iPAS AI應用規劃師 經典題庫
L22202 數據儲存與管理
出題方向
1
數據儲存基礎與演進
2
關聯式資料庫與資料倉儲 (Data Warehouse)
3
NoSQL 資料庫原理與類型
4
分散式檔案系統 (Distributed File System)
5
資料湖 (Data Lake) 與資料湖倉 (Lakehouse)
6
雲端儲存服務與架構
7
數據管理、備份與安全
8
儲存技術選型與比較
#1
★★★★
相較於傳統的檔案系統,大數據時代的儲存系統主要需要解決什麼核心問題?
答案解析
大數據(Big Data)最顯著的特徵之一就是數據量(Volume)巨大,傳統單機檔案系統無法有效儲存和管理 PB(Petabyte)甚至 EB(Exabyte)等級的數據。因此,大數據儲存系統(如分散式檔案系統 HDFS)的核心目標是透過水平擴展(horizontal scaling)將數據分散儲存在多台機器上,以應對海量數據的挑戰。雖然數據壓縮和可靠性也很重要,但處理超大規模數據是其最根本的驅動力。

#2
★★★★
資料倉儲(Data Warehouse)的主要目的是什麼?
答案解析
資料倉儲是一個專門設計用於報告和數據分析的系統。它通常會從企業內部的多個營運系統(如 ERP, CRM)中抽取(Extract)、轉換(Transform)、載入(Load)結構化的歷史數據(此過程稱為 ETL),並將其整理成適合分析的模式(如星型模型、雪花模型)。主要目標是提供一個統一、乾淨、一致的數據視圖,以支援管理階層的決策制定和商業智慧應用,而非處理日常交易或儲存原始、未經處理的非結構化數據。
#3
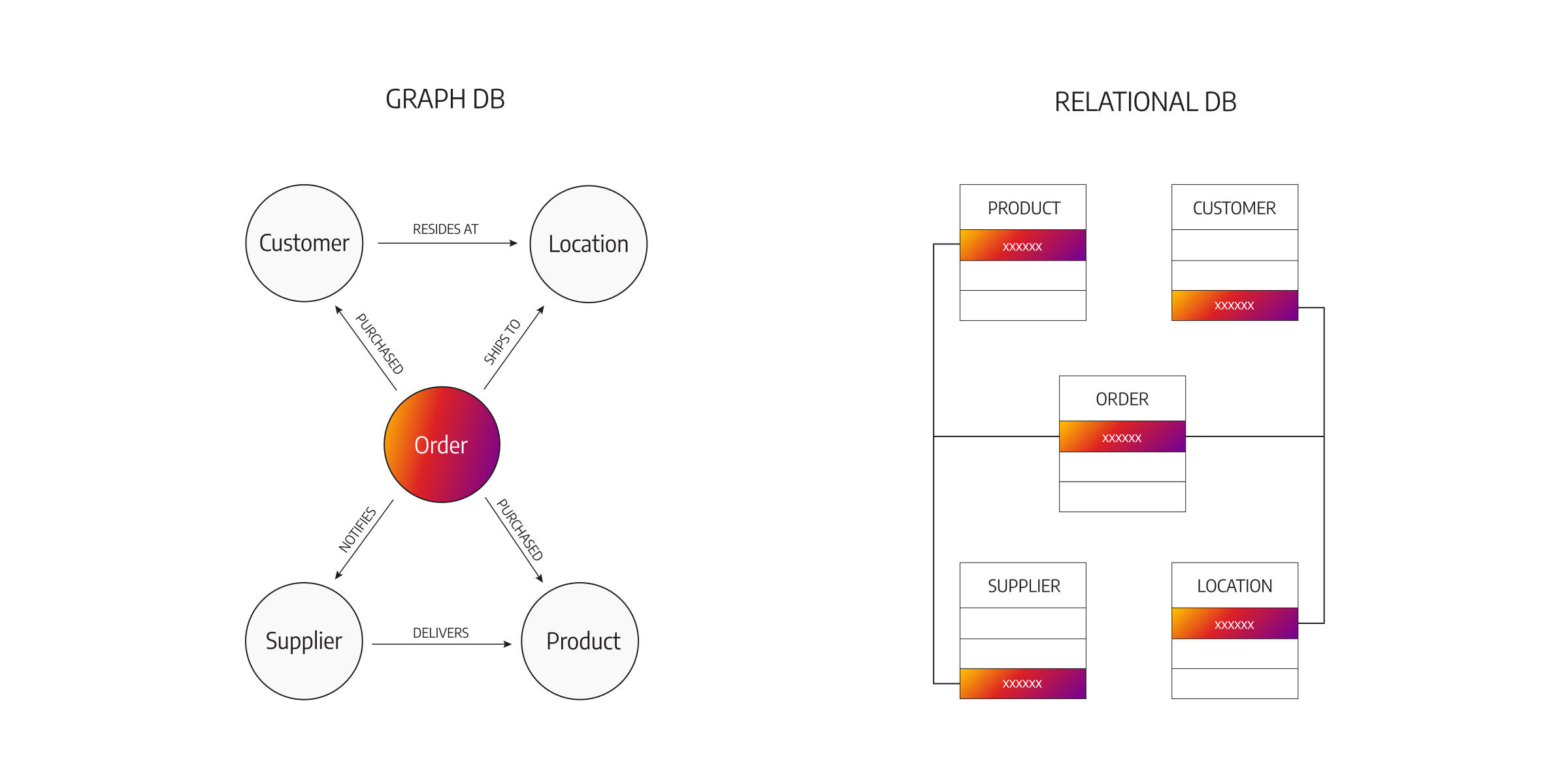
★★★★★
下列哪一種 NoSQL 資料庫類型最適合儲存和查詢具有複雜關係的數據,例如社交網路圖譜或推薦系統?
答案解析
圖形資料庫專門設計用來處理節點(Nodes/Vertices)和關係(Relationships/Edges)構成的數據。它非常擅長處理數據之間的連結關係,例如社交網路中的朋友關係、使用者對產品的評分、組織結構等。對於需要頻繁遍歷或查詢多層關係的應用(如找出朋友的朋友、根據使用者關係進行推薦),圖形資料庫通常比其他類型的資料庫(包括關聯式資料庫和其它 NoSQL 類型)更有效率和直觀。
#4
★★★★
HDFS (Hadoop Distributed File System) 設計的主要目標是?
答案解析
HDFS 是 Apache Hadoop 專案的核心組件之一,設計用來在廉價的商用硬體叢集上儲存海量數據(通常是 GB 到 TB 等級的大檔案)。它的設計哲學是「一次寫入,多次讀取」(Write-Once-Read-Many, WORM),並針對高數據吞吐量和串流式讀取進行了優化,非常適合 MapReduce 等批次處理框架。它犧牲了低延遲的隨機讀寫能力,並且對於儲存大量小檔案效率不高(因為每個檔案的元數據都會佔用 NameNode 的記憶體)。
#5
★★★★★
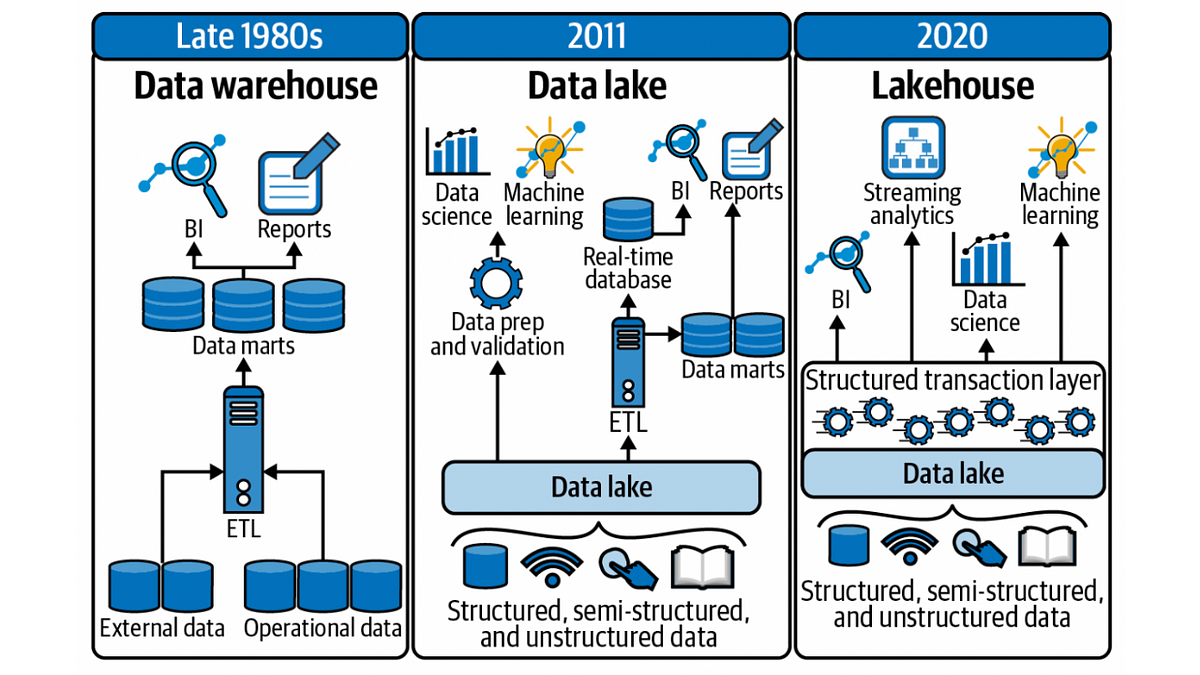
相較於傳統的資料倉儲 (Data Warehouse),資料湖 (Data Lake) 最主要的特點是什麼?
答案解析
資料湖的核心理念是提供一個集中式的儲存庫,可以容納來自各種來源、各種格式的原始數據,而不需要在寫入時就進行嚴格的轉換和結構化。這使得數據可以快速地被收集和儲存,保持其原始的保真度。數據的結構和意義通常是在需要進行分析或查詢時(讀取時)才被解析和應用,這稱為「Schema-on-Read」。這與資料倉儲的「Schema-on-Write」方法形成對比,後者要求數據在載入前就必須符合預定義的綱要。資料湖提供了更大的靈活性,特別是在處理多樣化和快速變化的數據來源時。
#6
★★★★
在公有雲環境中,像 AWS S3 (Amazon Simple Storage Service) 或 Azure Blob Storage 這樣的服務屬於哪一種類型的儲存?
答案解析
物件儲存是一種將數據作為離散單元(物件)進行管理的儲存架構。每個物件包含數據本身、可變數量的元數據以及一個全域唯一的識別碼。物件儲存非常適合儲存大量的非結構化數據,如圖片、影片、備份檔案、日誌檔等。它具有高擴展性、高持久性和成本效益。AWS S3、Azure Blob Storage 和 Google Cloud Storage 都是領先的雲端物件儲存服務。區塊儲存(如 AWS EBS)提供原始區塊設備,通常用於資料庫或需要高效能 I/O 的應用。檔案儲存(如 AWS EFS)提供共享的檔案系統介面。暫存儲存則是臨時性的。
| 特性 | 檔案儲存 (File Storage) | 區塊儲存 (Block Storage) | 物件儲存 (Object Storage) |
|---|---|---|---|
| 儲存單位 | 檔案 (File) | 區塊 (Block) | 物件 (Object) |
| 結構 | 階層式 (目錄/資料夾) | 無結構 (原始磁區) | 扁平式 (Flat Namespace) |
| 存取方式 | 檔案路徑 (NFS, SMB/CIFS) | SCSI, iSCSI, Fibre Channel | 唯一ID (HTTP/REST API) |
| 元數據 | 有限 (檔案名、大小、日期) | 極少 (僅區塊位址) | 豐富且可自訂 |
| 效能特性 | 適合共享檔案存取 | 高效能、低延遲、高IOPS | 高吞吐量、高擴展性 |
| 主要應用 | 檔案共享、NAS | 資料庫、虛擬機磁碟 (SAN) | 大數據、備份、歸檔、雲端原生應用 |
| 雲端範例 | AWS EFS, Azure Files | AWS EBS, Azure Disk Storage | AWS S3, Azure Blob Storage |

#7
★★★
在數據儲存管理中,"3-2-1 備份原則" 是指什麼?
答案解析
3-2-1 備份原則是一個廣泛推薦的數據保護策略,旨在提高數據的冗餘度和災難恢復能力。它的含義是:
3: 至少保留三份數據副本(一份原始數據 + 兩份備份)。
2: 將這些副本儲存在至少兩種不同的儲存媒介上(例如,內接硬碟、外接硬碟、磁帶、雲端儲存等)。
1: 至少將其中一份副本儲存在異地(Off-site),以防止本地發生火災、洪水等災難時所有數據同時損毀。
3: 至少保留三份數據副本(一份原始數據 + 兩份備份)。
2: 將這些副本儲存在至少兩種不同的儲存媒介上(例如,內接硬碟、外接硬碟、磁帶、雲端儲存等)。
1: 至少將其中一份副本儲存在異地(Off-site),以防止本地發生火災、洪水等災難時所有數據同時損毀。

#8
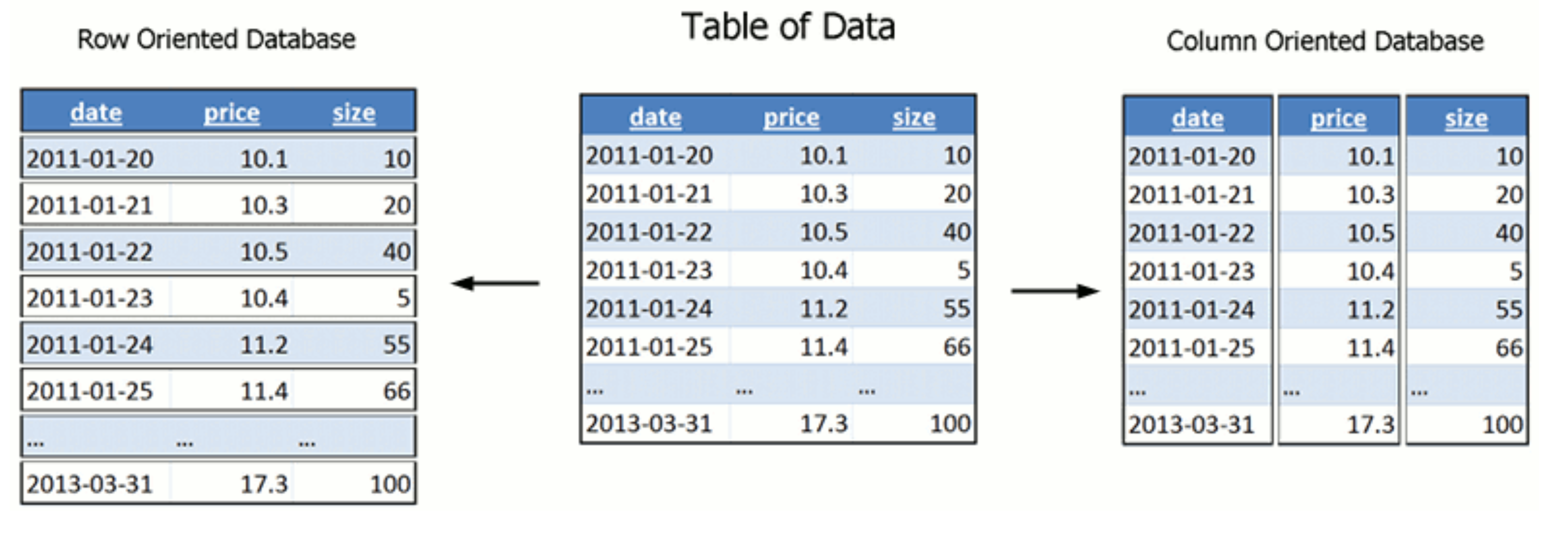
★★★★
對於需要進行複雜分析查詢(例如 OLAP - Online Analytical Processing)的大規模結構化數據集,哪種類型的資料庫通常能提供較好的查詢效能?
答案解析
欄式儲存(Columnar Storage)的資料庫將同一欄位的數據連續儲存在一起,而不是像傳統行式儲存那樣將一整行的數據存在一起。這種儲存方式非常適合分析型查詢(OLAP),因為這類查詢通常只關心表格中的少數幾個欄位(例如計算某個產品的總銷售額),而不是整行數據。欄式儲存可以顯著減少 I/O 操作,因為只需要讀取相關欄位的數據,同時也更利於數據壓縮。許多資料倉儲和分析平台(如 Amazon Redshift, Google BigQuery, Apache Cassandra, ClickHouse)都採用或支援欄式儲存。
#9
★★★★
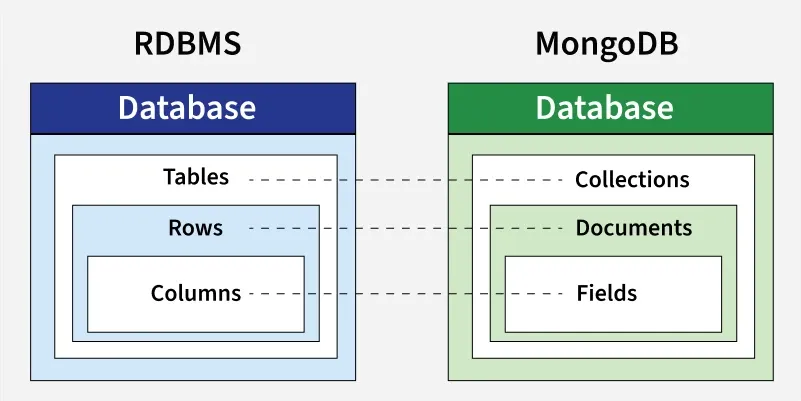
MongoDB 是一種流行的 NoSQL 資料庫,它屬於哪種類型?
答案解析
MongoDB 是一種以文件(Document)為基礎的 NoSQL 資料庫。它將數據儲存為類似 JSON(JavaScript Object Notation)格式的 BSON(Binary JSON)文件,這些文件可以包含嵌套的結構和陣列。文件資料庫提供了靈活的綱要(Flexible Schema),使得儲存和演化複雜的數據結構相對容易,適合內容管理、產品目錄、使用者設定檔等應用場景。
#10
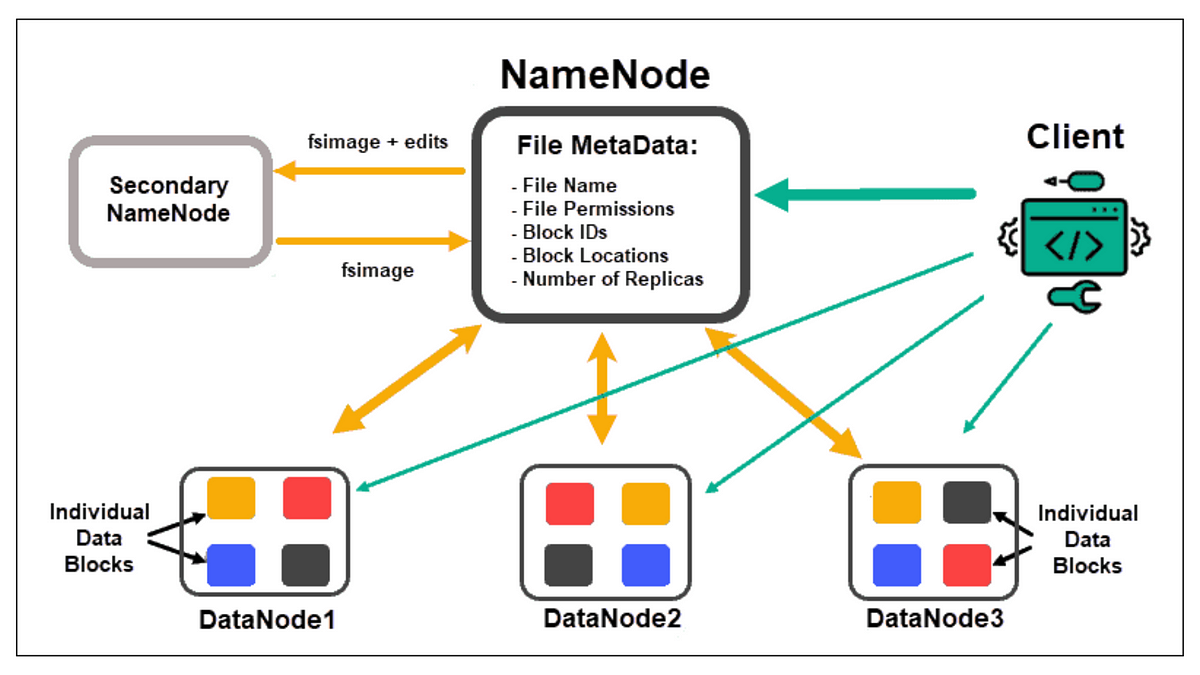
★★★
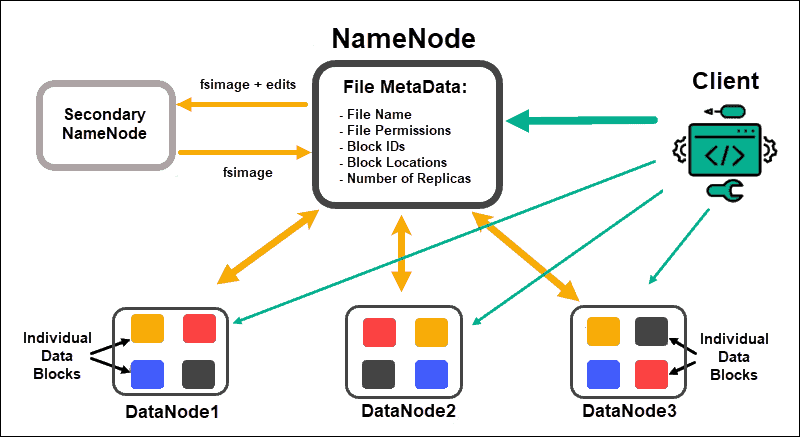
在 HDFS 中,負責儲存檔案系統命名空間(Namespace)資訊和檔案區塊(Block)映射關係的節點是?
答案解析
HDFS 採用主從(Master/Slave)架構。NameNode 是 HDFS 的主節點(Master),負責管理整個檔案系統的元數據(Metadata),包括檔案名稱、目錄結構、檔案權限以及每個檔案被切分成哪些區塊(Blocks)以及這些區塊儲存在哪些 DataNode 上。DataNode 是從節點(Slave),負責實際儲存檔案的數據區塊,並根據 NameNode 的指令執行區塊的建立、刪除和複製。ResourceManager 和 NodeManager 是 YARN(Yet Another Resource Negotiator)的組件,負責資源管理和任務調度,與 HDFS 的儲存管理角色不同。
#11
★★★
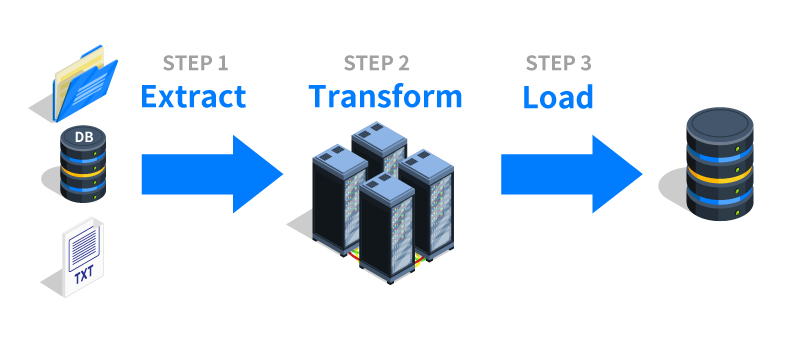
在資料倉儲中,ETL 過程代表什麼?
答案解析
ETL 是構建資料倉儲的關鍵過程,代表:
抽取 (Extract): 從各種來源系統(如資料庫、檔案、API)讀取數據。
轉換 (Transform): 對抽取的數據進行清洗、整合、標準化、計算等操作,使其符合目標資料倉儲的結構和品質要求。
載入 (Load): 將轉換後的數據寫入目標資料倉儲中。這個過程確保了進入資料倉儲的數據是一致且適合分析的。
抽取 (Extract): 從各種來源系統(如資料庫、檔案、API)讀取數據。
轉換 (Transform): 對抽取的數據進行清洗、整合、標準化、計算等操作,使其符合目標資料倉儲的結構和品質要求。
載入 (Load): 將轉換後的數據寫入目標資料倉儲中。這個過程確保了進入資料倉儲的數據是一致且適合分析的。
#12
★★★★
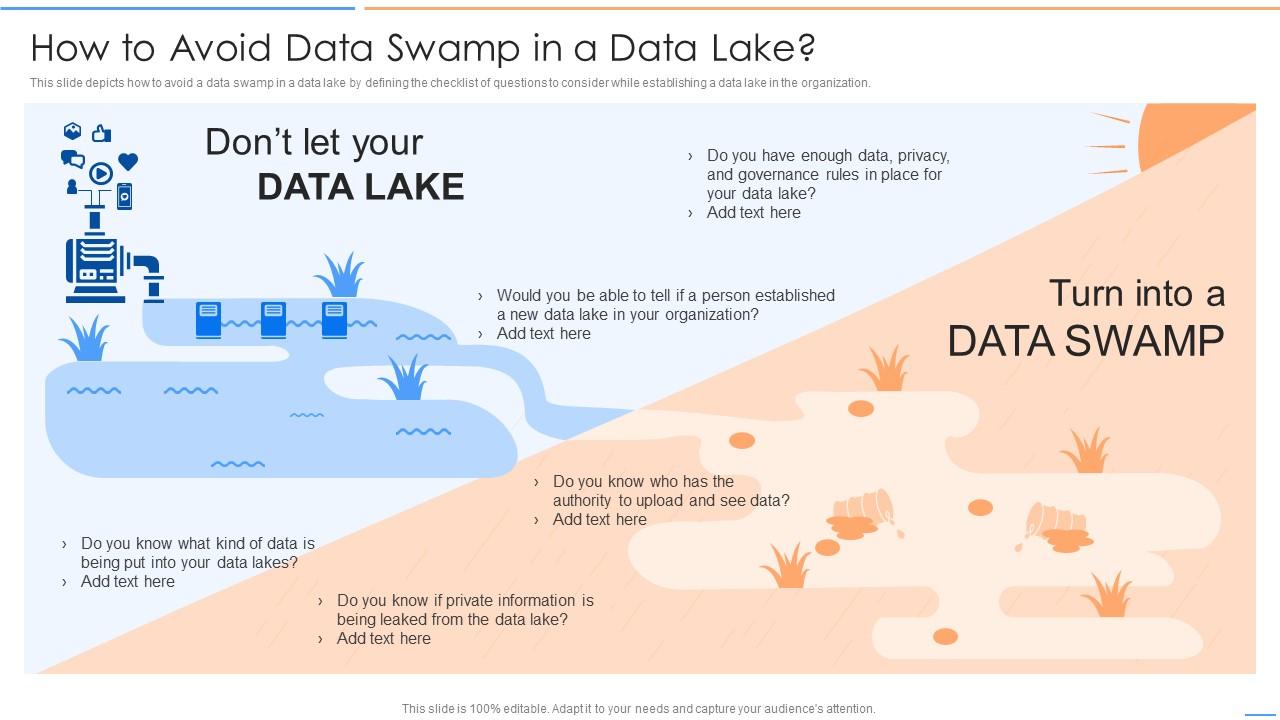
"Data Swamp"(數據沼澤)通常用來形容資料湖 (Data Lake) 的哪種潛在問題?
答案解析
雖然資料湖的靈活性是一大優點,但如果缺乏良好的數據管理實踐、元數據管理和數據治理策略,資料湖很容易變成「數據沼澤」。這意味著大量數據被隨意傾倒入湖中,但沒有清晰的來源說明、品質標記或組織結構,導致使用者難以找到有用的數據,數據的可信度和可用性大大降低,最終失去了資料湖應有的價值。有效的數據治理對於維持健康的資料湖至關重要。

#13
★★★
雲端儲存服務通常提供的「持久性」(Durability)指標衡量的是什麼?
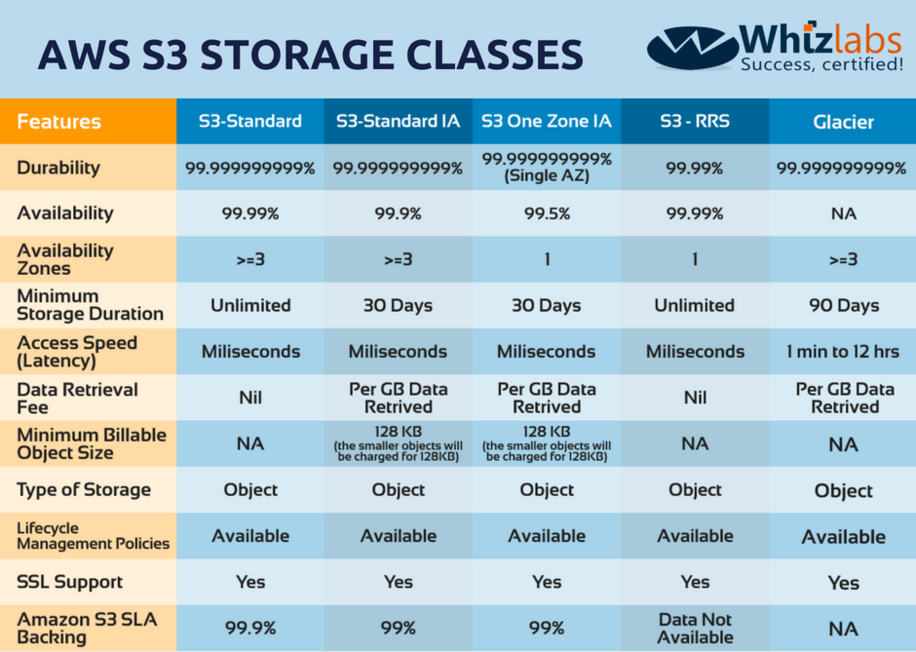
答案解析
持久性(Durability)是衡量儲存系統保護數據免於遺失的能力的指標,通常以年數據遺失率的百分比表示(例如,AWS S3 標準儲存提供 99.999999999%,即 11 個 9 的持久性)。高持久性意味著即使發生硬體故障或其他問題,數據遺失的風險也非常低,這通常是通過在多個設備和多個地理區域複製數據來實現的。它與可用性(Availability)不同,可用性衡量的是系統在需要時可以被存取的概率。
#14
★★★★
數據治理(Data Governance)的主要目標不包含下列哪一項?
答案解析
數據治理是一個涵蓋政策、流程、標準、角色和控制的框架,旨在確保組織能夠有效地管理其數據資產。其核心目標包括提高數據品質、確保數據一致性、定義數據擁有權和責任、保障數據安全、滿足法規遵循要求(如 GDPR, CCPA)以及提升數據的可發現性和可用性。數據治理關注的是數據的管理和使用,而不是單純追求儲存容量的最大化。雖然有效的治理可能間接影響儲存需求(例如通過數據清理減少冗餘),但增加原始儲存容量本身並非其主要目的。
#15
★★★★
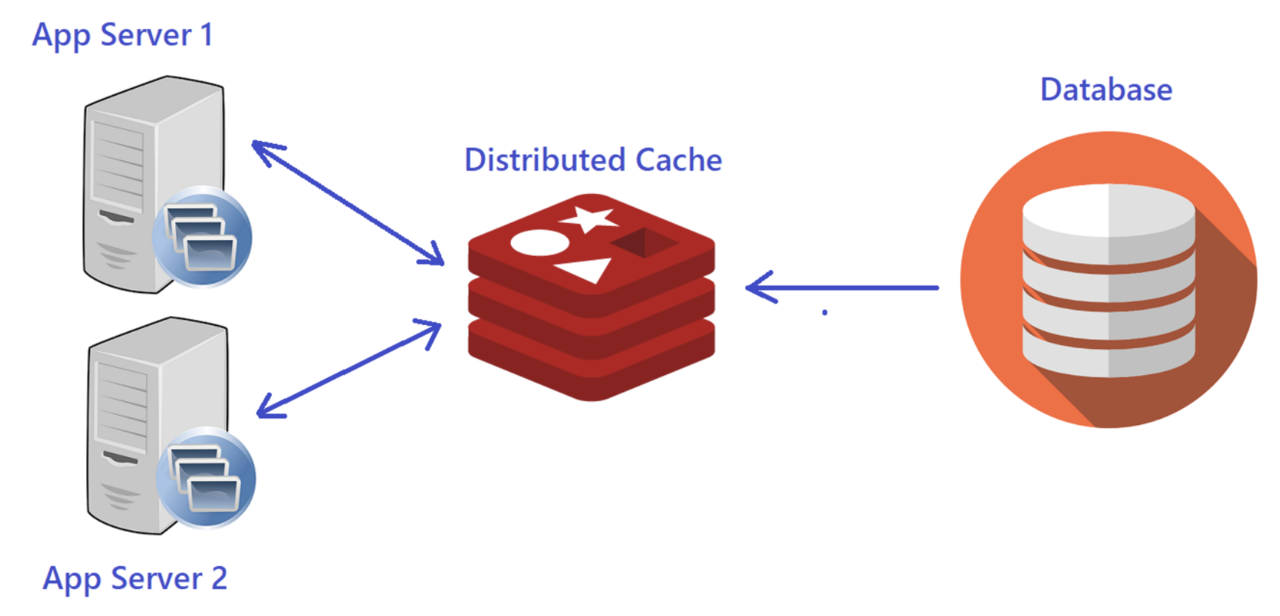
當應用程式需要極低延遲的數據存取,並且數據量相對較小但查詢頻繁時(例如快取 Cache),哪種儲存方案最為合適?
答案解析
記憶體內數據儲存(In-Memory Data Store)將數據主要存儲在伺服器的 RAM(Random Access Memory)中,而不是傳統的硬碟(HDD)或固態硬碟(SSD)。由於記憶體的存取速度遠快於磁碟,這類儲存方案能夠提供非常低的讀寫延遲(通常在微秒或毫秒級)。因此,它們非常適合用作快取層,以加速對常用數據的訪問,減輕後端資料庫的負載。Redis 和 Memcached 是兩種廣泛使用的開源記憶體內鍵值儲存系統。其他選項如 HDFS 和 S3 主要針對大容量儲存和高吞吐量,延遲較高;磁帶則主要用於長期歸檔,延遲極高。
#16
★★★
結構化數據 (Structured Data)、半結構化數據 (Semi-structured Data) 和非結構化數據 (Unstructured Data) 的主要區別在於?
答案解析
這三種數據類型的主要區別在於其組織程度和是否有固定的結構:
結構化數據: 具有嚴格定義的格式,通常儲存在關聯式資料庫的表格中,有固定的欄位和數據類型。
非結構化數據: 沒有預先定義的結構或格式,例如純文字文件、圖片、音訊、影片等。
半結構化數據: 不符合嚴格的表格式結構,但包含一些標籤或標記來區分語義元素和建立層次結構,例如 JSON、XML、日誌檔案等。
結構化數據: 具有嚴格定義的格式,通常儲存在關聯式資料庫的表格中,有固定的欄位和數據類型。
非結構化數據: 沒有預先定義的結構或格式,例如純文字文件、圖片、音訊、影片等。
半結構化數據: 不符合嚴格的表格式結構,但包含一些標籤或標記來區分語義元素和建立層次結構,例如 JSON、XML、日誌檔案等。

#17
★★★★
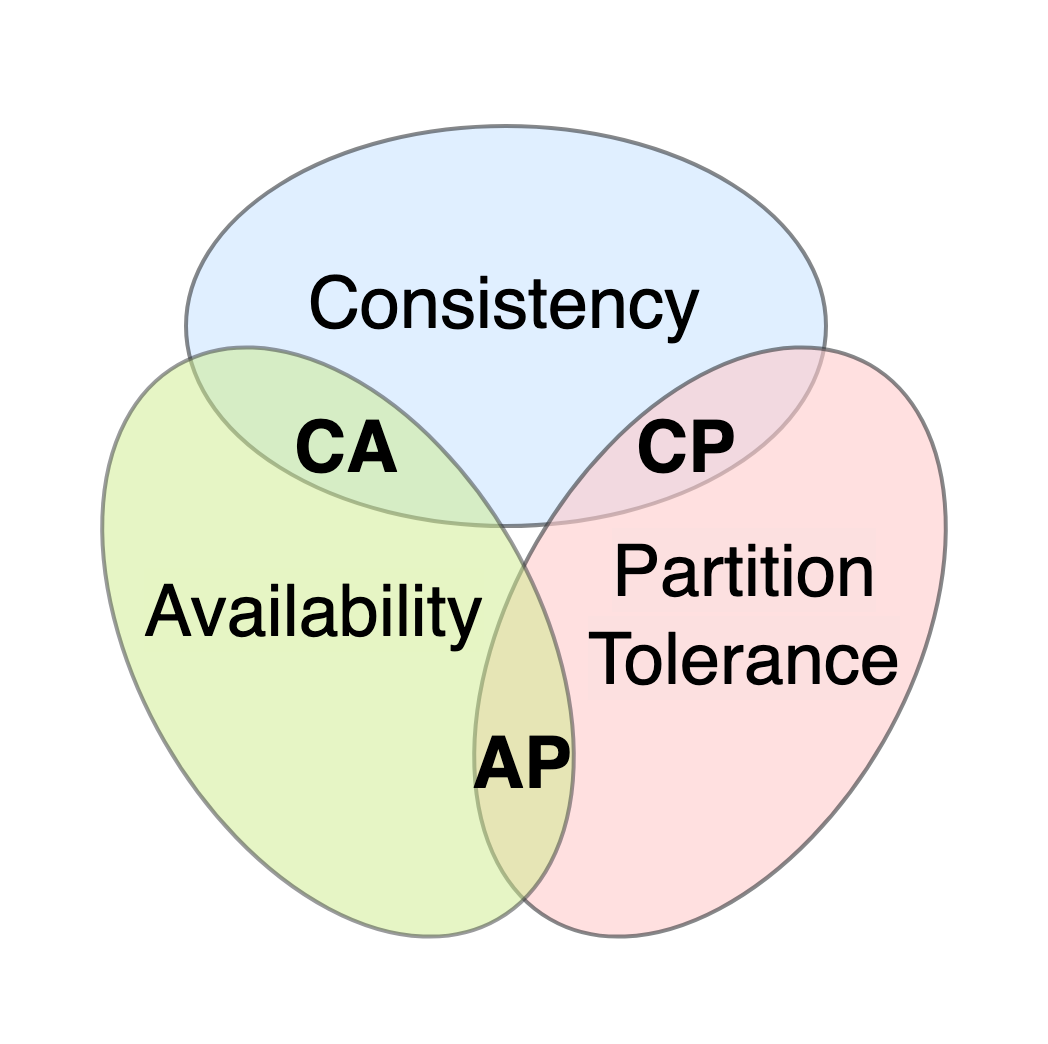
CAP 定理(CAP Theorem)是分散式系統設計中的一個重要原則,它指出在一個分散式系統中,哪三個特性無法同時被滿足?
答案解析
CAP 定理(由 Eric Brewer 提出)指出,任何分散式數據儲存系統最多只能同時滿足以下三個特性中的兩個:
一致性 (Consistency): 所有節點在同一時間看到相同的數據。每次讀取操作都能返回最新的寫入結果或一個錯誤。
可用性 (Availability): 每個請求(讀或寫)都能收到一個回應(非錯誤),即使系統中的某些節點發生故障。
分割區容錯性 (Partition Tolerance): 即使系統中的節點之間發生網路分割(無法互相通信),系統仍能繼續運作。
由於網路分割在分散式系統中是不可避免的,設計者通常必須在一致性(C)和可用性(A)之間做出取捨。許多 NoSQL 資料庫選擇了可用性和分割區容錯性(AP 系統),而犧牲了強一致性(Strong Consistency),轉而提供最終一致性(Eventual Consistency)。
一致性 (Consistency): 所有節點在同一時間看到相同的數據。每次讀取操作都能返回最新的寫入結果或一個錯誤。
可用性 (Availability): 每個請求(讀或寫)都能收到一個回應(非錯誤),即使系統中的某些節點發生故障。
分割區容錯性 (Partition Tolerance): 即使系統中的節點之間發生網路分割(無法互相通信),系統仍能繼續運作。
由於網路分割在分散式系統中是不可避免的,設計者通常必須在一致性(C)和可用性(A)之間做出取捨。許多 NoSQL 資料庫選擇了可用性和分割區容錯性(AP 系統),而犧牲了強一致性(Strong Consistency),轉而提供最終一致性(Eventual Consistency)。
#18
★★★
在 HDFS 中,為了提高數據的容錯能力,預設會將每個數據區塊(Block)複製幾份?
答案解析
HDFS 透過數據複製(Replication)來實現高容錯性。預設情況下,HDFS 會將每個數據區塊複製 3 份,並將這些副本分散儲存在不同的 DataNode 上(通常還會考慮機架感知 Rack Awareness,盡量將副本放在不同的機架上)。這樣即使某個 DataNode 或整個機架發生故障,數據仍然可以從其他副本中獲取,保證了數據的可用性和可靠性。這個複製因子(Replication Factor)是可以配置的。
#19
★★★★
資料湖倉一體(Lakehouse)架構試圖結合資料湖和資料倉儲的哪些優點?
答案解析
Lakehouse 是一種新興的數據管理架構,旨在將資料湖(通常基於低成本的物件儲存)和資料倉儲的最佳特性結合起來。它希望在資料湖的開放格式、靈活性和能夠處理各種數據類型(結構化、半結構化、非結構化)的基礎上,增加傳統資料倉儲提供的強大數據管理功能,如 ACID 事務支援、數據版本控制、索引優化、數據品質強制以及統一的治理模型。像 Delta Lake、Apache Iceberg 和 Apache Hudi 這樣的開源專案是實現 Lakehouse 架構的關鍵技術。
#20
★★★
在選擇雲端儲存服務時,"儲存層級"(Storage Tiering)或 "儲存類別"(Storage Class)的主要目的是什麼?
答案解析
雲端儲存供應商(如 AWS, Azure, GCP)通常提供多種儲存類別或層級,每種類別在存取效能、可用性、持久性和成本方面有所不同。例如,經常存取的「熱」數據(Hot Data)可以放在標準儲存類別,提供較低的存取延遲但成本較高;不常存取但需要快速檢索的「溫」數據(Warm Data)可以放在不常存取類別,成本較低但可能有檢索費用;而很少存取用於歸檔的「冷」數據(Cold Data)可以放在歸檔儲存(如 AWS Glacier),成本最低但檢索時間可能需要數小時。透過將數據根據其生命週期和存取模式放置在合適的層級,企業可以有效地平衡效能需求和儲存成本。
#21
★★★
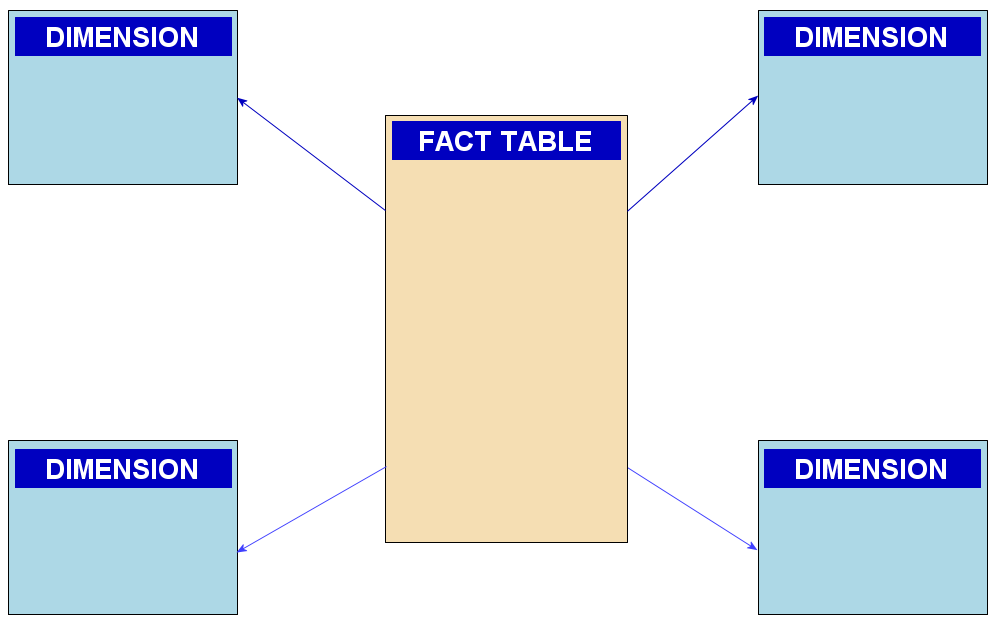
在資料倉儲建模中,星型模型 (Star Schema) 的中心通常是什麼?
答案解析
星型模型是資料倉儲中最常見的模式之一。它的結構類似星星,中心是一個事實表(Fact Table),周圍環繞著多個維度表(Dimension Table)。事實表包含衡量業務流程的指標(Measures,通常是數值數據,如銷售額、數量)以及指向相關維度表的外鍵(Foreign Keys)。維度表則包含描述業務背景的屬性(Attributes,如時間、地點、產品、客戶等)。這種結構使得基於維度的分析查詢(例如,按地區和時間匯總銷售額)變得簡單和高效。
#22
★★★
Redis 主要被歸類為哪種類型的 NoSQL 資料庫?
答案解析
Redis(Remote Dictionary Server)是一個開源的高效能記憶體內數據結構儲存,通常被用作鍵值儲存、快取和訊息代理。雖然它可以儲存比簡單字串更複雜的數據結構(如列表、集合、雜湊表、有序集合),但其核心模型仍然是基於鍵來快速查找對應的值,因此主要歸類為鍵值儲存。

#23
★★★★
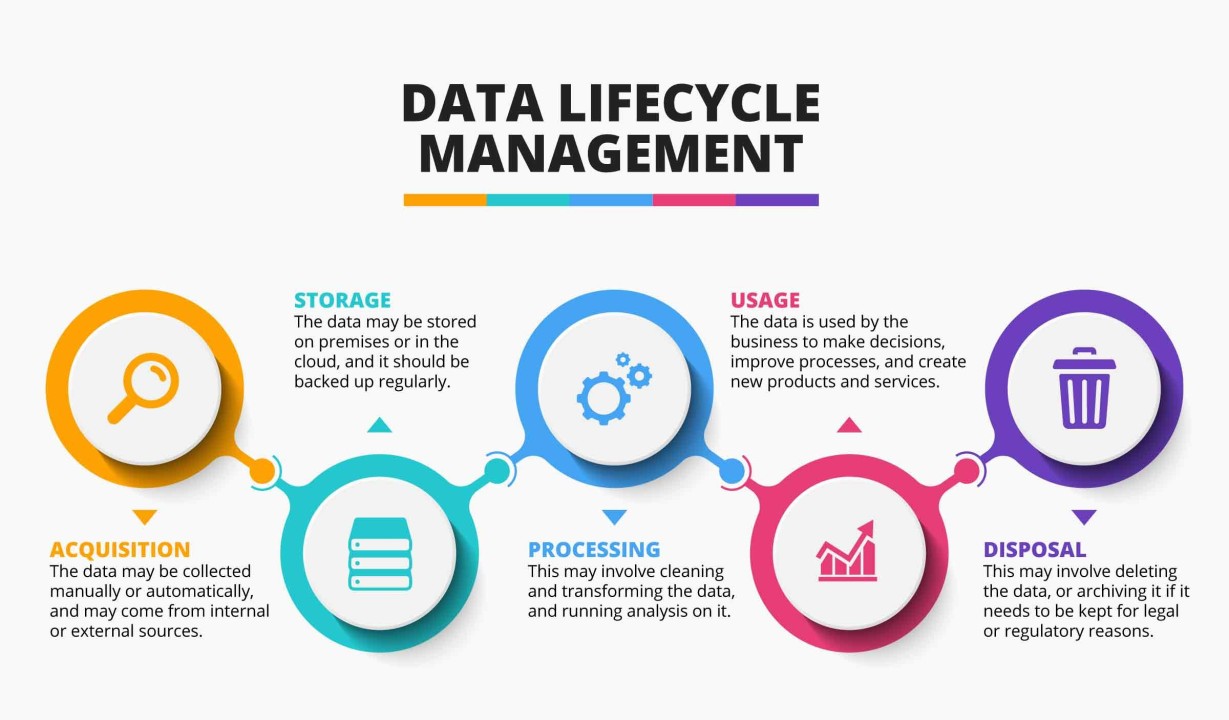
數據生命週期管理 (Data Lifecycle Management, DLM) 的主要目的是?
答案解析
數據生命週期管理(DLM)是一種策略性的方法,用於管理數據從創建或獲取到最終銷毀的整個過程。它認識到數據的價值和存取需求會隨著時間的推移而變化。DLM 的目標是透過自動化或策略驅動的方式,將數據在不同儲存層級之間遷移(例如,從高效能的熱儲存移至低成本的冷儲存或歸檔儲存),並最終根據法規或業務需求安全地刪除數據。這有助於優化儲存成本、提高效能、確保合規性並降低風險。
#24
★★★
NAS (Network Attached Storage) 和 SAN (Storage Area Network) 的主要區別在於它們提供的儲存類型?
答案解析
NAS 和 SAN 是兩種主要的網路儲存架構,它們在存取層級、協定和應用場景上有根本的不同:
- NAS (Network Attached Storage): 是一種專用的檔案儲存設備,它透過標準的乙太網路和協定(如 NFS 或 SMB/CIFS)將儲存空間以檔案系統的形式共享給網路上的多個客戶端。對客戶端來說,它就像一個網路磁碟機,易於設定和共享。
- SAN (Storage Area Network): 是一個專用的高速網路(通常使用 Fibre Channel 或 iSCSI 協定),將伺服器連接到共享的儲存設備陣列。SAN 提供的是區塊級儲存,伺服器將其視為本地連接的原始磁碟區塊,可以在上面建立自己的檔案系統。SAN 通常提供比 NAS 更高的效能和更低的延遲,適用於資料庫等高效能應用。
| 特性 | NAS (網路附加儲存) | SAN (儲存區域網路) |
|---|---|---|
| 儲存層級 | 檔案級 (File-level) | 區塊級 (Block-level) |
| 網路協定 | NFS, SMB/CIFS (基於 TCP/IP) | Fibre Channel (FC), iSCSI |
| 客戶端視圖 | 掛載的網路磁碟機/共享資料夾 | 本地連接的原始磁碟 (硬碟) |
| 效能 | 適合檔案共享,延遲較高 | 高效能、低延遲、高 IOPS |
| 管理複雜度 | 相對簡單,易於部署 | 較複雜,需要專門知識 |
| 主要應用 | 檔案伺服器、集中化檔案儲存、備份 | 資料庫、虛擬化環境、高效能運算 |
#25
★★★
下列何者不是分散式檔案系統 (Distributed File System) 的典型優點?
答案解析
分散式檔案系統(如 HDFS, CephFS, GlusterFS)透過將數據分佈在多台伺服器上,提供了良好的擴展性(可以輕易增加節點來擴充容量和效能)、容錯性(透過數據複製或糾刪碼防止單點故障)和高吞吐量(可以並行讀寫數據)。然而,由於數據需要在網路間傳輸以及協調多個節點,其讀寫延遲通常高於本地檔案系統或專用的高效能儲存(如 SAN 或記憶體內儲存)。因此,極低的延遲不是分散式檔案系統的典型優點,它們更側重於處理大規模數據的容量和吞吐量。
#26
★★★★
相較於自行建置和維護本地儲存基礎設施,使用公有雲儲存服務的主要優勢通常包含哪些?
答案解析
使用公有雲儲存(如 AWS S3, Azure Blob Storage, Google Cloud Storage)的主要優勢包括:
彈性擴展: 可以根據需求快速增加或減少儲存容量。
按用量付費: 通常只需為實際使用的儲存空間和數據傳輸付費,避免了前期大量的硬體投資。
高可用性/持久性: 雲服務商通常透過多重複製和跨區域部署來提供高水平的服務可靠性和數據持久性。
減少維運負擔: 無需自行管理硬體採購、部署、維護、升級和監控等工作。
相對地,缺點可能包括對硬體的控制權較少、成本可能隨用量增加而難以預測、效能可能受網路影響以及數據隱私和合規性的考量。
彈性擴展: 可以根據需求快速增加或減少儲存容量。
按用量付費: 通常只需為實際使用的儲存空間和數據傳輸付費,避免了前期大量的硬體投資。
高可用性/持久性: 雲服務商通常透過多重複製和跨區域部署來提供高水平的服務可靠性和數據持久性。
減少維運負擔: 無需自行管理硬體採購、部署、維護、升級和監控等工作。
相對地,缺點可能包括對硬體的控制權較少、成本可能隨用量增加而難以預測、效能可能受網路影響以及數據隱私和合規性的考量。
#27
★★★★★
當數據模型經常變動,或者需要儲存結構不固定的數據時,哪種類型的資料庫提供了較大的靈活性?
答案解析
NoSQL 文件資料庫(如 MongoDB, Couchbase)以其「彈性綱要」(Flexible Schema)或「無綱要」(Schemaless)特性而聞名。這意味著同一個集合(Collection,類似於關聯式資料庫的表格)中的文件(Document,類似於行)可以有不同的欄位和結構。這使得它們非常適合需要快速迭代開發、數據模型經常變更或需要儲存結構多樣(例如使用者自訂欄位)的應用場景。相比之下,傳統的關聯式資料庫要求在寫入數據前必須先定義好嚴格的表格綱要,修改綱要通常較為複雜。
#28
★★★
下列何者最能描述資料湖 (Data Lake) 通常使用的底層儲存技術?
答案解析
資料湖需要儲存海量的、各種格式的原始數據。為了滿足這種需求並控制成本,資料湖通常建立在具有高擴展性、高持久性和相對較低單位儲存成本的技術之上。在雲端環境中,物件儲存(如 AWS S3, Azure Blob Storage, Google Cloud Storage)是最常見的選擇。在本地(On-premises)環境中,HDFS(Hadoop Distributed File System)是傳統的選擇,儘管現在也有基於物件儲存的本地解決方案。高效能的 SAN 或記憶體內資料庫成本過高,不適合儲存整個資料湖的原始數據;關聯式資料庫則不適合儲存非結構化和半結構化數據。
#29
★★★
數據加密(Data Encryption)在數據儲存安全中扮演什麼角色?
答案解析
數據加密是透過使用加密演算法和密鑰,將原始數據(明文)轉換為不可讀的格式(密文)的過程。其主要目的是保護數據的機密性。在數據儲存的背景下,加密可以分為:
靜態加密 (Encryption at Rest): 保護儲存在磁碟、資料庫、備份介質等儲存設備上的數據。即使儲存介質被盜或未經授權訪問,沒有正確的密鑰也無法讀取數據。
傳輸中加密 (Encryption in Transit): 保護數據在網路中傳輸時(例如,從客戶端到伺服器)不被竊聽,通常使用 TLS/SSL 等協定。加密本身不會增加容量、加快查詢或自動備份。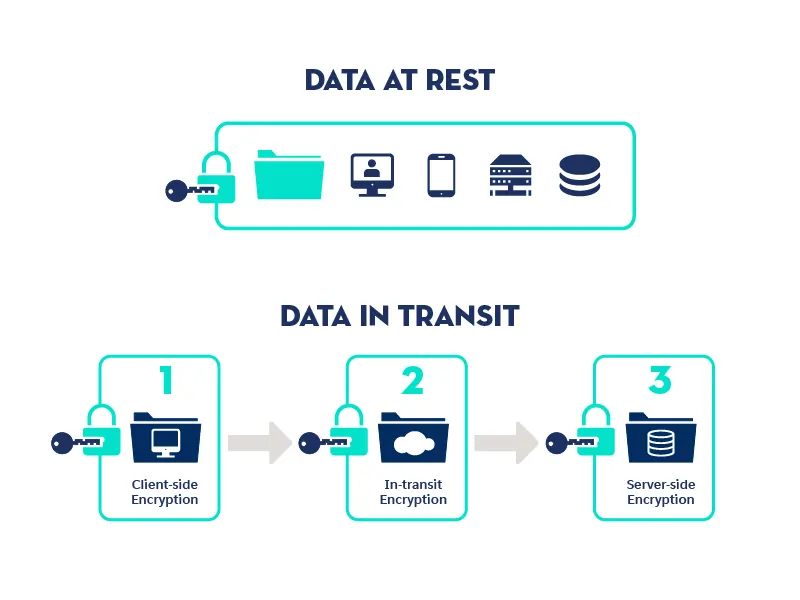
靜態加密 (Encryption at Rest): 保護儲存在磁碟、資料庫、備份介質等儲存設備上的數據。即使儲存介質被盜或未經授權訪問,沒有正確的密鑰也無法讀取數據。
傳輸中加密 (Encryption in Transit): 保護數據在網路中傳輸時(例如,從客戶端到伺服器)不被竊聽,通常使用 TLS/SSL 等協定。加密本身不會增加容量、加快查詢或自動備份。
#30
★★
RAID (Redundant Array of Independent Disks) 技術的主要目的是什麼?
答案解析
RAID 是一種將多個獨立的實體硬碟組合起來,形成一個或多個邏輯單元(Logical Unit)的技術。不同的 RAID 級別(如 RAID 0, RAID 1, RAID 5, RAID 6, RAID 10)提供不同的效益組合。總體而言,RAID 的主要目標是利用多硬碟的組合來改善儲存系統的效能、可靠性(透過冗餘)或兩者。
| RAID 級別 | 描述 | 最少磁碟數 | 容錯能力 | 儲存效率 | 優點 | 缺點 |
|---|---|---|---|---|---|---|
| RAID 0 | 分條 (Stripe) | 2 | 0 顆磁碟 | 100% | 讀寫效能極佳 | 無冗餘,任一磁碟損壞將導致所有數據遺失 |
| RAID 1 | 鏡像 (Mirror) | 2 | 1 顆磁碟 | 50% | 高數據冗餘,讀取效能好 | 儲存成本高(容量利用率低) |
| RAID 5 | 分條含分散式校驗碼 | 3 | 1 顆磁碟 | (N-1)/N | 效能、容量、冗餘的良好平衡 | 寫入效能有損耗,重建時間長 |
| RAID 6 | 分條含雙重分散式校驗碼 | 4 | 2 顆磁碟 | (N-2)/N | 比 RAID 5 更高的容錯能力 | 寫入效能損耗更大,成本更高 |
| RAID 10 (1+0) | 鏡像與分條的組合 | 4 | 至少 1 顆磁碟 | 50% | 兼具高效能與高冗餘 | 成本非常高 |
#31
★★★★
相較於 OLTP (Online Transaction Processing) 系統,資料倉儲(OLAP - Online Analytical Processing 系統)的設計通常更側重於?
答案解析
OLTP 系統(如訂單處理系統、銀行交易系統)主要處理大量、簡短、即時的交易,重點在於快速的單筆記錄插入、更新和刪除,並確保數據的一致性和高可用性。而 OLAP 系統(如資料倉儲)主要用於數據分析和報告,其工作負載通常涉及對大量歷史數據進行複雜的聚合、切片、鑽取等查詢操作。因此,OLAP 系統的設計更側重於優化讀取效能和處理複雜查詢的能力,而不是高併發的寫入效能。
| 特性 | OLTP (線上交易處理) | OLAP (線上分析處理) |
|---|---|---|
| 主要目的 | 支援日常業務營運 | 支援決策制定、商業智慧 |
| 資料來源 | 當前營運系統 | 歷史數據、多個營運系統整合 |
| 資料結構 | 高度正規化 (Normalized) | 反正規化 (Denormalized), 星型/雪花模型 |
| 主要操作 | 大量、簡短的讀寫、更新 (CRUD) | 大量讀取、複雜聚合查詢 |
| 查詢複雜度 | 簡單、預定義 | 複雜、多維度分析 |
| 效能重點 | 高併發、低延遲的交易 | 高吞吐量、快速的分析查詢 |
| 使用者 | 前線員工、客戶 | 數據分析師、管理階層 |
| 系統範例 | 電商訂單系統、銀行ATM、ERP | 資料倉儲、BI報表平台 |
#32
★★★
下列哪項不是 NoSQL 資料庫的常見優點?
答案解析
NoSQL 資料庫通常設計用於應對大數據時代的需求,其常見優點包括:易於水平擴展以處理大量數據和高流量、彈性的數據模型(不需要預先定義嚴格的綱要)、以及通常設計為具有高可用性和容錯性。然而,為了實現這些特性,許多 NoSQL 資料庫放寬了對傳統關聯式資料庫所提供的 ACID(Atomicity, Consistency, Isolation, Durability)事務的嚴格保證,特別是跨多個記錄或節點的強一致性。它們可能提供最終一致性(Eventual Consistency)或僅在單一操作層級保證原子性。因此,保證強 ACID 事務通常不是 NoSQL 資料庫的典型優點(儘管一些 NoSQL 資料庫正在增加更強的事務支援)。
#33
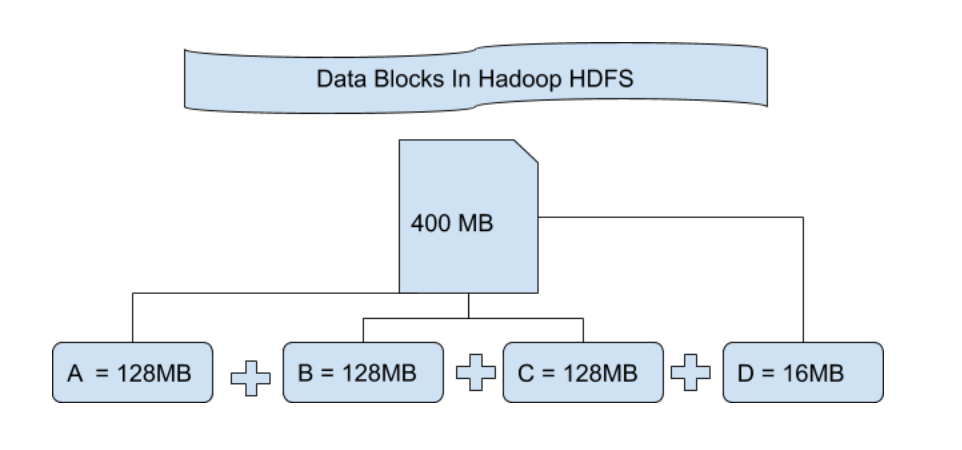
★★
HDFS 中的預設區塊大小 (Block Size) 通常是多少?
答案解析
HDFS 將大檔案切分成固定大小的區塊(Blocks)來儲存。與傳統檔案系統(如 Linux ext4)通常使用較小的區塊(如 4KB)不同,HDFS 使用非常大的區塊。早期版本的 Hadoop 預設為 64MB,而較新的版本(Hadoop 2.x 及以後)通常預設為 128MB 或 256MB。使用大區塊的主要目的是減少 NameNode 需要管理的元數據數量(因為元數據是按區塊儲存的),並最小化磁碟尋址(Seek)時間的開銷,從而提高數據傳輸的效率,更適合處理大檔案和高吞吐量的串流式讀取。
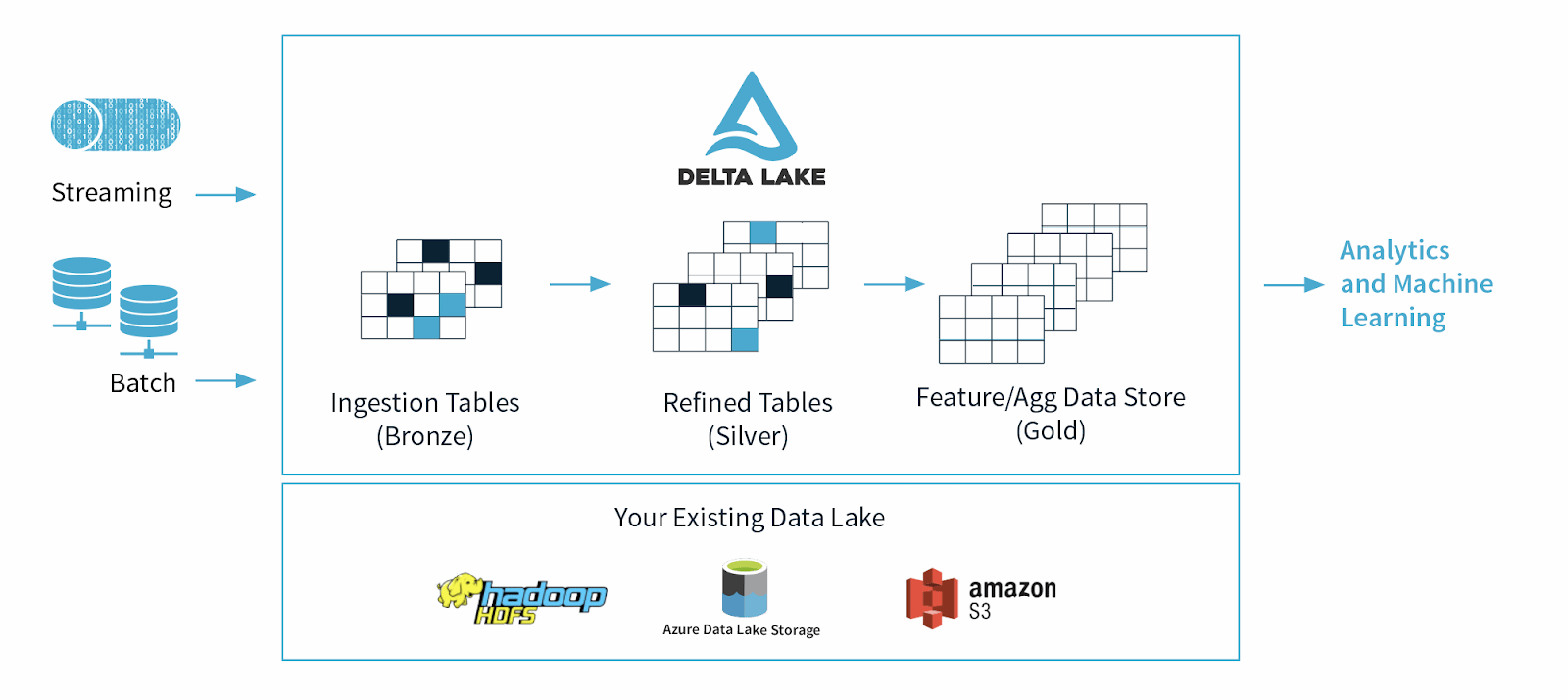
#34
★★★★
Delta Lake 是一個開源儲存層,它為資料湖帶來了哪些關鍵功能?
答案解析
Delta Lake 是由 Databricks 開發並開源的儲存層,旨在提高資料湖的可靠性和效能,使其具備部分資料倉儲的功能(實現 Lakehouse 架構)。其核心功能建立在標準數據格式(如 Parquet)之上,並透過事務日誌(Transaction Log)增加了:
ACID 事務: 確保對資料湖的讀寫操作具有原子性、一致性、隔離性和持久性。
時間旅行 (Time Travel): 可以查詢歷史版本的數據,方便審計、回滾錯誤或重現實驗。
綱要強制與演進: 可以強制寫入的數據符合預期綱要,防止數據污染,同時也支援綱要的平滑演進。
統一批次與串流處理: 可以將 Delta 表作為批次處理和串流處理的統一來源和目的地。
Delta Lake 是開源的,可以在多種環境中使用,不限於 Databricks。
ACID 事務: 確保對資料湖的讀寫操作具有原子性、一致性、隔離性和持久性。
時間旅行 (Time Travel): 可以查詢歷史版本的數據,方便審計、回滾錯誤或重現實驗。
綱要強制與演進: 可以強制寫入的數據符合預期綱要,防止數據污染,同時也支援綱要的平滑演進。
統一批次與串流處理: 可以將 Delta 表作為批次處理和串流處理的統一來源和目的地。
Delta Lake 是開源的,可以在多種環境中使用,不限於 Databricks。
#35
★★
CDN (Content Delivery Network) 的主要功能與數據儲存的關係是?
答案解析
CDN 是一個分佈式的伺服器網路,其主要目標是加速靜態內容(如網站圖片、CSS、JavaScript 檔案、影片串流)的傳遞給終端使用者。CDN 會將這些內容從源伺服器(Origin Server,可能是 Web 伺服器或物件儲存)快取(Cache)到地理位置分散的邊緣伺服器(Edge Server)上。當使用者請求內容時,CDN 會將請求導向離使用者最近或網路延遲最低的邊緣伺服器,從而縮短載入時間、提高可用性並減輕源伺服器的壓力。雖然 CDN 涉及到內容的臨時儲存(快取),但其主要功能是內容分發加速,而不是主要的數據儲存或歸檔解決方案。
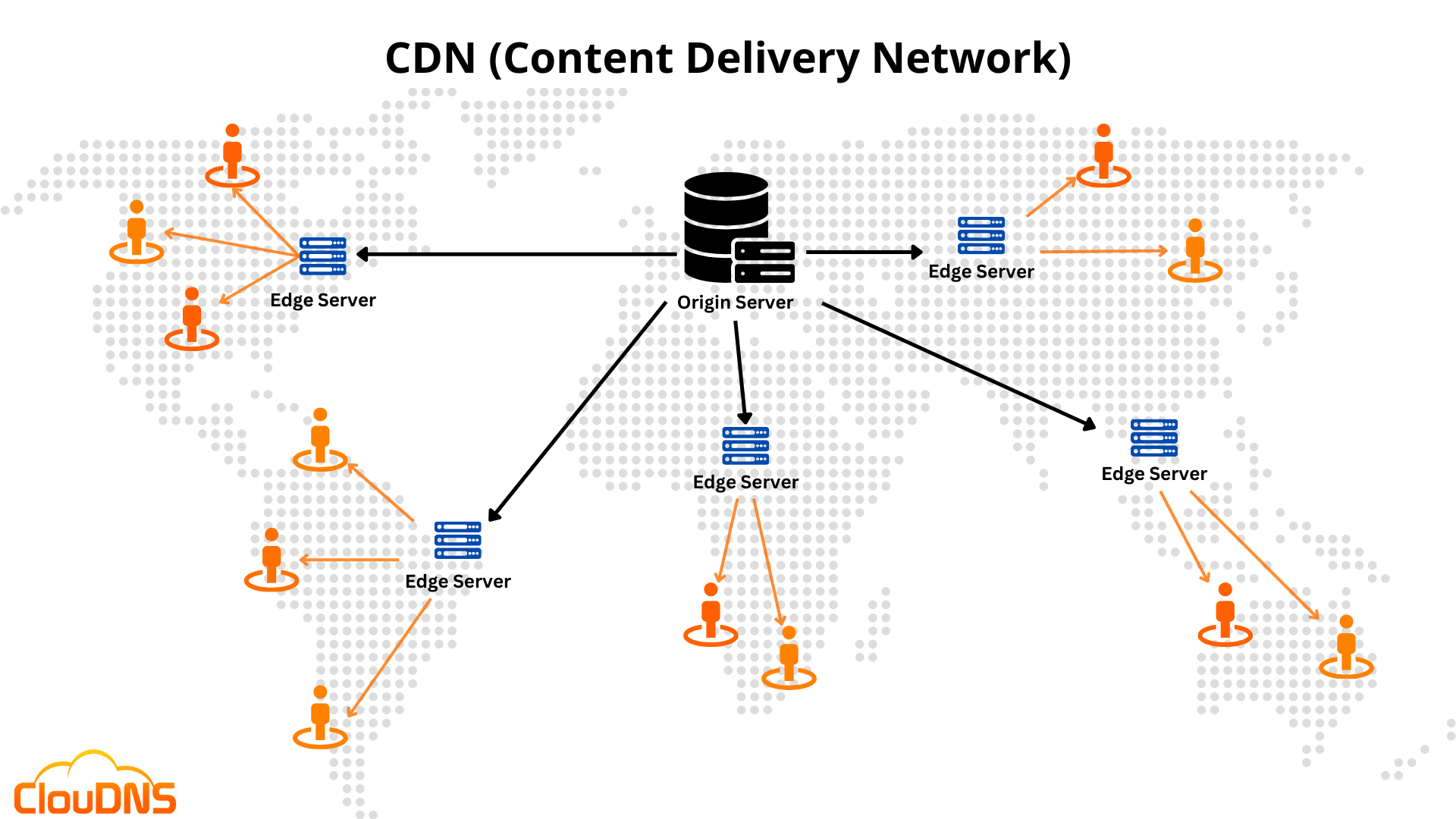
#36
★★★
元數據(Metadata)在數據儲存與管理中扮演什麼重要角色?
答案解析
元數據(Metadata)常被稱為「關於數據的數據」(Data about Data)。它提供了描述數據特徵和背景的資訊,使得數據更容易被發現、理解、管理和使用。例如,檔案系統的元數據包含檔案名稱、大小、創建/修改時間、權限等;資料庫的元數據(數據字典)包含表格名稱、欄位名稱、數據類型、約束等;圖片的元數據(如 EXIF)可能包含相機型號、拍攝時間、地理位置等。有效的元數據管理對於數據治理、數據搜尋、數據整合和數據分析至關重要,尤其是在資料湖等包含大量異質數據的環境中。
#37
★★★★
在比較儲存解決方案時,IOPS (Input/Output Operations Per Second) 主要衡量的是什麼指標?
答案解析
IOPS (Input/Output Operations Per Second) 是衡量儲存設備(如 HDD, SSD, SAN)效能的一個關鍵指標,它表示設備每秒能夠處理的讀取和寫入操作的總次數。IOPS 特別重要於衡量處理大量小型、隨機 I/O 請求的效能,例如資料庫交易處理、虛擬桌面基礎設施(VDI)等場景。高 IOPS 通常意味著更快的隨機存取速度和更低的延遲。它與吞吐量(Throughput)不同,吞吐量衡量的是每秒可以傳輸的數據量(MB/s 或 GB/s),通常更能反映處理大型、連續 I/O(如大檔案複製或串流)的效能。
#38
★★★
固態硬碟 (Solid State Drive, SSD) 相較於傳統機械硬碟 (Hard Disk Drive, HDD) 的主要優勢是什麼?
答案解析
SSD 使用快閃記憶體(Flash Memory)來儲存數據,沒有像 HDD 那樣的旋轉碟盤和移動讀寫臂等機械部件。這使得 SSD 具有顯著的優勢:
速度快、延遲低: 隨機讀寫速度遠超 HDD,啟動應用程式和載入檔案更快。
抗震性好: 沒有機械部件,更耐衝擊和振動。
功耗低、噪音小: 通常比 HDD 更省電且運行安靜。
然而,SSD 的主要缺點是每 GB 的儲存成本通常高於 HDD,且快閃記憶體有寫入壽命限制(儘管現代 SSD 的壽命對於大多數應用已足夠)。HDD 在大容量儲存方面仍然具有成本優勢。
速度快、延遲低: 隨機讀寫速度遠超 HDD,啟動應用程式和載入檔案更快。
抗震性好: 沒有機械部件,更耐衝擊和振動。
功耗低、噪音小: 通常比 HDD 更省電且運行安靜。
然而,SSD 的主要缺點是每 GB 的儲存成本通常高於 HDD,且快閃記憶體有寫入壽命限制(儘管現代 SSD 的壽命對於大多數應用已足夠)。HDD 在大容量儲存方面仍然具有成本優勢。
| 特性 | SSD (固態硬碟) | HDD (機械硬碟) |
|---|---|---|
| 儲存技術 | 快閃記憶體 (Flash Memory) | 磁性碟盤 (Magnetic Platters) |
| 機械部件 | 無 | 有 (旋轉碟盤、讀寫臂) |
| 讀寫速度 | 非常快 | 較慢 |
| 延遲 | 極低 | 較高 (受尋道時間影響) |
| 抗震性 | 高 | 低 |
| 功耗/噪音 | 低/幾乎無聲 | 較高/有噪音 |
| 每GB成本 | 較高 | 較低 |
| 寫入壽命 | 有限 (有寫入次數限制) | 較長 (無理論寫入限制) |
| 主要優勢 | 效能、耐用性 | 容量、成本效益 |
#39
★★★
資料超市 (Data Mart) 與資料倉儲 (Data Warehouse) 的關係通常是?
答案解析
資料超市(Data Mart)可以被視為一個小型化的、聚焦的資料倉儲。它通常只包含與特定業務部門(如銷售、行銷、財務)或特定業務流程相關的數據。資料超市可以從企業級的中央資料倉儲中衍生出來(依賴型資料超市),也可以獨立建置(獨立型資料超市)。相較於涵蓋整個企業範圍的資料倉儲,資料超市規模更小、建置更快、更容易被特定部門的使用者理解和使用。
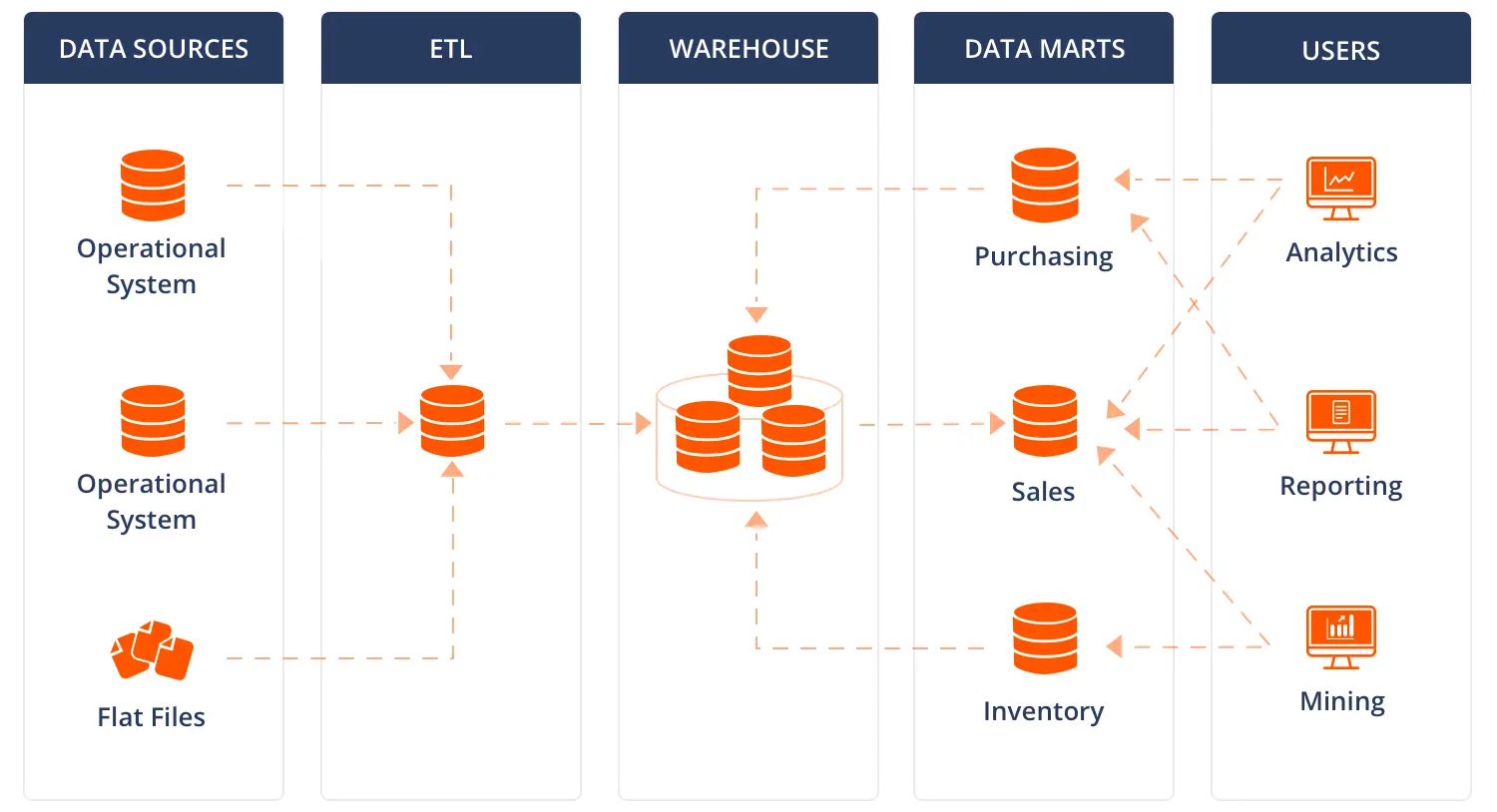
#40
★★★★
Apache Cassandra 是一種分散式 NoSQL 資料庫,其數據模型主要基於?
答案解析
Apache Cassandra 是一種高度可擴展、高可用性的分散式 NoSQL 資料庫,其數據模型屬於寬欄儲存(或稱欄族儲存)。它不像傳統關聯式資料庫那樣有固定的表格結構,而是使用鍵空間(Keyspace,類似於資料庫)、欄族(Column Family,類似於表格,但欄可以動態增減)和資料列(Row)來組織數據。每列由一個唯一的列鍵(Row Key)標識,並且可以包含大量的欄(Columns),這些欄不必在所有資料列中都存在。這種模型非常適合需要處理大量寫入、數據模型可能演變且需要高可用性的場景。
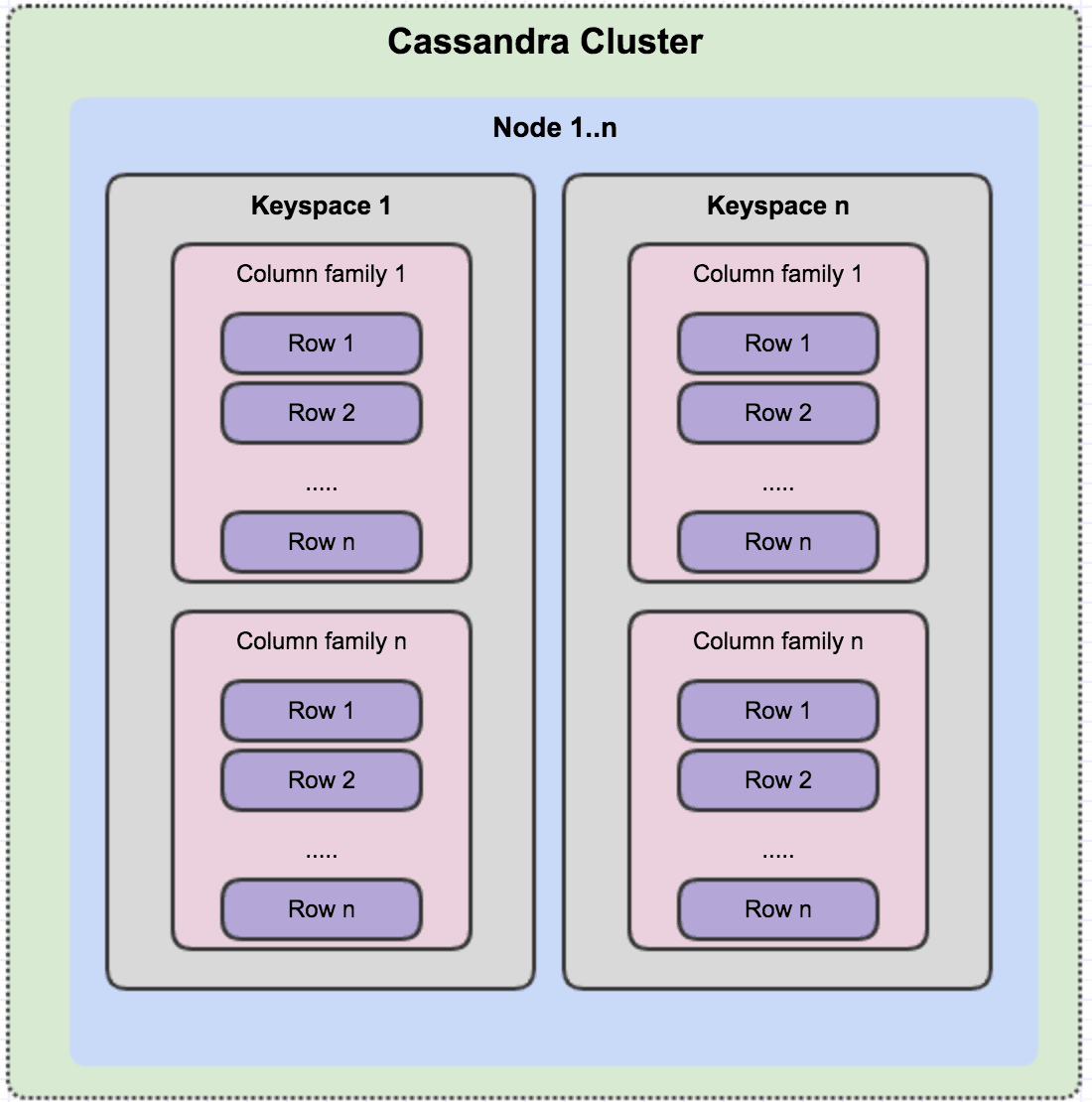
#41
★★★
HDFS 的 NameNode 可能成為單點故障 (Single Point of Failure),常見的解決方案是什麼?
答案解析
由於 NameNode 儲存著整個 HDFS 的元數據,如果 NameNode 發生故障且沒有備援,整個檔案系統將無法存取。為了解決這個單點故障問題,Hadoop 引入了 NameNode 高可用性(HA)方案。常見的實現方式是設定一個 Active NameNode 和一個或多個 Standby NameNode。Active NameNode 處理所有客戶端請求,而 Standby NameNode 則與 Active NameNode 保持狀態同步(通常透過共享編輯日誌 EditLog)。當 Active NameNode 發生故障時,Standby NameNode 可以快速接管,從而實現故障轉移(Failover),保證服務的連續性。Secondary NameNode 的角色主要是合併 EditLog 和 FsImage,減少 NameNode 啟動時間,它本身不能直接取代 Active NameNode。
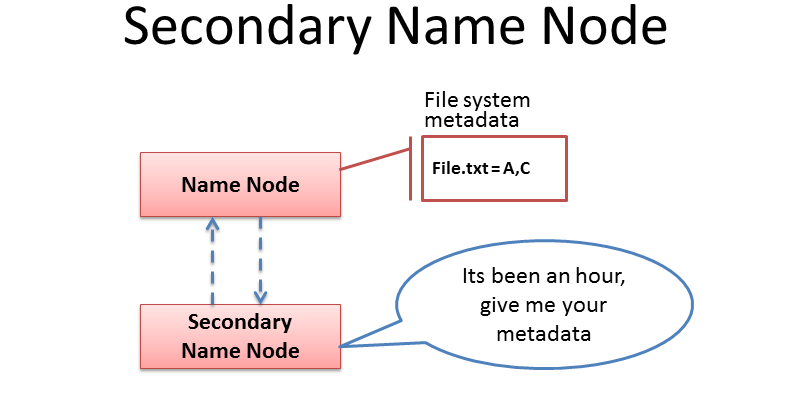
#42
★★★
在資料湖中常用的檔案格式,如 Parquet 和 ORC (Optimized Row Columnar),屬於哪種儲存方式?
答案解析
Apache Parquet 和 Apache ORC 是兩種在大數據生態系統(特別是資料湖)中廣泛使用的開源檔案格式。它們都採用欄式儲存(Columnar Storage)的方式來組織數據。欄式儲存將同一欄位的數據連續存放在一起,相比於傳統的行式儲存(如 CSV, JSON),它在分析型查詢(通常只讀取部分欄位)中具有更高的 I/O 效率和更好的壓縮率。這使得它們非常適合與 Spark, Hive, Presto 等大數據處理引擎配合使用。
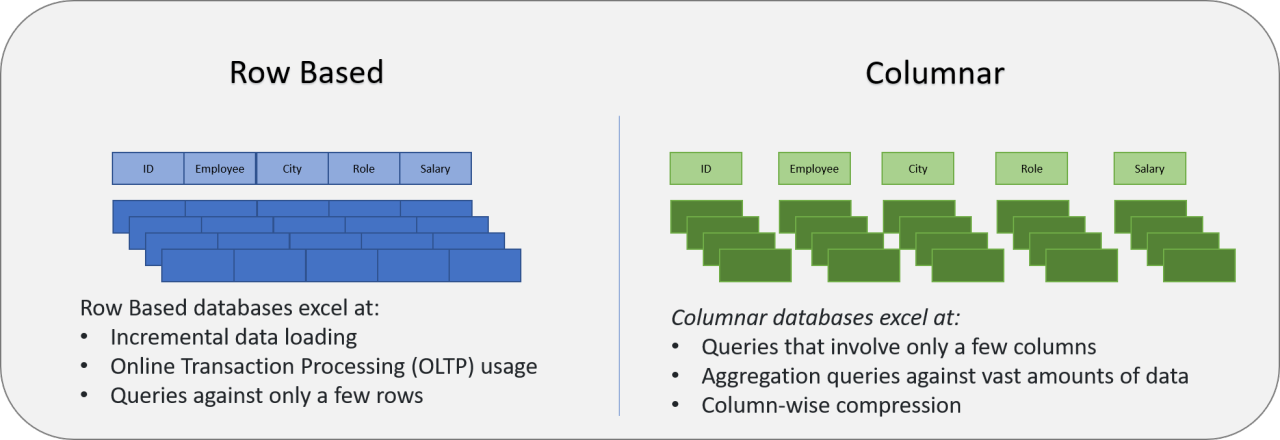
#43
★★★★
「伺服器端加密」(Server-Side Encryption, SSE) 和「客戶端加密」(Client-Side Encryption, CSE) 在雲端儲存中的主要區別是什麼?
答案解析
這兩種加密方式的主要區別在於加密操作發生在哪裡以及誰管理密鑰:
伺服器端加密 (SSE): 數據以明文形式上傳到雲端,由雲服務提供商在將數據寫入磁碟之前進行加密。加密密鑰可以由服務商自動管理(如 SSE-S3, SSE-Blob),也可以由客戶提供(SSE-C),或者使用雲端金鑰管理服務(如 SSE-KMS)。對使用者來說相對透明方便。
客戶端加密 (CSE): 數據在離開客戶端(使用者本地機器)之前就已經被加密。客戶端負責產生和管理加密密鑰,雲服務提供商只儲存加密後的數據(密文),無法訪問原始數據或密鑰。這種方式提供了更高的安全控制權給客戶,但客戶需要自行負責密鑰管理。
伺服器端加密 (SSE): 數據以明文形式上傳到雲端,由雲服務提供商在將數據寫入磁碟之前進行加密。加密密鑰可以由服務商自動管理(如 SSE-S3, SSE-Blob),也可以由客戶提供(SSE-C),或者使用雲端金鑰管理服務(如 SSE-KMS)。對使用者來說相對透明方便。
客戶端加密 (CSE): 數據在離開客戶端(使用者本地機器)之前就已經被加密。客戶端負責產生和管理加密密鑰,雲服務提供商只儲存加密後的數據(密文),無法訪問原始數據或密鑰。這種方式提供了更高的安全控制權給客戶,但客戶需要自行負責密鑰管理。
#44
★★
RPO (Recovery Point Objective) 指標在數據備份和災難恢復計畫中代表什麼?
答案解析
RPO (Recovery Point Objective) 是衡量在發生數據遺失事件(如系統故障、災難)後,企業可以承受多少數據損失的指標,通常以時間單位表示(例如,1 小時、4 小時、24 小時)。它決定了數據備份的頻率。例如,如果 RPO 是 1 小時,則意味著需要至少每小時備份一次數據,以確保在最壞情況下只會遺失最多 1 小時的數據。RPO 與 RTO (Recovery Time Objective) 不同,RTO 指的是從災難發生到系統恢復正常運作所需的最長時間。
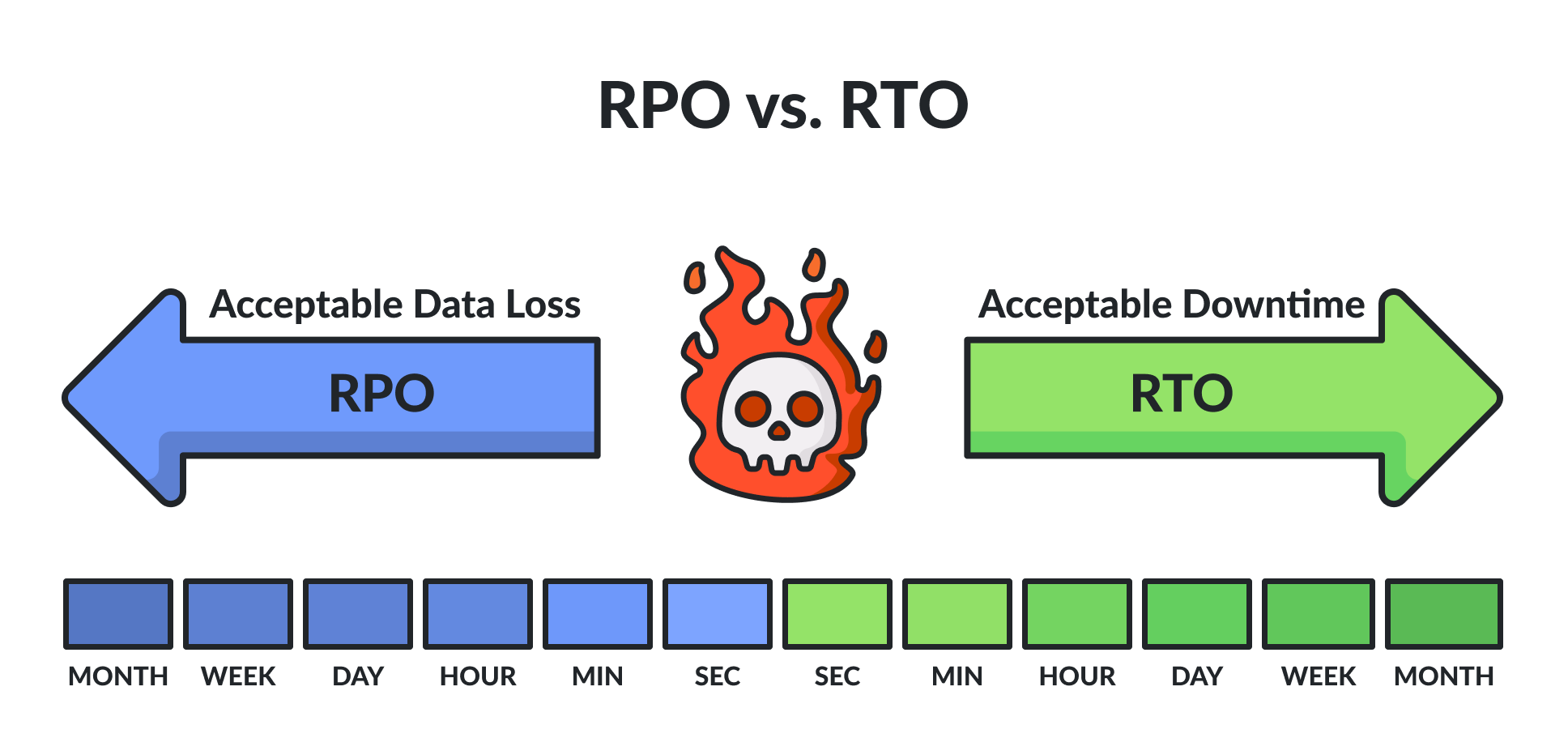
#45
★★★
糾刪碼 (Erasure Coding) 是一種數據保護技術,相較於簡單的數據複製 (Replication),它的主要優勢通常是什麼?
答案解析
糾刪碼是一種數據保護機制,它將原始數據分割成 k 個數據塊,然後計算出 m 個校驗塊(Parity Blocks),並將這 k+m 個塊分散儲存。系統可以容忍最多 m 個塊的遺失,並能透過剩餘的塊恢復出原始數據。例如,一個 (k=10, m=4) 的糾刪碼方案可以容忍最多 4 個塊遺失。相比於需要儲存 n 份完整副本的複製技術(例如 3 副本需要 3 倍的儲存空間),糾刪碼通常可以用更少的額外開銷(例如 (k+m)/k 倍)來達到相同甚至更高的容錯級別,從而提高儲存空間的利用率。然而,糾刪碼的計算通常比簡單複製更複雜,可能在寫入或恢復時引入更高的延遲或計算開銷。許多現代分散式儲存系統(如 Ceph, HDFS EC, S3)都支援糾刪碼。
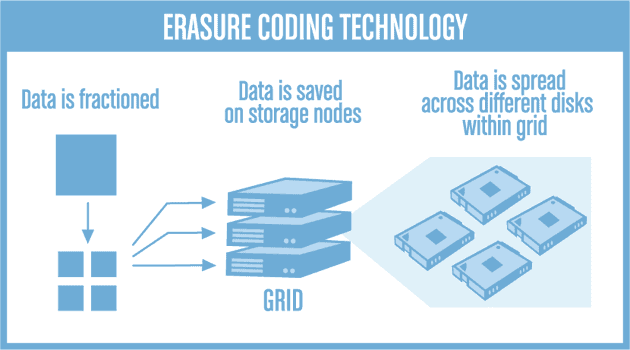
#46
★★
在數據儲存中,「熱數據」(Hot Data)、「溫數據」(Warm Data)和「冷數據」(Cold Data)是根據什麼來劃分的?
答案解析
這種數據分類主要是基於數據的存取模式和生命週期價值:
熱數據: 經常被存取、需要快速回應的數據,通常儲存在最高效能(但也最貴)的儲存層,如 SSD 或記憶體。
溫數據: 存取頻率較低,但仍需偶爾存取的數據,可以儲存在成本和效能居中的儲存層。
冷數據: 很少或幾乎不被存取,主要用於歸檔或合規目的的數據,可以儲存在最低成本(但存取速度也最慢)的儲存層,如磁帶或雲端歸檔儲存。這種分類有助於實施數據生命週期管理和優化儲存成本。
熱數據: 經常被存取、需要快速回應的數據,通常儲存在最高效能(但也最貴)的儲存層,如 SSD 或記憶體。
溫數據: 存取頻率較低,但仍需偶爾存取的數據,可以儲存在成本和效能居中的儲存層。
冷數據: 很少或幾乎不被存取,主要用於歸檔或合規目的的數據,可以儲存在最低成本(但存取速度也最慢)的儲存層,如磁帶或雲端歸檔儲存。這種分類有助於實施數據生命週期管理和優化儲存成本。
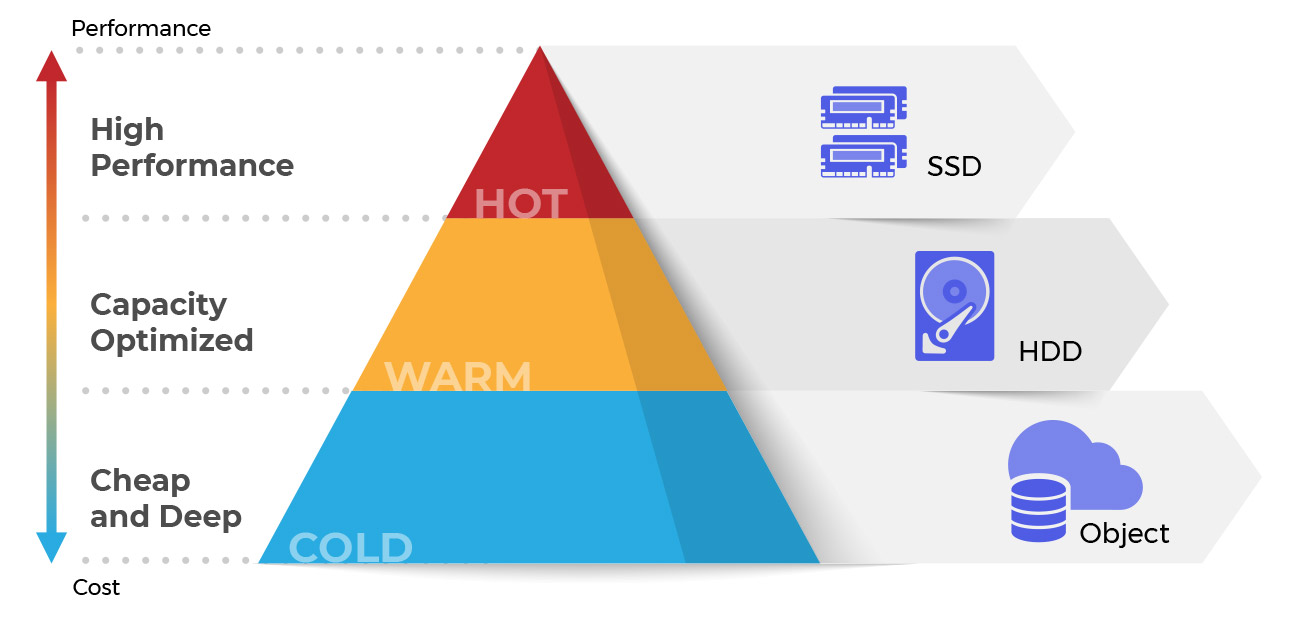
#47
★★★
維度緩慢變更 (Slowly Changing Dimensions, SCD) 是資料倉儲設計中用來處理維度屬性隨時間變化的技術。其中 SCD Type 2 的處理方式是?
答案解析
在資料倉儲中,維度屬性(例如客戶地址、產品價格)可能會隨時間改變。SCD Type 2 是一種常見的處理方式,它旨在保留完整的歷史變化記錄。當某個維度屬性發生變化時,不是直接修改現有記錄(SCD Type 1),也不是只保留部分歷史(SCD Type 3),而是將原有的記錄標記為過期(例如更新失效日期或標記旗標),並插入一條新的記錄來反映新的屬性值和生效日期。這樣,分析師就可以根據需要查詢特定時間點的維度狀態,或者追蹤屬性隨時間的變化情況。
| 類型 | 處理方式 | 歷史保存 | 優點 | 缺點 |
|---|---|---|---|---|
| SCD Type 1 | 覆蓋舊值 (Overwrite) | 不保存歷史 | 簡單、易於實現 | 遺失歷史數據,無法追蹤變化 |
| SCD Type 2 | 新增一筆新記錄 (Add New Row) | 保存完整歷史 | 提供完整的歷史視圖,分析準確 | 維度表快速增長,可能使查詢變複雜 |
| SCD Type 3 | 新增一個欄位 (Add New Column) | 保存部分歷史 (如 '前一個值') | 無需增加行數即可追蹤有限的歷史 | 只能追蹤有限次數的變化,擴展性差 |
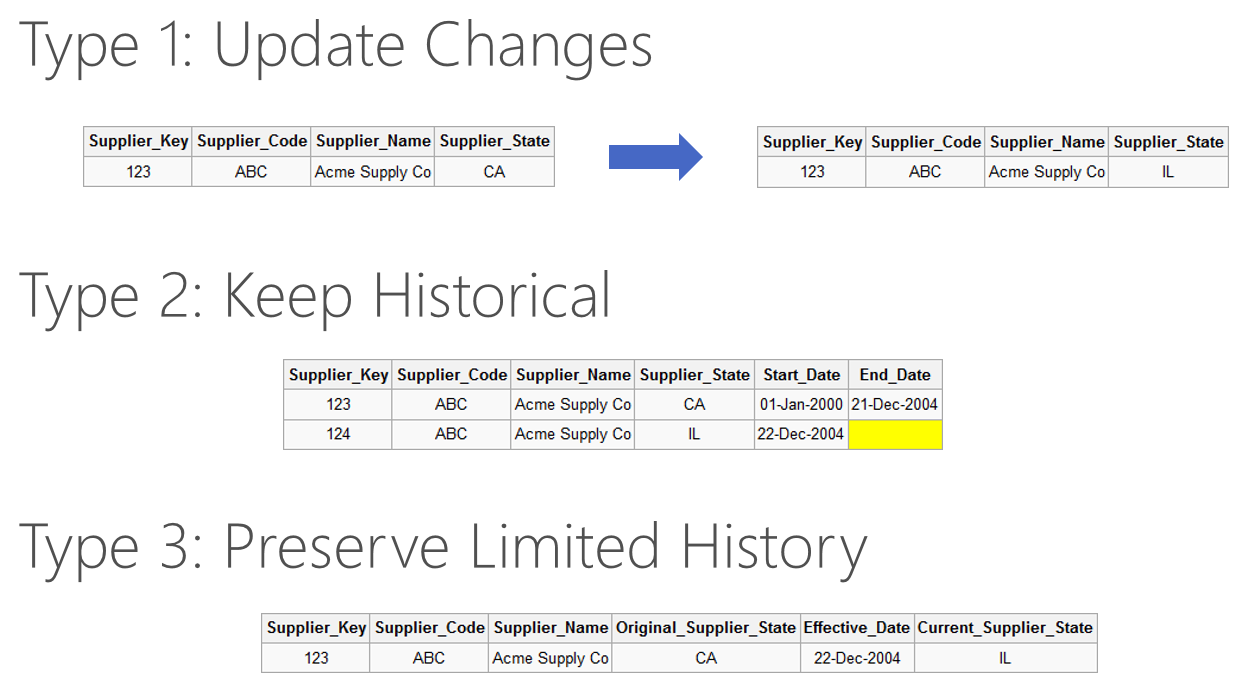
#48
★★★
Neo4j 是一種廣泛使用的 NoSQL 資料庫,它主要屬於哪種類型?
答案解析
Neo4j 是目前最流行的圖形資料庫之一。它使用屬性圖模型(Property Graph Model),其中包含節點(Nodes)和帶方向的關係(Relationships),節點和關係都可以擁有屬性(Key-Value Pairs)。Neo4j 非常適合儲存和查詢高度連接的數據,並提供了專門的查詢語言 Cypher 來方便地遍歷和操作圖形結構。
#49
★★★
雲端原生儲存 (Cloud-Native Storage) 通常具備哪些特性以更好地支援容器化 (Containerized) 和微服務 (Microservices) 架構?
答案解析
雲端原生儲存是為了適應現代雲端原生應用(通常基於容器和微服務)的需求而設計的儲存解決方案。其關鍵特性包括:
API 驅動: 可以透過 API 進行程式化的配置、管理和自動化。
彈性擴展: 能夠根據應用負載動態地擴展或縮減儲存資源。
分散式架構: 通常基於分散式系統,提供高可用性和容錯性。
平台整合: 與 Kubernetes 等容器編排平台緊密整合,支援動態配置儲存卷(Persistent Volumes)。
服務化: 以服務的形式提供,屏蔽了底層基礎設施的複雜性。例如 Ceph (透過 Rook), Longhorn, OpenEBS 等都是雲端原生儲存的例子。
API 驅動: 可以透過 API 進行程式化的配置、管理和自動化。
彈性擴展: 能夠根據應用負載動態地擴展或縮減儲存資源。
分散式架構: 通常基於分散式系統,提供高可用性和容錯性。
平台整合: 與 Kubernetes 等容器編排平台緊密整合,支援動態配置儲存卷(Persistent Volumes)。
服務化: 以服務的形式提供,屏蔽了底層基礎設施的複雜性。例如 Ceph (透過 Rook), Longhorn, OpenEBS 等都是雲端原生儲存的例子。
#50
★★★★
在選擇大數據儲存方案時,需要考量的主要因素不包含下列哪一項?
答案解析
選擇合適的大數據儲存方案是一個複雜的決策過程,需要綜合考慮多方面因素:
數據特性: 數據的總量、增長速度、數據的格式(結構化、半結構化、非結構化)。
工作負載: 數據的存取模式(讀多寫少?寫多讀少?)、查詢類型(簡單查找?複雜分析?)、效能要求(需要低延遲還是高吞吐量?)。
營運考量: 成本預算(硬體、軟體、維運、雲端費用)、可靠性要求(可用性 SLA、持久性指標)、安全性需求(加密、存取控制)、法規遵循、與現有技術棧的整合性、維運的複雜度等。
伺服器機殼的顏色顯然與儲存方案的功能性、效能或成本無關,不是技術選型時需要考量的因素。
數據特性: 數據的總量、增長速度、數據的格式(結構化、半結構化、非結構化)。
工作負載: 數據的存取模式(讀多寫少?寫多讀少?)、查詢類型(簡單查找?複雜分析?)、效能要求(需要低延遲還是高吞吐量?)。
營運考量: 成本預算(硬體、軟體、維運、雲端費用)、可靠性要求(可用性 SLA、持久性指標)、安全性需求(加密、存取控制)、法規遵循、與現有技術棧的整合性、維運的複雜度等。
伺服器機殼的顏色顯然與儲存方案的功能性、效能或成本無關,不是技術選型時需要考量的因素。
沒有找到符合條件的題目。
↑