iPAS AI應用規劃師 考試重點
L22203 數據處理技術與工具
主題分類
1
數據清理 (Data Cleaning)
2
數據轉換 (Data Transformation)
3
數據集成 (Data Integration)
4
數據規約 (Data Reduction)
5
ETL 流程 (ETL Process)
6
Python 數據處理工具 (Pandas)
7
分散式處理技術 (Hadoop & Spark)
8
數據處理中的挑戰
#1
★★★★★
數據清理 (Data Cleaning / Cleansing) - 目的
核心概念
數據清理是數據預處理 (Data Preprocessing) 的關鍵步驟,旨在識別和修正數據集中的錯誤、不一致和缺失的部分,以提高數據質量,確保後續分析或模型訓練的準確性和可靠性。
"Garbage In, Garbage Out" (GIGO) 原則強調了數據清理的重要性。
"Garbage In, Garbage Out" (GIGO) 原則強調了數據清理的重要性。
#2
★★★★★
缺失值處理 (Handling Missing Values)
核心概念
處理數據中缺失值 (Missing Value) 的常見方法:
- 忽略/刪除記錄 (Ignore/Delete Record):如果缺失值佔比小且隨機分佈,可以考慮刪除包含缺失值的整筆記錄。但可能損失信息。
- 忽略/刪除屬性 (Ignore/Delete Attribute):如果某個屬性(欄位)缺失值比例過高,可以考慮刪除整個屬性。
- 手動填充 (Manual Imputation):對於少量缺失值,由領域專家手動填補。耗時且主觀。
- 使用全局常量填充 (Global Constant Imputation):用一個特定值(如 "Unknown", 0, -1)填充。簡單但可能引入偏差。
- 使用統計量填充 (Statistical Imputation):
- 平均數 (Mean):適用於數值型數據,易受異常值影響。
- 中位數 (Median):適用於數值型數據,對異常值較不敏感。
- 眾數 (Mode):適用於類別型數據。
- 使用模型預測填充 (Model-Based Imputation):使用迴歸、分類或其他機器學習模型,根據其他屬性的值來預測缺失值。較複雜但可能更準確。
#3
★★★★
噪聲數據處理 (Handling Noisy Data)
核心概念
噪聲 (Noise) 是指數據中隨機的錯誤或變異。
處理方法(也稱為數據平滑 Data Smoothing):
處理方法(也稱為數據平滑 Data Smoothing):
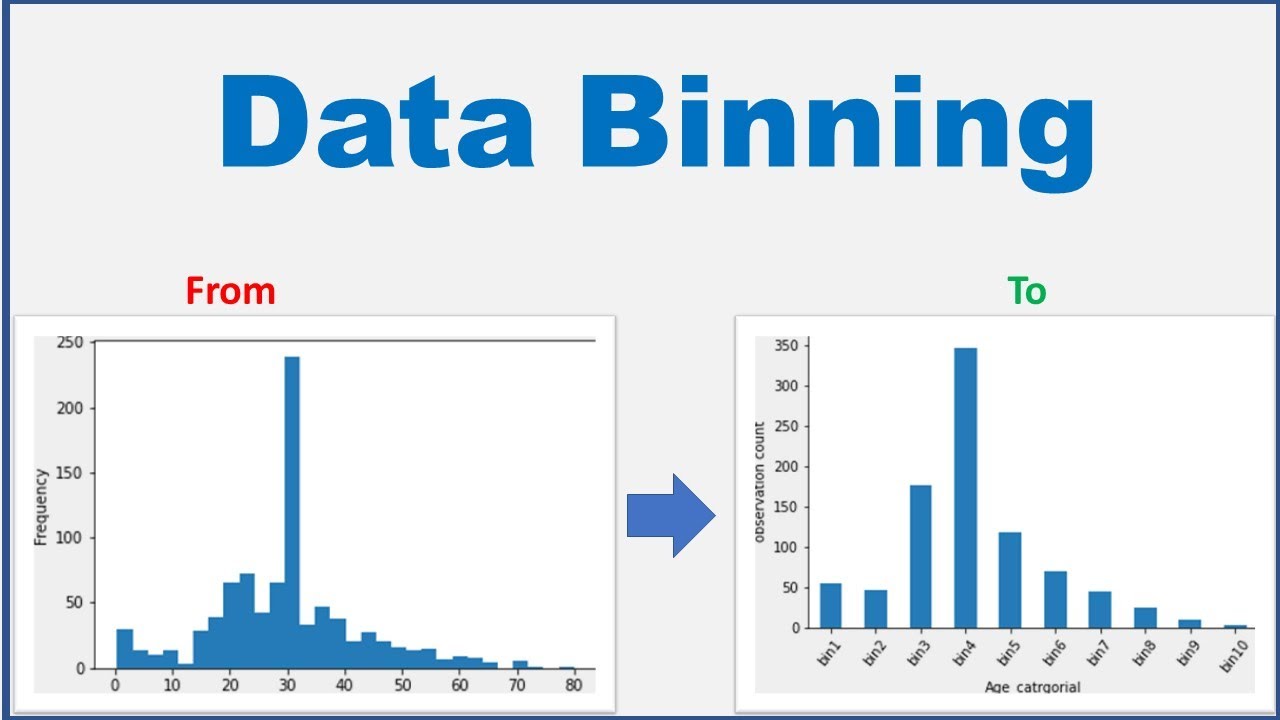
- 分箱 (Binning):將排序後的數據分到不同的"箱"中,然後用箱的平均值、中位數或邊界值替換箱內所有值。
- 迴歸 (Regression):用迴歸模型擬合數據,用模型的預測值替換原始值。
- 聚類 (Clustering):檢測並移除不屬於任何簇的異常點。
- 移動平均 (Moving Average):用於時間序列數據,用鄰近點的平均值替換當前點。
#4
★★★★
異常值檢測與處理 (Outlier Detection and Handling)
核心概念
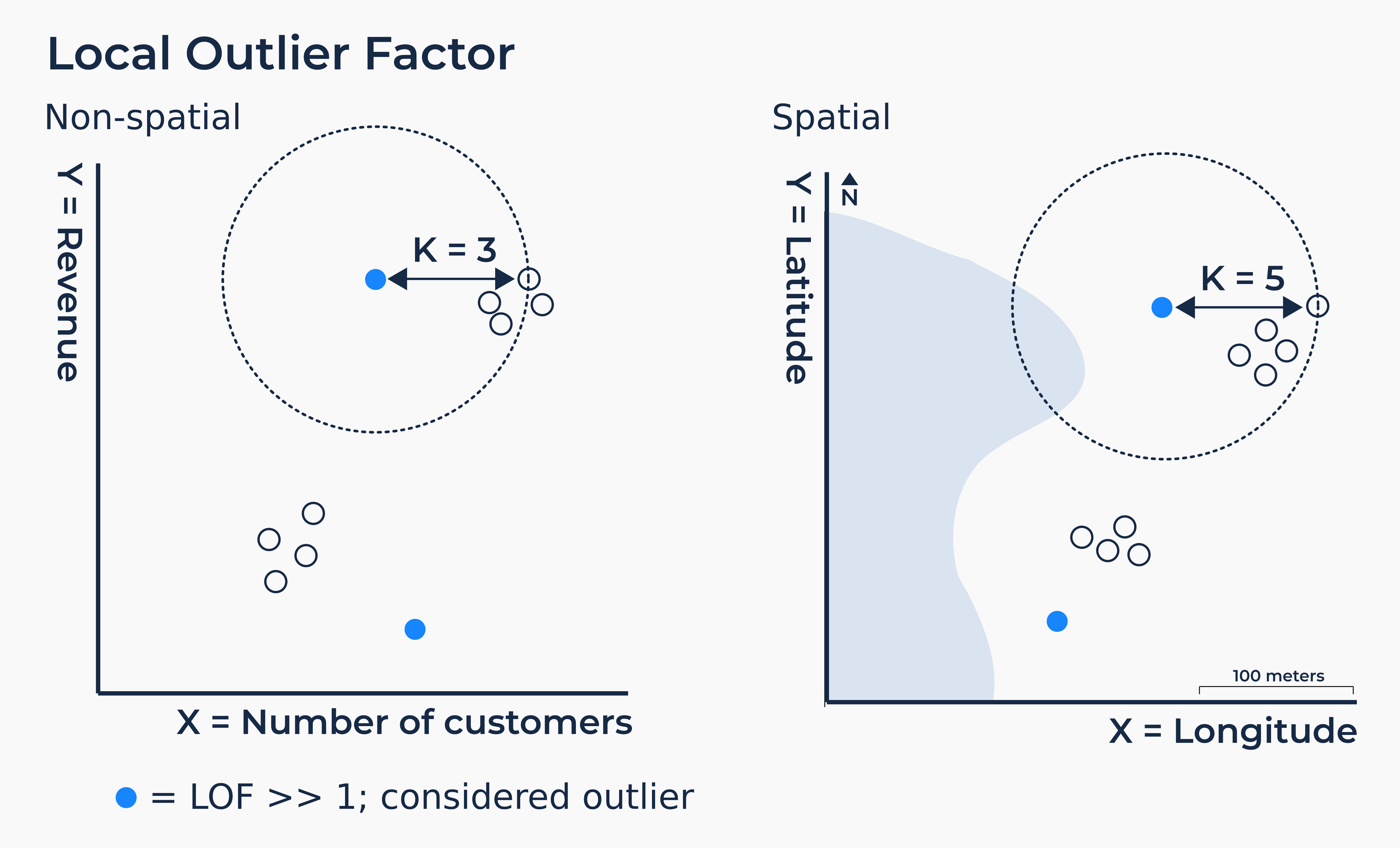
異常值 (Outlier) 是指與數據集中其他觀測值顯著不同的數據點。
檢測方法:
檢測方法:
- 統計方法:基於分佈(如 Z-score 超過閾值)、箱形圖(超出 1.5 * IQR)。
- 基於距離:如 K 最近鄰 (KNN)。
- 基於密度:如 LOF (Local Outlier Factor)。
- 基於聚類。
#5
★★★
重複數據處理 (Handling Duplicate Data)
核心概念
數據集中可能存在完全相同或幾乎相同的記錄。
處理方法:識別重複記錄(基於唯一標識符或多個屬性的組合),然後移除多餘的記錄,只保留一份。 在數據集成 (Data Integration) 後尤其需要檢查重複數據。
處理方法:識別重複記錄(基於唯一標識符或多個屬性的組合),然後移除多餘的記錄,只保留一份。 在數據集成 (Data Integration) 後尤其需要檢查重複數據。
#6
★★★★★
數據轉換 (Data Transformation) - 標準化與正規化
核心概念
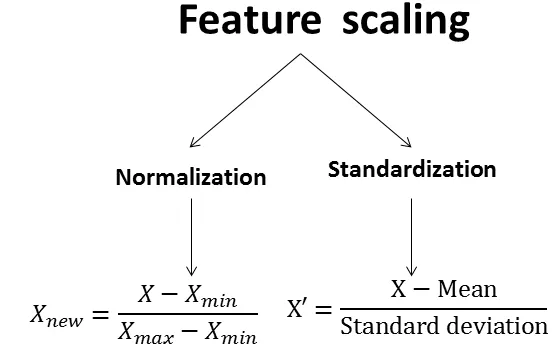
將數據轉換成適合分析或模型訓練的形式。常見的特徵縮放 (Feature Scaling) 方法:
- 正規化 (Normalization) / 最小-最大縮放 (Min-Max Scaling):將數據線性地縮放到一個特定範圍,通常是 [0, 1] 或 [-1, 1]。公式:X_norm = (X - X_min) / (X_max - X_min)。對異常值敏感。
- 標準化 (Standardization) / Z-分數標準化 (Z-score Standardization):將數據轉換為平均值為 0,標準差為 1 的分佈。公式:X_std = (X - μ) / σ。對異常值相對不敏感。
#7
★★★
數據轉換 - 屬性建構 (Attribute Construction / Feature Engineering)
核心概念
通過組合現有屬性或應用函數來創建新的、可能更有用的屬性(特徵)。
例如:
例如:
- 從日期時間中提取年、月、日、星期幾。
- 計算兩個數值屬性的比率或差值。
- 將多個類別合併成一個新的類別。
#8
★★★
數據轉換 - 數據聚合 (Data Aggregation)
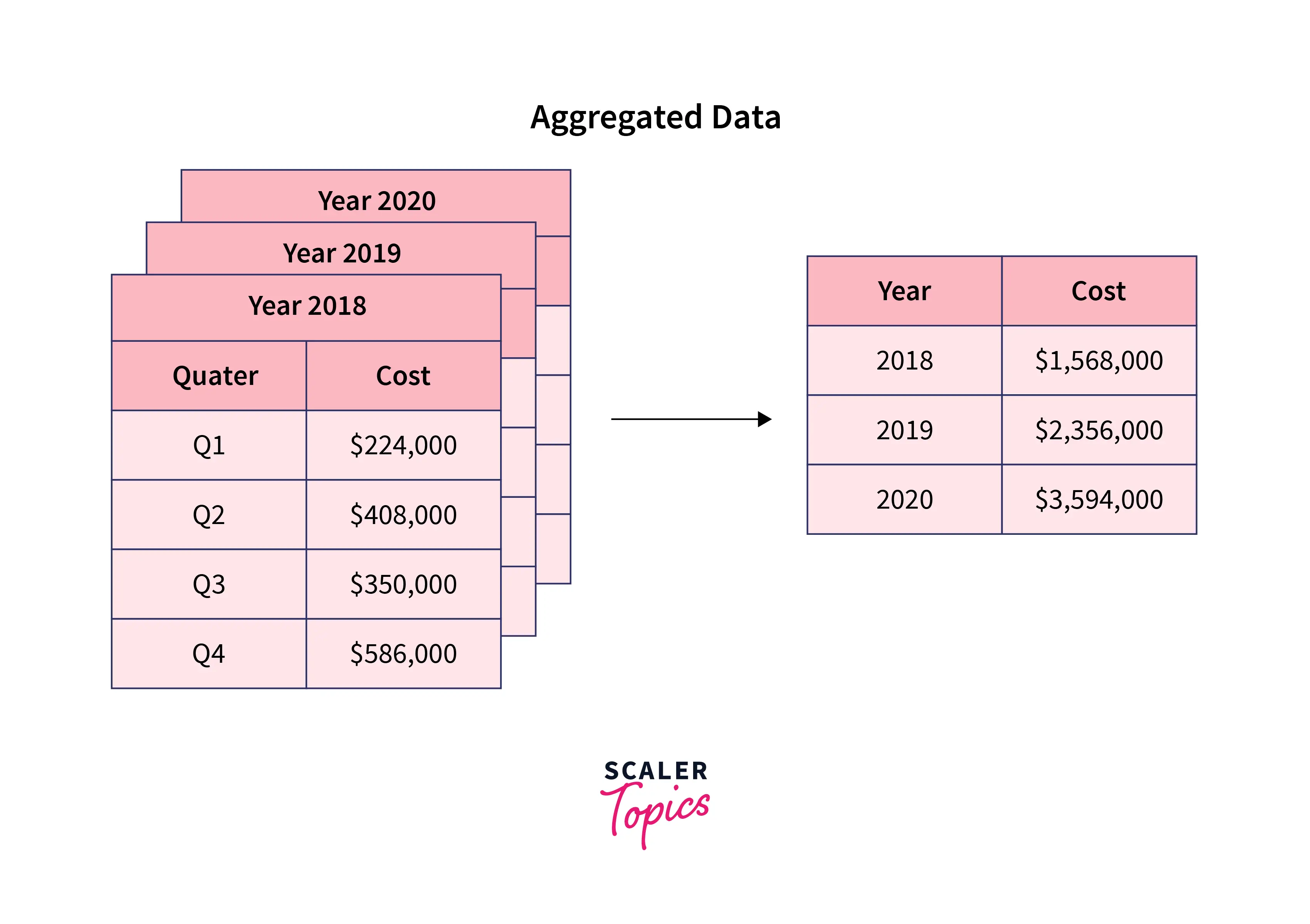
核心概念
將數據匯總或合併成更高層次的摘要信息。
例如:
例如:
- 計算每日銷售總額(從每筆交易數據聚合)。
- 計算每個地區的平均客戶年齡。
#9
★★★★
數據轉換 - 離散化 (Discretization)
核心概念
將連續屬性的值劃分成有限數量的區間(bins),並將每個區間映射到一個離散的類別標籤。
方法:
方法:
- 等寬分箱 (Equal-width Binning):將數值範圍劃分成寬度相等的區間。
- 等頻分箱 (Equal-frequency Binning / Quantile Binning):將數據劃分成包含大致相同數量數據點的區間。

#10
★★★★
數據集成 (Data Integration) - 概念與挑戰
核心概念
數據集成是指將來自多個異構數據源(如資料庫、文件、API)的數據合併成一個統一、一致的數據集。
主要挑戰:
主要挑戰:
- 實體識別問題 (Entity Identification Problem):識別不同數據源中指向同一真實世界實體的記錄(如識別不同系統中的同一個客戶)。
- 模式集成 (Schema Integration):處理不同數據源的屬性名稱、格式、單位的差異。
- 數據值衝突 (Data Value Conflict):同一實體的同一屬性在不同來源中有不同的值。
- 冗餘與相關性 (Redundancy and Correlation):合併後可能出現重複的屬性或高度相關的屬性。
#11
★★★
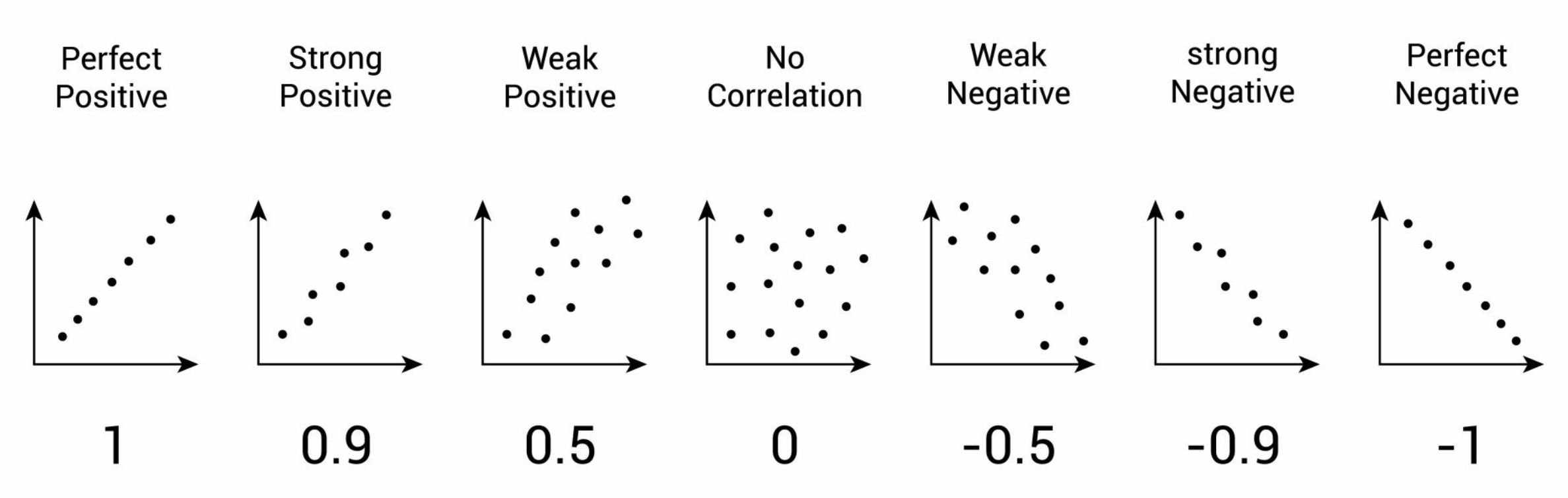
數據集成 - 冗餘與相關性分析
核心概念
在集成數據時,需要檢測和處理冗餘。如果一個屬性可以從其他屬性"推導"出來,則可能是冗餘的。
分析方法:
分析方法:
- 相關係數 (Correlation Coefficient):對於數值屬性,計算皮爾森相關係數。高相關性(接近+1或-1)可能表示冗餘。
- 卡方檢定 (Chi-squared Test):對於類別屬性,檢定它們之間是否獨立。顯著相關可能表示冗餘。

#12
★★★★★
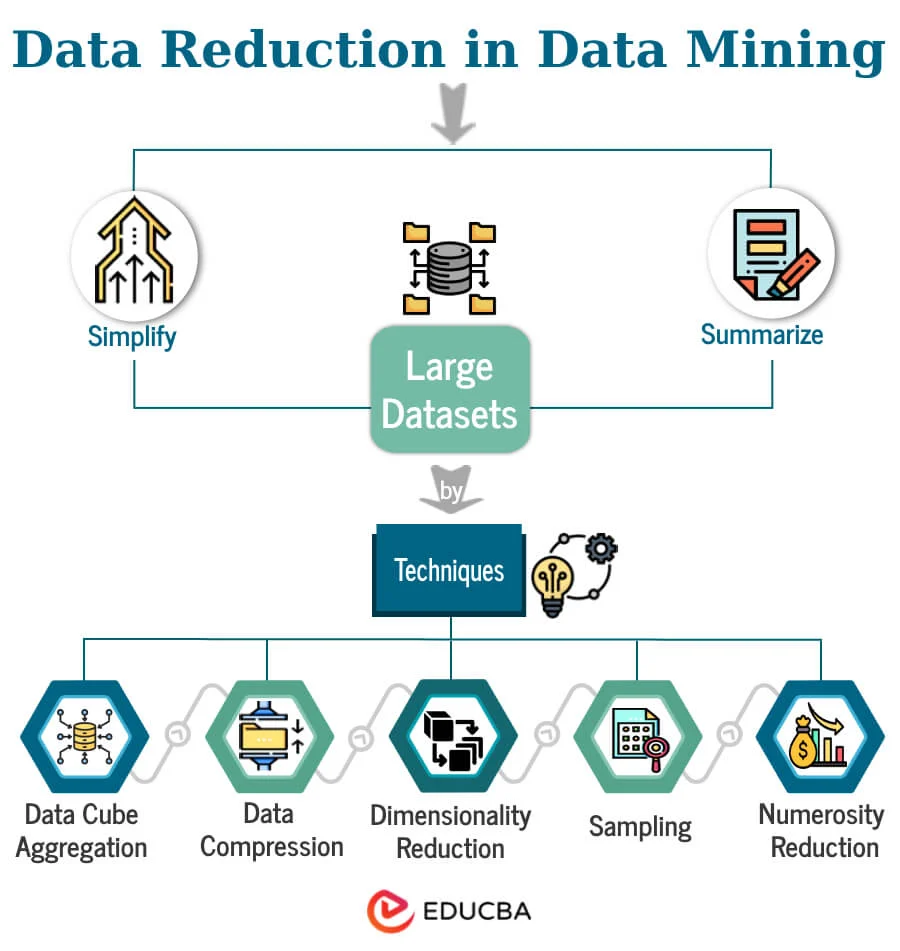
資料規約 (Data Reduction) - 目的與策略
核心概念
資料規約旨在獲得資料集的簡化表示,但保持其資訊的完整性(或損失最小)。
目的:
目的:
- 提高儲存效率。
- 減少計算時間和成本。
- 簡化模型,可能提高模型泛化能力,避免維度災難 (Curse of Dimensionality)。
- 維度規約 (Dimensionality Reduction):減少屬性(特徵)的數量。
- 數量規約 (Numerosity Reduction):減少記錄的數量。
- 資料壓縮 (Data Compression)。
#13
★★★★★
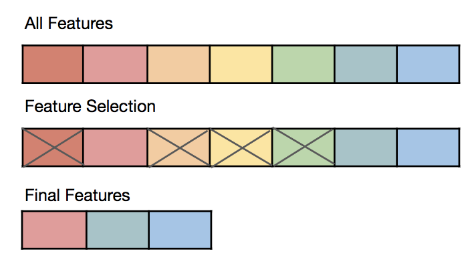
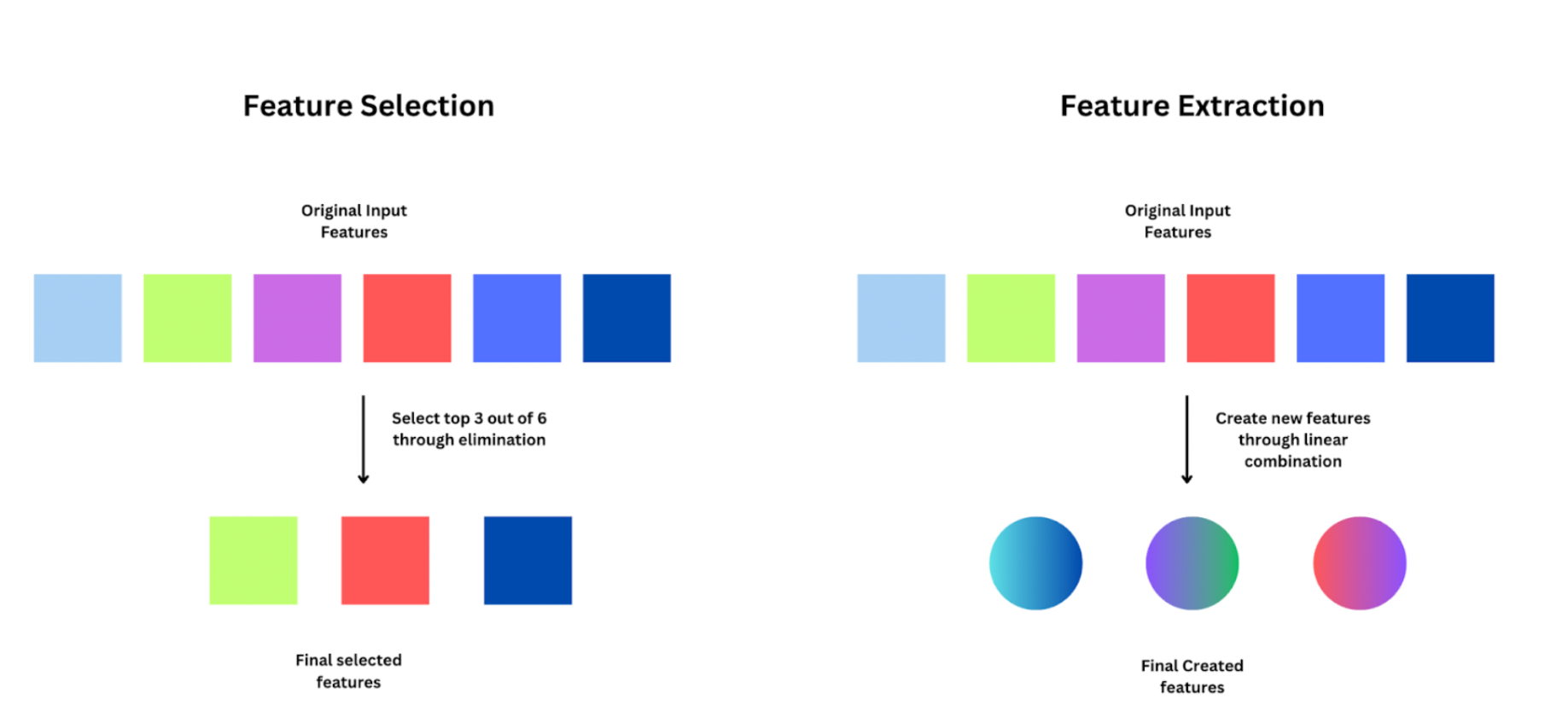
維度規約 - 特徵選擇 vs 特徵提取
核心概念
減少數據維度(屬性/特徵數量)的兩種主要方法:
- 特徵選擇 (Feature Selection):從原始特徵集中選出一個子集,移除不相關或冗餘的特徵。保持原始特徵的物理意義。方法包括過濾法 (Filter)、包裹法 (Wrapper)、嵌入法 (Embedded)。
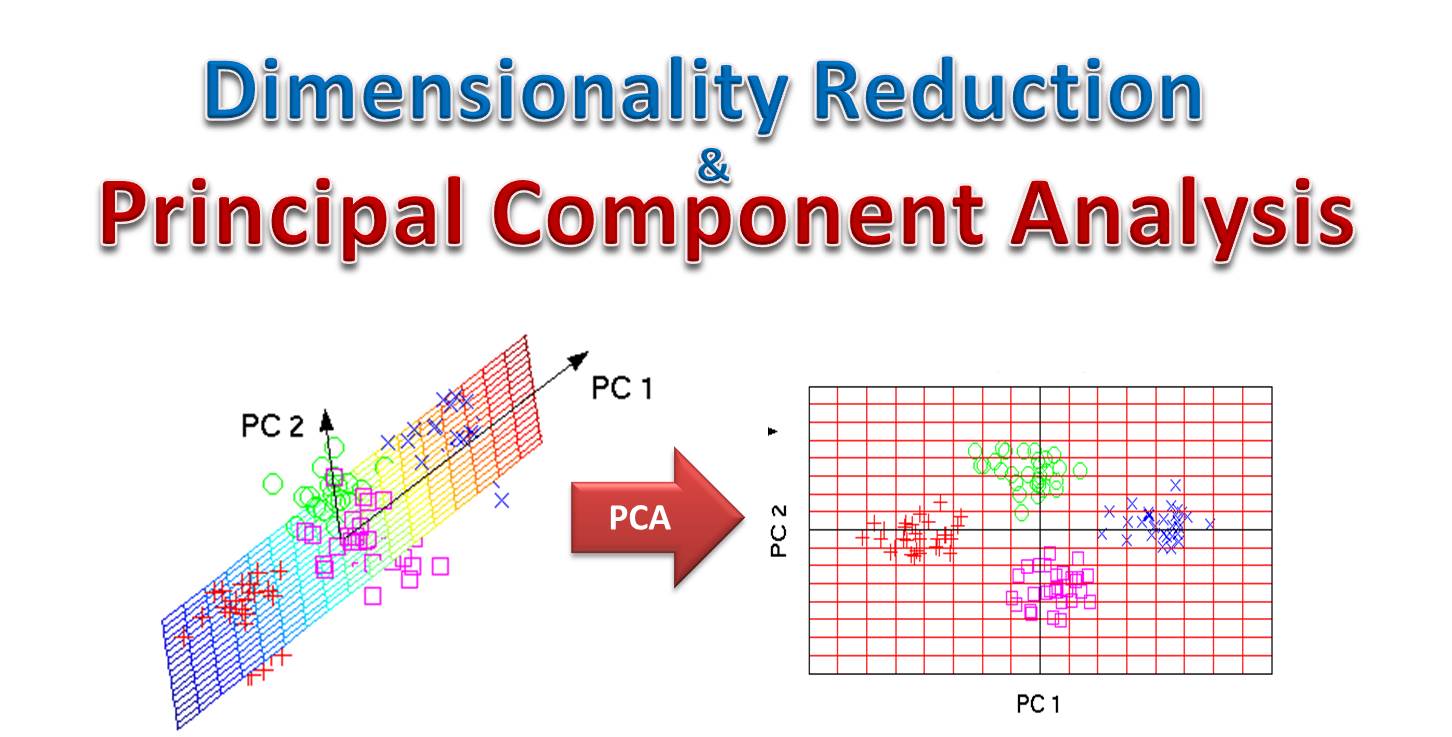
- 特徵提取 (Feature Extraction):將原始高維數據轉換到一個新的低維空間,生成新的、數量較少的特徵,這些新特徵是原始特徵的組合。新特徵可能失去原始物理意義。常用方法如主成分分析 (PCA)。
#14
★★★★
主成分分析 (PCA)
核心概念
主成分分析 (Principal Component Analysis, PCA) 是一種常用的無監督線性特徵提取方法。
目標:找到一組新的正交(不相關)軸(稱為主成分),使得數據在這些軸上的投影變異數最大化。
過程:計算數據的協方差矩陣,找到其特徵值和特徵向量。特徵值表示對應主成分解釋的變異量大小,特徵向量定義了主成分的方向。
應用:選擇特徵值最大的前 k 個主成分作為新的低維表示,達到降維目的,同時保留盡可能多的原始數據變異信息。
目標:找到一組新的正交(不相關)軸(稱為主成分),使得數據在這些軸上的投影變異數最大化。
過程:計算數據的協方差矩陣,找到其特徵值和特徵向量。特徵值表示對應主成分解釋的變異量大小,特徵向量定義了主成分的方向。
應用:選擇特徵值最大的前 k 個主成分作為新的低維表示,達到降維目的,同時保留盡可能多的原始數據變異信息。
#15
★★★
數量規約 (Numerosity Reduction)
核心概念
減少數據記錄(樣本)的數量。
方法:
方法:
- 抽樣 (Sampling):從大數據集中選取一個具有代表性的子集(如簡單隨機抽樣、分層抽樣)。
- 數據聚合 (Data Aggregation):將相似的數據點合併(如聚類後用簇中心代表)。
- 參數化模型:用模型參數代替數據(如用線性迴歸的係數代替原始點)。
#16
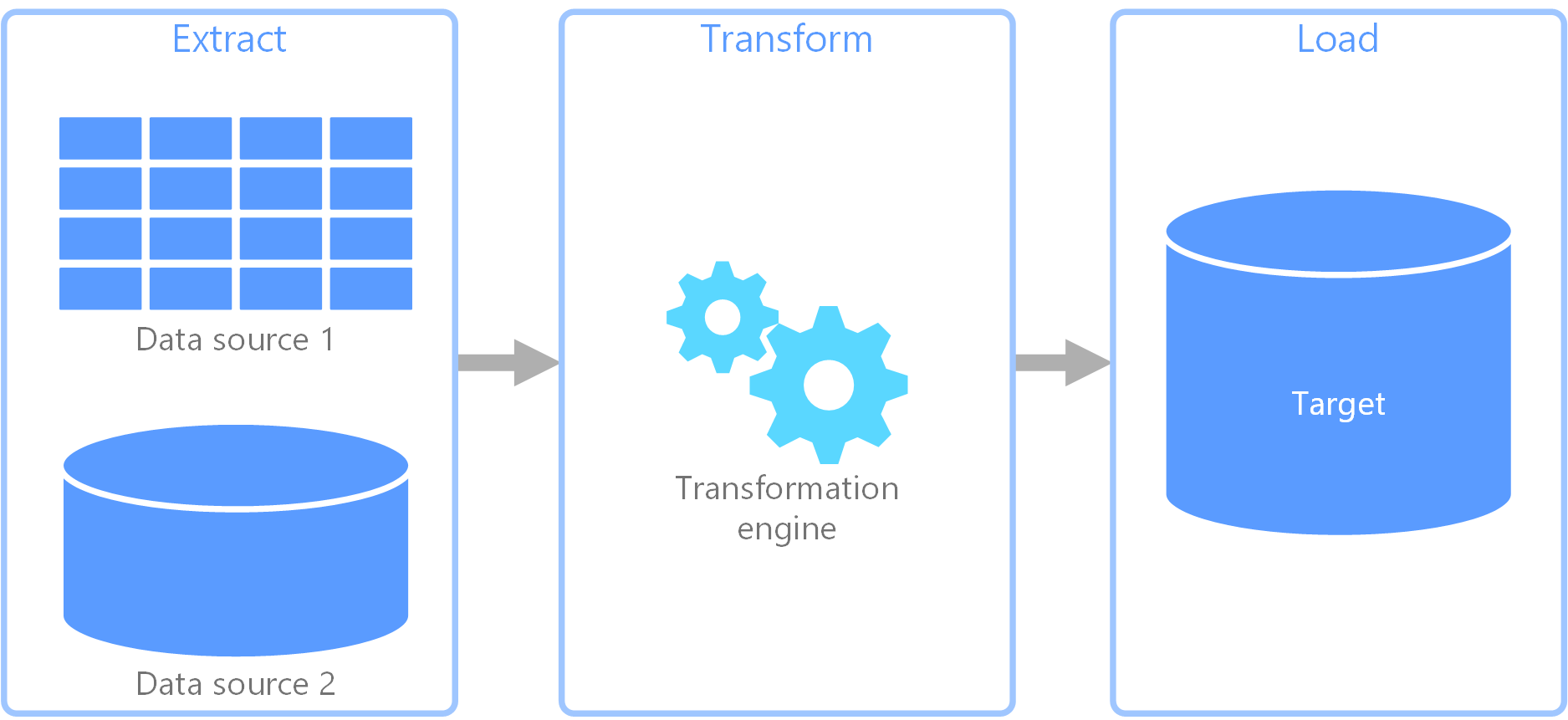
★★★★★
ETL 流程 (Extract, Transform, Load)
核心概念
ETL 是構建資料倉儲 (Data Warehouse) 或數據湖 (Data Lake) 的核心過程,包含三個階段:
- 抽取 (Extract):從一個或多個源系統(如資料庫、應用程式、文件)中讀取和收集數據。
- 轉換 (Transform):對抽取的數據進行清理、轉換、整合,使其符合目標系統的格式和要求。這是最複雜的階段,包括數據清理、數據轉換、數據集成等操作。
- 載入 (Load):將轉換後的數據寫入目標系統(如資料倉儲、數據市集)。
#17
★★★
ETL 工具
核心概念
有許多專門的軟體工具可以幫助實現 ETL 流程,提供圖形化界面來設計、管理和監控數據流。
常見工具包括:
常見工具包括:
- Informatica PowerCenter
- Microsoft SQL Server Integration Services (SSIS)
- Talend Open Studio
- AWS Glue
- Apache NiFi
- 基於程式碼的解決方案(如使用 Python 的 Pandas, Spark)
#18
★★★★★
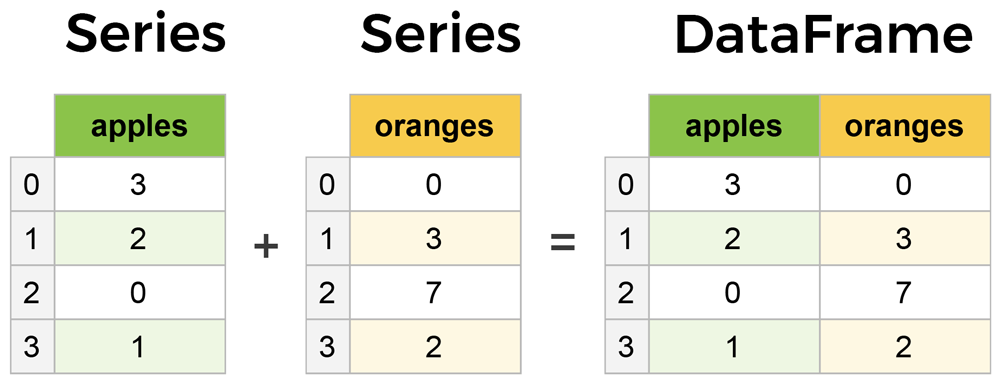
Python 數據處理庫:Pandas
核心概念
Pandas 是 Python 中用於數據處理和分析的核心函式庫。
主要數據結構:
主要數據結構:
- Series:一維帶標籤的陣列,類似於帶索引的列表或字典。
- DataFrame:二維帶標籤的表格數據結構,包含行索引和列索引,類似於關聯式資料庫的表格或 Excel 工作表。
#19
★★★★
Pandas DataFrame - 常用操作
核心概念
DataFrame 常用操作:
- 數據讀取/寫入:`pd.read_csv()`, `pd.read_excel()`, `df.to_csv()`
- 查看數據:`df.head()`, `df.tail()`, `df.info()`, `df.describe()`
- 選擇數據:
- 按標籤:`df.loc[...]`
- 按位置:`df.iloc[...]`
- 條件選擇:`df[df['column'] > value]`
- 缺失值處理:`df.isnull()`, `df.dropna()`, `df.fillna()`
- 數據合併/連接:`pd.concat()`, `pd.merge()`
- 分組聚合:`df.groupby().agg()`
- 數據轉換:`df.apply()`, `df.map()`
#20
★★★★
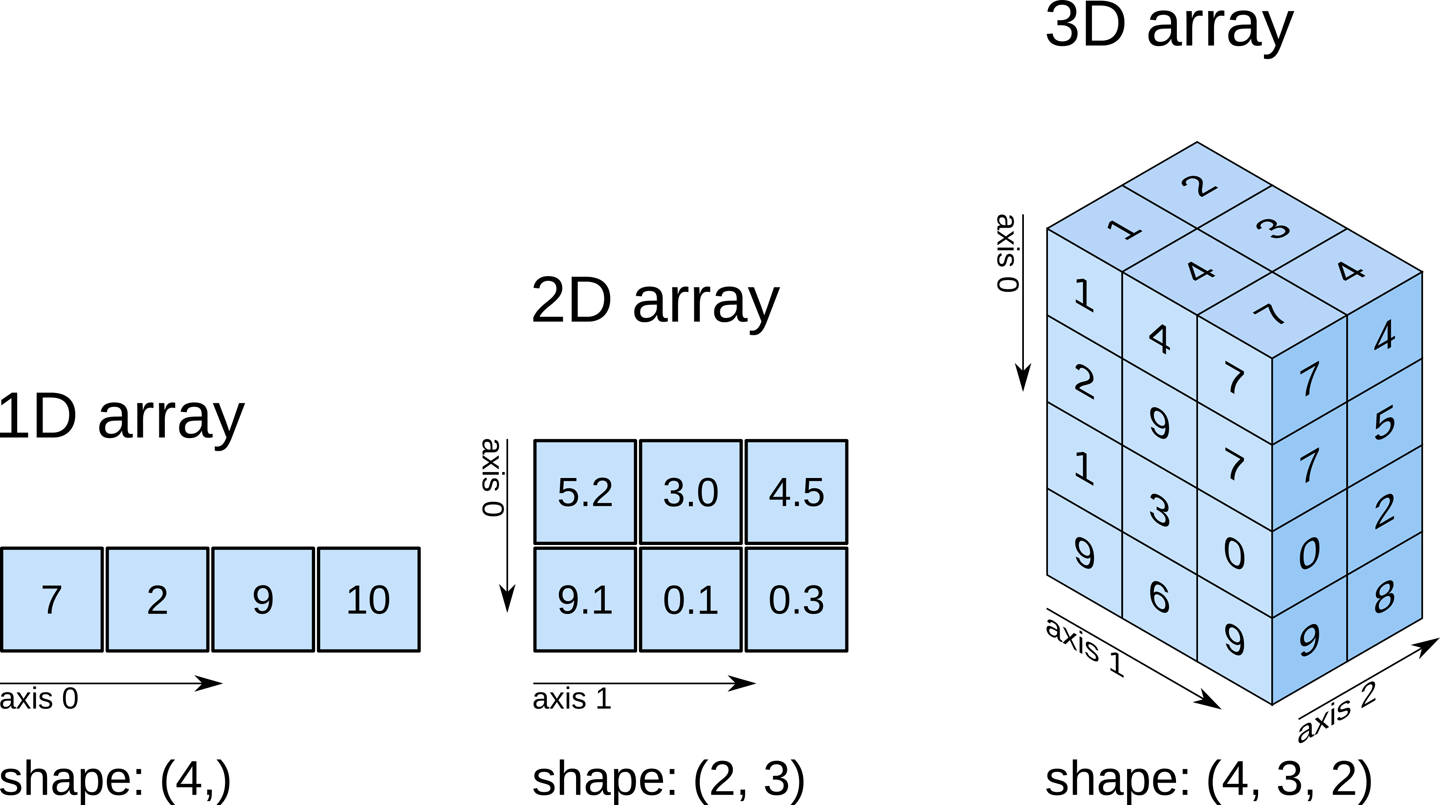
Python 數據處理庫:NumPy
核心概念
NumPy (Numerical Python) 是 Python 進行科學計算的基礎套件。
核心是ndarray (n-dimensional array) 物件,提供高效的多維陣列操作。
主要功能:
核心是ndarray (n-dimensional array) 物件,提供高效的多維陣列操作。
主要功能:
- 高效的數值運算(向量化操作)。
- 線性代數、傅立葉變換、隨機數生成等功能。
- 是許多其他科學計算庫(包括 Pandas, Scikit-learn)的底層依賴。
#21
★★★★
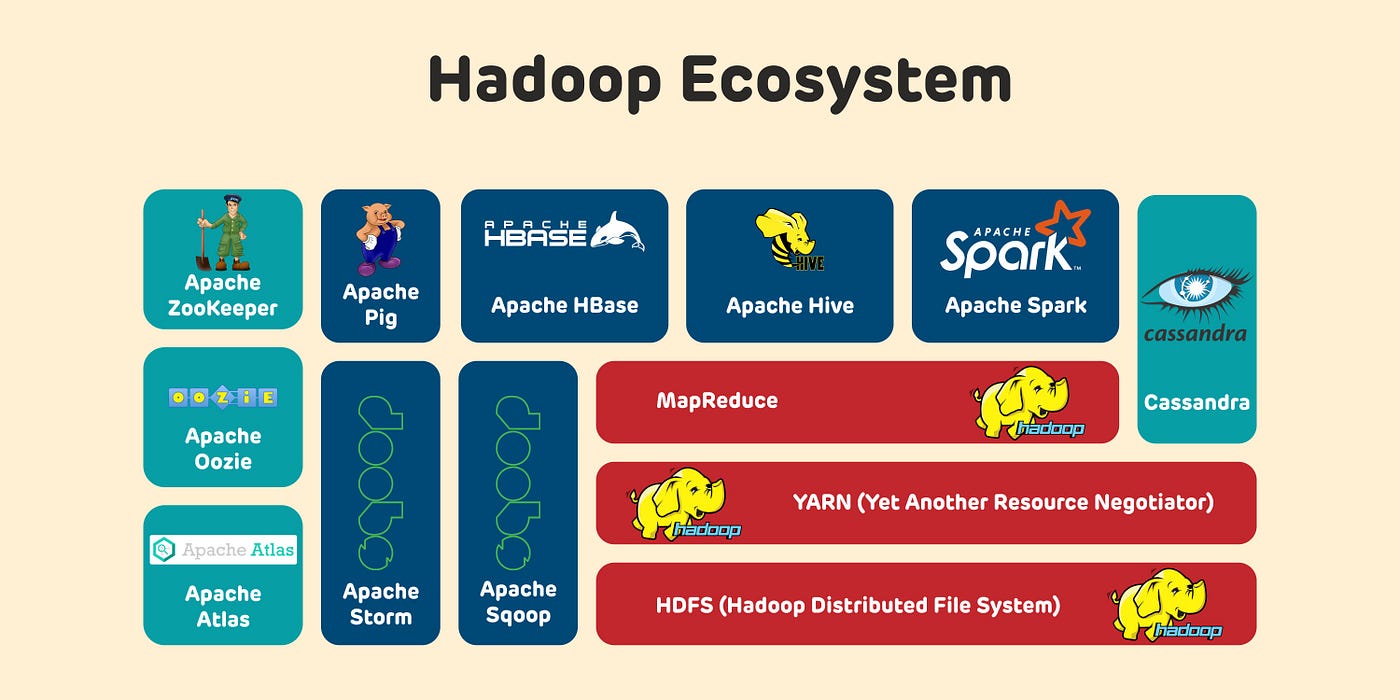
分散式處理技術 - Hadoop 簡介
核心概念
Apache Hadoop 是一個開源框架,用於在計算機集群上進行大規模數據的分散式儲存和處理。
核心組件:
核心組件:
- Hadoop 分散式檔案系統 (HDFS):提供高容錯性的分散式數據儲存。將大文件分割成塊 (Blocks) 儲存在集群的不同節點。
- MapReduce:一個編程模型和處理引擎,用於在集群上並行處理大規模數據集。包含 Map 階段(處理和生成鍵值對)和 Reduce 階段(匯總結果)。
- YARN (Yet Another Resource Negotiator):集群資源管理和作業調度框架。
#22
★★★★★
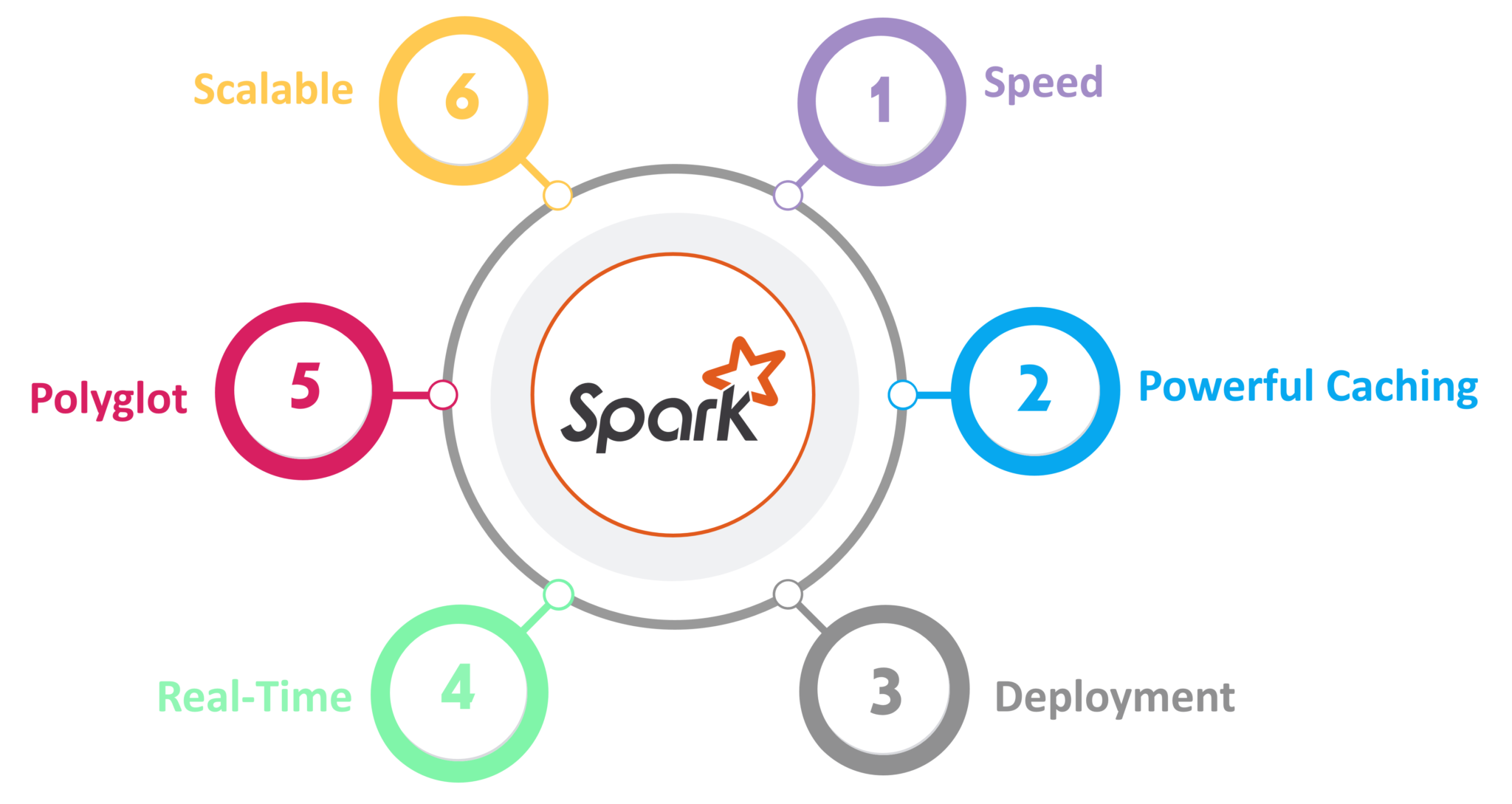
分散式處理技術 - Spark 簡介
核心概念
Apache Spark 是一個快速、通用的集群計算系統。
相較於 Hadoop MapReduce 的主要優勢:
相較於 Hadoop MapReduce 的主要優勢:
- 速度更快:利用記憶體計算 (In-Memory Computing),減少了磁碟 I/O。
- 易用性:提供 Python, Scala, Java, R 的 API。
- 通用性:支持多種計算模式,包括批處理、互動式查詢 (Spark SQL)、流處理 (Spark Streaming / Structured Streaming)、機器學習 (MLlib) 和圖計算 (GraphX)。
#23
★★★★
Spark 核心概念:RDD, DataFrame, Dataset
核心概念
Spark 的數據抽象:
- RDD (Resilient Distributed Dataset):Spark 最初的核心抽象,是不可變、可分區、可並行操作的數據集合。具有容錯性(通過血緣關係 Lineage 重算)。操作分為轉換 (Transformation, 惰性計算) 和行動 (Action, 觸發計算)。
- DataFrame:在 RDD 基礎上增加了模式 (Schema) 信息,類似於關聯式資料庫的表格。提供更豐富的操作接口(類似 Pandas DataFrame)和優化的執行計劃(通過 Catalyst Optimizer)。是 Spark SQL 的基礎。
- Dataset:DataFrame 的擴展,結合了 RDD 的類型安全和 DataFrame 的性能優化。在 Scala 和 Java 中常用。

#24
★★★
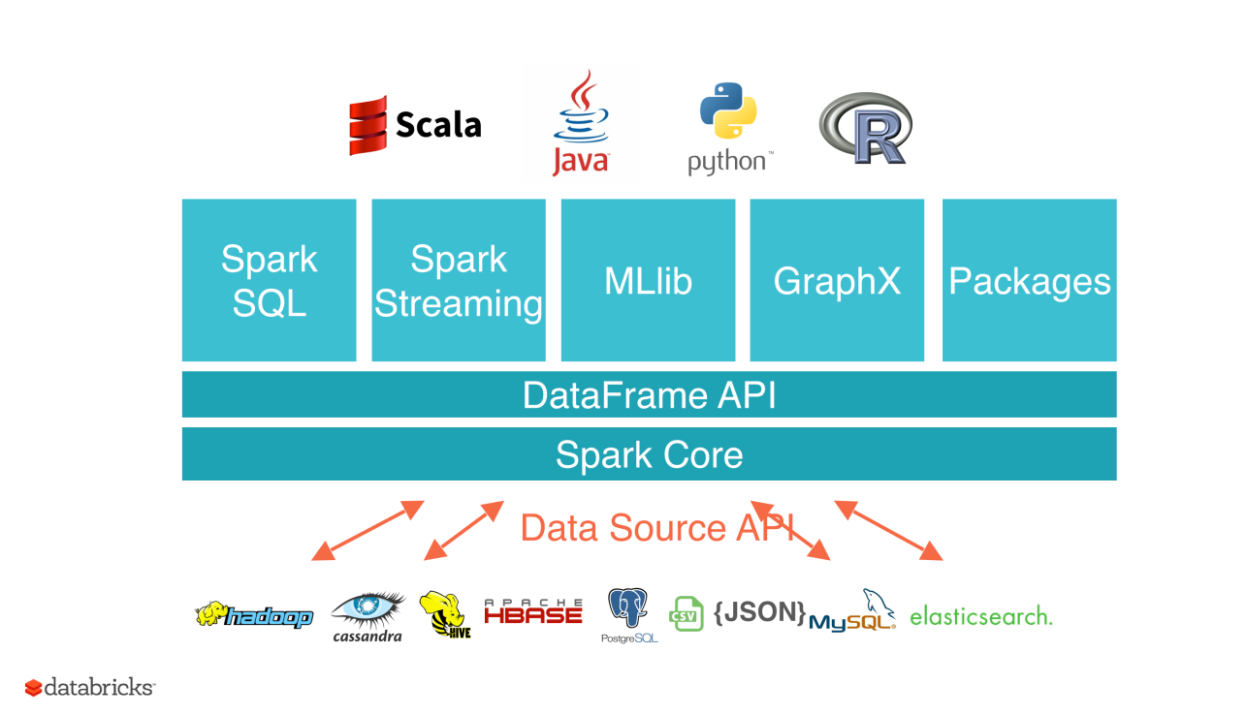
Spark 生態系統組件 (Spark SQL, MLlib 等)
核心概念
Spark 包含多個函式庫,提供統一的計算平台:
- Spark SQL:用於處理結構化數據,可以使用 SQL 語句或 DataFrame/Dataset API 進行查詢。
- Spark Streaming / Structured Streaming:用於處理實時數據流。
- MLlib:提供常用的機器學習算法庫,包括分類、迴歸、聚類、推薦等,以及特徵工程和模型評估工具。
- GraphX:用於圖計算和圖分析。
#25
★★★
數據處理中的挑戰
核心概念
數據處理過程中面臨的主要挑戰:
- 數據質量 (Data Quality):處理缺失值、噪聲、異常值、不一致性、重複數據等。
- 數據量 (Data Volume):處理 TB、PB 甚至更大量級的數據,需要高效的存儲和計算能力(如分散式處理)。
- 數據多樣性 (Data Variety):處理來自不同來源、不同格式(結構化、半結構化、非結構化)的數據。
- 處理速度 (Data Velocity):需要實時或近實時處理快速生成的數據流。
- 數據安全與隱私 (Data Security and Privacy):確保數據在處理過程中的安全,符合法規要求(如 GDPR)。
- 成本 (Cost):存儲和計算資源的成本。
#26
★★★
數據不一致性處理 (Handling Data Inconsistency)
核心概念
數據不一致性指數據中存在相互矛盾或不符合預期模式的信息。例如:
- 命名慣例不一致(如 "Taipei", "TPE")。
- 格式不一致(如日期格式 "YYYY-MM-DD" vs "MM/DD/YYYY")。
- 編碼不一致(如使用不同的字符編碼)。
- 數據值衝突(如年齡與生日不符)。
#27
★★★★
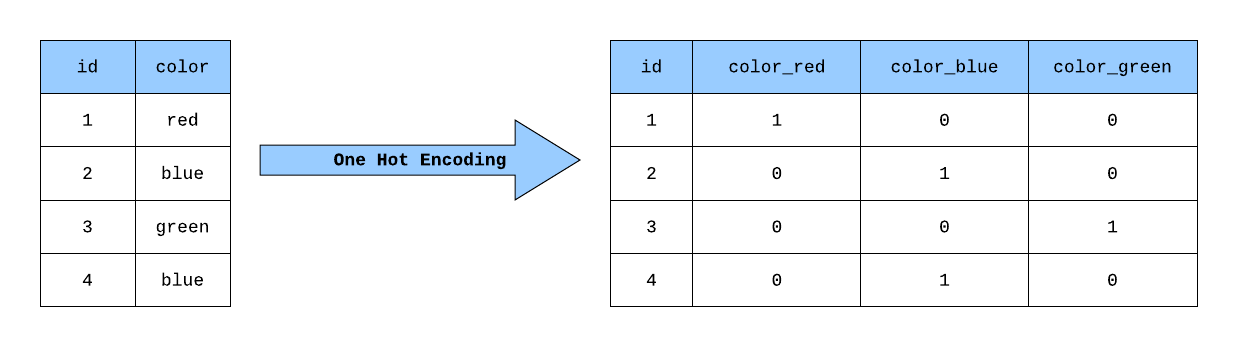
獨熱編碼 (One-Hot Encoding)
核心概念
獨熱編碼是一種常用的將類別變數轉換為數值形式的技術,以便機器學習模型處理。
方法:為類別屬性的每個可能值創建一個新的二元(0或1)屬性。對於某個樣本,其原始類別值對應的新屬性為 1,其他新屬性為 0。
例如,顏色屬性有 "紅", "綠", "藍" 三個值,轉換後會變成三個新屬性:is_Red, is_Green, is_Blue。一個值為 "紅" 的樣本,其 is_Red 為 1,is_Green 和 is_Blue 為 0。
優點:避免了直接用數值(如 0, 1, 2)表示類別可能帶來的虛假順序關係。
缺點:如果類別值非常多,會導致維度急劇增加(高維稀疏)。
方法:為類別屬性的每個可能值創建一個新的二元(0或1)屬性。對於某個樣本,其原始類別值對應的新屬性為 1,其他新屬性為 0。
例如,顏色屬性有 "紅", "綠", "藍" 三個值,轉換後會變成三個新屬性:is_Red, is_Green, is_Blue。一個值為 "紅" 的樣本,其 is_Red 為 1,is_Green 和 is_Blue 為 0。
優點:避免了直接用數值(如 0, 1, 2)表示類別可能帶來的虛假順序關係。
缺點:如果類別值非常多,會導致維度急劇增加(高維稀疏)。
#28
★★★
元數據管理 (Metadata Management)
核心概念
元數據是描述數據的數據。例如,數據的來源、定義、格式、創建時間、所有者、訪問權限等。
在數據集成和數據處理中,良好的元數據管理至關重要:
在數據集成和數據處理中,良好的元數據管理至關重要:
- 幫助理解數據含義和上下文。
- 促進數據發現和重用。
- 追蹤數據血緣關係 (Data Lineage),了解數據的來源和轉換過程。
- 支持數據治理 (Data Governance) 和合規性。
#29
★★★
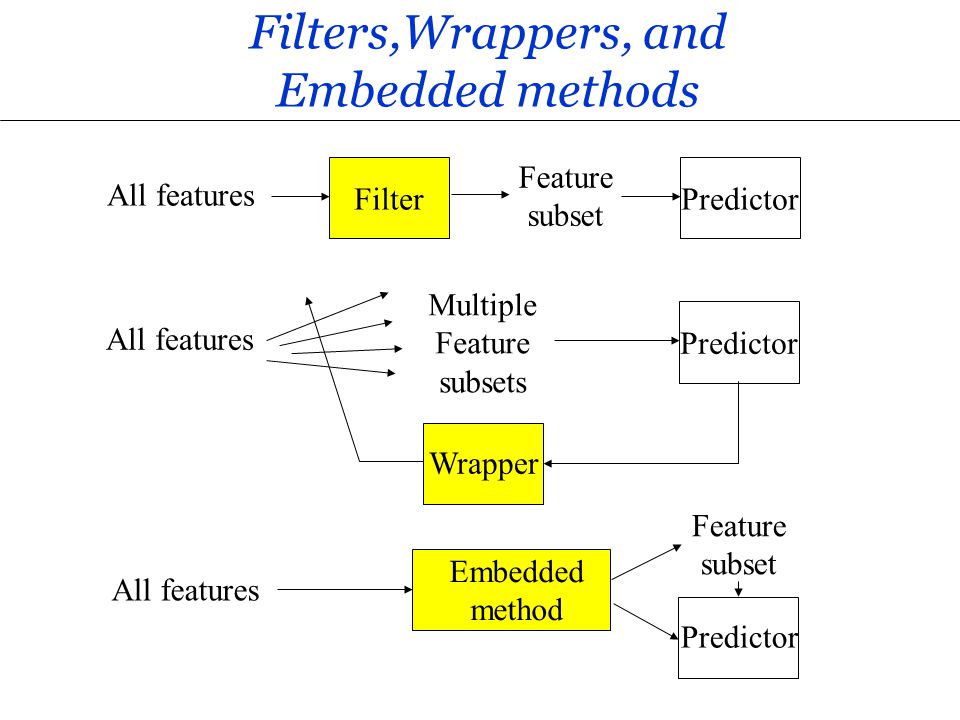
特徵選擇方法 - 過濾法、包裹法、嵌入法
核心概念
常見的特徵選擇策略:
- 過濾法 (Filter Methods):獨立於任何機器學習算法,根據特徵本身的統計特性(如相關性、卡方值、互信息)來評分和排序特徵,選擇得分高的。速度快,但可能選出與特定模型不佳的子集。
- 包裹法 (Wrapper Methods):將特徵子集的選擇視為一個搜索問題,使用特定的機器學習模型來評估不同特徵子集的性能(如準確率)。效果通常較好,但計算成本高。例如:遞歸特徵消除 (RFE)。
- 嵌入法 (Embedded Methods):特徵選擇過程嵌入在模型訓練過程中。模型自身學習哪些特徵重要。例如:LASSO 迴歸會將不重要特徵的係數壓縮至 0;決策樹/隨機森林可以提供特徵重要性評分。
#30
★★★★
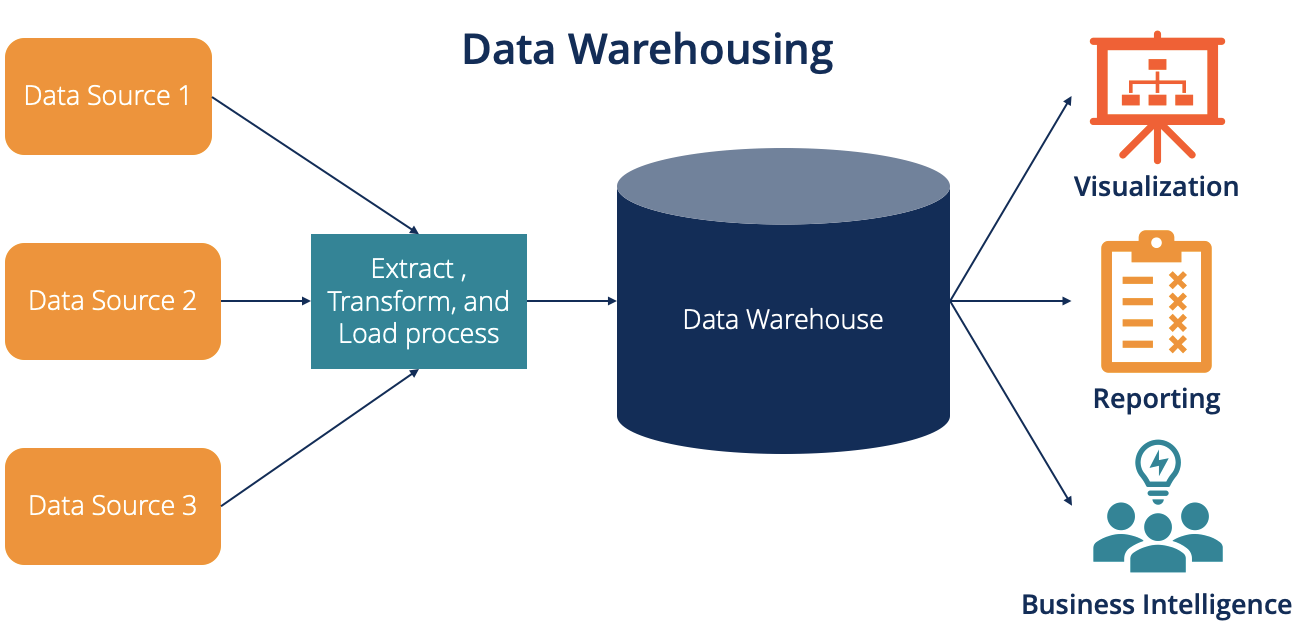
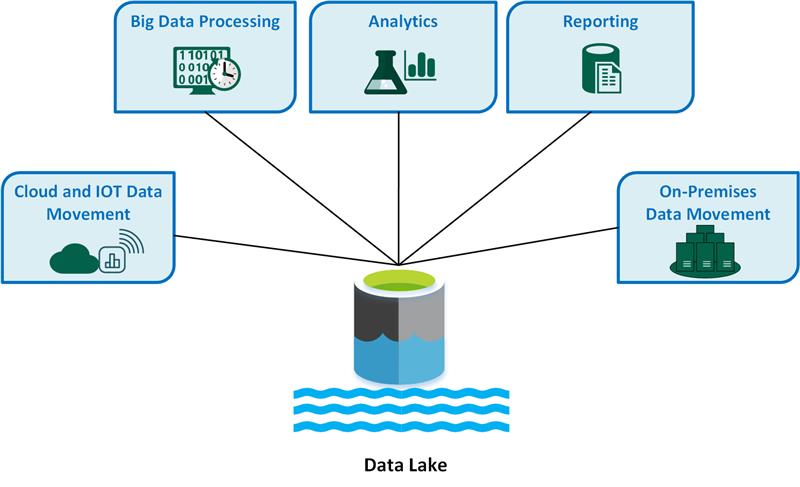
資料倉儲 (Data Warehouse) vs 數據湖 (Data Lake)
核心概念
兩者都是用於存儲大量數據的系統,但設計理念不同:
- 資料倉儲:主要存儲經過清洗、轉換、整合後的結構化數據,數據具有明確定義的模式 (Schema-on-Write)。主要用於商業智慧 (BI) 和報表。
- 數據湖:可以存儲各種格式的原始數據,包括結構化、半結構化和非結構化數據,模式在讀取時定義 (Schema-on-Read)。更加靈活,適用於數據探索、機器學習等需要原始數據的場景。
#31
★★★★
Pandas - 時間序列處理
核心概念
Pandas 提供了強大的時間序列數據處理能力:
- 時間戳 (Timestamp) 和時間區間 (Period) 資料類型。
- 創建日期範圍:`pd.date_range()`。
- 將字串轉換為日期時間:`pd.to_datetime()`。
- 設置時間索引 (DatetimeIndex)。
- 時間重採樣 (Resampling):將時間序列數據聚合到不同的頻率(如從每日到每月)。
- 移動窗口 (Rolling Window) 計算:計算移動平均、移動標準差等。
- 時間位移 (Shifting) 和滯後 (Lagging)。
#32
★★★
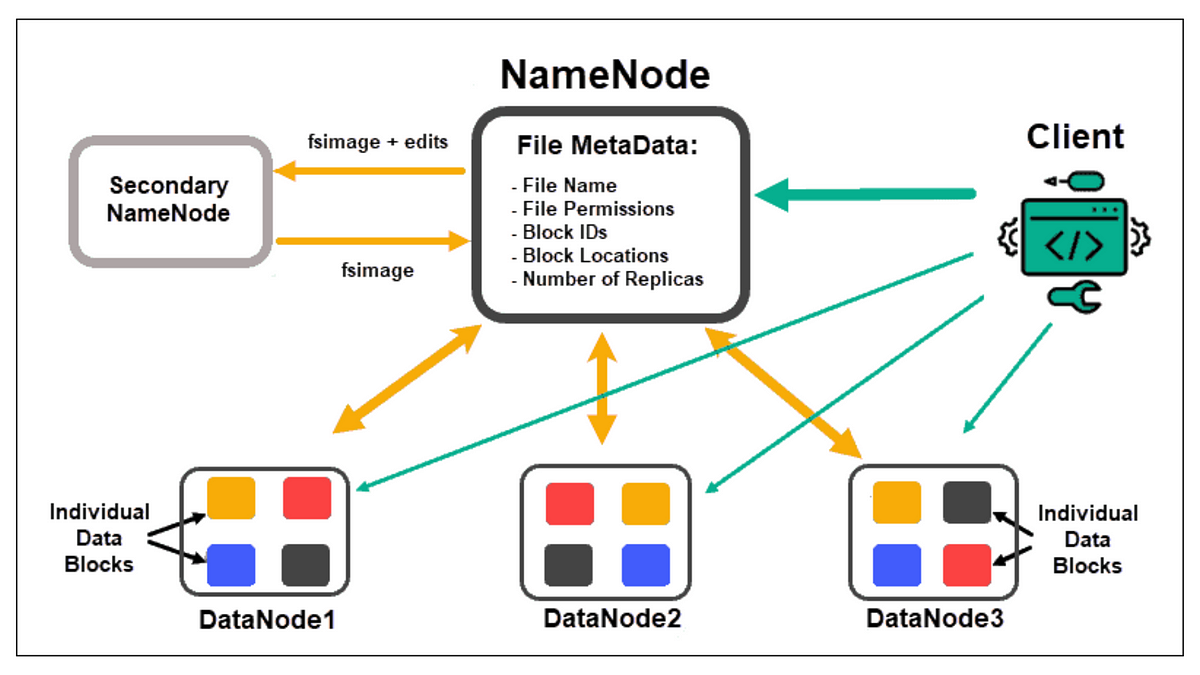
HDFS (Hadoop Distributed File System) - 特性
核心概念
HDFS 的主要特性:
- 處理超大文件:設計用於存儲 GB、TB 甚至 PB 級別的文件。
- 流式數據訪問 (Streaming Data Access):優化目標是高吞吐量,而非低延遲。適合一次寫入、多次讀取的場景。
- 運行於商用硬體 (Commodity Hardware):設計用於普通、廉價的硬體集群,通過軟體實現可靠性。
- 高容錯性:通過數據塊複製(默認複製 3 份)來保證數據在節點故障時的可用性。
- 架構:主從架構,包含一個 NameNode(管理元數據)和多個 DataNode(存儲數據塊)。
#33
★★★
MapReduce 編程模型
核心概念
MapReduce 是一種簡化的並行編程模型,用於處理大規模數據集。
核心思想:分而治之 (Divide and Conquer)。
核心思想:分而治之 (Divide and Conquer)。
- Map 階段:將輸入數據分割成小塊,每個 Map 任務處理一塊數據,應用 Map 函數,輸出中間鍵值對 (Key-Value Pairs)。
- Shuffle & Sort 階段:(框架自動處理)將 Map 輸出的鍵值對按鍵進行分組和排序。
- Reduce 階段:每個 Reduce 任務處理一個或多個鍵及其對應的值列表,應用 Reduce 函數,匯總結果,輸出最終結果。
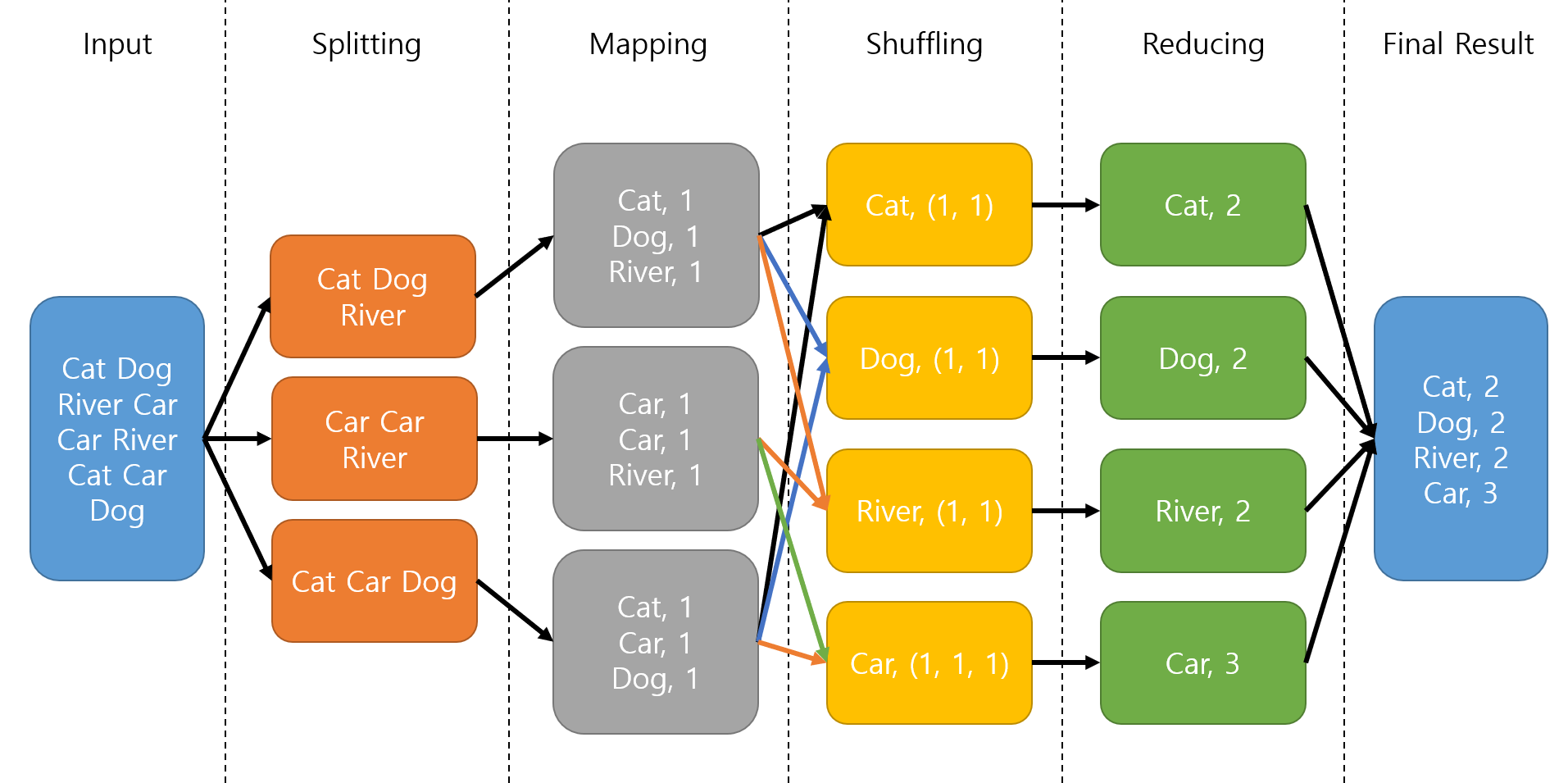
#34
★★★
數據治理 (Data Governance) 在數據處理中的作用
核心概念
數據治理是指對組織數據資產的可用性、可用性、完整性和安全性進行管理的整體方法。
在數據處理中的作用:
在數據處理中的作用:
- 確保數據質量標準的建立和執行。
- 定義數據所有權和責任。
- 管理元數據和數據血緣關係。
- 確保數據處理符合法規要求(如隱私保護)。
- 制定數據安全策略和訪問控制。
#35
★★★
Pandas - 處理類別數據
核心概念
Pandas 提供了處理類別數據 (Categorical Data) 的專用功能:
- Categorical 數據類型:比使用 object (字串) 類型更節省記憶體,並能表示數據的類別性質。可使用 `df['col'].astype('category')` 轉換。
- 獲取類別信息:`.cat.categories` (獲取所有類別), `.cat.codes` (獲取每個值對應的內部整數編碼)。
- 類別操作:添加/刪除類別、重命名類別、設置類別順序。
- 與獨熱編碼結合:使用 `pd.get_dummies()` 函數可以方便地對 Categorical 或 object 類型的列進行獨熱編碼。
沒有找到符合條件的重點。
↑