iPAS AI應用規劃師 考試重點
L22302 常見的大數據分析方法
主題分類
1
大數據分析方法概觀
2
描述性分析 (Descriptive)
3
診斷性分析 (Diagnostic)
4
預測性分析 (Predictive)
5
指示性分析 (Prescriptive)
6
統計方法應用
7
機器學習方法應用
8
特定數據類型分析
#1
★★★★★
大數據分析方法的層次
核心概念
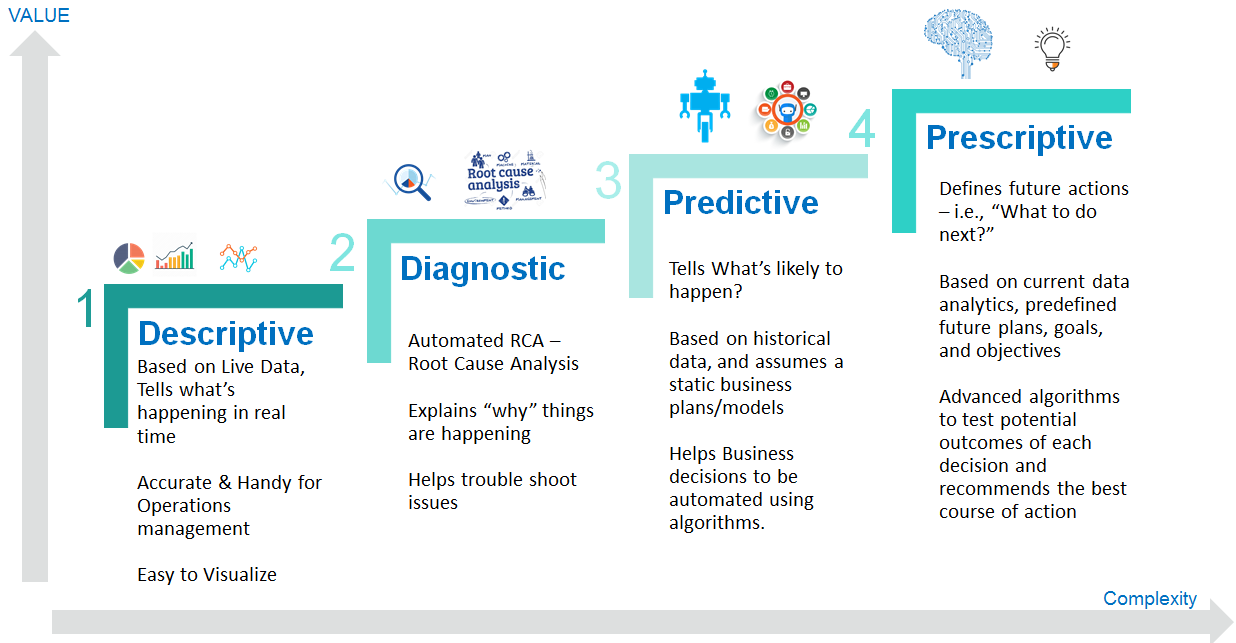
常見將大數據分析分為四個主要層次,從描述過去到指導未來:
- 描述性分析 (Descriptive Analytics): 發生了什麼?
- 診斷性分析 (Diagnostic Analytics): 為什麼發生?
- 預測性分析 (Predictive Analytics): 將會發生什麼?
- 指示性分析 (Prescriptive Analytics): 應該做什麼?
#2
★★★★
大數據分析與傳統數據分析的區別
核心區別
主要區別在於處理的數據規模、速度和多樣性。大數據分析通常需要:
- 可擴展的儲存和計算技術(如分散式系統)。
- 處理非結構化和半結構化數據的能力。
- 更複雜的機器學習演算法來處理高維度和大規模數據。
- 更關注即時或近即時的分析能力。
#3
★★★
數據分析流程 (Data Analysis Process)
典型步驟 (參考 L11202)
一個典型的數據分析項目流程包括:
- 問題定義:明確分析的目標和要回答的問題。
- 數據收集:從各種來源獲取所需數據。
- 數據清理與預處理:處理缺失值、異常值、不一致,轉換數據格式。
- 探索性數據分析 (EDA):使用統計和可視化方法理解數據特性。
- 模型建立與分析:應用統計或機器學習方法進行分析或預測。
- 結果解釋與呈現:將分析結果轉化為洞見並進行溝通。
- 部署與監控(如果適用)。
#4
★★★★
描述性分析 (Descriptive Analytics) - 目標與方法 (參考 L22101)
核心概念
目標是總結和描述過去發生的情況,回答「發生了什麼?」的問題。這是最基礎的分析層次。常用方法包括:
- 計算基本統計量:如平均值、中位數、眾數、標準差 (樣題 Q6)、最小值、最大值、頻率等。
- 製作報表和儀表板。
- 使用數據可視化圖表(長條圖、折線圖、圓餅圖等)展示數據。
#5
★★★★
描述性統計量:集中趨勢 (Central Tendency)
常用指標
衡量數據中心位置的指標:
- 平均數 (Mean): 數據總和除以個數,易受極端值影響。
- 中位數 (Median): 將數據排序後位於中間位置的值,對極端值不敏感。(樣題 Q6 選項 D 提及)
- 眾數 (Mode): 數據中出現次數最多的值。
#6
★★★★
描述性統計量:離散趨勢 (Dispersion / Variability) (參考樣題 Q6)
常用指標
衡量數據分散程度的指標:
- 全距 (Range): 最大值減最小值。
- 變異數 (Variance): 數據點與平均值之差的平方的平均值。
- 標準差 (Standard Deviation): 變異數的平方根,量綱與原始數據相同。標準差越大,表示數據越分散,波動越大。(樣題 Q6)
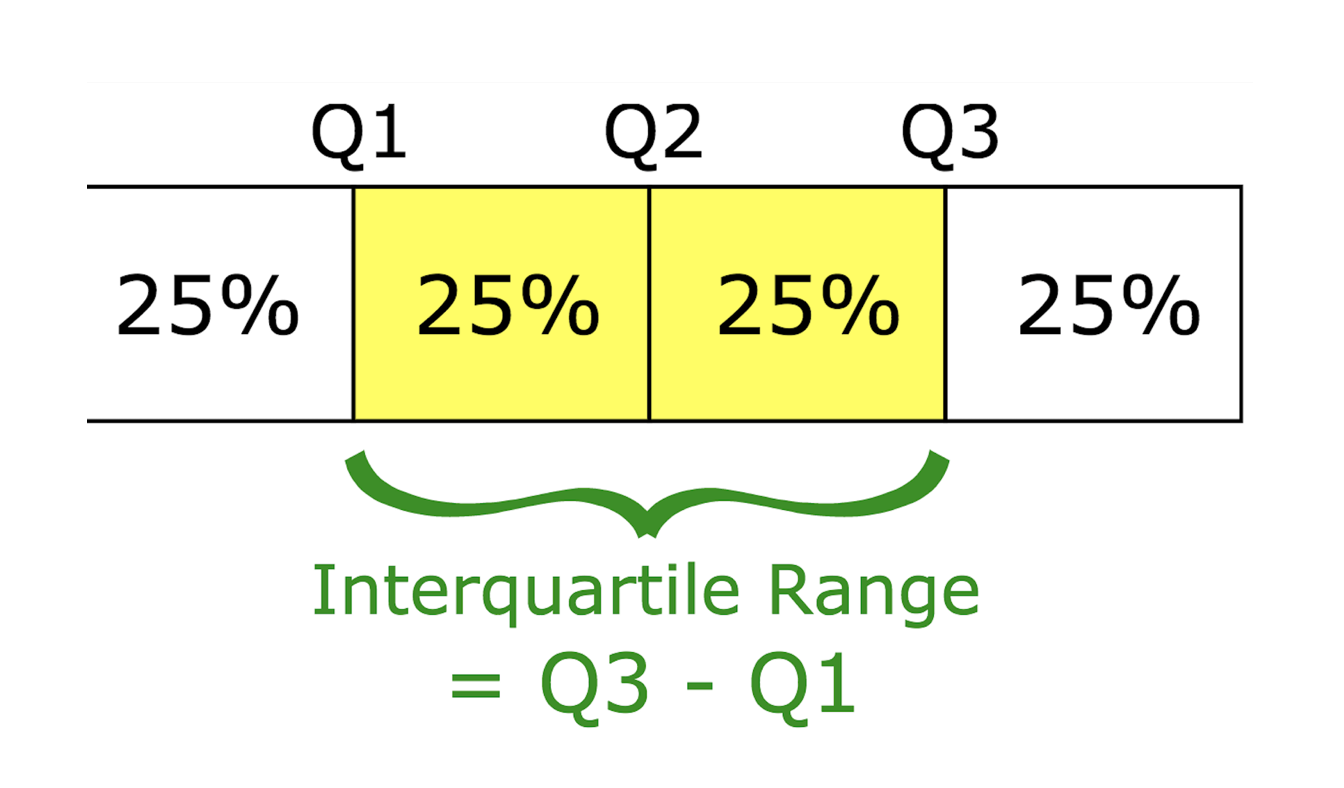
- 四分位距 (IQR, Interquartile Range): Q3 減 Q1,衡量中間 50% 數據的離散程度。


#7
★★★
數據分佈的視覺化 (直方圖、箱形圖)
可視化方法 (參考 L22303)
描述性分析常用可視化來展示數據分佈:
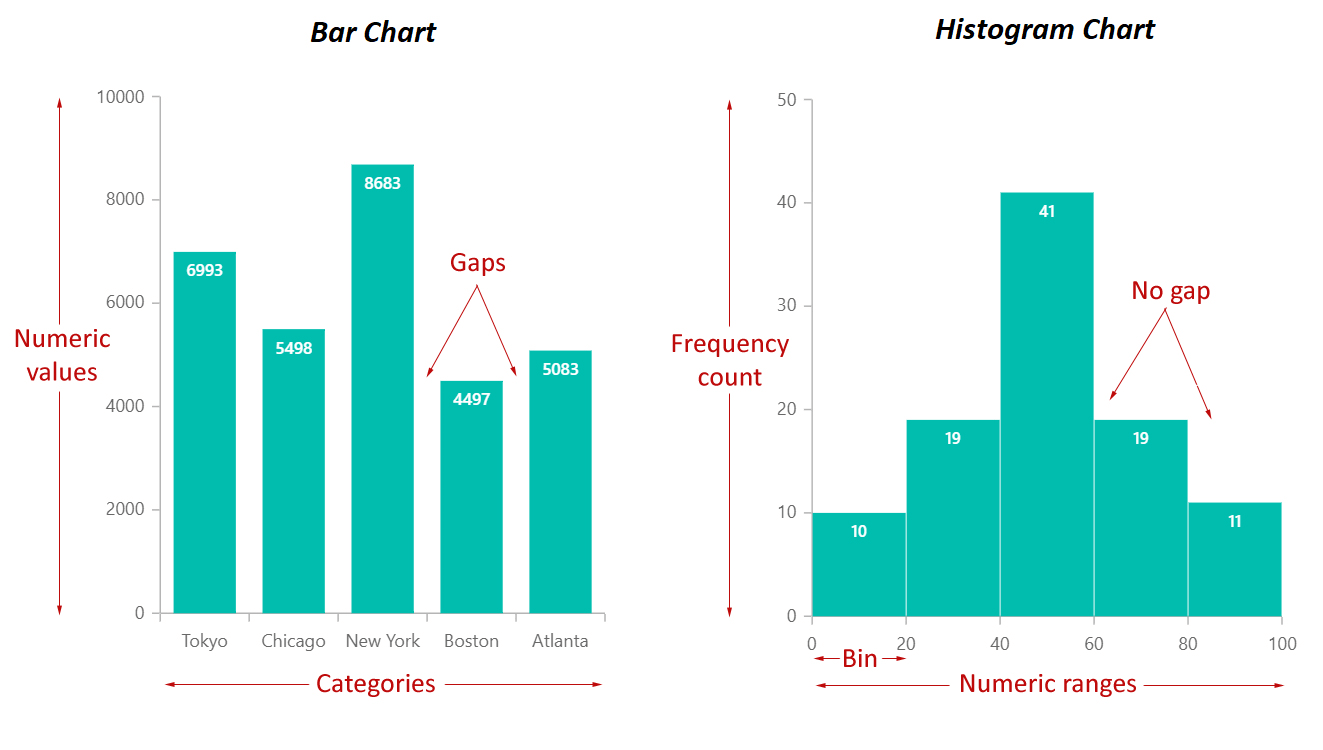
- 直方圖 (Histogram): 展示單個連續變數的頻率分佈。
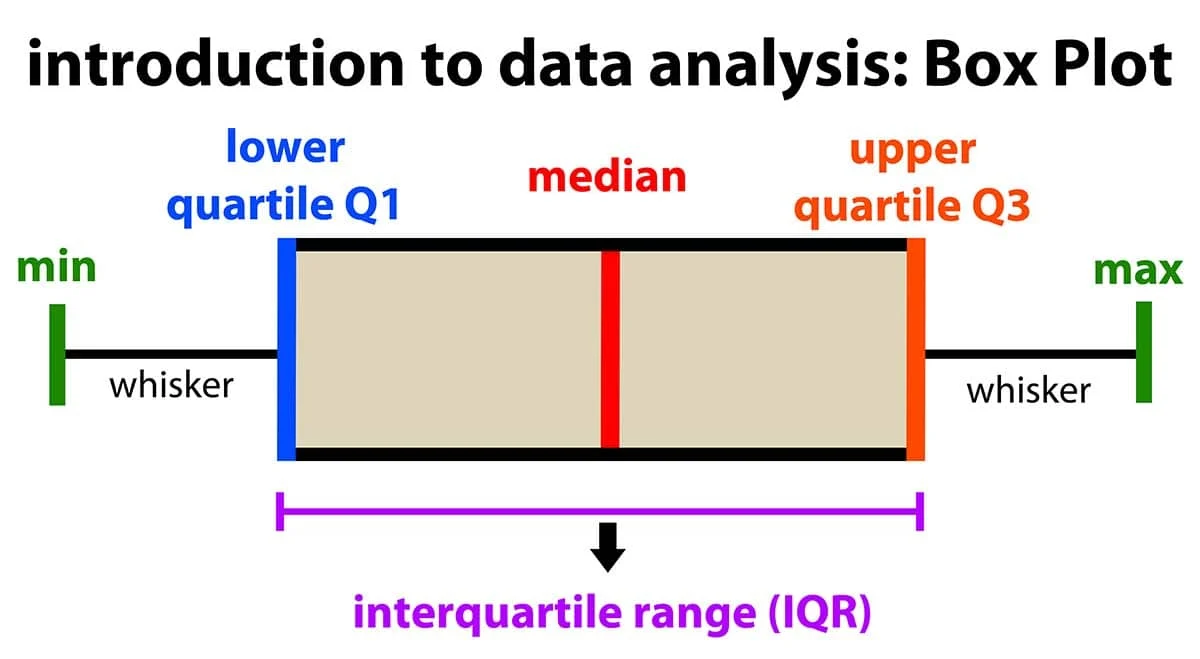
- 箱形圖 (Box Plot): 展示數據的五數摘要和離群值。
- 密度圖 (Density Plot): 直方圖的平滑版本。

#8
★★★
診斷性分析 (Diagnostic Analytics) - 目標與方法
核心概念
目標是深入探究數據以理解事件發生的原因,回答「為什麼發生?」的問題。通常在描述性分析之後進行。常用方法包括:
- 下鑽分析 (Drill-down): 從概覽數據深入到更詳細的層級。
- 數據挖掘 (Data Mining): 發現數據中的關聯或模式。
- 相關性分析 (Correlation Analysis): 找出變數之間的關係(注意相關不等於因果)。
- 根本原因分析 (Root Cause Analysis)。
#9
★★★
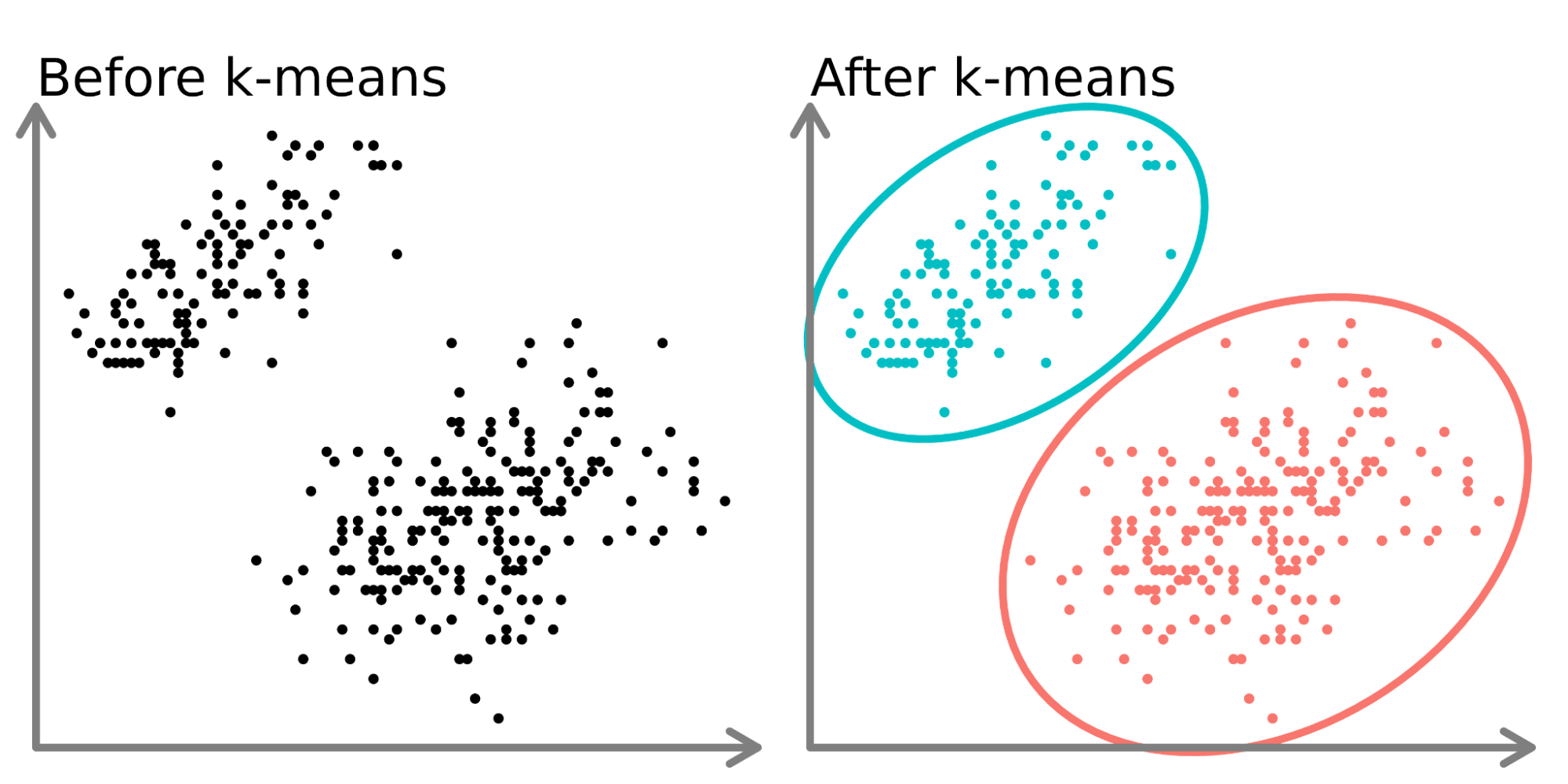
診斷性分析中的分群 (Clustering) 應用
應用方法
分群演算法(如 K-Means)可以將具有相似特徵的數據點分組,有助於識別不同的客戶群體、異常模式或潛在的細分市場,從而為「為什麼某些群體表現不同」提供線索。
#10
★★★
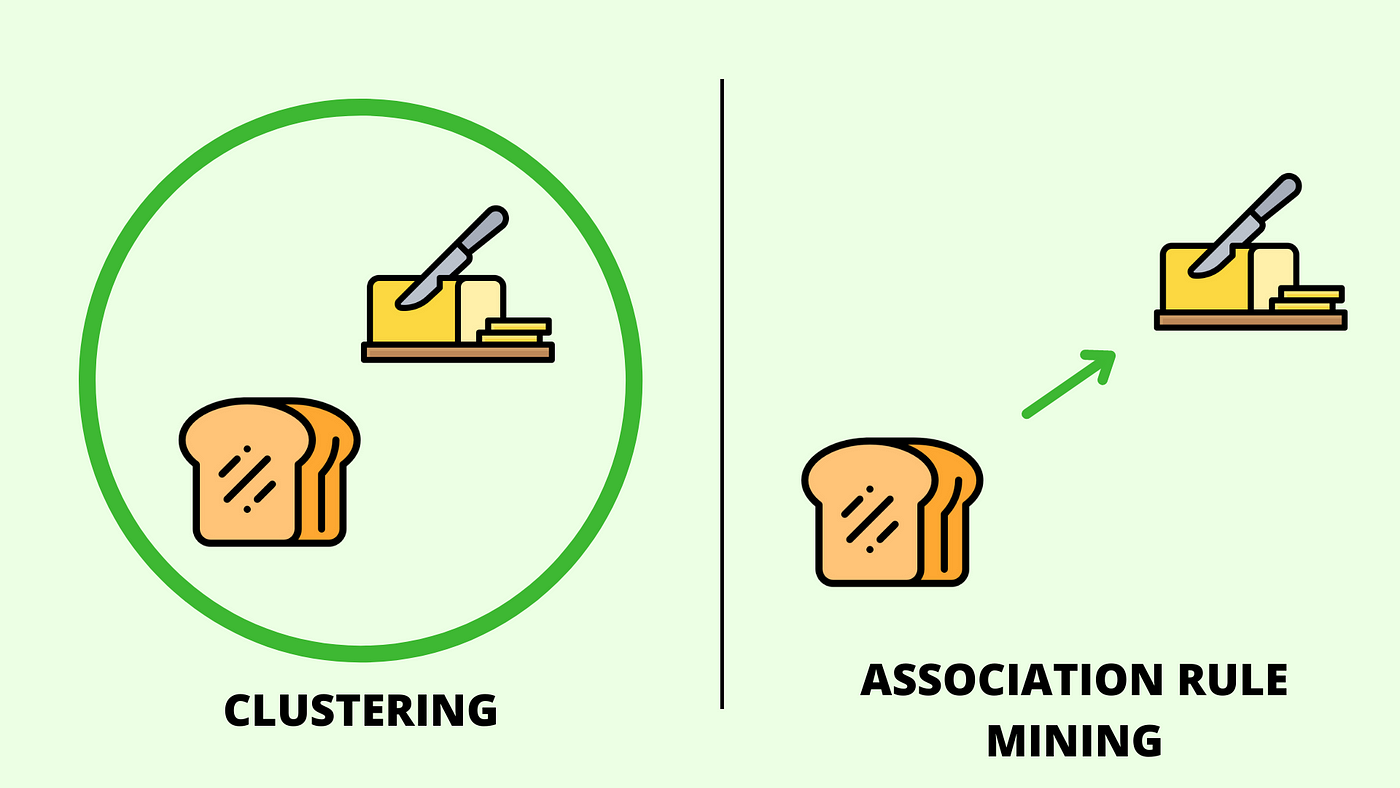
診斷性分析中的關聯規則 (Association Rules) 應用
應用方法
透過挖掘數據項之間的共現關係(例如,「購買 A 的人中有 70% 也購買了 B」),可以發現潛在的行為模式或驅動因素,例如市場籃分析中的商品關聯,有助於解釋某些購買行為的原因。
#11
★★★★★
預測性分析 (Predictive Analytics) - 目標與方法 (參考樣題 Q8, Q9)
核心概念
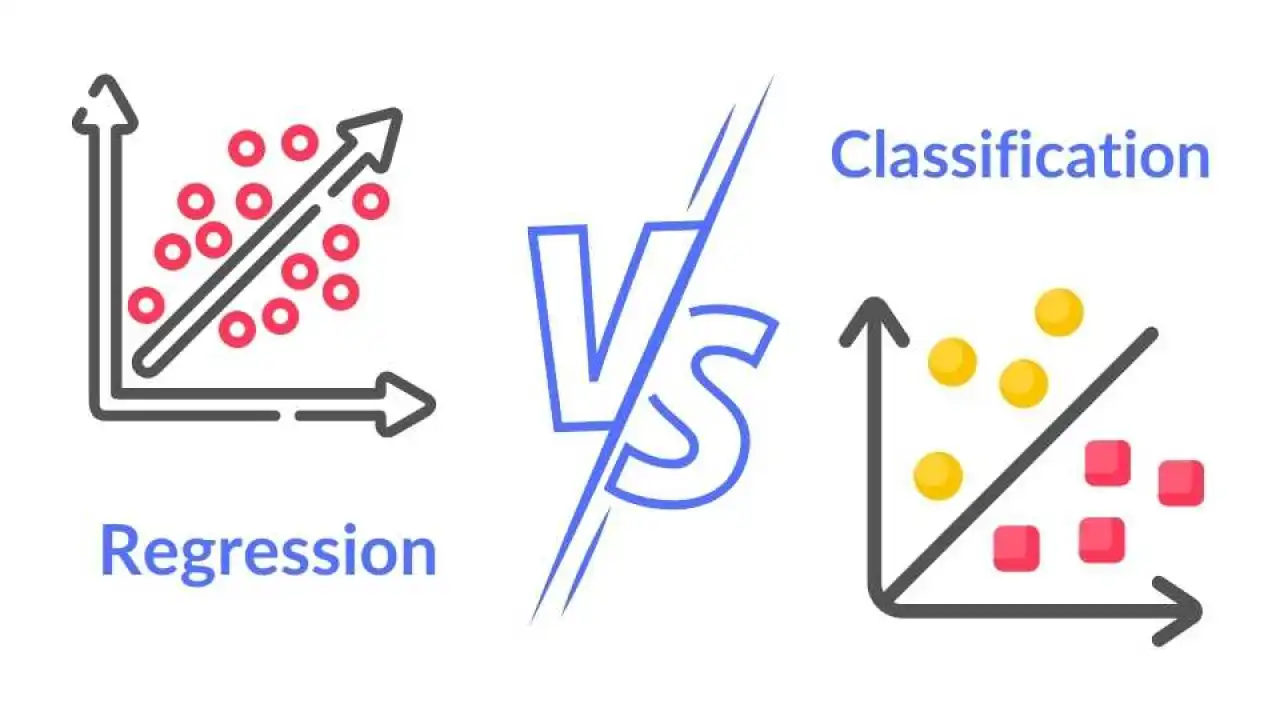
目標是利用歷史數據來預測未來可能發生的事件或結果,回答「將會發生什麼?」的問題。這是機器學習(特別是監督式學習)的主要應用領域。常用方法包括:
- 迴歸分析 (Regression Analysis): 預測連續值(如銷售額、房價)。(樣題 Q8)
- 分類分析 (Classification Analysis): 預測離散類別(如客戶是否流失、郵件是否垃圾)。(樣題 Q9 選項)
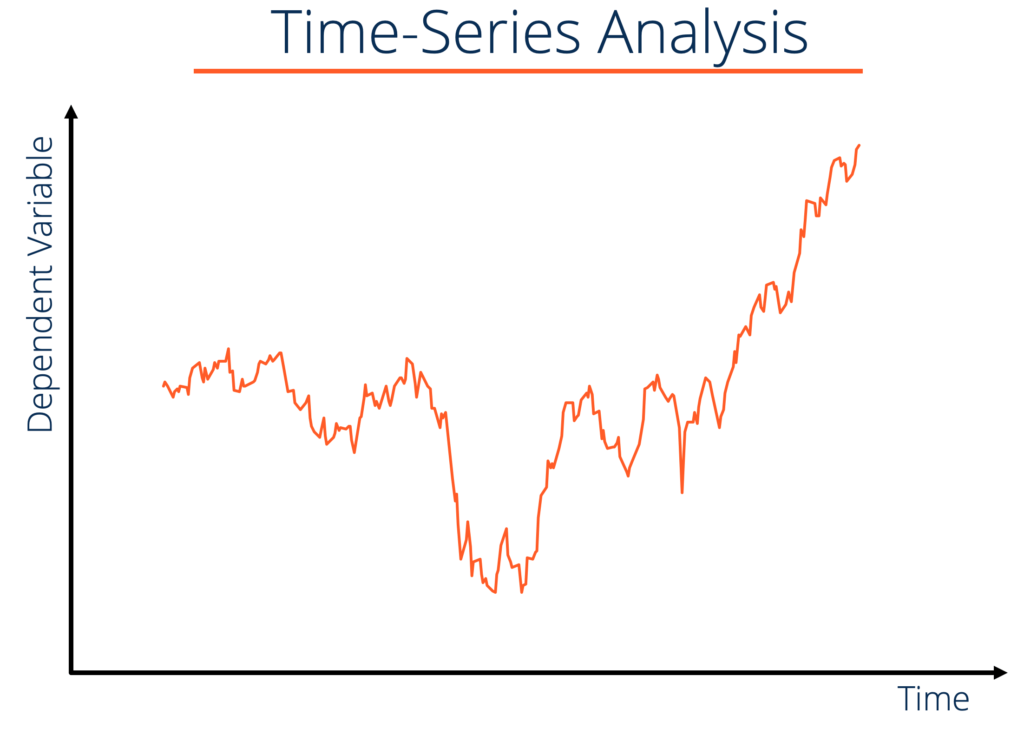
- 時間序列分析 (Time Series Analysis): 預測未來時間點的值。
#12
★★★★
預測性分析常用演算法:迴歸 (線性, 邏輯, 樹模型等)
常用演算法
如線性迴歸、邏輯迴歸、支持向量機 (SVM)、決策樹、隨機森林、梯度提升樹 (GBDT)、神經網路等監督式學習演算法常用於預測性分析。(參考 L23202)
#13
★★★
預測性分析中的模型評估
關鍵步驟
需要使用獨立的測試數據和合適的評估指標(如分類的準確率、AUC;迴歸的 RMSE、R²)來評估預測模型的準確性和泛化能力。(參考 L23303)
#14
★★★★
指示性分析 (Prescriptive Analytics) - 目標與方法

核心概念
目標是基於預測性分析的結果,建議應該採取什麼行動以達到最佳結果或目標,回答「我們應該做什麼?」的問題。這是最高級、最具價值的分析層次。常用方法包括:
- 優化 (Optimization): 在約束條件下尋找最佳決策方案。
- 模擬 (Simulation): 評估不同行動方案可能產生的結果。
- 決策分析 (Decision Analysis) / 規則引擎 (Rule Engine)。
- 強化學習 (RL) 也可以看作是尋找最佳行動策略的方法。
#15
★★★
指示性分析與預測性分析的關係
關係
指示性分析通常建立在預測性分析的基礎之上。預測模型提供了對未來可能性的預計,而指示性分析則利用這些預測結果來推薦最優的行動方案。例如,預測客戶流失風險後,指示性分析可以建議針對高風險客戶採取哪種挽留措施最有效。
#16
★★★★
假設檢定 (Hypothesis Testing) 在大數據分析中的應用 (參考 L22103)
統計方法
用於判斷觀察到的數據差異(例如,兩組用戶的點擊率差異)是否具有統計學上的顯著性,而不僅僅是隨機波動。常用於 A/B 測試結果分析、比較不同策略的效果等。在大數據背景下,需要注意樣本量對 p 值的影響以及多重比較問題。
#17
★★★
A/B 測試 (A/B Testing)
實驗方法
一種對照實驗方法,用於比較兩個版本(A 版本和 B 版本,例如不同的網頁設計、推薦算法)的效果差異。將用戶隨機分配到不同組,收集數據並使用統計檢定分析結果。是驗證改進效果的常用方法。
#18
★★★
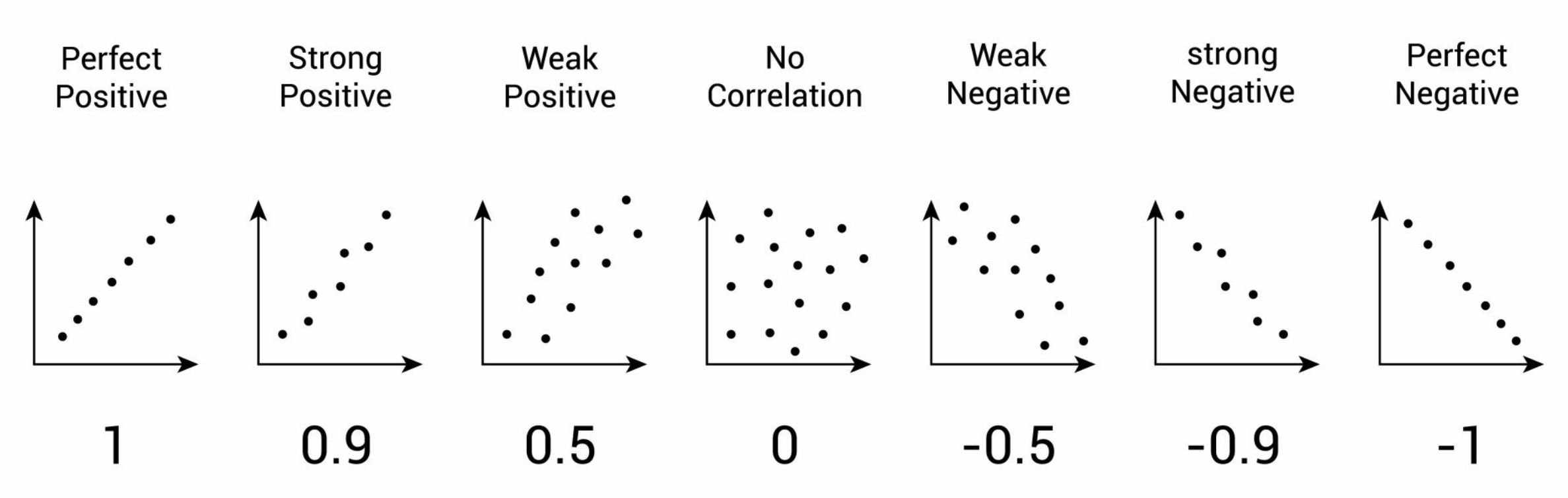
相關性分析 (Correlation Analysis)
統計方法
衡量兩個數值變數之間線性關係的強度和方向。常用指標是皮爾森相關係數 (Pearson Correlation Coefficient),值域為 [-1, 1]。需要注意相關性不等於因果性。
#19
★★
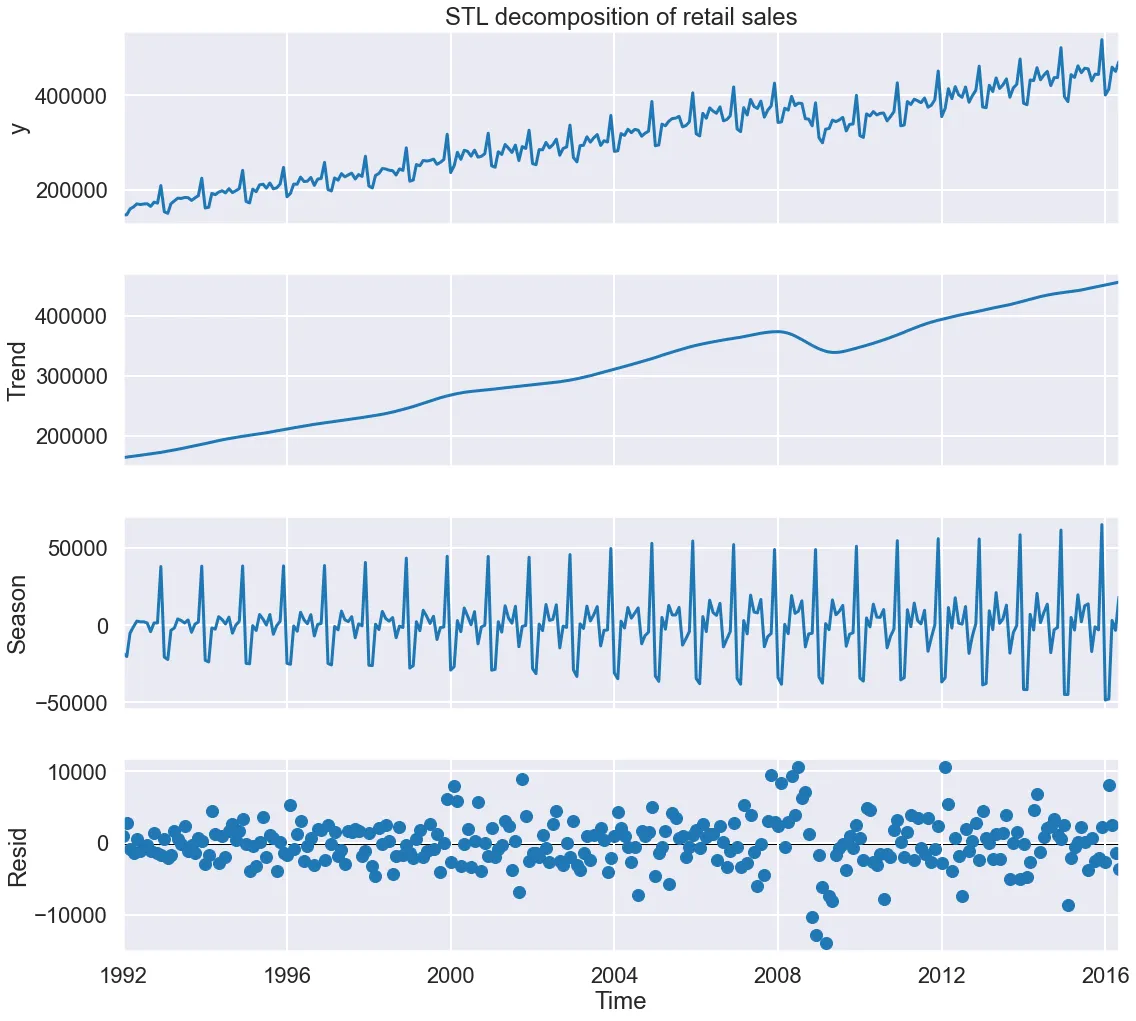
時間序列分解 (Time Series Decomposition)
統計方法
將時間序列數據分解為幾個組成部分:趨勢 (Trend)、季節性 (Seasonality) 和殘差 (Residual)。有助於理解時間序列的模式並用於預測。
#20
★★★★
迴歸分析 (Regression Analysis) 作為預測方法
ML 方法
使用各種迴歸模型(線性、多項式、樹模型、SVM、神經網路等)來學習輸入特徵與連續目標變數之間的關係,並進行預測。
#21
★★★★
分類分析 (Classification Analysis) 作為預測方法
ML 方法
使用各種分類模型(邏輯迴歸、SVM、決策樹、隨機森林、樸素貝氏、神經網路等)來學習輸入特徵與離散目標類別之間的關係,並預測新樣本的類別。
#22
★★★★
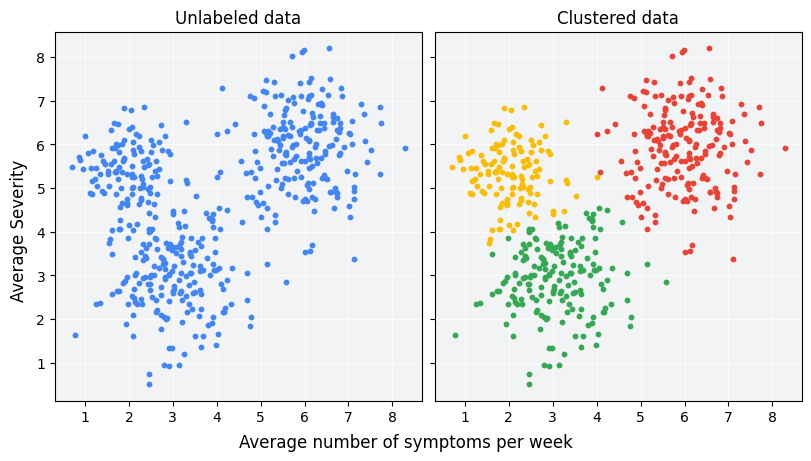
分群分析 (Cluster Analysis) 作為探索/診斷方法 (參考樣題 Q5)
ML 方法
使用分群演算法(K-Means, 階層式, DBSCAN 等)自動發現數據中的自然群組。常用於客戶區隔、異常檢測、模式識別等探索性和診斷性分析任務。樣題 Q5 考查 K-Means。
#23
★★★
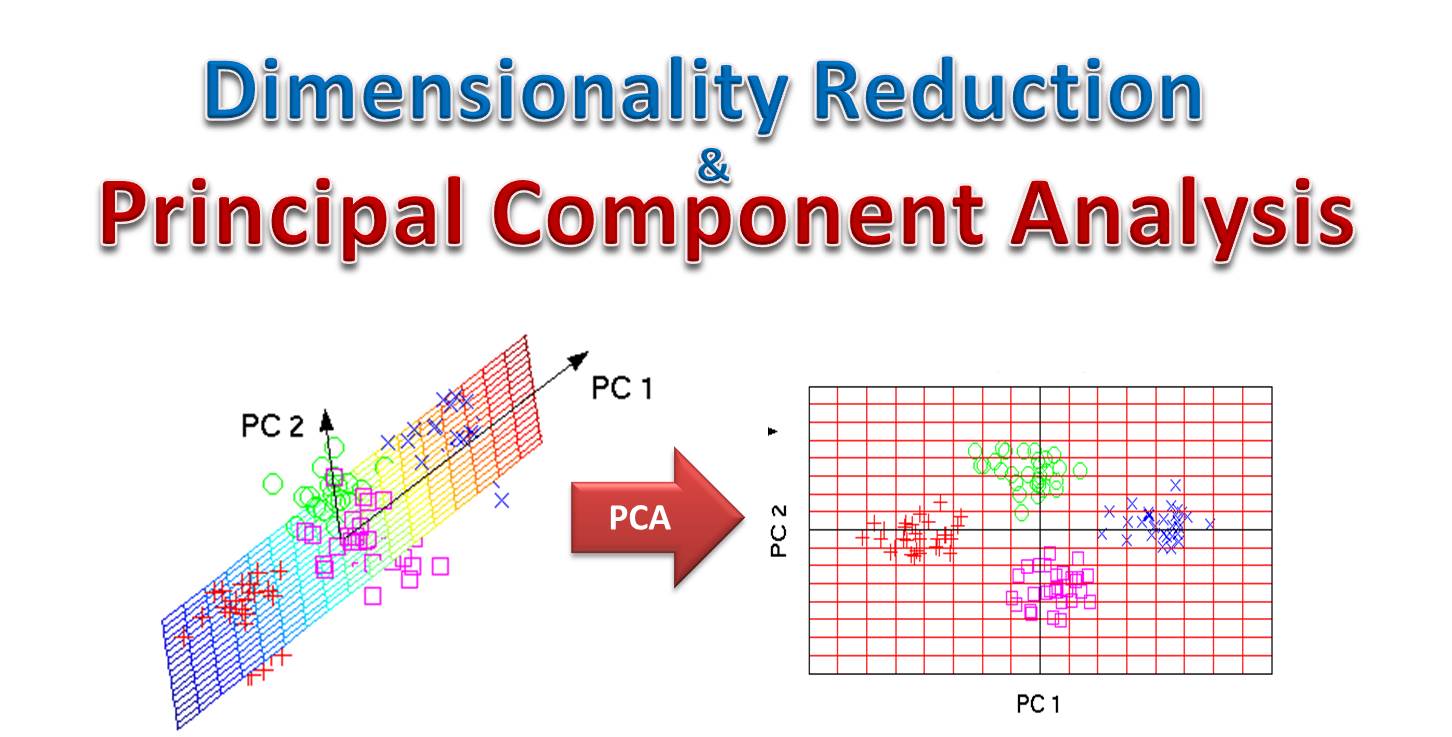
降維 (Dimensionality Reduction) 作為預處理/探索方法 (參考樣題 Q10)
ML 方法
使用 PCA, t-SNE 等降維技術減少數據維度,有助於視覺化高維數據、去除冗餘、加速後續模型訓練。樣題 Q10 涉及 PCA。
#24
★★★
文本分析 (Text Analytics) 方法
特定數據分析 (參考樣題 Q7)
分析非結構化文本數據的方法,包括:關鍵詞提取、主題模型 (Topic Modeling, 如 LDA)、情感分析、命名實體識別 (NER) 等。常涉及自然語言處理 (NLP) 技術。樣題 Q7 提及 NLP。
#25
★★
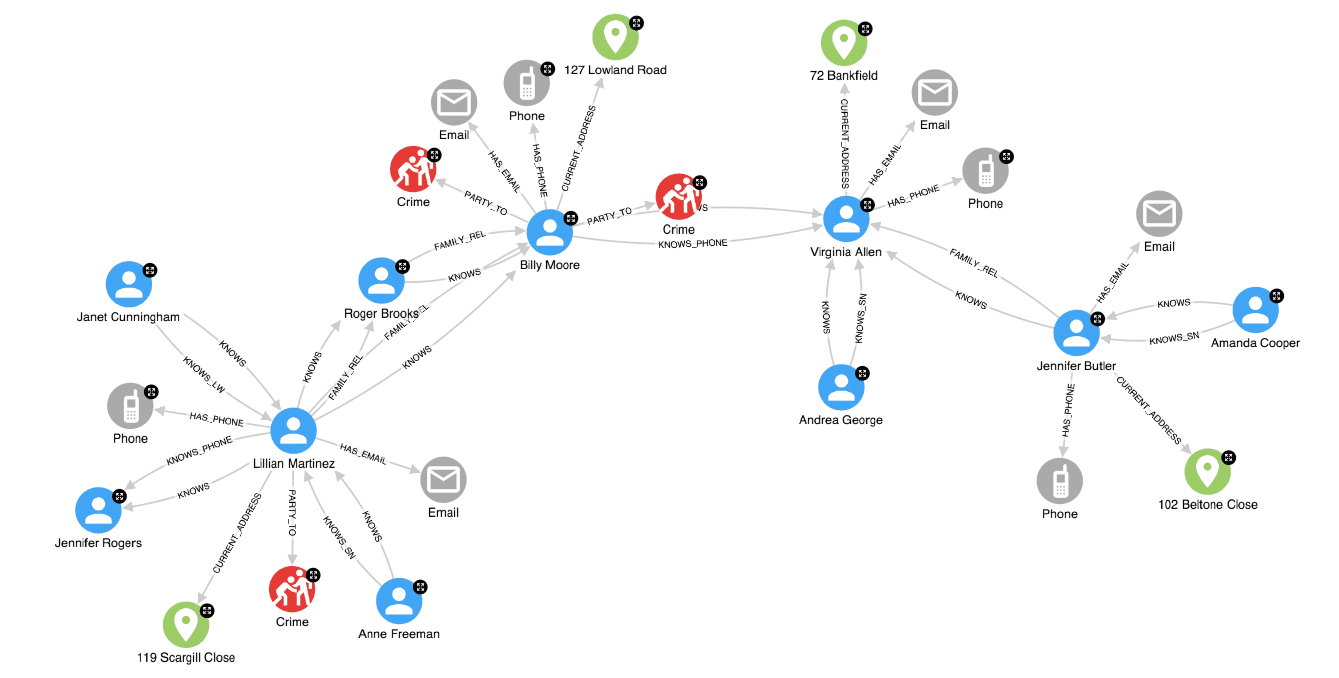
圖分析 (Graph Analytics) 方法
特定數據分析
分析由節點和邊組成的圖結構數據的方法,包括:中心性分析(識別重要節點)、社群偵測 (Community Detection)、連結預測 (Link Prediction)、路徑分析等。應用於社交網路、推薦系統、生物網路等。
#26
★★
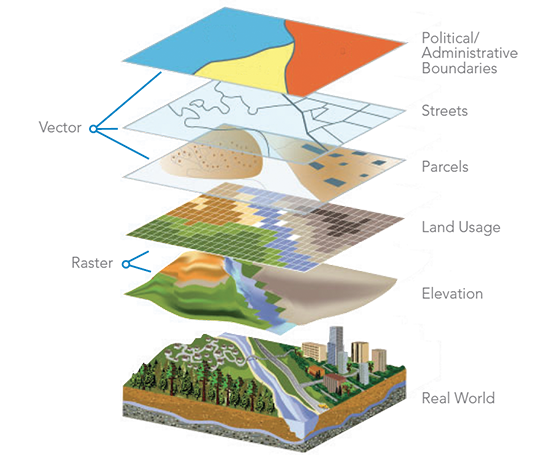
空間數據分析 (Spatial Data Analysis)
特定數據分析
分析帶有地理位置訊息的數據的方法,包括:空間聚類、空間自相關分析、地理加權迴歸 (GWR) 等。用於地理資訊系統 (GIS)、城市規劃、流行病學等。
#27
★★
分析方法的組合應用
實務應用
在實際的大數據分析項目中,通常會組合使用多種分析方法。例如,先用描述性分析了解概況,再用診斷性分析(如分群)找出差異,最後用預測性分析建立模型。
#28
★★
頻率分析 (Frequency Analysis)
描述性分析
統計離散變數(類別)中每個值出現的次數或比例。是描述性分析的基本方法。
#29
★★
異常偵測 (Anomaly Detection / Outlier Detection)
診斷/預測分析
識別數據中與大多數數據顯著不同的模式或數據點。可用於發現錯誤、詐欺行為或罕見事件。可以使用統計方法(如基於標準差)、基於距離的方法(如 DBSCAN)、或監督/半監督學習方法。
#30
★★
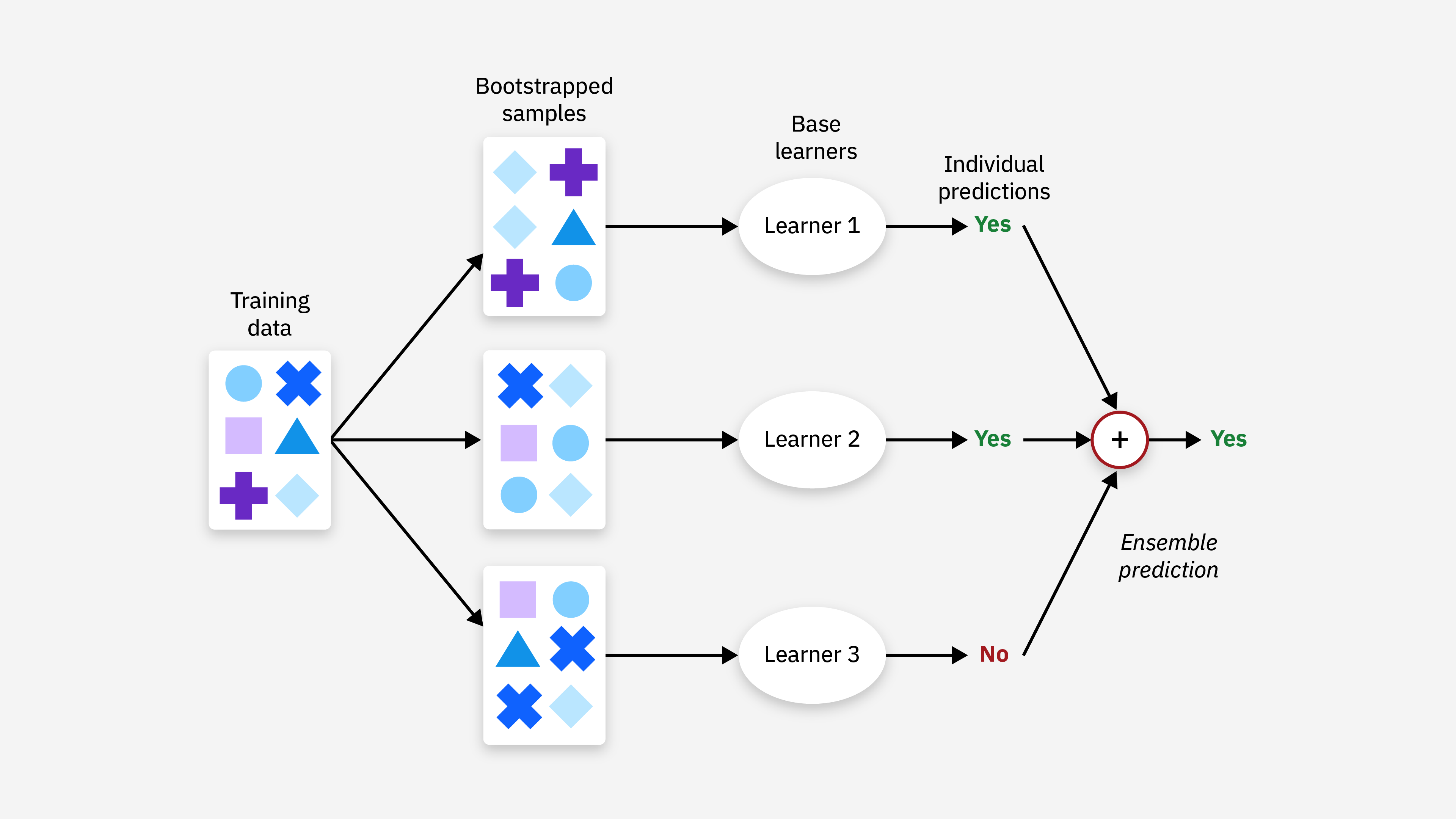
集成學習 (Ensemble Learning) 在預測中的應用
預測方法
集成學習(如隨機森林、GBDT)通常能夠提供比單個模型更準確、更穩健的預測結果,在預測性分析中廣泛應用。
#31
★★
優化技術 (Optimization Techniques)
指示性分析方法
如線性規劃 (Linear Programming)、整數規劃 (Integer Programming)、非線性規劃 (Nonlinear Programming) 等,用於在給定約束條件下尋找使目標函數(如利潤、成本)最優的決策變數值。
#32
★★
抽樣 (Sampling) 技術
統計方法
當無法處理全部大數據時,需要從中抽取代表性樣本進行分析。常用的抽樣方法包括簡單隨機抽樣、分層抽樣、系統抽樣、整群抽樣。
#33
★★
深度學習 (DL) 作為分析方法
ML 方法
深度學習模型(CNN, RNN, Transformer 等)能夠自動從大規模、複雜、非結構化數據中學習特徵和模式,常用於圖像、文本、語音等領域的預測性分析。
#34
★
流數據分析 (Stream Data Analysis)
特定數據分析
處理連續不斷產生的數據流(如感測器數據、交易日誌)的分析方法。需要能夠即時處理、更新模型、檢測異常。常用工具如 Spark Streaming, Flink。
#35
★
數據挖掘 (Data Mining)
相關領域
數據挖掘是指從大量數據中自動發現有用模式和知識的過程。許多大數據分析方法(如分類、分群、關聯規則)都源於數據挖掘領域。

#36
★
報表 (Reporting)
描述性分析
將數據分析結果(通常是描述性統計量)以結構化、易於閱讀的方式(表格、圖表)呈現出來,用於監控和溝通。
#37
★
根本原因分析 (Root Cause Analysis, RCA)
診斷性分析
一套用於找出問題或事件發生的根本原因的方法論。診斷性數據分析可以為 RCA 提供重要的線索和證據。
#38
★
預測建模 (Predictive Modeling)
預測性分析
建立數學或計算模型來預測未來結果的過程。是預測性分析的核心活動。
#39
★
模擬 (Simulation)
指示性分析方法
建立系統模型,並模擬不同條件或決策下的行為,以評估可能結果,輔助指示性分析。
#40
★
實驗設計 (Design of Experiments, DOE)
統計方法
一套系統性地規劃、執行和分析實驗的方法,旨在有效地研究輸入變數對輸出結果的影響。A/B 測試是 DOE 的一種簡單形式。
#41
★
半監督學習應用
ML 方法
利用大量未標籤數據輔助少量標籤數據進行學習,在標註成本高昂的大數據場景中有應用潛力。
#42
★
多模態數據分析 (Multimodal Data Analysis)
特定數據分析 (參考 L21104)
分析和整合來自多種不同類型數據源(如文本、圖像、聲音)的訊息,以獲得更全面的理解或預測。(參考 L21104)
#43
★
數據驅動決策 (Data-Driven Decision Making)
分析目標
大數據分析的最終目標是基於數據分析的結果和洞見來做出更明智的業務或營運決策。
#44
★
KPI (Key Performance Indicator) 監控
描述性分析應用
使用儀表板等工具追蹤和展示關鍵績效指標,是描述性分析的常見應用。
#45
★
魚骨圖 (Fishbone Diagram) / 石川圖
診斷工具
一種用於系統性分析問題潛在原因的視覺化工具,常用於根本原因分析。
#46
★
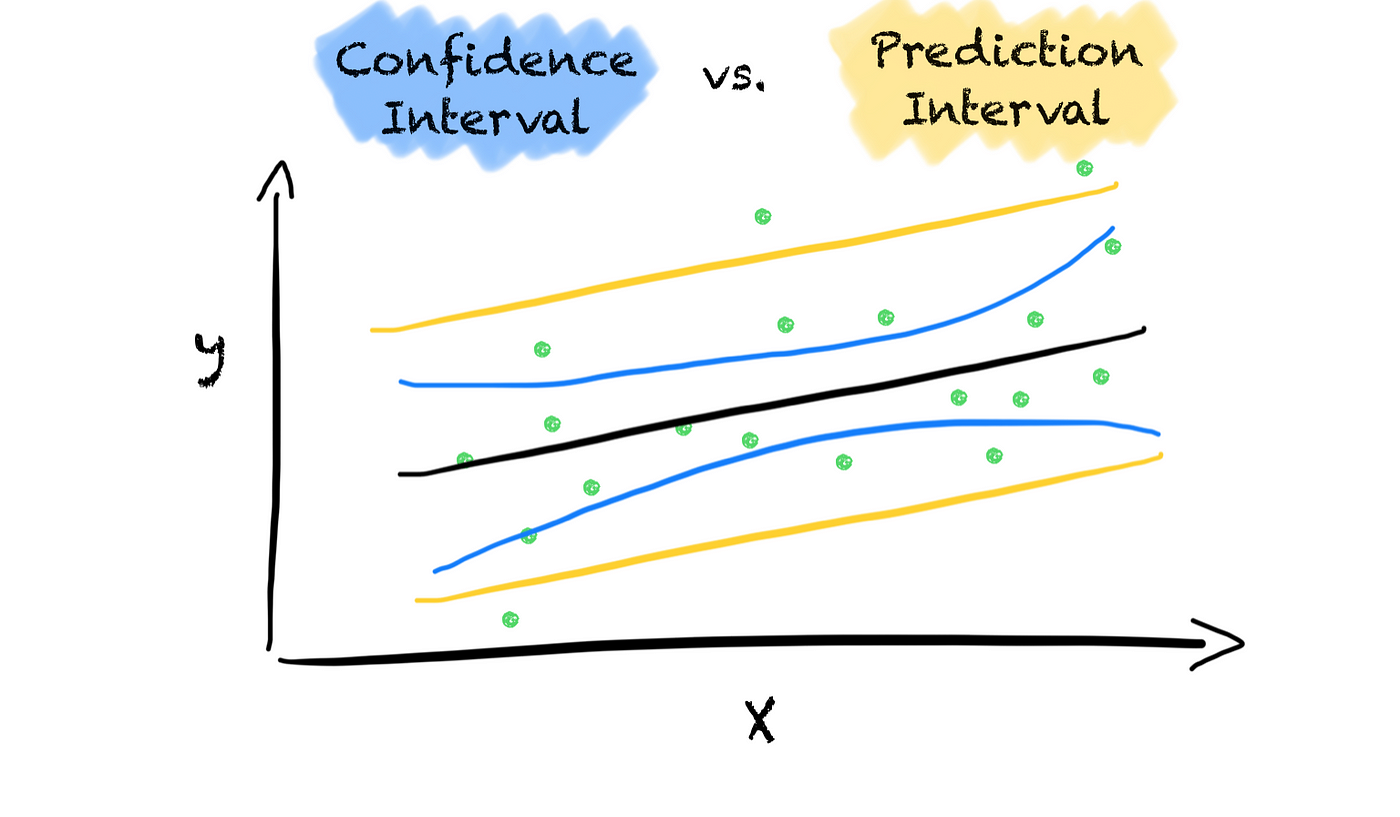
預測區間 (Prediction Interval)
迴歸評估
除了點預測,迴歸模型還可以提供一個預測區間,表示未來單個觀測值可能落入的範圍(具有一定的信賴水準)。
#47
★
敏感度分析 (Sensitivity Analysis)
指示性/診斷性
分析模型輸出對輸入參數或假設變化的敏感程度。有助於理解模型的不確定性,評估不同方案的穩健性。
#48
★
變異數分析 (ANOVA, Analysis of Variance)
統計方法
用於比較三個或更多組之間平均值是否存在顯著差異的統計檢定方法。
#49
★
自然語言處理 (NLP) 技術
ML 應用 (參考樣題 Q7)
一系列用於處理和理解人類語言的機器學習技術,如分詞、詞性標註、句法分析、情感分析、機器翻譯等。樣題 Q7 提及。
#50
★
MapReduce 典範 (參考樣題 Q11)
大數據處理
一種用於大規模數據集並行處理的編程模型和框架(由 Google 提出,Hadoop 為其開源實現)。包含 Map(映射/轉換)和 Reduce(匯總/歸約)兩個主要階段。(樣題 Q11)
#51
★
數據分析的迭代性
流程特性
數據分析通常是一個迭代的過程,分析結果可能會引導回到前面的步驟(如重新收集數據、重新進行預處理或特徵工程)。
#52
★
數據聚合 (Data Aggregation)
描述性分析
將數據按特定維度分組,並對每個組計算匯總統計量(如總和、平均值、計數)。是生成報表和儀表板的常用操作。
#53
★
歸因分析 (Attribution Analysis)
診斷性分析
試圖確定不同因素或渠道對某個結果(如銷售、轉換)的貢獻程度。例如,分析不同廣告渠道對用戶最終購買的影響。
#54
★
預測模型的可解釋性 (XAI)
預測性分析
除了預測準確性,理解模型為何做出某個預測(哪些特徵起作用)對於信任和應用模型也很重要。
#55
★
決策樹 (作為決策規則)
指示性分析
訓練好的決策樹可以被解釋為一系列「如果...那麼...」的決策規則,可以直接用於指導行動。
#56
★
卡方檢定 (Chi-squared Test)
統計方法
常用於檢定兩個類別變數之間是否存在關聯,或觀察到的頻率分佈是否符合預期分佈。
#57
★
表示學習 (Representation Learning)
ML 方法
指自動從原始數據中學習有用的特徵表示的方法,深度學習是其代表。目標是學習到能更好支持下游任務(如分類、迴歸)的數據表示。
#58
★
生存分析 (Survival Analysis)
特定數據分析
分析事件發生時間(如客戶流失時間、設備故障時間)的統計方法,考慮了刪失數據(事件尚未發生)。
#59
★
分析與洞見 (Insight)
分析目標
數據分析的目標不僅僅是計算指標或建立模型,更重要的是從結果中提煉出有價值的、可行動的洞見。
#60
★
信賴區間 (Confidence Interval)
統計推論
用於估計總體參數(如平均值)可能範圍的一個區間。提供了對估計值不確定性的度量。
沒有找到符合條件的重點。
↑