iPAS AI應用規劃師 考試重點
L21302 AI技術系統集成與部署
主題分類
1
系統架構設計
2
模型部署策略與技術
3
系統整合
4
雲端環境與部署
5
模型監控與維護
6
測試、驗證與效能
7
系統穩定性與可用性
8
部署工具與實務
#1
★★★★★
AI 技術系統架構設計 (AI Technology
System Architecture Design) - 核心目標
核心概念
目標是設計一個能夠有效支持 AI 模型訓練、部署、運行和維護的整體系統藍圖。需要考慮模型的計算需求、數據流、與現有系統的整合、可擴展性、安全性、成本等多方面因素,確保系統能夠滿足業務目標和非功能性需求。
(參考 L21302, K16)
#2
★★★★
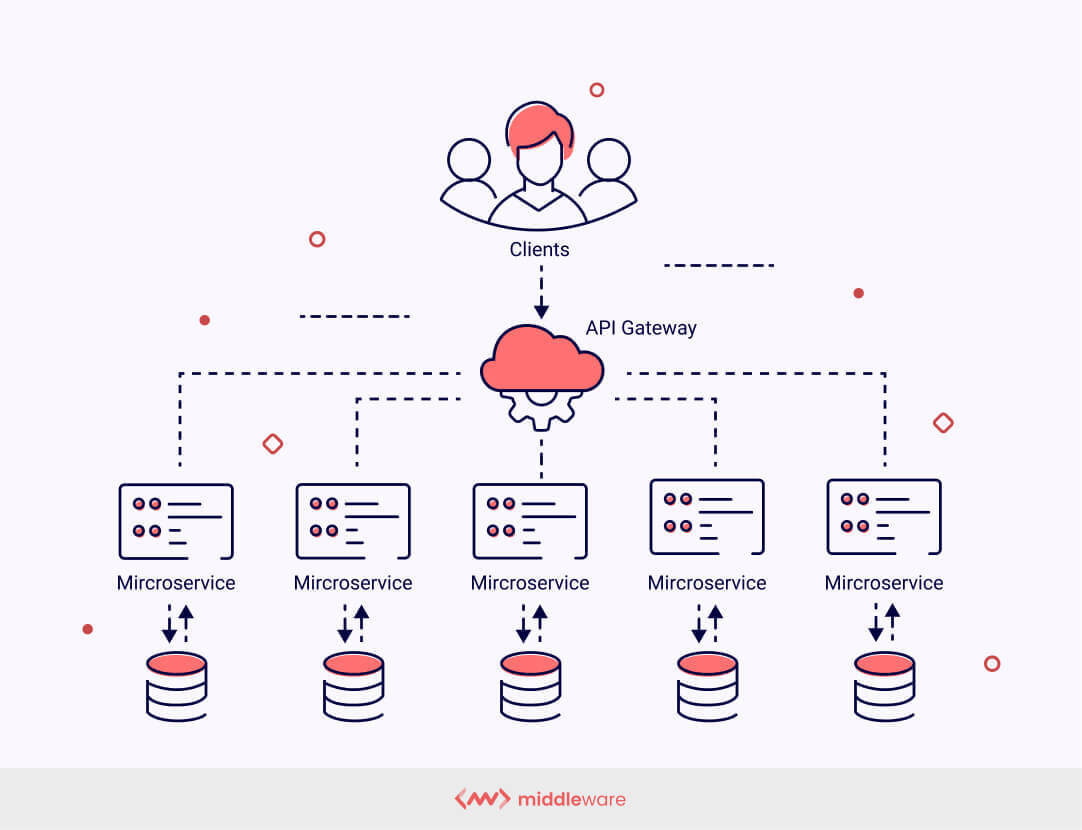
常見架構模式:微服務架構 (Microservices
Architecture)
架構模式
將大型應用程式拆分成一組小型、獨立、可獨立部署和擴展的服務。在 AI 系統中,可以將數據預處理、模型推論、結果後處理等功能封裝為不同的微服務,透過 API 互相調用。有助於提高靈活性、可擴展性和容錯性。
#3
★★★
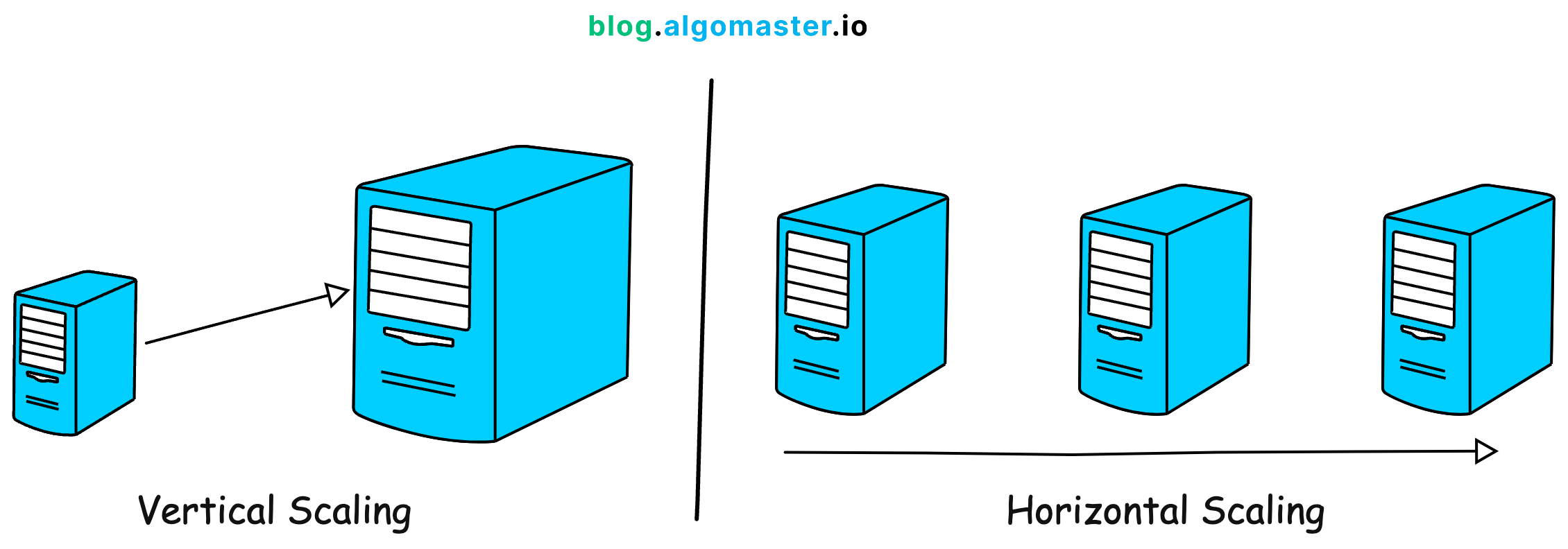
架構設計考量:可擴展性 (Scalability)
設計原則
系統架構應能應對不斷增長的數據量和用戶請求。設計時需考慮如何水平擴展(增加更多機器/容器)或垂直擴展(提升單機性能),以及如何設計無狀態服務和使用負載平衡等技術。
#4
★★★★
架構設計考量:數據流 (Data Flow) 與
數據儲存
設計原則
需要規劃數據如何從來源流入系統、經過預處理、輸入模型進行推論、以及結果如何儲存和呈現。選擇合適的數據儲存方案(如資料庫、數據湖、對象儲存)和數據處理管道(如使用 ETL 工具、訊息佇列)是架構設計的關鍵部分。(參考 K11, L222)
#5
★★★★★
模型部署 (Model Deployment)
- 核心目標
核心概念
模型部署是指將訓練好的機器學習模型整合到生產環境中,使其能夠接收新的輸入數據並產生預測或決策,從而為終端用戶或下游系統提供價值的過程。(參考 L21302, K18)
#6
★★★★
部署策略:批次預測 (Batch
Prediction)
策略說明
模型定期地(例如,每天、每週)對累積的一批數據進行預測處理。預測結果通常儲存起來供後續使用。適用於不需要即時結果的場景,如離線報告生成、定期客戶評分等。
#7
★★★★
部署策略:即時/線上預測 (Real-time/Online
Prediction)
策略說明
模型部署為一個可隨時接收請求並立即返回預測結果的服務(通常透過 API)。適用於需要低延遲、即時響應的場景,如線上推薦、即時詐欺檢測、聊天機器人等。對系統的可用性和效能要求較高。
#8
★★★★
模型部署為 API 服務 (API
Service)
常見技術
將訓練好的模型封裝起來,並透過一個Web
應用程式介面 (API, 通常是 RESTful API) 提供預測服務。客戶端應用程式可以透過發送 HTTP 請求(包含輸入數據)到 API 端點,並接收包含預測結果的回應。常用的框架如 Flask, FastAPI
(Python)。
#9
★★★
部署策略:邊緣部署 (Edge
Deployment)
策略說明
將模型直接部署到終端設備(如手機、攝影機、感測器)或本地閘道器上運行,而不是在中央伺服器或雲端。
- 優點:低延遲(無需網路傳輸)、保護數據隱私(數據不離開本地)、減少網路頻寬需求。
- 挑戰:設備資源有限(計算能力、記憶體),需要輕量級模型和模型優化/壓縮。
#10
★★★
模型版本控制 (Model Versioning)
部署管理
在部署和更新模型時,對模型進行版本控制非常重要。需要能夠追蹤哪個版本的模型正在運行、其訓練數據、超參數和性能指標。當新模型出現問題時,能夠快速回滾到舊的穩定版本。
#11
★★★★
漸進式部署策略:藍綠部署 (Blue-Green
Deployment)
部署策略
維護兩個完全相同的生產環境:藍色(當前運行版本)和綠色(新部署版本)。當綠色環境準備就緒並通過測試後,將流量(例如,透過負載平衡器)一次性地從藍色切換到綠色。如果新版本有問題,可以快速切回藍色環境。實現零停機部署和快速回滾。

#12
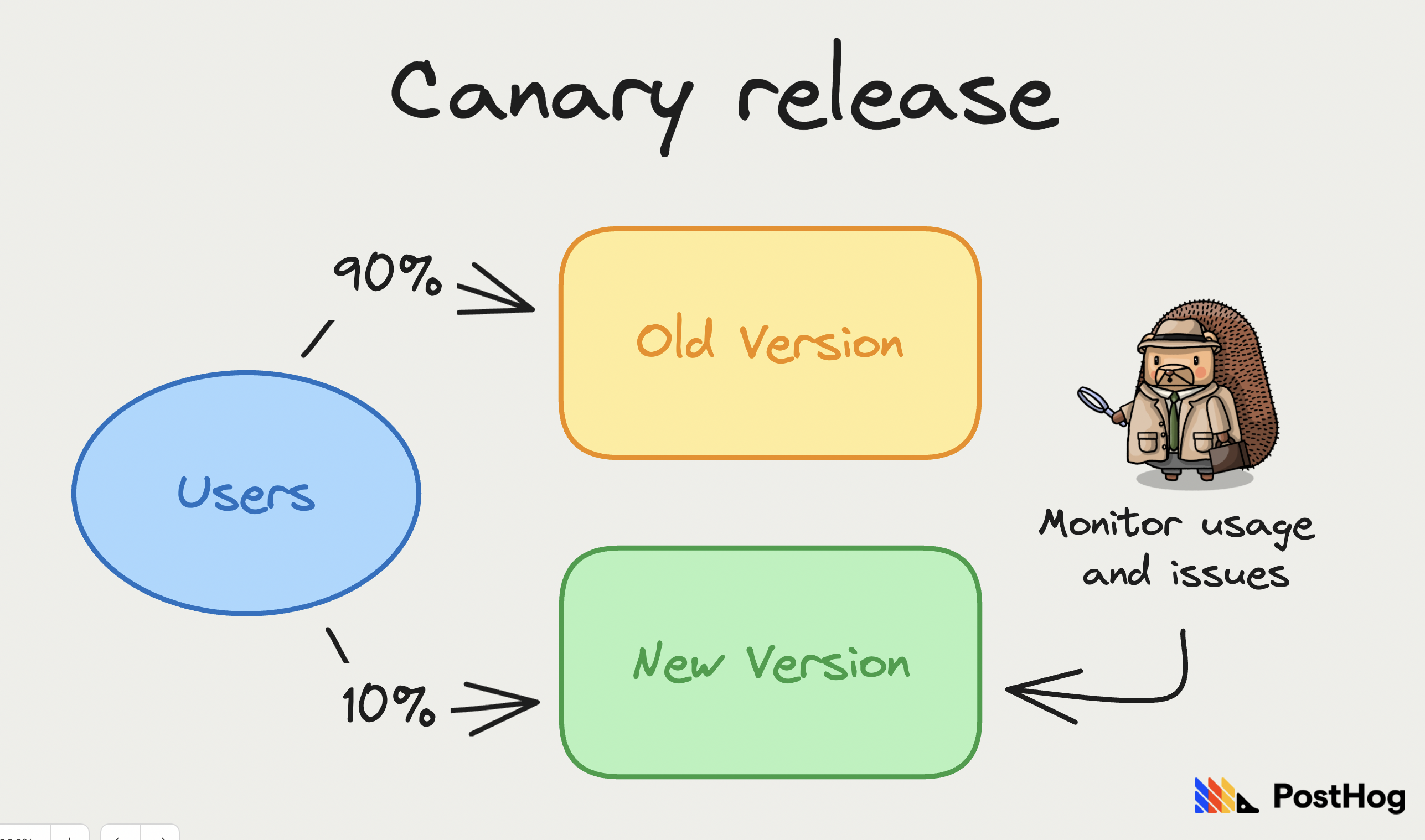
★★★★
漸進式部署策略:金絲雀釋出 (Canary
Release)
部署策略
將一小部分用戶流量(例如 1%, 5%)先導向新版本的模型或系統,同時大部分流量仍由舊版本處理。監控新版本在這一小部分流量上的表現(錯誤率、延遲、業務指標)。如果表現穩定,逐漸增加導向新版本的流量比例,直到完全取代舊版本。風險較小,可以在真實流量下驗證新版本。

#13
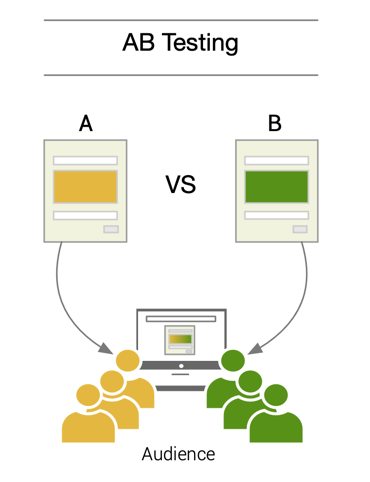
★★★
漸進式部署策略:A/B 測試 (A/B
Testing)
部署與評估
將用戶隨機分配到兩個(或多個)組,分別使用不同版本的模型或系統(A 組用舊版,B 組用新版)。在一段時間內收集兩組用戶的關鍵業務指標(如點擊率、轉換率),然後進行統計比較,以判斷新版本是否顯著優於舊版本。常用於驗證模型改進的實際業務效果。
#14
★★★★★
系統整合 (System
Integration) 的重要性 (參考課程 P3.3.1)
核心概念
AI 系統通常不是獨立運作的,需要與企業現有的應用程式、資料庫、工作流程或硬體設備進行整合。成功的系統整合確保 AI 模型能夠順暢地獲取輸入數據、將預測結果傳遞給下游系統,並融入現有的業務流程中。課程 P3.3.1 強調將 AI 應用與現有系統整合。 (參考 K17, S17)
#15
★★★★
系統整合方式:API (Application
Programming Interface) 整合
整合技術
最常見的整合方式。AI 模型被部署為一個提供 API 的服務。其他系統可以透過調用這個 API 來發送數據並獲取預測結果。通常使用 RESTful API 或 gRPC 等標準協議。
#16
★★★
系統整合方式:資料庫整合 (Database
Integration)
整合技術
AI 系統直接讀取現有資料庫中的數據作為輸入,或將預測結果寫回資料庫供其他系統使用。需要考慮資料庫的性能、一致性、安全性以及讀寫權限等問題。
#17
★★
系統整合方式:訊息佇列 (Message
Queue) 整合
整合技術
使用訊息佇列(如 Kafka, RabbitMQ)作為中介,實現異步的系統間通信。上游系統將需要預測的數據放入佇列,AI
服務從佇列中讀取數據進行處理,並將結果放入另一個佇列供下游系統消費。有助於系統解耦和提高吞吐量。
#18
★★★
系統整合中的挑戰
整合難點
- 技術異質性:不同系統可能使用不同的程式語言、平台或數據格式。
- 數據一致性:確保跨系統數據的同步與一致。
- 性能瓶頸:整合點可能成為系統性能的瓶頸。
- 安全性問題:確保數據在傳輸和處理過程中的安全。
- 溝通協調:需要不同團隊(AI 團隊、應用開發團隊、維運團隊)之間的密切合作。(參考 S06)
#19
★★★★★
雲端平台 (Cloud Platform) 在
AI 部署中的作用 (參考樣題 Q5)
核心作用
雲端平台(如 AWS, Azure, GCP)提供了豐富的服務來支持 AI 模型的開發、訓練、部署和管理:
- 彈性的計算資源(CPU, GPU, TPU)。
- 可擴展的儲存(數據湖、資料庫、對象儲存)。
- 託管的機器學習服務(如 SageMaker, Azure ML, Vertex AI),簡化 MLOps 流程。
- 容器化 (Containerization) 和編排 (Orchestration) 服務(如 Docker, Kubernetes)。
- API 閘道器、負載平衡、監控等基礎設施服務。
#20
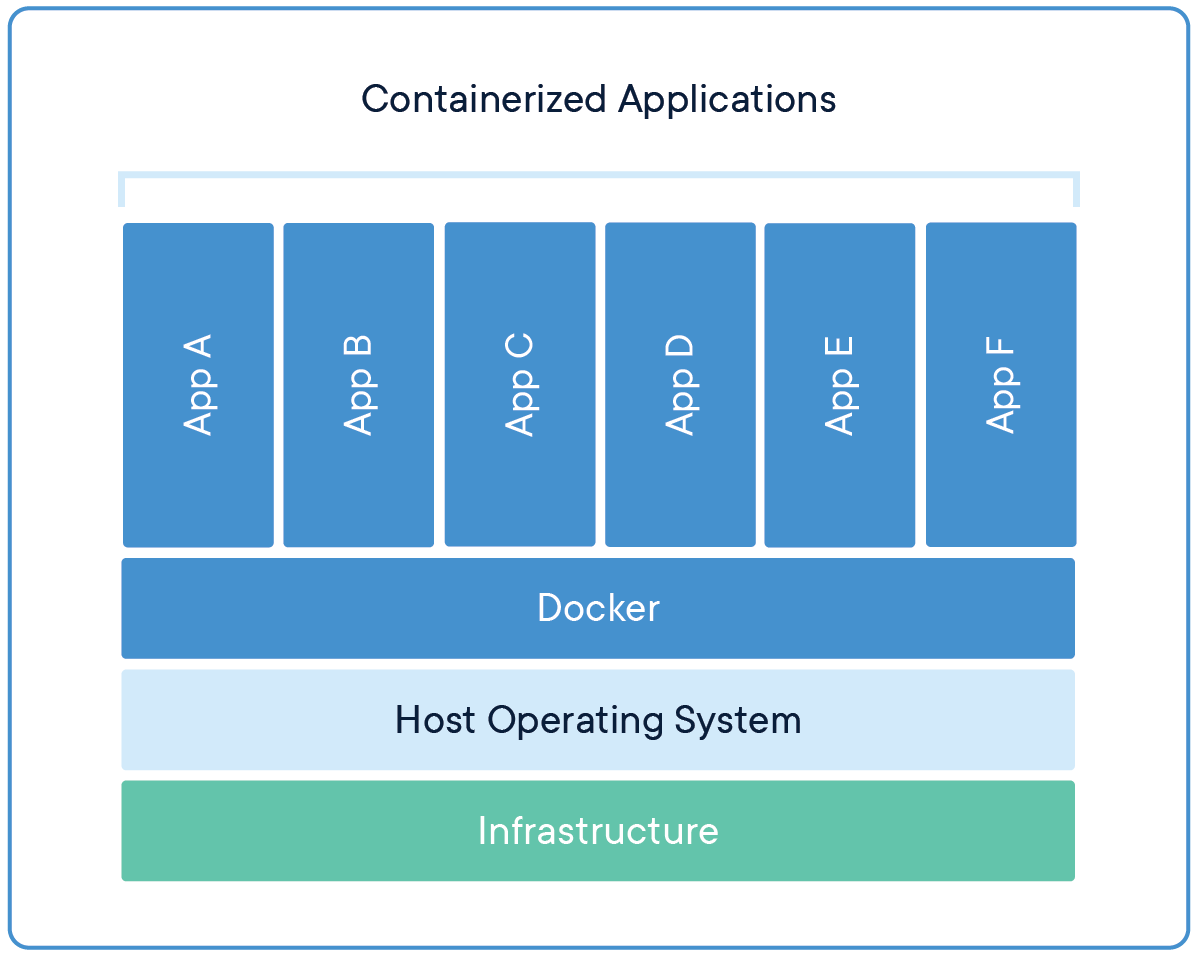
★★★★
容器化技術 (Containerization)
- Docker
部署技術
容器化(以 Docker 為代表)是將應用程式及其所有依賴項(函式庫、環境變數等)打包在一起的技術。
- 優點:環境一致性(確保模型在不同環境中運行方式相同)、快速部署、資源隔離、易於擴展。
- 在 AI 部署中,常將模型推論服務打包成 Docker 容器進行部署。
#21
★★★★
容器編排 (Container
Orchestration) - Kubernetes (K8s)
部署管理
Kubernetes 是目前最流行的容器編排平台。它負責自動化容器的部署、擴展(伸縮)、管理和網路。
- 功能:服務發現、負載平衡、自動裝箱、自我修復、滾動更新和回滾等。
- 使得在大規模集群上管理容器化 AI 應用(如模型推論服務)更加容易和可靠。
#22
★★★
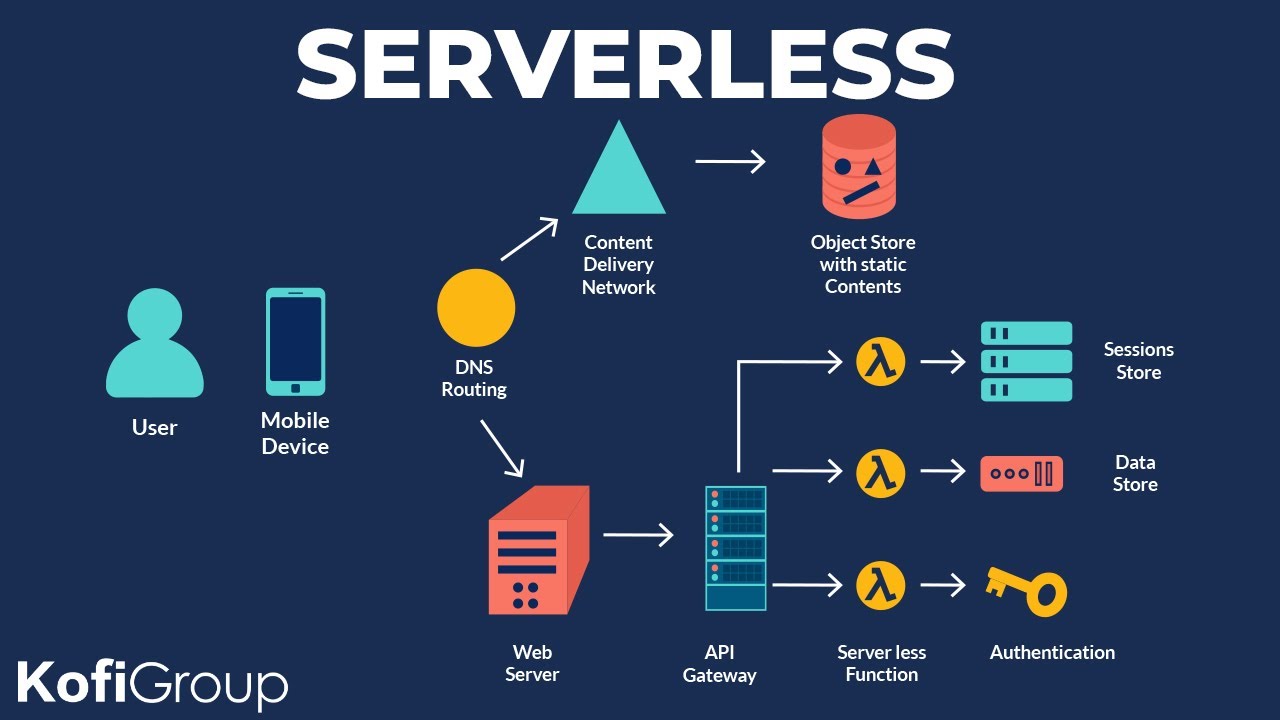
無伺服器計算 (Serverless
Computing) / 函數即服務 (FaaS)
雲端部署模式
一種雲端計算模型,開發者只需編寫和部署代碼(函數),而無需管理底層的伺服器基礎設施。雲平台會自動處理資源的分配、擴展和管理。
- 優點:簡化部署和維運、按需付費、自動擴展。
- 適用於:事件驅動的、無狀態的模型推論任務(如 AWS Lambda, Azure Functions, Google Cloud Functions)。
#23
★★★
雲端環境建置考量:安全性與合規性
建置考量
在雲端建置 AI 系統時,需要特別關注:
- 身份與存取管理 (IAM): 精確控制誰可以訪問哪些雲資源。
- 網路安全:配置防火牆、安全群組、虛擬私有雲 (VPC)。
- 數據加密:保護傳輸中和靜態數據。
- 合規性認證:選擇符合行業或地區法規(如 GDPR, HIPAA, PCI DSS)的雲服務。
#24
★★★★★
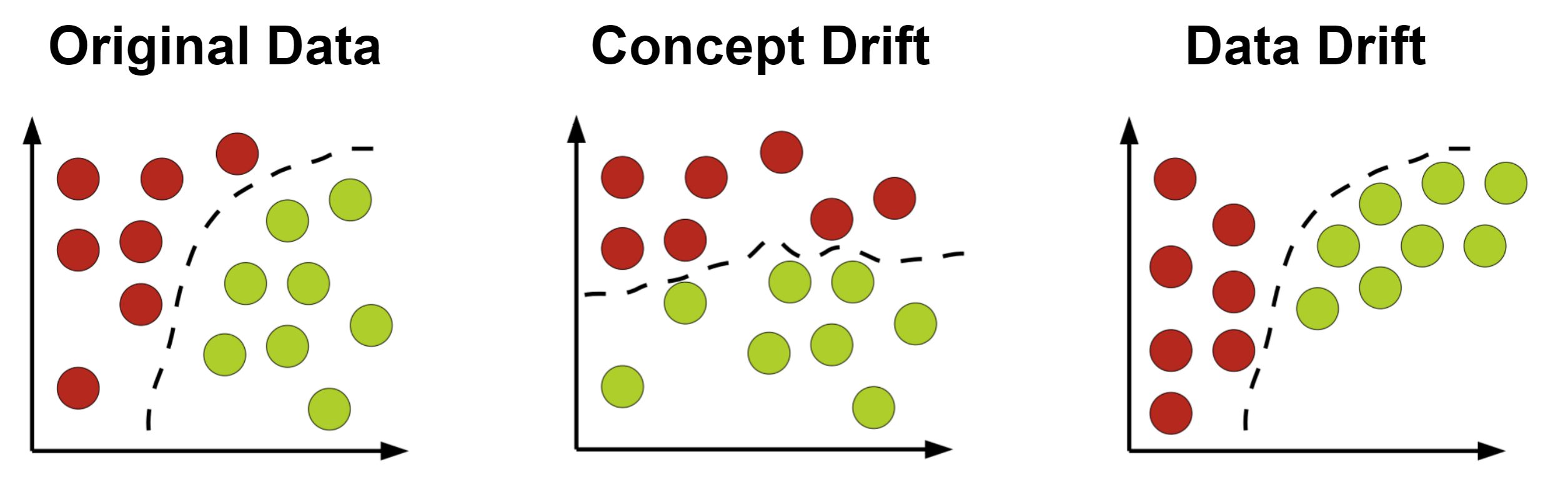
模型效能監控 (Model Performance
Monitoring) 的重要性
核心概念
AI 模型部署到生產環境後,其性能並非一成不變。由於數據漂移 (Data Drift) 或概念漂移 (Concept
Drift),模型的準確性可能隨時間下降。持續監控模型在真實數據上的性能指標(如準確率、延遲、錯誤率)至關重要,以便及早發現問題並觸發更新或重新訓練。 (參考 L21302)

#25
★★★★
監控指標:模型預測性能指標
監控內容
需要監控模型在生產數據上的核心性能指標,例如:
- 分類:準確率、精確率、召回率、F1 分數、AUC 等(如果能獲取真實標籤)。
- 迴歸:RMSE、MAE、R² 等。
- 監控這些指標的變化趨勢。
#26
★★★★
監控指標:數據漂移 (Data Drift)
監控
監控內容
監控輸入到模型的生產數據的分佈是否與訓練數據的分佈發生了顯著變化。可以使用統計檢定(如 KS 檢定)或分佈距離度量來檢測漂移。數據漂移是模型性能下降的常見原因。
#27
★★★
監控指標:概念漂移 (Concept
Drift) 監控
監控內容
監控輸入特徵與目標變數之間的真實關係是否發生了變化。例如,用戶的偏好可能隨時間改變。概念漂移通常更難直接檢測,常透過模型性能的持續下降來間接推斷。
#28
★★★★
模型更新管理 (Model Update
Management)
核心流程
當監控到模型性能下降或數據發生顯著漂移時,需要觸發模型的更新流程。這可能包括:
- 使用新數據重新訓練 (Retraining) 現有模型。
- 調整超參數。
- 甚至重新選擇或設計模型架構。
#29
★★★
模型監控工具
工具舉例
許多 MLOps 平台和雲服務提供了模型監控功能,例如:AWS
SageMaker Model Monitor, Azure Machine Learning Data Drift
Detection, Google Cloud Model Monitoring,以及開源工具如
Evidently AI, Grafana+Prometheus 等。
#30
★★★★★
系統測試 (System Testing) 在
AI 系統中的重要性
核心概念
對包含 AI 模型在內的整個系統進行測試,以確保其功能正確、性能達標、穩定可靠並滿足所有需求。AI 系統的測試比傳統軟體測試更複雜,因為需要考慮數據依賴性、模型隨機性、性能評估等因素。(參考 L21302, S19)
#31
★★★★
測試類型:單元測試 (Unit Testing)
測試層級
測試系統中最小的可測試單元,例如單個函數、類或模組。在 AI
系統中,可能包括測試數據預處理函數、特徵提取函數、模型加載函數等的正確性。
#32
★★★★
測試類型:整合測試 (Integration Testing)
測試層級 (參考 S19)
測試不同模組或服務之間的交互和接口是否按預期工作。例如,測試數據管道是否能正確將數據傳遞給模型服務,模型服務是否能正確調用其他依賴服務。(S19
強調整合測試能力)
#33
★★★★
測試類型:模型評估/驗證 (Model Evaluation/Validation)
AI 特定測試
使用獨立的驗證集或測試集,根據預定義的性能指標(如準確率、AUC、RMSE)評估訓練好的模型的預測能力和泛化能力。這是 AI 系統測試的核心環節。(參考 L23303)
#34
★★★
測試類型:效能測試 (Performance Testing)
非功能測試 (參考 K19)
測試系統在不同負載下的響應時間、吞吐量、資源利用率等性能指標。對於即時預測服務,延遲 (Latency) 和吞吐量 (Throughput)
是關鍵指標。(K19 強調效能分析方法)
#35
★★★
測試類型:壓力測試 (Stress Testing)
非功能測試
測試系統在極端負載或資源不足的情況下的穩定性和行為,找出系統的瓶頸和失效點。
#36
★★★
測試類型:安全性測試 (Security Testing)
非功能測試
測試系統是否存在安全漏洞,能否抵禦常見的攻擊(如注入攻擊、權限繞過、對抗性攻擊等)。
#37
★★★
系統驗證 (System Validation) 的目標
目標
確認最終構建的系統是否滿足原始定義的需求和業務目標。測試關注「系統是否正確構建」,驗證關注「是否構建了正確的系統」。(參考 L21302)
#38
★★★★
系統穩定性 (Stability)
核心概念
指系統在正常負載和預期環境下能夠持續、可靠地運行,不易出現崩潰、錯誤或性能急劇下降的能力。影響因素包括代碼品質、資源管理、錯誤處理、依賴項穩定性等。(參考
L21302)
#39
★★★★
系統可用性 (Availability)
核心概念
指系統在需要時能夠正常提供服務的時間比例。通常用百分比表示(如 99.9%, 99.99%)。高可用性意味著系統的停機時間非常短。影響因素包括硬體可靠性、軟體穩定性、冗餘設計、快速故障轉移能力等。(參考 L21302)
#40
★★★
提高可用性的技術:冗餘 (Redundancy)
高可用技術
部署多個相同功能的組件(伺服器、資料庫、網路連接等),當一個組件失效時,其他組件可以接管其工作,避免單點故障 (Single Point of Failure)。
#41
★★★
提高可用性的技術:故障轉移 (Failover)
高可用技術
當主系統或組件發生故障時,能夠自動或手動地將服務切換到備用系統或組件,以確保持續服務。需要配合冗餘設計。
#42
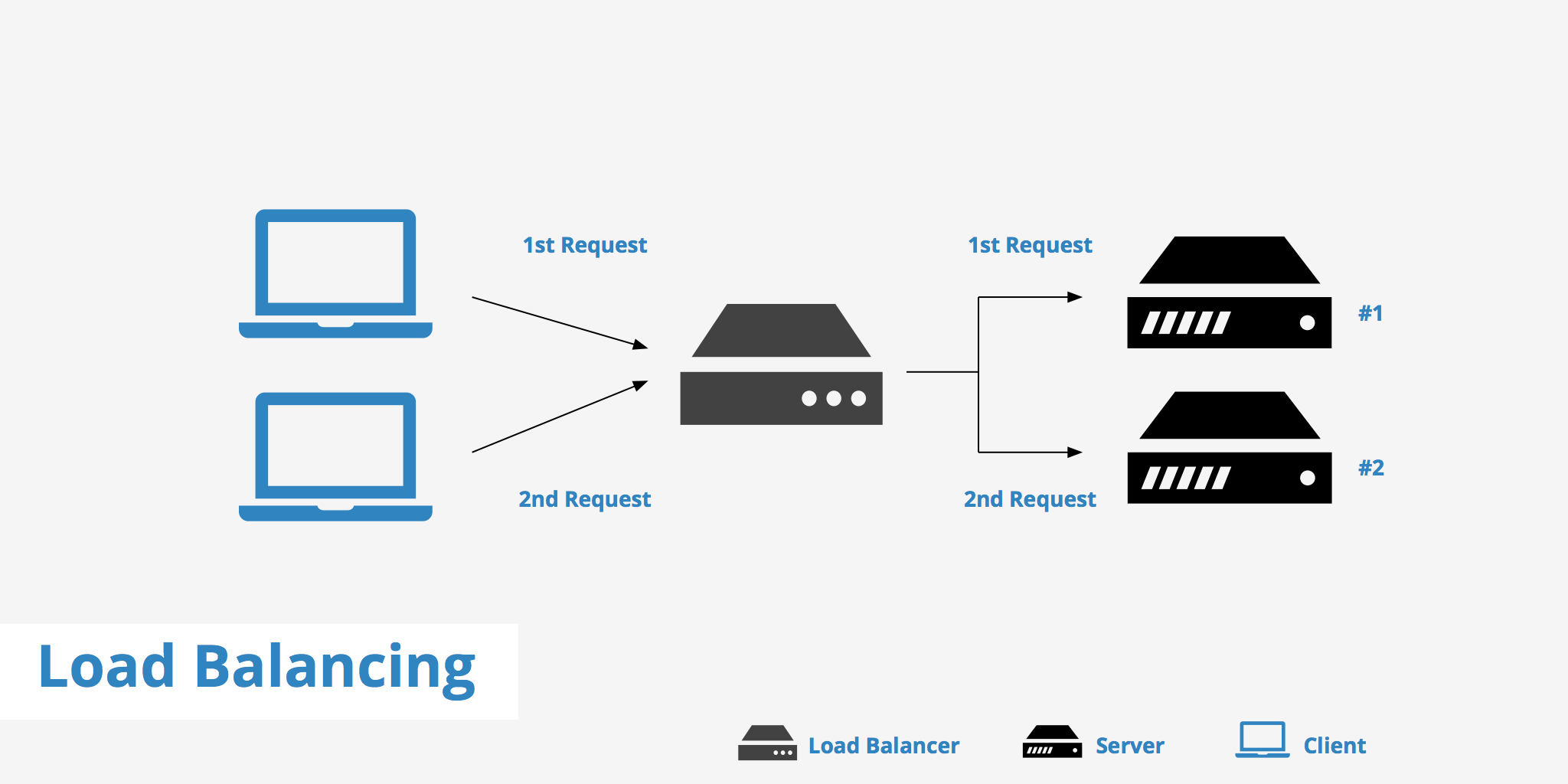
★★★
提高可用性的技術:負載平衡 (Load Balancing)
高可用/擴展技術
將傳入的請求(如 API 調用)分發到多個後端伺服器或服務實例上。不僅可以提高系統的吞吐量和響應速度,還可以提高可用性(如果一個實例失效,請求可以轉發到其他健康實例)。
#43
★★★★
MLOps (Machine Learning Operations) 的角色
核心實踐
MLOps 是一套結合了機器學習、數據工程和 DevOps 的實踐,旨在實現
AI 模型的標準化、自動化和高效部署與管理。它涵蓋了從數據準備、模型訓練、驗證、部署、監控到再訓練的整個生命週期,對於確保 AI 系統的集成部署順利、可靠和可持續至關重要。
#44
★★★
持續整合/持續部署 (CI/CD) 在 AI 中的應用
自動化流程
CI/CD 是一種自動化軟體開發和部署流程的方法。在 AI 領域,CI/CD 管道可以自動化數據驗證、模型訓練、模型評估、打包和部署等步驟,加速模型迭代和上線速度,並確保流程的一致性和可靠性。(參考 K14 敏捷開發)
#45
★★★
模型伺服框架 (Model Serving Frameworks)
部署工具
專門用於部署和提供模型推論服務的框架,例如:
- TensorFlow Serving
- TorchServe (PyTorch)
- NVIDIA Triton Inference Server
- Seldon Core
- KServe (前身 KFServing)

#46
★★
實驗追蹤與模型註冊 (Experiment Tracking & Model
Registry)
MLOps 工具
- 實驗追蹤:記錄模型訓練過程中的超參數、代碼、數據、指標等(如 MLflow Tracking, Weights & Biases)。
- 模型註冊:集中管理和版本化訓練好的、準備部署的模型(如 MLflow Model Registry, 雲平台服務)。
#47
★★
技術債 (Technical Debt) 在 AI 系統中的體現
架構考量
AI 系統中特有的技術債可能來自:數據依賴性、模型複雜性、配置複雜性、監控和修復成本等。架構設計需要考慮如何管理和償還這些技術債。

#48
★★
模型序列化 (Model Serialization)
部署準備
將訓練好的模型(包括其架構和學習到的參數)保存到檔案中的過程,以便後續可以加載並用於部署或推論。常見格式如 Pickle (Python), SavedModel (TensorFlow), torch.save (PyTorch), ONNX。
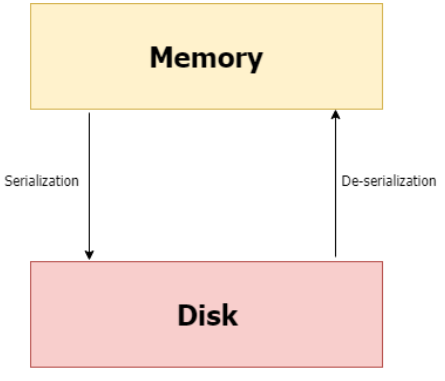
#49
★
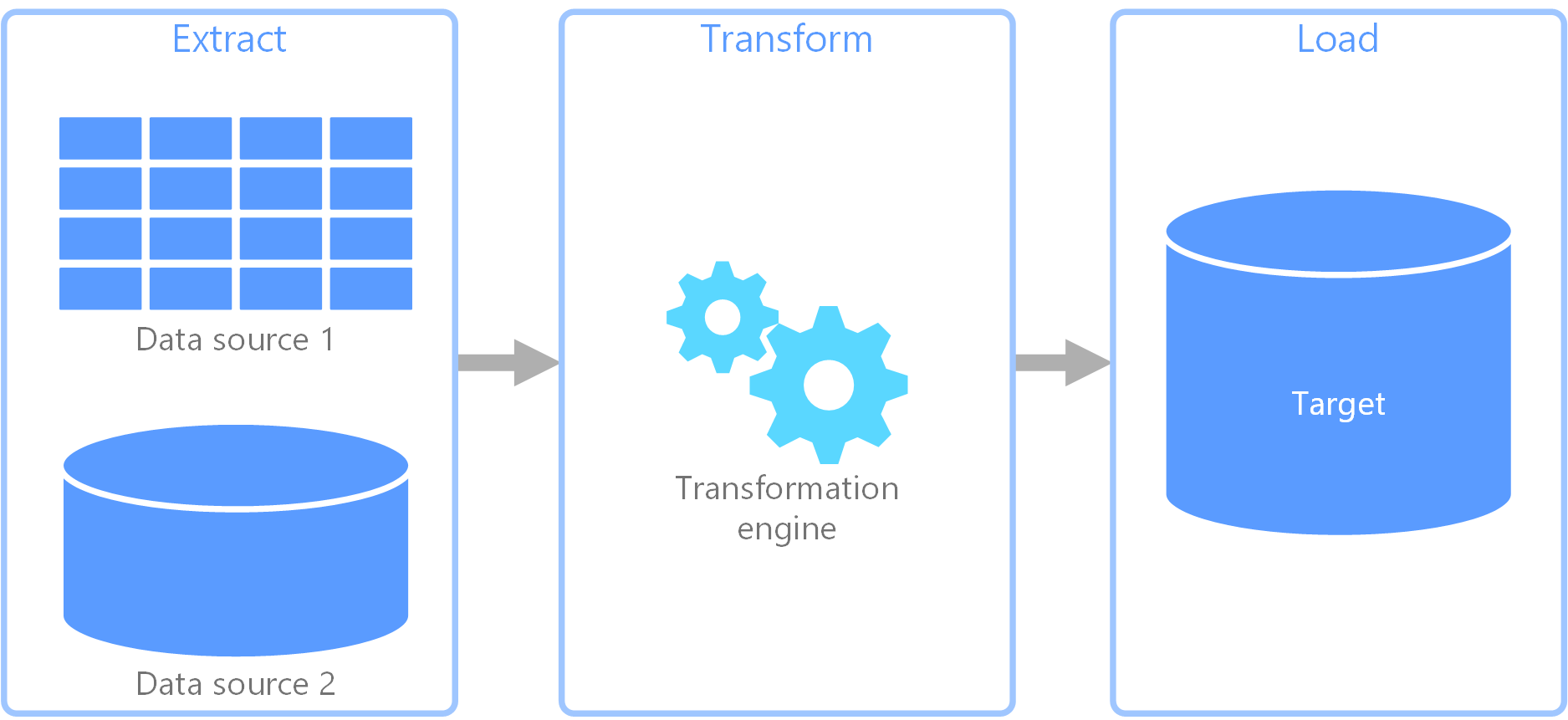
ETL (Extract, Transform, Load) 管道
數據整合
用於從不同來源提取數據,進行轉換和清洗,然後加載到目標系統(如資料倉儲或 AI 模型的輸入)的標準流程。是系統整合中數據層面的關鍵。
#50
★★
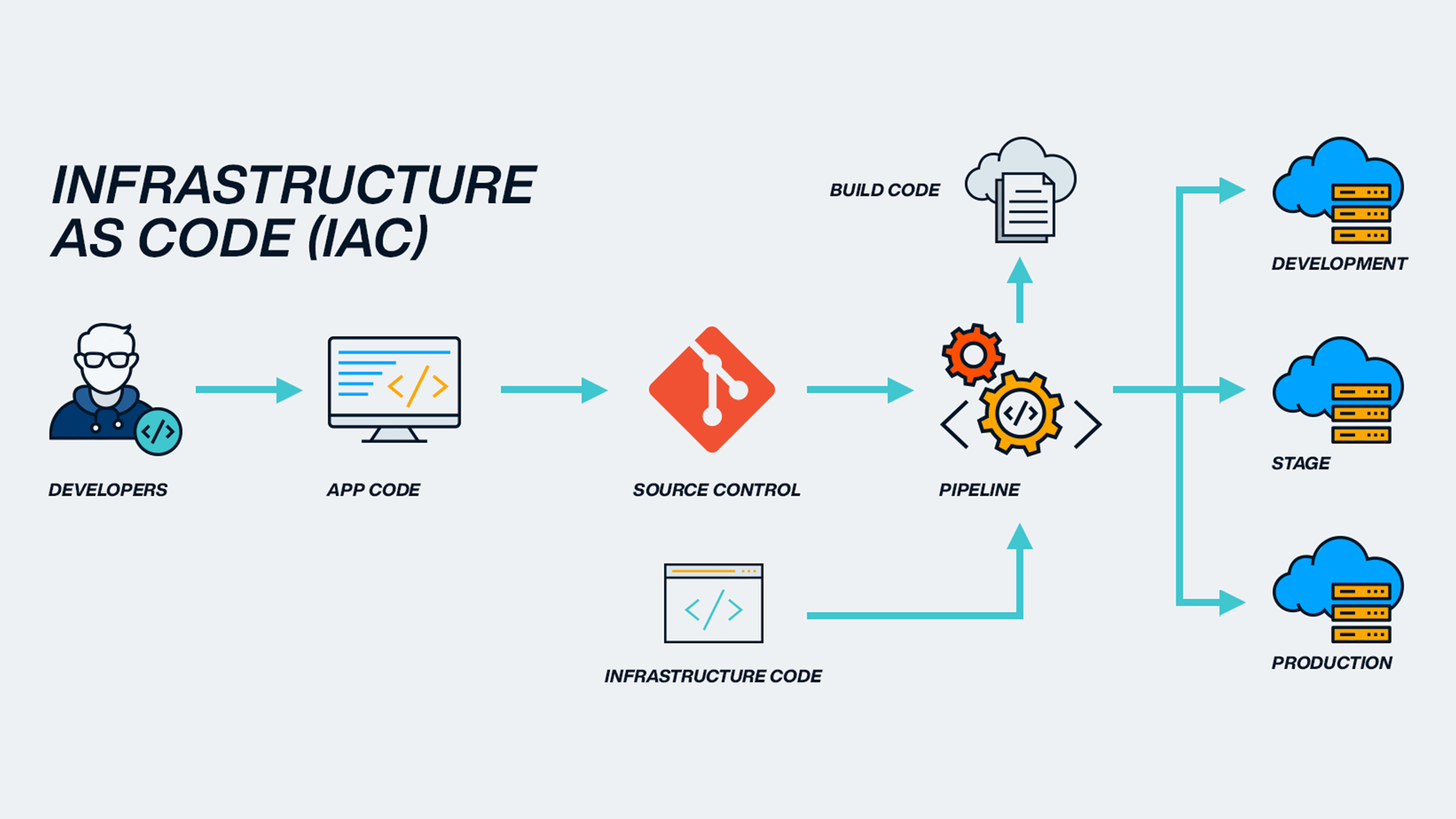
基礎設施即代碼 (IaC, Infrastructure as Code)
雲端建置
使用代碼(如 Terraform, CloudFormation)來定義和管理雲端基礎設施(伺服器、網路、資料庫等)。有助於實現環境的一致性、可重複性和自動化。
#51
★★
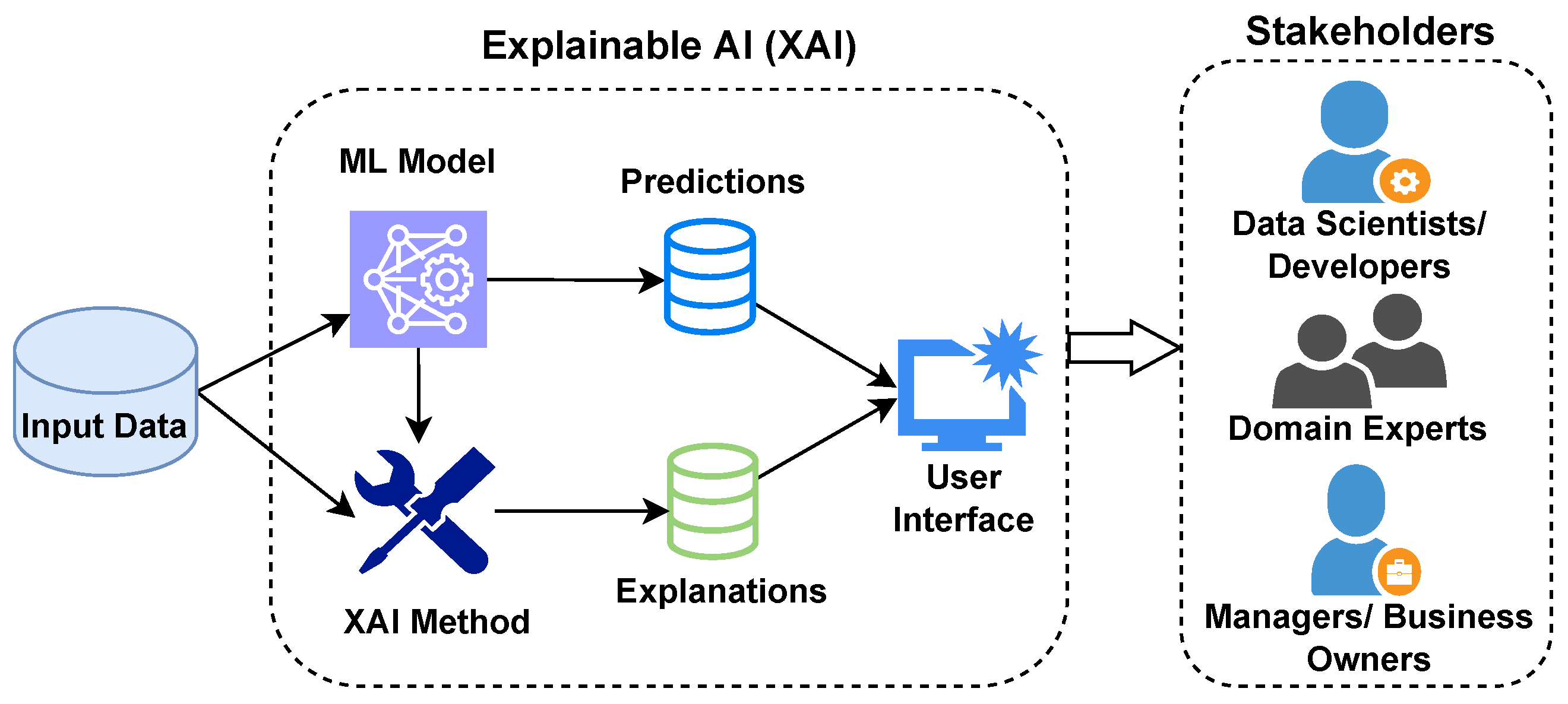
模型可解釋性 (XAI) 與監控
監控輔助
除了監控性能指標,使用 XAI 工具(如 SHAP
值監控)可以幫助理解模型預測行為的變化,可能指示數據或概念漂移。
#52
★★
回歸測試 (Regression Testing)
測試類型
在修改代碼或更新模型後,重新運行先前的測試案例,以確保修改沒有引入新的錯誤或導致原有功能失效。
#53
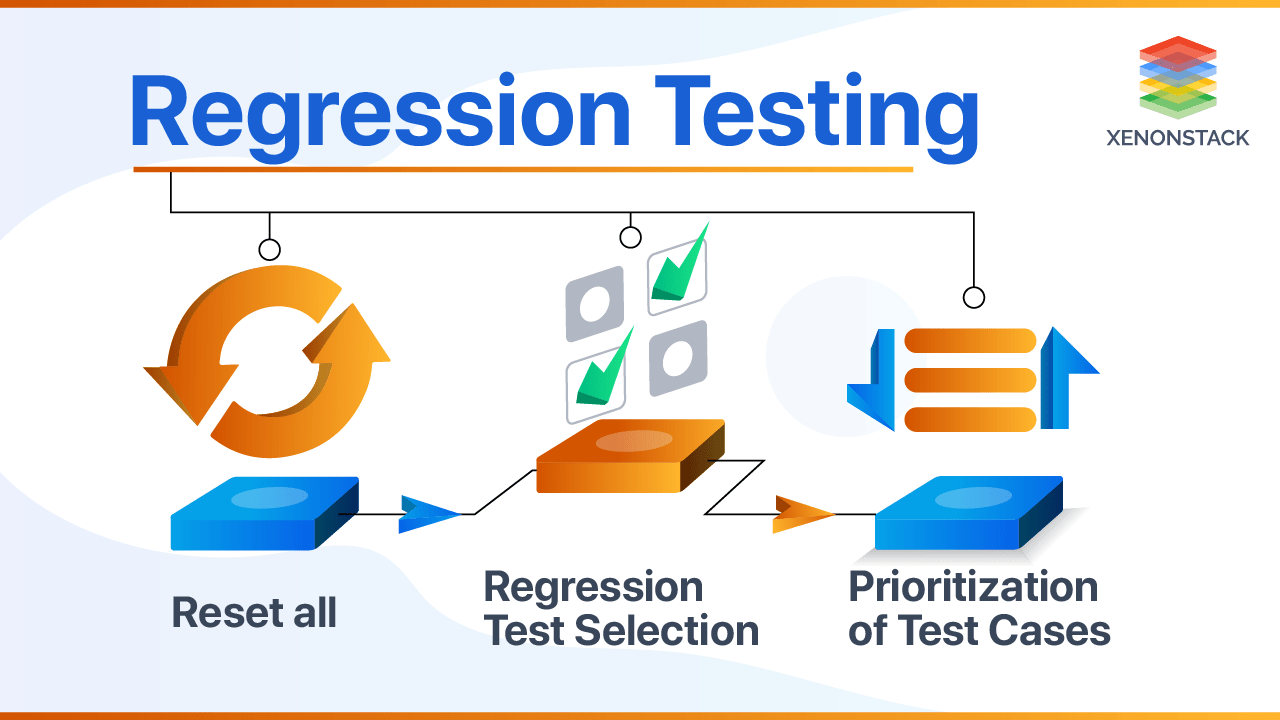
★★
容錯設計 (Fault Tolerance)
穩定性設計
設計系統使其在部分組件發生故障時仍能繼續運行(可能性能有所降低)。冗餘和故障轉移是實現容錯的常用手段。
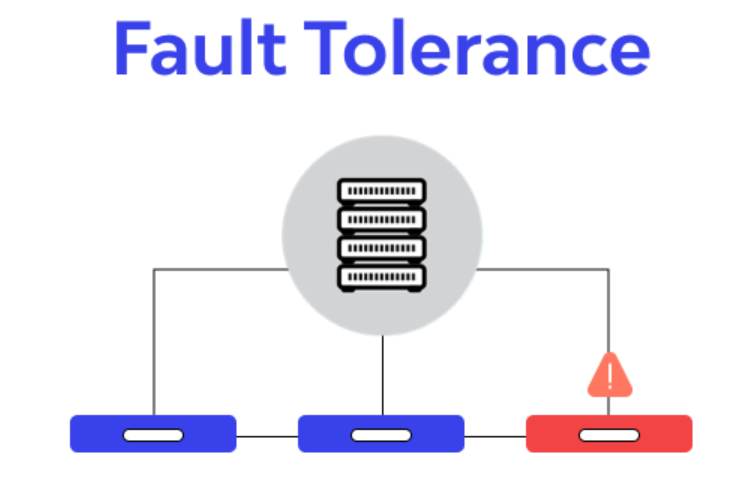
#54
★★
敏捷開發方法 (Agile Methodologies) (參考 K14)
開發實務
迭代式、增量式的開發方法(如 Scrum, Kanban)強調快速交付、持續反饋和適應變化。在 AI 系統開發和部署中,敏捷方法有助於應對模型和需求的快速變化。(K14 知識點)
#55
★
面向服務架構 (SOA, Service-Oriented Architecture)
架構模式
一種比微服務更粗粒度的架構模式,將業務功能組織為可重用的服務。是微服務的前身或相關概念。
#56
★
模型量化 (Quantization)
模型優化
將模型參數(權重、激活值)從高精度浮點數(如 32
位)轉換為低精度整數(如 8 位)的技術。可以顯著減小模型大小、加速推論並降低功耗,常用於邊緣部署。
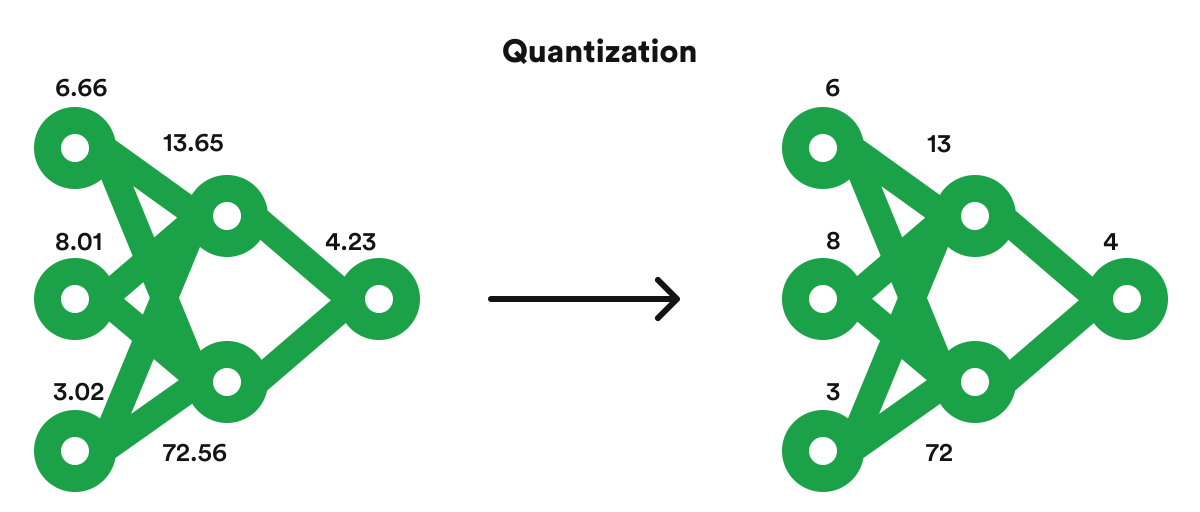
#57
★
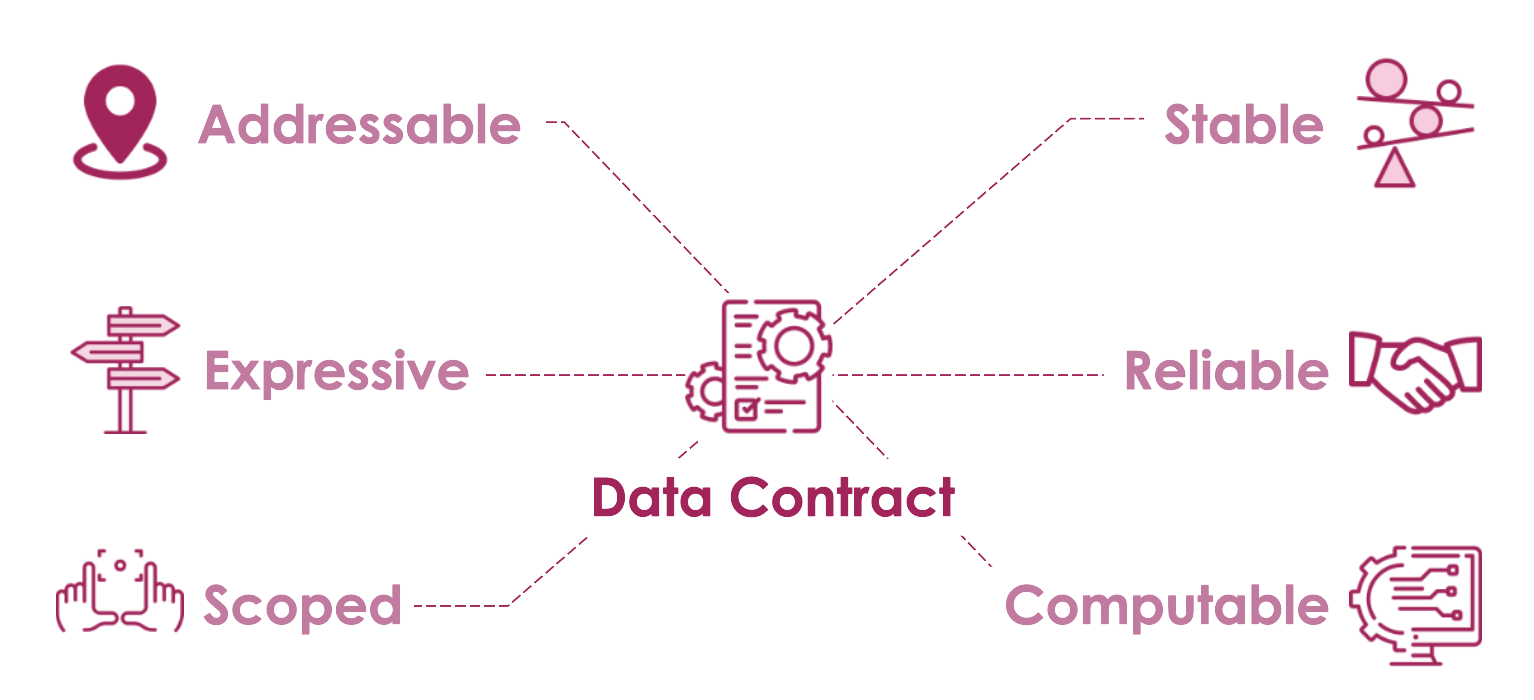
數據契約 (Data Contracts)
整合協調
定義系統間數據交換的格式、結構、語義和品質標準的協議。有助於確保系統整合的穩定性和數據一致性。
#58
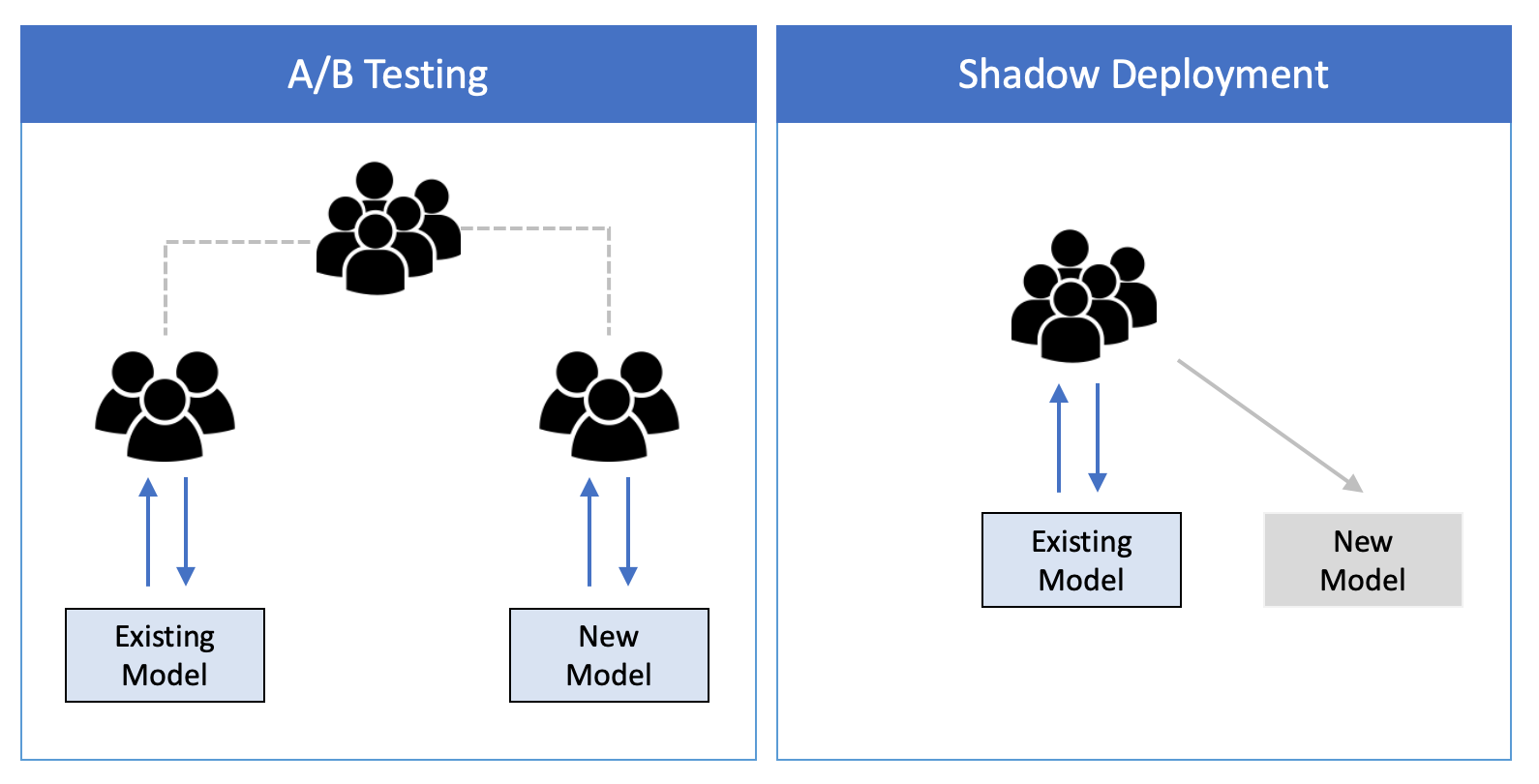
★
影子部署 (Shadow Deployment)
監控與驗證
將新模型與現有模型並行運行,接收相同的生產流量,但只有現有模型的預測被實際使用。新模型的預測結果被記錄下來用於離線比較和評估,驗證其在真實數據上的表現,風險最低。
#59
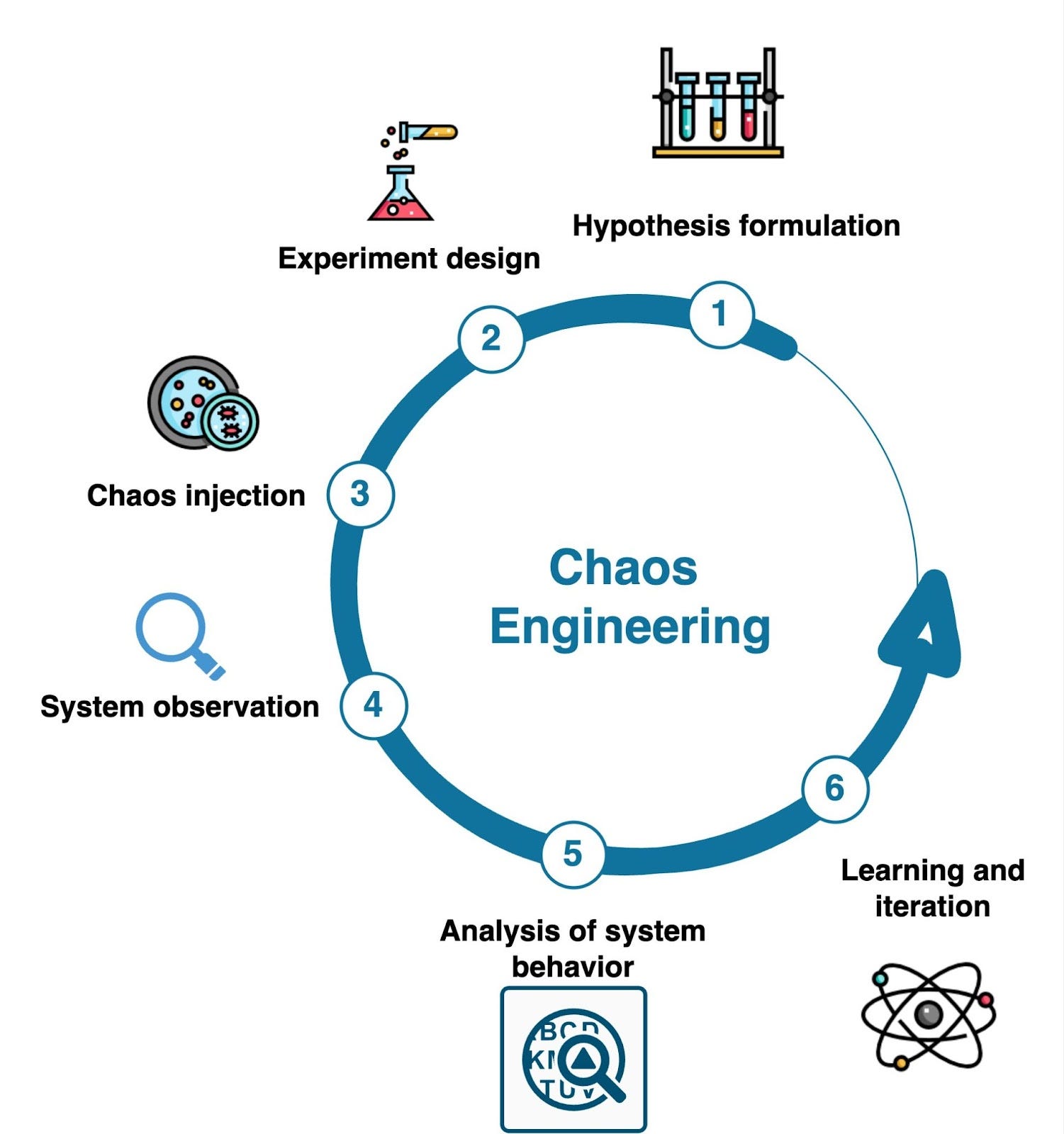
★
混沌工程 (Chaos Engineering)
穩定性測試
透過在生產環境中故意注入故障(如關閉服務實例、增加延遲)來測試系統的彈性和恢復能力,以建立對系統處理混亂情況能力的信心。
#60
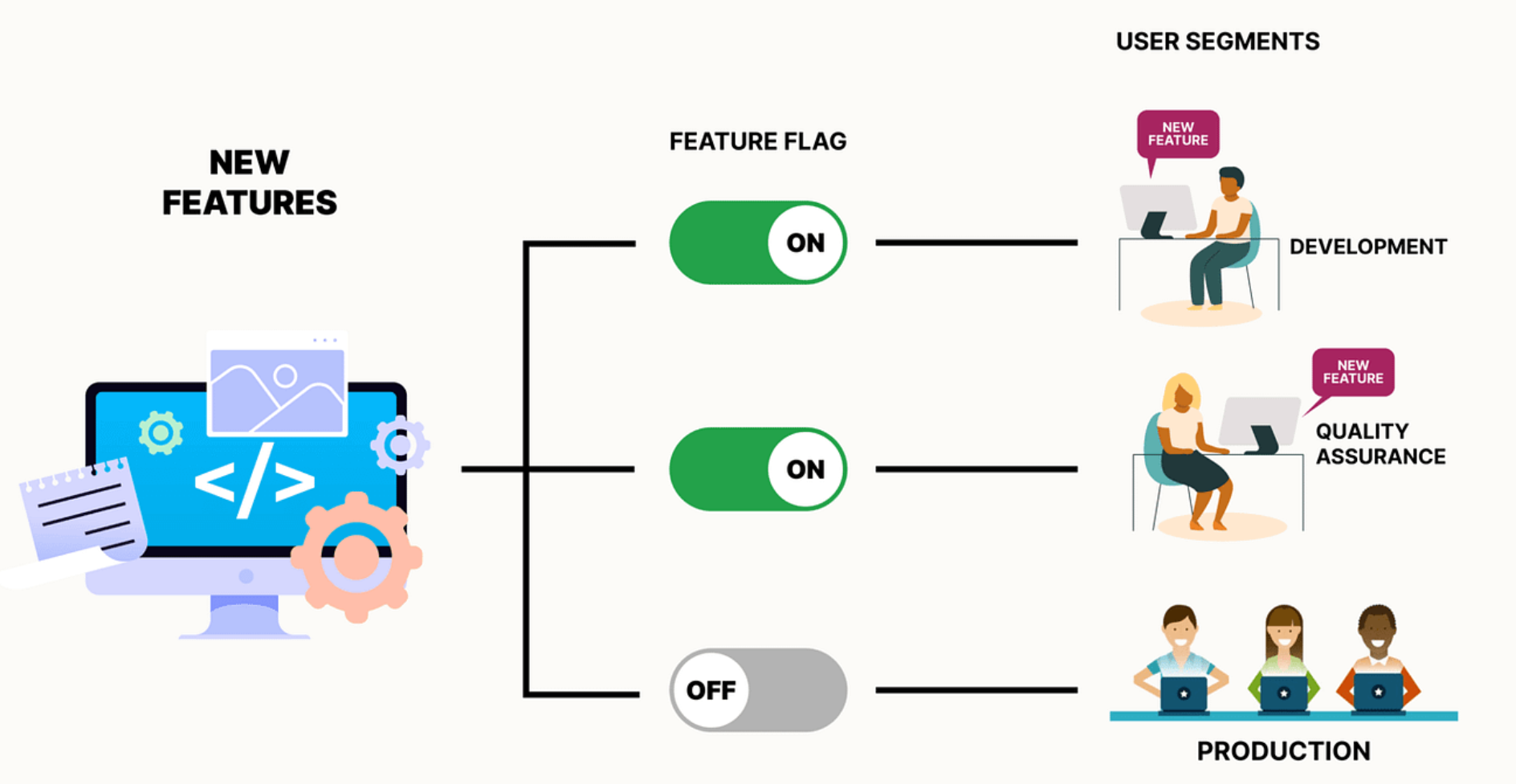
★
特性開關 (Feature Flags/Toggles)
部署控制
允許在運行時動態地啟用或禁用系統的某些特性(例如,切換使用新舊模型)。可用於控制金絲雀釋出、進行 A/B 測試或在出現問題時快速禁用新功能。
沒有找到符合條件的重點。
↑