iPAS AI應用規劃師 考試重點
L21104 多模態人工智慧應用
主題分類
1
多模態 AI 基本概念
2
常見模態與挑戰
3
多模態融合技術
4
多模態表徵學習
5
跨模態生成與轉換
6
常見多模態模型
7
多模態 AI 應用場景
8
多模態 AI 挑戰與未來
#1
★★★★★
多模態人工智慧 (Multimodal AI) - 基本定義
核心概念
多模態 AI 是指能夠同時處理和理解來自多種不同類型或來源的數據(模態)的人工智慧系統。目標是讓 AI 能夠像人類一樣,整合多種感官訊息,以更全面、深入地理解世界或完成複雜任務。
#2
★★★★★
常見模態 (Modality)
數據類型 (L21104 備註)
多模態 AI 處理的常見數據類型包括:
- 文本 (Text): 書面語言、文章、對話紀錄。
- 圖像 (Image): 靜態圖片、照片。
- 聲音/音訊 (Audio/Sound): 語音、音樂、環境聲音。
- 影片 (Video): 連續的圖像幀,通常包含視覺和聽覺訊息。
- 感測器數據 (Sensor Data): 如 LiDAR(光達)、IMU(慣性測量單元)、溫度、壓力等。
- 表格/結構化數據 (Tabular/Structured Data): 資料庫中的數據。
- 圖譜數據 (Graph Data): 如社交網路、知識圖譜。
#3
★★★★
多模態 AI 的核心挑戰
主要難點
處理多模態數據面臨獨特挑戰:
- 異質性 (Heterogeneity): 不同模態數據的結構、維度和統計特性差異很大。
- 對齊 (Alignment): 如何將不同模態數據中相關的部分對應起來(例如,影片中的聲音和畫面)。
- 融合 (Fusion): 如何有效地結合來自不同模態的資訊,以提高整體性能。
- 表徵學習 (Representation Learning): 如何學習能夠捕捉各模態資訊及其交互關係的有效表示。
- 協同學習/轉換 (Co-learning/Translation): 如何利用一種模態的資訊來輔助另一種模態的學習,或在不同模態間進行轉換。
#4
★★★★★
多模態融合 (Multimodal Fusion) - 策略分類
主要方法
根據融合發生的階段,可分為:
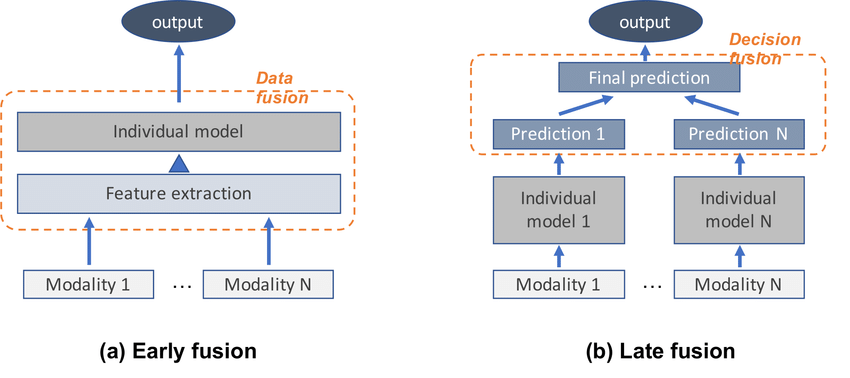
- 早期融合 (Early Fusion / Feature-level Fusion): 在輸入層或早期特徵層次將不同模態的特徵直接拼接或組合。優點是能捕捉模態間的低層次關聯,缺點是要求數據對齊且可能維度過高。
- 晚期融合 (Late Fusion / Decision-level Fusion): 先對每個模態單獨進行處理和預測,然後在決策層面(如預測分數或結果)進行整合(例如投票、加權平均)。優點是簡單靈活,對數據異質性容忍度高,缺點是可能忽略模態間的早期交互。
- 混合融合 (Hybrid Fusion): 結合早期和晚期融合的策略,或在模型的中間層次進行融合。試圖平衡兩者的優缺點。
#5
★★★★
融合技術示例
具體方法
實現融合的具體技術包括:
- 拼接 (Concatenation): 最簡單的早期融合,將不同模態的特徵向量直接連在一起。
- 加權求和/平均 (Weighted Sum/Average): 常用於晚期融合,根據各模態預測的可信度賦予權重。
- 張量融合 (Tensor Fusion): 使用張量運算(如外積)來捕捉模態間的高階交互關係。
- 基於注意力機制的融合 (Attention-based Fusion): 利用注意力機制動態地學習不同模態或特徵的重要性,進行加權融合。
#6
★★★★
多模態表徵學習 (Multimodal Representation Learning)
核心目標
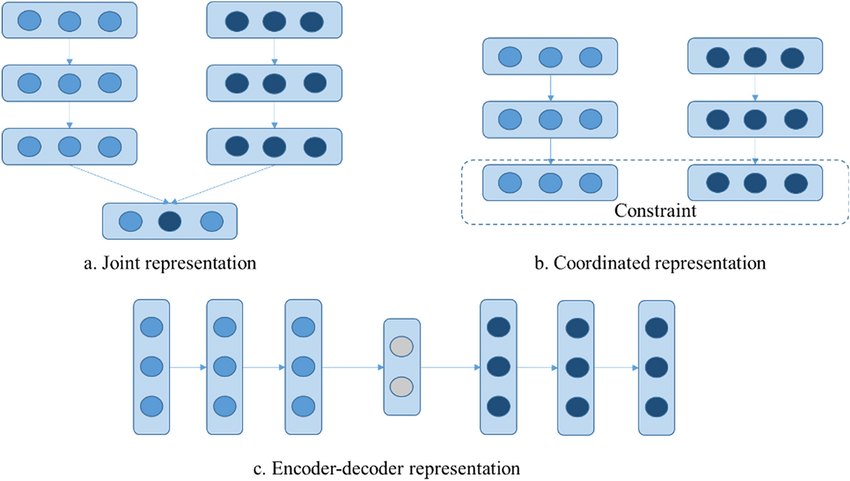
目標是學習能夠有效表示來自不同模態數據的向量表示(嵌入, Embedding),這些表示應能捕捉單一模態的資訊以及模態之間的關聯性。主要有兩種類型:
- 聯合表徵 (Joint Representation): 將所有模態的資訊映射到同一個共享的潛在空間中。
- 協同表徵 (Coordinated Representation): 為每個模態學習獨立的表示空間,但這些空間之間具有某種約束或關聯(例如,相似的語意在不同空間中距離相近)。
#7
★★★
聯合表徵學習方法示例
Joint Representation
常用於需要融合多模態資訊進行預測的任務,例如情感分析(結合文本和語音)。模型(如某些融合模型)會將不同模態的特徵在某個階段結合,最終輸出一個聯合的表示。
#8
★★★★
協同表徵學習方法示例 - CLIP
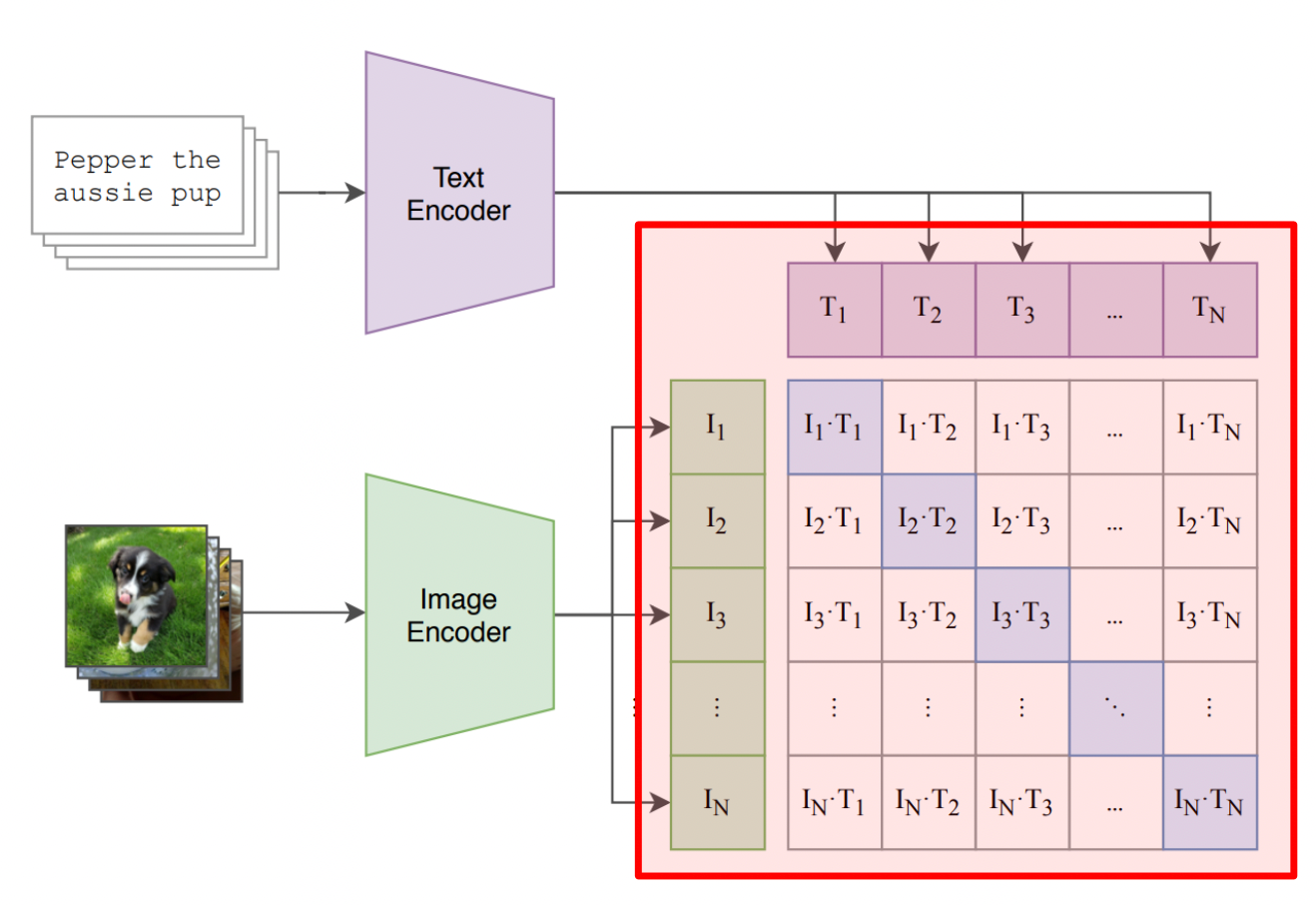
Coordinated Representation
常用於跨模態檢索或匹配任務。CLIP (Contrastive Language–Image Pre-training) 模型是一個代表。它分別學習圖像和文本的編碼器,使得匹配的(圖像,文本)對在嵌入空間中的相似度高,而不匹配的對相似度低。這種對比學習方法使得 CLIP 在零樣本圖像分類等任務上表現出色。
#9
★★★★
跨模態生成/轉換 (Cross-modal Generation/Translation)
核心任務
這類任務的目標是根據一種模態的輸入生成另一種模態的輸出。常見示例包括:
- 圖像描述生成 (Image Captioning): 輸入圖像,生成描述圖像內容的文本。
- 文本到圖像生成 (Text-to-Image Generation): 輸入文本描述,生成對應的圖像。
- 語音合成 (Speech Synthesis / TTS): 輸入文本,生成對應的語音。
- 視覺到語音 (Visual-to-Speech): 輸入圖像或影片,生成描述內容的語音。
#10
★★★
跨模態檢索 (Cross-modal Retrieval)
核心任務
目標是使用一種模態的查詢來檢索另一種模態的相關數據。例如:
- 以文找圖: 輸入文本描述,檢索相關的圖像。
- 以圖找文: 輸入圖像,檢索描述該圖像的文本。
- 以音找視: 輸入聲音片段,檢索相關的影片片段。
#11
★★★★
視覺語言模型 (VLM - Vision-Language Model)
重要模型架構
VLM 是專門設計用於處理和關聯視覺(圖像/影片)和語言(文本)訊息的模型。它們通常包含:
- 視覺編碼器 (Vision Encoder): 如 CNN 或 ViT,用於提取圖像特徵。
- 語言編碼器/解碼器 (Language Encoder/Decoder): 如 Transformer,用於處理文本。
- 融合機制 (Fusion Mechanism): 用於結合視覺和語言特徵,如交叉注意力 (Cross-Attention)。
#12
★★★
音訊-視覺模型 (Audio-Visual Model)
模型架構類型
這類模型同時處理聽覺和視覺訊息,通常應用於影片分析任務。例如:
- 音訊-視覺語音辨識 (Audio-Visual Speech Recognition): 結合說話者的唇部運動(視覺)和語音信號(聽覺)來提高語音辨識的準確性,尤其在嘈雜環境中。
- 聲音定位 (Sound Localization): 根據聲音確定聲源在影片畫面中的位置。
- 事件檢測 (Event Detection): 結合視覺和聽覺線索檢測影片中的特定事件。
#13
★★★★
視覺問答 (VQA - Visual Question Answering)
經典應用場景
VQA 任務要求模型根據輸入的圖像和關於圖像的自然語言問題,生成相應的答案。這需要模型同時理解圖像內容和問題語意,並進行推理。
#14
★★★★
圖像描述生成 (Image Captioning)
經典應用場景
該任務要求模型為輸入的圖像自動生成一段自然語言描述。模型需要識別圖像中的物件、屬性和它們之間的關係,並用流暢的語句表達出來。
#15
★★★
多模態情感分析 (Multimodal Sentiment Analysis)
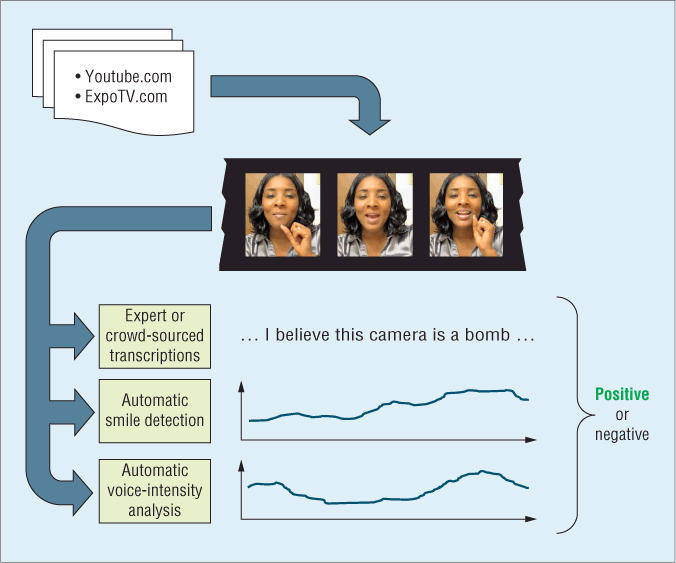
應用場景
結合來自不同模態(如文本、語音語調、面部表情)的資訊來判斷說話者或內容的情感傾向(正面、負面、中性)或具體情緒(喜、怒、哀、樂)。相比單模態,多模態可以提供更豐富、更準確的情感線索。
#16
★★★
跨模態人機互動 (Cross-modal Human-Computer Interaction)
應用場景
利用多模態技術創造更自然、更直觀的人機互動方式。例如,用戶可以通過語音和手勢同時與系統交互,或者系統可以根據用戶的視覺和聽覺線索來理解其意圖。
#17
★★★
挑戰:數據稀疏性與不平衡
多模態數據挑戰
獲取大規模、高質量且良好對齊的多模態數據集通常比單模態數據集更困難。某些模態的數據可能比其他模態更稀疏,或者某些模態組合的數據很少,這給模型訓練帶來了挑戰。
#18
★★
挑戰:模型複雜度與效率
模型部署挑戰
處理和融合多種模態通常需要更複雜的模型架構和更大的計算量,這對模型的訓練和實時部署提出了更高的要求。
#19
★★★
未來趨勢:更精細的模態交互理解
發展方向
未來的研究將更側重於深入理解不同模態之間複雜的交互關係,而不僅僅是簡單的融合。例如,理解語言如何影響視覺注意,或者視覺線索如何調節語音情感的感知。
#20
★★
未來趨勢:自監督多模態預訓練
發展方向
利用大規模未標註的多模態數據(如網路上的圖文、影音資料)進行自監督學習,以訓練通用的多模態基礎模型,然後再針對下游任務進行微調,從而減少對昂貴標註數據的依賴。
#21
★★★
多模態 AI 的優勢
核心價值
相比單模態 AI,多模態 AI 的主要優勢在於:
- 更全面的理解: 整合多源資訊,提供更豐富、互補的線索。
- 更高的穩健性: 當某一模態數據缺失或受干擾時,其他模態仍可提供資訊。
- 處理更複雜的任務: 能夠處理需要多種感知能力協同的任務(如 VQA)。
- 更自然的交互: 支援更接近人類自然交流方式的多模態輸入輸出。
沒有找到符合條件的重點。
↑