iPAS AI應用規劃師 經典題庫
L21302 AI技術系統集成與部署
出題方向
1
AI 系統架構設計原則
2
模型部署策略與環境選擇
3
API 設計與 AI 服務整合
4
容器化與編排技術應用
5
MLOps 與自動化流程
6
系統監控、日誌與效能優化
7
可擴展性與高可用性設計
8
部署中的安全性考量
#1
★★★★
設計 AI 系統架構時,將模型推論(Inference)服務與核心業務邏輯服務分離,主要遵循了哪個軟體架構原則?
答案解析
關注點分離是軟體設計的基本原則,主張將系統的不同功能模組化,每個模塊專注於單一的職責。微服務架構是實踐此原則的一種方式,將大型應用程式拆分成一組小型、獨立、可獨立部署的服務。將計算密集、資源需求可能不同的
AI 推論服務與其他業務邏輯(如使用者驗證、訂單處理)分離,可以:(1) 提高系統的可維護性與可擴展性(可以獨立更新和擴展 AI 服務);(2) 提升容錯性(單一服務故障不影響整體);(3)
允許為不同服務選擇最適當的技術棧和資源配置。單體式架構(A)則是將所有功能捆綁在一起。事件驅動(C)和客戶端-伺服器(D)描述的是不同的架構模式,但核心分離原則體現在 B 中。
#2
★★★★★
將 AI 模型部署到邊緣裝置(Edge Devices)而非雲端的主要優勢不包括下列何者?
答案解析
邊緣運算(Edge Computing)是指在靠近數據來源的物理位置(如感測器、手機、本地伺服器)執行計算。將 AI 模型部署到邊緣的優勢包括:(A)
低延遲:數據無需往返雲端,反應速度更快,適用於即時應用(如自動駕駛)。(B) 隱私與安全:敏感數據在本地處理,減少傳輸風險。(C) 離線可用性:即使沒有網路連線也能運行。然而,邊緣裝置通常在計算能力、記憶體和儲存空間方面受到限制,遠不如雲端平台所能提供的彈性和規模(D)。因此,邊緣部署的主要挑戰在於模型優化(使其能在資源受限的設備上運行)和管理大量分散的裝置。
#3
★★★★★
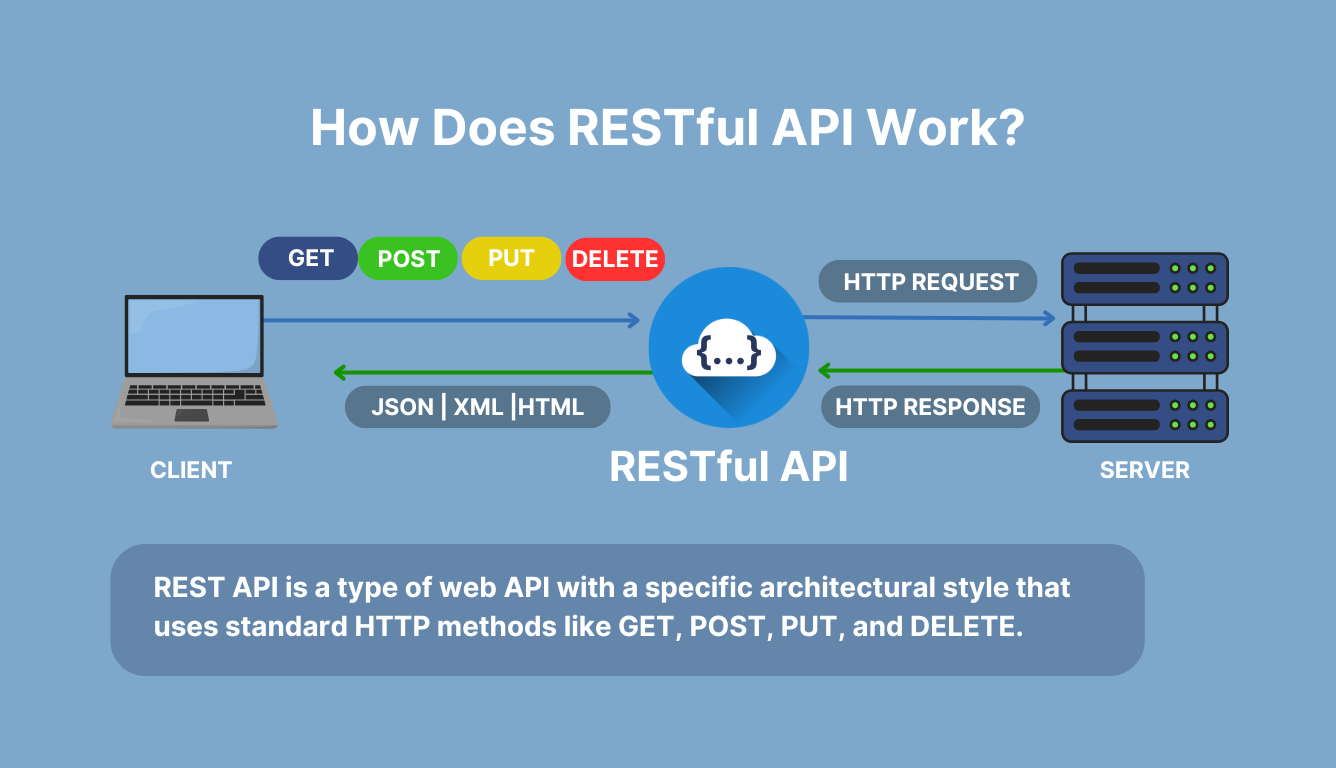
將訓練好的機器學習模型封裝成一個 RESTful API(Representational State
Transfer Application Programming Interface)服務,其主要目的是?
答案解析
將模型部署為 API 服務是一種常見的模型服務化(Model
Serving)方法。RESTful API 使用標準的 HTTP 協定(如 GET,
POST 方法)和常見的數據格式(如 JSON),使得不同的客戶端應用程式(網頁、手機 App、後端服務)可以輕易地透過網路請求來獲取模型的預測結果,而無需關心模型內部的實現細節。這實現了模型功能與應用邏輯的解耦,提高了系統的模組化程度和整合彈性。API 化本身不直接加速訓練(A)、提高準確率(B)或自動監控(D),而是提供了一種標準的服務接口。
#4
★★★★★
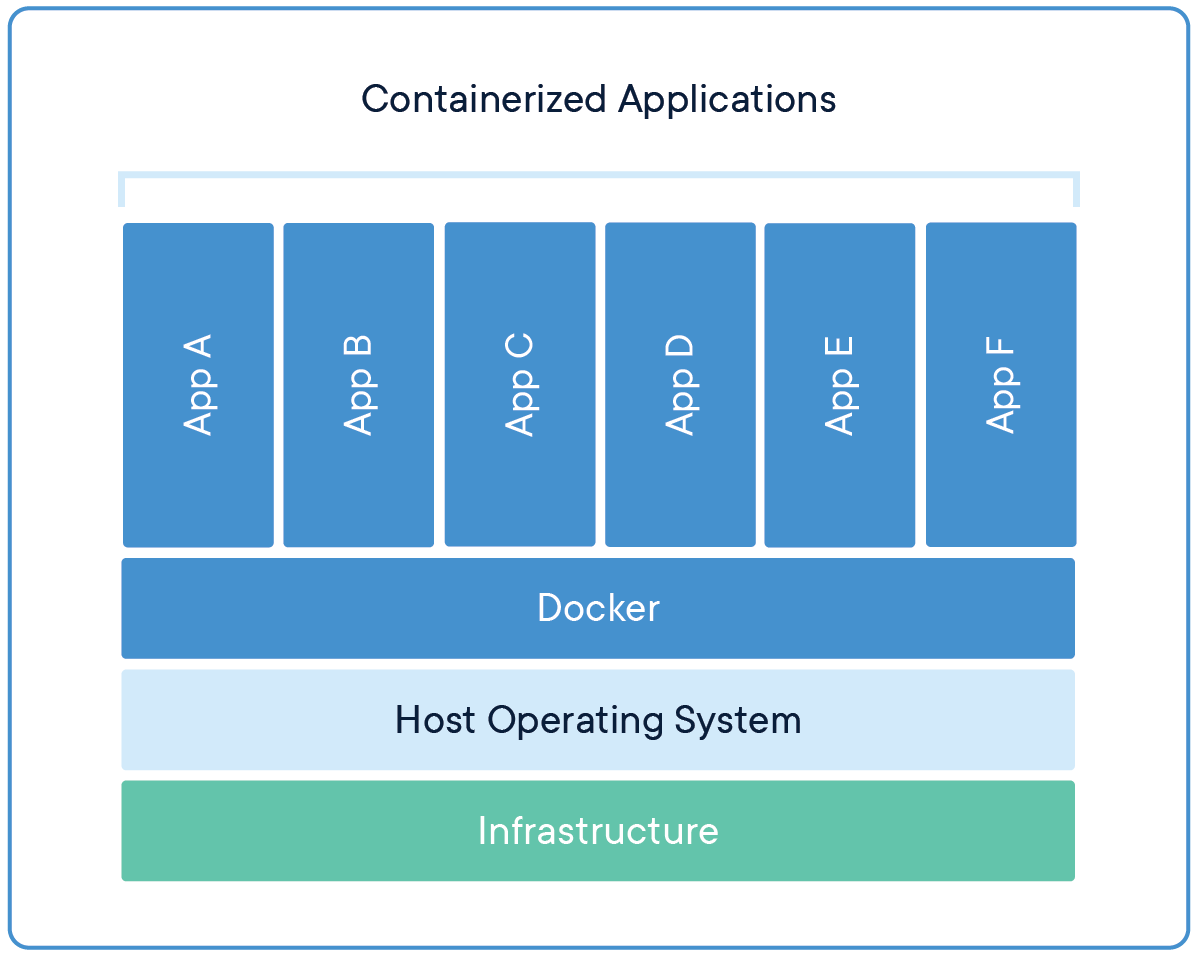
在 AI 系統部署中,使用 Docker 等容器化(Containerization)技術的主要優勢是什麼?
答案解析
容器化技術(如 Docker)允許開發者將應用程式程式碼、執行環境、系統工具、函式庫和設定檔等所有依賴項打包到一個輕量級、獨立的容器映像檔(Image)中。這個映像檔可以在任何支援容器技術的環境(開發、測試、生產、本地、雲端)中一致地運行,解決了傳統部署中常見的「在我的機器上可以跑」的環境差異問題。主要優勢包括:(1)
環境一致性:確保開發、測試和生產環境相同。(2) 可移植性:容器可以在不同基礎設施上輕鬆遷移。(3) 快速部署與擴展:容器啟動速度快,易於水平擴展。(4) 資源隔離:提供進程級別的隔離。容器化本身不直接提升模型準確率(A)、自動化特徵工程(C)或提供無限 GPU(D)。
#5
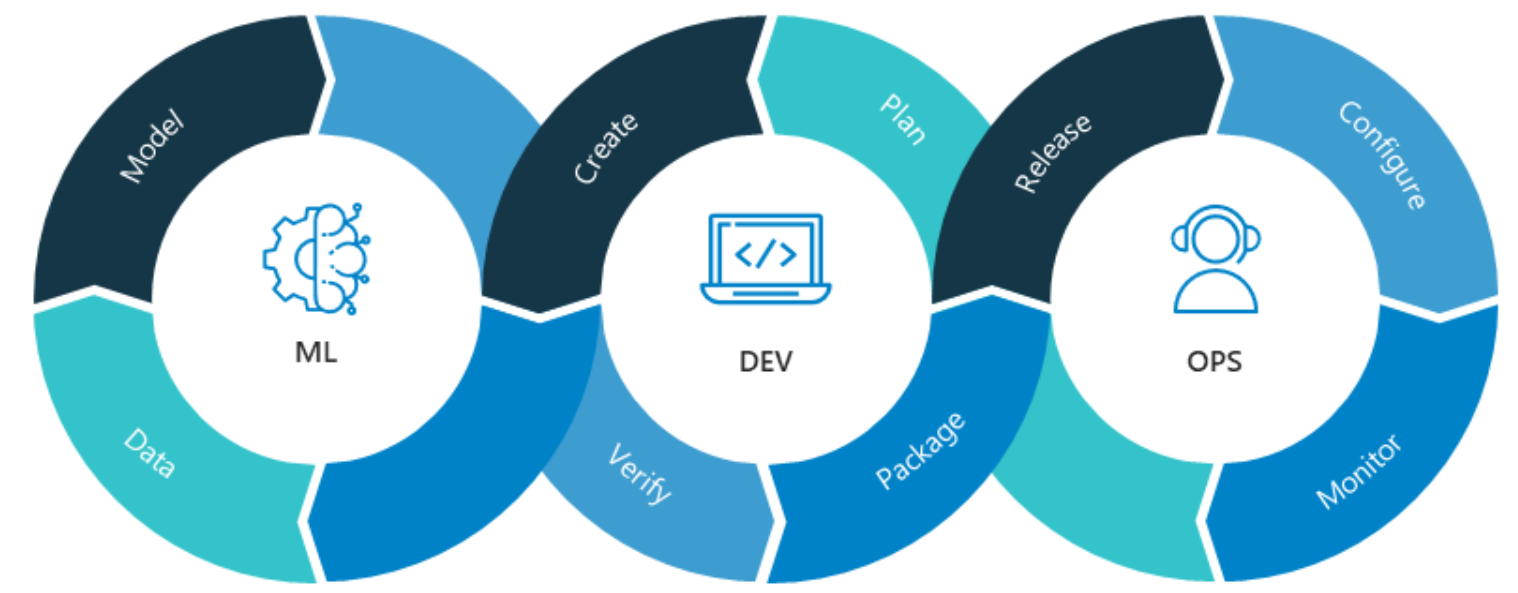
★★★★★
MLOps(Machine Learning Operations)的核心目標是?
答案解析
MLOps 結合了機器學習(Machine
Learning)、數據工程(Data Engineering)和 DevOps(Development and
Operations)的實踐,旨在縮短從模型開發到生產部署的週期,並確保持續的品質和可靠性。其核心目標是將自動化、版本控制、持續整合/持續部署(CI/CD)、監控、測試和協作等 DevOps 理念應用到整個機器學習工作流程中,包括數據準備、模型訓練、模型驗證、模型部署、生產監控和模型再訓練等環節。這有助於提高開發效率、降低部署風險、確保模型性能穩定、促進團隊協作,並實現
AI 應用的規模化和可持續維運。
#6
★★★★
在 AI 系統部署後,持續監控模型的預測延遲(Prediction
Latency)和吞吐量(Throughput)主要是為了確保系統的哪個方面?
答案解析
系統監控是部署後的重要環節。監控指標通常包括:
- 模型性能指標:如準確率、召回率、AUC 等,用於偵測模型漂移。
- 服務效能指標:
- 延遲(Latency):處理單個預測請求所需的時間。
- 吞吐量(Throughput):單位時間內能夠處理的預測請求數量。
- 資源使用率指標:如 CPU、記憶體、GPU 使用率。
#7
★★★★
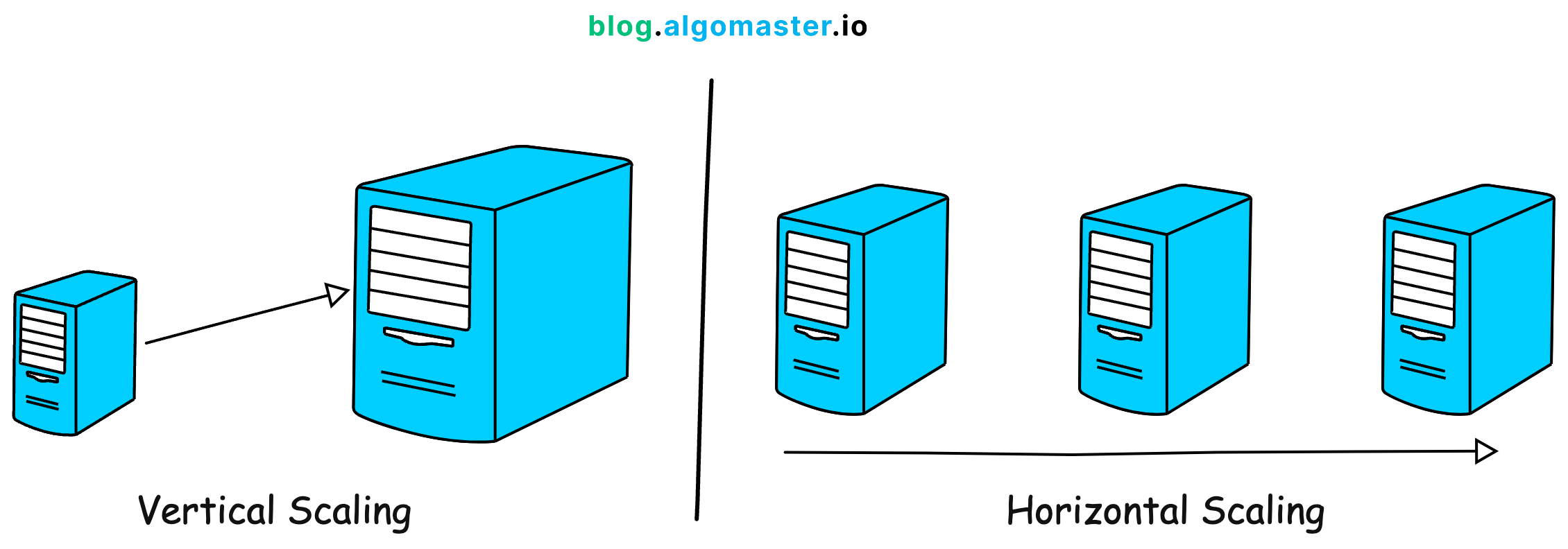
為了提高 AI 推論服務的可擴展性(Scalability),常用的策略是?
答案解析
可擴展性是指系統處理不斷增長的工作負載的能力。有兩種主要方式:(A) 垂直擴展(Scale
Up):提升單一伺服器的硬體資源(如更強的 CPU、更多記憶體)。這種方式有其物理和成本上限。(B) 水平擴展(Scale
Out):增加更多相同配置的伺服器(或容器實例),並透過負載平衡器將流量分發到這些實例上。這是現代雲端架構中更常用、更具彈性的擴展方式,可以根據負載動態增減實例數量。對於 AI 推論服務,通常採用水平擴展來應對大量併發請求。選項 C 和 D 與提高服務處理能力的可擴展性策略不直接相關。
#8
★★★★
在部署對外提供服務的 AI API 時,進行輸入驗證(Input Validation)的主要目的是?
答案解析
輸入驗證是保護任何對外服務(包括 AI
API)的基礎安全措施。它指的是在處理來自客戶端的請求數據之前,檢查數據是否符合預期的格式、類型、範圍和長度等。其主要目的是:(1) 防止服務錯誤或崩潰:格式錯誤或超出範圍的輸入可能導致模型推論失敗或服務異常。(2)
阻止安全攻擊:惡意使用者可能嘗試發送構造的數據來觸發漏洞,例如注入攻擊(Injection
Attacks)、導致資源耗盡(Denial of Service)等。嚴格的輸入驗證可以攔截這些惡意或無效的請求,保護後端系統的穩定性和安全性。它不直接提高速度(A)、確保公平性(C)或更新權重(D)。
#9
★★★
AI 系統架構中,日誌記錄(Logging)系統的主要職責是?
答案解析
日誌記錄是系統維運的基礎。它涉及記錄系統在運行時發生的各種事件資訊,例如:收到的 API 請求內容、模型的預測輸入與輸出、系統錯誤訊息、效能指標、安全事件等。這些日誌對於:(1) 監控:即時了解系統狀態;(2) 除錯:追溯問題發生的原因;(3) 效能分析:找出瓶頸;(4) 安全稽核:追蹤可疑活動;(5) 合規記錄:滿足法規要求等都至關重要。一個好的日誌系統應該能夠有效地收集、儲存、查詢和分析這些日誌數據。
#10
★★★★
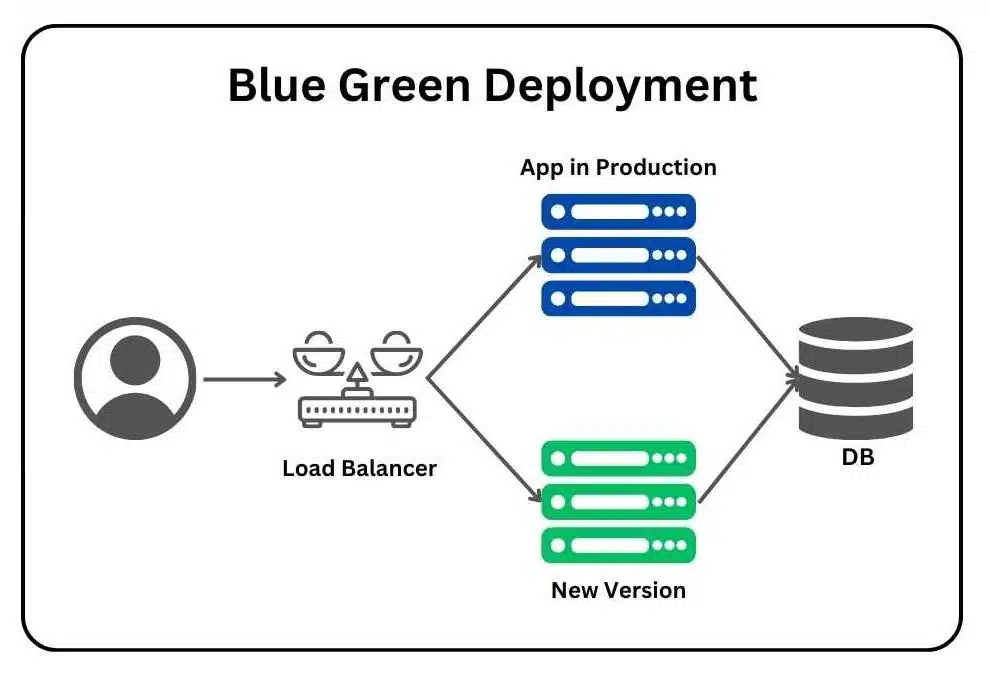
藍綠部署(Blue-Green Deployment)是一種常見的模型部署策略,其主要優點是?
答案解析
藍綠部署策略涉及維護兩個幾乎相同的生產環境:藍色環境(當前線上版本)和綠色環境(新版本)。部署新版本時,先將新版本部署到綠色環境並進行測試。確認無誤後,將流量(通常透過負載平衡器或路由器)從藍色環境切換到綠色環境。這樣,使用者感受不到服務中斷(零停機)。如果新版本出現問題,可以快速將流量切回藍色環境,實現快速回滾。其主要優點是安全、可靠、回滾方便。缺點是需要維護兩套環境,資源成本較高(C
錯誤)。雖然可以做到快速切換,但不一定是速度最快(A)的部署方式(如滾動更新可能更快完成部分更新)。金絲雀部署或
A/B 測試(D)更側重於逐步釋出流量或比較不同版本。
#11
★★★★
設計 AI 服務的 API 時,提供清晰的文件(API Documentation)非常重要,其主要目的是?
答案解析
良好的 API 文件是 API
易用性和可維護性的關鍵。它應該清楚地說明:API 的端點(Endpoint)URL、支援的 HTTP
方法、請求所需的參數(名稱、類型、是否必需、範例值)、請求主體的格式、認證方式、可能的響應狀態碼及其含義、成功響應的數據結構、錯誤響應的格式等。清晰的文件可以讓其他開發者或應用程式能夠快速、正確地整合和使用這個 API 服務,減少溝通成本和錯誤。雖然 API 設計應隱藏內部細節(D),但文件是用於說明如何使用其公開接口,而非隱藏。
#12
★★★★
Kubernetes 是一個開源的容器編排(Container
Orchestration)平台,它在 AI 系統部署中的主要作用是?
答案解析
當 AI 應用被容器化(例如使用 Docker)後,需要在生產環境中管理大量的容器實例。Kubernetes(常簡稱為 K8s)就是一個用於自動化這些管理任務的平台。它的核心功能包括:(1) 部署與調度:自動將容器部署到集群中的節點上。(2) 服務發現與負載平衡:為容器提供穩定的網路入口並分發流量。(3) 自動擴展:根據 CPU 使用率或其他指標自動調整容器實例數量。(4) 自我修復:自動替換失敗的容器。(5) 組態與密鑰管理。Kubernetes 使得管理複雜的、由多個容器組成的 AI 應用(如包含模型服務、數據處理、API 閘道等多個微服務)更加高效和可靠。
#13
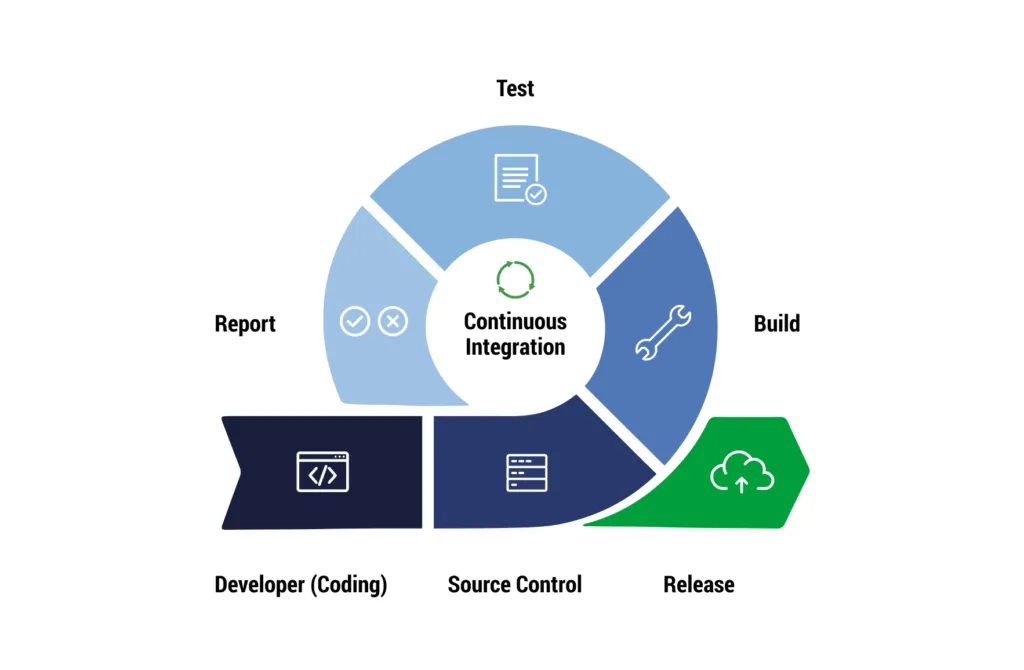
★★★★
在 MLOps 流程中,持續整合(Continuous Integration,
CI)主要關注的是哪個環節的自動化?
答案解析
持續整合(CI)是 DevOps 和
MLOps 中的核心實踐。它強調開發人員頻繁地將程式碼變更合併到中央儲存庫(如 Git),並且每次合併後都會自動觸發構建(Build)和測試(包括單元測試、整合測試、數據驗證測試、模型驗證測試等)流程。其主要目標是:(1)
及早發現和修復整合錯誤;(2) 確保程式碼庫始終處於可工作狀態;(3)
自動化重複性的構建和測試任務,提高效率和品質。選項 B 屬於持續部署(Continuous Deployment, CD)的範疇。選項 C 是持續監控。選項 D 是數據工程環節。
#14
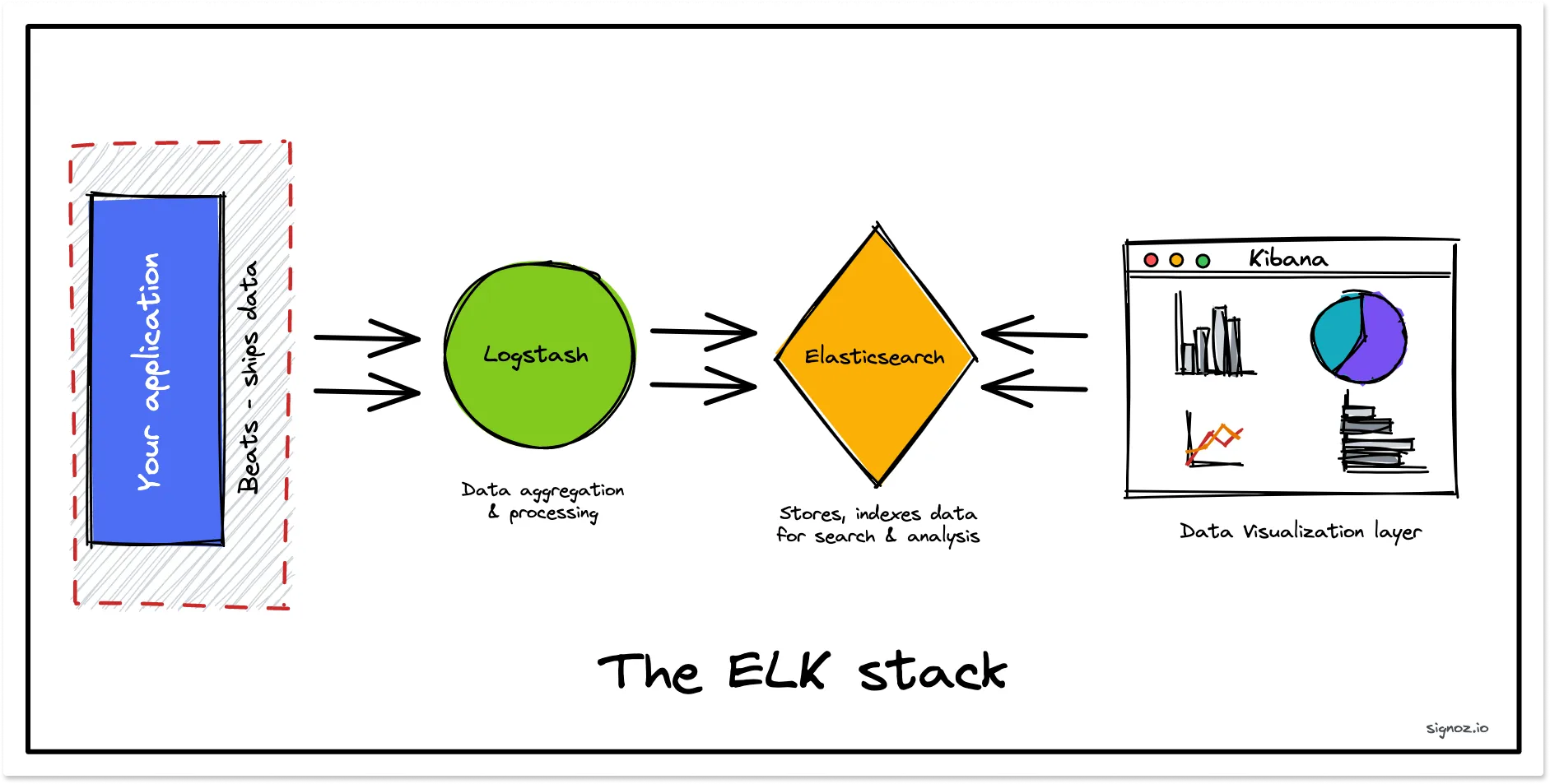
★★★
使用集中式的日誌管理系統(如 ELK Stack: Elasticsearch,
Logstash, Kibana 或
Splunk)收集和分析來自不同 AI
服務元件的日誌,其主要好處是?
答案解析
現代 AI 系統通常由多個分散的服務元件(如
API 閘道、模型推論服務、數據處理服務)組成,每個元件都會產生自己的日誌。如果日誌分散在各處,查詢和分析會非常困難。集中式的日誌管理系統將來自不同來源的日誌數據收集到一個中央儲存庫(如 Elasticsearch),並提供強大的工具(如 Logstash 進行處理,Kibana 或
Splunk 進行查詢、分析和視覺化)。這樣做的好處是:(1) 統一視圖:方便跨服務追蹤請求或問題。(2) 強大查詢與分析:支援複雜的搜索、聚合和關聯分析。(3) 即時監控與告警:可以設定規則,當特定模式出現時觸發告警。(4) 長期儲存與歸檔。它不取代版本控制(A),不自動修正錯誤(C),通常需要更多儲存空間(D)。
#15
★★★
在高可用性(High Availability, HA)設計中,設置備援(Redundancy)節點或服務實例的主要目的是?
答案解析
高可用性是指系統能夠在面臨單點故障(Single Point of
Failure)時,仍然能夠持續提供服務的能力,通常用服務的正常運行時間比例(如 99.9%, 99.99%)來衡量。實現高可用性的關鍵策略之一就是備援,即部署額外的、功能相同的硬體或軟體元件(如伺服器、資料庫副本、網路路徑、服務實例)。當主要元件失效時,系統可以自動或手動地將工作負載切換到備援元件上,從而避免或顯著縮短服務中斷時間。備援會增加成本(A
錯誤),不直接提高單點性能(C),反而可能增加監控的複雜性(D)。
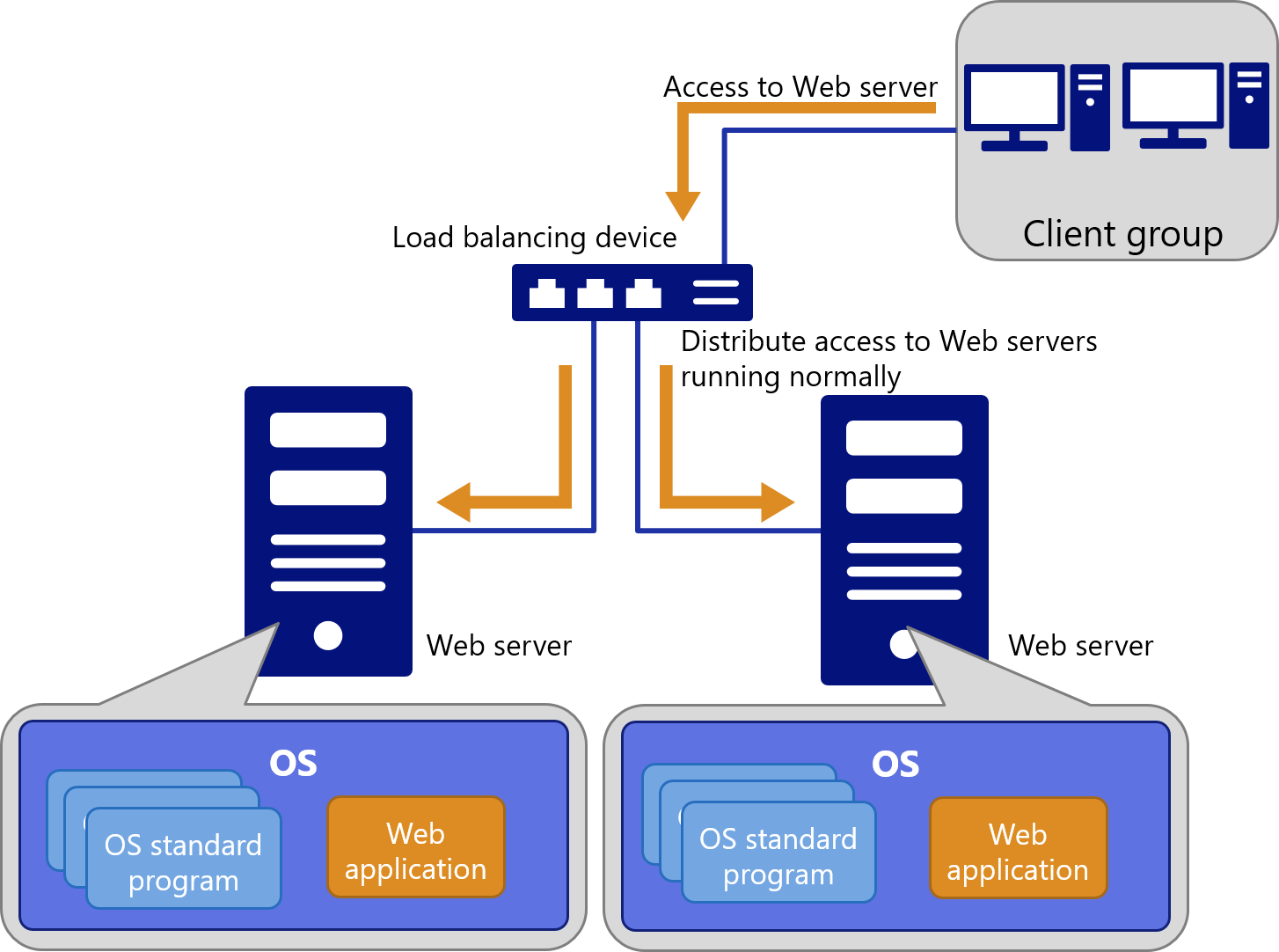
#16
★★★★★
在保護 AI 模型部署安全時,下列哪項措施最能有效防止未經授權的存取?
答案解析
保護 AI 服務(尤其是對外提供的 API)的首要步驟是確保只有合法的、經過授權的使用者或應用程式才能存取。這需要:(1) 身份驗證:確認請求者的身份,常用方法包括 API 金鑰(API
Keys)、令牌(Tokens,如 JWT - JSON Web
Tokens)、OAuth 協定等。(2) 授權:確認經過驗證的請求者是否有權限執行請求的操作(例如,某些使用者只能讀取,某些使用者可以讀寫)。透過角色基礎的存取控制(Role-Based Access
Control, RBAC)或屬性基礎的存取控制(Attribute-Based Access
Control, ABAC)來管理權限。開源(A)與存取控制無關。增加複雜度(C)不保證安全。清理日誌(D)可能妨礙安全稽核。強健的驗證和授權是防止未經授權存取的基礎。

#17
★★★
在設計 AI
系統時,考慮到未來模型可能需要更新或替換,架構上應該具備什麼特性?
答案解析
AI 模型是需要持續迭代和更新的(例如因應模型漂移、業務需求變化、演算法進步)。因此,系統架構應該設計成易於更新和維護。模組化是指將系統劃分為功能獨立的單元(如數據處理模組、模型推論模組、API 接口模組)。鬆散耦合是指模組之間的依賴性盡可能低,介面清晰穩定。具備這些特性的架構,使得更換或升級某個模組(如更新模型版本)時,對其他模組的影響最小,降低了維護的複雜度和風險。緊密耦合(A)則相反,修改一部分可能牽一髮動全身。固定硬體(C)和不再變更(D)都不符合 AI 系統的動態特性。
#18
★★★
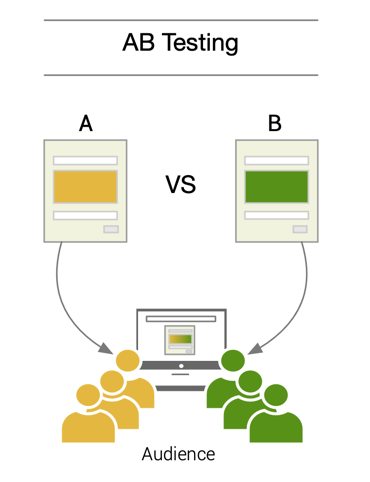
A/B 測試(A/B
Testing)是一種常用於比較不同模型版本或策略效果的方法,其基本做法是?
答案解析
A/B 測試是一種線上實驗方法,用於比較兩種(或多種)不同方案(例如不同版本的 AI 模型、不同的推薦演算法、不同的網頁設計)在真實使用者環境下的效果。其做法是將使用者隨機分流到不同的組別,每組使用不同的方案,然後收集並比較各組在關心的業務指標(如點擊率、轉換率、營收、使用者滿意度等)上的表現。透過統計檢定,判斷哪個方案的效果顯著更優。這是一種基於實際數據的決策方法,常用於模型選擇、新功能評估和持續優化。
#19
★★★
使用如 TensorFlow Serving 或 TorchServe 這樣的專用模型伺服器框架來部署模型,相比於自行編寫 Flask/Django 等通用 Web
框架來提供服務,其主要優勢通常在於?
答案解析
專用的模型伺服器框架(如 TensorFlow Serving, TorchServe, NVIDIA Triton
Inference Server, KServe
等)是為了高效、穩定地部署和服務機器學習模型而設計的。它們通常具備以下優勢:(1) 效能優化:針對底層硬體(CPU/GPU)和模型推論進行了深度優化,能提供更高的吞吐量和更低的延遲。(2) 內建功能:通常內建支援多模型、多版本管理、請求批次處理(將多個請求合併處理以提高效率)、健康檢查、度量指標(Metrics)暴露(便於監控)等生產環境所需的功能。(3) 標準化接口:提供標準的 API 接口(如 REST,
gRPC)。雖然使用通用 Web
框架也能實現模型部署,但通常需要開發者自行處理更多底層優化和維運相關的功能,而專用框架則提供了更完善、開箱即用的解決方案。
#20
★★★★
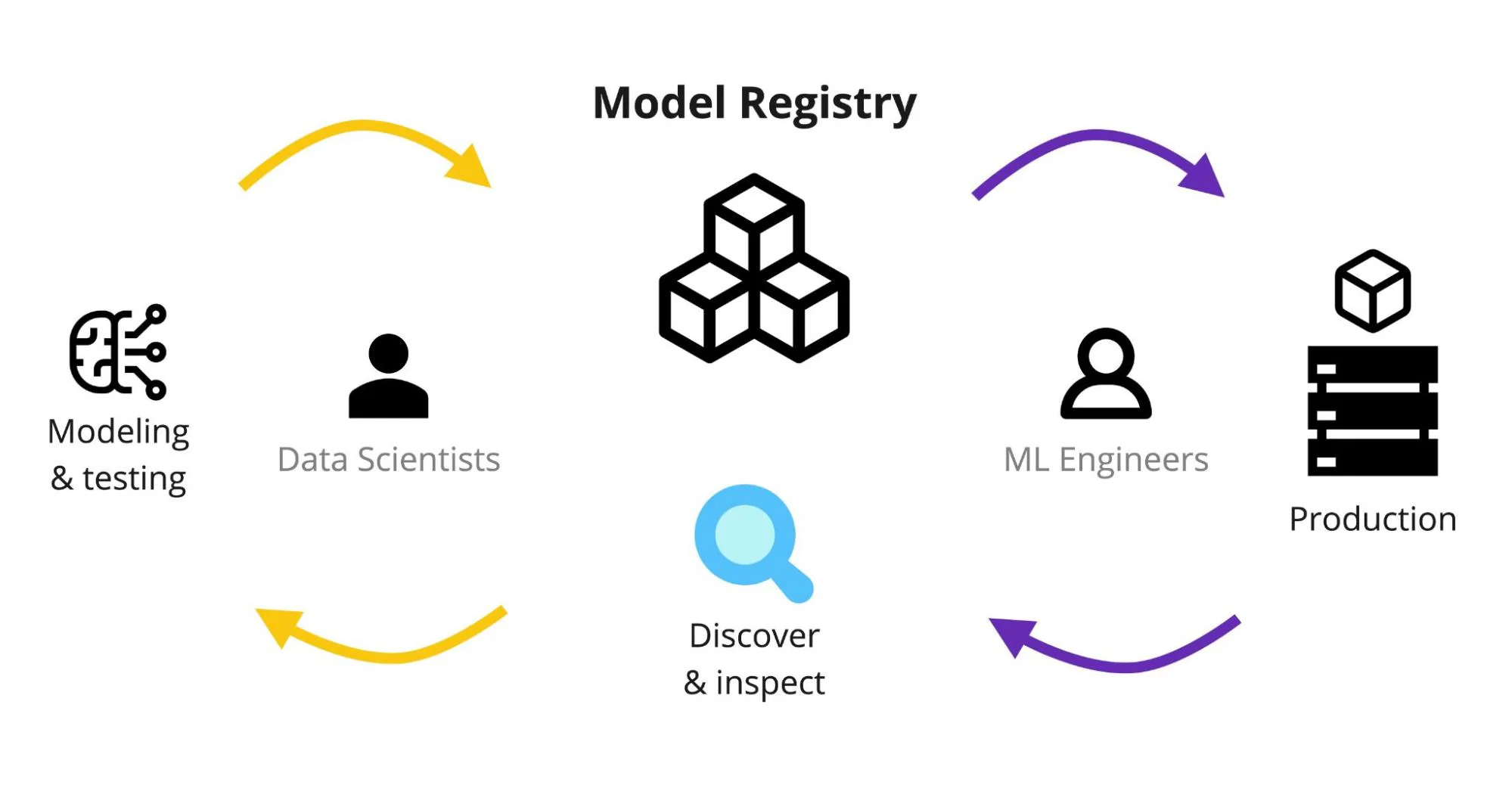
在 MLOps 中,模型登錄庫(Model Registry)的主要作用是?
答案解析
模型登錄庫是 MLOps 平台中的核心元件之一。它提供了一個中央化的位置來儲存、管理和追蹤所有已訓練的模型版本。其主要功能包括:(1)
模型版本控制:記錄每個模型的不同版本。(2) 元數據管理:儲存與模型相關的資訊,如訓練數據來源、使用的演算法、超參數、評估指標、訓練腳本連結、模型產出物(Artifacts)位置等。(3) 生命週期管理:標記模型所處的階段(例如 Staging, Production,
Archived),並控制模型的晉升流程。(4) 模型發現與共享:方便團隊成員查找和複用模型。模型登錄庫是連接模型開發和模型部署的橋樑,確保部署的模型是經過驗證且可追溯的。常見的工具包括 MLflow Model Registry, Kubeflow
Artifact Store 等。
#21
★★★★
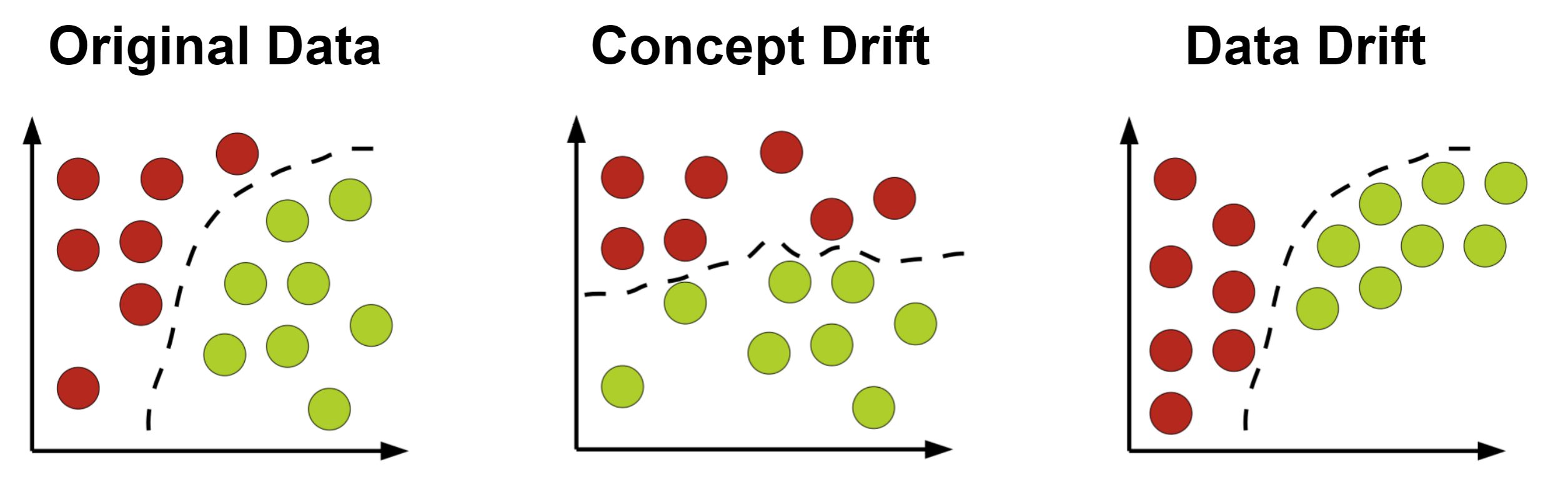
監控生產環境中 AI 模型的輸入數據分佈變化,對於偵測哪種潛在問題至關重要?
答案解析
模型漂移(包括數據漂移和概念漂移)是指生產環境中的數據特性(如分佈、特徵間關係、目標變數與特徵的關係)隨時間發生變化,導致模型訓練時所基於的假設不再成立,進而使模型性能下降。監控輸入數據的分佈(例如,特徵的均值、標準差、類別比例等)是否與訓練數據顯著不同,是偵測數據漂移的關鍵方法。一旦偵測到顯著漂移,可能就需要重新訓練模型、調整特徵工程策略或採取其他應對措施,以維持模型的有效性。語法錯誤(A)、硬體故障(C)、認證失敗(D)是其他類型的系統問題,與數據分佈變化關係不大。
#22
★★★
對於需要處理突發性高流量請求的 AI 服務,設計架構時應優先考慮哪種能力?
答案解析
突發性高流量(Spiky
Traffic)對系統的處理能力提出了挑戰。如果系統容量固定,可能在高流量時不堪重負導致延遲增加甚至服務癱瘓;在低流量時則造成資源浪費。彈性擴展是指系統能夠根據實際負載快速調整其資源容量(通常是透過水平擴展)。自動擴展則是指這個調整過程是自動化的,例如雲端平台或 Kubernetes
可以根據預設的指標(如 CPU
使用率、請求佇列長度)自動增加或減少服務實例數量。具備這種能力可以確保系統在高流量時能及時擴容以維持服務品質,在低流量時能縮容以節省成本。
#23
★★★★
在 AI 系統集成與部署中,對模型檔案和重要組態進行加密儲存,主要是為了防範哪類安全風險?
答案解析
訓練好的 AI
模型本身(模型檔案)以及相關的敏感組態(如 API
金鑰、資料庫密碼)是重要的智慧資產和安全憑證。如果這些檔案以明文形式儲存,一旦儲存系統被入侵,攻擊者就可以輕易地竊取模型(可能用於逆向工程或惡意應用)、獲取敏感憑證進一步滲透系統。對這些靜態數據(Data at
Rest)進行加密儲存,可以確保即使檔案被非法獲取,如果沒有對應的解密金鑰,攻擊者也無法讀取其內容,從而有效降低了數據洩露和被篡改的風險。模型偏見(A)、漂移(C)、效能瓶頸(D)是不同性質的問題。
#24
★★★
API 閘道器(API Gateway)在微服務架構(常用於部署
AI 系統)中扮演的角色通常不包括?
答案解析
API 閘道器是位於客戶端和後端微服務之間的反向代理伺服器。它的主要職責是:(A) 提供一個統一的 API 入口,簡化客戶端的呼叫。(B) 處理通用的橫切關注點(Cross-cutting
Concerns),如請求路由(將請求轉發給正確的後端服務)、負載平衡、身份驗證與授權、SSL 終止、速率限制(Rate Limiting)、日誌記錄、監控等。(D)
有時也負責聚合來自不同微服務的數據,以提供客戶端所需的單一響應。API 閘道器本身通常不負責儲存業務數據或模型訓練數據(C),這些應由專門的數據儲存服務或後端業務服務處理。
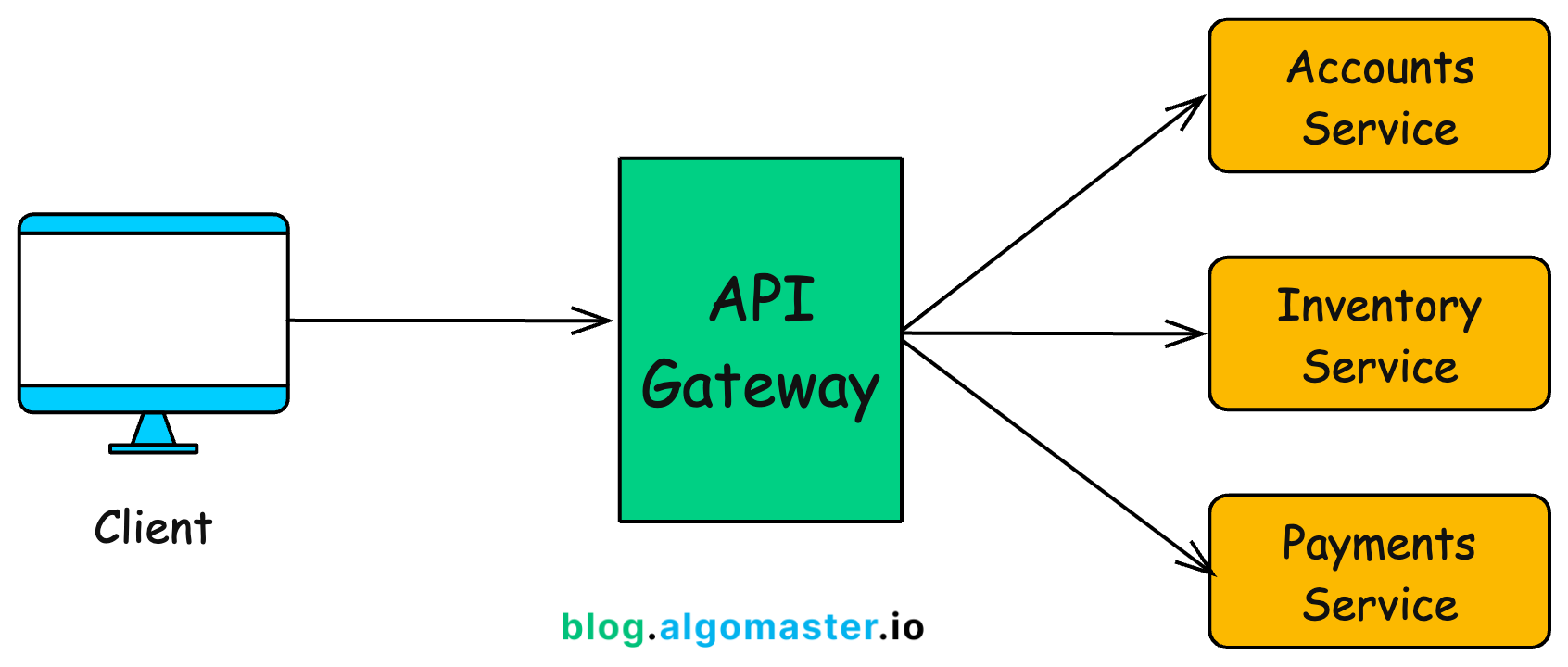
#25
★★★
將 AI 模型部署為無伺服器函數(Serverless Function,例如
AWS Lambda, Azure
Functions, Google Cloud Functions)的架構,其主要優勢是?
答案解析
無伺服器運算(Serverless
Computing)允許開發者專注於編寫和部署程式碼(函數),而無需關心底層伺服器的佈建、管理和擴展,這些由雲端供應商負責。其主要優勢包括:(1) 無需管理基礎設施:簡化了維運工作。(2) 自動擴展:平台會根據請求量自動擴展函數實例。(3) 按量付費:通常只為實際執行的時間和資源付費,對於流量波動大或不頻繁的應用可能更具成本效益。然而,無伺服器函數通常有執行時間限制(C 錯誤)、資源限制(可能不適合極需 GPU 的大型模型,A 相對不準確)、以及可能的冷啟動延遲(D 錯誤,函數長時間未被調用後首次啟動可能較慢)等缺點。
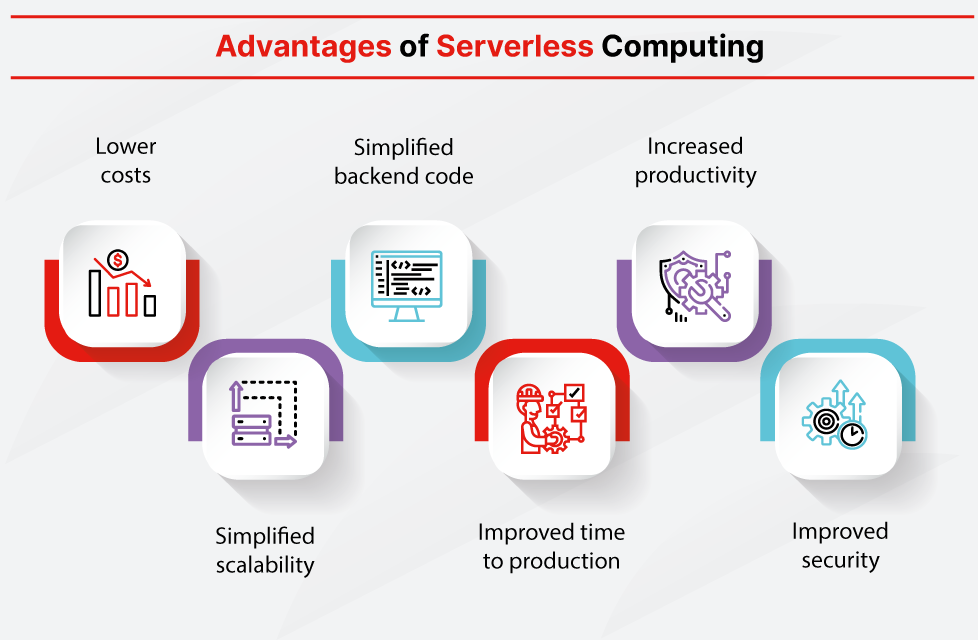
#26
★★★
版本控制系統(如 Git)在 MLOps
中不僅用於管理程式碼,還常用於管理什麼?
答案解析
版本控制是 MLOps 的基石,確保了可追溯性和可重現性。除了應用程式碼和模型訓練腳本,版本控制也常用於管理:(1) 數據版本:追蹤不同版本的數據集(有時結合 DVC - Data Version
Control 等工具)。(2) 模型配置與超參數:記錄用於訓練模型的設定。(3) 實驗追蹤:記錄不同實驗的參數、程式碼版本、數據版本和結果。(4) 基礎設施即程式碼(IaC):使用程式碼(如 Terraform, CloudFormation)來定義和管理基礎設施,並將其納入版本控制。這樣可以確保整個 ML
工作流程的各個環節都是可版本化、可追溯和可重現的。使用者憑證(C)應使用密鑰管理系統。流量(A)和延遲指標(D)是運行時狀態或監控數據。

#27
★★★
在 AI 系統監控中,設置告警(Alerting)規則的主要目的是?
答案解析
僅僅收集監控數據是不夠的,還需要建立機制以及時發現和響應問題。告警系統允許定義規則,當監控數據滿足特定條件時(例如,API 錯誤率連續 5 分鐘超過 1%、推論延遲超過 500 毫秒、CPU
使用率持續高於 90%、偵測到顯著的數據漂移),系統會自動透過郵件、簡訊、即時通訊工具(如 Slack)等方式通知負責的維運或開發人員。這使得團隊能夠快速介入,診斷問題並採取補救措施,從而縮短故障時間,保障服務穩定性。自動回滾(C)可能是對告警的一種響應動作,但不是告警本身的目的。
#28
★★★
對於儲存 API 金鑰、資料庫密碼等敏感資訊,最佳的安全實踐是?
答案解析
敏感資訊(Secrets),如密碼、API
金鑰、憑證等,絕不能以明文形式儲存在程式碼、組態檔或版本控制系統中(A
錯誤),因為這極易導致洩露。透過郵件傳遞(C)也不安全。雖然環境變數比硬編碼稍好,但將其直接寫入容器映像檔(D)仍然有洩露風險(例如映像檔被不當存取)。最佳實踐是使用專門的密鑰管理服務(B)。這些服務提供安全的儲存、嚴格的存取控制、生命週期管理(如自動輪換密鑰)和稽核記錄功能。應用程式在運行時可以透過安全的 API 從密鑰管理服務中動態獲取所需的敏感資訊,避免了將其硬編碼或儲存在不安全的地方。
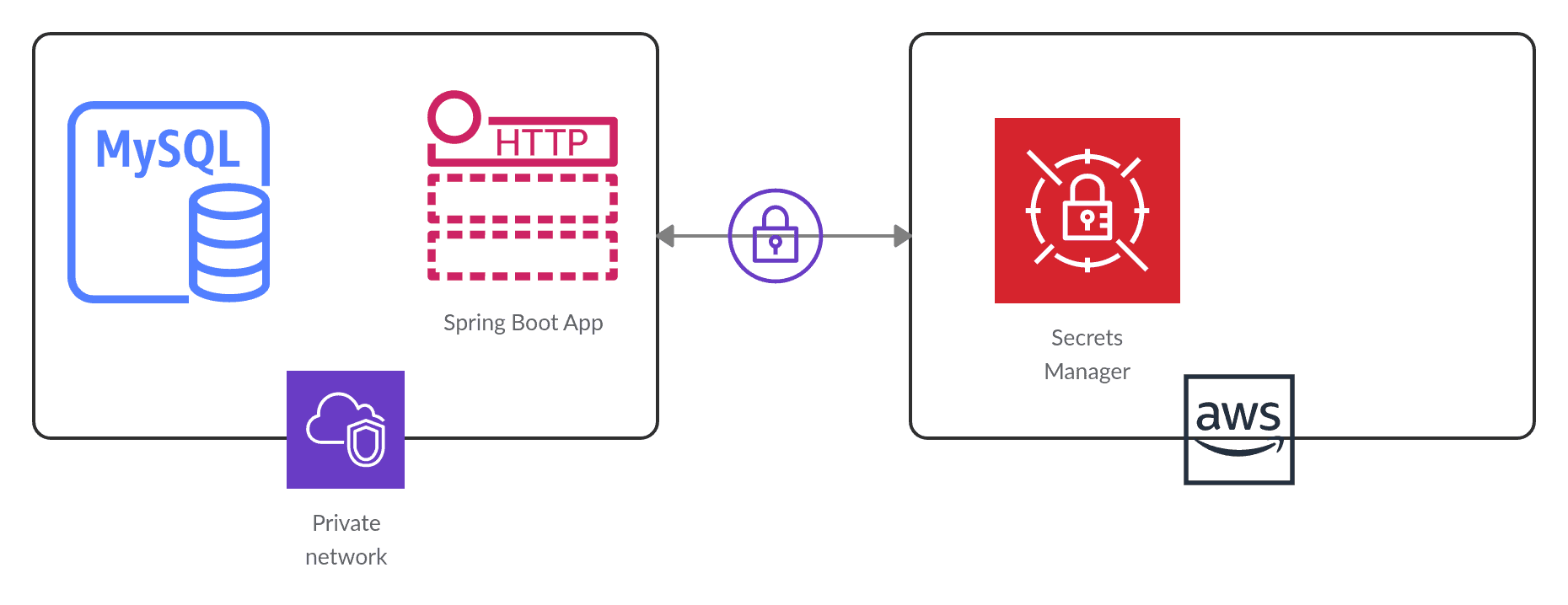
#29
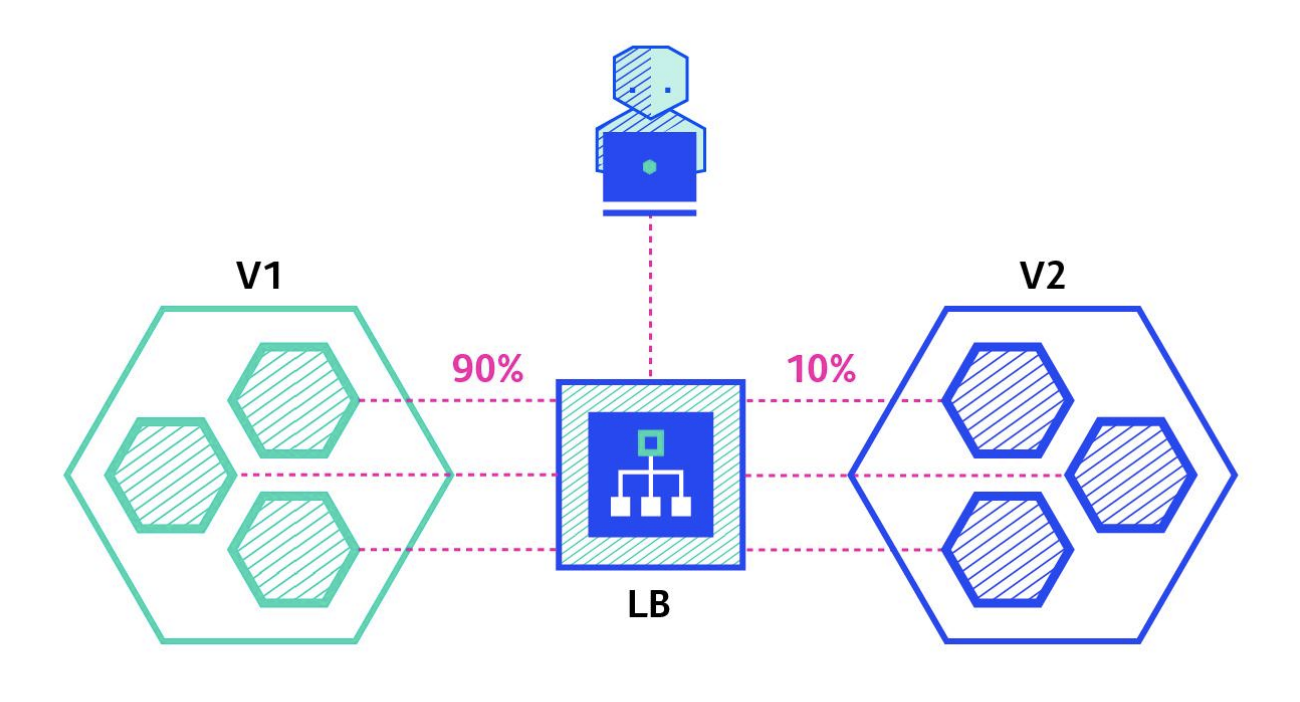
★★★
金絲雀部署(Canary Deployment)策略與藍綠部署的主要區別在於?
答案解析
金絲雀部署是一種更為謹慎的逐步釋出策略。它首先將新版本部署到少量伺服器(金絲雀伺服器),然後只將一小部分(例如 1% 或 5%)的使用者流量導向這些伺服器。團隊會密切監控新版本的性能、錯誤率等指標。如果表現符合預期,則逐步增加導向新版本的流量比例,並擴展新版本的部署範圍,直到最終取代舊版本。如果發現問題,可以快速將流量切回舊版本,影響範圍較小。相比之下,藍綠部署是將所有流量一次性從舊環境切換到新環境。金絲雀部署的回滾也很方便(C
錯誤)。資源需求方面,金絲雀初期可能資源需求較少,但最終也可能需要接近兩倍資源完成替換(A 不完全準確)。兩者都可用於多種類型的應用部署(D 錯誤)。

#30
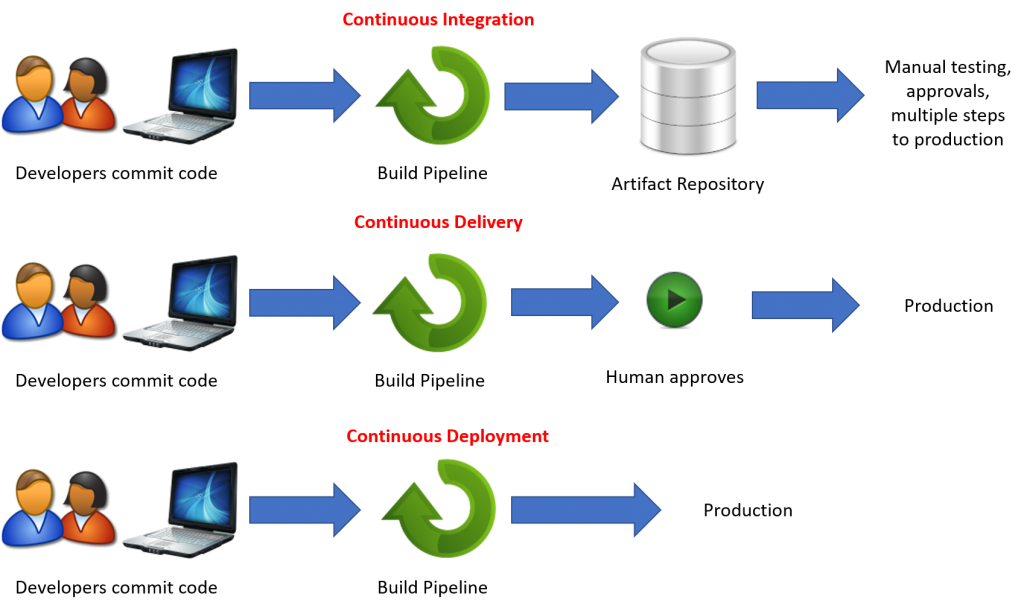
★★★
在 MLOps 中,持續交付(Continuous
Delivery)與持續部署(Continuous Deployment)的主要區別是?
答案解析
持續整合(CI)、持續交付(CDelivery)和持續部署(CDployment)是自動化流程的不同階段:
- CI:自動化構建和測試程式碼。
- 持續交付 (Continuous Delivery):是 CI 的延伸,除了自動構建和測試,還會自動將通過所有測試階段的變更部署到一個類生產環境(如預備環境 Staging)。確保軟體隨時處於「可發布」狀態,但最終部署到生產環境需要人工確認。
- 持續部署 (Continuous Deployment):是持續交付的再延伸,它自動將每一個通過所有測試階段的變更直接部署到生產環境,無需人工干預。
#31
★★
在設計 AI
系統架構時,若預期未來需要處理多種不同類型的輸入數據(如圖像、文本、語音),應考慮採用何種架構模式以提高靈活性?
答案解析
當系統需要處理多種不同類型的數據或未來可能擴展支援新類型時,採用模組化或基於插件的架構可以提供更好的靈活性。這種架構允許為不同數據類型開發獨立的處理模組或插件,並根據需要加載或替換。核心系統提供通用的框架和接口,而具體的處理邏輯則封裝在各個模組中。這樣可以更容易地增加對新數據類型的支援,而無需修改核心系統架構。
#32
★★★
設計 AI 服務 API 的響應(Response)時,除了包含預測結果,通常還建議包含哪些資訊以利於客戶端處理?
答案解析
一個設計良好的 API
響應應該清晰且包含足夠的上下文資訊。除了核心的預測結果外,建議包含:(1) 請求
ID:用於追蹤和關聯請求與響應,方便除錯。(2) 狀態碼:指示請求是否成功(如
HTTP 200 OK)或失敗(如 4xx 客戶端錯誤, 5xx 伺服器錯誤)。(3) 預測置信度/概率:對於分類或概率預測模型,提供置信度分數有助於客戶端判斷結果的可靠性。(4) 錯誤訊息:如果請求失敗,應提供清晰、具體的錯誤原因,而不是模糊的錯誤提示。模型日誌(A)和訓練數據(C)不應包含在響應中。伺服器
IP(D)通常也無需暴露。
#33
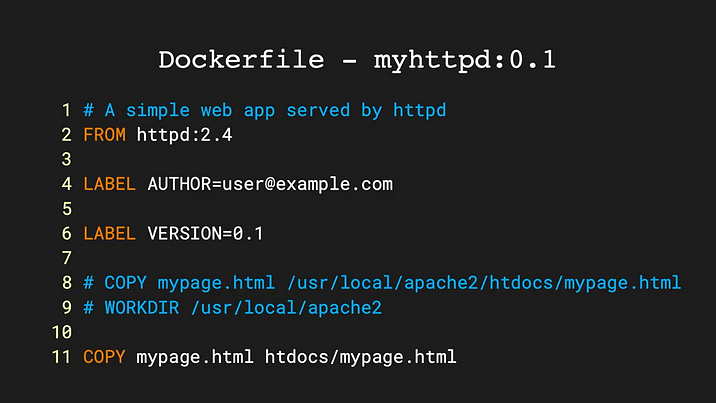
★★
Dockerfile 是用於定義什麼的文本文件?
答案解析
Dockerfile
包含了一系列按順序執行的指令,Docker 引擎根據這些指令來自動化地構建一個容器映像檔。這些指令定義了映像檔的基礎作業系統、需要安裝的軟體包和函式庫、要複製到映像檔中的應用程式碼、環境變數、容器啟動時要運行的命令等。透過
Dockerfile,可以確保映像檔的構建過程是可重複、可版本化的。Kubernetes 的部署配置通常寫在 YAML
文件中(A)。Python 依賴列表通常在
requirements.txt
或 pyproject.toml
中(C)。超參數是模型訓練設定(D)。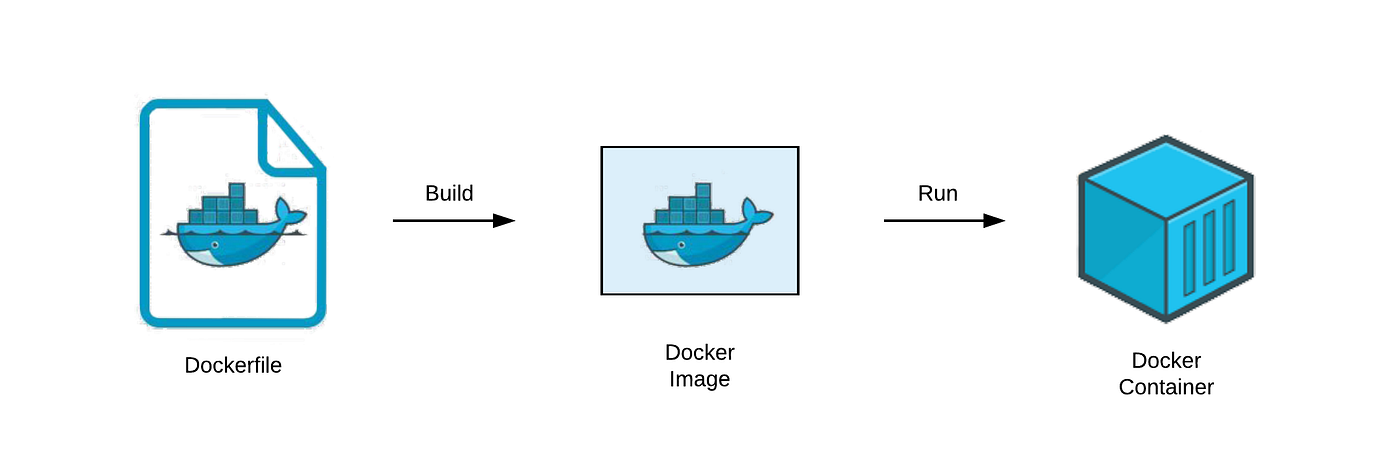
#34
★★★
MLOps 流程中,進行模型驗證(Model
Validation)的主要目的是確保什麼?
答案解析
模型驗證是 MLOps 管線(Pipeline)中的一個關鍵品質關卡,通常在模型訓練完成後、部署之前進行。其目的是評估新訓練出的模型版本是否滿足部署到生產環境的要求。這通常涉及:(1)
在獨立的驗證集或測試集上評估模型的性能指標(如準確率、AUC、RMSE 等);(2) 與預設的性能閾值或基線模型(Baseline)進行比較;(3)
與當前生產環境中的模型版本進行比較(例如 A/B 測試的離線模擬);(4) 檢查模型的公平性、穩健性、安全性等其他重要指標。只有通過驗證標準的模型才能被批准進入後續的部署階段。
#35
★★★
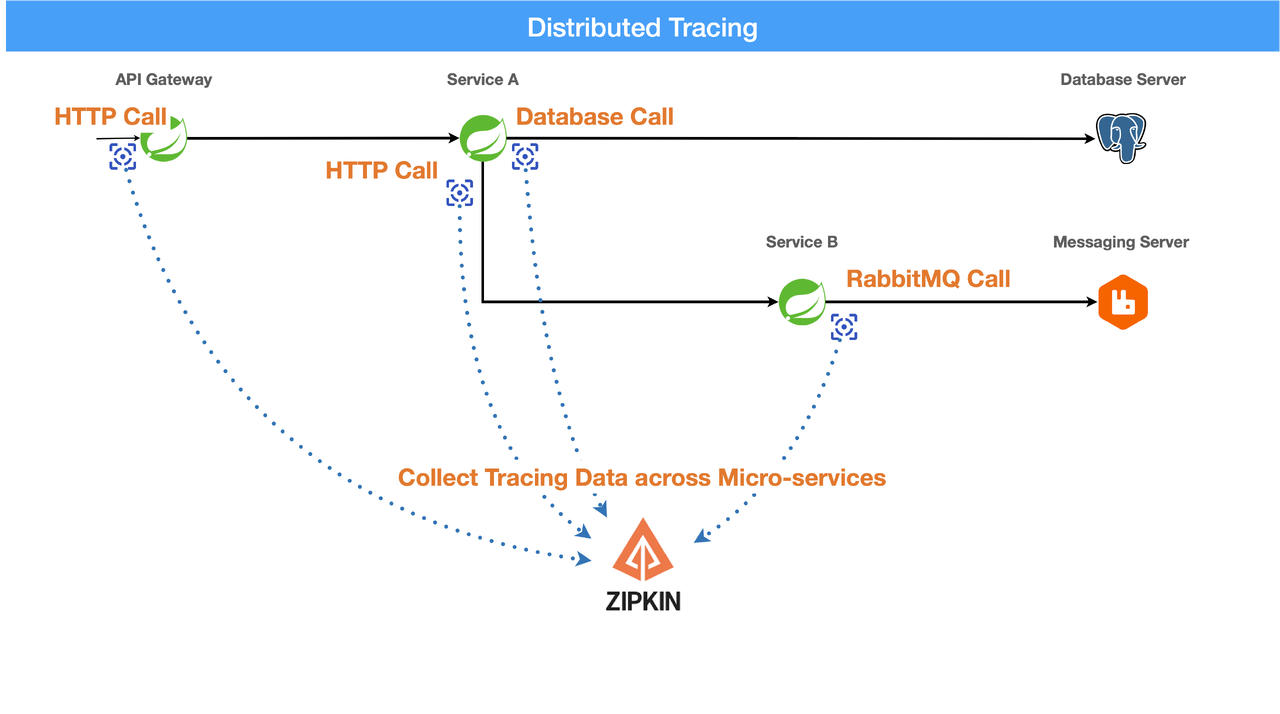
分布式追蹤(Distributed Tracing)系統(如 Jaeger, Zipkin)在監控微服務架構下的 AI
系統時,主要提供了什麼樣的洞察?
答案解析
在微服務架構中,一個使用者請求可能需要依序或並行地呼叫多個後端服務才能完成。當出現延遲或錯誤時,很難判斷是哪個環節出了問題。分布式追蹤系統透過為每個請求分配一個唯一的追蹤
ID(Trace ID),並在請求流經各個服務時記錄其處理時間(Span)和呼叫關係,從而可以視覺化地呈現一個請求的完整生命週期。這有助於:(1) 快速定位效能瓶頸(哪個服務耗時最長);(2) 理解服務間的依賴關係;(3) 診斷分散式系統中的錯誤。CPU 使用率(A)、準確率(C)、儲存空間(D)通常由其他監控工具(如 Metrics 系統、日誌系統)來收集。
#36
★★
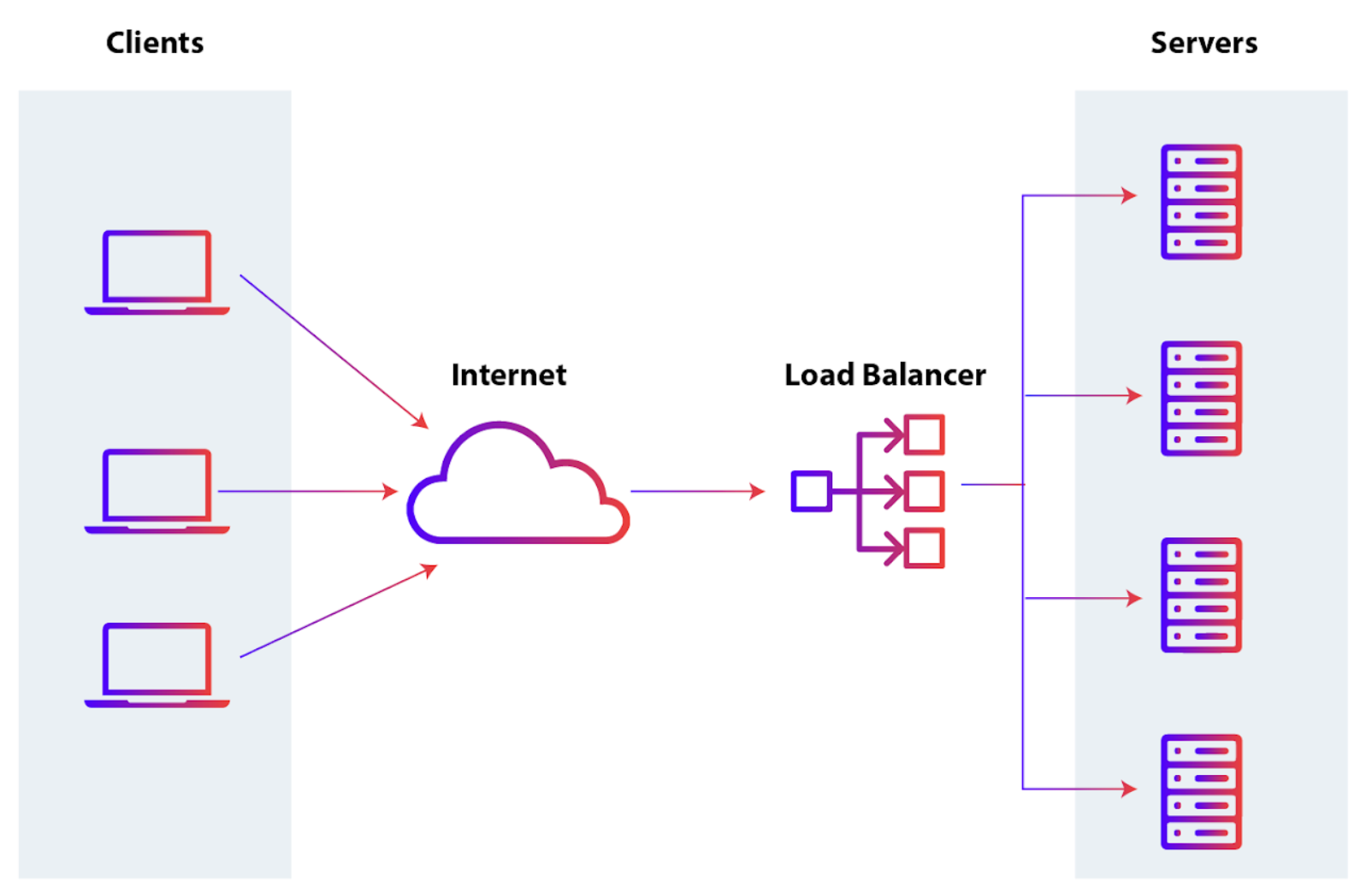
負載平衡器(Load Balancer)在高可用性和可擴展性設計中的核心功能是?
答案解析
負載平衡器位於客戶端和後端伺服器集群之間,作為流量的入口。它的主要職責是接收客戶端的請求,然後根據一定的分發演算法(如輪詢 Round Robin、最少連接 Least
Connections、基於來源 IP 等),將請求轉發給後端集群中處於健康狀態(能夠正常處理請求)的某一個伺服器實例。這樣做可以:(1) 提高可擴展性:將負載分攤到多個伺服器,避免單一伺服器過載。(2) 提高可用性:如果某個後端伺服器故障,負載平衡器可以自動將流量導向其他健康的伺服器,避免服務中斷。(3) 簡化客戶端:客戶端只需要知道負載平衡器的地址。
#37
★★★
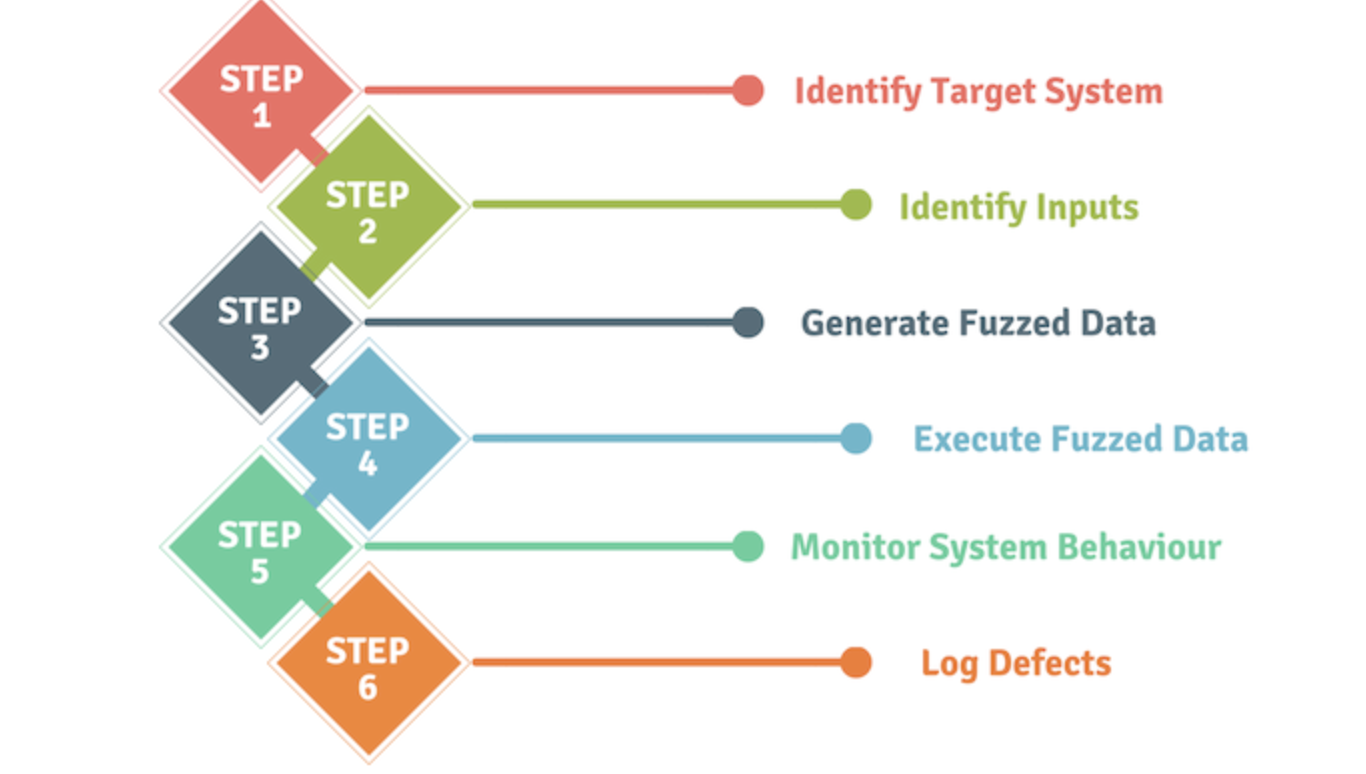
對 AI 模型進行模糊測試(Fuzz Testing)的目的是?
答案解析
模糊測試是一種自動化的軟體測試技術,常用於發現安全漏洞和穩定性問題。其核心思想是向目標程式(在這裡是 AI 模型或其 API
接口)自動生成並輸入大量無效、非預期或隨機變異的數據(Fuzz
Data)。目的是觀察系統在處理這些異常輸入時是否會出現崩潰、斷言失敗、記憶體錯誤、拒絕服務或其他異常行為。透過模糊測試,可以有效地發現模型在處理邊緣情況或惡意輸入時的潛在漏洞和穩健性問題,這對於確保部署後的系統安全至關重要。
#38
★★★
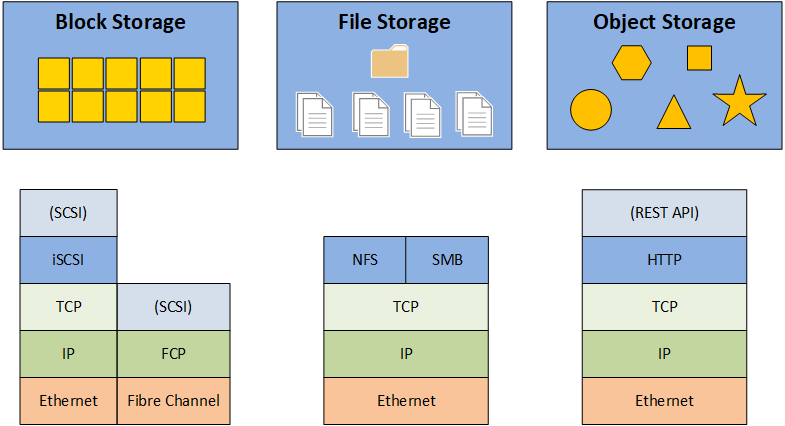
對於一個需要處理大量圖像數據的 AI 視覺應用,架構設計中通常需要包含哪個關鍵元件來高效儲存和管理圖像檔案?
答案解析
圖像、影片等非結構化數據通常檔案較大,且數量可能非常龐大。傳統的關聯式資料庫或本地文件系統可能不適合大規模儲存和管理。物件儲存服務(如
S3)提供了高擴展性、高可用性、高持久性且成本相對較低的儲存方案,非常適合存放大量的非結構化數據檔案。分散式文件系統(如
Hadoop Distributed File System, HDFS)則常用於大數據處理框架中,也能夠儲存大規模文件。記憶體內數據庫(A)主要用於高速快取。消息佇列(C)用於異步通信。API
閘道器(D)用於管理 API 請求。
#39
★★★
在設計 AI API 時,使用非同步處理(Asynchronous Processing)模式的主要適用情境是?
答案解析
同步處理是指用戶端發送請求後,必須等待伺服器處理完成並回傳結果才能繼續執行。對於耗時較長的 AI 任務,同步等待可能導致用戶端超時或體驗不佳。非同步處理模式允許用戶端發送請求後立即獲得一個回應(例如一個任務 ID),伺服器則在背景執行該耗時任務。用戶端可以稍後透過輪詢(Polling)狀態或接收回呼(Callback)/通知(Notification)的方式來獲取最終結果。這種模式適用於:(1) 長時間運行的任務;(2) 批次處理大量數據;(3) 解耦請求發送和結果獲取,提高系統的回應能力和吞吐量。
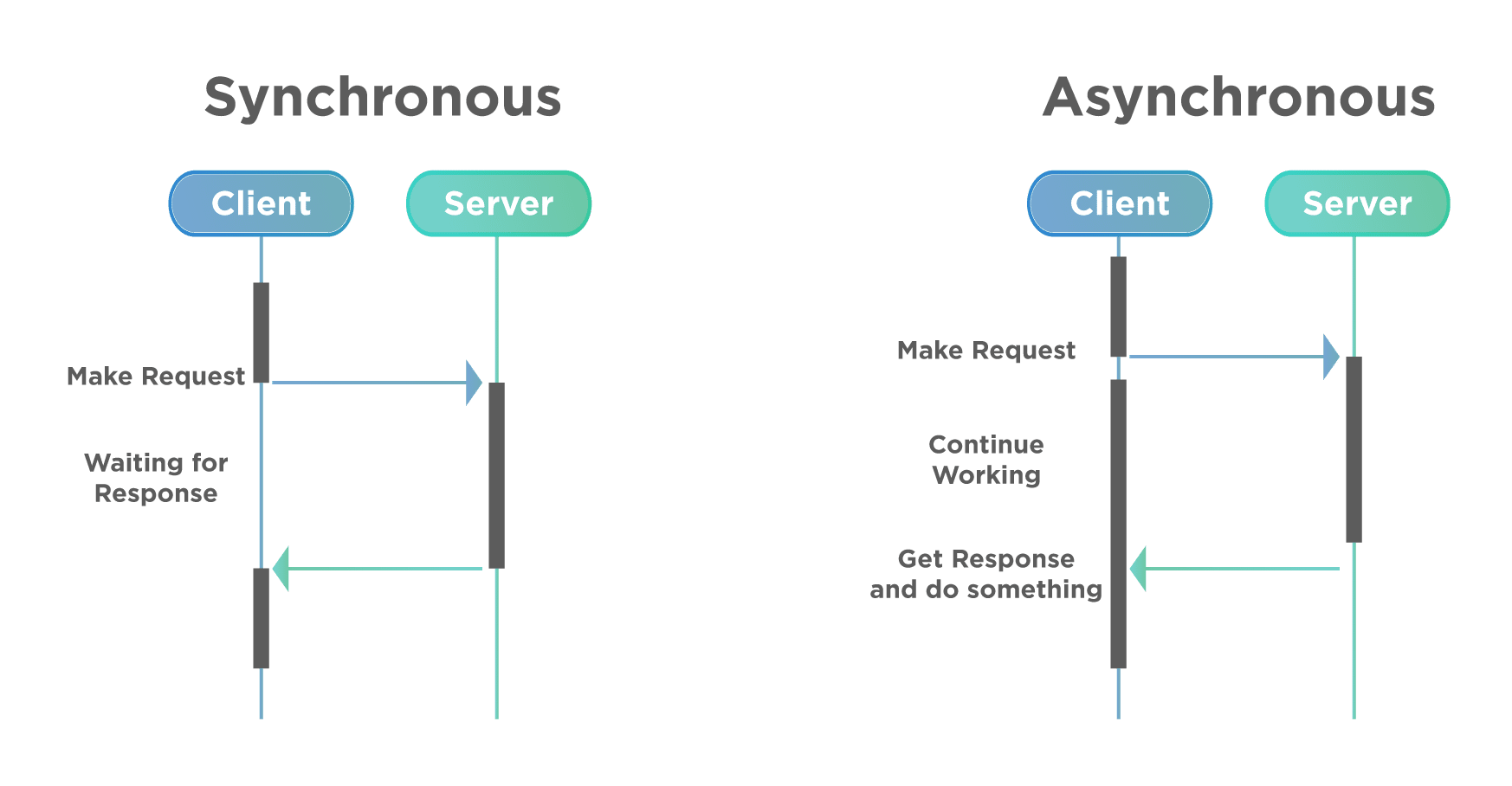
#40
★★★
基礎設施即程式碼(Infrastructure as Code, IaC)工具(如 Terraform,
AWS CloudFormation)在 MLOps 中的主要價值是?
答案解析
手動配置和管理雲端或本地的基礎設施容易出錯且難以追蹤。IaC 允許開發者或維運人員使用描述性語言(如 HCL for Terraform,
YAML/JSON for
CloudFormation)來定義所需的基礎設施狀態(例如需要多少台伺服器、網路規則、資料庫配置等)。IaC 工具會讀取這些程式碼,並自動化地創建、更新或刪除實際的基礎設施資源,使其與定義的狀態保持一致。將基礎設施的定義像應用程式碼一樣進行版本控制、審查和自動化部署,可以顯著提高部署的一致性、可重複性和效率,減少人為錯誤,並便於環境複製(如創建開發、測試、生產環境)。
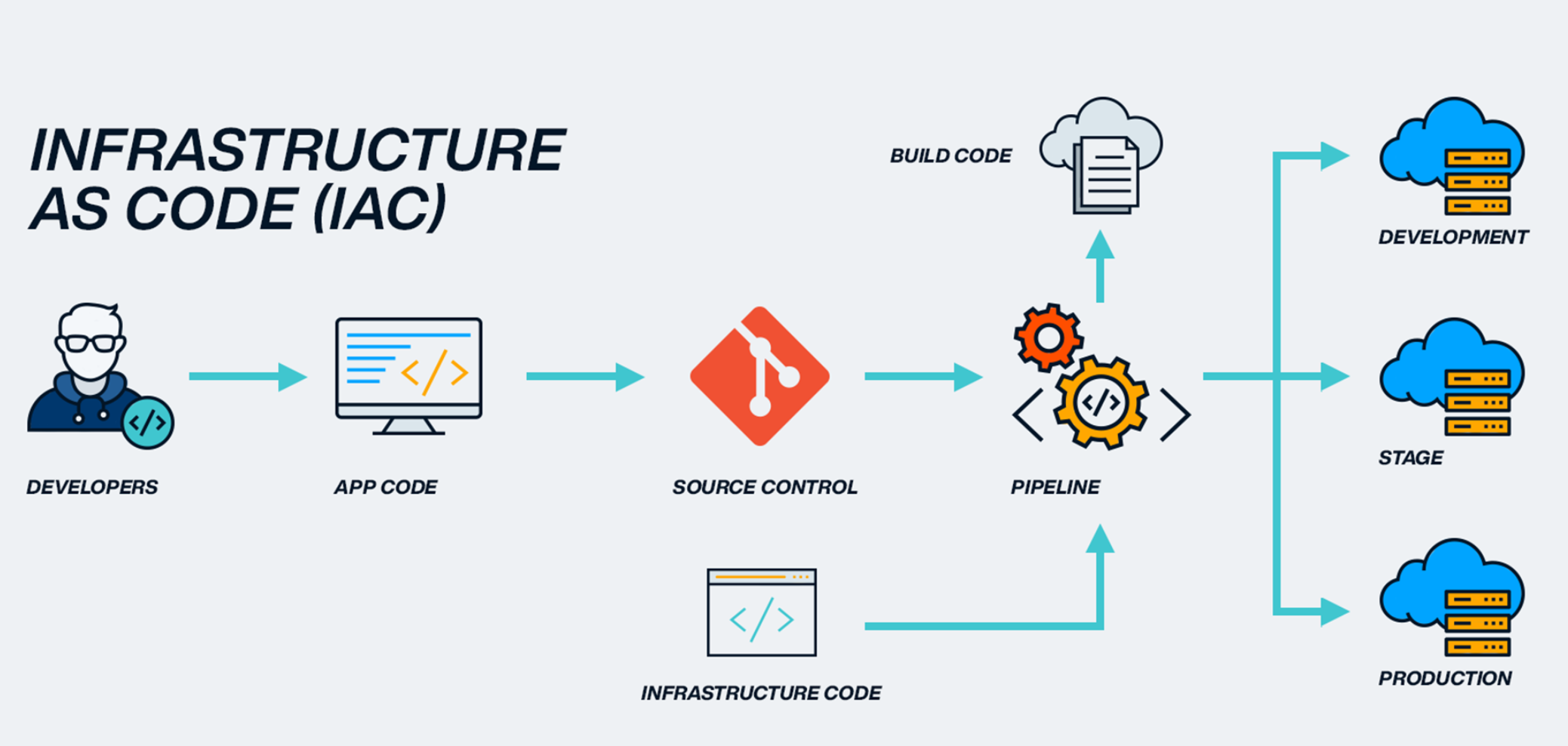
#41
★★
下列哪個指標最適合用於監控 AI 推論服務的資源使用效率?
答案解析
監控資源使用效率是效能優化和成本控制的關鍵。對於
AI 推論服務,重要的資源指標包括:(1) CPU
使用率:反映處理器負載。(2) 記憶體使用量:監控是否接近上限,避免記憶體不足。(3) GPU
利用率(如果使用 GPU):衡量 GPU 是否被充分利用。(4) 網路頻寬:監控數據傳輸量。透過監控這些指標,可以判斷服務是否資源配置過多(浪費成本)或不足(影響性能),並據此進行調整優化。準確率(A)是模型品質指標。使用者滿意度(C)和活躍使用者(D)是業務或產品指標。
#42
★★★
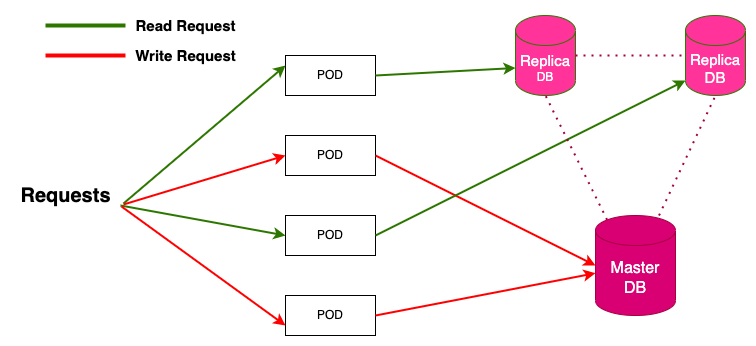
資料庫讀寫分離(Read-Write Splitting)架構通常如何提升系統的可擴展性?
答案解析
許多應用程式的讀取操作遠多於寫入操作。讀寫分離架構利用這一點來提升資料庫性能和可擴展性。它通常設置一個主資料庫(Primary/Master)處理所有的寫入操作(INSERT, UPDATE,
DELETE),並設置一個或多個從資料庫(Replica/Slave)異步或同步地複製主資料庫的數據。應用程式將讀取請求(SELECT)導向這些從資料庫,從而將讀取負載從主資料庫分擔出去。這樣可以顯著提高讀取密集型應用的吞吐量和響應速度。需要注意的是,這種架構可能引入主從複製延遲(Replication
Lag)的問題。
#43
★★★
在 AI 系統部署環境中,設定網路防火牆(Firewall)規則的主要目的是?
答案解析
防火牆是網路安全的第一道防線。它檢查進出網路(或網路內部不同區域之間)的封包,並根據設定好的規則(例如,允許或拒絕來自特定
IP 位址、特定埠號或特定協定的流量)來決定是否允許其通過。其主要目的是保護內部網路和系統免受來自外部網路(如網際網路)的未經授權訪問、惡意攻擊(如掃描、入侵嘗試)和惡意軟體的侵害。防火牆是建立安全網路邊界、實現網路分段(Segmentation)的基礎設施。
#44
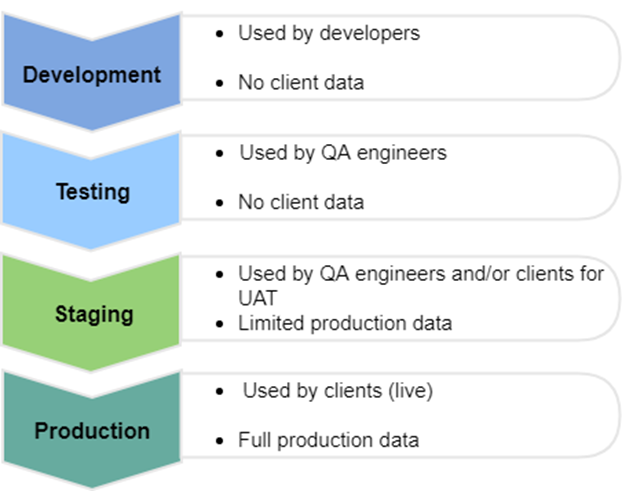
★★
對於需要快速迭代和實驗不同模型版本的場景,哪種部署環境最為合適?
答案解析
模型開發是一個需要大量實驗和迭代的過程。直接在生產環境進行實驗風險極高,可能影響真實使用者和業務。標準實踐是建立獨立的環境:(1) 開發環境:供開發人員編寫程式碼、進行單元測試和初步實驗。(2) 測試環境(Testing)/品質保證環境(QA):用於進行更全面的整合測試和功能驗證。(3) 預備環境(Staging):一個與生產環境盡可能相似的環境,用於部署前的最終驗證、壓力測試或 UAT(User Acceptance Testing)。開發和預備環境提供了安全的沙盒,讓團隊可以自由地實驗、測試和驗證新模型或功能,而不會影響到生產系統。
#45
★★★
Helm 是在 Kubernetes 生態系統中常用的工具,其主要用途是?
答案解析
部署到 Kubernetes
的應用程式通常涉及多個資源對象(如 Deployments, Services, ConfigMaps,
Secrets 等),管理這些 YAML
配置文件可能變得複雜。Helm 引入了「Charts」的概念,它將構成一個應用程式所需的所有 Kubernetes 資源定義和配置打包在一起。Helm 就像 Kubernetes
的包管理器(類似於 Linux 的
apt 或 yum),允許使用者:(1)
打包:將應用定義為可重用的 Chart。(2) 版本化:管理 Chart 的不同版本。(3) 分享:透過 Chart 儲存庫分享和發現應用。(4) 安裝與升級:使用簡單命令安裝、升級或回滾 Kubernetes 上的應用。這大大簡化了在 Kubernetes 上部署和管理複雜應用(包括 AI 應用)的過程。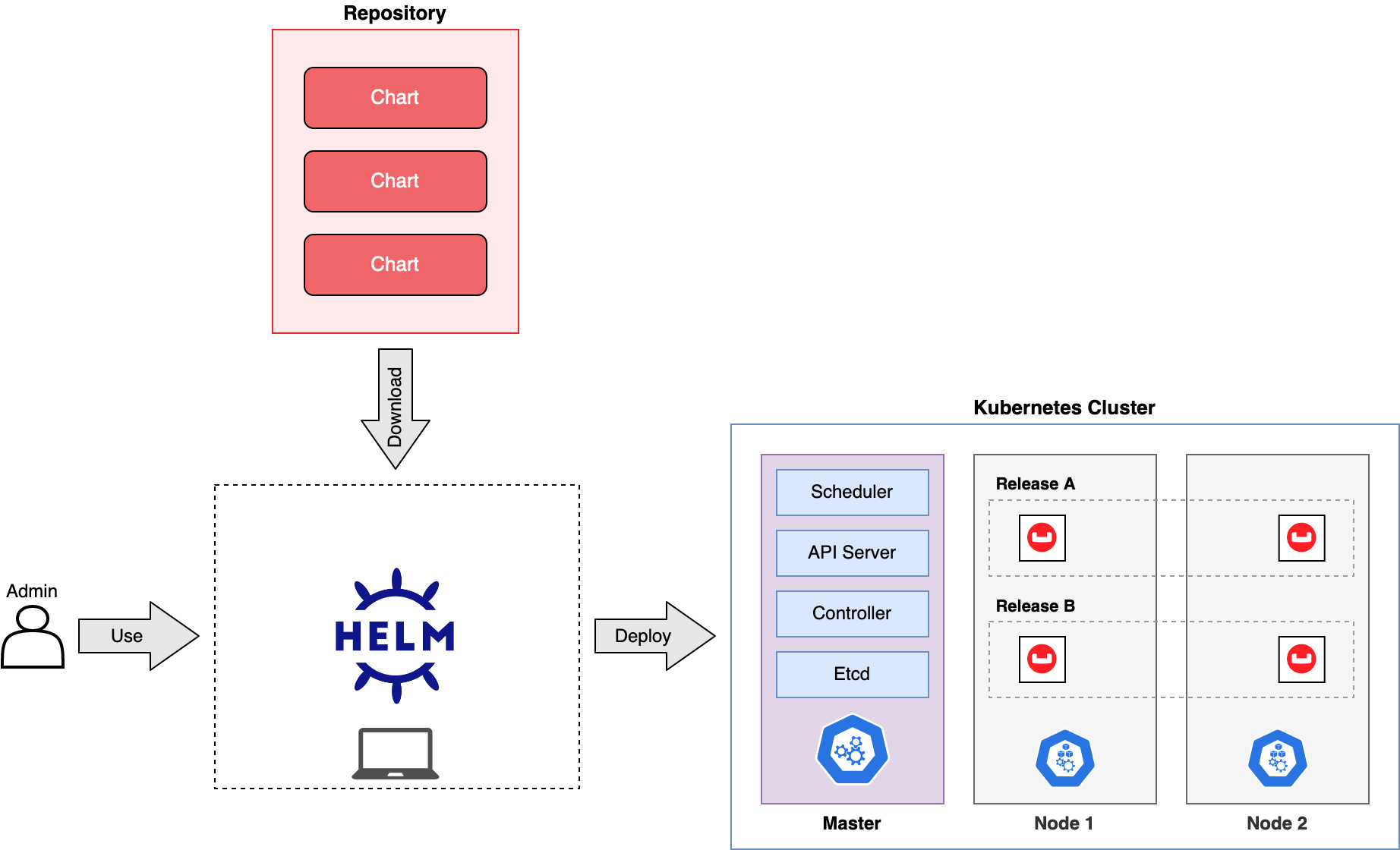
#46
★★★★
MLOps 中的「模型可重現性」(Model
Reproducibility)指的是什麼?
答案解析
模型可重現性是 MLOps 和科學研究中的重要原則。它意味著整個模型訓練的過程應該是可追溯和可重複執行的。如果給定與原始訓練完全相同的條件——包括:(1) 程式碼版本(訓練腳本、函式庫);(2) 數據版本(訓練和驗證數據);(3) 環境配置(軟體依賴、硬體);(4) 超參數和隨機種子——應該能夠重新運行訓練流程,並得到與原始模型相同(或在統計意義上非常接近)的模型結果和性能指標。確保可重現性對於除錯、驗證、協作、稽核以及建立對模型的信任至關重要。
#47
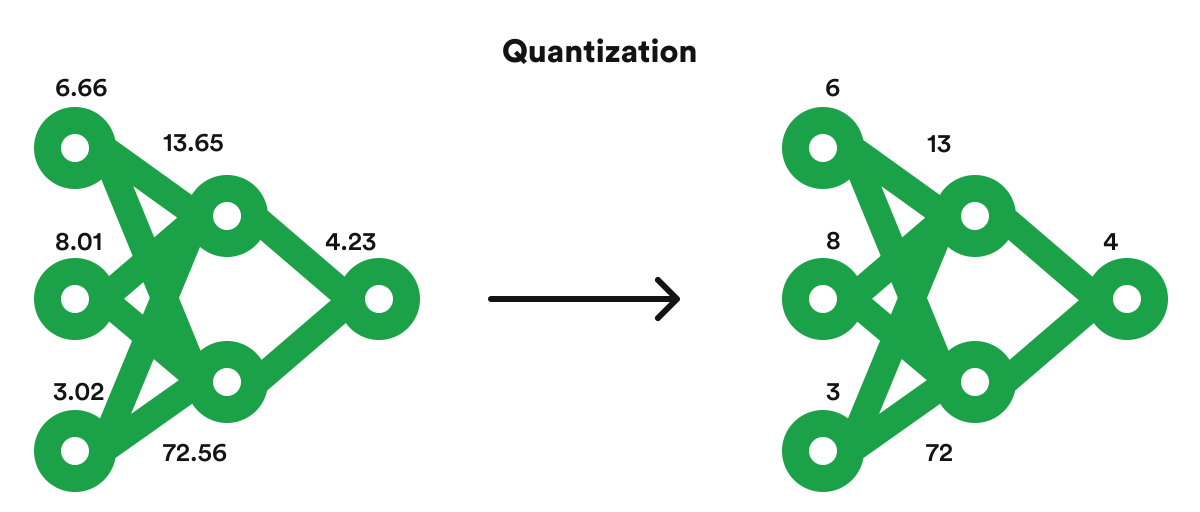
★★★
在對 AI 推論服務進行效能優化時,模型量化(Model Quantization)技術通常涉及什麼操作?
答案解析
模型量化是一種模型壓縮和優化技術,旨在減少模型的大小和計算複雜度,以提高推論速度並降低資源消耗(特別是在邊緣裝置上部署時)。其核心思想是降低模型中數值表示的精度。例如,將原本使用 32 位元浮點數(FP32)儲存的模型權重和/或中間計算結果(激活值),轉換為 16 位元浮點數(FP16)、8 位元整數(INT8)甚至更低的精度。這樣做可以:(1) 減少模型檔案大小:降低儲存和傳輸成本。(2) 減少記憶體占用。(3) 加速計算:低精度計算通常更快,尤其是在支援相關指令集的硬體上。(4) 降低功耗。當然,量化過程需要謹慎進行,以盡量減少對模型準確率的影響。
#48
★★★
服務熔斷(Circuit Breaking)模式在系統集成中的主要作用是?
答案解析
在分散式系統中,一個服務通常會依賴其他服務。如果被依賴的服務變得不穩定或無響應,持續向其發送請求不僅無法成功,還可能耗盡呼叫方服務的資源(如線程、連接),導致呼叫方也跟著變慢或崩潰,形成「連鎖故障」(Cascading
Failure)。服務熔斷器模式就像電路中的保險絲,它會監控對下游服務的呼叫。當失敗率超過某個閾值時,熔斷器會「跳閘」(Open),在接下來的一段時間內,所有對該下游服務的請求都會立即失敗返回,而不會真正發送出去。這可以:(1) 防止故障擴散:保護呼叫方服務。(2) 給下游服務恢復時間。熔斷器會定期嘗試允許少量請求通過(Half-Open 狀態),如果成功,則恢復正常(Closed 狀態);如果仍然失敗,則繼續保持跳閘狀態。
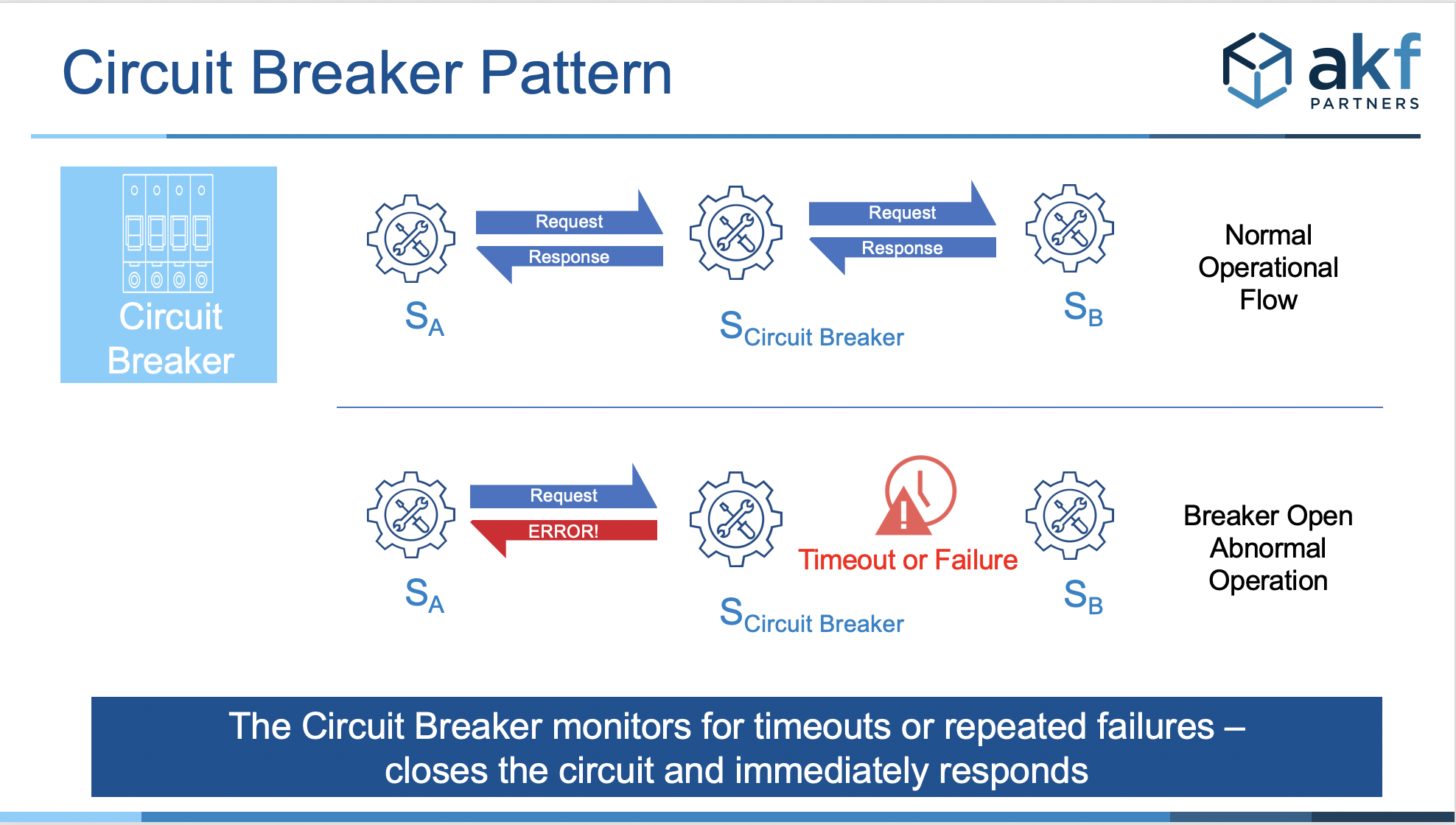
#49
★★
對部署的 AI 系統進行滲透測試(Penetration
Testing)的目的是?
答案解析
滲透測試是一種授權的、模擬的網路攻擊,由安全專家(滲透測試人員)執行,旨在評估目標系統(包括 AI 系統及其基礎設施)的安全性。測試人員會嘗試使用與真實攻擊者相同的技術和工具來發現並利用系統中的安全弱點,例如:不安全的 API 端點、配置錯誤、易受攻擊的軟體元件、權限控制缺陷、注入漏洞等。滲透測試的目標是找出潛在的安全風險,並提供修復建議,以在真正的攻擊發生前加固系統防禦。它不同於公平性評估(A)、超參數優化(C)或性能/負載測試(D)。
#50
★★★
在 AI 系統架構中引入快取(Caching)機制的主要好處是?
答案解析
快取是一種常用的性能優化技術。其原理是將經常被訪問的數據或計算結果暫時儲存在一個讀取速度更快的儲存介質中(例如,記憶體快取如 Redis 或 Memcached,或者 CDN -
Content Delivery Network)。當後續有相同的請求到達時,系統可以直接從快取中返回結果,而無需再次執行較慢的操作(如訪問資料庫、重新進行複雜計算或模型推論)。對於
AI 推論服務,如果某些輸入請求非常頻繁,將其對應的預測結果快取起來,可以顯著降低平均響應延遲,並減輕模型推論服務本身的負載。需要注意的是,快取設計需要考慮快取失效(Cache Invalidation)策略,以確保返回的不是過期的數據。
沒有找到符合條件的題目。
↑