iPAS AI應用規劃師 經典題庫
L21103 生成式AI技術與應用
出題方向
1
生成式AI基本概念與原理
2
常見生成式模型架構
3
Transformer與大型語言模型
4
文本生成技術與應用
5
圖像/視覺生成技術與應用
6
其他模態生成 (音訊/影片/程式碼等)
7
提示工程與模型微調
8
生成式AI的倫理、風險與未來
#1
★★★★★
生成式人工智慧(Generative AI)最主要的目標是?
答案解析
生成式AI的核心能力在於「生成」。它透過學習大量現有數據(如文字、圖像、音樂)的潛在模式和分佈,然後利用這些學習到的知識來創造出全新的、與原始數據相似但不完全相同的新內容。選項A、B、D描述的是判別式AI(Discriminative AI)或其他機器學習任務的主要目標,它們側重於理解和區分現有數據,而非創造新數據。
#2
★★★★★
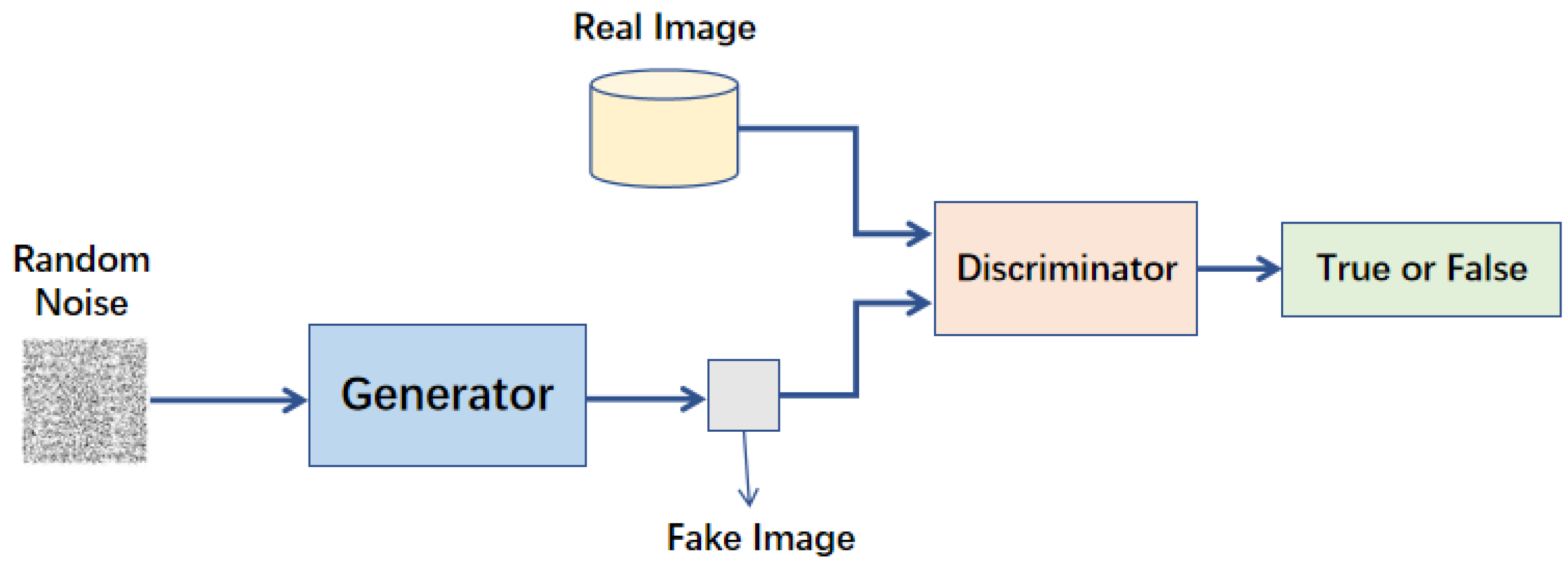
生成對抗網路(Generative Adversarial Network, GAN)是由哪兩個主要部分組成的?
答案解析
GAN是生成式AI中一種重要的模型架構。它包含兩個相互競爭的神經網路:生成器負責從隨機雜訊中生成「假」數據,試圖模仿真實數據;判別器則負責判斷輸入的數據是「真」(來自真實數據集)還是「假」(由生成器生成)。兩者透過對抗訓練,生成器努力生成更逼真的數據來欺騙判別器,而判別器則努力提高辨別真偽的能力,最終促使生成器產生高品質的生成內容。選項A是自編碼器(Autoencoder)或VAE的組成。選項C是強化學習的概念。選項D是Transformer中注意力機制的組成部分。
#3
★★★★
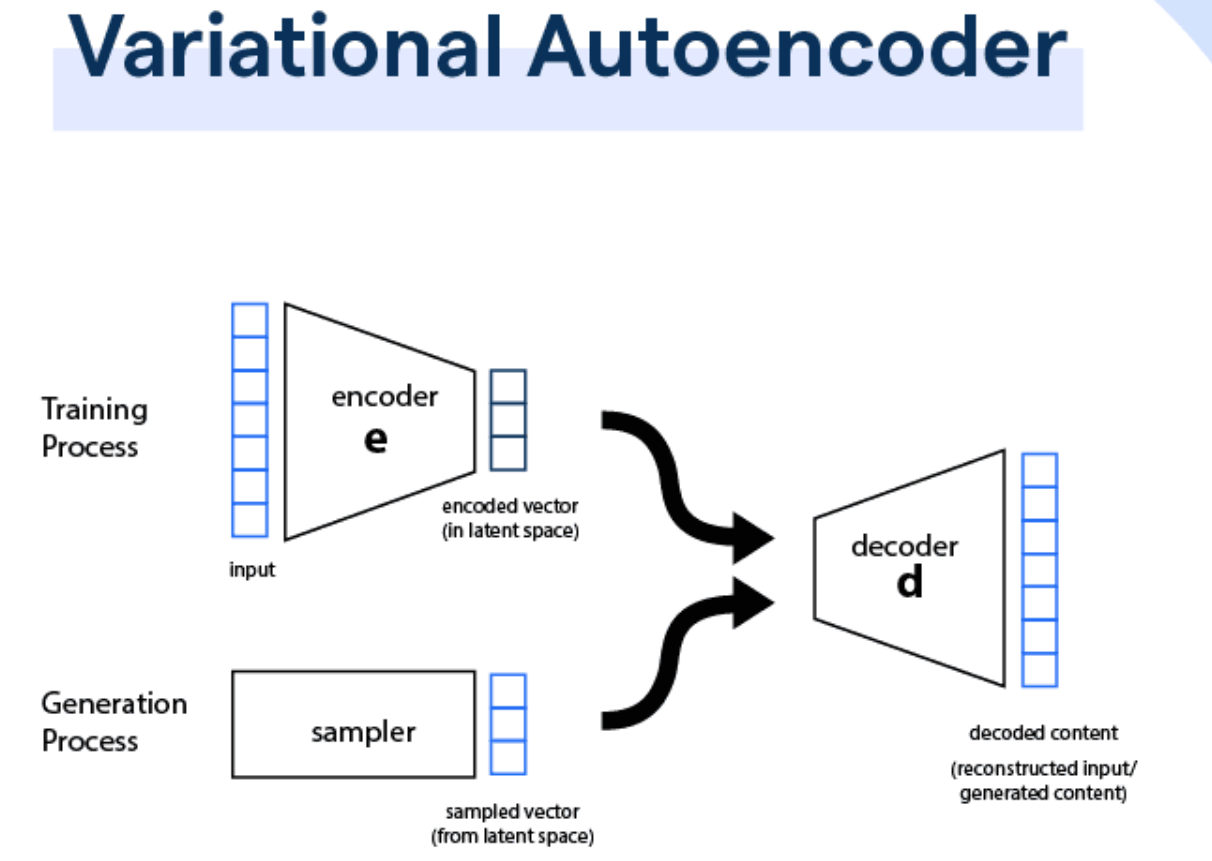
變分自編碼器(Variational Autoencoder, VAE)的主要優勢之一是能夠生成具有什麼特性的潛在空間(Latent Space)?
答案解析
VAE是一種生成模型,它透過編碼器將輸入數據映射到一個潛在空間分佈(通常是高斯分佈),然後從該分佈中採樣一個潛在向量,再由解碼器生成新的數據。VAE的一個關鍵特性是它學習到的潛在空間是連續且平滑的。這意味著在潛在空間中相近的點,其解碼後生成的數據也相似。這使得我們可以在潛在空間中進行插值(Interpolation),從而生成介於兩個已知數據之間的新數據,實現平滑的內容過渡。
#4
★★★★
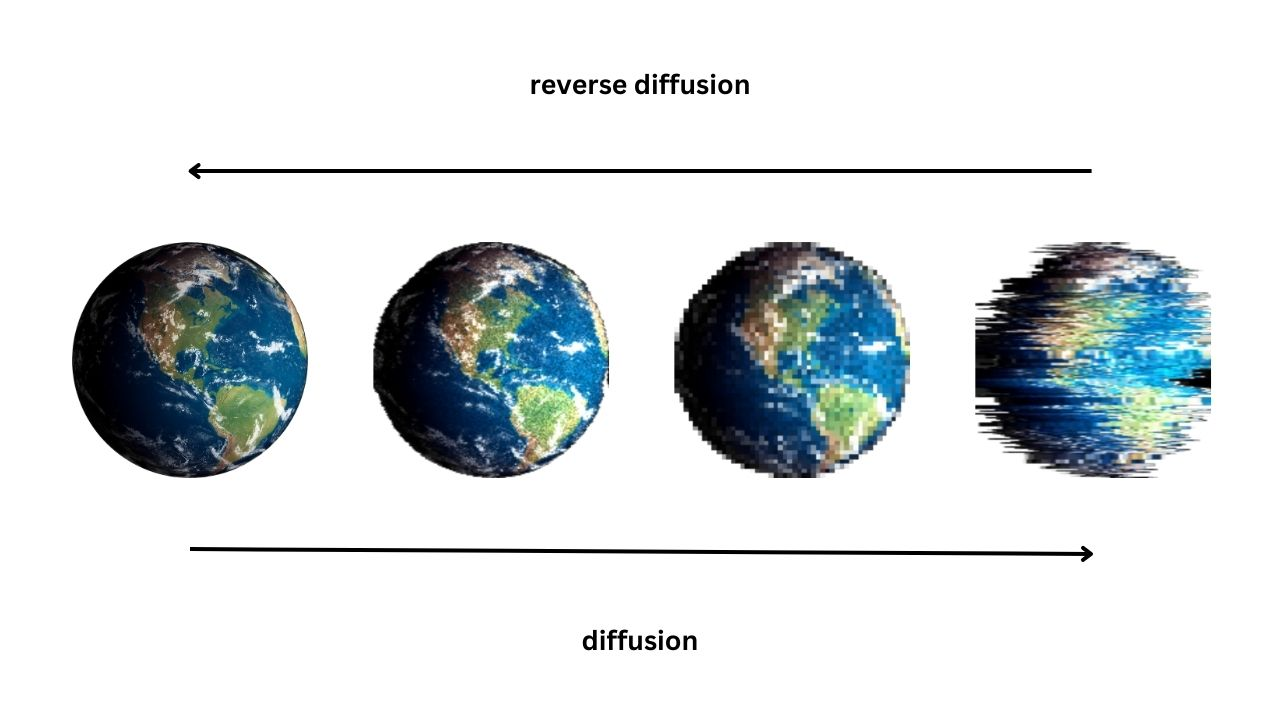
擴散模型(Diffusion Models)生成數據的基本原理涉及哪個過程?
答案解析
擴散模型是近年來非常成功的生成模型,尤其在圖像生成領域。其核心思想包含兩個過程:前向過程(Forward Process)和反向過程(Reverse Process)。前向過程逐步向真實數據中添加高斯雜訊,直到數據變成純雜訊。反向過程則是學習如何從純雜訊開始,逐步地、迭代地去除雜訊,最終恢復(生成)出符合原始數據分佈的清晰數據。選項A是GAN的原理。選項B是VAE的原理。選項D是自回歸模型(Autoregressive Models)如GPT的原理。
#5
★★★★★
大型語言模型(Large Language Model, LLM)如GPT系列,其基礎架構主要是?
答案解析
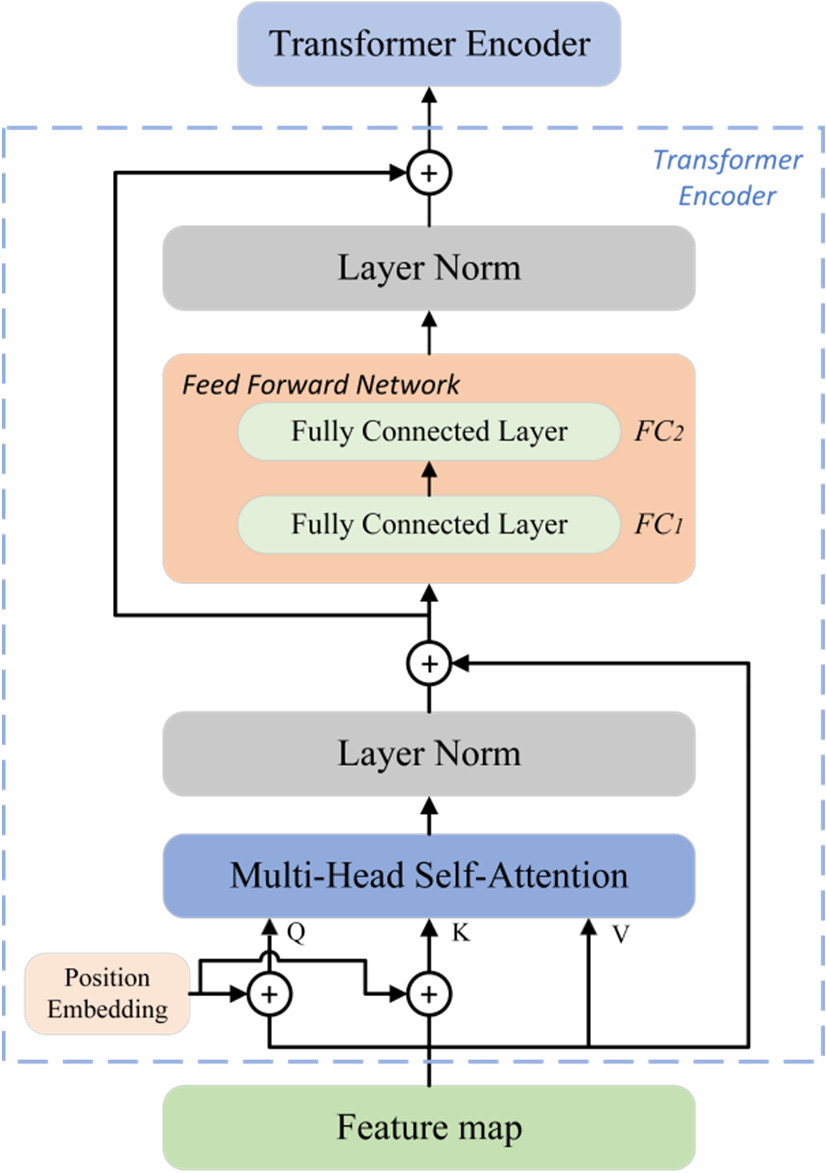
自2017年Google提出Transformer架構以來,它已成為自然語言處理(Natural Language Processing, NLP)領域的主流架構,特別是大型語言模型的基石。Transformer利用自注意力機制(Self-Attention Mechanism)來捕捉輸入序列中不同位置之間的長距離依賴關係,並且具有良好的平行計算能力,使其能夠有效地處理長文本並擴展到巨大的模型規模。GPT(Generative Pre-trained Transformer)、BERT等著名LLM均基於Transformer架構。
#6
★★★★
在文本生成任務中,「自回歸」(Autoregressive)模型是指模型如何生成文本?
答案解析
自回歸模型是文本生成中常用的一種方式。它生成文本的過程是序列性的、一步一步的。在生成第 N 個詞語時,模型會考慮前面已經生成的 N-1 個詞語作為上下文,來預測最可能的下一個詞語。這個過程不斷重複,直到生成結束符號或達到預定長度。例如,GPT 模型就是典型的自回歸模型。選項A描述的是非自回歸(Non-Autoregressive)模型。選項C是機器翻譯任務。選項D是情感分析任務。
#7
★★★★
StyleGAN 是哪一類生成模型的著名代表,特別擅長生成高解析度、風格可控的人臉圖像?
答案解析
StyleGAN及其後續版本(StyleGAN2, StyleGAN3)是由NVIDIA開發的一系列基於GAN的模型,它們在生成逼真、高解析度的人臉圖像方面取得了驚人的效果。StyleGAN的創新之處在於引入了風格轉換(Style Transfer)的概念,允許對生成圖像的不同層次(如粗糙特徵、細節紋理)的風格進行精細控制。

#8
★★★★★
「提示工程」(Prompt Engineering)在與大型語言模型互動時,指的是什麼?
答案解析
提示工程是使用大型語言模型(LLM)或其他生成式AI模型時的一項關鍵技能。由於這些模型通常是透過輸入提示(Prompt)來觸發回應的,提示的設計方式(措辭、結構、範例等)會極大地影響輸出的品質和相關性。提示工程就是研究如何設計出最有效的提示,來引導模型理解任務意圖並生成符合要求的結果,而不需要重新訓練或修改模型本身。
#9
★★★★
生成式AI可能產生的「幻覺」(Hallucination)問題,指的是什麼?
答案解析
AI幻覺是生成式模型(特別是LLM)中常見的問題。它指模型自信地生成了一些聽起來很有道理,但實際上與事實不符、缺乏現實依據或邏輯矛盾的資訊。這可能是因為模型在訓練數據中學習到了錯誤的關聯,或者在生成過程中「編造」了不存在的細節。識別和減少幻覺是提升生成式AI可靠性的重要挑戰。偏見(選項D)也是問題,但與幻覺的概念不同。
#10
★★★
以下哪項是大型語言模型在文本生成中常見的應用?
答案解析
大型語言模型(LLM)在處理和生成自然語言方面表現出色。常見的文本生成應用包括:自動生成長篇文章的摘要、開發能夠進行自然對話的聊天機器人(Chatbots)、根據需求描述自動生成程式碼、內容創作(如寫詩、故事、行銷文案)、機器翻譯等。選項A、D是電腦視覺任務。選項B是語音處理任務,雖然也可能用到生成模型,但核心是語音模態。
#11
★★★
Midjourney 和 Stable Diffusion 主要應用於哪個領域?
答案解析
Midjourney 和 Stable Diffusion 都是當前非常流行的生成式AI工具/模型,它們的核心功能是根據使用者輸入的文字提示(Prompt)來生成對應的圖像。這屬於文本到圖像生成(Text-to-Image Generation)的範疇,是生成式AI在視覺領域的重要應用。
#12
★★★★
在提示工程中,"Few-shot Prompting" 是指什麼?
答案解析
Few-shot Prompting 是一種提示技巧,旨在透過在提示中包含幾個(通常很少,如1-5個)完整的任務範例(包含輸入和期望的輸出),來向大型語言模型展示如何執行特定任務。這有助於模型更好地理解任務要求和輸出格式,而無需進行模型微調。相對的,"Zero-shot Prompting" 是指不提供任何範例,只給任務描述;"One-shot Prompting" 是指只提供一個範例。選項C描述的是模型微調(Fine-tuning),而不是提示工程的範疇。
#13
★★★★
生成式AI在應用中可能引發的主要倫理風險不包含以下哪項?
答案解析
生成式AI的強大能力也帶來了倫理風險。選項A、B、C都是生成式AI應用中廣泛關注的倫理問題:它可以被用來製造逼真的虛假新聞、偽造影音內容;其訓練數據可能包含受版權保護的內容,導致生成的內容侵權;模型可能學習並放大訓練數據中的社會偏見。選項D則與現實相反,訓練大型生成式模型通常需要消耗大量的計算資源和電力,引發的是環境影響的擔憂,而非消耗過少。
#14
★★★★
Transformer 模型中的「自注意力機制」(Self-Attention Mechanism)主要作用是?
答案解析
自注意力機制是Transformer模型的核心。它允許模型在處理輸入序列(如一個句子)中的某個元素(如一個詞語)時,動態地計算該元素與序列中所有其他元素的相關性得分(注意力權重),然後根據這些權重對其他元素的表示進行加權求和,從而得到該元素考慮了全局上下文的新表示。這使得模型能夠有效地捕捉長距離依賴關係,優於傳統RNN的序列處理方式。
#15
★★★
除了文本和圖像,生成式AI還可以應用於生成以下哪種內容?
答案解析
生成式AI的應用範圍非常廣泛,不限於文本和圖像。它可以學習各種數據模態的模式並生成新的內容,包括:生成新的音樂片段或歌曲(如MusicLM, Jukebox)、合成逼真的人類語音(如WaveNet, Tacotron)、生成影片內容(如Sora, Gen-2)、創建3D模型、自動生成程式碼(如GitHub Copilot)、生成分子結構、設計遊戲關卡等。
#16
★★★
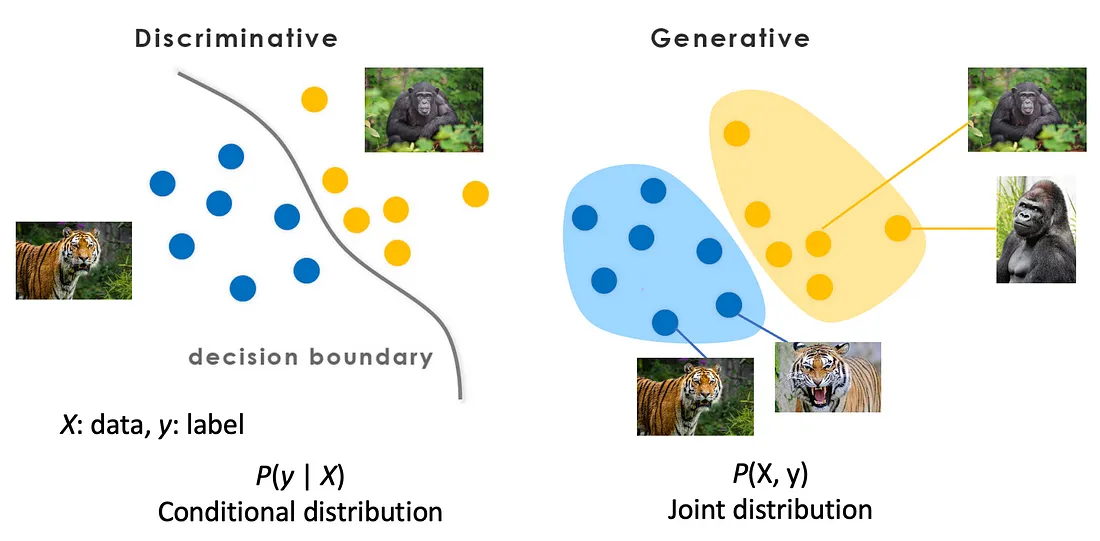
與判別式模型(Discriminative Models)相比,生成式模型(Generative Models)主要學習的是數據的什麼?
答案解析
機器學習模型可大致分為生成式和判別式。判別式模型(如邏輯回歸、SVM、多數分類神經網路)直接學習輸入 x 到輸出 y 的條件機率 P(y|x) 或學習它們之間的決策邊界,目標是區分不同類別。生成式模型(如樸素貝葉斯、GAN、VAE、擴散模型)則學習數據本身的整體分佈,例如輸入 x 和輸出 y 的聯合機率分佈 P(x, y)(如果是有標籤數據),或者僅學習輸入數據的分佈 P(x)。學習了數據的生成機制後,模型就能夠生成新的數據樣本。
#17
★★★★
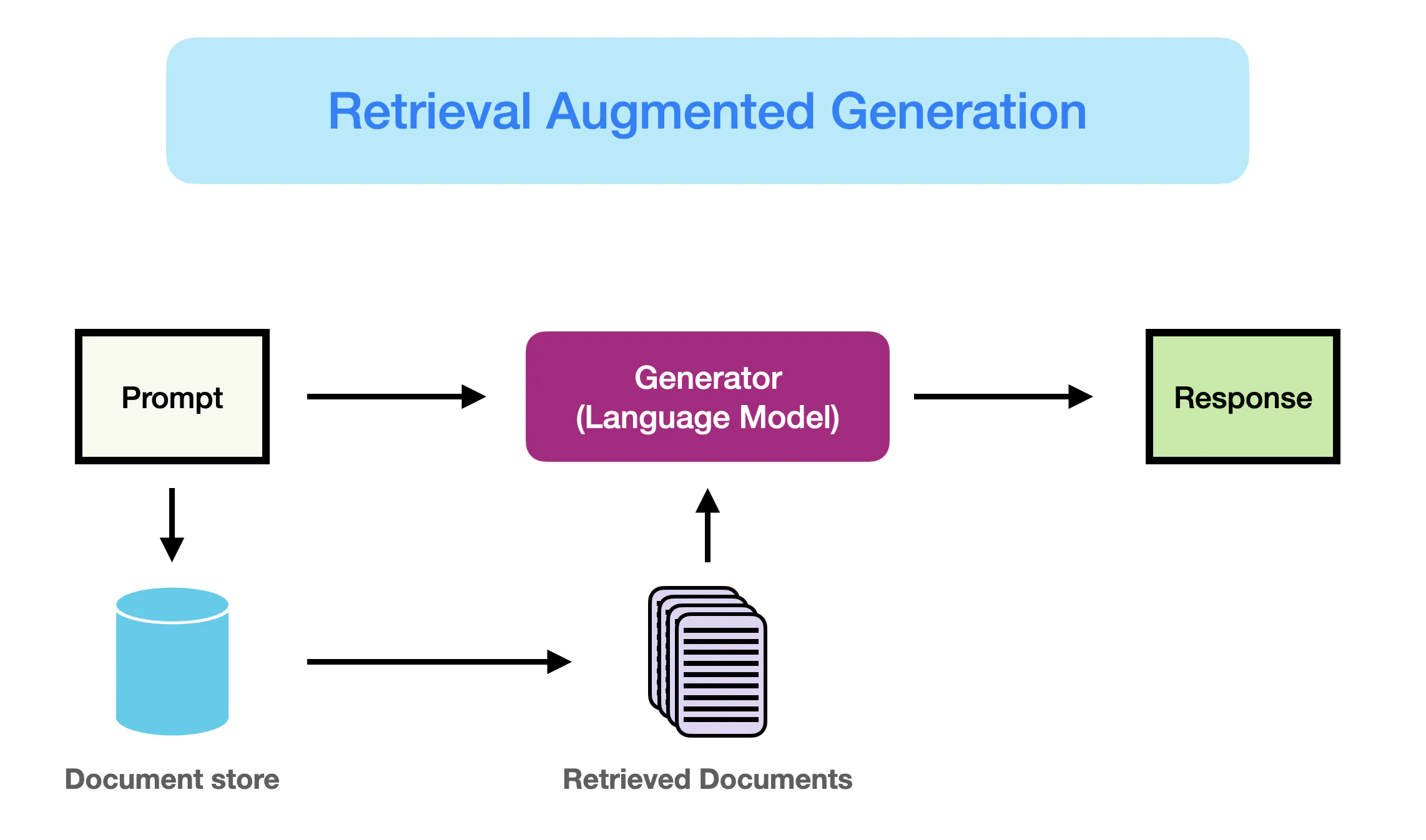
檢索增強生成(Retrieval-Augmented Generation, RAG)技術主要是為了解決大型語言模型的哪個問題?
答案解析
RAG 是一種結合了資訊檢索(Information Retrieval)和生成模型(Generation)的技術。大型語言模型(LLM)雖然能力強大,但其知識受限於訓練數據,無法獲取最新資訊,且有時會產生不準確的幻覺。RAG 試圖解決這個問題:當收到一個提問時,它首先從一個外部的、可即時更新的知識庫(如文件、資料庫)中檢索相關的資訊片段,然後將這些檢索到的資訊連同原始提問一起作為上下文(Context)提供給LLM,讓LLM 在生成答案時能夠參考這些外部知識,從而提高答案的時效性、準確性和可信度。
#18
★★★
與 GAN 相比,擴散模型(Diffusion Models)在訓練穩定性方面通常表現如何?
答案解析
GAN 的訓練過程涉及生成器和判別器之間的零和博弈,這常常導致訓練不穩定、模式崩潰(生成器只生成少數幾種樣本)或梯度消失/爆炸等問題,需要仔細調整超參數和架構。相比之下,擴散模型的訓練目標(預測每一步添加的雜訊或去噪後的數據)通常更穩定,優化過程相對更容易收斂,不容易出現模式崩潰。但擴散模型的缺點是生成過程通常需要多步迭代,速度較慢(儘管已有改進方法)。
#19
★★★
「圖像修復」(Image Inpainting)任務是指利用生成式AI做什麼?
答案解析
圖像修復是生成式AI在圖像處理中的一個應用。其目標是對於輸入圖像中被遮擋、損壞或人為移除的部分(通常用遮罩標出),利用圖像中其他已知區域的上下文資訊,生成合理且視覺上連續的內容來填補這些缺失區域,使得修復後的圖像看起來自然完整。這在照片編輯、文物修復等場景中有應用價值。選項A是超解析度(Super-Resolution)。選項C是風格轉換(Style Transfer)。選項D是圖像描述生成(Image Captioning)。

#20
★★★
目前評估生成式AI模型(特別是LLM)能力時,常用的基準測試(Benchmark)集包括?
答案解析
評估大型語言模型的綜合能力需要多樣化的基準測試。MMLU (Massive Multitask Language Understanding) 涵蓋了57個不同學科的知識問答。HellaSwag 測試常識推理能力,要求模型選擇最合理的句子結尾。GSM8K 包含小學數學應用題,測試模型的數學推理和解題能力。這些都是衡量LLM知識、推理、常識等方面能力的常用基準。選項A和C是電腦視覺領域常用的圖像分類/檢測數據集。選項D是語音辨識領域的數據集。
#21
★★★★
大型語言模型(LLM)中的「上下文長度」(Context Length/Window)限制指的是什麼?
答案解析
Transformer 架構的 LLM 在處理輸入時,並非能無限地回看所有之前的內容。存在一個「上下文長度」或「上下文視窗」的限制,通常以 token 數量來衡量(如 2048, 4096, 8192, 甚至更高)。這代表模型在生成下一個 token 或進行理解時,最多只能參考輸入序列中最近的這麼多個 token。超過這個長度的更早內容將被忽略,這可能導致模型在處理非常長的文本或需要長期記憶的任務時表現下降。突破上下文長度限制是 LLM 研究的一個重要方向。
#22
★★★
對預訓練好的大型語言模型進行「微調」(Fine-tuning)的主要目的是?
答案解析
大型語言模型通常先在海量的通用數據上進行預訓練(Pre-training),學習廣泛的語言知識。然而,為了讓模型在某個特定任務(如特定行業的客服、特定風格的寫作)或特定領域(如法律、醫療)表現更好,可以進行微調。微調使用與目標任務/領域相關的、規模相對較小的標註數據集,在預訓練模型的基礎上繼續進行短時間的訓練,調整模型參數以適應特定需求。這比從頭訓練高效得多,是遷移學習(Transfer Learning)的一種應用。選項D描述的是模型壓縮(Model Compression)。
#23
★★★
在評估文本生成品質時,除了人工評估外,常用的自動評估指標(Automatic Metric)可能包括?
答案解析
評估生成文本的品質很困難,人工評估最可靠但成本高。自動評估指標試圖量化生成文本與參考文本(人工撰寫的標準答案)的相似度或流暢度。BLEU (Bilingual Evaluation Understudy) 常用於機器翻譯,衡量 N-gram 的精確率。ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 常用於自動摘要,衡量 N-gram 的召回率。Perplexity (困惑度) 衡量語言模型的預測不確定性,值越低通常表示模型對序列的擬合越好,生成的文本可能更流暢。但這些自動指標與人類判斷之間往往存在差距。
#24
★★
GitHub Copilot 這類工具主要是利用生成式AI來輔助哪個任務?
答案解析
GitHub Copilot 是基於大型語言模型(如OpenAI Codex)開發的AI程式設計助手。它能夠理解開發者的程式碼上下文和註解,自動建議、補全甚至生成整個函數或程式碼區塊,支援多種程式語言,旨在提高開發者的編程效率。這屬於程式碼生成(Code Generation)的應用範疇。
#25
★★★
「負責任的AI」(Responsible AI)原則在生成式AI的開發與應用中,強調需要關注哪些面向?
答案解析
負責任的AI是一個框架,旨在確保AI系統的開發和部署是以安全、合乎道德和符合社會價值觀的方式進行的。對於生成式AI,這尤其重要,因為它可能產生影響深遠的內容。關鍵原則包括:公平性(避免偏見)、可靠性(減少幻覺,穩定運行)、安全性(防止惡意使用,如生成有害內容)、隱私保護(保護訓練數據和使用者數據)、可解釋性(理解模型決策過程)以及問責制(明確責任歸屬)。
#26
★★★★
目前主流的生成式AI模型,其能力很大程度上依賴於什麼?
答案解析
現代生成式AI,特別是大型模型如LLM、擴散模型等,其令人印象深刻的能力主要來自於兩個方面:一是使用了海量的、多樣化的數據進行訓練(涵蓋網頁文本、書籍、程式碼、圖像等),使模型能夠學習到廣泛的知識和模式;二是模型本身具有巨大的規模,包含數十億甚至數兆的參數,使其有足夠的容量來擬合複雜的數據分佈。這種「大數據+大模型」的範式是當前取得突破的關鍵。選項A、B代表的是早期的符號AI或專家系統。選項D與物理模擬相關,不是生成式AI的核心依賴。
#27
★★★
在GAN的訓練過程中,如果判別器(Discriminator)過於強大,總是能輕易區分真假樣本,可能會導致什麼問題?
答案解析
GAN 的訓練需要生成器和判別器之間達到一種平衡。如果判別器訓練得太好,能夠輕易地將生成器產生的所有假樣本都辨識出來(給予極低的概率),那麼生成器在更新時,從判別器獲得的梯度信號就會非常微弱甚至趨近於零(梯度消失)。這使得生成器無法有效地學習如何改進自己以生成更逼真的樣本,導致訓練停滯。因此,維持兩者的相對平衡是GAN訓練成功的關鍵。
#28
★★★★
DALL-E 2 和 Imagen 是主要用於哪種跨模態生成任務的模型?
答案解析
DALL-E 2 (由 OpenAI 開發) 和 Imagen (由 Google 開發) 都是著名的文本到圖像生成模型。它們能夠根據使用者輸入的自然語言描述,生成高質量、富有創意且符合描述內容的圖像。這類模型的出現極大地推動了AI在創意設計、藝術生成等領域的應用。
#29
★★★
在使用檢索增強生成(RAG)時,選擇合適的「檢索器」(Retriever)模型至關重要,其主要作用是?
答案解析
RAG系統包含檢索器和生成器兩部分。檢索器的任務是理解使用者的查詢(提問),然後在龐大的外部知識庫(如向量資料庫中存儲的文件嵌入)中快速、準確地找到與查詢最相關的文檔或段落。檢索到的內容的品質直接影響最終生成答案的品質。常用的檢索方法包括基於向量相似度(如餘弦相似度)的稠密檢索(Dense Retrieval)。生成最終答案是生成器(通常是LLM)的工作。
#30
★★★
相較於基於 RNN 的模型,Transformer 在處理長序列時的主要優勢是?
答案解析
RNN(循環神經網路)及其變體(如LSTM, GRU)在處理序列時是逐步進行的,對於非常長的序列,容易出現梯度消失或爆炸問題,難以捕捉相距很遠的元素之間的依賴關係。Transformer 使用自注意力機制,可以直接計算序列中任意兩個位置之間的關聯,無論它們相距多遠,因此能更好地捕捉長距離依賴關係。同時,由於其非序列性的計算方式(對於輸入序列中的所有位置可以同時計算注意力),Transformer 非常適合利用現代GPU進行大規模平行計算,訓練效率更高。
#31
★★
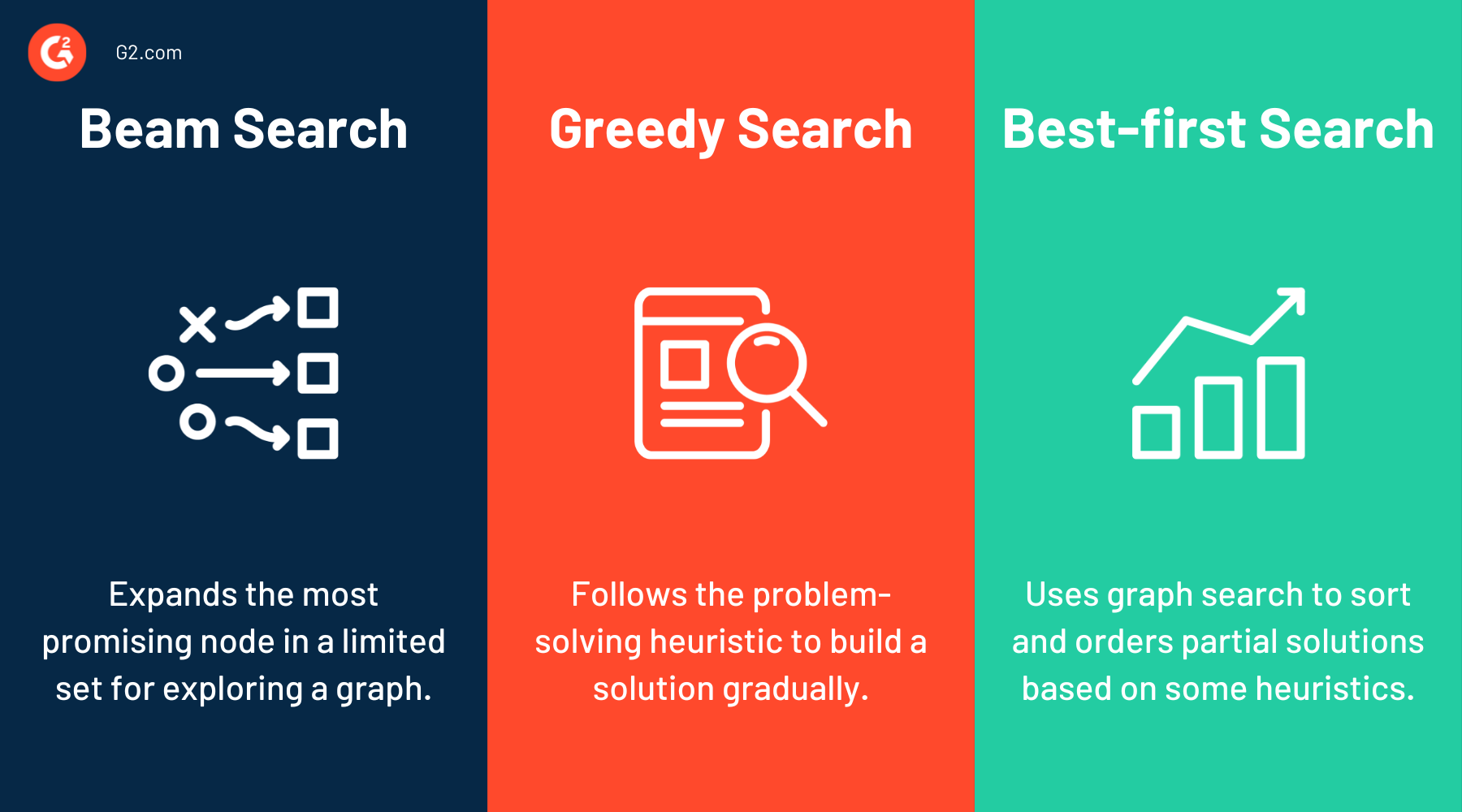
在文本生成中,"Beam Search" 是一種什麼技術?
答案解析
在自回歸模型生成文本時,每一步都需要從可能的下一個詞語中進行選擇。最簡單的策略是貪婪搜索(Greedy Search),即每一步都選擇概率最高的詞語。但這可能導致局部最優而非全局最優。Beam Search 是一種改進策略,它在每一步保留 K 個(K 稱為 Beam Width)概率最高的候選序列,然後在下一步基於這 K 個序列擴展,再選出新的 K 個最佳序列。這樣可以在計算效率和生成品質之間取得較好的平衡,找到概率更高的完整序列。
#32
★★
「風格轉換」(Style Transfer)在圖像生成中的目標是?
答案解析
神經風格轉換是一種利用深度學習(特別是CNN)進行圖像處理的技術。它通常需要兩張輸入圖像:一張內容圖像(提供主要的物體和結構)和一張風格圖像(提供紋理、顏色、筆觸等藝術風格)。模型的目標是生成一張新的圖像,該圖像保留了內容圖像的主要結構,同時又呈現出風格圖像的藝術風格。
#33
★★★
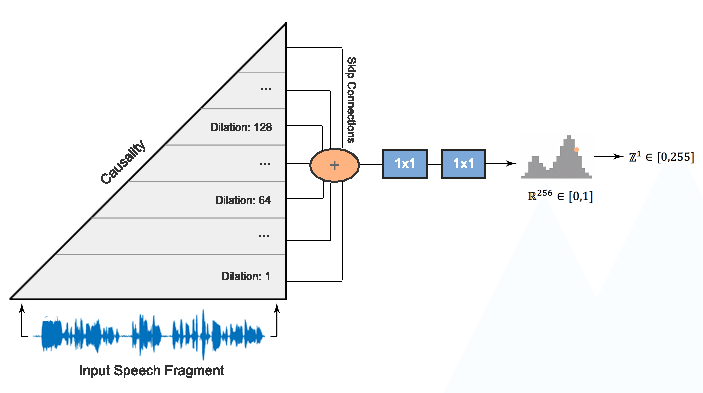
WaveNet 模型主要被設計用來生成哪種類型的數據?
答案解析
WaveNet 是由 DeepMind 開發的一種深度生成模型,專門用於生成原始音訊波形。它採用了類似於卷積神經網路的架構(特別是因果卷積和擴張卷積),能夠捕捉音訊信號中的長期依賴關係,生成非常逼真和自然的語音(用於語音合成)和音樂。
#34
★★★
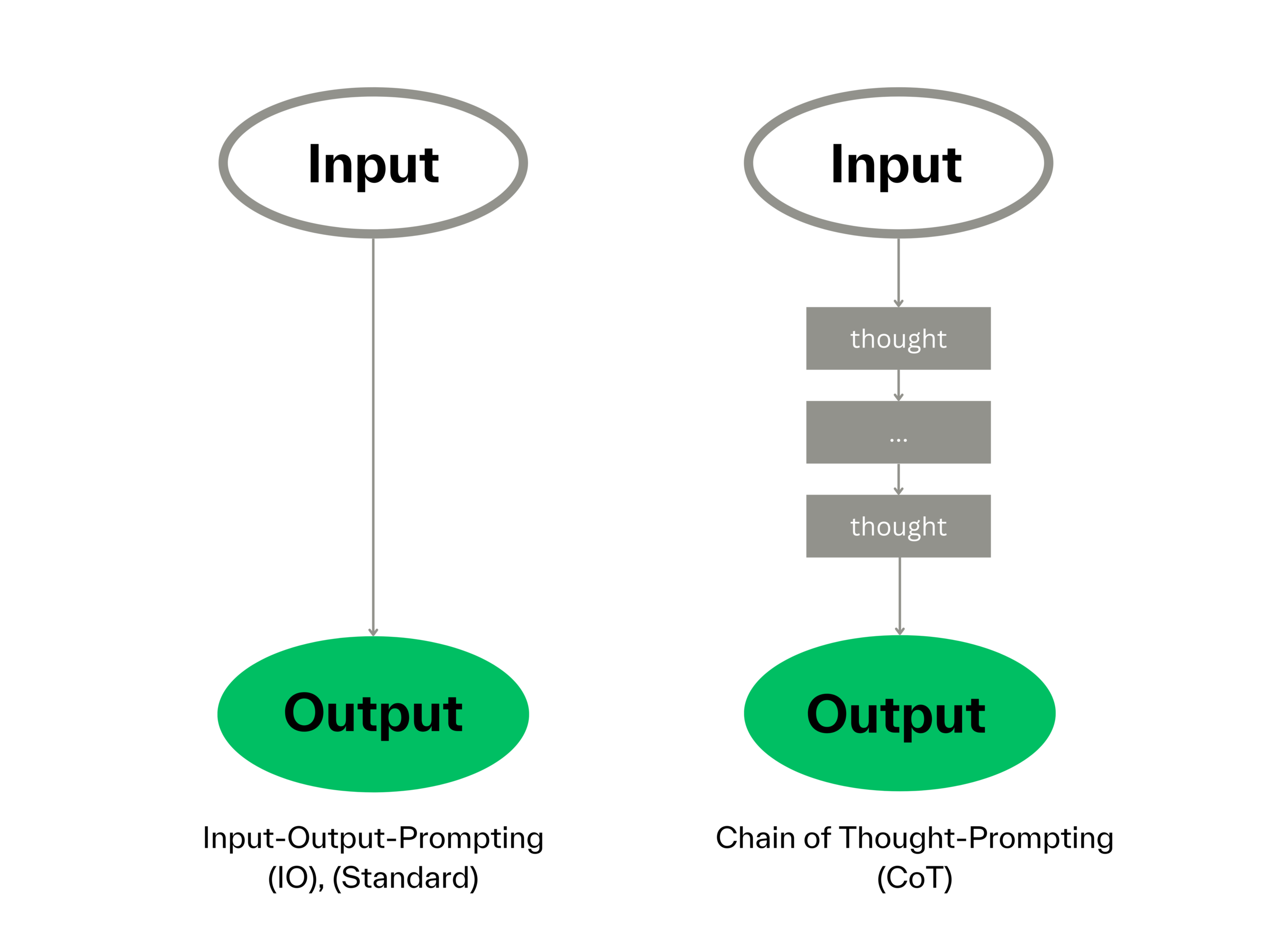
在提示工程中,「思維鏈」(Chain-of-Thought, CoT)提示技巧是指?
答案解析
思維鏈(CoT)提示是一種增強大型語言模型(特別是在數學、常識和符號推理任務上)表現的技巧。它透過在提示的範例中(Few-shot CoT)或直接在指令中(Zero-shot CoT)明確地引導模型,不僅要給出最終答案,還要展示得出答案的詳細推理步驟或中間思考過程。這種方式鼓勵模型進行更深入、更結構化的思考,從而提高複雜問題的求解準確率。
#35
★★
為生成式AI模型生成的內容添加「浮水印」(Watermarking)技術,主要是為了達成什麼目的?
答案解析
隨著AI生成內容越來越逼真,區分AI生成和人類創作變得困難,這可能被用於傳播虛假資訊或侵犯版權。AI浮水印技術試圖在模型生成內容(如文本、圖像)時嵌入難以察覺但可以被特定演算法檢測到的標記(浮水印)。這樣做的目的是為了增加透明度,讓接收者或平台能夠判斷內容是否由AI生成,有助於追溯來源、打擊濫用,是負責任AI實踐的一部分。
#36
★★★
生成式AI的「預訓練-微調」(Pre-training and Fine-tuning)範式指的是什麼流程?
答案解析
這是當前訓練大型生成式模型(尤其是LLM)的標準流程。第一階段是預訓練:使用海量的、無標註或自監督的通用數據(如來自網路的文本)來訓練一個非常大的模型,使其學習通用的語言模式、世界知識和基本推理能力。第二階段是微調:針對特定的下游任務(如情感分析、問答、特定領域知識)或特定的行為偏好(如遵循指令、無害性),使用規模相對較小的、有標註的數據來進一步優化預訓練好的模型,使其更好地適應特定需求。
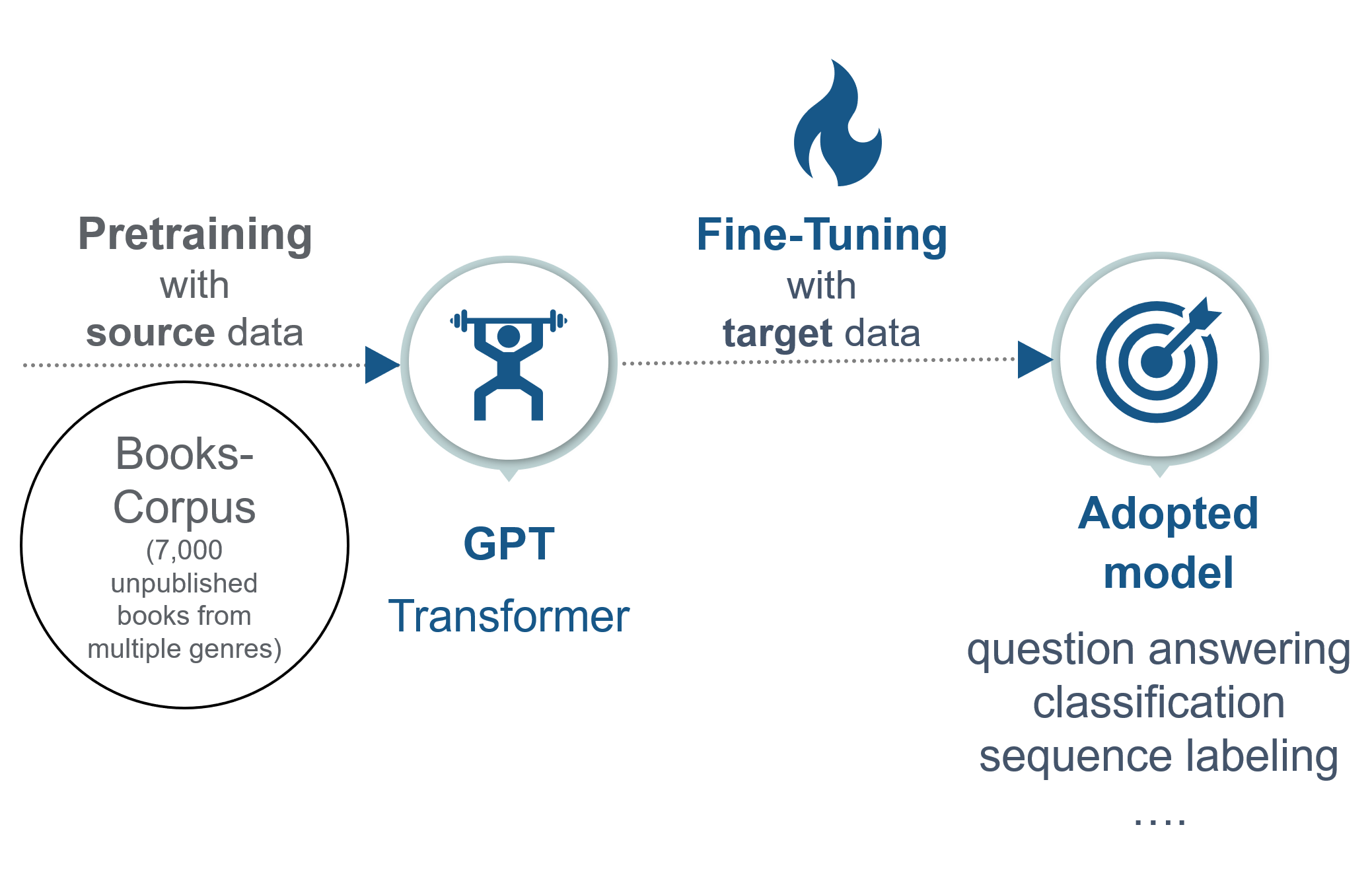
#37
★★
在VAE中,KL散度(Kullback–Leibler Divergence)損失項的作用是什麼?
答案解析
VAE的損失函數通常包含兩部分:重構損失(Reconstruction Loss)和KL散度損失。重構損失(如均方誤差或交叉熵)確保解碼器能夠從潛在向量中恢復出接近原始輸入的數據。KL散度損失則是一個正規化項(Regularization Term),它衡量編碼器輸出的潛在變數分佈(通常是多元高斯分佈)與一個預設的簡單先驗分佈(通常是標準常態分佈 N(0, I))之間的差異。最小化KL散度損失會促使潛在空間結構化,使其接近先驗分佈,有利於從先驗分佈中採樣來生成新數據,並使得潛在空間更加平滑。
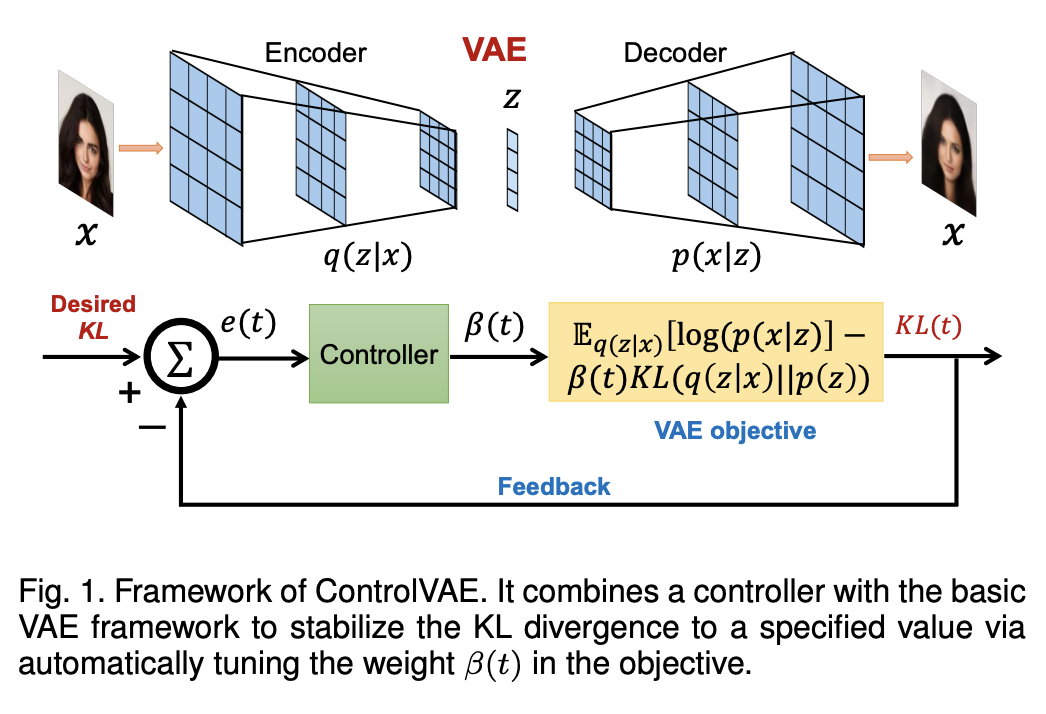
#38
★★★
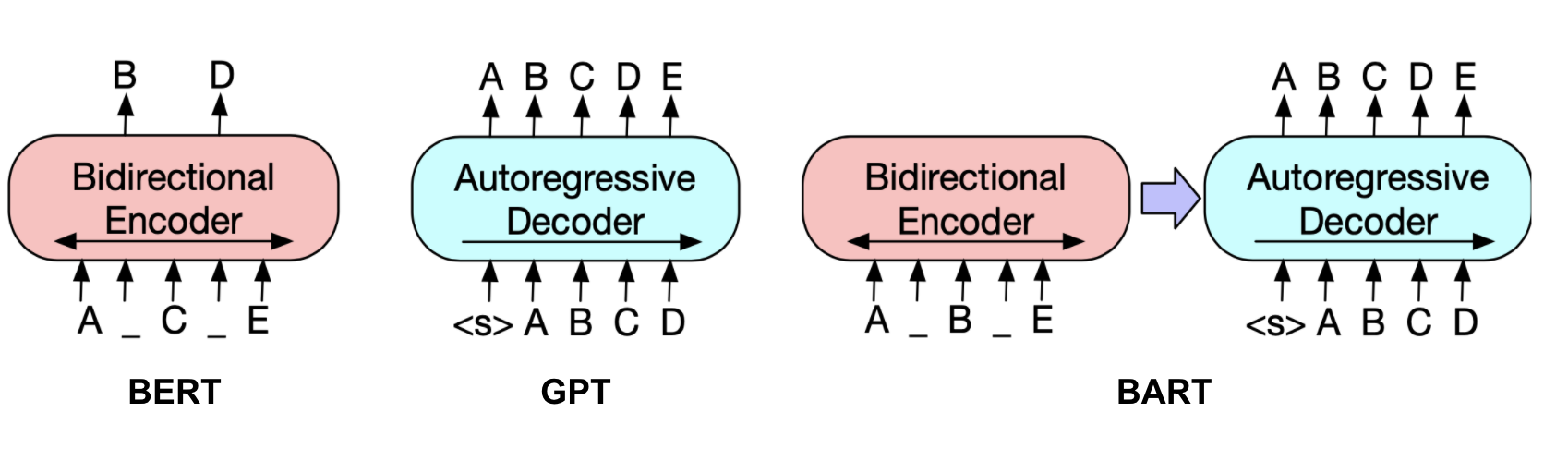
GPT 模型系列(如 GPT-3, GPT-4)主要是哪種類型的 Transformer 架構?
答案解析
原始的 Transformer 模型包含編碼器和解碼器兩部分,常用於序列到序列(Seq2Seq)任務,如機器翻譯。然而,後續發展出了不同的變體。BERT 及其家族主要採用僅編碼器(Encoder-only)架構,擅長理解輸入文本的上下文,常用於自然語言理解(NLU)任務。GPT 系列模型則主要採用僅解碼器(Decoder-only)架構,並使用遮蔽式自注意力(Masked Self-Attention)來確保在預測當前詞語時只看到前面的詞語,特別適合自回歸式的文本生成任務。T5 和 BART 等模型則採用完整的編碼器-解碼器架構。
#39
★★
文本生成中的「溫度縮放」(Temperature Scaling)參數的作用是?
答案解析
在自回歸模型生成下一個詞語時,模型會輸出一個詞彙表中所有詞語的概率分佈。溫度(Temperature)是一個超參數,用於在從這個概率分佈中採樣之前對其進行調整。較低的溫度(如 < 1)會使得概率分佈更尖銳,模型更傾向於選擇概率最高的詞語,生成結果更保守、確定性更高。較高的溫度(如 > 1)會使得概率分佈更平緩,增加了選擇低概率詞語的可能性,生成結果更隨機、更有創造性,但也可能不連貫。溫度為 1 時不改變原始分佈。
#40
★★★
潛在擴散模型(Latent Diffusion Models, LDM),如 Stable Diffusion,與標準擴散模型的主要區別在於?
答案解析
標準的擴散模型直接在高維的像素空間中進行加噪和去噪,計算成本非常高。潛在擴散模型(LDM)是對此的改進。它首先使用一個預訓練好的自編碼器(Autoencoder)將高維圖像壓縮到一個低維的潛在空間。然後,在該潛在空間中執行擴散模型的加噪和去噪過程。最後,再使用自編碼器的解碼器將去噪後的潛在向量映射回像素空間,生成最終圖像。這種在低維空間操作的方式大大降低了計算複雜度和訓練成本,使得高解析度圖像生成更加高效,Stable Diffusion 就是一個成功的例子。
.png)
#41
★★
生成式AI在影片生成方面的挑戰之一是?
答案解析
影片生成比靜態圖像生成更具挑戰性,因為它不僅需要生成視覺上逼真的畫面,還需要確保這些畫面在時間維度上是連貫的。這意味著物體應該平滑地移動,場景變化應該合理,並且要符合基本的物理規律(如重力、碰撞)。維持長時間的時序一致性(Temporal Coherence)和物理合理性是當前影片生成模型(如Sora)需要克服的主要難題。
#42
★★
指令微調(Instruction Fine-tuning)是一種讓預訓練語言模型學會什麼能力的技術?
答案解析
原始的預訓練語言模型(如GPT-3的基礎模型)主要學會了預測下一個詞,但不一定能很好地理解並遵循人類的指令。指令微調透過使用大量「指令-回應」格式的數據對預訓練模型進行微調,教導模型如何理解各種自然語言指令(如「總結這段文字」、「寫一封郵件」、「翻譯這句話」)並生成恰當的回應。這是使LLM變得更像有用助手(如ChatGPT)的關鍵步驟之一。

#43
★★★
AI Alignment(對齊)問題在大型語言模型中主要關注什麼?
答案解析
AI對齊是一個重要的研究領域,特別是對於能力越來越強的大型模型。其核心目標是確保AI系統的目標、行為和決策過程符合設計者和社會的期望、意圖和倫理價值觀。這涉及到如何讓模型理解並遵循複雜的、有時甚至是模糊的人類指令,避免產生有害、有偏見或非預期的輸出,即使在追求其設定的目標時也是如此。例如,透過指令微調和從人類回饋中學習(RLHF)等技術來實現對齊。
#44
★★
生成式AI與傳統軟體開發的主要區別在於?
答案解析
傳統軟體開發是基於程式設計師編寫的明確指令、規則和演算法來運作的,對於相同的輸入,通常會產生完全相同的確定性輸出。生成式AI則是基於數據驅動的,它從大量數據中學習潛在的模式和關係,其輸出是基於學習到的概率分佈生成的,因此往往帶有一定的隨機性,對於相同的輸入提示,可能產生不同的輸出結果。雖然生成式AI的底層也需要程式碼來實現模型和訓練流程,但其核心行為模式與傳統基於規則的軟體有本質區別。
#45
★★★★
從人類回饋中學習(Reinforcement Learning from Human Feedback, RLHF)主要用於訓練大型語言模型實現什麼目標?
答案解析
RLHF 是對齊(Alignment)大型語言模型行為的關鍵技術之一,特別是用於訓練像 ChatGPT 這樣的對話模型。它通常在指令微調之後進行。其過程大致是:首先讓模型針對一些提示生成多個不同的回應,然後由人類標註者對這些回應進行排序或評分,以體現人類的偏好(哪個答案更好、更有幫助、更安全等)。接著,利用這些人類偏好數據訓練一個獎勵模型(Reward Model),該模型能夠預測哪個回應更符合人類偏好。最後,使用強化學習演算法(如PPO)來微調原始的語言模型,使其生成的內容能夠最大化獎勵模型的評分,從而使其行為更符合人類的期望。
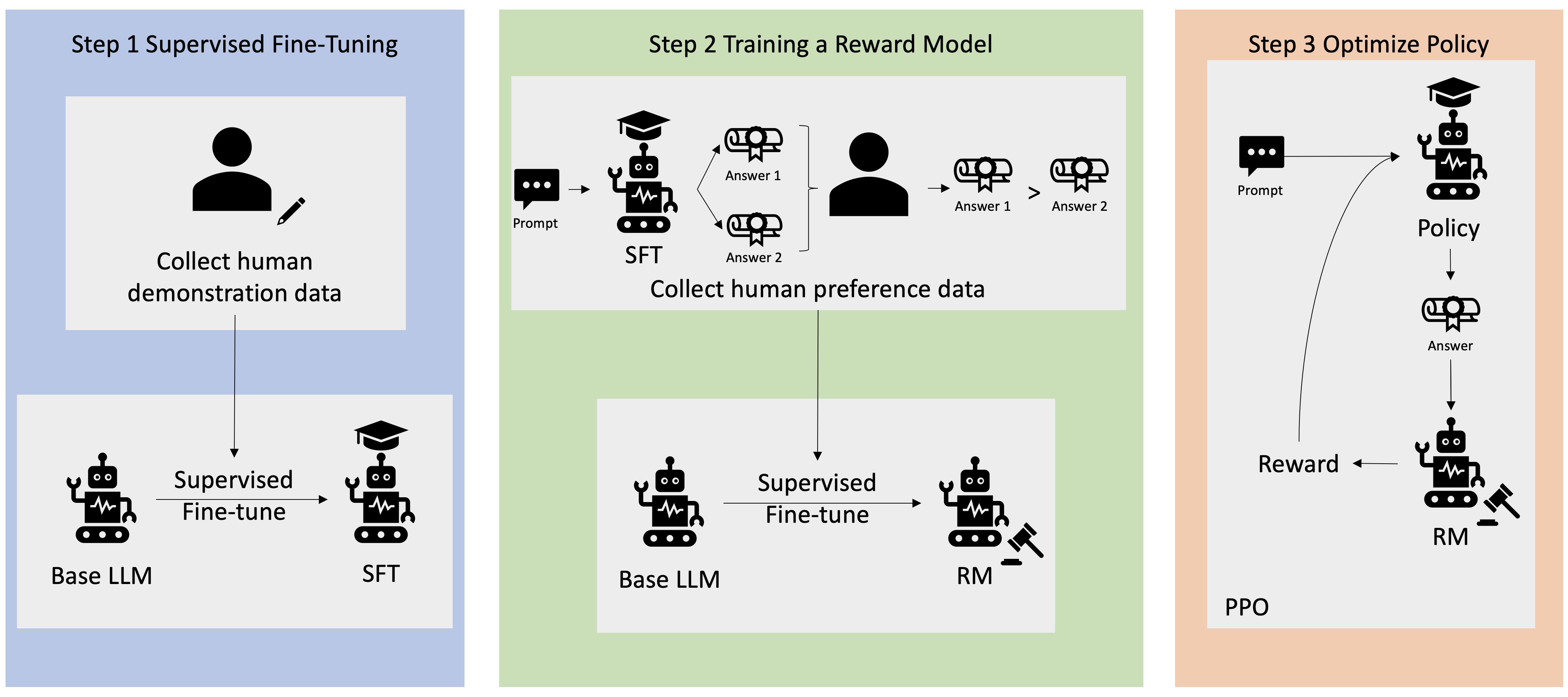
#46
★★
在Transformer架構中,"位置編碼" (Positional Encoding) 的目的是什麼?
答案解析
Transformer 的自注意力機制在計算相關性時,是平等地看待輸入序列中的所有位置的,它本身並不直接處理或利用詞語的順序資訊。然而,在自然語言中,詞語的順序至關重要。為了讓模型能夠利用這種順序資訊,Transformer 在將詞嵌入(Word Embedding)輸入模型之前,會為每個位置的詞嵌入添加一個獨特的「位置編碼」向量。這個位置編碼向量提供了關於詞語在序列中絕對或相對位置的資訊,使得模型能夠區分不同位置的相同詞語,並理解序列的順序結構。

#47
★
哪種技術常用於評估生成圖像品質的自動指標,透過比較生成圖像和真實圖像的特徵分佈?
答案解析
評估生成圖像的品質(逼真度和多樣性)也很困難。FID 是一個廣泛使用的自動評估指標。它首先使用一個預訓練好的圖像分類模型(通常是 Inception V3)提取大量真實圖像和生成圖像的深層特徵(通常是某個隱藏層的激活值)。然後,假設這些特徵服從多維高斯分佈,計算這兩個分佈之間的 Fréchet 距離。FID 分數越低,表示生成圖像的特徵分佈與真實圖像越接近,通常意味著生成圖像的品質越高、多樣性越好。選項A是分類指標。選項C通常用於像素級比較。選項D用於文本評估。
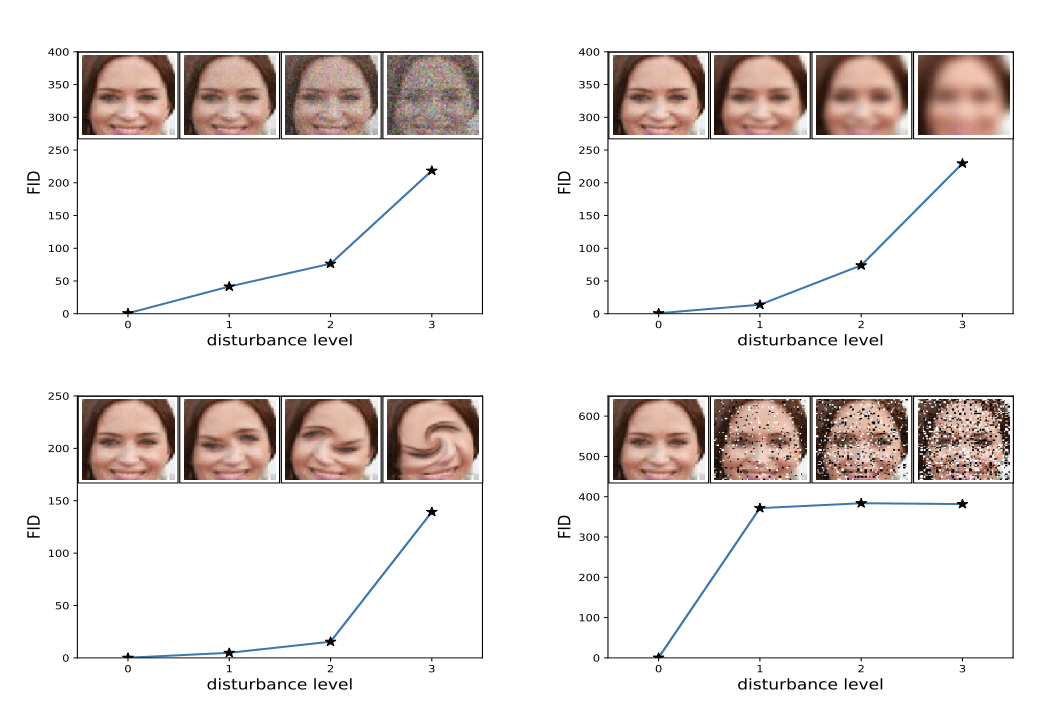
#48
★★
關於生成式AI的未來發展趨勢,以下描述何者較不可能?
答案解析
生成式AI的未來發展趨於整合多種模態(文本、圖像、聲音等)以更全面地理解世界;同時,隨著模型能力增強,如何提高效率(用於部署)、增強可控性(減少幻覺和有害輸出)、保障安全性將是關鍵;將通用模型與特定領域知識(如醫療、法律、金融)結合以提供專業服務也是重要方向。然而,認為AI會「完全取代」人類的決策和創造力是一種過於簡化和極端的看法。AI更可能作為強大的輔助工具,增強人類的能力,而非完全替代,特別是在涉及複雜價值判斷、情感和原創性的領域。
#49
★★
當我們說一個大型語言模型具有「湧現能力」(Emergent Abilities)時,通常是指什麼?
答案解析
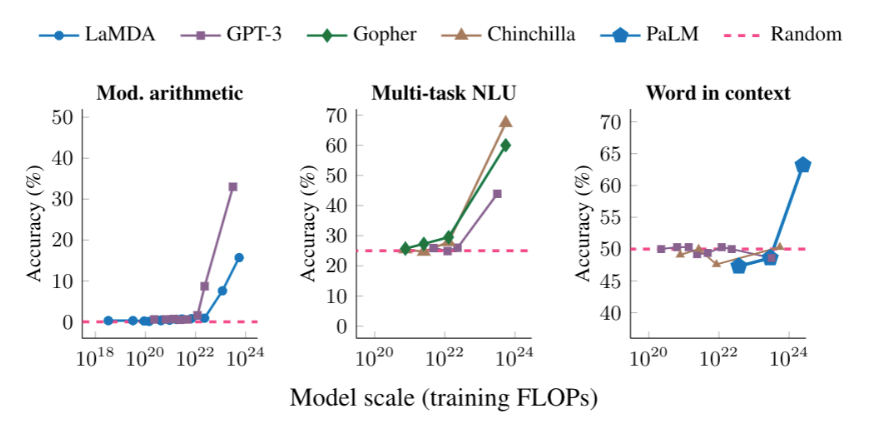
湧現能力是觀察到的大型模型現象。指的是某些複雜能力(如進行多步推理、理解比喻、寫程式碼等)在模型規模較小時幾乎不存在或表現很差,但當模型規模增大到一定程度後,這些能力會突然顯著地出現或提升,其表現超出簡單外插(Extrapolation)的預期。理解和預測湧現能力是大型模型研究中的一個有趣且重要的課題。
#50
★★★
為了讓文本到圖像模型(如Stable Diffusion)生成特定人物或物體的圖像,常用的一種技術是?
答案解析
預訓練的文本到圖像模型雖然能生成多樣化的圖像,但通常無法精確生成使用者指定的特定人物、物體或風格(因為模型沒見過)。為了實現這種客製化生成,需要對模型進行調整。常用的技術包括:
- 微調(Fine-tuning):使用包含目標概念的少量圖像對整個模型或部分模型進行微調。
- Textual Inversion:為目標概念學習一個特殊的詞嵌入(text embedding),之後可以在提示詞中使用這個特殊詞彙來生成該概念。
- LoRA (Low-Rank Adaptation):一種參數高效的微調技術,只訓練添加到模型原有權重上的少量低秩矩陣,就能有效適應新概念,同時保持原有模型能力。
↑