iPAS AI應用規劃師 考試重點
L22202 數據儲存與管理
主題分類
1
數據儲存概念與演進
2
關聯式資料庫 (RDBMS)
3
NoSQL 資料庫 - 類型與特性
4
NoSQL 資料庫 - 應用場景
5
資料倉儲與資料湖
6
大數據儲存技術與格式
7
雲端儲存服務
8
數據管理與治理
#1
★★★★
數據儲存 (Data Storage) 的基本需求
核心考量
有效的數據儲存需要滿足多方面的需求,包括:
- 持久性 (Durability):確保數據不會意外遺失。
- 可用性 (Availability):在需要時能夠存取數據。
- 效能 (Performance):數據讀寫的速度。
- 可擴展性 (Scalability):能夠應對數據量的增長。
- 成本效益 (Cost-effectiveness):儲存成本合理。
- 安全性 (Security):保護數據免於未經授權的存取。
#2
★★★
結構化、半結構化、非結構化數據儲存
儲存方式差異
不同類型的數據通常需要不同的儲存方式:
- 結構化數據 (Structured Data):具有固定綱要(Schema),如表格數據,通常儲存在關聯式資料庫 (RDBMS) 或資料倉儲中。
- 半結構化數據 (Semi-structured Data):具有一定的結構,但格式較彈性,如 JSON、XML,常儲存在 NoSQL 資料庫(如文件資料庫)或資料湖中。
- 非結構化數據 (Unstructured Data):沒有預定義的結構,如文本、圖像、影音,常儲存在檔案系統、物件儲存 (Object Storage) 或資料湖中。

#3
★★★★
關聯式資料庫管理系統 (Relational Database Management System, RDBMS)
核心概念
- 基於關聯模型,將數據儲存在二維表格(Table)中,表格由列(Row/Record)和欄(Column/Attribute)組成。
- 使用主鍵 (Primary Key) 和外鍵 (Foreign Key) 來建立表格之間的關聯。
- 強調數據一致性和完整性。
- 通常使用SQL (Structured Query Language) 進行數據操作。
- 常見系統:MySQL, PostgreSQL, Oracle Database, SQL Server。
#4
★★★★
RDBMS 的 ACID 特性
四大特性
ACID 是關聯式資料庫確保交易 (Transaction) 可靠性的核心原則:
- 原子性 (Atomicity):交易中的所有操作要麼全部完成,要麼全部不完成,不會停留在中間狀態。
- 一致性 (Consistency):交易必須使資料庫從一個有效的狀態轉移到另一個有效的狀態,符合所有約束。
- 隔離性 (Isolation):並行執行的交易之間互不干擾,如同循序執行一樣。
- 持久性 (Durability):一旦交易成功提交,其結果就是永久性的,即使發生系統故障也不會遺失。
#5
★★★
資料庫正規化 (Database Normalization)
目的
正規化是在關聯式資料庫設計中,減少數據冗餘 (Redundancy) 和改善數據完整性 (Integrity) 的過程。
- 透過將大型表格分解為更小、結構更良好的表格,並定義它們之間的關聯。
- 主要範式 (Normal Forms):第一正規化 (1NF), 第二正規化 (2NF), 第三正規化 (3NF), BCNF 等。
- 目標:消除插入、更新和刪除異常。
#6
★★★★★
NoSQL (Not Only SQL) 資料庫 - 基本概念
核心特性
NoSQL 資料庫是一類非關聯式的資料庫,設計用來處理大規模、高併發、多樣化的數據。
- 彈性綱要 (Flexible Schema):不需要預先定義嚴格的表格結構。
- 水平擴展性 (Horizontal Scalability):易於透過增加更多伺服器來擴展容量和效能。
- 高可用性 (High Availability):通常設計為分佈式,能容忍部分節點故障。
- 不同的一致性模型:通常放寬 ACID 要求,採用 BASE (Basically Available, Soft state, Eventually consistent) 模型,強調最終一致性 (Eventual Consistency)。
#7
★★★★★
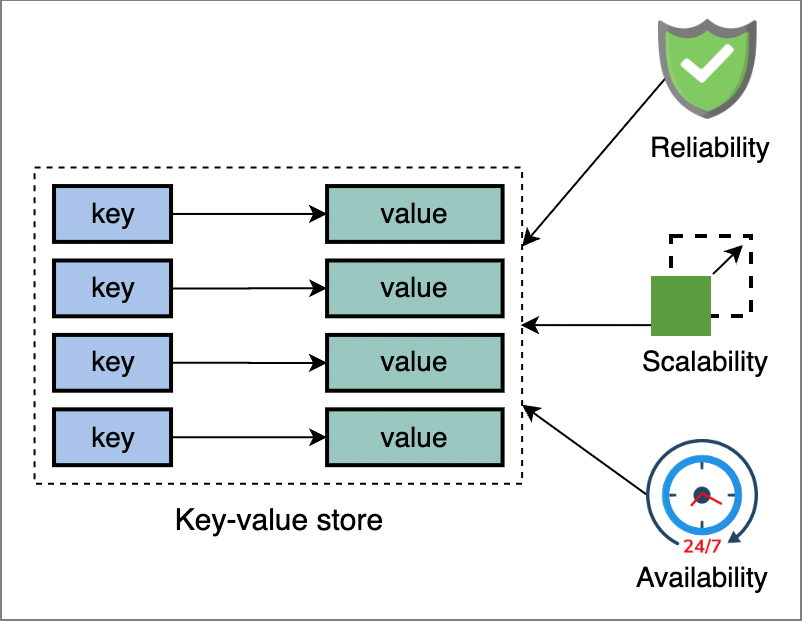
NoSQL 資料庫類型 - 鍵值儲存 (Key-Value Store)
特性與範例
- 模型:將數據儲存為唯一的鍵和與之關聯的值(可以是簡單類型或複雜物件)。
- 操作:主要透過鍵進行快速的讀取 (Get)、寫入 (Put)、刪除 (Delete) 操作。
- 優點:結構簡單、極高讀寫效能、易於擴展。
- 缺點:通常不支援複雜查詢(如範圍查詢、條件查詢)。
- 範例:Redis, Memcached, Amazon DynamoDB (部分特性)。
- 應用:快取 (Caching)、會話管理 (Session Management)、使用者設定檔。
#8
★★★★★
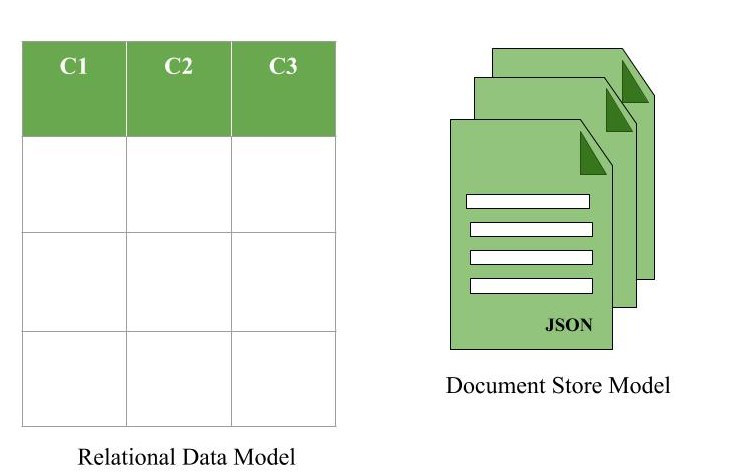
NoSQL 資料庫類型 - 文件資料庫 (Document Store)
特性與範例
- 模型:將數據儲存為文件(通常是 JSON, BSON, XML 格式),文件內部可以有巢狀結構。
- 操作:可以根據文件內容進行查詢和索引。
- 優點:彈性綱要,適合儲存結構多變或複雜的數據,開發直觀。
- 缺點:跨文件交易支持較弱,某些複雜查詢效能可能不如關聯式資料庫。
- 範例:MongoDB, Couchbase, Elasticsearch (部分特性)。
- 應用:內容管理系統 (CMS)、產品目錄、使用者設定檔。
#9
★★★★
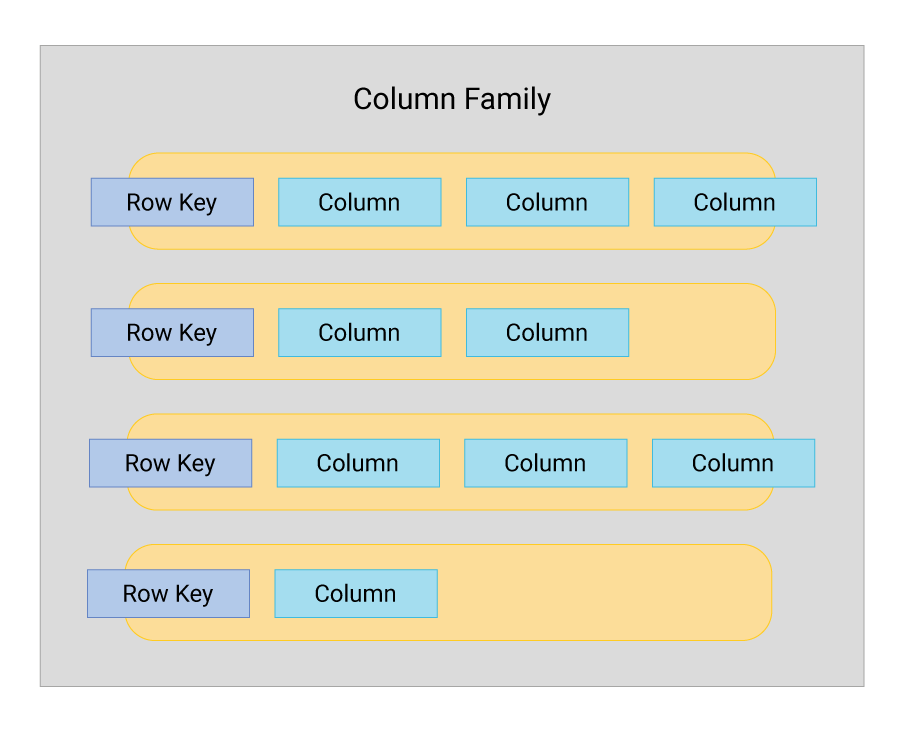
NoSQL 資料庫類型 - 欄式資料庫 (Column-Family Store)
特性與範例
- 模型:資料按欄族 (Column Family) 組織,每個欄族包含多個欄。與關聯式資料庫的按「列」儲存不同,它優化了按「欄」讀取的效能。
- 操作:適合對大量資料的特定欄進行聚合或分析。
- 優點:高可擴展性、高寫入效能、高效的欄壓縮和查詢。
- 缺點:資料模型較複雜,不適合頻繁更新單列多欄資料。
- 範例:Apache Cassandra, HBase。
- 應用:時間序列資料、日誌分析、大數據分析。
#10
★★★★
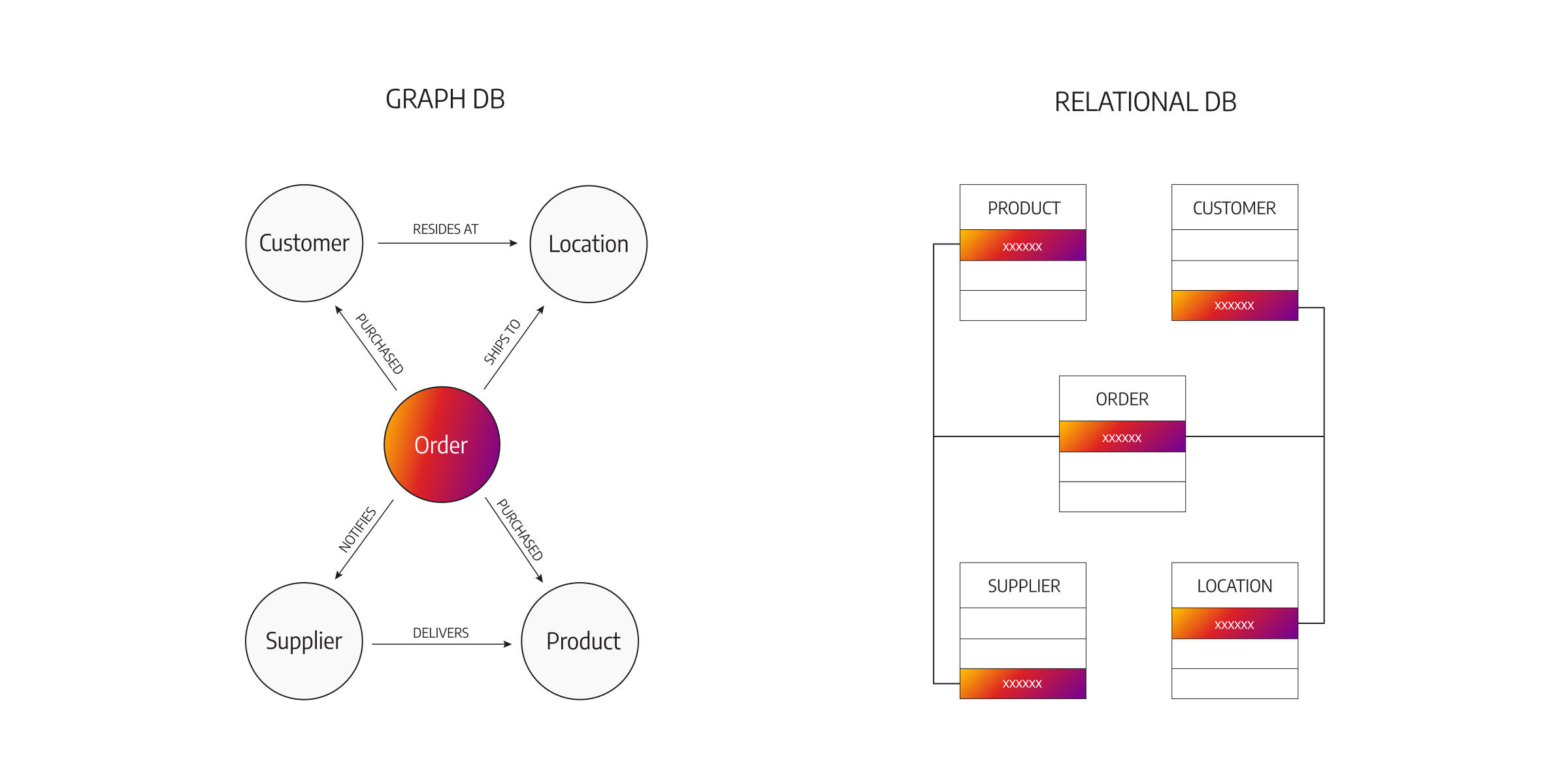
NoSQL 資料庫類型 - 圖形資料庫 (Graph Database)
特性與範例
- 模型:使用節點 (Nodes / Vertices) 代表實體,邊 (Edges / Relationships) 代表實體間的關係,節點和邊都可以有屬性。
- 操作:優化了對複雜關係(如朋友的朋友、多層次推薦)的遍歷和查詢。
- 優點:非常適合處理高度連接的數據,關係查詢效能遠超其他類型資料庫。
- 缺點:不適合處理大量的簡單聚合操作。
- 範例:Neo4j, Amazon Neptune。
- 應用:社交網路分析、推薦系統、知識圖譜、詐欺偵測。
#11
★★★★
選擇 RDBMS vs NoSQL
考量因素
選擇哪種資料庫取決於應用需求:
- 數據結構:結構固定且關係明確 → RDBMS;結構多變或非結構化 → NoSQL。
- 一致性要求:強一致性 (ACID) → RDBMS;可接受最終一致性 → NoSQL。
- 擴展性需求:垂直擴展為主 → RDBMS;需要大規模水平擴展 → NoSQL。
- 查詢複雜性:複雜的 JOIN 和交易 → RDBMS;針對特定模式優化的查詢(Key查詢、關係查詢)→ NoSQL。
- 開發模型:需要預先設計綱要 → RDBMS;彈性綱要,快速迭代 → NoSQL。
#12
★★★★★
資料倉儲 (Data Warehouse) - 定義與目的
核心概念
資料倉儲是一個整合、主題導向、時間相關且不可變的數據集合,主要用於支援商業智慧 (Business Intelligence, BI) 和決策分析。
- 整合:從多個異質來源收集數據並轉換為一致的格式。
- 主題導向:圍繞特定業務主題(如客戶、產品、銷售)組織數據。
- 時間相關:數據包含時間維度,用於趨勢分析。
- 不可變 (Non-volatile):數據一旦寫入通常不修改,主要用於讀取分析。
- 數據模型:常使用星型綱要 (Star Schema) 或雪花綱要 (Snowflake Schema)。
- 處理流程:通常涉及 ETL (Extract, Transform, Load) 過程。
#13
★★★★★
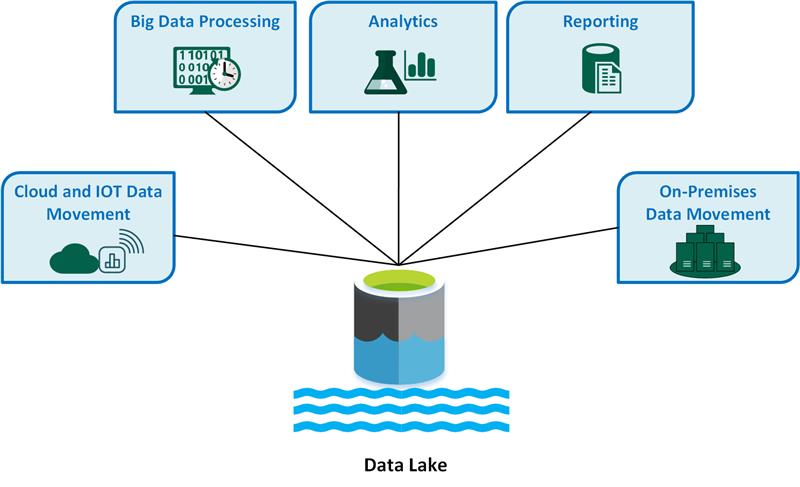
資料湖 (Data Lake) - 定義與目的
核心概念
資料湖是一個集中式儲存庫,允許以原始格式儲存大量、多樣化(結構化、半結構化、非結構化)的數據。
- 儲存原始數據:數據在載入時不需預先定義綱要或進行轉換 (Schema-on-Read)。
- 彈性:支援各種分析需求,包括數據探索、機器學習、BI。
- 可擴展性:通常建立在可擴展的儲存技術(如 HDFS, 物件儲存)之上。
- 挑戰:若管理不當,可能變成數據沼澤 (Data Swamp),難以查找和使用數據。需要良好的數據治理和元數據管理。
- 處理流程:常涉及 ELT (Extract, Load, Transform) 過程。
#14
★★★★
資料倉儲 vs 資料湖
主要區別
| 特性 | 資料倉儲 (Data Warehouse) | 資料湖 (Data Lake) |
|---|---|---|
| 數據類型 | 結構化, 已處理 | 所有類型 (結構化, 半結構化, 非結構化), 原始 |
| 綱要 (Schema) | 預先定義 (Schema-on-Write) | 讀取時定義 (Schema-on-Read) |
| 主要使用者 | 商業分析師 (BI) | 數據科學家, 數據工程師, 分析師 |
| 主要用途 | 報表, BI 分析 | 數據探索, 機器學習, 各式分析 |
| 處理流程 | ETL | ELT (常見) |
| 彈性 | 較低 | 較高 |
#15
★★★★
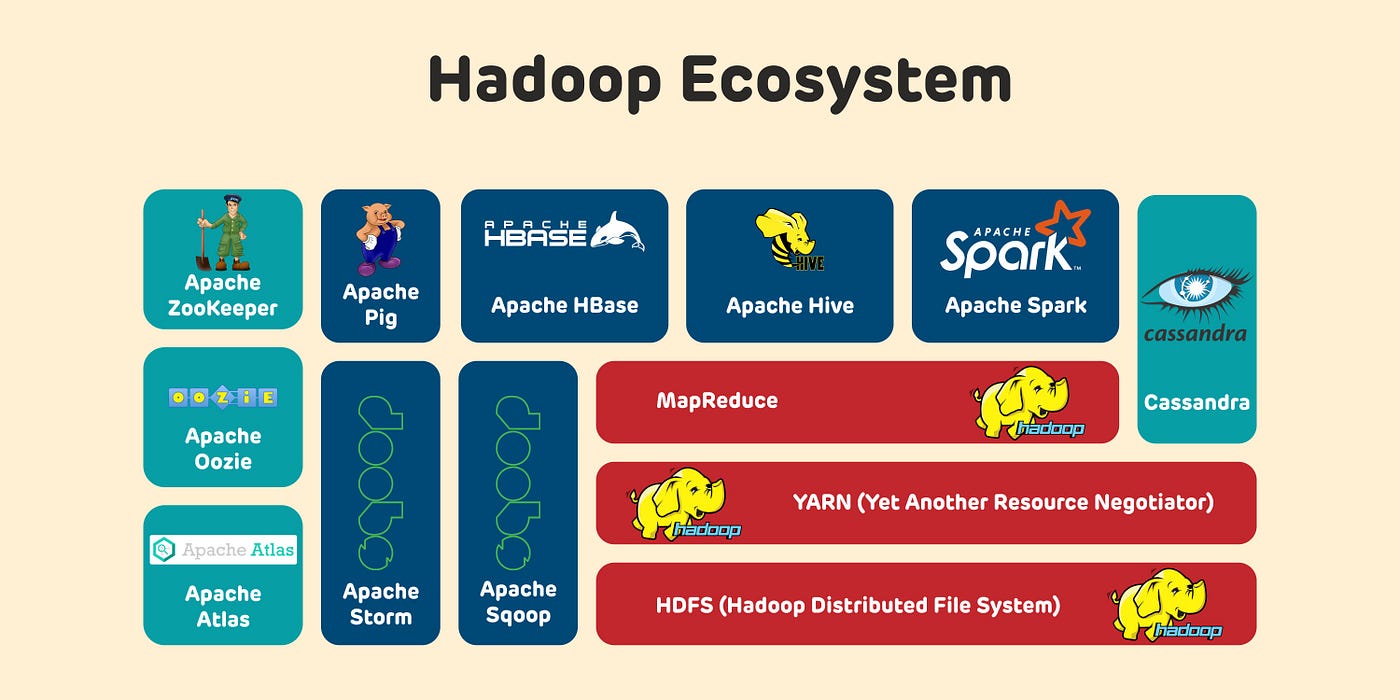
Hadoop 分散式檔案系統 (Hadoop Distributed File System, HDFS)
核心特性
HDFS 是 Apache Hadoop 專案的核心組件,設計用於在大型商用硬體叢集上儲存超大檔案。
- 容錯性 (Fault Tolerance):透過數據複製(預設複製3份)到不同節點來實現高可靠性。
- 高吞吐量 (High Throughput):優化了對大型檔案的循序讀取。
- 架構:主從式架構,包含一個 名稱節點 (NameNode) 管理元數據,多個 數據節點 (DataNode) 儲存實際數據區塊。
- 適用場景:大數據批次處理(如 MapReduce)、資料湖底層儲存。
- 不適用:低延遲的隨機讀寫、大量小檔案。
#16
★★★★
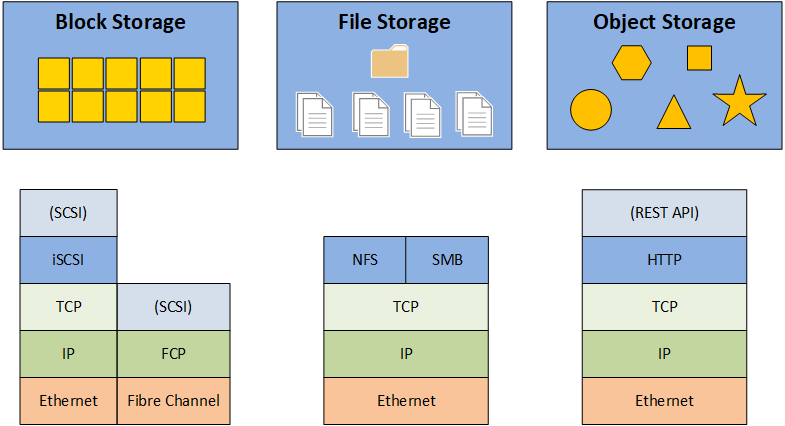
物件儲存 (Object Storage)
核心特性
物件儲存將數據作為物件(包含數據本身、元數據和唯一識別碼)儲存在扁平的地址空間中,而非傳統的階層式檔案系統。
- 高可擴展性:易於擴展到極大的容量。
- 高持久性:通常透過多副本或糾刪碼 (Erasure Coding) 實現。
- API 存取:主要透過 HTTP/REST API 進行存取。
- 成本效益:通常比區塊儲存或檔案儲存更便宜。
- 適用場景:非結構化數據(圖片、影音、備份)、雲原生應用、資料湖儲存。
- 範例:AWS S3, Azure Blob Storage, GCP Cloud Storage, Ceph。
#17
★★★★
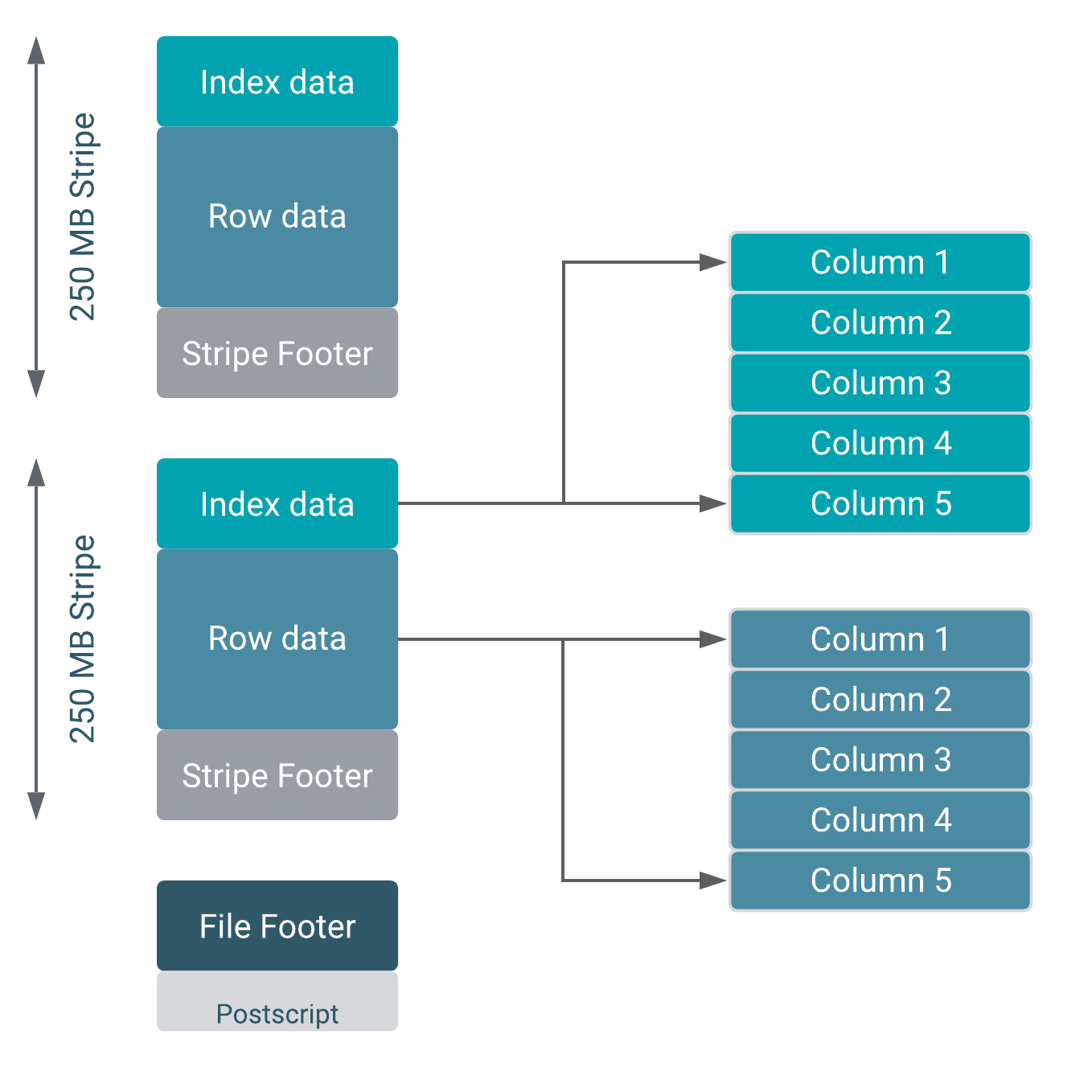
欄式儲存格式 (Columnar Storage Formats) - Parquet, ORC
優點與適用
Parquet 和 Optimized Row Columnar (ORC) 是大數據生態系中常用的欄式儲存格式。
- 按欄儲存:相同欄位的資料儲存在一起,而不是按列儲存。
- 優點:
- 高效壓縮:同欄資料類型相似,壓縮效果好。
- 高效查詢:分析查詢通常只涉及部分欄位,欄式儲存只需讀取相關欄位,減少 I/O。
- 支援條件下推 (Predicate Pushdown),進一步減少讀取量。
- 適用場景:資料倉儲、資料湖中的分析型工作負載(OLAP),尤其適合搭配 Spark, Hive, Presto 等引擎。

#18
★★★★★
雲端儲存服務 - 主要類型
常見選項
主流雲端供應商提供多樣化的儲存服務:
- 物件儲存 (Object Storage):如 AWS S3, Azure Blob Storage, GCP Cloud Storage。高度可擴展、高持久性、成本效益高,適合儲存大量非結構化數據、備份、資料湖。
- 檔案儲存 (File Storage):提供共享檔案系統介面(如 NFS, SMB),適合需要傳統檔案系統語義的應用。如 AWS EFS, Azure Files, GCP Filestore。
- 區塊儲存 (Block Storage):提供原始儲存區塊,如同附加的硬碟,通常用於掛載到雲端伺服器 (VM) 作為作業系統碟或資料碟,提供低延遲。如 AWS EBS, Azure Disk Storage, GCP Persistent Disk。
- 資料庫服務:雲端供應商也提供託管的關聯式資料庫(如 AWS RDS, Azure SQL Database)和 NoSQL 資料庫(如 AWS DynamoDB, Azure Cosmos DB)。
#19
★★★
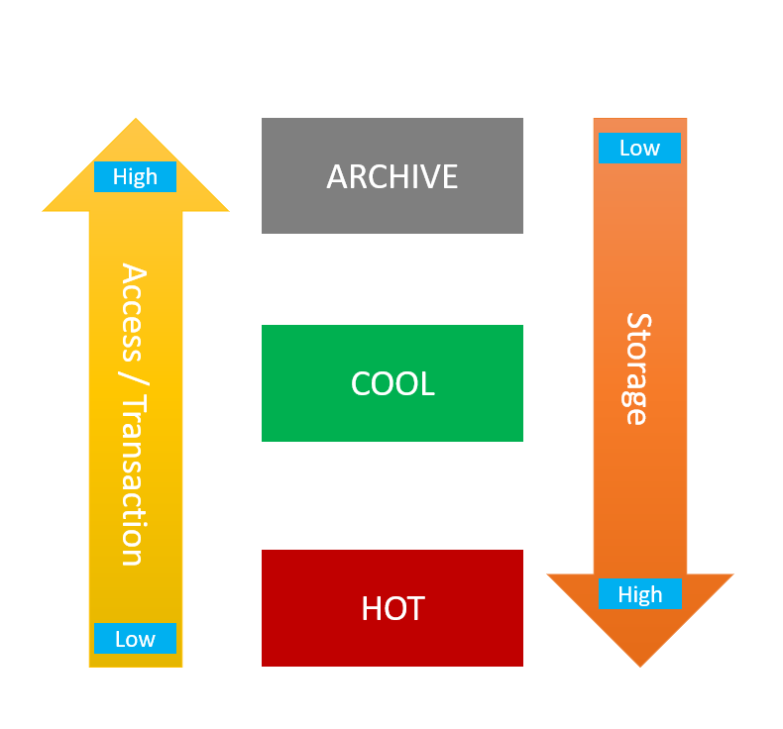
雲端儲存分層 (Cloud Storage Tiers)
概念與目的
雲端物件儲存通常提供不同的儲存層級(分層),以平衡成本、存取效能和可用性。
- 標準層/常用層 (Standard/Hot Tier):最高效能、最高可用性、最高成本,適合頻繁存取的數據。
- 不常存取層 (Infrequent Access/Cool Tier):效能和可用性略低、儲存成本較低、存取成本較高,適合不常存取但需要快速取用的數據(如備份)。
- 封存層/冷層 (Archive/Cold Tier):最低儲存成本、最低存取效能(可能需要數分鐘到數小時才能取回)、最高的存取成本,適合長期封存、法規遵循數據。如 AWS Glacier, Azure Archive Storage。
#20
★★★★
元數據管理 (Metadata Management)
重要性
元數據是描述數據的數據。有效的元數據管理對於理解、查找、使用和治理數據至關重要,尤其是在資料湖環境中。
- 類型:
- 技術元數據:數據結構、格式、儲存位置、資料類型。
- 業務元數據:業務定義、術語、擁有者、使用規則。
- 操作元數據:數據來源、處理歷史、存取記錄、生命週期。
- 目的:提升數據可發現性 (Discoverability)、可理解性 (Understandability)、信任度 (Trust) 和合規性 (Compliance)。
- 常用工具:數據目錄 (Data Catalog) 如 Apache Atlas, AWS Glue Data Catalog。
#21
★★★★
數據品質管理 (Data Quality Management)
核心維度
數據品質是指數據滿足其預期用途的程度。評估數據品質通常考慮以下維度:
- 準確性 (Accuracy):數據是否正確反映真實世界的情況。
- 完整性 (Completeness):是否存在缺失值或缺少必要的記錄。
- 一致性 (Consistency):數據在不同系統或時間點是否相互矛盾。
- 及時性 (Timeliness):數據是否在其需要的時間內可用。
- 唯一性 (Uniqueness):是否存在重複的記錄。
- 有效性 (Validity):數據是否符合預定義的格式、類型或範圍規則。
#22
★★★★★
數據安全與隱私 (Data Security & Privacy)
關鍵措施
在數據儲存和管理中,保護數據安全和使用者隱私至關重要。
- 存取控制 (Access Control):確保只有授權人員才能存取特定數據(如基於角色的存取控制 RBAC)。
- 加密 (Encryption):對靜態數據(儲存中)和傳輸中數據進行加密。
- 數據遮罩/去識別化 (Data Masking / De-identification):對敏感資訊(如身分證號、姓名)進行模糊化或移除處理。
- 稽核記錄 (Audit Logging):記錄數據的存取和修改歷史。
- 法規遵循 (Compliance):遵守相關法規要求,如 GDPR (General Data Protection Regulation)、個資法。
#23
★★★
數據生命週期管理 (Data Lifecycle Management, DLM)
概念
DLM 是指對數據從創建/收集到最終銷毀的整個過程進行策略性管理。
- 包含定義數據的儲存策略(如不同階段使用不同儲存層級)、保留期限、封存規則、銷毀程序等。
- 目標:優化儲存成本、確保法規遵循、降低風險。
- 雲端儲存服務通常提供自動化的生命週期管理功能。
沒有找到符合條件的重點。
↑