iPAS AI應用規劃師 考試重點
L22102 機率分佈與資料分佈模型
主題分類
1
機率基本概念
2
隨機變數與機率分佈
3
常見離散型機率分佈
4
常見連續型機率分佈
5
常態分佈特性與應用
6
中央極限定理
7
資料分佈模型與擬合
8
機率分佈在AI中的應用
#1
★★★★
機率 (Probability) - 基本定義
核心概念
機率是衡量某一事件 (Event) 發生可能性大小的數值。其值介於 0 到 1 之間。
- 0:表示事件不可能發生。
- 1:表示事件必然發生。
- 數值越接近 1,發生的可能性越高。
#2
★★★
樣本空間 (Sample Space) 與 事件 (Event)
基本術語
- 樣本空間 (S):一個隨機試驗 (Random Experiment) 所有可能結果的集合。例如,擲一骰子的樣本空間 S = {1, 2, 3, 4, 5, 6}。
- 事件 (E):樣本空間的一個子集合,即我們感興趣的一個或多個結果。例如,擲骰子出現奇數的事件 E = {1, 3, 5}。
#3
★★★★
機率公理 (Axioms of Probability)
基本規則
機率的計算遵循以下基本規則:
- 非負性:任何事件 E 的機率 P(E) ≥ 0。
- 歸一性:樣本空間 S 的機率 P(S) = 1。
- 可加性:若 A 和 B 為互斥事件(Mutually Exclusive,即不能同時發生),則 P(A ∪ B) = P(A) + P(B)。對於一系列互斥事件,此規則可推廣。
#4
★★★★★
隨機變數 (Random Variable) - 離散 vs 連續
定義與分類
隨機變數是一個變數,其數值是隨機現象的數值結果。
- 離散型隨機變數 (Discrete Random Variable):其可能取值是有限個或可數無限個。例如:擲骰子次數、產品缺陷數量。
- 連續型隨機變數 (Continuous Random Variable):其可能取值是在一個區間內的任何數值。例如:身高、溫度、反應時間。
#5
★★★★★
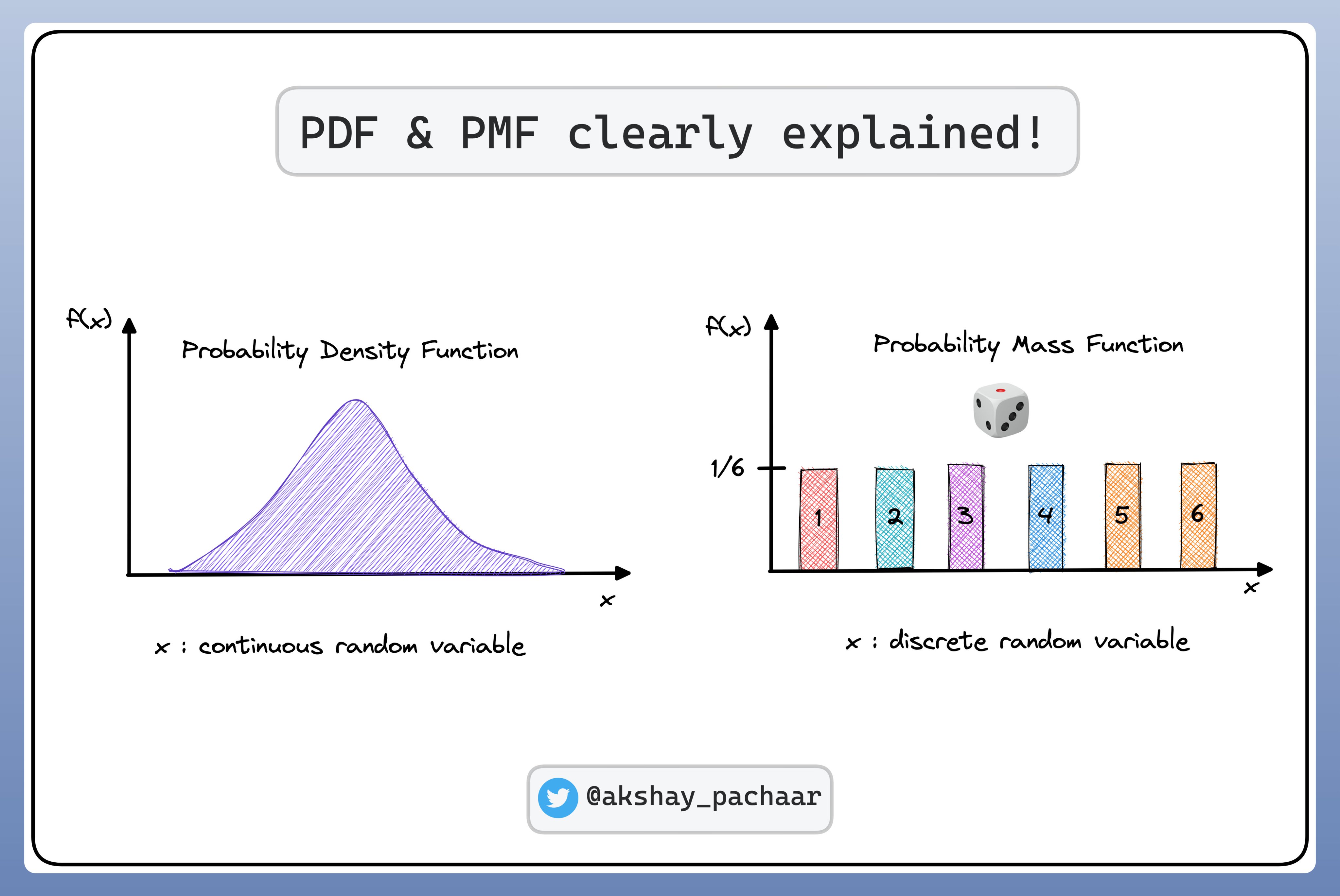
機率質量函數 (Probability Mass Function, PMF)
定義與特性
PMF 用於描述離散型隨機變數的機率分佈。
- 它給出了隨機變數取每個特定值的機率 P(X = x)。
- 特性:
- 所有可能值的機率 P(X = x) ≥ 0。
- 所有可能值的機率總和 ∑ P(X = x) = 1。
#6
★★★★★
機率密度函數 (Probability Density Function, PDF)
定義與特性
PDF 用於描述連續型隨機變數的機率分佈。
- PDF本身不是機率,而是表示數值在某點附近的相對可能性(密度)。
- 隨機變數落在某區間 [a, b] 的機率是 PDF 在該區間下的曲線下面積:P(a ≤ X ≤ b) = ∫[a,b] f(x) dx。
- 連續型隨機變數取任何單一特定值的機率為 0 (P(X = c) = 0)。
- 特性:
- f(x) ≥ 0 對於所有 x。
- 總面積(從負無限大到正無限大積分)等於 1。
#7
★★★★
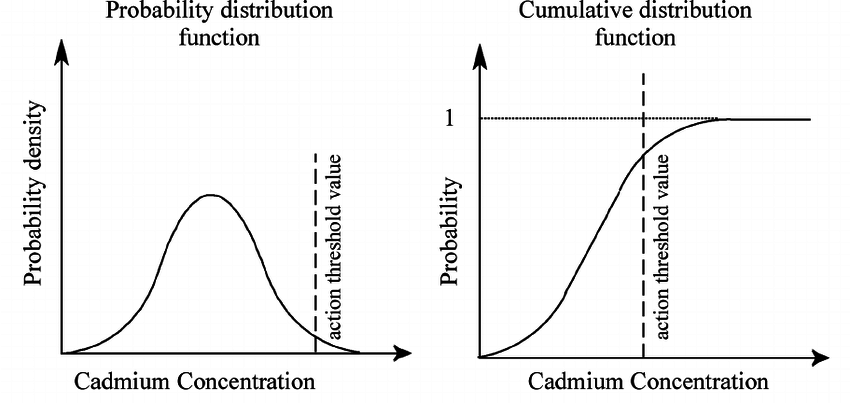
累積分布函數 (Cumulative Distribution Function, CDF)
定義與特性
CDF F(x) 定義為隨機變數 X 取值小於或等於某個特定值 x 的機率:F(x) = P(X ≤ x)。
- 適用於離散型和連續型隨機變數。
- 特性:
- 是一個非遞減函數 (Non-decreasing)。
- 其值域介於 0 和 1 之間 (0 ≤ F(x) ≤ 1)。
- 當 x 趨近負無限大時,F(x) 趨近 0;當 x 趨近正無限大時,F(x) 趨近 1。
- 對於連續型變數,CDF 是 PDF 的積分;PDF 是 CDF 的微分。
#8
★★★★
期望值 (Expected Value) E[X]
定義與意義
期望值是隨機變數所有可能取值的加權平均,權重為其對應的機率。
- 離散型:E[X] = ∑ [x * P(X = x)]
- 連續型:E[X] = ∫ [x * f(x)] dx
- 代表隨機變數長期平均值或分佈的中心位置,類似於資料的平均數。

#9
★★★★
變異數 (Variance) Var(X)
定義與意義
變異數衡量隨機變數取值偏離其期望值的程度的期望值。
- 計算:Var(X) = E[(X - E[X])²] = E[X²] - (E[X])²
- 意義:衡量隨機變數分佈的分散程度或波動性。變異數越大,分佈越分散。
- 標準差 (Standard Deviation) σ 是變異數的平方根,單位與隨機變數相同。

#10
★★★★
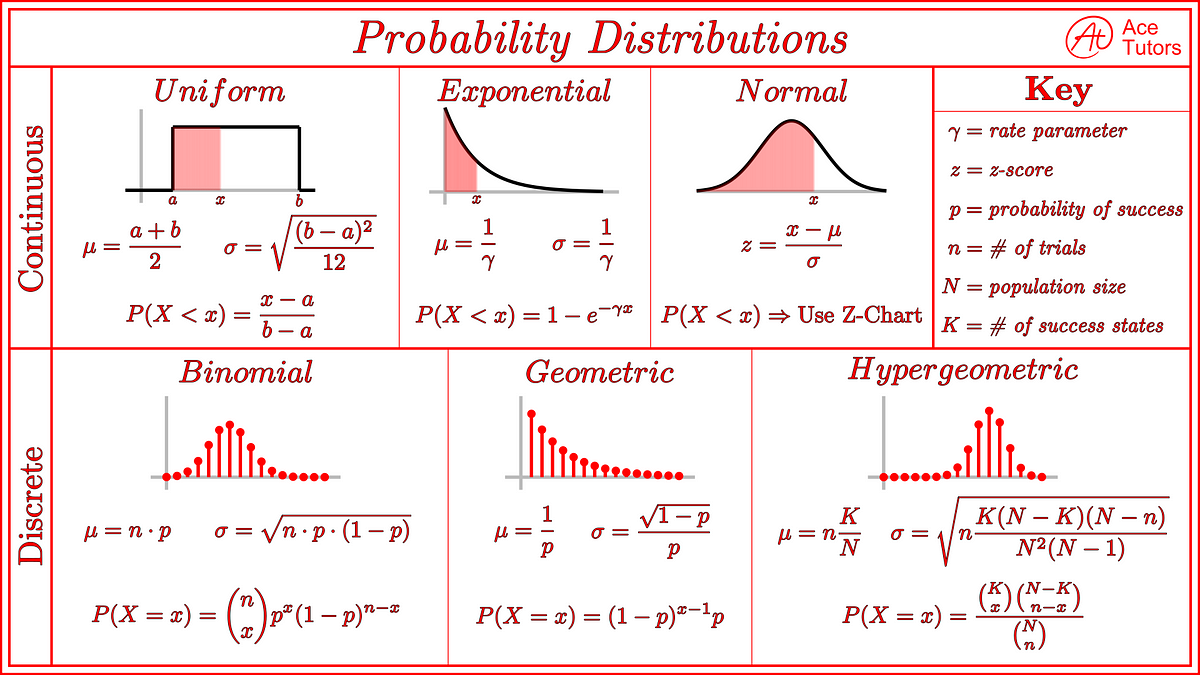
白努力分佈 (Bernoulli Distribution)
定義與應用
白努力分佈描述只有兩種可能結果(通常稱為「成功」和「失敗」)的單次隨機試驗的機率分佈。
- 參數:成功的機率 p (0 ≤ p ≤ 1)。失敗機率為 1-p。
- PMF:P(X=1) = p, P(X=0) = 1-p。
- 應用:模擬單次拋硬幣、單個產品是否合格等。
- 期望值:E[X] = p。
- 變異數:Var(X) = p(1-p)。

#11
★★★★★
二項分佈 (Binomial Distribution)
定義與應用
二項分佈描述在固定次數 n 的獨立白努力試驗中,成功次數 X 的機率分佈。
- 參數:試驗次數 n (n ≥ 1),每次試驗成功的機率 p (0 ≤ p ≤ 1)。
- PMF:P(X=k) = C(n, k) * p^k * (1-p)^(n-k),其中 k=0, 1, ..., n,C(n, k) 是組合數。
- 應用:計算 n 次拋硬幣中出現 k 次正面的機率、抽樣檢查中發現 k 個不良品的機率等。
- 期望值:E[X] = np。
- 變異數:Var(X) = np(1-p)。

#12
★★★★
卜瓦松分佈 (Poisson Distribution)
定義與應用
卜瓦松分佈描述在固定時間間隔或空間區域內,某事件發生的次數 X 的機率分佈,前提是事件獨立發生且平均發生率固定。
- 參數:平均發生次數 λ (λ > 0)。
- PMF:P(X=k) = (e^(-λ) * λ^k) / k!,其中 k=0, 1, 2, ...。
- 應用:模擬單位時間內到達服務台的顧客數、單位面積內的瑕疵數、網頁每小時的點擊次數等。
- 期望值:E[X] = λ。
- 變異數:Var(X) = λ。(期望值等於變異數是其重要特性)

#13
★★★
均勻分佈 (Uniform Distribution)
定義與特性
均勻分佈描述一個隨機變數在某個區間 [a, b] 內取任何值的可能性都相同。
- 參數:區間下限 a,區間上限 b (a < b)。
- PDF:在區間 [a, b] 內,f(x) = 1 / (b - a);在區間外,f(x) = 0。圖形呈矩形。
- 應用:模擬隨機數生成、表示在沒有任何先驗資訊下等可能性事件。
- 期望值:E[X] = (a + b) / 2。
- 變異數:Var(X) = (b - a)² / 12。
#14
★★★★★
常態分佈 (Normal Distribution / Gaussian Distribution)
定義與重要性
常態分佈是最重要的連續型機率分佈之一,在自然界和社會科學中廣泛存在。
- 參數:平均數 μ (決定中心位置),標準差 σ (σ > 0,決定分散程度)。
- PDF:f(x) = [1 / (σ * √(2π))] * e^(-(x-μ)² / (2σ²))。圖形呈鐘形、對稱。
- 重要性:許多自然現象(如身高、智商)近似常態分佈;許多統計推論方法基於常態假設;中央極限定理的核心。
#15
★★★
指數分佈 (Exponential Distribution)
定義與應用
指數分佈描述獨立事件發生所需等待時間的機率分佈,前提是事件以固定的平均速率發生。
- 參數:速率參數 λ (λ > 0),即單位時間內事件發生的平均次數。
- PDF:f(x) = λ * e^(-λx),對於 x ≥ 0。
- 應用:模擬設備壽命、顧客到達服務台的間隔時間、放射性衰變等。
- 重要特性:無記憶性 (Memorylessness)。即過去等待多久不影響未來還需等待多久的機率。
- 與卜瓦松分佈關係:若事件發生次數服從卜瓦松分佈(λ),則事件發生的間隔時間服從指數分佈(λ)。

#16
★★★★★
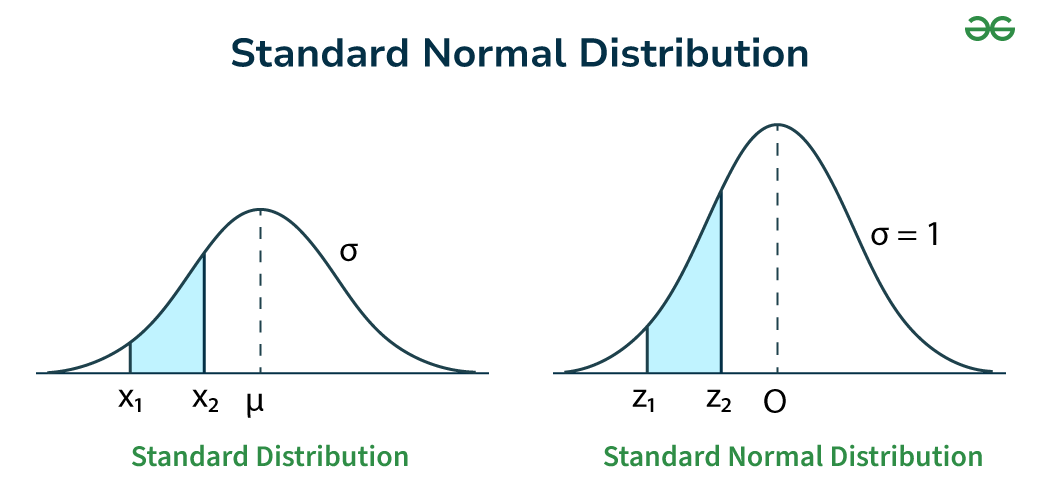
標準常態分佈 (Standard Normal Distribution)
定義與轉換
標準常態分佈是一種特殊的常態分佈,其平均數 μ = 0,標準差 σ = 1。通常用 Z 表示服從標準常態分佈的隨機變數。
- 轉換:任何常態分佈 X ~ N(μ, σ²) 可以通過標準化 (Standardization) 轉換為標準常態分佈: Z = (X - μ) / σ。
- 用途:方便查表或使用軟體計算任意常態分佈下的機率。Z值 (Z-score) 表示原始數值距離平均數有多少個標準差。
#17
★★★★
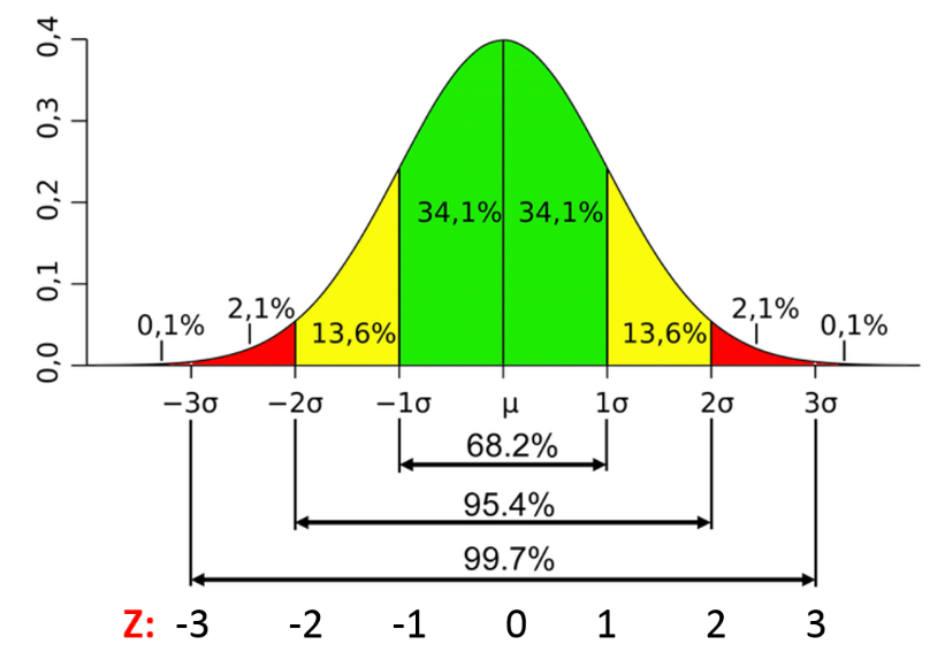
常態分佈 - 經驗法則 (68-95-99.7 Rule)
規則內容
對於常態分佈:
- 約 68% 的數值落在 平均數 ± 1 個標準差 (μ ± σ) 的範圍內。
- 約 95% 的數值落在 平均數 ± 2 個標準差 (μ ± 2σ) 的範圍內。
- 約 99.7% 的數值落在 平均數 ± 3 個標準差 (μ ± 3σ) 的範圍內。
#18
★★★★★
中央極限定理 (Central Limit Theorem, CLT)
核心思想
CLT 指出,無論原始母體的分佈為何(只要不是病態分佈且有有限的變異數),從該母體中抽取足夠大的獨立隨機樣本 (n 通常 ≥ 30),其樣本平均數 (Sample Mean) 的抽樣分佈將會近似常態分佈。
- 樣本平均數分佈的平均數等於母體平均數 μ。
- 樣本平均數分佈的標準差(稱為標準誤, Standard Error, SE)等於母體標準差 σ 除以樣本數的平方根 (σ / √n)。
- 重要性:使得我們可以利用常態分佈的性質來進行關於樣本平均數的統計推論,即使不知道母體分佈。

#19
★★★★
資料分佈模型 - 概念
意義
資料分佈模型是用一個已知的理論機率分佈(如常態、二項、卜瓦松等)來描述或近似實際觀察到的資料分佈。
- 目的:理解資料的生成機制、進行預測、模擬數據、簡化分析。
- 選擇模型:通常基於對資料性質的理解(離散/連續、範圍、形狀)以及視覺化探索(如直方圖)。
#20
★★★
模型擬合 (Model Fitting) 與 參數估計 (Parameter Estimation)
過程
模型擬合是選擇一個理論分佈模型,並估計其參數(如常態分佈的 μ 和 σ,卜瓦松分佈的 λ),使得該模型最能代表觀察到的資料。
- 參數估計方法:常用方法包括最大概似估計法 (Maximum Likelihood Estimation, MLE) 和動差法 (Method of Moments)。
- 例如,用樣本平均數估計常態分佈的 μ,用樣本標準差估計 σ。
#21
★★★
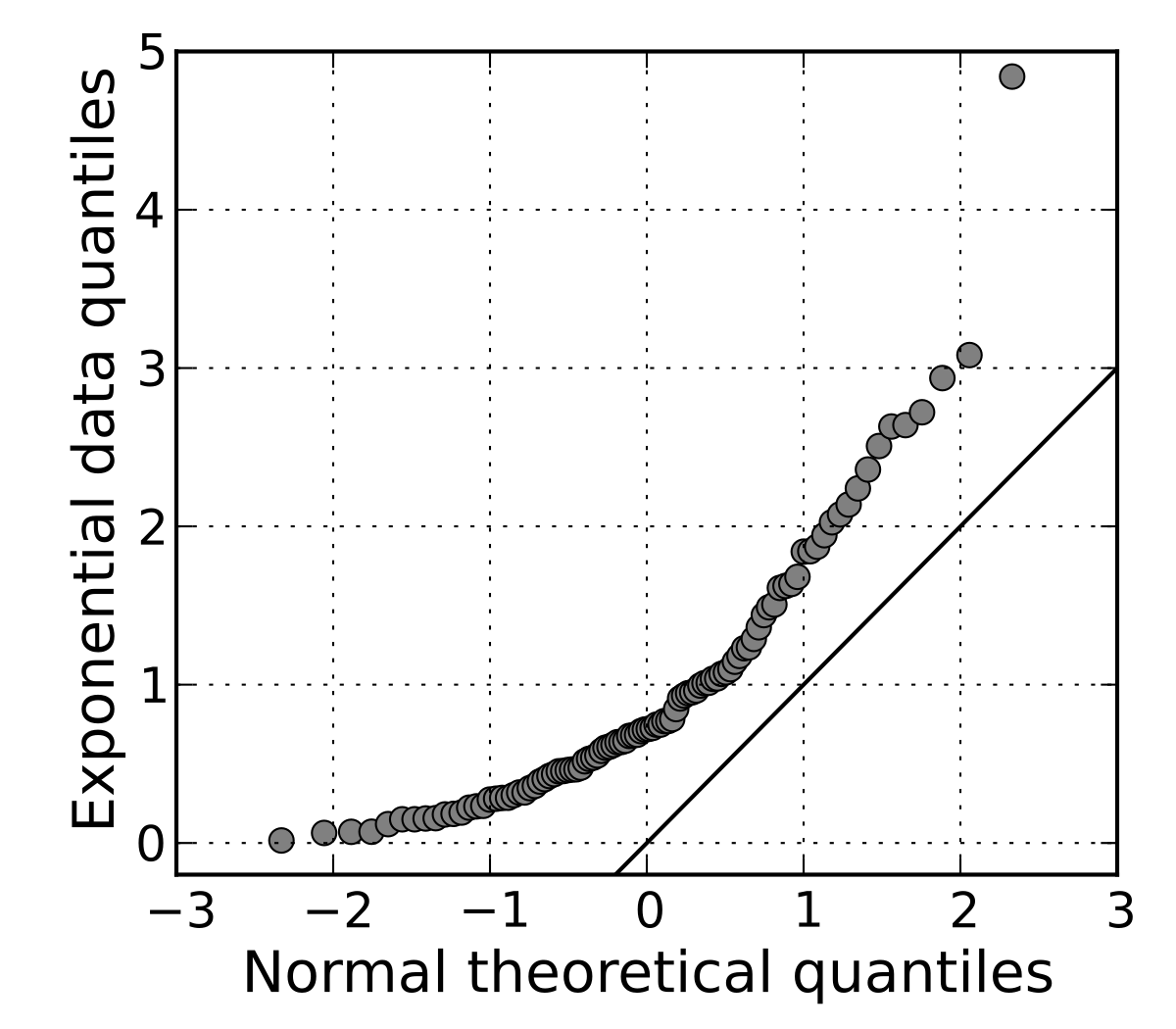
適合度檢定 (Goodness-of-Fit Test)
目的
適合度檢定用於評估觀察到的資料分佈與假設的理論分佈模型(如常態分佈)是否一致。
- 常用檢定:卡方適合度檢定 (Chi-squared Goodness-of-Fit Test) 主要用於類別資料;Kolmogorov-Smirnov 檢定 (K-S Test) 和 Shapiro-Wilk 檢定常用於檢驗常態性。
- 視覺化方法:Q-Q 圖 (Quantile-Quantile Plot) 可直觀比較資料分位數與理論分佈分位數是否接近直線。
#22
★★★★
機率分佈在機器學習中的應用
範例
機率分佈是許多AI和機器學習模型的基礎:
- 生成模型 (Generative Models):如 生成對抗網路 (GAN) 或 變分自動編碼器 (VAE) 學習資料的潛在機率分佈以生成新樣本。
- 分類器:樸素貝氏 (Naive Bayes) 分類器基於貝氏定理和特徵的條件機率分佈。羅吉斯回歸輸出屬於某類別的機率。
- 異常檢測:假設正常資料服從某種分佈(如常態分佈),偏離該分佈的點可能被視為異常。
- 模型評估:理解預測誤差的分佈。
- 強化學習:策略 (Policy) 可以是選擇動作的機率分佈。
#23
★★★
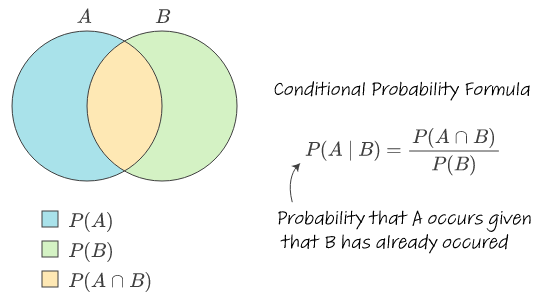
條件機率 (Conditional Probability) P(A|B)
定義
條件機率是指在事件 B 已經發生的前提下,事件 A 發生的機率。
- 計算:P(A|B) = P(A ∩ B) / P(B),其中 P(B) > 0。(P(A ∩ B) 是 A 和 B 同時發生的機率)
- 是貝氏定理等許多統計推論方法的基礎。
#24
★★★
獨立事件 (Independent Events)
定義
如果事件 A 的發生不影響事件 B 發生的機率(反之亦然),則稱 A 和 B 為獨立事件。
- 數學定義:P(A ∩ B) = P(A) * P(B)。
- 或者:P(A|B) = P(A) 且 P(B|A) = P(B)。
- 許多機率模型(如二項分佈)假設試驗是獨立的。

沒有找到符合條件的重點。
↑