iPAS AI應用規劃師 考試重點
L22201 數據收集與清理
主題分類
1
數據收集來源與方法
2
數據格式與儲存
3
數據品質問題識別
4
處理缺失值
5
處理錯誤值/異常值
6
數據類型轉換
7
數據標準化/正規化
8
數據清理工具與流程
#1
★★★★★
數據收集 (Data Collection) 的重要性
核心概念
數據收集是機器學習和 AI 專案的起點。收集到的數據品質和相關性直接影響模型的效能和可靠性。垃圾進,垃圾出 (Garbage In, Garbage Out, GIGO) 原則強調了高品質數據的重要性。規劃師需理解不同收集方法以獲取符合專案需求的數據。
#2
★★★★
數據來源 - 內部數據 vs 外部數據
分類
- 內部數據 (Internal Data):來自組織內部系統的數據,如銷售紀錄、客戶關係管理 (Customer Relationship Management, CRM) 系統、生產數據等。通常較易取得且相關性高。
- 外部數據 (External Data):來自組織外部的數據,如政府公開資料、社群媒體、市場調查報告、第三方數據供應商等。可提供更廣泛的背景資訊。
#3
★★★★
數據收集方法 - 結構化數據
常見方式
收集有固定格式和欄位的數據:
- 資料庫查詢 (Database Query):使用 SQL (Structured Query Language) 從關聯式資料庫中提取數據。
- 應用程式介面 (Application Programming Interface, API):透過程式介面從特定服務或系統(如社群平台、天氣服務)獲取數據,通常以 JSON 或 XML 格式返回。
- 檔案匯入:直接讀取已存在的結構化檔案,如 CSV、Excel 檔案。
- 表單/問卷:透過線上或紙本表單收集使用者輸入。
#4
★★★
數據收集方法 - 非結構化/半結構化數據
常見方式
收集沒有固定格式(如文字、圖片)或有彈性格式(如 JSON、XML)的數據:
- 網頁爬蟲 (Web Scraping):自動化程式從網站上提取資訊。需注意合法性(網站的 `robots.txt` 規定)與道德性。
- 感測器數據收集 (Sensor Data Acquisition):從物聯網 (IoT) 裝置、穿戴式裝置等收集數據。
- 文本/圖像/影音擷取:從文件、圖片庫、影音平台等來源獲取資料。
- 日誌檔案 (Log Files):收集伺服器、應用程式產生的操作記錄。
#5
★★★★★
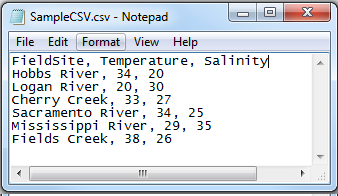
常見數據格式 - CSV (Comma-Separated Values)
特性
- 純文字格式,用逗號(或其他分隔符)分隔欄位值。
- 通用性高,易於讀寫和處理,被多數數據分析工具支援。
- 缺點:無法儲存複雜的數據結構(如巢狀資料)、沒有內建的數據類型資訊。
#6
★★★★
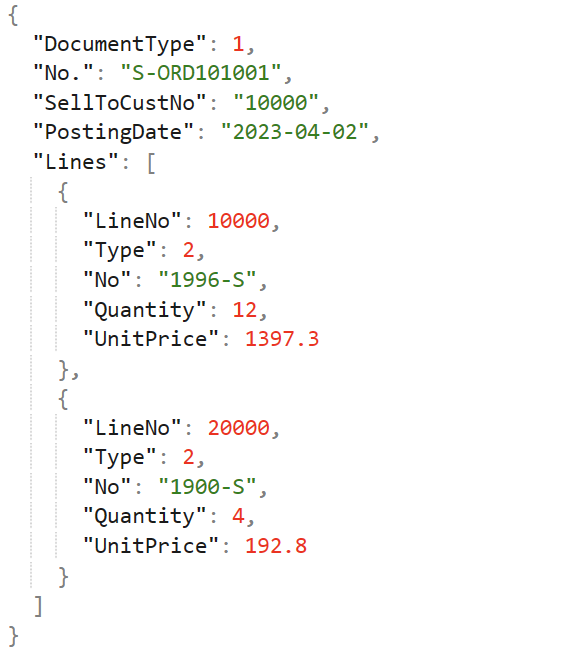
常見數據格式 - JSON (JavaScript Object Notation)
特性
- 基於 JavaScript 語法的輕量級數據交換格式。
- 使用鍵值對 (Key-Value Pairs) 和陣列 (Arrays) 來組織數據,易於人類閱讀和機器解析。
- 支援巢狀結構,常用於 API 資料傳輸和 NoSQL 資料庫。
- 缺點:相較於二進位格式可能較佔空間。
#7
★★★
常見數據格式 - XML (eXtensible Markup Language)
特性
- 使用標籤 (Tags) 來定義數據結構,類似 HTML。
- 具有良好的擴展性和自我描述性。
- 也支援巢狀結構,常用於配置文件、Web 服務(如 SOAP)。
- 缺點:格式相對冗長,解析速度可能比 JSON 慢。

#8
★★★
數據儲存 (Data Storage) 考量
主要因素
選擇數據儲存方案需考慮:
- 數據量 (Volume):數據有多大?
- 數據類型與結構 (Variety):是結構化、半結構化還是非結構化?
- 讀寫速度需求 (Velocity):數據產生和存取的速度有多快?
- 成本:儲存和維護的費用。
- 可擴展性 (Scalability):是否容易擴充容量?
- 安全性 (Security):數據保護措施。
#9
★★★★★
數據清理 (Data Cleaning / Data Cleansing) 的目的
核心目標
數據清理是識別和修正(或移除)數據集中錯誤、不完整、不一致或不相關的部分的過程。
- 目標:提高數據品質,確保數據的準確性、一致性和完整性,為後續分析和模型建立提供可靠的基礎。
- 是數據前處理 (Data Preprocessing) 中最耗時但至關重要的步驟之一。
#10
★★★★★
常見數據品質問題 - 缺失值 (Missing Values)
定義與成因
缺失值是指數據集中某些觀測值的某些欄位沒有數值。
- 常見表示:NaN (Not a Number), NULL, 空白格。
- 成因:數據收集錯誤、使用者未填寫、系統故障、數據合併問題等。
- 影響:許多演算法無法直接處理缺失值,可能導致分析結果偏差或錯誤。
#11
★★★★
常見數據品質問題 - 錯誤值/異常值 (Erroneous Values / Outliers)
定義與成因
- 錯誤值:明顯不合理或不符合定義的數值(如年齡為負數、性別為未知字元)。通常由輸入錯誤、測量錯誤造成。
- 異常值/離群值:顯著偏離數據集中大多數值的觀測值。可能是真實的極端情況,也可能是錯誤。
#12
★★★★
常見數據品質問題 - 不一致性 (Inconsistency)
表現形式
不一致性指數據中存在矛盾或不符的情況。
- 格式不一致:日期格式多樣("YYYY-MM-DD", "MM/DD/YY")、單位不統一(公斤 vs 磅)。
- 命名不一致:同一類別有多種表示方式("台北市", "臺北市", "Taipei")。
- 邏輯不一致:出生日期晚於入院日期、訂單狀態與付款狀態矛盾。
#13
★★★
常見數據品質問題 - 重複數據 (Duplicate Data)
定義與影響
重複數據指數據集中存在完全相同或幾乎相同的記錄。
- 成因:數據輸入錯誤、系統合併、多次收集。
- 影響:可能扭曲統計分析結果(如誇大計數)、增加儲存成本、影響模型訓練。
- 處理:需要識別並移除重複的記錄,保留唯一值。
#14
★★★★★
處理缺失值 - 刪除法 (Deletion)
方法與考量
最簡單的處理方式是直接刪除含有缺失值的數據。
- 列刪除/個案刪除 (Listwise/Casewise Deletion):刪除任何欄位有缺失值的整筆記錄。簡單易行,但如果缺失值比例高或呈非隨機分佈,可能損失大量資訊並導致樣本偏差。
- 欄刪除/變數刪除 (Column Deletion):如果某個欄位的缺失值比例非常高(如 > 50-70%),且該欄位對分析不重要,可考慮刪除整個欄位。
#15
★★★★★
處理缺失值 - 插補法 (Imputation) - 平均數/中位數/眾數插補
方法與適用
插補法是用估計值取代缺失值。這是常用的方法。
- 平均數插補 (Mean Imputation):用該欄位的非缺失值的平均數填補缺失值。適用於數值型資料,但會減小變異數,且受異常值影響。
- 中位數插補 (Median Imputation):用該欄位的非缺失值的中位數填補缺失值。適用於數值型資料,尤其是在偏態分佈或有異常值時,比平均數插補更穩健。
- 眾數插補 (Mode Imputation):用該欄位的非缺失值的眾數填補缺失值。主要適用於類別型資料。
#16
★★★
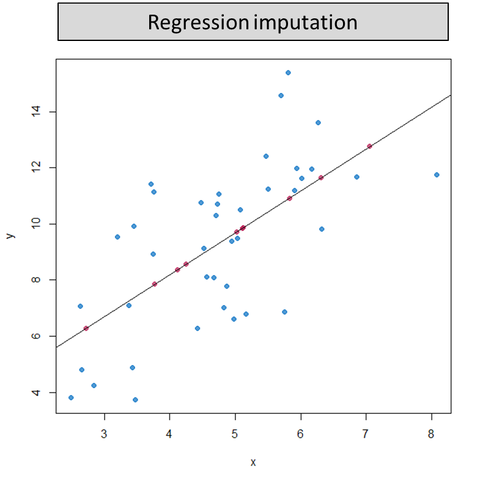
處理缺失值 - 插補法 (Imputation) - 迴歸插補
方法
迴歸插補 (Regression Imputation) 利用其他相關變數來預測缺失值。
- 建立一個迴歸模型,以含有缺失值的變數為應變數,其他相關變數為自變數。
- 用訓練好的模型預測缺失值並填補。
- 優點:考慮了變數間的關係,通常比簡單插補更準確。
- 缺點:模型建立較複雜,且可能引入基於模型的偏差。
#17
★★★
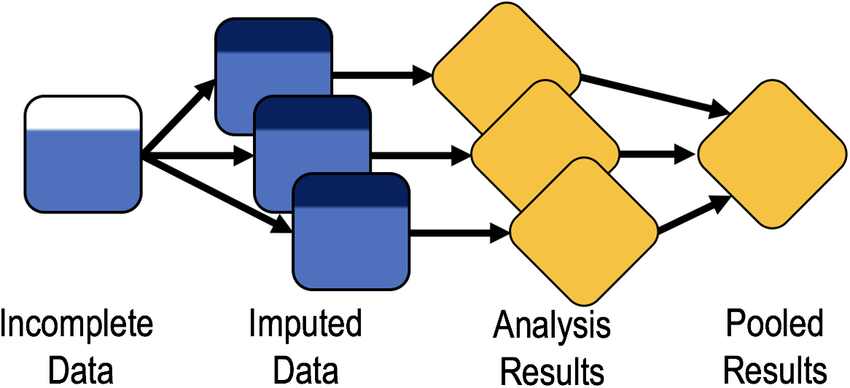
處理缺失值 - 多重插補 (Multiple Imputation)
概念
多重插補是一種更進階的插補技術,它多次(例如 5-10 次)對缺失值進行插補,產生多個完整的數據集。
- 每次插補會考慮缺失值的不確定性,引入隨機性。
- 對每個插補後的數據集進行分析,最後將結果合併,以考慮插補帶來的不確定性。
- 優點:能較好地處理缺失值的不確定性,提供更可靠的統計推論。
- 缺點:過程較複雜。
#18
★★★★
處理錯誤值/異常值 - 偵測方法回顧
常用技術
識別錯誤值和異常值是清理的前提。常見方法(複習自 L22101):
- 視覺化探索:盒鬚圖 (Box Plot)、散佈圖 (Scatter Plot)、直方圖 (Histogram)。
- 統計方法:
- IQR 法則:基於四分位距識別異常值 (Q1 - 1.5*IQR, Q3 + 1.5*IQR)。
- Z 分數法:基於標準差識別異常值(如 |Z| > 3)。
- 領域知識 (Domain Knowledge):判斷數值是否在合理範圍內。
#19
★★★★
處理錯誤值/異常值 - 處理策略
主要方法
根據值的性質和分析目標選擇處理方式:
- 修正 (Correction):如果確定是輸入錯誤且能找到正確值,則進行修正。
- 刪除 (Deletion):若錯誤值無法修正,或異常值對模型產生嚴重干擾且非分析重點,可考慮刪除整筆記錄(謹慎使用)。
- 插補/替換 (Imputation/Replacement):類似處理缺失值,可用平均數、中位數等替換異常值,或使用設限法 (Capping/Winsorizing) 將其替換為邊界值(如 1% 和 99% 百分位數)。
- 轉換 (Transformation):對數據進行對數、平方根等轉換,可能減輕異常值的影響。
- 保留 (Keeping):若異常值是真實且重要的(如金融詐欺),則應保留,或使用對異常值穩健的演算法。
#20
★★★★
數據類型轉換 (Data Type Conversion)
需求與場景
有時需要將數據從一種類型轉換為另一種,以滿足分析或模型的需求。
- 字串轉數值:將表示數字的文字(如 "123")轉換為數值型態 (integer/float)。
- 數值轉類別(分箱/離散化, Binning/Discretization):將連續數值(如年齡)劃分為不同的區間(如 "青年", "中年", "老年")。
- 類別轉數值(編碼, Encoding):將類別文字轉換為數值表示,以便機器學習模型處理。常見方法有標籤編碼 (Label Encoding) 和獨熱編碼 (One-Hot Encoding)。(此部分與特徵工程重疊)
- 日期/時間轉換:將字串轉換為標準的日期時間格式,以便進行時間相關計算。
#21
★★★★★
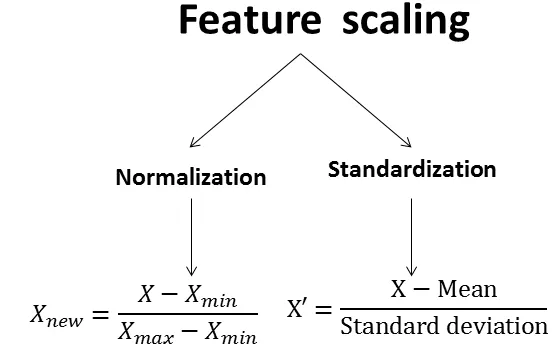
數據標準化 (Standardization / Z-score Normalization)
定義與公式
標準化是將數據轉換為平均數為 0,標準差為 1 的分佈。
- 公式:Z = (X - μ) / σ,其中 X 是原始值,μ 是平均數,σ 是標準差。
- 目的:消除不同變數因單位或尺度不同所造成的影響,使得基於距離或梯度下降的演算法(如 SVM, Logistic Regression, Neural Networks)能更好地收斂。
- 特性:轉換後的數據沒有固定的範圍限制,保留了異常值的相對位置。
#22
★★★★★
數據正規化 (Normalization / Min-Max Scaling)
定義與公式
正規化是將數據縮放到一個固定的區間,通常是 [0, 1] 或 [-1, 1]。
- Min-Max Scaling 公式 (縮放到 [0, 1]):X_norm = (X - X_min) / (X_max - X_min)。
- 目的:與標準化類似,消除尺度差異。常用於需要數據在特定範圍內的演算法(如某些神經網路激活函數、圖像處理)。
- 特性:轉換後的數據範圍固定,但對異常值非常敏感,一個極端值可能壓縮大部分數據到一個很小的範圍。
#23
★★★
標準化 vs 正規化 的選擇
考量因素
- 演算法需求:某些演算法對輸入範圍有要求(如神經網路部分激活函數),適合正規化;基於距離的演算法(如 k-NN, PCA)或假設常態分佈的,標準化可能更適合。
- 異常值:如果數據存在較多異常值,標準化通常比 Min-Max 正規化更穩健。
- 分佈形狀:標準化不改變數據的分佈形狀,正規化會改變。
- 通常標準化是更常用的預設選擇,除非有特定理由使用正規化。
#24
★★★
數據清理常用工具
範例
- 程式語言函式庫:
- Python: Pandas (核心數據處理), NumPy (數值計算), Scikit-learn (含插補、標準化/正規化功能)。
- R: `dplyr`, `tidyr`, `data.table`。
- 試算表軟體:Microsoft Excel, Google Sheets (適合小型、簡單數據集)。
- 專用數據清理工具:OpenRefine (原 Google Refine), Trifacta 等。
- 資料庫語言:SQL 可用於查詢、篩選、更新、刪除數據。
#25
★★★★
數據清理流程
典型步驟
數據清理通常是一個迭代的過程,沒有固定順序,但常見步驟包括:
- 數據檢視與探索:理解數據結構、類型、分佈,識別潛在問題。
- 處理重複數據:查找並移除重複記錄。
- 處理缺失值:選擇合適策略(刪除、插補)。
- 處理錯誤值/異常值:偵測並決定處理方式(修正、刪除、轉換、保留)。
- 處理不一致性:統一格式、命名、單位。
- 數據類型轉換:確保數據類型符合需求。
- (可選)數據標準化/正規化:根據模型需求進行縮放。
- 驗證與記錄:檢查清理結果,記錄清理步驟與決策。
#26
★★
數據收集中的偏誤 (Bias in Data Collection)
類型與影響
數據收集中可能存在的偏誤會影響後續分析的公平性和準確性:
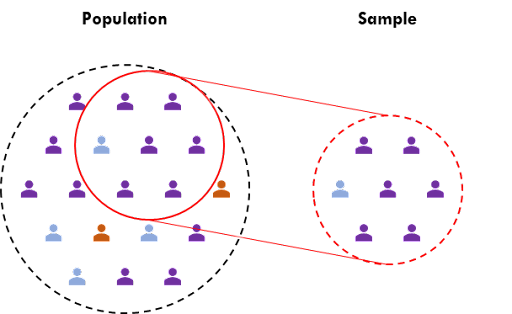
- 抽樣偏誤 (Sampling Bias):樣本未能代表目標母體。
- 選擇偏誤 (Selection Bias):選擇受試者或數據點的方式存在系統性差異。

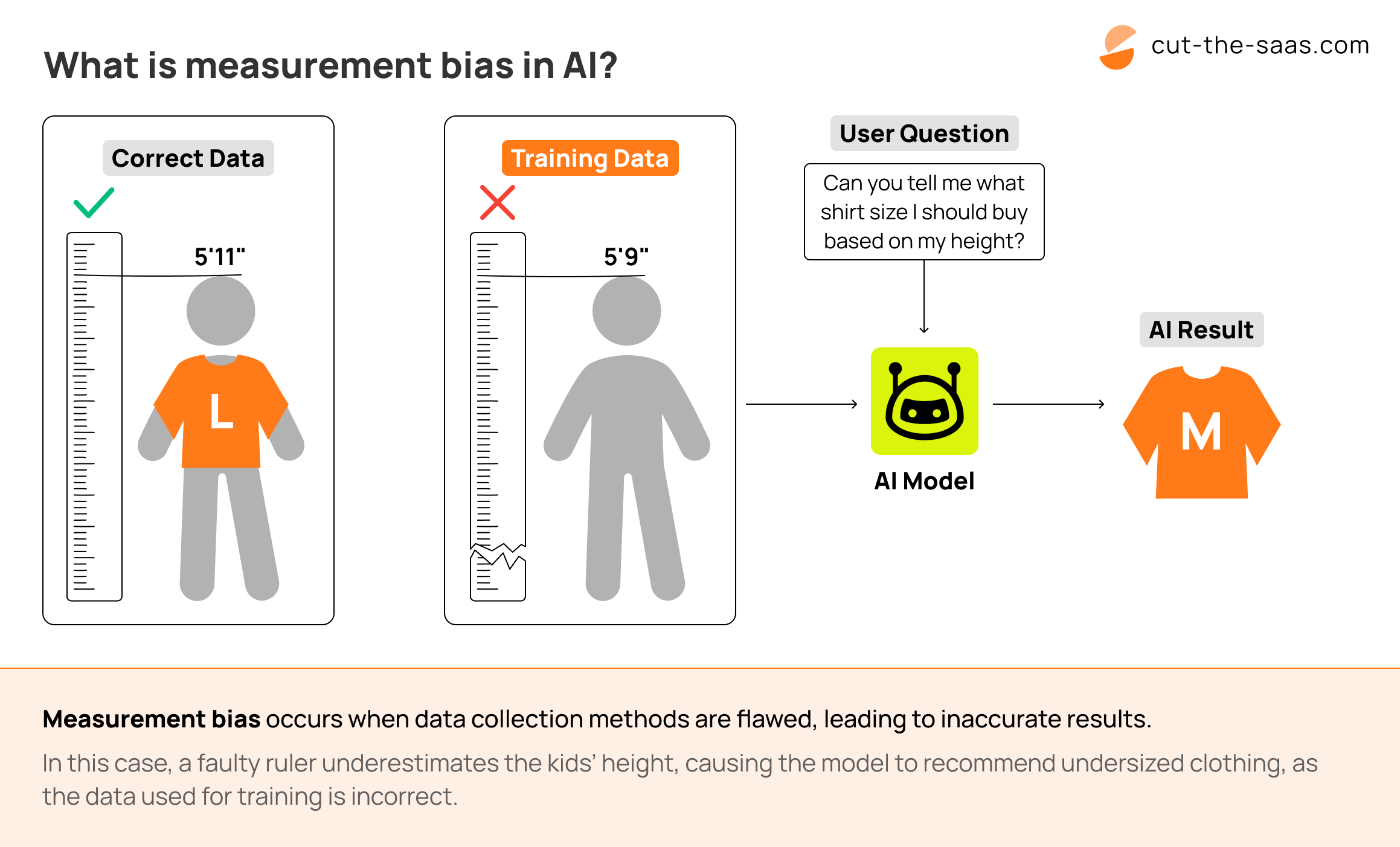
- 測量偏誤 (Measurement Bias):數據收集工具或方法本身存在系統性誤差。
沒有找到符合條件的重點。
↑