iPAS AI應用規劃師 經典題庫
L22203 數據處理技術與工具
出題方向
1
數據清理基礎與缺失值處理
2
異常值與重複數據處理
3
數據轉換:標準化與歸一化
4
數據轉換:離散化與聚合
5
數據整合與合併
6
數據歸約與抽樣
7
常用數據處理工具
8
ETL/ELT流程概念
#1
★★★★★
在數據清理過程中,面對數據集中的缺失值(Missing Values),以下哪種處理方式最為簡單直接,但可能損失最多資訊?
答案解析
直接刪除包含任何缺失值的紀錄(或稱為 Listwise Deletion / Complete Case Analysis)是最簡單的處理方法,不需要進行估計或假設。然而,如果缺失值比例較高,或者缺失模式並非完全隨機,這種方法會導致大量數據被丟棄,可能嚴重減少樣本數,並可能引入偏差(Bias),因為被刪除的紀錄可能具有某些未觀察到的共同特性。其他選項(B, C, D)是填補(Imputation)方法,旨在保留數據紀錄,但需要基於一定的假設來估計缺失值。
#2
★★★★
在偵測數值型數據中的異常值(Outliers)時,以下哪種方法是基於數據分佈的統計特性?
答案解析
使用 IQR 來偵測異常值是一種常見的統計方法,特別適用於非嚴格常態分佈的數據。計算方式為:找出第一四分位數(Q1)和第三四分位數(Q3),計算 IQR = Q3 - Q1。通常將低於 Q1 - 1.5 * IQR 或高於 Q3 + 1.5 * IQR 的值視為異常值。選項A用於偵測重複。選項C可能用於時間序列分析但非標準異常值偵測。選項D是類別變數的處理方式。
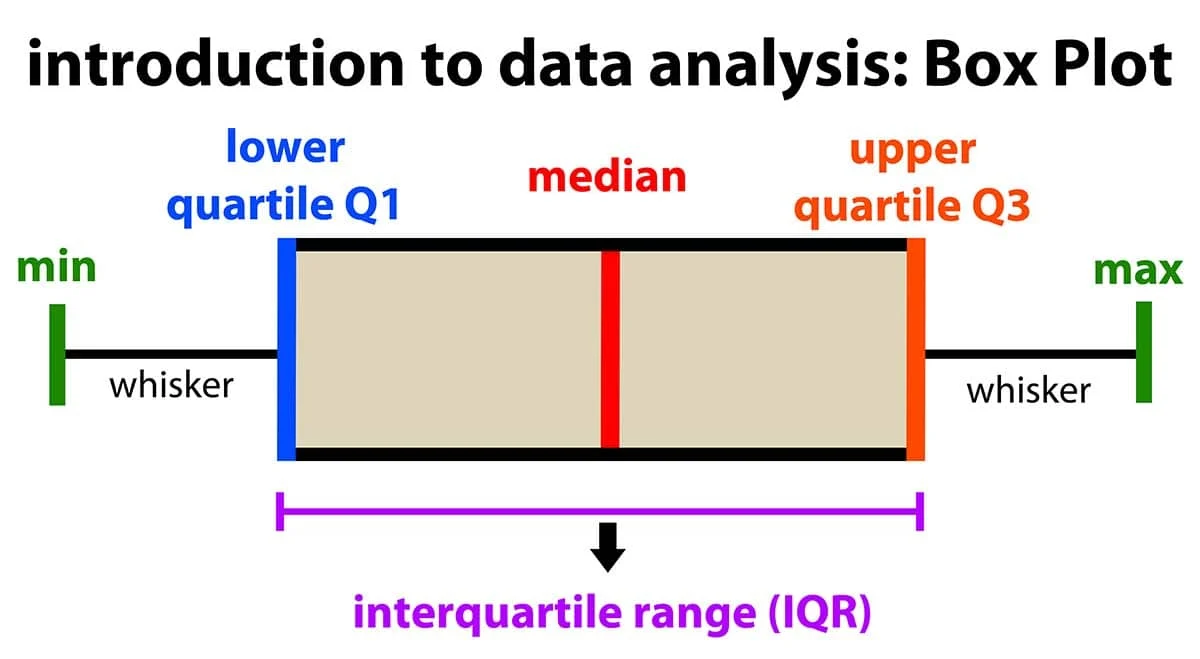
#3
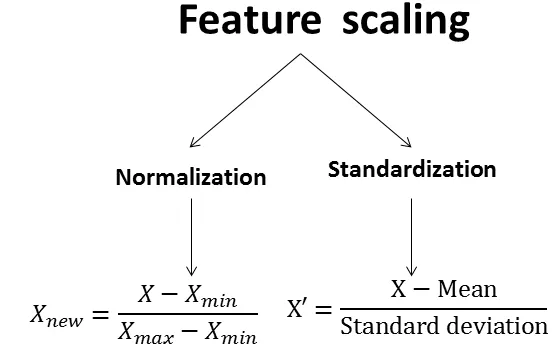
★★★★★
將數據特徵(Feature)的值縮放到 [0, 1] 或 [-1, 1] 區間內的過程,通常稱為什麼?
答案解析
歸一化(Normalization),特別是最小-最大縮放(Min-Max Scaling),是將原始數據線性地轉換到指定的範圍內,通常是 [0, 1] 或 [-1, 1]。計算公式為:X_scaled = (X - X_min) / (X_max - X_min)。標準化(Standardization)則是將數據轉換為平均值為0、標準差為1的分佈,公式為:X_scaled = (X - mean) / std_dev。離散化是將連續數值轉換為有限個區間或類別。聚合是將多個數據點匯總成單一值(如求和、平均)。
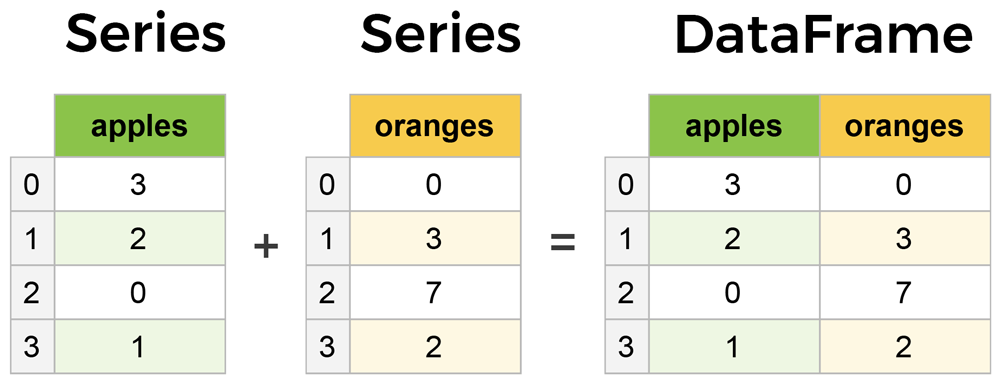
#4
★★★★
在 Python 程式語言中,哪個函式庫(Library)被廣泛用於數據處理、操作和分析,特別是處理表格式數據(Tabular Data)?
答案解析
Pandas 是 Python 中進行數據處理和分析的核心函式庫。它提供了兩種主要的數據結構:Series(一維陣列)和 DataFrame(二維表格),並內建了大量用於數據讀取、寫入、清理、轉換、合併、重塑、聚合等操作的功能。NumPy 主要用於數值計算和處理多維陣列。Matplotlib 用於數據視覺化。Scikit-learn 是機器學習函式庫。
#5
★★★★
在數據倉儲(Data Warehousing)的 ETL 流程中,"T" 代表哪個步驟?
答案解析
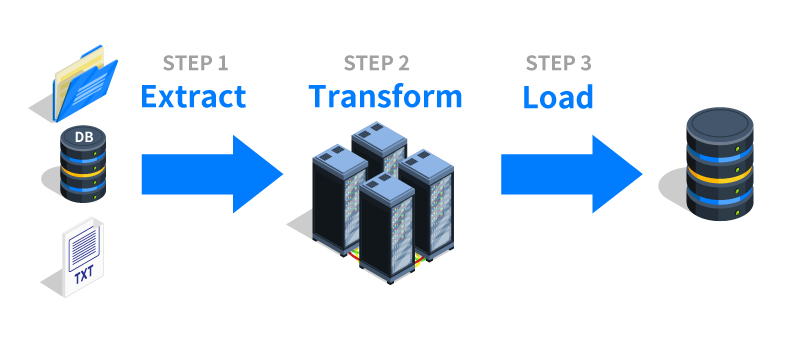
ETL 是 Extract(萃取)、Transform(轉換)、Load(載入)三個字的縮寫,是建構數據倉儲的經典流程。
E (Extract):從各種異質的來源系統(如資料庫、檔案、API)讀取數據。
T (Transform):對萃取的數據進行清理、整合、標準化、計算、聚合等轉換操作,使其符合目標數據倉儲的結構和分析需求。
L (Load):將轉換後的數據載入到目標數據倉儲中。
#6
★★★★
與歸一化(Normalization)相比,標準化(Standardization)的主要優勢是什麼?
答案解析
標準化(Z-score Normalization)是通過減去平均值並除以標準差來轉換數據。因為平均值和標準差不像最小值和最大值那樣容易受到極端值(異常值)的劇烈影響,所以標準化通常對異常值更為穩健(Robust)。歸一化(Min-Max Scaling)使用的最小值和最大值會直接被異常值拉伸,導致大部分數據被壓縮到一個很小的範圍內。標準化後的數據沒有固定的範圍限制。對於某些基於距離的演算法(如 K-Means、SVM)或需要假設數據呈常態分佈的演算法,標準化通常更受青睞。
#7
★★★
在 Pandas DataFrame 中,若要根據某個或多個共同欄位(Key Columns)將兩個 DataFrame 合併起來,類似於資料庫中的 JOIN 操作,應使用哪個函數?
答案解析
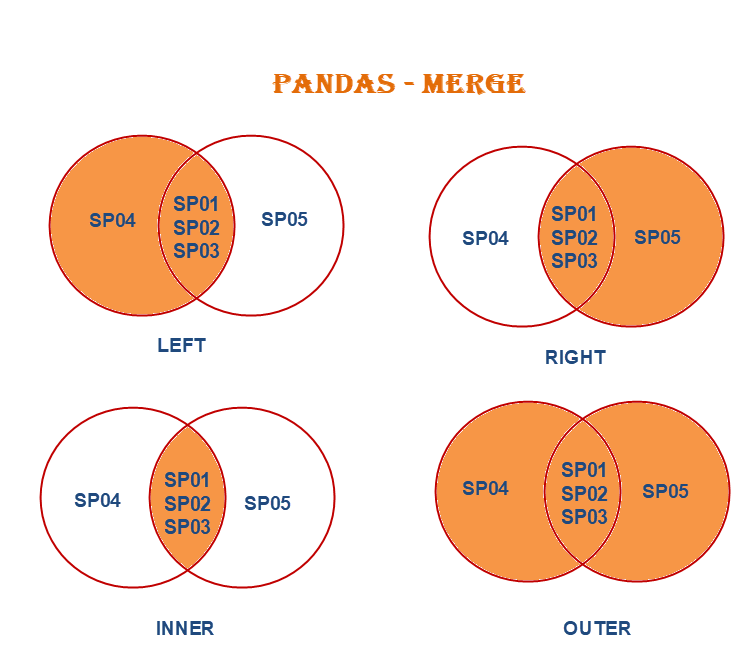
Pandas 的 `merge()` 函數提供了類似 SQL JOIN 的功能,可以根據指定的鍵(`on` 參數)或索引將兩個 DataFrame 橫向合併。它支持多種合併方式,如內連接(`inner`)、左連接(`left`)、右連接(`right`)、外連接(`outer`)。`concat()` 主要用於沿著某個軸(行或列)將多個 DataFrame 堆疊起來。`append()` 是 `concat()` 的一個簡化版本,主要用於在 DataFrame 末尾追加行。`groupby()` 用於分組聚合操作。
#8
★★★
將連續的數值型特徵(如年齡)轉換為有限個區間或類別(如 "青年", "中年", "老年")的過程稱為什麼?
答案解析
離散化(Discretization)或 分箱(Binning)是將連續變數轉換為離散變數的過程。這可以通過定義固定的區間寬度(Equal Width Binning)或確保每個區間包含大致相同數量的樣本(Equal Frequency Binning)來實現。這樣做有時可以簡化模型,處理非線性關係,或將數值特徵用於需要類別輸入的演算法。特徵縮放是改變數值範圍。獨熱編碼用於處理類別變數。PCA 是降維技術。

#9
★★★★
在處理類別型數據(Categorical Data)的缺失值時,以下哪種填補方法最常用?
答案解析
對於類別型數據(例如 "顏色"、"城市" 等),計算平均值或中位數通常沒有意義。最常用且簡單的填補方法是使用該欄位中出現頻率最高的類別,即眾數(Mode),來填補缺失值。雖然這也可能引入偏差,但在沒有更複雜的模型或領域知識的情況下,這是一種常用的基準方法。
#10
★★★
數據清理中偵測重複數據(Duplicate Data)時,通常基於什麼來判斷兩筆紀錄是否重複?
答案解析
偵測完全重複的紀錄通常是比較兩筆紀錄的所有欄位值是否都一模一樣。在某些情況下,也可以根據業務邏輯定義一組關鍵欄位(例如 "用戶ID" + "訂單日期"),如果這些關鍵欄位的值相同,則認為是重複紀錄。選項A、B、D 不是判斷數據內容是否重複的標準方法。
#11
★★★★
主成分分析(Principal Component Analysis, PCA)是一種常用的數據處理技術,其主要目的是什麼?
答案解析
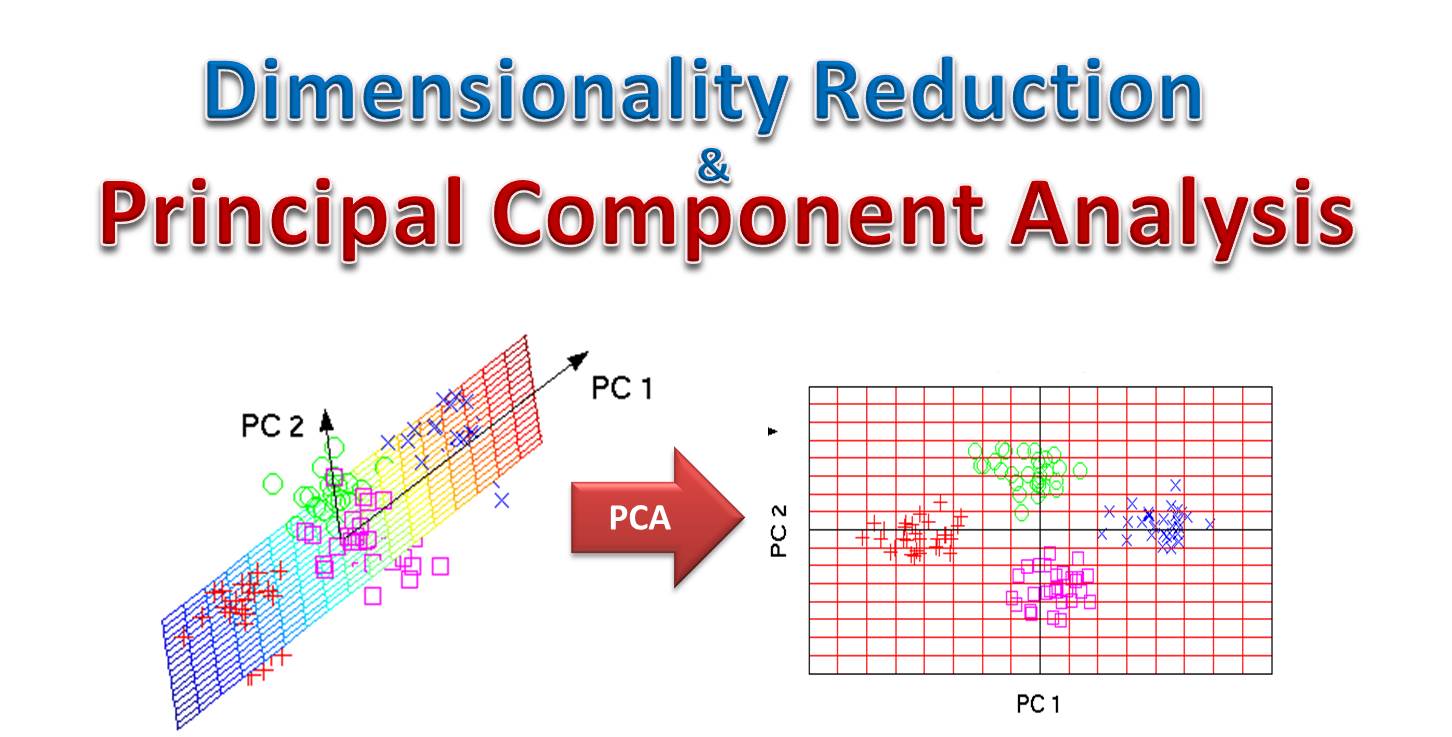
PCA 是一種非監督式的線性變換技術,常用於數據降維。它通過尋找數據中方差最大的方向(主成分),將原始的高維數據投影到一個新的低維子空間上,同時目標是最大化保留原始數據的變異信息。降維有助於減少計算複雜度、去除雜訊、視覺化高維數據等。選項B是標準化。選項C是缺失值處理。選項D是異常值處理。
#12
★★★
當你需要將多個結構相同(欄位名稱和類型一致)的數據檔案(例如,每個月的銷售紀錄檔)垂直堆疊成一個大的數據集時,Pandas 中的哪個函數最適合?
答案解析
`concat()` 函數用於沿著指定的軸(預設是 axis=0,即垂直堆疊行)將多個 Pandas 物件(如 DataFrame 或 Series)連接起來。當數據結構相同,需要將它們上下堆疊時,`concat()` 是最常用的方法。`merge()` 和 `join()` 主要用於基於鍵值的橫向合併。`pivot_table()` 用於創建數據透視表進行聚合。

#13
★★★
Apache Spark 是一個廣泛用於大數據處理的分散式運算框架。其核心的數據抽象是什麼?
答案解析
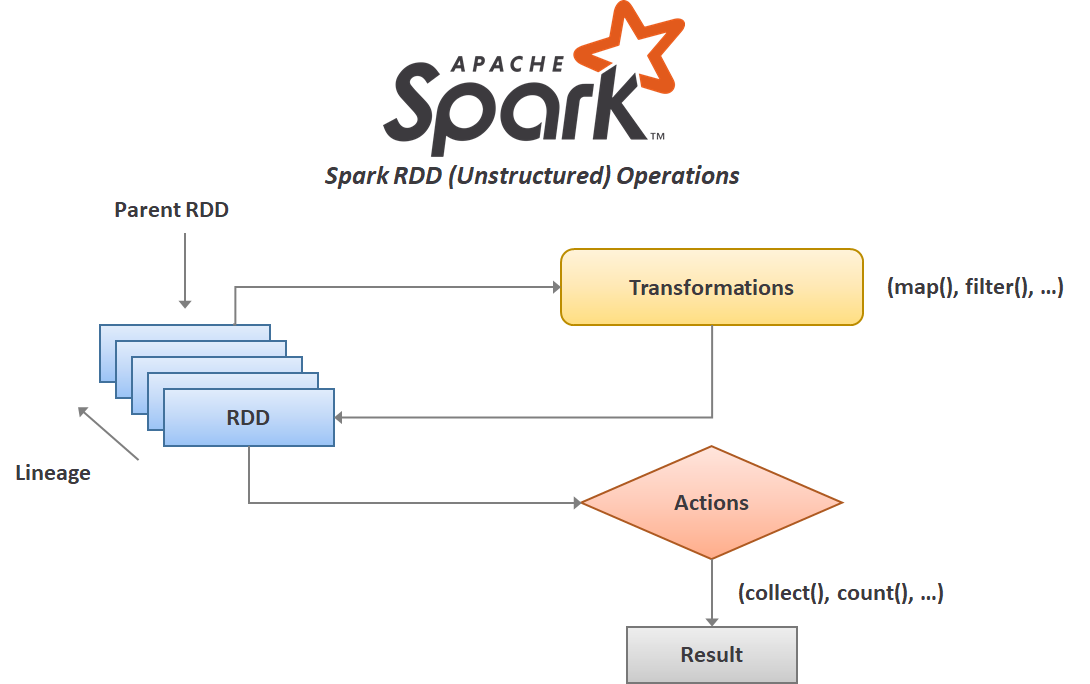
RDD 是 Spark 最早也是最核心的數據抽象。它代表一個不可變(Immutable)、可分區(Partitioned)、可並行操作(Parallelizable)的元素集合。RDD 提供了豐富的轉換(Transformations,如 map, filter, reduceByKey)和動作(Actions,如 count, collect, save)操作接口,並具有容錯性。雖然 Spark 後續引入了 DataFrame 和 Dataset 等更高級、更優化的 API,但 RDD 仍然是其底層基礎。MapReduce 是 Hadoop 的計算模型。HDFS 是 Hadoop 的儲存系統。DataFrame 也是 Spark 的一種數據結構,但 RDD 是更核心的抽象。
#14
★★
在進行數據聚合(Aggregation)時,`GROUP BY` 操作通常與哪種類型的函數結合使用?
答案解析
`GROUP BY` 操作的目的是將數據集中具有相同鍵值的紀錄分組,然後對每個組應用一個或多個函數。這些函數通常是聚合函數,它們將每個組內的多個值匯總成一個單一的結果值(例如,計算每個部門的總銷售額、每個產品的平均評分等)。排序函數用於改變紀錄順序。視窗函數也在分組數據上操作,但不像聚合函數那樣將多行壓縮為一行。字串函數用於處理文字。
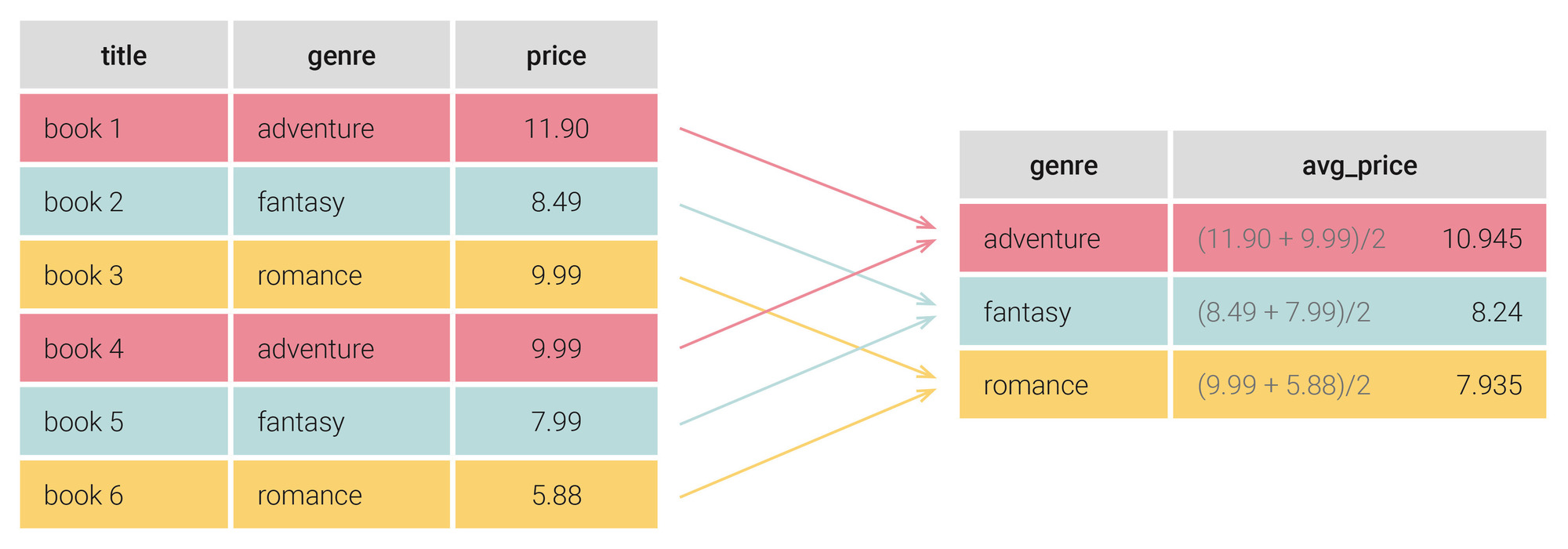
#15
★★★
假設一個數據欄位存在缺失值,且該欄位為數值型,數據分佈呈現明顯的右偏斜(Right-skewed)。在這種情況下,使用哪種統計量填補缺失值通常比使用平均值更穩健?
答案解析
當數據分佈偏斜時,平均值會受到極端值(在右偏斜情況下是大的數值)的影響而被拉向偏斜的方向。中位數是將數據排序後位於中間位置的值,它不受極端值的影響,因此對於偏斜分佈的數據,中位數更能代表數據的集中趨勢。使用中位數填補缺失值在這種情況下通常比使用平均值更為穩健。眾數主要用於類別數據。標準差是衡量數據離散程度的指標,不用於填補。
#16
★★★
相較於傳統的 ETL (Extract, Transform, Load),ELT (Extract, Load, Transform) 流程的主要區別和潛在優勢是什麼?
答案解析
ELT 改變了 T 和 L 的順序。它先將從來源系統萃取出的原始數據(或經過少量預處理的數據)直接載入到目標儲存系統(通常是具有強大運算能力的雲端數據倉儲或數據湖)。然後,數據轉換工作在目標系統內部進行,利用其可擴展的計算資源。優勢包括:載入速度可能更快(因為未經複雜轉換),可以保留原始數據以供未來不同的轉換需求,更適合處理大量、多樣化的數據。ETL 則需要在載入前完成所有轉換,通常需要一個獨立的 ETL 伺服器。
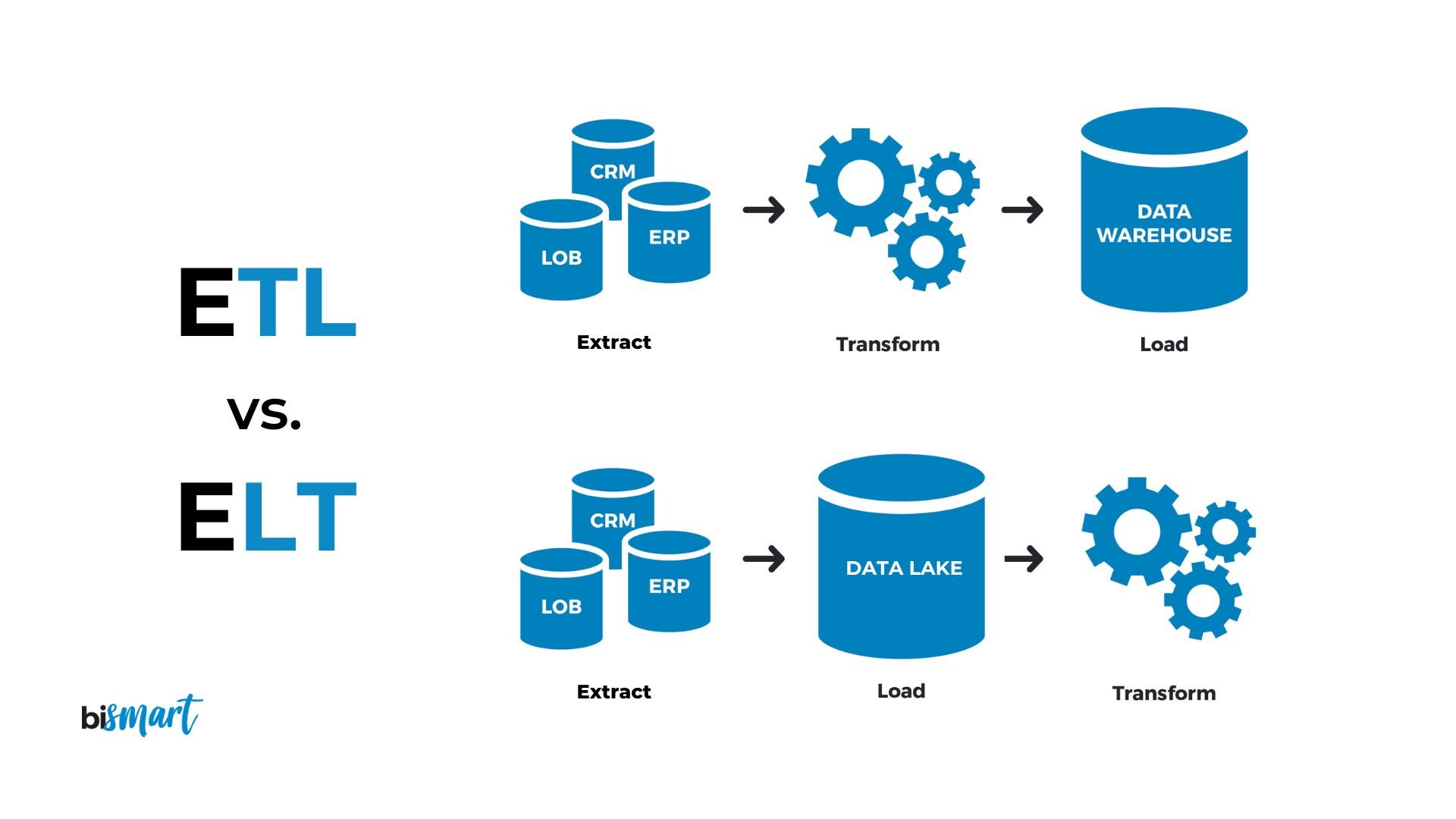
#17
★★★
在處理非常大的數據集時,為了降低分析或模型訓練的計算成本,可以從原始數據集中選取一部分代表性子集的過程稱為什麼?
答案解析
數據抽樣是從大的數據母體中選取一部分樣本(子集)的過程,目的是用這個子集來推斷母體的特性或進行初步的分析與建模。常見的抽樣方法包括簡單隨機抽樣(Simple Random Sampling)、分層抽樣(Stratified Sampling)、系統抽樣(Systematic Sampling)等。抽樣可以在保證一定代表性的前提下,顯著減少處理數據所需的時間和資源。聚合是匯總數據,整合是合併數據,標準化是轉換數據尺度。

#18
★★★
以下哪種視覺化圖表最常用於直觀地檢查數值變數是否存在異常值?
答案解析
箱形圖是一種非常有效的視覺化工具,用於展示數據的分佈特性,包括中位數、四分位數(Q1, Q3)、全距以及異常值。箱體代表 IQR(Q1 到 Q3 的範圍),箱外的線(鬚)通常延伸到 Q1 - 1.5*IQR 和 Q3 + 1.5*IQR 的範圍內(或數據的最小值/最大值,如果在該範圍內)。超出這些鬚線的點通常被標記出來,直觀地指示了潛在的異常值。圓餅圖和長條圖主要用於比較類別數據的比例或數量。熱力圖用於展示矩陣數據的大小關係。
#19
★★
Hadoop 生態系統中,主要負責資源管理和任務調度的元件是?
答案解析
YARN 是 Hadoop 2.x 版本後引入的資源管理系統。它將 MapReduce 1.x 中 JobTracker 的資源管理和任務調度功能分離開來。YARN 負責管理 Hadoop 叢集中的計算資源(CPU、記憶體等),並根據應用程式(如 MapReduce、Spark、Flink 等)的需求進行分配和調度。HDFS 是分散式儲存系統。MapReduce 是批次處理的計算模型。Hive 是建立在 Hadoop 之上的數據倉儲工具,提供 SQL 介面。
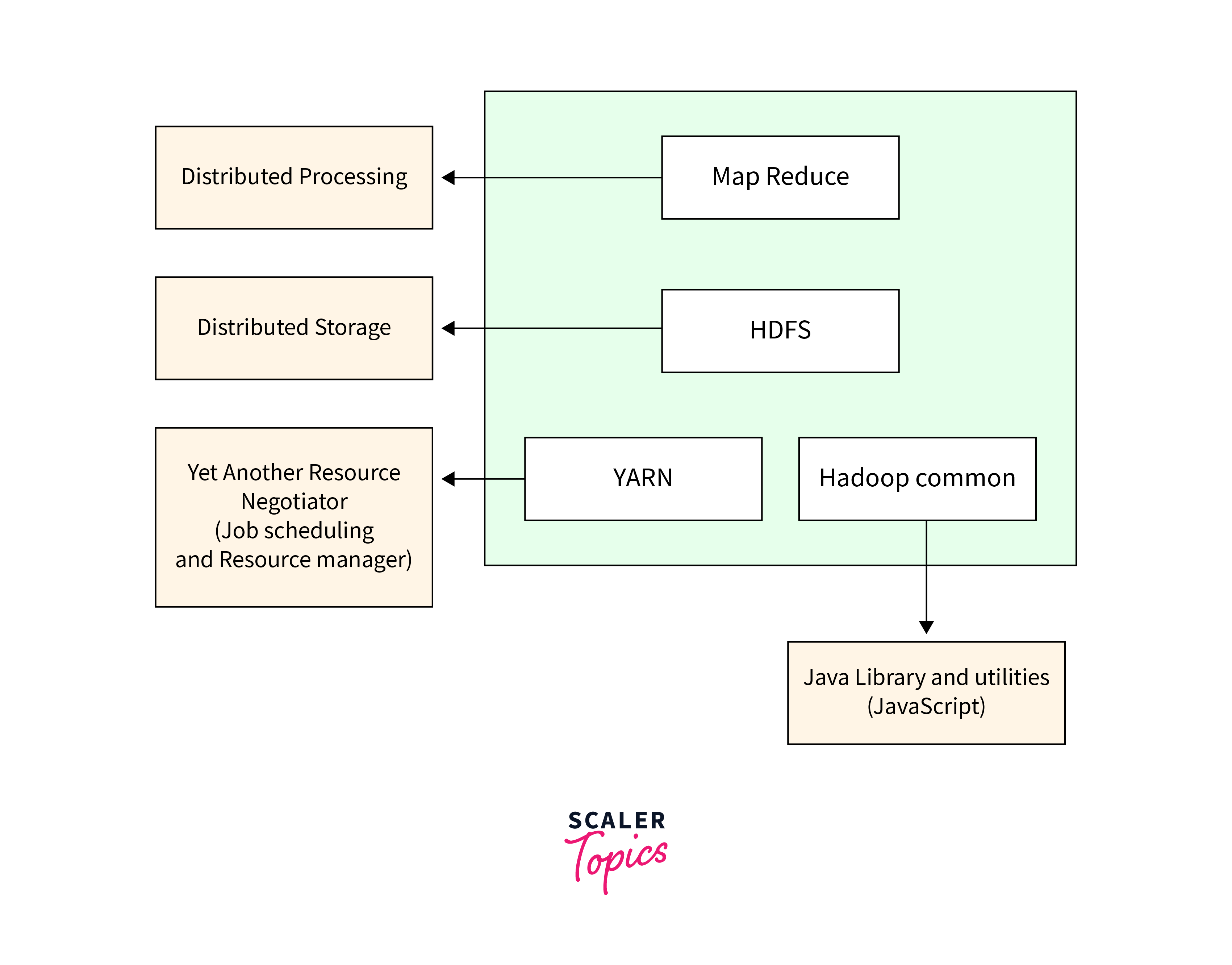
#20
★★★
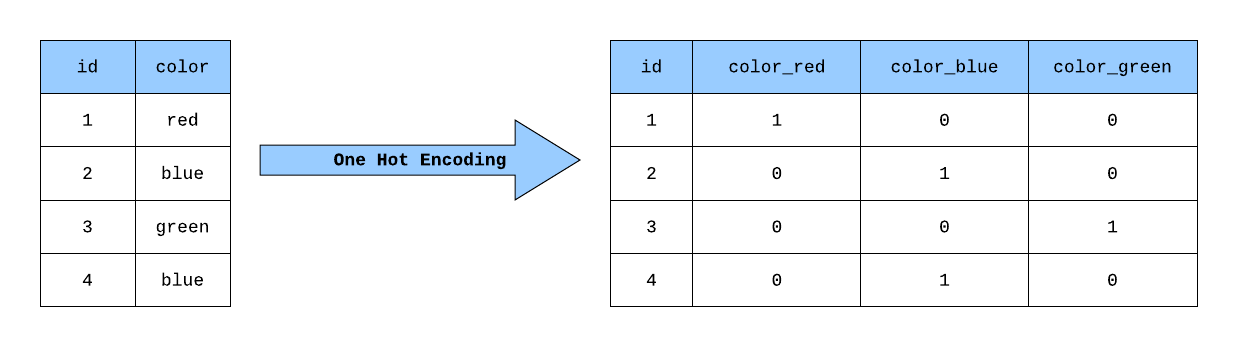
獨熱編碼(One-Hot Encoding)主要用於處理哪種類型的數據特徵?
答案解析
獨熱編碼是將類別變數轉換為機器學習模型更容易處理的數值格式的一種常用方法。它特別適用於處理沒有內在順序關係的類別特徵(名目變數,Nominal),例如 "顏色"(紅、綠、藍)。它會為每個類別創建一個新的二元(0 或 1)特徵欄位,如果原始紀錄屬於該類別,則對應欄位為 1,其餘為 0。對於有序類別特徵(例如 "評級":差、中、好),有時會使用標籤編碼(Label Encoding)或其他保留順序資訊的方法。
#21
★★★★
數據清理是數據預處理中的重要環節,其主要目標不包含以下哪一項?
答案解析
數據清理的主要目標是提高數據品質,使其更適合後續的分析和建模。這包括處理缺失值、異常值、重複值、雜訊以及修正數據格式、單位、編碼等不一致的問題。直接訓練模型是數據分析流程的後續步驟,而不是數據清理本身的目標。
#22
★★★
將來自不同數據來源(例如,客戶基本資料庫和交易紀錄資料庫)的數據合併在一起,以獲得更全面的客戶視圖,這個過程屬於?
答案解析
數據整合是指將來自多個異質數據來源的數據合併成一個一致、統一的數據集的過程。這通常涉及解決數據模式(Schema)匹配、實體識別(如識別不同來源中的同一個客戶)、處理數據值衝突等問題。目的是提供一個更完整、更全面的數據視圖以支持分析。
#23
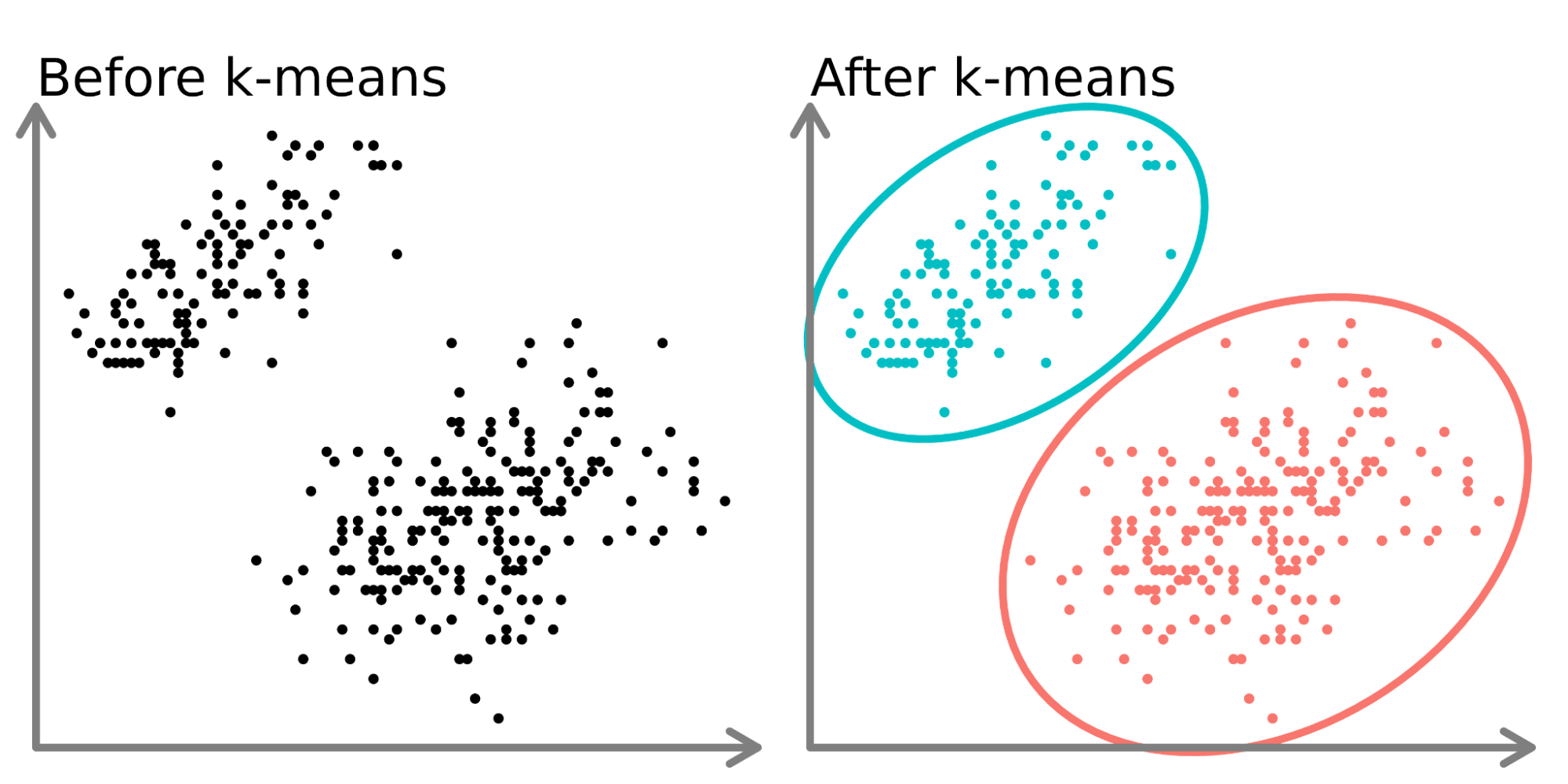
★★★
以下哪種機器學習演算法對輸入特徵的尺度(Scale)差異最為敏感,因此通常需要進行特徵縮放(如標準化或歸一化)?
答案解析
K-Means 聚類是基於計算樣本點之間的距離(通常是歐氏距離)來進行分群的。如果不同特徵的數值範圍(尺度)差異很大,那麼尺度較大的特徵會在距離計算中佔主導地位,使得尺度較小的特徵幾乎不起作用,導致聚類結果不佳。因此,在使用 K-Means 或其他基於距離的演算法(如 SVM、KNN、PCA)之前,通常需要對數據進行標準化或歸一化。決策樹和隨機森林等基於樹的模型對特徵尺度不敏感。樸素貝氏主要基於條件機率,對尺度也不敏感。
#24
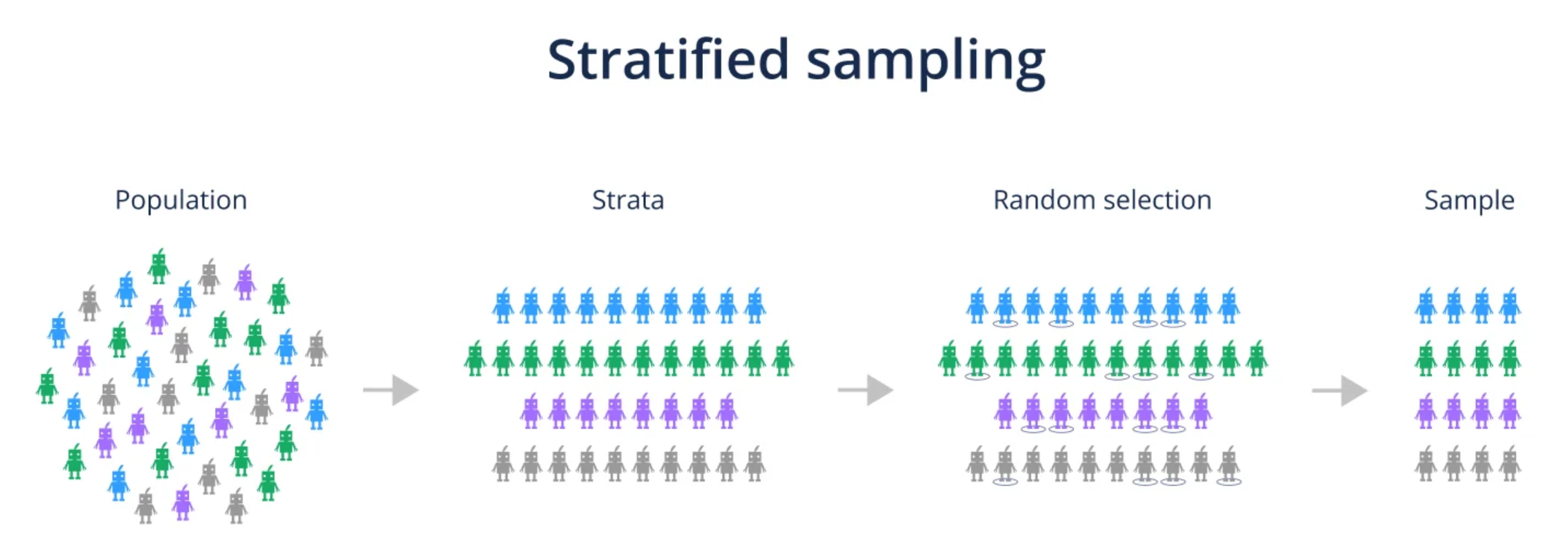
★★
分層抽樣(Stratified Sampling)的主要目的是什麼?
答案解析
分層抽樣首先將母體按照某個或某些特徵劃分成互不重疊的子群體(稱為「層」,Strata),然後在每個層內獨立進行隨機抽樣。這樣做的主要目的是確保最終的樣本能夠準確地反映母體中各個層的比例,特別是當某些層的規模較小或層間差異較大時,分層抽樣可以提高樣本的代表性,減少抽樣誤差。
#25
★★★★
處理數據中的異常值時,以下哪種做法屬於「替換法」?
答案解析
處理異常值的方法大致可分為刪除法、替換法和保留法。替換法是指用一個較為合理的數值來取代偵測到的異常值。Winsorization(縮尾處理)是一種常見的替換法,它將所有低於某個百分位數(如 5%)的值替換為該百分位數的值,並將所有高於另一個百分位數(如 95%)的值替換為該百分位數的值。其他替換方法還包括用平均值、中位數等替換。選項A是刪除法。選項C是保留法的一種策略。選項D適用於將異常視為一種特殊情況,但不常用於數值異常值。
#26
★★★
SQL (Structured Query Language) 是一種用於管理和操作關聯式資料庫的標準語言。以下哪個 SQL 關鍵字用於從表格中選取特定的欄位?
答案解析
在 SQL 查詢中,`SELECT` 關鍵字用於指定要從數據表中檢索或計算的欄位(列)。`FROM` 關鍵字用於指定數據來源的表格。`WHERE` 關鍵字用於設定篩選條件,只選取滿足條件的紀錄(行)。`GROUP BY` 關鍵字用於將具有相同值的行分組,通常與聚合函數一起使用。
#27
★★★
當數據欄位的值格式不一致時,例如日期欄位同時存在 "YYYY/MM/DD" 和 "MM-DD-YYYY" 兩種格式,這屬於哪一類數據品質問題?
答案解析
數據一致性指的是數據在不同地方或不同時間點的表示是否符合相同的標準或規則。日期格式不統一、單位不一致(如公尺 vs. 英尺)、編碼方式不同(如 'M'/'F' vs. 'Male'/'Female')等都屬於一致性問題。完整性涉及數據是否有缺失。唯一性涉及是否有重複紀錄。時效性涉及數據是否足夠新。
#28
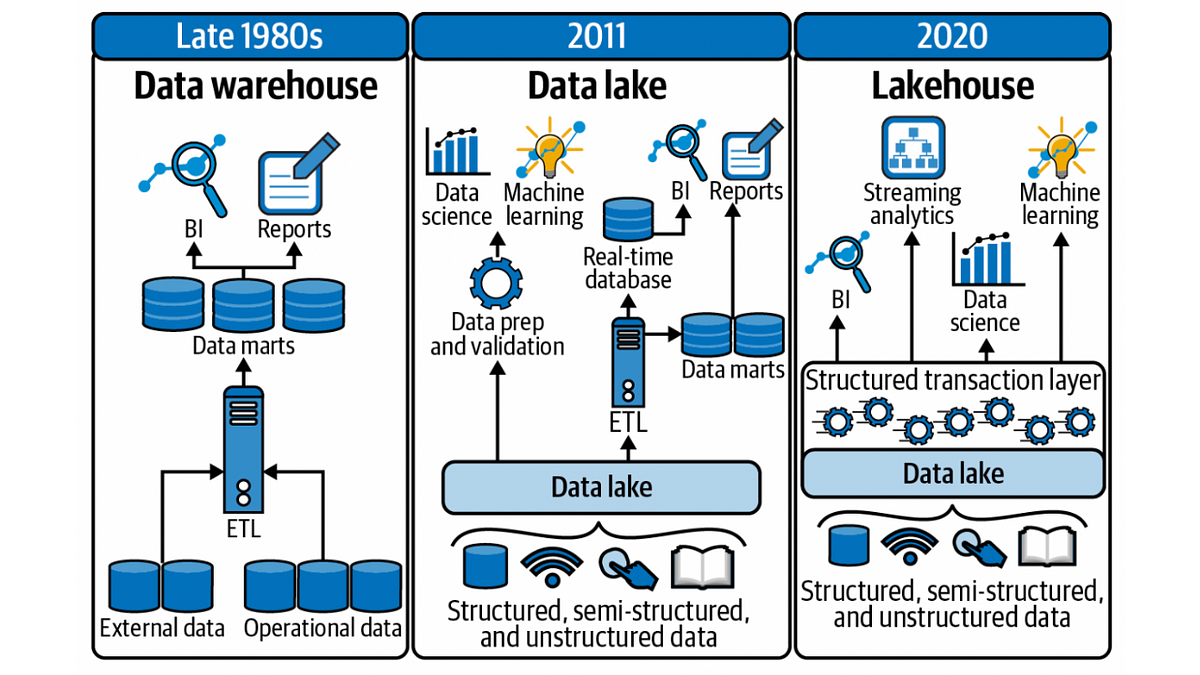
★★
數據湖(Data Lake)與傳統數據倉儲(Data Warehouse)相比,其主要特點之一是?
答案解析
數據湖是一個集中式的儲存庫,允許以原始格式儲存大量結構化、半結構化和非結構化數據。它通常採用 Schema-on-Read(讀取時定義綱要)的方法,而不是像傳統數據倉儲那樣要求在數據載入前就定義好嚴格的綱要(Schema-on-Write)。這使得數據湖非常靈活,可以快速地接納各種來源的數據,但後續的查詢和分析可能需要更多的處理。
#29
★★★
在 Pandas 中,對 DataFrame 使用 `groupby()` 函數後,通常會接著調用哪個類型的方法來計算每個分組的匯總統計量?
答案解析
`groupby()` 操作本身只是創建了一個 GroupBy 物件,定義了分組方式。要獲得實際的匯總結果,需要在這個 GroupBy 物件上調用聚合方法。Pandas 提供了許多內建的聚合方法,如 `.sum()`, `.mean()`, `.count()`, `.max()`, `.min()`, `.std()` 等。`.agg()` 方法則允許同時應用多個聚合函數或自定義聚合函數。`.transform()` 對每個分組應用函數但返回與原 DataFrame 同形狀的結果。`.filter()` 用於篩選分組。`.apply()` 功能更通用,可以應用任意函數,但對於標準的匯總統計,直接使用聚合方法通常更高效。
#30
★★★
對數轉換(Log Transformation)是一種常用的數據轉換技術,它主要適用於處理哪種類型的數據分佈?
答案解析
對數轉換(通常使用自然對數或以10為底的對數)對較大的數值有較強的壓縮作用,而對較小的數值影響較小。因此,它特別適用於處理正偏態(右偏斜)的數據,即數據集中包含一些遠大於大部分數據點的數值。通過對數轉換,可以有效地減小這些大數值的影響,使數據分佈更接近對稱或常態分佈,這有助於滿足某些統計模型(如線性迴歸)的假設。對於負偏斜數據,可能需要先進行反射(如 `log(max(X+1) - X)`)再轉換。
#31
★★
特徵選擇(Feature Selection)和特徵萃取(Feature Extraction)都是數據歸約的方法,它們的主要區別在於?
答案解析
特徵選擇(如過濾法、包裹法、嵌入法)的目標是直接從原始的特徵集合中選出一個子集,移除不相關或冗餘的特徵,保留的特徵仍然是原始特徵。特徵萃取(如 PCA、LDA)則是將原始特徵轉換到一個新的特徵空間,創建出新的、通常是原始特徵線性或非線性組合的特徵,這些新特徵可能不再具有直接的物理意義,但希望能更好地捕捉數據中的關鍵資訊並降低維度。兩者都是降維的方法,但實現方式不同。
#32
★★★
當數據集中存在拼寫錯誤或不一致的標籤(例如 "New York", "NY", "new york city" 都指向同一個城市),這屬於哪種數據品質問題,通常需要如何處理?
答案解析
這種情況屬於數據不一致性問題,特別是標籤或類別表示的不一致。處理方法通常是定義一個標準化的表示方式(例如,統一使用 "New York"),然後將所有變體("NY", "new york city" 等)映射到這個標準值。這可能需要使用查找表、正則表達式或更複雜的模糊匹配技術。這不屬於缺失值、典型數值異常值或完全重複紀錄的問題。
#33
★★
在進行缺失值填補時,使用基於模型的填補方法(如迴歸填補、KNN填補)相較於簡單的統計量填補(平均值、中位數、眾數),其主要優點是什麼?
答案解析
基於模型的填補方法(如使用線性迴歸預測缺失值,或使用 K 最近鄰居(K-Nearest Neighbors, KNN)找到相似樣本的值來填補)利用了數據集中其他特徵欄位的資訊。它們試圖捕捉特徵之間的相互關係,因此相比於只考慮單一欄位統計量的簡單填補方法,可能能夠產生更合理、更接近真實情況的填補值。然而,這些方法通常計算成本更高,且其效果也依賴於模型的選擇和數據本身的特性。
#34
★★
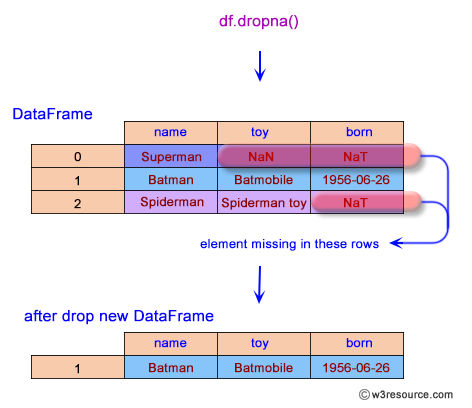
在 Python 的 Pandas 函式庫中,`DataFrame.dropna()` 方法的主要功能是什麼?
答案解析
`dropna()` 方法用於處理缺失值,其主要功能是移除包含 NaN(Not a Number,Pandas 中代表缺失值)的標籤。可以通過 `axis` 參數指定是移除包含缺失值的行(`axis=0`,預設)還是列(`axis=1`)。還可以通過 `how`('any' 或 'all')和 `thresh` 參數更精細地控制移除條件。填補缺失值使用 `fillna()` 方法。移除重複行使用 `drop_duplicates()` 方法。
#35
★★
當合併兩個 Pandas DataFrame 時,如果只想保留兩個 DataFrame 中共同存在的鍵值所對應的紀錄,應該使用哪種合併方式(`how` 參數)?
答案解析
內連接(`how='inner'`)是 `merge()` 函數的預設合併方式。它只會保留那些在兩個 DataFrame 中鍵值都存在的紀錄,類似於 SQL 的 INNER JOIN。外連接(`outer`)會保留兩個 DataFrame 中所有的鍵值,如果某個鍵值只存在於其中一個 DataFrame,則另一個 DataFrame 對應的欄位會被填充為 NaN。左連接(`left`)會保留左邊 DataFrame 的所有鍵值。右連接(`right`)會保留右邊 DataFrame 的所有鍵值。
#36
★★
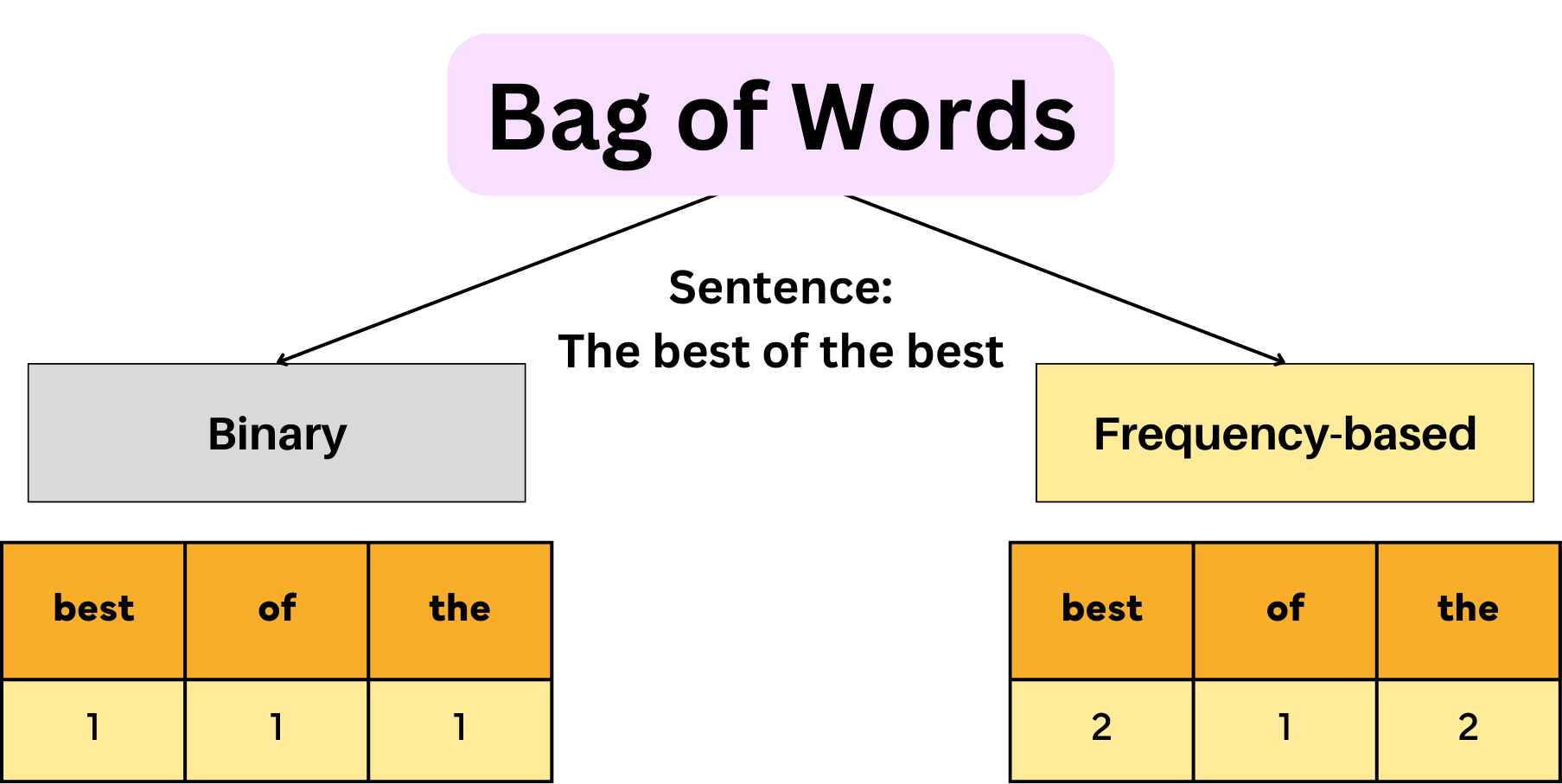
將文本數據轉換為數值表示的一種簡單方法是計算每個詞彙在文件中的出現次數,這被稱為什麼?
答案解析
詞袋模型(BoW)是一種簡化文本表示的方法,它忽略文法和詞序,只考慮每個詞彙在文件中出現的頻率(TF)。它將每個文件表示為一個向量,向量的維度是整個語料庫中的詞彙數量,每個維度的值是對應詞彙在該文件中的出現次數。TF-IDF 在詞頻的基礎上,乘以逆文件頻率,以降低常用詞的權重。獨熱編碼通常用於類別變數。詞嵌入(如 Word2Vec, GloVe)是更複雜的技術,旨在學習詞彙的語意表示。
#37
★★
以下哪種數據轉換方法的主要目的是消除特徵之間的線性相關性?
答案解析
PCA 在尋找數據中方差最大的方向時,生成的各個主成分(新的特徵)彼此之間是線性不相關(正交)的。這是 PCA 的一個重要特性。因此,PCA 不僅可以用於降維,也可以作為一種數據轉換方法來消除原始特徵之間的多重共線性問題。標準化和歸一化改變數據尺度,對數轉換改變數據分佈,但它們不直接消除特徵間的線性相關性。
#38
★
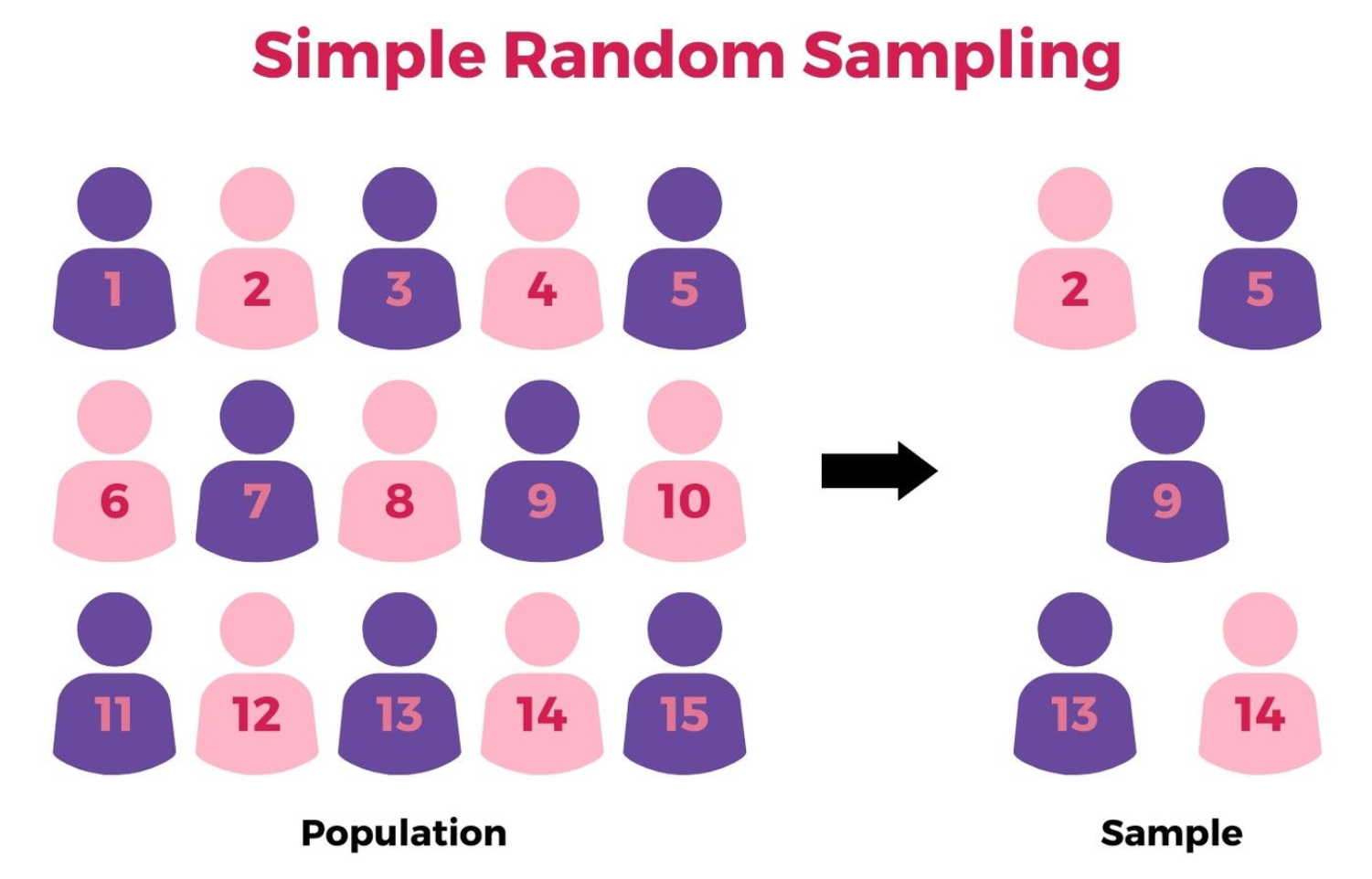
簡單隨機抽樣(Simple Random Sampling)的主要特點是?
答案解析
簡單隨機抽樣是最基本的機率抽樣方法。它的核心原則是確保母體中的每一個個體都有相同且獨立的機會被選入樣本中。抽樣過程通常像抽籤一樣,完全隨機,不考慮個體的任何特徵或母體的結構。選項A描述的是分層抽樣。選項C描述的是系統抽樣。選項D描述的是非機率抽樣中的立意抽樣。
#39
★★
處理缺失值時,Multiple Imputation (多重插補) 方法相比於 Single Imputation (單一插補,如均值填補) 的主要優勢在於?
答案解析
單一插補(如用平均值填補)會人為地降低數據的變異性,並且沒有考慮到填補值本身的不確定性,可能導致後續分析結果的偏差和標準誤的低估。多重插補通過生成多個(例如 5 或 10 個)填補後的完整數據集,每個數據集的缺失值是用考慮了不確定性的模型(通常基於抽樣)生成的。然後對每個數據集進行分析,最後將結果匯總。這種方法能夠更準確地反映由於缺失值存在而帶來的不確定性,得到更可靠的分析結果,但計算相對複雜。
#40
★★★
以下哪個工具或技術通常用於實現 ETL 流程中的數據轉換步驟?
答案解析
數據轉換是 ETL 流程的核心,涉及數據清理、整合、計算、格式化等。這可以通過專用的視覺化 ETL 工具來實現,這些工具通常提供圖形介面來設計轉換邏輯。也可以通過編寫程式碼來實現,例如使用 Python 的 Pandas 函式庫進行數據操作,或使用 Spark SQL、PySpark 等分散式框架處理大數據。FTP 用於文件傳輸。備份工具用於數據備份。版本控制用於管理程式碼。
#41
★★
基於密度的聚類演算法(如 DBSCAN)在處理數據時,具有哪項優點,尤其是在異常值偵測方面?
答案解析
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) 是一種基於密度的聚類方法。它不需要預先指定聚類數量,可以發現任意形狀的聚類。其核心思想是,如果一個點的鄰域內包含足夠多的點,則它是一個核心點,密度相連的核心點形成聚類。那些鄰域內點數不足且不屬於任何聚類邊界的點,會被標記為噪聲點,因此 DBSCAN 可以同時完成聚類和異常值(噪聲)偵測。K-Means 需要指定 K 且通常假設聚類為球狀。DBSCAN 對參數(鄰域半徑 Eps 和最小點數 MinPts)和距離度量敏感,計算複雜度可能較高。

#42
★
以下哪項不是數據聚合操作的常見例子?
答案解析
數據聚合是指將一組數據值匯總成一個或少數幾個代表性值的過程。計算平均值(Mean)、總和(Sum)、計數(Count)、最大值(Max)、最小值(Min)等都是典型的聚合操作。將客戶姓名轉換為大寫是一種數據轉換或數據清理操作,它作用於單個數據值,而不是將多個值匯總成一個。
#43
★★
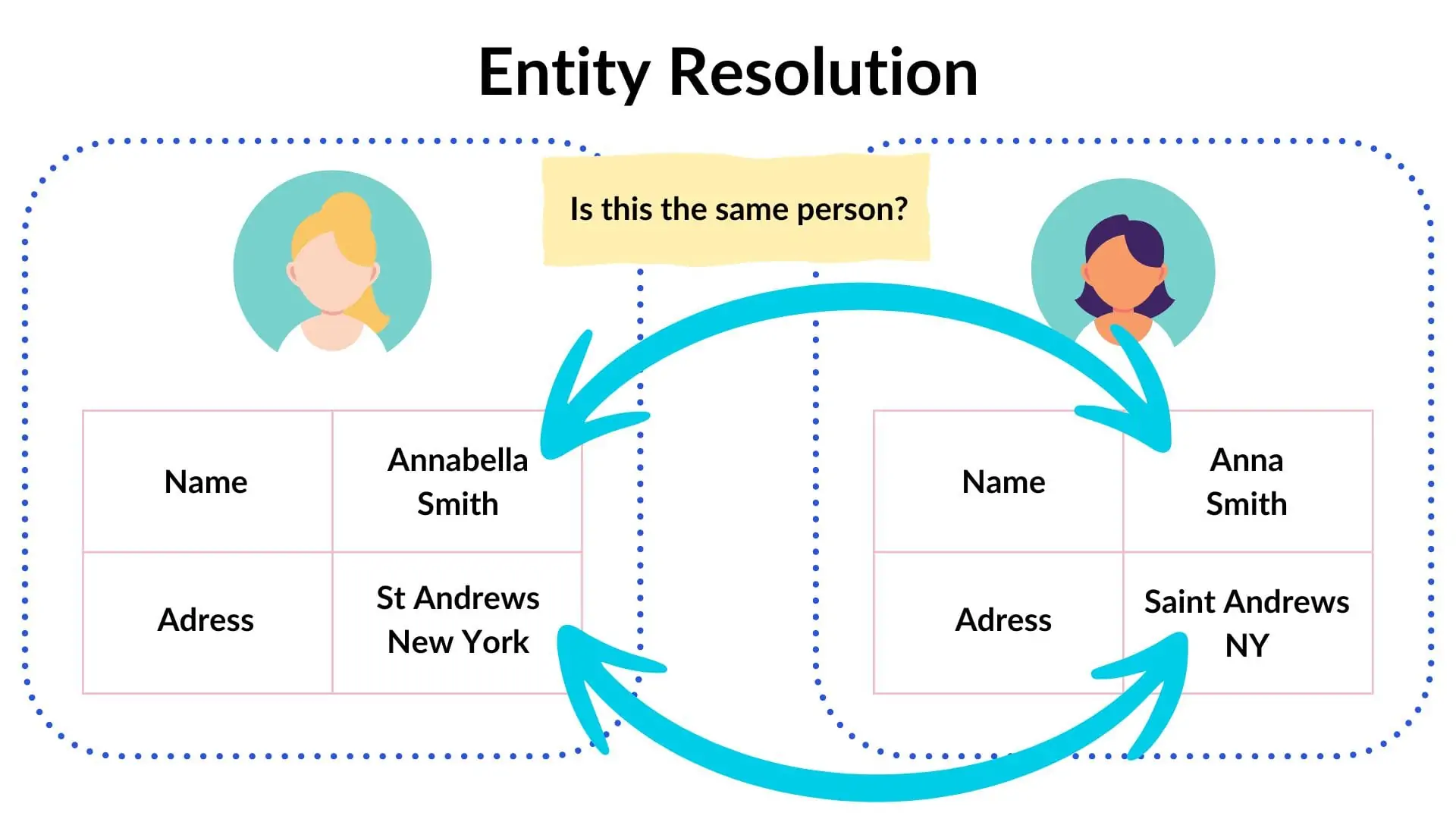
數據整合過程中,"實體解析" (Entity Resolution) 主要解決什麼問題?
答案解析
當從多個來源整合數據時,同一個真實世界的實體(例如,同一個客戶)可能在不同的來源中有不同的表示方式或不同的識別碼。實體解析(也稱為記錄連結 Record Linkage 或重複偵測 Duplicate Detection,但更側重於跨來源)的任務就是找出這些指向同一實體的不同紀錄,並將它們連結起來,以避免重複計算或得到不一致的分析結果。
#44
★★★
下列哪種情況下,使用歸一化 (Min-Max Scaling) 可能比標準化 (Standardization) 更合適?
答案解析
歸一化(Min-Max Scaling)的主要特點是將數據嚴格地縮放到一個固定的區間(通常是 [0, 1])。當後續使用的演算法或模型對輸入數據的數值範圍有明確要求時(例如,某些神經網路的激活函數或圖像處理流程),歸一化是必要的。標準化後的數據沒有固定的範圍。如果數據近似常態分佈,標準化通常效果更好。歸一化對異常值敏感。標準化會改變零值的意義(轉換後均值為0)。
#45
★
在 ETL 流程中,哪一個階段通常計算成本最高、最耗時?
答案解析
在傳統的 ETL 流程中,轉換(Transform)階段通常是最複雜、計算成本最高、也最耗時的環節。因為它涉及到數據清理、驗證、標準化、整合、業務邏輯計算、聚合等多種操作,這些操作可能需要大量的 CPU 和記憶體資源,尤其是在處理大量數據時。萃取和載入相對而言,主要是 I/O 操作,雖然也可能遇到瓶頸,但轉換階段的計算複雜性往往是主要挑戰。這也是 ELT 模式興起的原因之一,將複雜的轉換推遲到載入後進行。
#46
★★
主成分分析 (PCA) 在降維前,通常建議先對數據進行哪種預處理?
答案解析
PCA 是通過尋找數據方差最大的方向來確定主成分的。如果不同特徵的尺度(數值範圍或單位)差異很大,那麼方差會被尺度大的特徵所主導,導致 PCA 結果偏向這些特徵。為了避免這種情況,使得每個特徵對主成分的貢獻更加公平,通常在應用 PCA 之前需要對數據進行標準化(使其均值為0,標準差為1)。雖然移除缺失值也是必要的預處理,但標準化對於 PCA 本身的運作更為關鍵。
#47
★
若要在 Python Pandas 中選取 DataFrame 的前 5 行數據進行快速查看,應使用哪個方法?
答案解析
`.head(n)` 方法用於返回 DataFrame 或 Series 的前 n 行數據,預設 n=5。`.tail(n)` 用於返回後 n 行。`.iloc[]` 用於基於整數位置的索引。`.sample(n)` 用於隨機抽取 n 行。因此,查看前 5 行應使用 `.head(5)` 或直接 `.head()`。
#48
★★★
數據雜訊(Noise)指的是數據中存在的隨機誤差或無意義的變異。以下哪項是處理數據雜訊的常用方法?
答案解析
處理數據雜訊的目標是減少隨機誤差對數據分析的影響。常用的方法包括:1. 分箱(Binning):將相鄰的值分組到同一個箱中,然後用箱的平均值、中位數或邊界值替換箱內所有值。2. 回歸(Regression):用回歸模型擬合數據,然後用模型的預測值代替原始值。3. 聚類(Clustering):檢測並移除不屬於任何聚類的離群點(可能包含雜訊)。4. 平滑(Smoothing):例如在時間序列中使用移動平均法。選項 A、B、D 都不是處理雜訊的標準方法。
#49
★★★
在 Pandas 中,若要找出並移除 DataFrame 中的完全重複行,保留第一次出現的紀錄,應使用哪個方法?
答案解析
`drop_duplicates()` 方法用於移除 DataFrame 中的重複資料列。可透過 `subset` 參數指定要根據哪些欄位來判斷重複。`keep` 參數則用來控制要保留哪一筆重複的紀錄:`'first'`(保留第一筆,此為預設值)、`'last'`(保留最後一筆)或 `False`(移除所有重複的紀錄)。`dropna()` 用於移除缺失值。`fillna()` 用於填補缺失值。`unique()` 通常用於 Series,會傳回不重複值的陣列。
#50
★
在進行數據整合時,如果兩個來源的數據模式(Schema,即欄位名稱、類型、順序)不同,需要先進行哪個步驟?
答案解析
當整合來自不同來源、具有不同結構的數據時,首要步驟之一是理解並協調這些不同的數據模式。數據模式映射涉及識別不同來源中語意相同但名稱或格式可能不同的欄位,並定義它們之間的對應關係。數據模式轉換則可能涉及重命名欄位、改變數據類型、調整欄位順序等操作,以使來自不同來源的數據能夠在一個統一的結構下進行合併或比較。這是數據整合中的關鍵挑戰。
沒有找到符合條件的題目。
↑