iPAS AI應用規劃師 考試重點
L21203 AI風險管理
主題分類
1
風險管理基本概念
2
風險識別與分析
3
AI 特定風險 (技術、數據、模型)
4
AI 倫理風險
5
AI 安全與合規風險
6
風險評估與應對策略
7
AI 治理與負責任 AI
8
生成式 AI 風險管理
#1
★★★★★
風險管理 (Risk Management) - 定義與目的
核心概念 (K12)
風險管理是指識別、評估、並控制可能對組織目標(如 AI 專案成功)產生負面影響的不確定性事件(風險)的過程。其目的是將風險的發生機率和/或影響程度降至可接受的範圍內,以保護組織資產、確保目標達成。 (A06)
#2
★★★★
風險管理基本流程
主要步驟
一個典型的風險管理流程包括:
- 風險識別 (Identification): 找出潛在的風險事件。
- 風險分析 (Analysis): 評估風險發生的可能性和影響程度。
- 風險評估/排序 (Evaluation/Prioritization): 根據分析結果確定風險的優先級。
- 風險應對 (Response/Treatment): 制定並實施應對高優先級風險的策略。
- 風險監控與審查 (Monitoring & Review): 持續追蹤風險狀態和應對措施的有效性。
#3
★★★
風險的構成要素
基本屬性
風險通常涉及三個主要構成要素:事件本身(可能發生的不確定情況)、發生的可能性(機率或頻率)以及事件發生後的結果(影響或後果)。
#4
★★★
風險管理在 AI 專案中的重要性
必要性
AI 技術本身具有複雜性和不確定性,其應用可能帶來技術、數據、倫理、安全等多方面的新型風險。主動進行風險管理有助於提高 AI 專案成功率,避免潛在的負面後果,並建立利害關係人的信任。
#5
★★★★★
風險識別 (Risk Identification)
核心活動 (L21203)
系統性地找出可能影響 AI
專案目標的所有潛在風險。這是風險管理的基礎,目標是盡可能全面地列出風險清單。
#6
★★★★
風險識別的常用方法
技術手段
- 腦力激盪 (Brainstorming): 團隊成員自由發想可能的風險。
- 檢查表分析 (Checklist Analysis): 根據過往經驗或行業標準檢查表識別風險。
- 訪談 (Interviews): 與專家、利害關係人進行訪談。
- 根本原因分析 (Root Cause Analysis): 分析問題發生的深層原因。
- SWOT 分析: 分析專案的優劣勢、機會與威脅 (P1.3.1)。
- 假設分析 (Assumption Analysis): 檢視專案假設的有效性。
#7
★★★★
風險分析 (Risk Analysis)
風險評估基礎
對識別出的風險進行深入分析,主要評估兩個方面:
- 發生機率 (Likelihood / Probability): 風險發生的可能性,可以是定性描述(高、中、低)或定量估計(百分比)。
- 影響程度 (Impact / Consequence): 風險一旦發生,對專案目標(如成本、時程、品質、聲譽)造成的損害程度。
#8
★★★
定性 vs. 定量風險分析
分析方法
- 定性分析 (Qualitative Analysis): 使用描述性詞語(如高、中、低)或評分來評估風險的機率和影響,快速對風險進行排序。
- 定量分析 (Quantitative Analysis): 使用數值方法(如機率分佈、模擬)來估計風險的具體數值影響(如成本增加、時程延誤)。通常用於高優先級風險。
#9
★★★★
AI 技術風險
技術層面問題 (K12)
與 AI 技術本身相關的風險:
- 模型性能不足: 無法達到預期的準確率、召回率等指標。
- 泛化能力差: 模型在真實數據上表現不佳(過擬合)。
- 推論速度慢/延遲高: 無法滿足即時應用需求。
- 技術選擇錯誤: 選用的 AI 技術不適合解決目標問題。
- 技術過時風險: AI 技術發展迅速,當前方案可能很快被淘汰。
#10
★★★★★
AI 數據風險
數據層面問題 (K12, K13)
與數據相關的風險是 AI 專案中最常見的風險之一:
- 數據量不足: 無法有效訓練複雜模型。
- 數據品質差: 數據包含錯誤、缺失值、噪聲、不一致性。
- 數據標註錯誤或不一致: 影響監督式學習的效果。
- 數據代表性不足/偏差 (Data Bias): 訓練數據無法反映真實世界的數據分佈,導致模型偏見。
- 數據隱私風險: 訓練數據包含個人敏感資訊,處理不當可能洩露。
- 數據安全風險: 數據被未授權訪問、竊取或篡改。
- 數據來源合規性: 數據收集方式是否符合法規。
#11
★★★★★
AI 模型風險
模型固有問題 (K12)
與 AI 模型本身特性相關的風險:
- 模型偏見 (Model Bias): 模型學習到並放大了訓練數據中的偏見,產生不公平或歧視性結果。
- 模型漂移 (Model Drift): 部署後,由於真實數據分佈變化導致模型性能下降。
- 缺乏可解釋性/黑盒子問題 (Lack of Interpretability): 難以理解模型做出決策的原因。
- 模型脆弱性/對抗性攻擊風險 (Adversarial Attacks): 模型容易受到精心設計的微小干擾而產生錯誤輸出。
- 模型穩定性/穩健性不足: 模型對輸入的微小變化過於敏感。
#12
★★★
AI 營運與整合風險
部署與維護問題
- 與現有系統整合困難。
- 部署環境配置複雜。
- 模型監控和維護成本高。
- 使用者接受度低,不願使用新系統。
- 缺乏足夠的技術支援。
#13
★★★★★
AI 倫理風險 (AI Ethical Risks) - 核心議題
價值觀與影響 (K10, L21203)
AI
技術的應用可能引發或加劇的倫理問題,是風險管理中日益重要的部分。核心議題包括:
- 公平性與偏見 (Fairness & Bias): AI 系統是否對不同群體產生系統性的不公平對待或歧視 (Q30)。
- 透明度與可解釋性 (Transparency & Interpretability): AI 系統的決策過程是否可被理解和解釋。
- 問責制 (Accountability): 當 AI 系統出錯或造成損害時,由誰負責。
- 隱私 (Privacy): AI 對個人數據的收集和使用是否侵犯隱私權。
- 安全性與可靠性 (Safety & Reliability): AI 系統是否穩定可靠,不會造成意外傷害。
- 人類福祉與社會影響: AI 對就業、社會結構、人際關係的影響。
#14
★★★★★
演算法偏見 (Algorithmic Bias) 的來源
偏見成因 (K12)
演算法偏見可能源於多個環節:
- 數據偏見: 訓練數據本身就存在偏見或代表性不足(最常見來源)。
- 演算法設計偏見: 演算法本身的設計或目標函數可能隱含了某些價值取向。
- 交互偏見: 用戶與 AI 系統的互動可能反過來強化系統的偏見(如推薦系統)。
- 評估偏見: 用於評估模型性能的指標或數據集本身可能存在偏見。
#15
★★★★
識別與減緩偏見的方法
公平性措施
- 數據層面: 收集更多元、更具代表性的數據;對數據進行重採樣或重加權。
- 演算法層面: 設計對偏見不敏感的演算法;在訓練過程中加入公平性約束。
- 後處理層面: 對模型輸出結果進行調整,以滿足公平性要求。
- 評估與審計: 使用公平性指標(如 Demographic Parity, Equal Opportunity)定期評估模型,並進行人工審查。
#16
★★★
AI 透明度與可解釋性的重要性
理解決策 (K10)
透明度指了解 AI
系統的設計、數據和運作方式。可解釋性指能夠向人類解釋模型為何做出特定決策。對於建立信任、偵錯、確保公平性、滿足法規要求都至關重要,特別是在金融、醫療等領域。
#17
★★★★
AI 安全風險 (AI Security Risks)
威脅類型 (K13)
針對 AI 系統的特定安全威脅:
- 對抗性攻擊 (Adversarial Attacks): 對輸入數據進行微小擾動,使模型產生錯誤輸出。
- 數據中毒 (Data Poisoning): 在訓練數據中注入惡意樣本,影響模型訓練。
- 模型竊取 (Model Stealing): 通過查詢接口逆向工程或複製模型。
- 成員推斷攻擊 (Membership Inference): 判斷某個特定數據點是否被用於訓練模型,可能洩露隱私。
- 傳統資訊安全風險: 如系統漏洞、未授權訪問、數據洩露等。
#18
★★★★
資訊安全 (Information Security) 在 AI 中的應用
基礎防護 (K13)
傳統的資訊安全原則和措施對保護 AI 系統同樣重要,包括:
- 存取控制 (Access Control): 限制對數據和模型的訪問權限 (Q28)。
- 數據加密 (Data Encryption): 保護儲存和傳輸中的數據。
- 安全審計與日誌 (Security Auditing & Logging): 記錄系統活動,便於追溯和調查。
- 漏洞管理 (Vulnerability Management): 定期掃描和修補系統漏洞。
#19
★★★★★
法規遵循/合規性 (Regulatory Compliance)
遵守規範 (K12, Q28)
確保 AI 系統的開發和使用符合相關的法律、法規和標準。關鍵領域包括:
- 數據隱私法規: 如歐盟的 GDPR (General Data Protection Regulation)、加州的 CCPA (California Consumer Privacy Act)、台灣的個人資料保護法。
- 反歧視法規: 確保 AI 決策不產生歧視。
- 特定行業法規: 如金融業的公平借貸法、醫療業的 HIPAA (Health Insurance Portability and Accountability Act)。
- 新興的 AI 專門法規: 如歐盟的 AI Act 草案。
#20
★★★
隱私增強技術 (PET - Privacy-Enhancing
Technology)
隱私保護方法
用於在處理數據時保護個人隱私的技術,例如:
- 差分隱私 (Differential Privacy): 在數據分析結果中添加噪聲,使得無法從結果中推斷出單個個體的資訊。
- 聯邦學習 (Federated Learning): 在不共享原始數據的情況下,讓多方協同訓練模型。
- 同態加密 (Homomorphic Encryption): 允許在加密數據上直接進行計算。
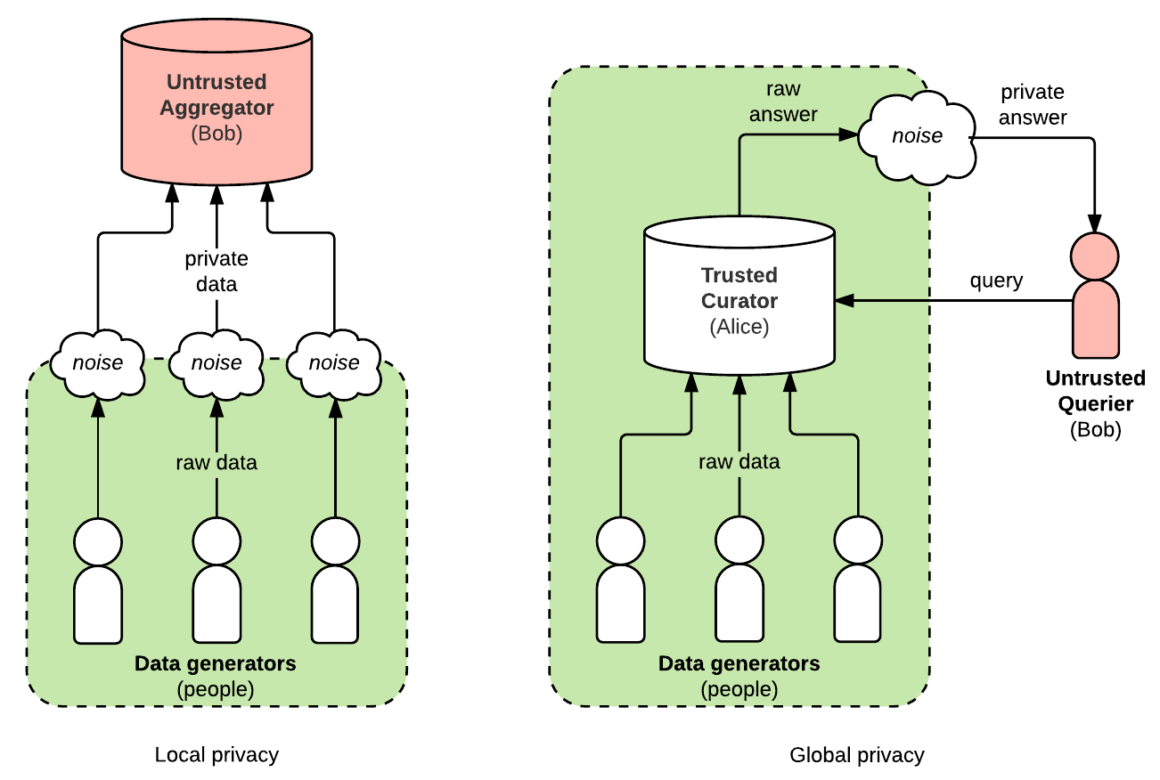

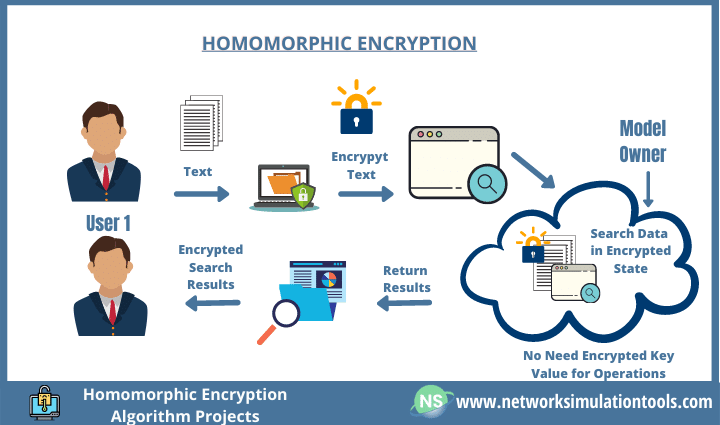
#21
★★★★
風險評估 (Risk Assessment) 與風險排序
優先級判斷
結合風險分析的結果(機率和影響),對風險進行評估和排序,以確定哪些風險需要優先處理。常用的工具是風險矩陣 (Risk Matrix)
或風險熱力圖 (Heat
Map),將風險劃分到不同的優先級區域(如高、中、低)。
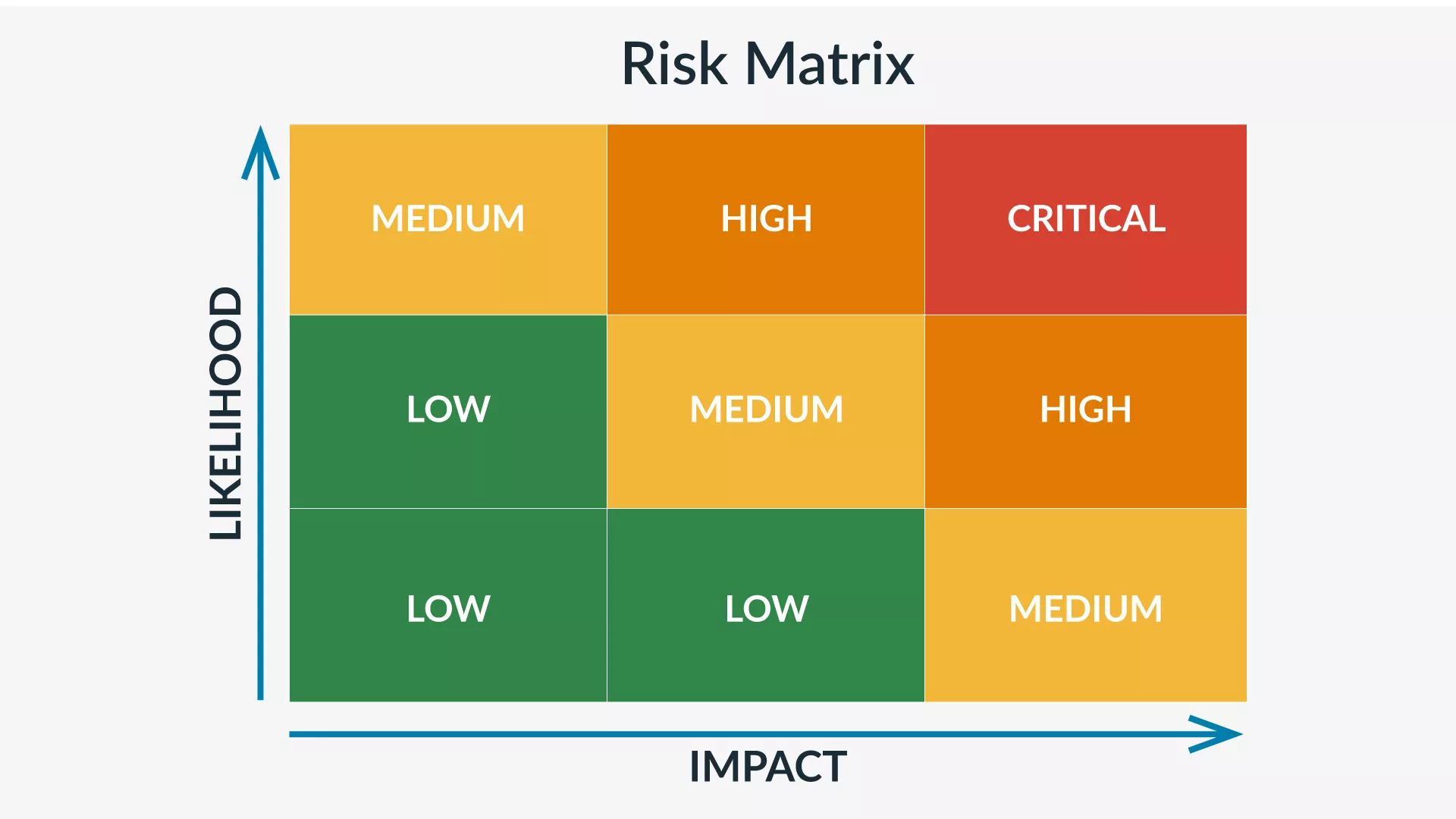
#22
★★★★★
風險應對策略 (Risk Response Strategies)
處理選項 (S07, Q29)
針對評估後的風險,可以選擇以下幾種主要應對策略:
- 風險規避 (Avoidance): 改變計畫、流程或目標,完全消除風險來源。例如,決定不使用某項不成熟的技術。
- 風險轉移 (Transfer / Sharing): 將風險或其影響轉移給第三方。例如,購買保險、將特定任務外包 (Q29)。
- 風險減緩/緩解 (Mitigation / Reduction): 採取措施降低風險發生的機率或減輕其影響程度。這是最常用的策略,例如加強測試、數據驗證、增加安全措施。
- 風險接受 (Acceptance): 對於低優先級風險,或應對成本過高的風險,決定不採取額外措施,接受其可能帶來的後果,但通常需要建立應急計畫。
#23
★★★★
制定風險管理計畫 (Risk Management Plan)
文件化規劃
將風險管理的流程、方法、工具、角色職責、預算、時程以及具體的風險應對措施文件化。風險管理計畫是指導整個專案風險管理活動的藍圖。
#24
★★★
風險監控與審查 (Risk Monitoring & Review)
持續追蹤
風險管理是一個持續的過程。需要定期監控已識別風險的狀態、評估應對措施的有效性、識別新出現的風險,並根據需要調整風險管理計畫。
#25
★★★
風險登錄表 (Risk Register)
記錄工具
用於集中記錄和追蹤所有已識別風險的工具。通常包含風險描述、類別、原因、潛在影響、發生機率、影響程度、風險評分、應對措施、負責人、狀態等資訊。
#26
★★★★★
AI 治理 (AI Governance)
框架與機制 (K10, L11102)
AI 治理是指建立一套組織層面的框架、政策、流程和控制機制,以指導 AI 技術的開發、部署和應用,確保其符合法律法規、倫理原則、組織目標和社會價值觀。目標是最大化 AI 的效益,同時最小化其潛在風險。
#27
★★★★
AI 治理的核心要素
組成部分
- 策略與原則: 明確組織使用 AI 的願景、目標和倫理原則。
- 組織架構與職責: 設立 AI 治理委員會或指定負責人。
- 政策與標準: 制定數據使用、模型開發、風險管理、安全合規等方面的政策。
- 流程與控制: 建立模型審查、風險評估、變更管理等流程。
- 工具與技術: 採用模型監控、可解釋性、公平性檢測等工具。
- 人員與培訓: 提升員工對 AI 倫理和風險的意識與能力。
#28
★★★★★
負責任 AI (RAI - Responsible
AI)
核心理念 (L21203, K10)
負責任 AI 是一種開發和部署 AI 系統的方法論和理念,旨在確保 AI 以安全、合乎倫理和值得信賴的方式運行。它強調將倫理原則融入 AI 生命週期的各個階段。
#29
★★★★★
負責任 AI 的核心原則
指導方針
各組織提出的 RAI 原則略有不同,但通常包含以下核心要素:
- 公平性 (Fairness): 避免不公平的偏見和歧視。
- 可靠性與安全性 (Reliability & Safety): 系統應穩定運行並避免造成傷害。
- 隱私與安全 (Privacy & Security): 保護數據隱私和系統安全。
- 包容性 (Inclusiveness): 服務於不同人群,賦能所有人。
- 透明度 (Transparency): AI 系統的運作方式應可被理解。
- 問責制 (Accountability): 明確系統開發者和部署者的責任。
#30
★★★
國內外 AI 治理相關指引/法規
參考依據 (L11102 備註)
了解國內外重要的 AI 治理指引或法規草案,有助於制定合規的風險管理策略。例如:
- OECD AI Principles
- 歐盟 AI Act (草案)
- 美國 NIST AI Risk Management Framework
- 台灣國科會 AI 科學發展策略、數位發展部《公部門人工智慧應用參考手冊》、金管會《金融業運用人工智慧(AI)指引》
#31
★★★★
生成式 AI (GenAI) 特定風險
獨有挑戰 (L12303)
除了通用 AI 風險,GenAI 還帶來一些獨特的風險:
- 幻覺 (Hallucination): 產生錯誤或捏造的資訊。
- 內容偏見與有害內容: 生成帶有偏見、歧視、仇恨或不當的內容 (Q30)。
- 智慧財產權/版權侵權: 生成的內容可能侵犯現有作品的版權。
- 深度偽造 (Deepfake) 與濫用: 被用於製造假訊息、詐騙等惡意用途。
- 提示注入攻擊 (Prompt Injection): 通過惡意設計的提示,操縱模型產生非預期或有害的輸出。
- 數據洩露風險增加: 模型可能無意中洩露訓練數據中的敏感資訊。
#32
★★★★
管理幻覺風險的方法
應對策略
- 檢索增強生成 (RAG): 讓模型參考外部知識庫,提高回答的事實準確性。
- 提示工程: 設計引導性提示,要求模型基於提供的上下文回答,或指出知識的局限性。
- 事實核查 (Fact-Checking): 對模型生成的關鍵資訊進行人工或自動化核查。
- 模型微調: 使用高質量、事實準確的數據對模型進行微調。
- 設定溫度參數: 較低的溫度參數通常會使輸出更具確定性和一致性,減少隨機性。
#33
★★★
管理 GenAI 有害內容風險
內容過濾
部署內容過濾器或審核機制,用於檢測和攔截模型生成的不當、有害或違反政策的內容。這可以在模型輸入(提示)或輸出(生成結果)階段進行。
#34
★★★
GenAI 版權風險的應對
智慧財產權考量
- 謹慎使用訓練數據: 了解訓練數據的來源和版權狀況。
- 檢查生成內容: 評估生成的內容是否與現有受版權保護作品過於相似。
- 遵守平台使用條款: 了解所使用的 GenAI 平台關於內容所有權和使用的規定。
- 尋求法律建議: 在商業應用中,如有疑慮應諮詢法律專家。
#35
★★★
防範提示注入 (Prompt Injection)
輸入安全
採取措施防止惡意用戶通過特殊設計的提示來操縱或攻擊模型。方法包括輸入過濾、指令隔離、限制模型能力、監控異常輸出等。
#36
★★
風險偏好 (Risk Appetite)
風險承受度
組織願意接受的風險類型和程度。在制定風險管理策略時,需要了解組織的風險偏好,以決定應對措施的力度。
#37
★★
風險擁有者 (Risk Owner)
責任分配
為每個識別出的風險指定一個負責人(風險擁有者),負責監控風險狀態、實施應對措施並匯報進展。
#38
★★
模型可重現性 (Reproducibility) 風險
一致性問題
由於隨機性、環境依賴性等因素,可能難以完全重現模型的訓練過程或預測結果。這對除錯、驗證和法規審查構成挑戰。需加強版本控制和環境記錄。
#39
★★★
AI 倫理委員會/審查機制
治理實踐
建立內部的倫理委員會或審查流程,用於評估高風險
AI 應用的倫理影響,提供指導建議,並監督倫理原則的落實。
#40
★★★
數據最小化原則 (Data Minimization)
隱私保護
在收集和處理數據時,只收集和保留與 AI
應用直接相關且必要的最小量數據,以降低隱私洩露風險。
#41
★★
殘餘風險 (Residual Risk)
應對後剩餘
在採取風險應對措施後仍然存在的風險。需要評估殘餘風險是否在可接受範圍內。
#42
★★
模型卡 (Model Cards)
透明度工具
提供關於 AI
模型簡明資訊的文件,內容通常包括模型的用途、性能指標、訓練數據、局限性、倫理考量等,旨在提高模型的透明度。
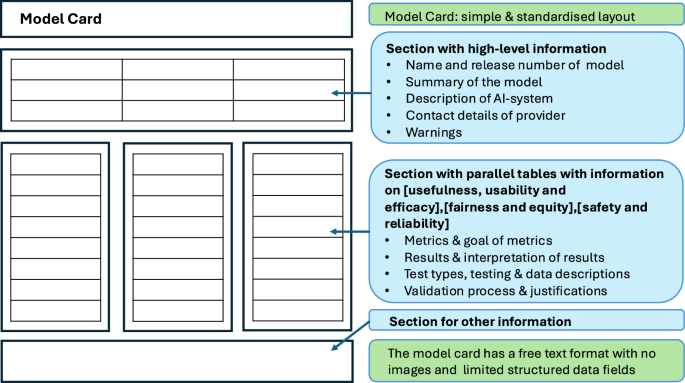
#43
★★
GenAI 內容真實性 (Authenticity) 標示
來源透明
為了應對 Deepfake 和假訊息風險,研究和推廣標示
AI 生成內容的技術和標準(如數位浮水印),讓用戶能區分真實內容和 AI 生成內容。
#44
★★
風險 vs. 問題 (Issue)
概念區分
風險是未來可能發生的不確定事件,而問題是當前已經發生的狀況。風險管理側重於預防和應對未來,而問題管理側重於解決當前。
#45
★★
風險分析中的敏感度分析
變數影響
評估輸入變數或假設條件的變化對風險評估結果(如機率、影響)的影響程度。有助於識別哪些因素對風險最敏感,需要重點關注。
#46
★★
AI 供應鏈風險
外部依賴風險
依賴第三方提供的 AI 模型、工具、平台或數據可能引入供應鏈風險,例如供應商服務中斷、安全漏洞、技術鎖定、數據隱私問題等。需要對供應商進行盡職調查和風險評估。
#47
★★
AI 倫理影響評估 (Ethical Impact Assessment)
主動評估
在 AI
系統開發或部署前,系統性地評估其可能產生的倫理影響,識別潛在的倫理風險,並制定相應的緩解措施。
#48
★★★
安全開發生命週期 (SDL) 的整合
安全融入開發
將安全性考量整合到 AI
系統開發的整個生命週期中,從需求分析、設計、編碼、測試到部署和維護,早期發現並修復安全漏洞。
#49
★★★
風險應對措施的有效性評估
效果驗證
不僅要制定風險應對措施,還需要規劃如何評估這些措施是否有效。例如,實施安全措施後,是否降低了攻擊成功率?進行去偏見處理後,公平性指標是否改善?
#50
★★★
AI 稽核 (AI Auditing)
獨立驗證
由內部或第三方獨立機構對 AI
系統的開發過程、性能、安全性、公平性、合規性等進行審查和評估,以確保其符合標準和要求,並提供客觀的驗證。
#51
★★
GenAI 風險與模型規模的關係
規模效應
通常模型規模越大(參數越多、訓練數據越多),其能力越強,但也可能放大某些風險,例如更容易記憶訓練數據中的隱私資訊、產生更難以預測的幻覺、或被濫用的潛力更大。
#52
★
風險態度 (Risk Attitude)
主觀因素
組織或個人對待風險的主觀傾向,可能影響風險評估和應對策略的選擇。可分為風險趨避、風險中立、風險愛好等。
#53
★
黑天鵝事件 (Black Swan Event)
極端風險
指發生機率極低但一旦發生影響極其巨大的事件。傳統風險管理方法可能難以預測和應對黑天鵝事件,需要更強調組織的韌性 (Resilience)。
#54
★★
AI 倫理風險的社會文化差異
情境依賴
對於公平、隱私等倫理概念的界定可能因不同的社會文化背景而異。在跨國部署 AI
系統時,需要考慮這些差異,避免將單一的倫理標準強加於所有情境。
#55
★★
合規科技 (RegTech) 的應用
自動化合規
利用科技(包括 AI)來自動化和簡化合規流程,例如自動監控交易以發現洗錢行為、自動檢查 AI 模型是否符合公平性要求等。
#56
★★
風險溝通 (Risk Communication)
資訊傳遞
有效地向利害關係人傳達關於風險的資訊(性質、可能性、影響、應對措施等),建立共同理解和信任,是風險管理成功的重要一環。
#57
★★
AI 影響評估 (AI Impact Assessment)
全面評估
一種更廣泛的評估方法,不僅考慮倫理風險,還評估 AI 系統可能對個人、社會、環境產生的各種正面和負面影響。
#58
★
GenAI 的環境影響風險
碳足跡
訓練大型生成模型需要消耗大量電力,產生顯著的碳足跡,引發對其環境可持續性的擔憂。
#59
★
技術債 (Technical Debt) 風險
長期維護成本
為了快速開發或應急,可能在 AI 系統設計或實施中採取了非最優的方案,導致未來需要花費更多成本來重構或維護,這就是技術債。
#60
★
AI 風險管理的標準化
行業發展
隨著 AI 應用的普及,國際和行業組織(如 ISO, IEEE)正在制定 AI 風險管理、倫理、安全等方面的標準,以提供更統一的指導和最佳實踐。
沒有找到符合條件的重點。
↑