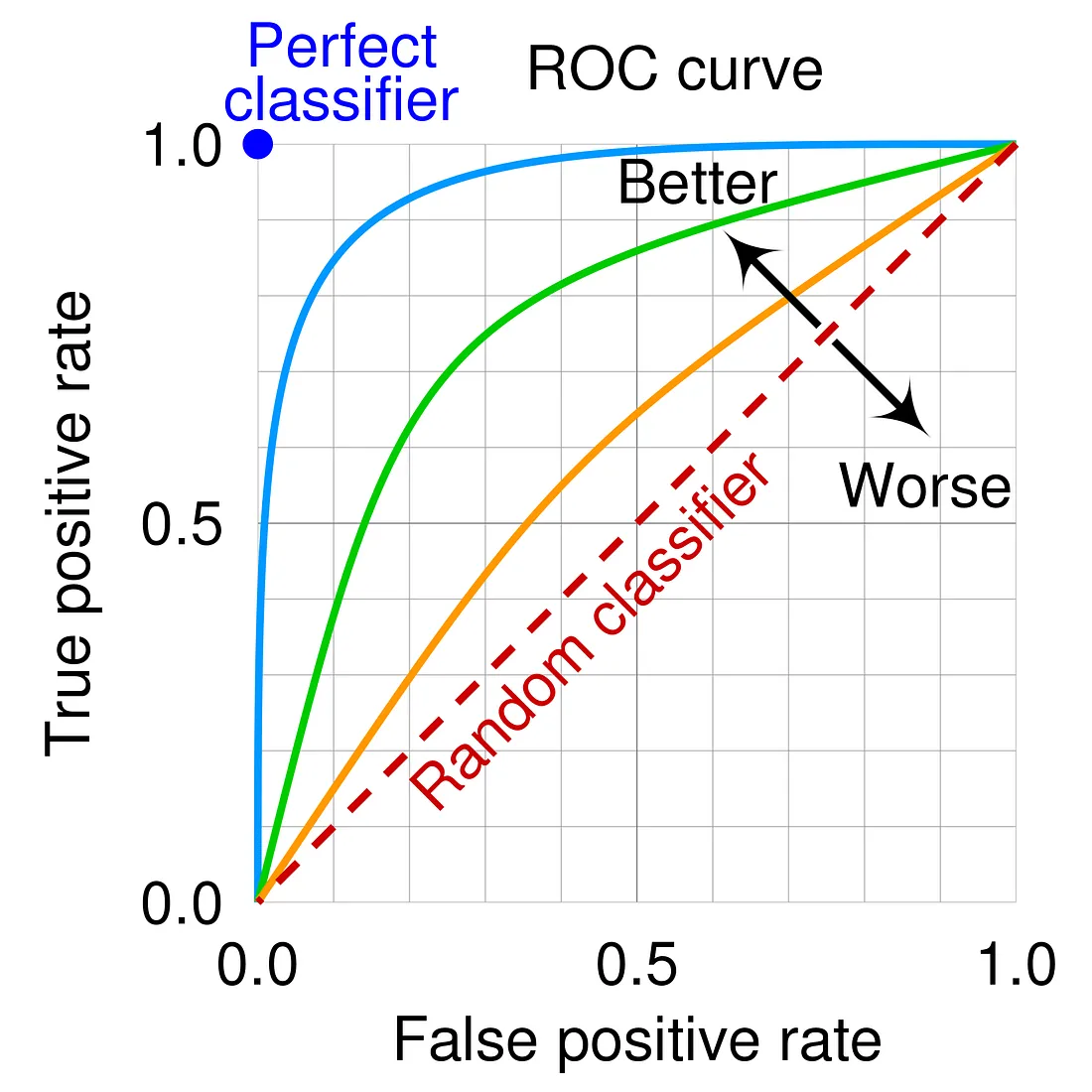
在評估分類模型性能時,ROC 曲線 (Receiver Operating Characteristic Curve) 的橫軸和縱軸分別代表什麼?
答案解析
ROC 曲線是用來視覺化二元分類模型在不同閾值下性能的圖形。其橫軸是偽陽性率 (False Positive Rate, FPR),計算方式為 FP / (FP + TN),代表實際為負樣本但被誤判為正樣本的比例。其縱軸是真陽性率 (True Positive Rate, TPR),也稱為召回率 (Recall) 或敏感度 (Sensitivity),計算方式為 TP / (TP + FN),代表實際為正樣本且被正確判斷為正樣本的比例。一個好的分類器其 ROC 曲線會盡量靠近左上角。
#12
★★★
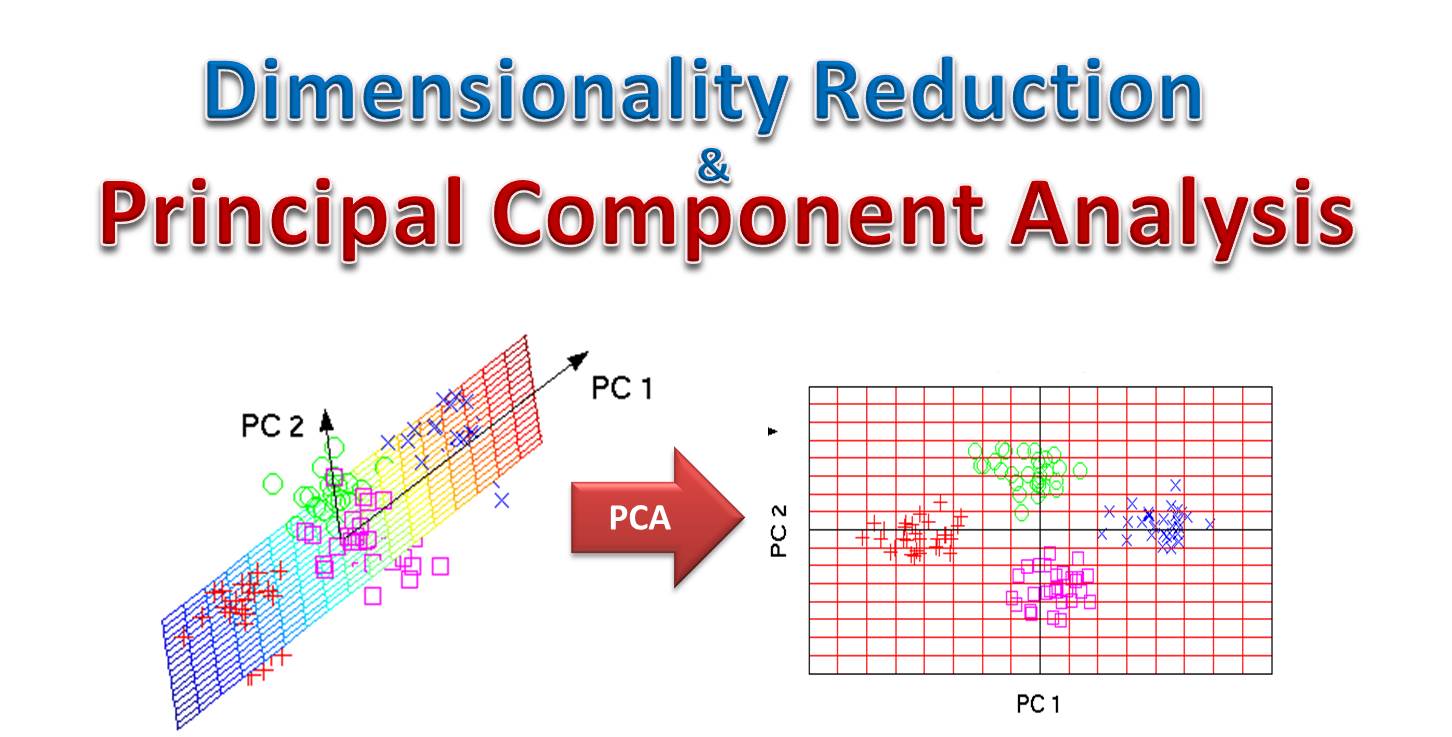
下列哪種方法屬於非監督式學習 (Unsupervised Learning)?
答案解析
非監督式學習是指在沒有標籤(label)的數據上進行學習,模型需要自行找出數據中的結構或模式。主成分分析 (PCA) 是一種常見的降維技術,它尋找數據中方差最大的方向(主成分),將高維數據投影到低維空間,這個過程不需要標籤,屬於非監督式學習。支持向量機、邏輯迴歸和隨機森林通常用於分類或迴歸任務,需要有標籤的數據進行訓練,屬於監督式學習。
#13
★★★★
分析大量客戶評論以了解他們對產品的整體看法是正面、負面還是中性,這屬於哪種分析技術的應用?
答案解析
情感分析(或稱意見探勘 Opinion Mining)是自然語言處理 (Natural Language Processing, NLP) 中的一項技術,旨在識別和提取文本中所表達的主觀情感色彩(如正面、負面、中性)或情緒。分析客戶評論以判斷其褒貶態度是情感分析的典型應用。主題模型用於發現文本集中的潛在主題;命名實體識別用於找出文本中的特定實體(如人名、地名);關鍵詞提取用於找出代表文本核心內容的詞語。

#14
★★★
比較兩組獨立樣本的平均數是否有顯著差異,且假設數據大致符合常態分佈,通常使用哪種統計檢定方法?
答案解析
t 檢定用於比較兩組數據平均數的差異是否具有統計顯著性。
獨立樣本 t 檢定:用於比較兩個獨立組別(例如,實驗組 vs. 對照組)的平均數。
配對樣本 t 檢定:用於比較同一組對象在兩種不同條件下(例如,前測 vs. 後測)的平均數差異。
變異數分析 (ANOVA) 用於比較三個或更多組別的平均數差異。卡方檢定主要用於分析類別變數之間的關聯性。因此,比較兩組獨立樣本的平均數差異,應使用獨立樣本 t 檢定。
獨立樣本 t 檢定:用於比較兩個獨立組別(例如,實驗組 vs. 對照組)的平均數。
配對樣本 t 檢定:用於比較同一組對象在兩種不同條件下(例如,前測 vs. 後測)的平均數差異。
變異數分析 (ANOVA) 用於比較三個或更多組別的平均數差異。卡方檢定主要用於分析類別變數之間的關聯性。因此,比較兩組獨立樣本的平均數差異,應使用獨立樣本 t 檢定。
#15
★★★★
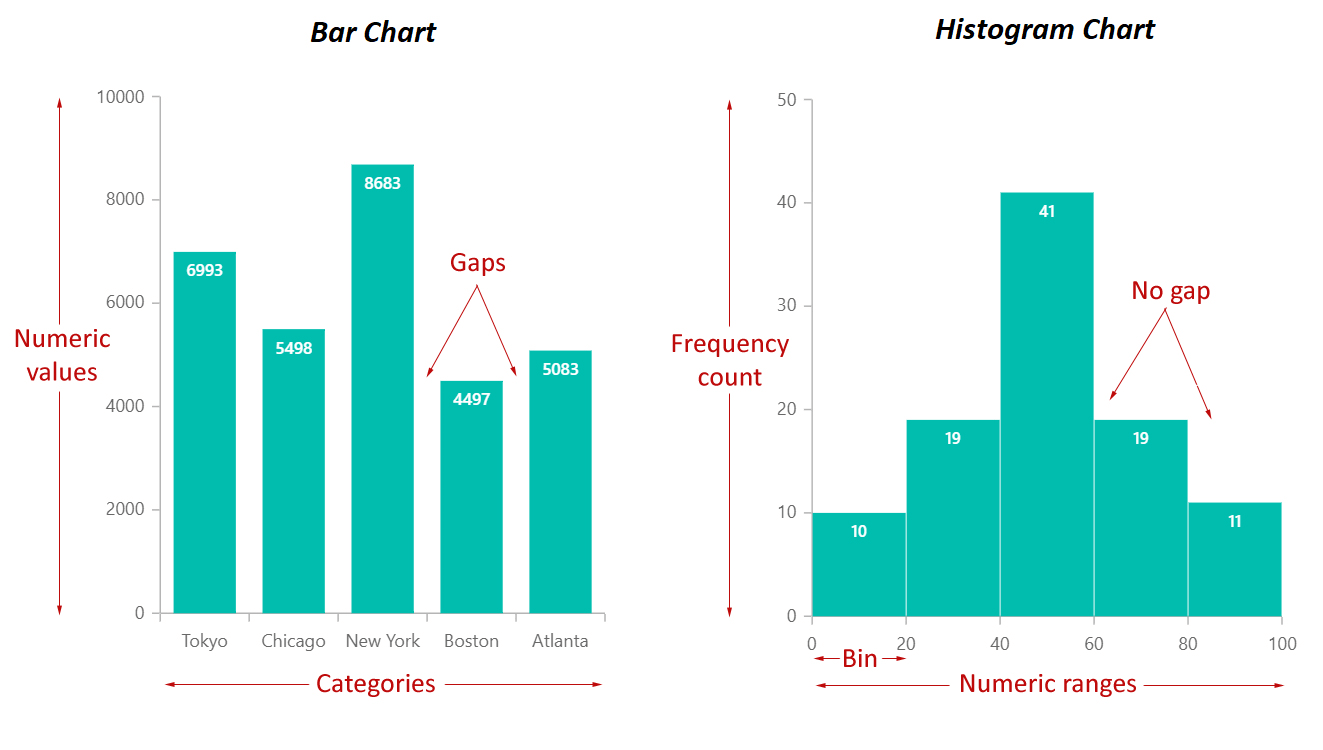
哪種圖表最適合用來展示單一類別變數中各個類別的頻率或百分比分佈?
答案解析
長條圖和圓餅圖都常用於視覺化類別數據的分佈。長條圖使用長條的高度或長度來表示各個類別的頻率或數值,易於比較不同類別的大小。圓餅圖則將一個圓形劃分為扇形,每個扇形的面積代表該類別佔總體的百分比,適合展示各部分佔整體的比例。散佈圖用於展示兩個連續變數的關係。折線圖常用於展示數據隨時間變化的趨勢。盒鬚圖用於展示數值數據的分佈特徵(如中位數、四分位距、異常值)。
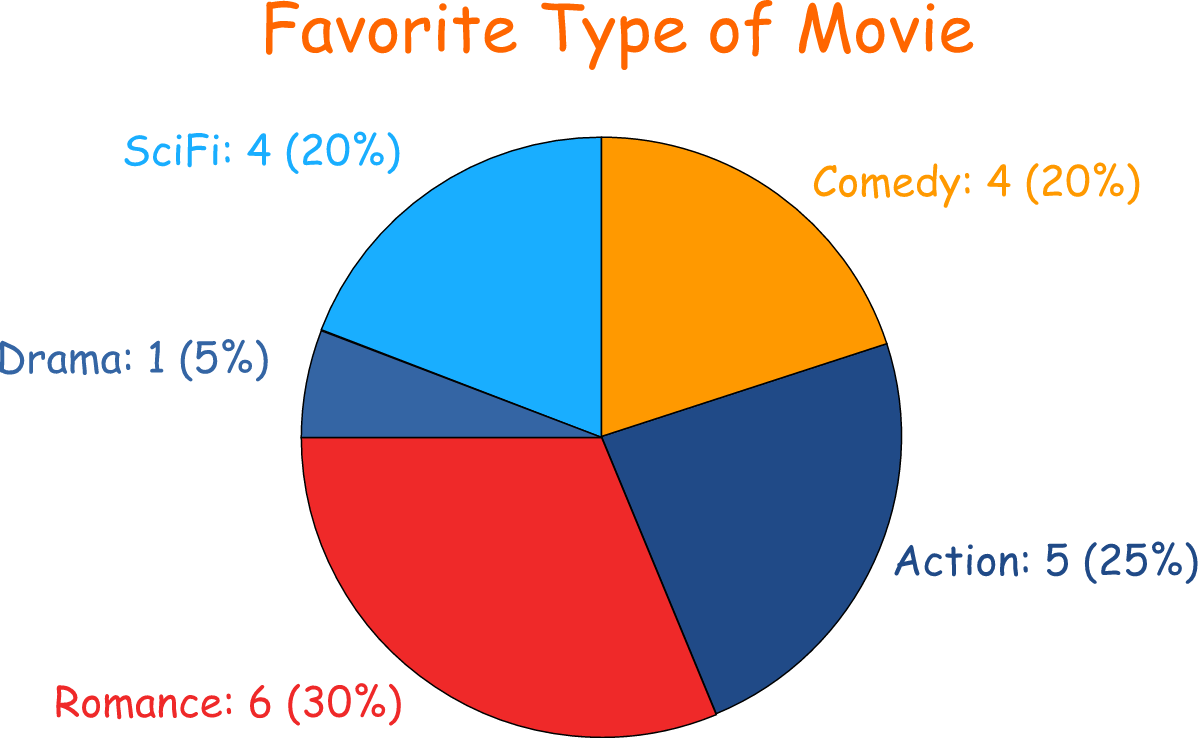
#16
★★★
在監督式學習中,用來訓練模型的數據集通常包含輸入特徵和對應的什麼?
答案解析
監督式學習 (Supervised Learning) 的核心在於從帶有標籤的訓練數據中學習一個映射函數,能夠根據輸入特徵預測輸出。訓練數據集必須包含成對的輸入特徵和已知的、正確的輸出。如果輸出是離散的類別(如「是/否」、「貓/狗」),稱為分類問題,輸出就是標籤 (Labels)。如果輸出是連續的數值(如房價、溫度),稱為迴歸問題,輸出就是數值 (Values)。非監督式學習(如分群、降維)則使用沒有標籤的數據。
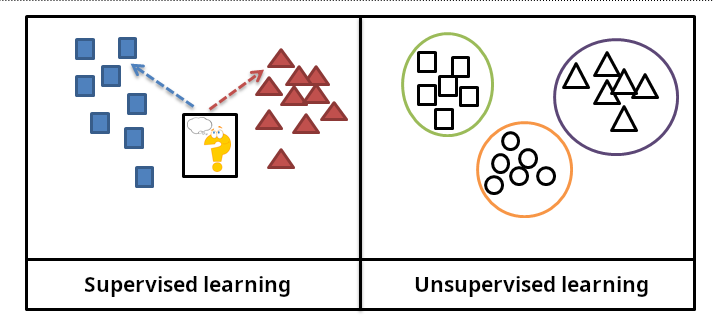
#17
★★★★
大數據分析流程通常包含數據收集、數據清理、數據處理/轉換、數據分析/建模以及哪個最終步驟?
答案解析
典型的大數據分析流程是一個迭代過程,大致包含:
1. 定義問題/目標
2. 數據收集 (Data Collection)
3. 數據清理/預處理 (Data Cleaning/Preprocessing):處理缺失值、異常值、格式轉換等。
4. 數據探索與轉換 (Data Exploration & Transformation):包含特徵工程 (Feature Engineering)。
5. 數據分析/建模 (Data Analysis/Modeling):應用統計或機器學習方法。
6. 模型評估 (Model Evaluation)
7. 結果解釋與視覺化/溝通 (Interpretation & Visualization/Communication):將分析洞察轉化為可行動資訊。
8. 模型部署 (Model Deployment) (若需應用模型於實際場景)
雖然模型部署也是重要一步,但「結果解釋與視覺化/溝通」是將分析洞察轉化為可行動資訊的關鍵最終環節。數據儲存和特徵工程是流程中的中間步驟。
1. 定義問題/目標
2. 數據收集 (Data Collection)
3. 數據清理/預處理 (Data Cleaning/Preprocessing):處理缺失值、異常值、格式轉換等。
4. 數據探索與轉換 (Data Exploration & Transformation):包含特徵工程 (Feature Engineering)。
5. 數據分析/建模 (Data Analysis/Modeling):應用統計或機器學習方法。
6. 模型評估 (Model Evaluation)
7. 結果解釋與視覺化/溝通 (Interpretation & Visualization/Communication):將分析洞察轉化為可行動資訊。
8. 模型部署 (Model Deployment) (若需應用模型於實際場景)
雖然模型部署也是重要一步,但「結果解釋與視覺化/溝通」是將分析洞察轉化為可行動資訊的關鍵最終環節。數據儲存和特徵工程是流程中的中間步驟。
#18
★★★
哪種分群方法會產生一個樹狀結構(樹狀圖,Dendrogram),展示數據點如何逐步合併或分裂成群集?
答案解析
階層式分群(又稱層次聚類)建立一個群集的層次結構。它有兩種主要方式:凝聚式(agglomerative,由下往上,從單個點開始逐步合併最相似的群集)和分裂式(divisive,由上往下,從包含所有點的單一群集開始逐步分裂)。其結果可以用樹狀圖 (Dendrogram) 來視覺化,顯示群集的合併或分裂過程以及它們之間的層次關係。K-means 需要預先指定 K 值,產生 K 個扁平的群集。DBSCAN 是基於密度的分群方法。GMM 是基於機率模型的分群方法。

#19
★★★★
決策樹 (Decision Tree) 演算法在建立模型時,通常會選擇哪個準則來進行節點的分裂?
答案解析
決策樹是一種貪婪演算法 (greedy algorithm),在每個節點分裂時,它會遍歷所有可能的特徵和分割點,選擇那個能夠使得分裂後子節點的「不純度」總和最小化的分裂方式。不純度的衡量指標常用的有:
吉尼不純度 (Gini Impurity):常用於 CART (Classification and Regression Tree) 演算法。
資訊增益 (Information Gain):基於熵 (Entropy) 計算,常用於 ID3, C4.5 演算法。
目標是讓每次分裂後,子節點內的樣本盡可能屬於同一類別,即純度最高(不純度最低)。
吉尼不純度 (Gini Impurity):常用於 CART (Classification and Regression Tree) 演算法。
資訊增益 (Information Gain):基於熵 (Entropy) 計算,常用於 ID3, C4.5 演算法。
目標是讓每次分裂後,子節點內的樣本盡可能屬於同一類別,即純度最高(不純度最低)。
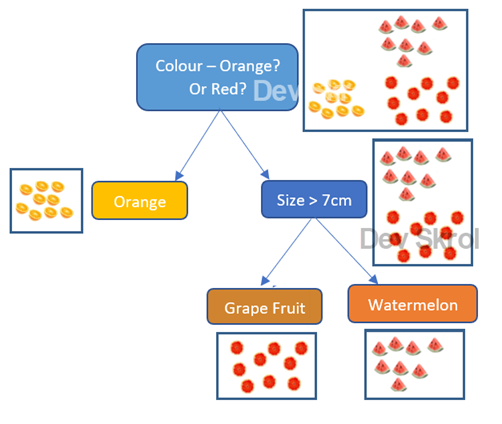
#20
★★★
在社交網路分析 (Social Network Analysis, SNA) 中,用來衡量一個節點在網路中重要性或影響力的指標,通常稱為什麼?
答案解析
中心性 (Centrality) 是社交網路分析中的核心概念,用來量化節點(例如,人、組織)在網路中的相對重要性。常見的中心性指標包括:
度中心性 (Degree Centrality): 節點的連接數。
介數中心性 (Betweenness Centrality): 節點出現在其他節點對之間最短路徑上的次數。
接近中心性 (Closeness Centrality): 節點到網路中所有其他節點的平均距離的倒數。
特徵向量中心性 (Eigenvector Centrality): 節點的重要性取決於其鄰居節點的重要性(例如 Google 的 PageRank)。
群集係數衡量節點鄰居之間的連接緊密程度。路徑長度指節點間的距離。網路密度指實際存在的連接數佔所有可能連接數的比例。
度中心性 (Degree Centrality): 節點的連接數。
介數中心性 (Betweenness Centrality): 節點出現在其他節點對之間最短路徑上的次數。
接近中心性 (Closeness Centrality): 節點到網路中所有其他節點的平均距離的倒數。
特徵向量中心性 (Eigenvector Centrality): 節點的重要性取決於其鄰居節點的重要性(例如 Google 的 PageRank)。
群集係數衡量節點鄰居之間的連接緊密程度。路徑長度指節點間的距離。網路密度指實際存在的連接數佔所有可能連接數的比例。
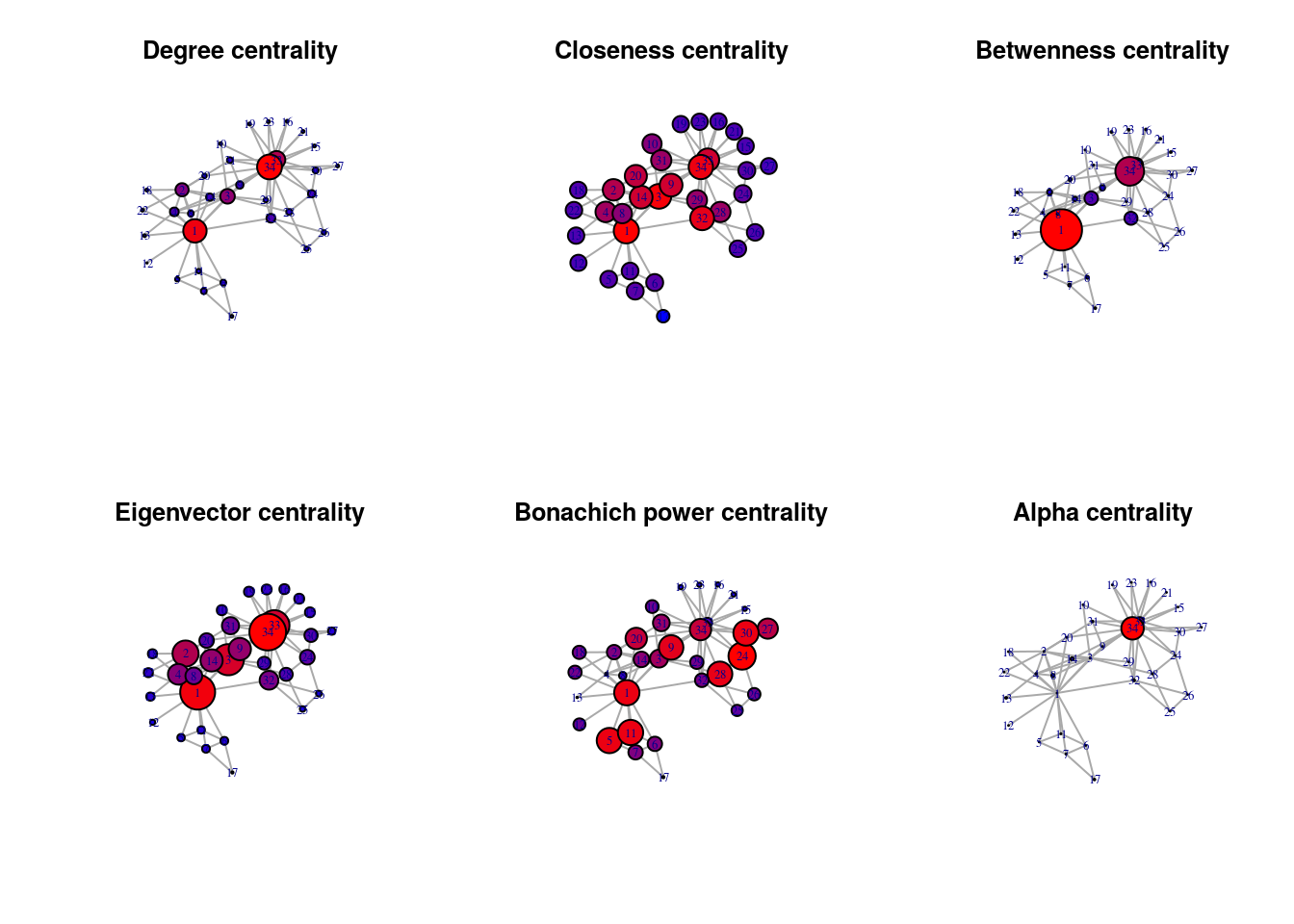
#21
★★★
使用彙總表 (Pivot Table) 的主要目的是?
答案解析
彙總表(常見於試算表軟體如 Excel 或數據分析工具)是一種強大的數據摘要工具。它允許使用者以互動的方式,拖放不同的欄位到行、列、值和篩選器區域,從而快速地對數據進行分組、計數、求和、平均等聚合運算,並以表格形式呈現結果。這是描述性分析和數據探索中非常常用的技術。
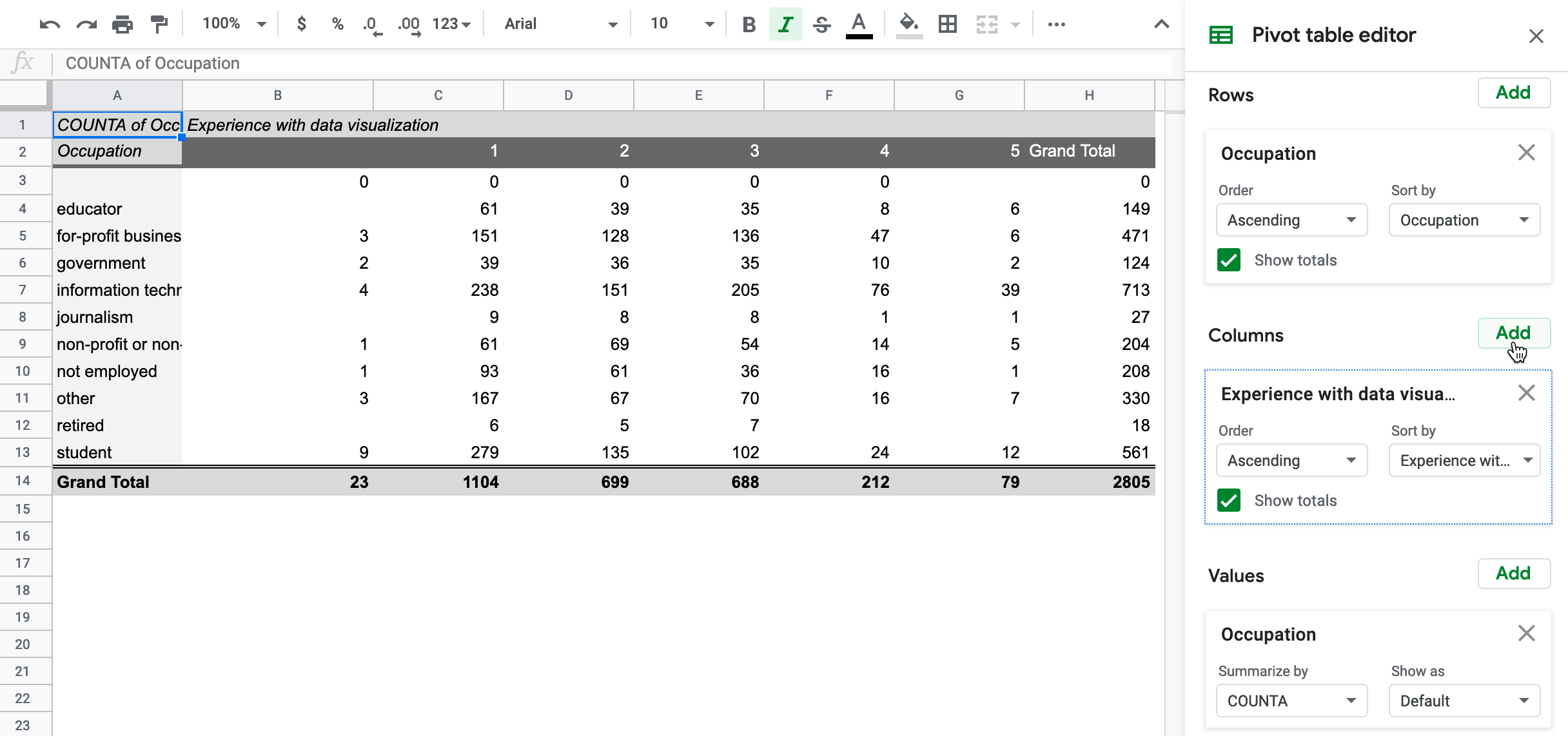
#22
★★★★
分析師觀察到兩個變數之間存在強烈的正相關關係。這是否意味著其中一個變數導致了另一個變數的變化?
答案解析
統計學中的一個基本原則是「相關性不等於因果關係」(Correlation does not imply causation)。兩個變數之間存在相關性,僅表示它們傾向於一起變化,但不能直接推斷其中一個變數的變化是「導致」另一個變數變化的原因。這種相關性可能是由第三個潛在變數(混淆變數 Confounding Variable)引起的,或者僅僅是巧合。要確定因果關係,通常需要進行更嚴謹的實驗設計(如隨機對照試驗 Randomized Controlled Trial, RCT)或使用更高級的因果推斷 (Causal Inference) 方法。
#23
★★★★
下列哪個指標衡量的是分類模型預測為「正類」的樣本中,實際上也確實是「正類」的比例?
答案解析
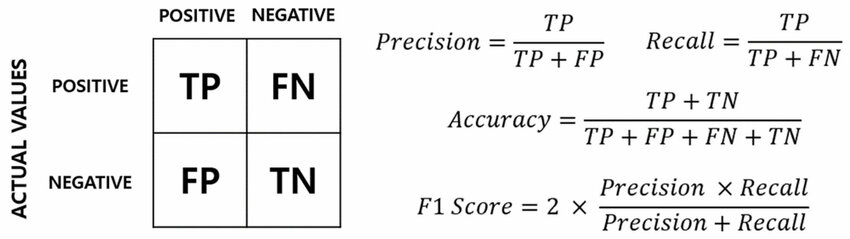
分類模型評估指標:
精確率 (Precision): TP / (TP + FP)。在所有被模型預測為正類的樣本中,有多少是真正為正類的。衡量模型預測正類的可信度,避免誤報 (False Positives)。
召回率 (Recall) / 真陽性率 (TPR): TP / (TP + FN)。在所有實際為正類的樣本中,有多少被模型成功找出來了。衡量模型找出所有正類的能力,避免漏報 (False Negatives)。
準確率 (Accuracy): (TP + TN) / (TP + TN + FP + FN)。模型預測正確的樣本數佔總樣本數的比例。在類別不平衡時可能具有誤導性。
F1 分數 (F1 Score): 2 * (Precision * Recall) / (Precision + Recall)。精確率和召回率的調和平均數,用於綜合考量兩者。
題目描述的是精確率。
精確率 (Precision): TP / (TP + FP)。在所有被模型預測為正類的樣本中,有多少是真正為正類的。衡量模型預測正類的可信度,避免誤報 (False Positives)。
召回率 (Recall) / 真陽性率 (TPR): TP / (TP + FN)。在所有實際為正類的樣本中,有多少被模型成功找出來了。衡量模型找出所有正類的能力,避免漏報 (False Negatives)。
準確率 (Accuracy): (TP + TN) / (TP + TN + FP + FN)。模型預測正確的樣本數佔總樣本數的比例。在類別不平衡時可能具有誤導性。
F1 分數 (F1 Score): 2 * (Precision * Recall) / (Precision + Recall)。精確率和召回率的調和平均數,用於綜合考量兩者。
題目描述的是精確率。
#24
★★★
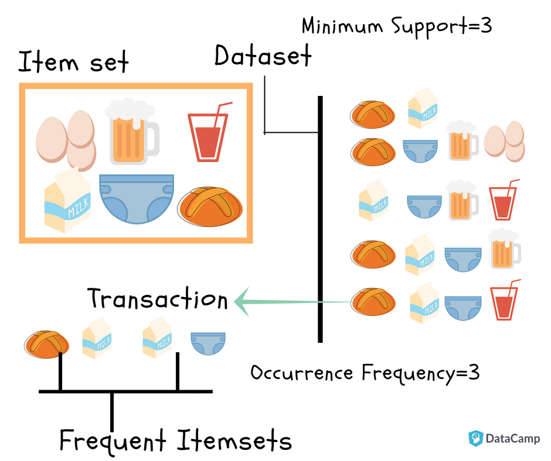
Apriori 演算法主要用於解決哪一類數據分析問題?
答案解析
Apriori 演算法是關聯規則學習 (Association Rule Learning) 中的經典演算法,用於從交易數據庫中找出頻繁項目集 (Frequent Itemsets) 和關聯規則。它最著名的應用是購物籃分析,找出哪些商品經常被顧客一起購買,例如「購買尿布的人也常購買啤酒」這類規則。
#25
★★★★
哪種分析方法不僅預測未來可能發生的情況,還能提供達成特定目標的最佳行動方案或決策建議?
答案解析
處方性分析 (Prescriptive Analytics) 是四種分析類型中最高級、最具行動導向性的一種。它建立在預測性分析的基礎上,利用優化 (Optimization)、模擬 (Simulation) 等技術,不僅告訴你未來可能發生什麼,還會建議你「應該怎麼做」才能達到最佳結果或避免不好的結果。例如,基於銷售預測,建議最佳的庫存水平或定價策略。
#26
★★★
處理大數據時,常見的數據預處理步驟不包含下列哪一項?
答案解析
數據預處理是在進行數據分析或建模之前,對原始數據進行清理和轉換的過程,目的是提高數據品質和模型性能。常見的預處理步驟包括處理缺失值(填充或刪除)、數據標準化/歸一化(調整數據尺度)、處理異常值、特徵編碼(將類別特徵轉換為數值)等。模型訓練與評估是數據預處理之後的建模階段步驟,而非預處理本身。
#27
★★★★
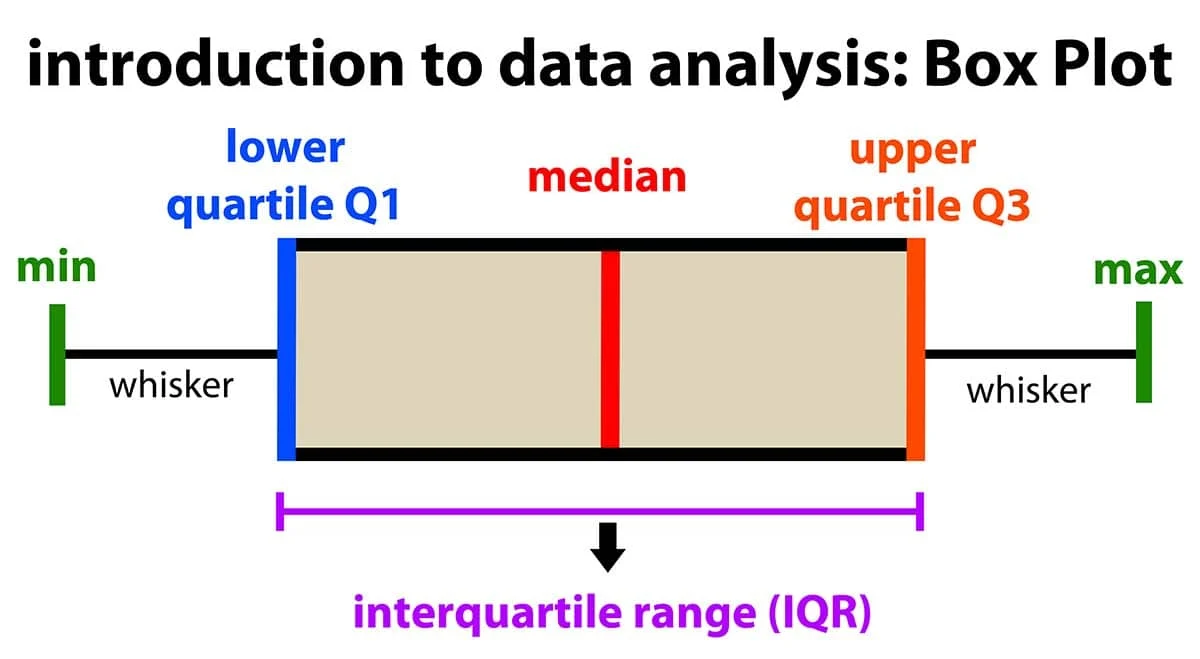
在描述性統計中,四分位距 (Interquartile Range, IQR) 是如何計算的?
答案解析
四分位數是將排序後的數據集分成四個相等部分的數值。第一四分位數 (Q1) 是第 25 百分位數,第三四分位數 (Q3) 是第 75 百分位數。四分位距 (IQR) 是衡量數據中間 50% 範圍的指標,計算方式為 IQR = Q3 - Q1。它對異常值不敏感,常用於描述數據的分散程度和檢測異常值(例如,在盒鬚圖中)。最大值減去最小值是全距 (Range)。
#28
★★★★★
在機器學習中,將數據集劃分為訓練集 (Training Set) 和測試集 (Test Set) 的主要目的是什麼?
答案解析
模型在訓練集上表現好,不代表它在實際應用中也能表現好,因為模型可能過度擬合 (Overfitting) 了訓練數據的雜訊或特定模式。為了客觀評估模型的泛化能力,即模型對從未見過的新數據的預測能力,通常會將一部分數據保留下來作為測試集。模型只在訓練集上進行訓練,然後在測試集上進行評估。測試集的表現更能反映模型在真實世界中的性能。有時還會劃分出驗證集 (Validation Set) 用於調整模型超參數。
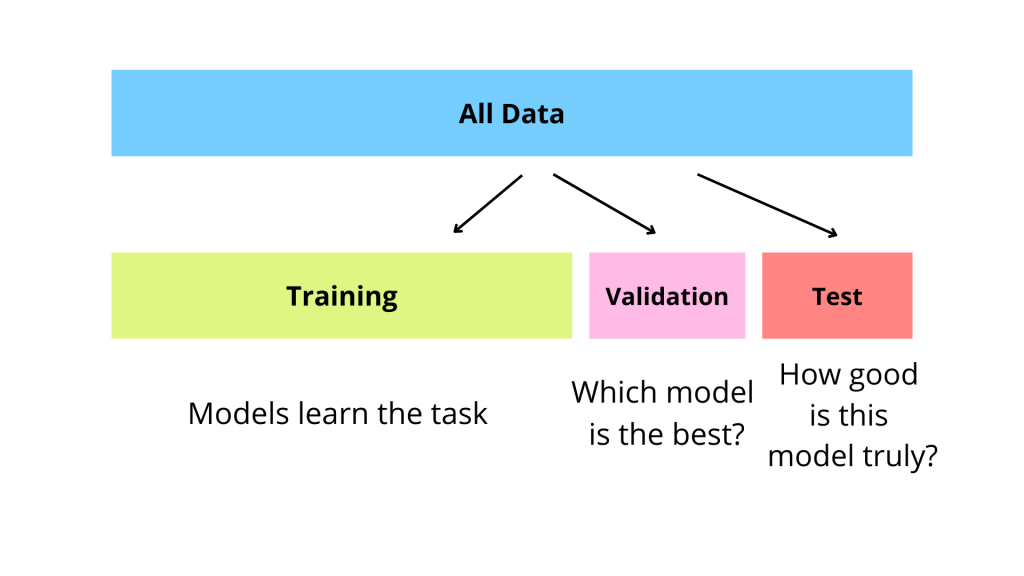
#29
★★★★
降維 (Dimensionality Reduction) 技術的主要好處不包含下列哪一項?
答案解析
降維技術(如 PCA、t-SNE)旨在保留數據主要變異性的同時,減少特徵的數量。其好處包括:
減少計算量:特徵減少,模型訓練和預測更快。
緩解維度災難:在高維空間中,數據點變得稀疏,距離計算失去意義,模型性能可能下降。降維有助於緩解此問題。
數據視覺化:將高維數據降到 2 或 3 維,方便觀察數據結構。
去除雜訊/冗餘特徵:可能提升某些模型性能。
然而,降維是一個有損壓縮的過程,會丟失部分資訊。雖然有時能因去除雜訊而提升模型性能,但並非總是如此,對於某些模型或任務,降維反而可能降低準確性。因此,不能保證提升所有模型的準確性。
減少計算量:特徵減少,模型訓練和預測更快。
緩解維度災難:在高維空間中,數據點變得稀疏,距離計算失去意義,模型性能可能下降。降維有助於緩解此問題。
數據視覺化:將高維數據降到 2 或 3 維,方便觀察數據結構。
去除雜訊/冗餘特徵:可能提升某些模型性能。
然而,降維是一個有損壓縮的過程,會丟失部分資訊。雖然有時能因去除雜訊而提升模型性能,但並非總是如此,對於某些模型或任務,降維反而可能降低準確性。因此,不能保證提升所有模型的準確性。
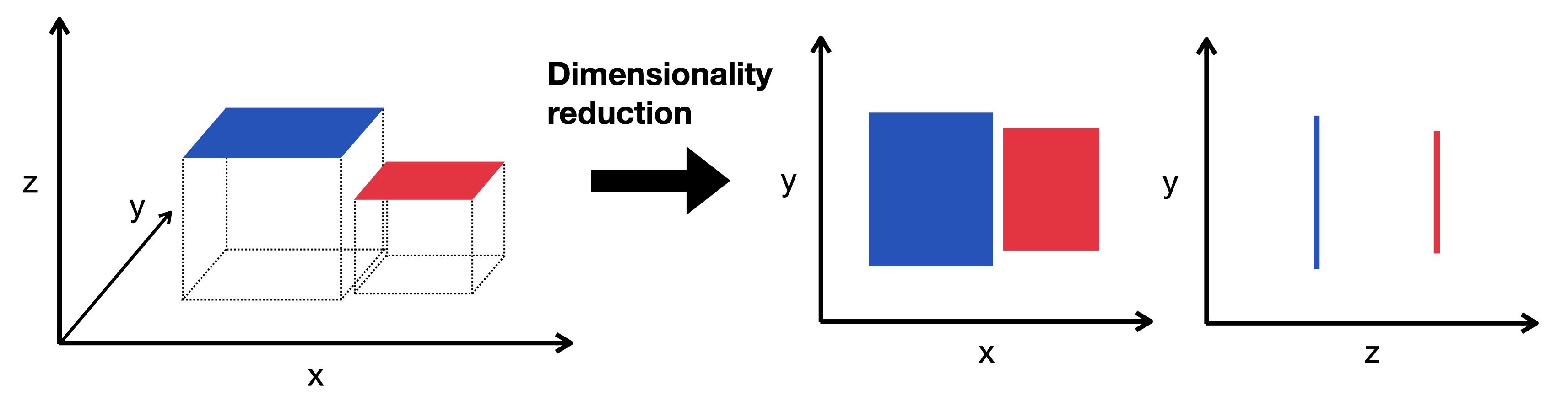
#30
★★★
哪種技術常用於模擬複雜系統(如生產線、交通流)在不同條件下的行為,以評估不同策略的效果?
答案解析
模擬是一種模仿真實世界系統運作過程的技術。通過建立系統的數學或邏輯模型,並在模型中引入隨機性或不同的輸入參數,可以觀察系統在不同情境下的行為和輸出。這有助於理解系統動態、評估不同決策或策略的潛在影響,常用於處方性分析中,以找出較優的方案。線性規劃用於求解約束條件下的最優化問題。因素分析用於找出觀測變數背後的潛在結構。時間序列分解用於將時間序列拆解為趨勢、季節性、週期和隨機波動等成分。
#31
★★★★
變異數分析 (ANOVA) 主要用於檢定什麼?
答案解析
變異數分析 (Analysis of Variance, ANOVA) 是一種統計檢定方法,用於比較三個或更多獨立組別的平均數是否存在顯著差異。它通過分析組間變異 (between-group variance) 和組內變異 (within-group variance) 的比率(F 統計量)來判斷這些組別的平均數是否可能來自同一個總體。如果 F 檢定結果顯著,則表示至少有兩組的平均數存在顯著差異,後續通常需要進行事後比較 (post-hoc tests) 來確定具體是哪些組別之間存在差異。
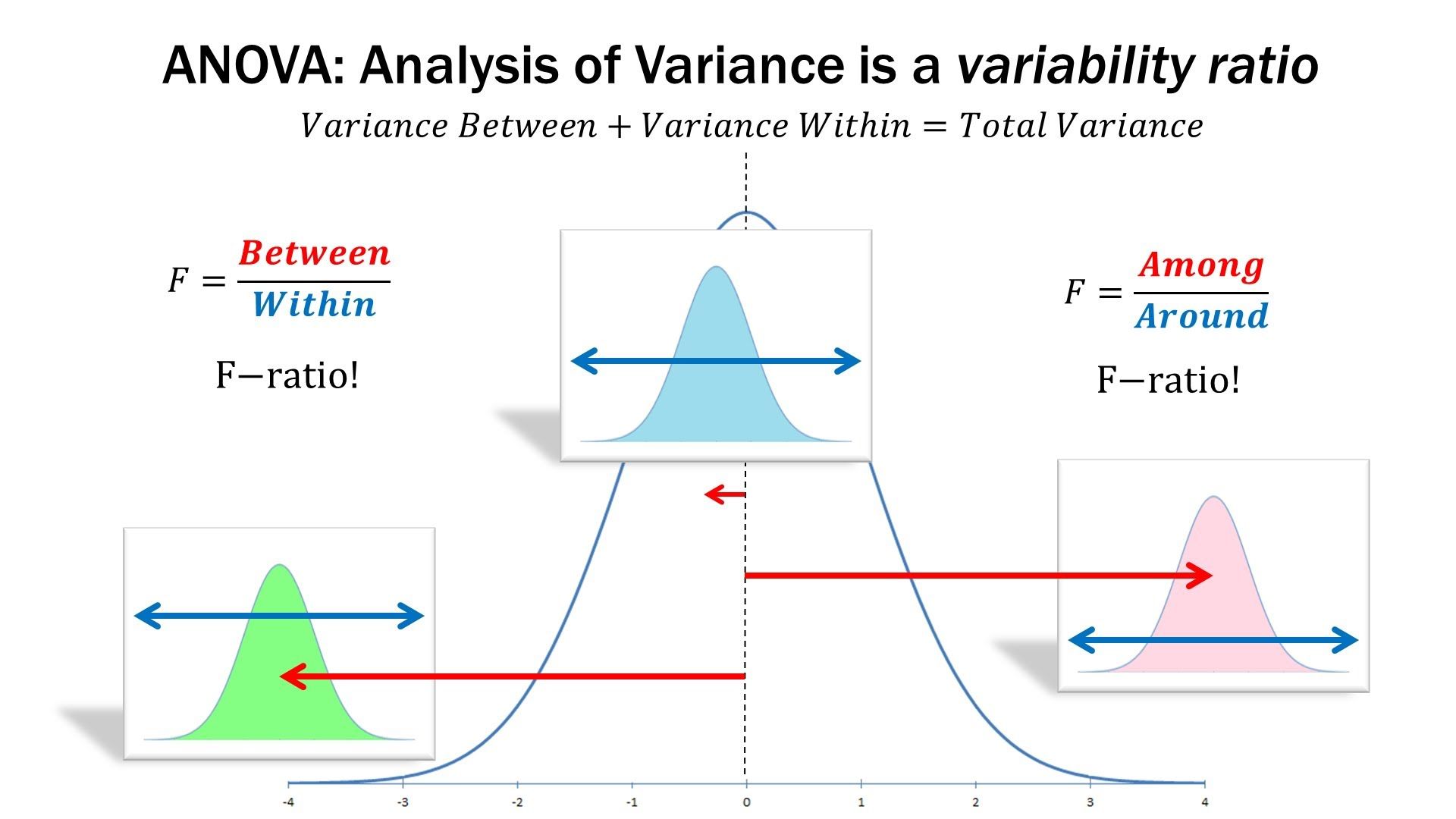
#32
★★★★
過度擬合 (Overfitting) 指的是模型發生了什麼情況?
答案解析
過度擬合是機器學習中常見的問題,指的是模型過於複雜,不僅學習了訓練數據中的一般模式,還學習了其中的雜訊和隨機波動。這導致模型在訓練集上表現非常好(例如,準確率很高),但由於它沒有學到數據的真實潛在規律,因此在應用到新的、未見過的數據(測試集)時,表現會很差,泛化能力低。相對地,模型在訓練集和測試集上表現都很差稱為擬合不足 (Underfitting)。
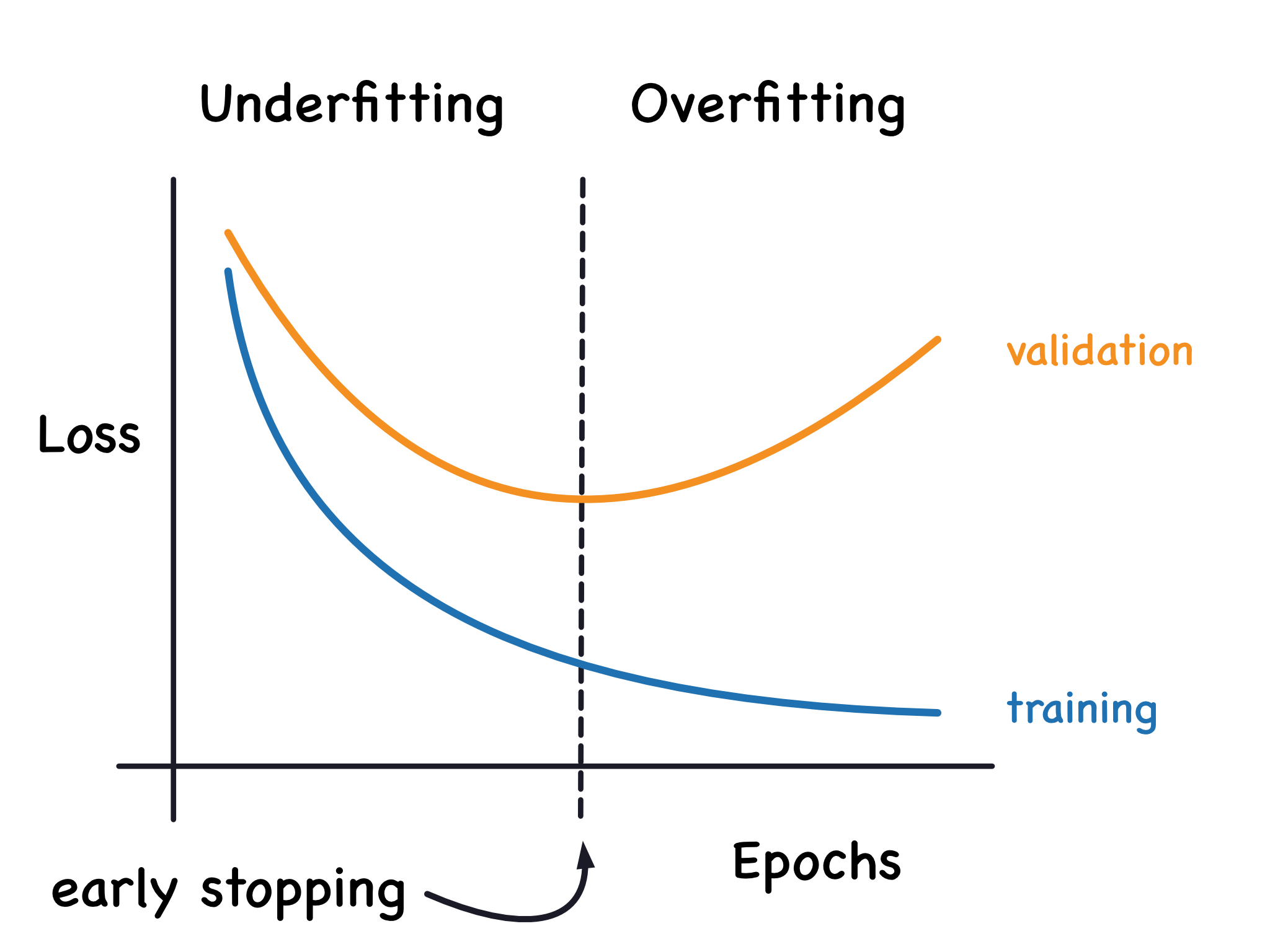
#33
★★★
在 K-means 分群中,如何選擇最佳的群集數量 K 值是一個常見問題,下列哪種方法常用於輔助選擇 K 值?
答案解析
肘部法則是選擇 K-means 最佳 K 值的一種啟發式方法。它通過計算不同 K 值對應的群內平方和 (Within-Cluster Sum of Squares, WCSS),並繪製 K 值與 WCSS 的關係圖。WCSS 衡量群內數據點的緊密程度,K 越大 WCSS 通常越小。理想的 K 值通常位於圖形曲線斜率變化趨於平緩的「肘部」位置,表示再增加 K 對於降低 WCSS 的效益不大。梯度下降法是優化演算法。交叉驗證和網格搜索常用於監督式學習的模型評估和超參數調整。
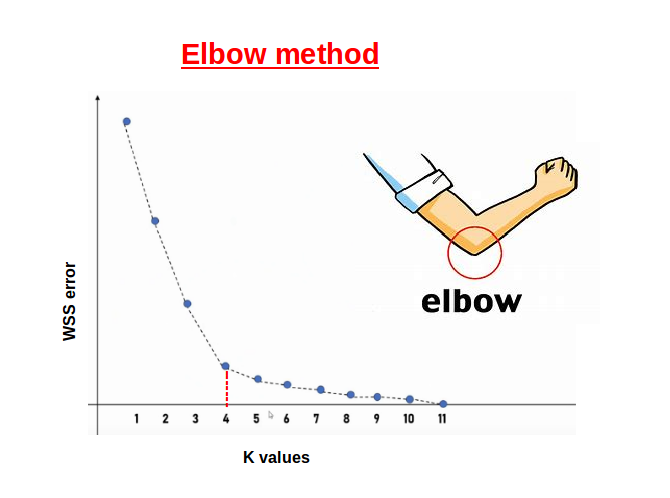
#34
★★
下列哪一項最能描述非結構化數據 (Unstructured Data)?
答案解析
數據類型通常分為:
結構化數據 (Structured Data): 具有固定的綱要 (schema),通常以表格形式存儲在關聯式數據庫中,欄位和格式定義明確 (如選項 A、B)。
非結構化數據 (Unstructured Data): 沒有預先定義的結構或模型,格式多樣,難以直接用傳統數據庫管理,佔大數據的大部分 (如選項 C)。
半結構化數據 (Semi-structured Data): 介於兩者之間,不符合嚴格的表格結構,但包含標籤或標記來分隔語意元素,具有一定的組織性 (如選項 D 的 XML/JSON)。
因此,電子郵件、社交媒體貼文、圖像、影片等是典型的非結構化數據。
結構化數據 (Structured Data): 具有固定的綱要 (schema),通常以表格形式存儲在關聯式數據庫中,欄位和格式定義明確 (如選項 A、B)。
非結構化數據 (Unstructured Data): 沒有預先定義的結構或模型,格式多樣,難以直接用傳統數據庫管理,佔大數據的大部分 (如選項 C)。
半結構化數據 (Semi-structured Data): 介於兩者之間,不符合嚴格的表格結構,但包含標籤或標記來分隔語意元素,具有一定的組織性 (如選項 D 的 XML/JSON)。
因此,電子郵件、社交媒體貼文、圖像、影片等是典型的非結構化數據。

#35
★★★
潛在狄利克雷分佈 (Latent Dirichlet Allocation, LDA) 是一種常用於什麼任務的機率模型?
答案解析
LDA 是一種生成式機率模型,常用於主題模型任務。主題模型旨在從大量文本文件中自動發現隱藏的「主題」結構。LDA 假設每份文件是多個主題的混合體,而每個主題又是多個詞語的機率分佈。通過分析文本集,LDA 可以推斷出文件的主題分佈和主題的詞語分佈,幫助理解文本集合的主要內容。
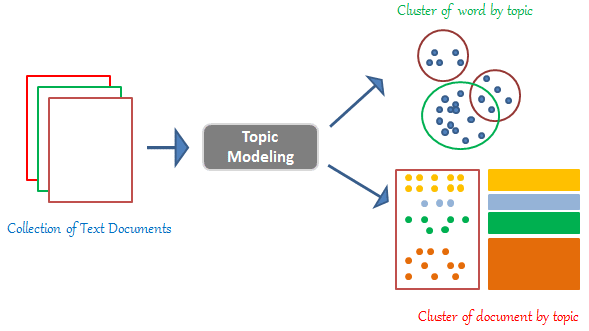
#36
★★★
哪種圖表適合用來視覺化兩個連續變數之間的關係與分佈模式?
答案解析
散佈圖將每個數據點表示為二維座標系中的一個點,其中橫軸和縱軸分別代表兩個連續變數的值。通過觀察點的分佈模式,可以判斷兩個變數之間是否存在線性關係、非線性關係、聚集模式或異常值等。長條圖和圓餅圖用於類別變數。直方圖用於視覺化單一連續變數的頻率分佈。
#37
★★★★
下列哪一種方法屬於集成學習 (Ensemble Learning) 的範疇,透過結合多個決策樹來提高預測性能?
答案解析
集成學習是一種結合多個學習器(通常稱為基學習器 Base Learner)的預測結果來獲得比單一學習器更好性能的技術。隨機森林就是一種基於決策樹的集成學習方法,它通過構建多棵決策樹(每棵樹在隨機選擇的數據子集和特徵子集上訓練),並將它們的預測結果進行投票(分類)或平均(迴歸)來得到最終預測。這通常能有效降低模型的變異數,提高穩定性和準確性。常見的集成方法還包括 Bagging、Boosting (如 AdaBoost, Gradient Boosting)。
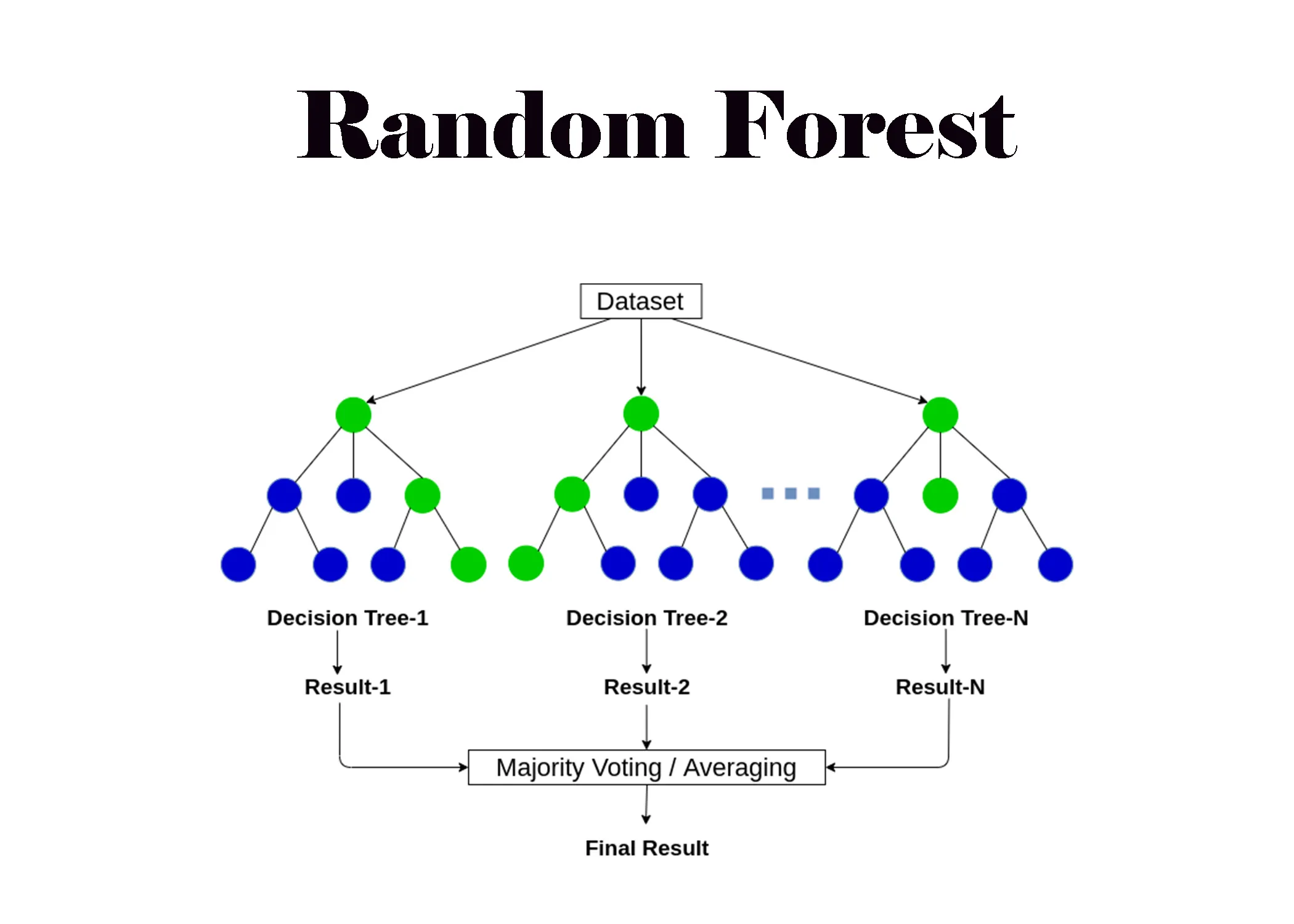
#38
★★★
在關聯規則 "牛奶 → 麵包 [支持度=20%, 信賴度=70%]" 中,70% 的信賴度代表什麼意義?
答案解析
信賴度 (Confidence)衡量的是規則的可靠性。對於規則 X → Y,信賴度表示包含了 X 的交易中,同時也包含 Y 的比例。因此,Confidence(牛奶 → 麵包) = 70% 意味著在所有購買了牛奶的交易記錄裡,有 70% 的交易也包含了麵包。支持度 20% 則表示所有交易中有 20% 同時包含了牛奶和麵包。
#39
★★
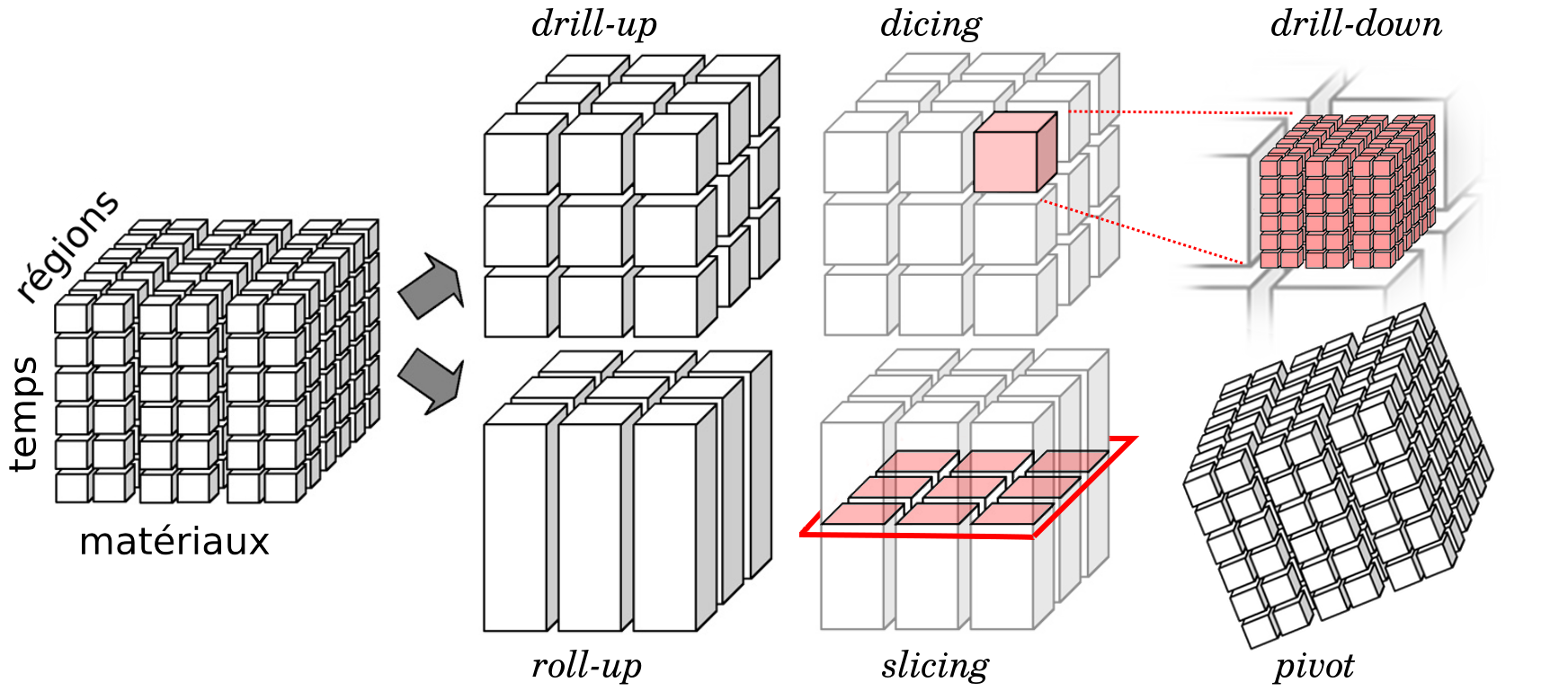
"向下鑽探" (Drill-down) 是數據分析中的一種常用操作,其主要目的是?
答案解析
向下鑽探是診斷性分析和數據探索中常用的互動技術。當使用者在儀表板或報表中看到一個匯總的指標(例如,某地區的總銷售額)時,可以通過向下鑽探操作,查看構成該匯總值的更細粒度的數據(例如,該地區各個城市的銷售額,或某個城市的各產品類別銷售額),以便更深入地了解情況或找出異常的原因。相對的操作是「向上彙總」(Roll-up)。
#40
★★★
下列哪一項不是大數據處理中常用的技術或框架?
答案解析
Apache Hadoop (包含 HDFS 和 MapReduce) 和 Apache Spark 是處理大規模數據集的分散式運算框架。NoSQL (Not Only SQL) 數據庫是設計用來處理大量、多樣化數據的非關聯式數據庫。這些都是大數據生態系統中的常用工具。Microsoft Word 是文書處理軟體,與大數據處理技術無關。
#41
★★★
邏輯迴歸 (Logistic Regression) 主要用於解決哪種類型的問題?
答案解析
儘管名稱中有「迴歸」,但邏輯迴歸實際上是一種廣泛用於二元分類問題的監督式學習演算法。它通過 Sigmoid 函數將線性迴歸的輸出映射到 (0, 1) 區間,表示樣本屬於正類的機率。根據這個機率和一個閾值(通常是 0.5),可以將樣本分類為正類或負類。它也可以擴展到多元分類問題(Multinomial Logistic Regression)。
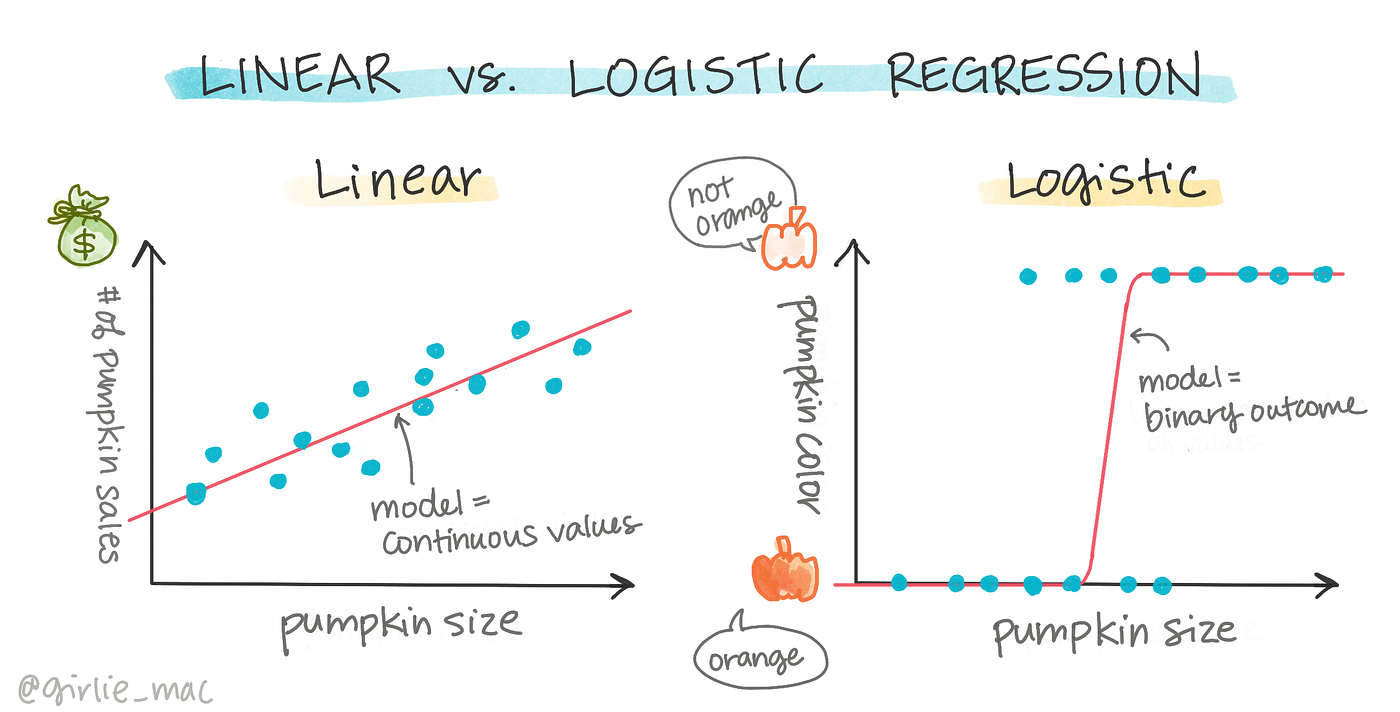
#42
★★
計算網站每日獨立訪客數 (Daily Unique Visitors) 屬於哪種分析活動?
答案解析
計算和報告網站的關鍵績效指標 (Key Performance Indicators, KPIs),如每日獨立訪客數、頁面瀏覽量、跳出率等,是描述性分析的核心工作。這些指標總結了過去的網站活動情況,回答了「發生了什麼?」的問題。
#43
★★★★
DBSCAN 演算法在哪種情況下相較於 K-means 可能表現更好?
答案解析
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 是一種基於密度的分群演算法。它的優點在於:
1. 不需要預先指定群集數量 K。
2. 能夠發現任意形狀的群集(K-means 假設群集是凸形的,通常是球狀)。
3. 能夠識別並標記出雜訊點(離群值),這些點不屬於任何群集。
因此,當群集形狀不規則或數據中存在雜訊時,DBSCAN 通常比 K-means 更適用。K-means 在群集呈球狀且 K 已知時效果較好。高維數據可能對兩者都帶來挑戰(維度災難)。階層式分群用於產生階層結構。
1. 不需要預先指定群集數量 K。
2. 能夠發現任意形狀的群集(K-means 假設群集是凸形的,通常是球狀)。
3. 能夠識別並標記出雜訊點(離群值),這些點不屬於任何群集。
因此,當群集形狀不規則或數據中存在雜訊時,DBSCAN 通常比 K-means 更適用。K-means 在群集呈球狀且 K 已知時效果較好。高維數據可能對兩者都帶來挑戰(維度災難)。階層式分群用於產生階層結構。

#44
★★★
在預測模型中,特徵工程 (Feature Engineering) 的主要目的是什麼?
答案解析
特徵工程是利用領域知識和數據分析技術,從原始數據中提取、構建或轉換出對預測目標更有用的特徵(輸入變數)的過程。好的特徵能夠更有效地捕捉數據中的模式,從而顯著提升機器學習模型的性能。這可能包括創建交互項、多項式特徵、對數轉換、處理日期時間特徵、文本特徵提取等。選擇演算法、調整超參數和評估模型是建模過程中的其他重要步驟。
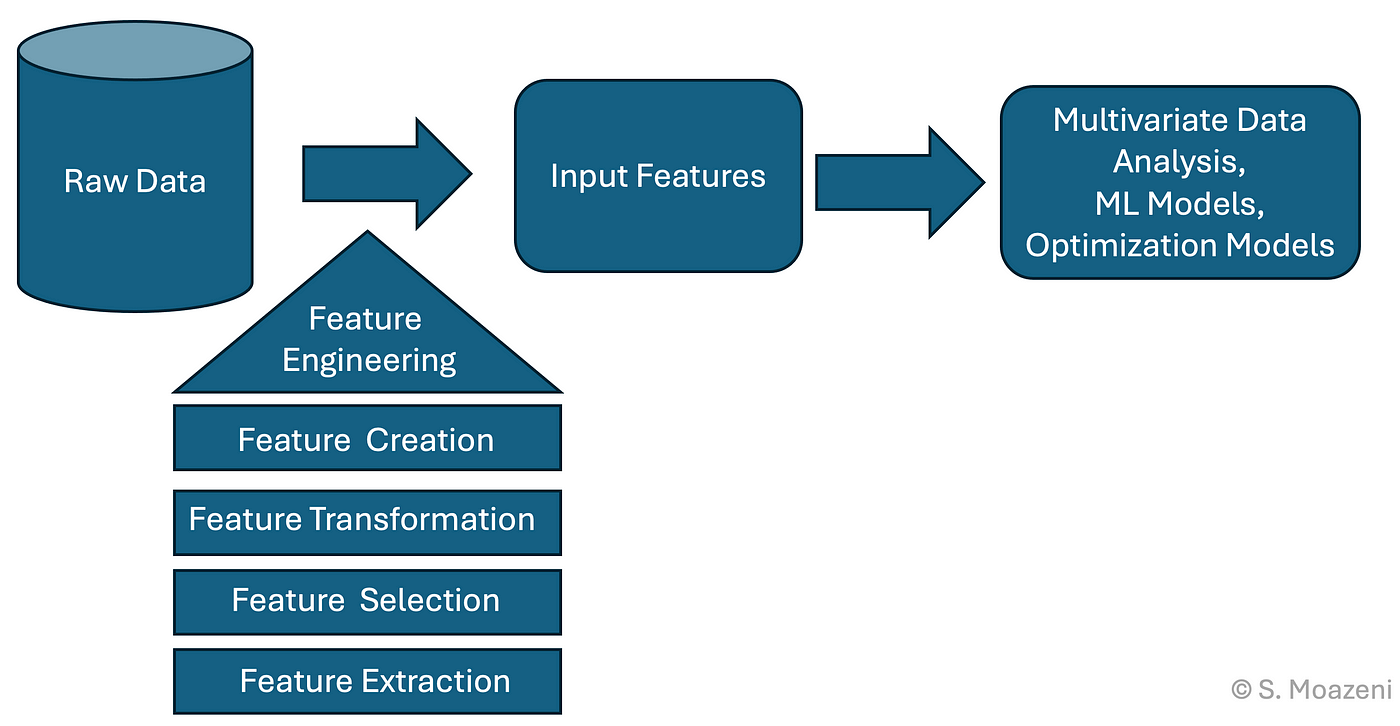
#45
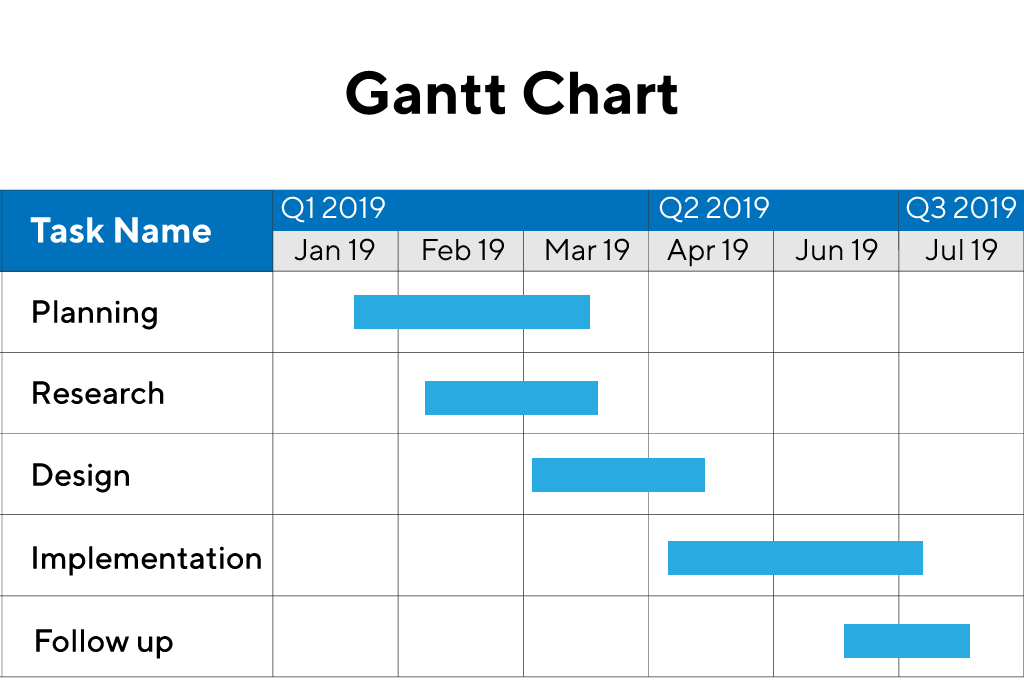
★★
哪種圖形常用來視覺化專案任務的排程與依賴關係?
答案解析
甘特圖是專案管理中常用的一種圖表,它以水平長條圖的形式展示專案的時程計畫。圖表的橫軸代表時間,縱軸列出專案的各項任務。每個長條代表一項任務,其起點和終點對應任務的開始和結束時間,長度表示任務的持續時間。甘特圖可以清晰地顯示任務的排程、進度以及任務之間的依賴關係。
#46
★★★★
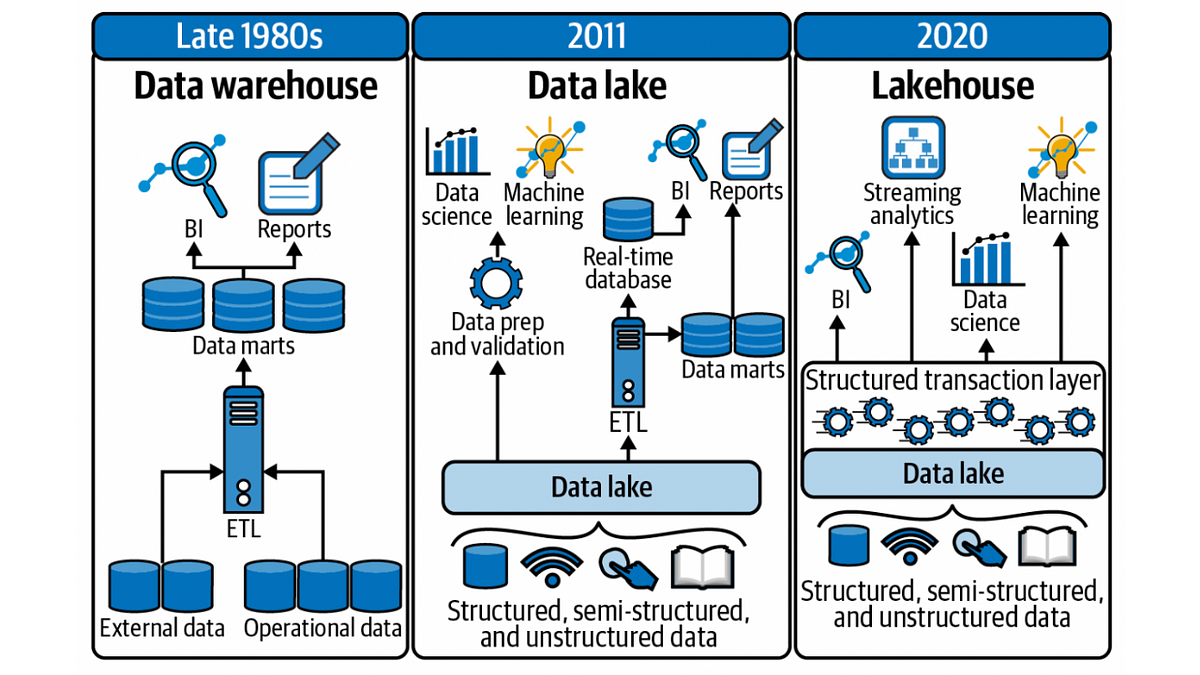
資料倉儲 (Data Warehouse) 與資料湖 (Data Lake) 的主要區別在於?
答案解析
資料倉儲和資料湖都是用於儲存大量數據的架構,但設計理念和用途不同:
資料倉儲 (Data Warehouse): 主要儲存來自不同營運系統、經過清洗、轉換和整合後的結構化數據。數據在寫入前就需要定義好綱要 (Schema-on-Write),主要目的是支持商業智慧 (Business Intelligence, BI) 報表和分析。
資料湖 (Data Lake): 可以儲存各種來源的原始數據,包括結構化、半結構化和非結構化數據,無需預先定義綱要。數據的結構和意義在讀取時才被賦予 (Schema-on-Read)。它提供了更大的靈活性,適合數據探索、機器學習等需要處理原始數據的場景。
選項 B 準確描述了這個核心差異。
資料倉儲 (Data Warehouse): 主要儲存來自不同營運系統、經過清洗、轉換和整合後的結構化數據。數據在寫入前就需要定義好綱要 (Schema-on-Write),主要目的是支持商業智慧 (Business Intelligence, BI) 報表和分析。
資料湖 (Data Lake): 可以儲存各種來源的原始數據,包括結構化、半結構化和非結構化數據,無需預先定義綱要。數據的結構和意義在讀取時才被賦予 (Schema-on-Read)。它提供了更大的靈活性,適合數據探索、機器學習等需要處理原始數據的場景。
選項 B 準確描述了這個核心差異。
#47
★★★
當分析師想要比較同一個班級學生在期中考和期末考成績是否有顯著進步時,應使用哪種統計檢定?
答案解析
這個情況下,比較的是「同一個」班級的學生在兩個不同時間點(期中考和期末考)的成績。由於比較的對象是同一群人,兩次測量的結果是相關的、非獨立的,因此應該使用配對樣本 t 檢定 (Paired Samples t-test) 來分析平均分數是否有顯著差異。獨立樣本 t 檢定用於比較兩個不同組別。單一樣本 t 檢定用於比較一組樣本的平均數與一個已知的總體平均數。ANOVA 用於比較三組或更多組。
#48
★★★
為了避免決策樹模型過度擬合,可以採取的常用方法不包含下列哪一項?
答案解析
防止決策樹過度擬合的常用方法(也稱為正則化 Regularization 技術)包括:
限制樹的最大深度:控制樹的生長複雜度。
設定節點分裂所需的最小樣本數:避免對少量樣本進行分裂。
設定葉節點所需的最小樣本數 (Min Samples Leaf): 確保每個葉節點包含足夠多的樣本。
剪枝 (Pruning):在樹完全生長後,移除一些對泛化能力貢獻不大的分支(後剪枝),或在生長過程中提前停止(預剪枝)。
增加每次分裂時考慮的最大特徵數 (Max Features) 反而可能增加模型的複雜度和過擬合風險(特別是如果設為全部特徵),限制特徵數(例如,設為總特徵數的平方根)是隨機森林中用於增加樹之間差異性、降低過擬合的方法。
限制樹的最大深度:控制樹的生長複雜度。
設定節點分裂所需的最小樣本數:避免對少量樣本進行分裂。
設定葉節點所需的最小樣本數 (Min Samples Leaf): 確保每個葉節點包含足夠多的樣本。
剪枝 (Pruning):在樹完全生長後,移除一些對泛化能力貢獻不大的分支(後剪枝),或在生長過程中提前停止(預剪枝)。
增加每次分裂時考慮的最大特徵數 (Max Features) 反而可能增加模型的複雜度和過擬合風險(特別是如果設為全部特徵),限制特徵數(例如,設為總特徵數的平方根)是隨機森林中用於增加樹之間差異性、降低過擬合的方法。
#49
★★
主成分分析 (PCA) 尋找的是數據中具有最大什麼特性的方向?
答案解析
主成分分析 (Principal Component Analysis, PCA) 是一種線性降維技術。它的核心思想是找到一組新的正交基(稱為主成分),使得數據在這些基上的投影具有最大的變異數。第一個主成分是數據變異最大的方向,第二個主成分是與第一個主成分正交且變異次大的方向,依此類推。通過保留前幾個變異數最大的主成分,可以在損失少量資訊的情況下顯著降低數據維度。
#50
★★★
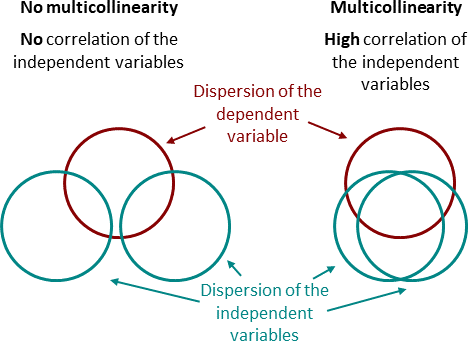
下列哪項是對「共線性」(Collinearity) 或「多重共線性」(Multicollinearity) 問題的正確描述?
答案解析
共線性(通常指兩個特徵間)或多重共線性(指多個特徵間)是指在迴歸模型(尤其是線性迴歸)的輸入特徵(自變數)之間存在高度線性相關的現象。這會導致問題,例如:
難以區分個別特徵對目標變數的獨立影響。
迴歸係數的估計變得不穩定,標準誤增大。
模型的解釋性下降。
雖然我們希望輸入特徵與輸出目標相關(選項 A),但輸入特徵之間的高度相關(選項 B)則是有問題的。殘差相關(選項 C)是另一個問題,稱為自相關 (Autocorrelation),常見於時間序列數據。
難以區分個別特徵對目標變數的獨立影響。
迴歸係數的估計變得不穩定,標準誤增大。
模型的解釋性下降。
雖然我們希望輸入特徵與輸出目標相關(選項 A),但輸入特徵之間的高度相關(選項 B)則是有問題的。殘差相關(選項 C)是另一個問題,稱為自相關 (Autocorrelation),常見於時間序列數據。
沒有找到符合條件的題目。
↑