iPAS AI應用規劃師 考試重點
L21103 生成式AI技術與應用
主題分類
1
生成式 AI 基礎概念
2
核心生成模型 (GAN, VAE, Transformer, Diffusion)
3
文本生成技術與應用
4
圖像/視覺生成技術與應用
5
程式碼與其他生成應用
6
提示工程與模型微調
7
生成式 AI 應用與整合
8
挑戰、倫理與未來趨勢
#1
★★★★★
生成式 AI (GenAI - Generative Artificial Intelligence) - 基本定義
核心概念
生成式 AI 是一種人工智慧,專注於學習現有數據的模式和結構,並利用這些知識創造出全新的、原創的內容,例如文本、圖像、音樂、程式碼等。其核心能力是「生成」而非僅僅是「分類」或「預測」。
#2
★★★★
生成式 AI vs. 鑑別式 AI (Discriminative AI)
核心差異 (L11401)
- 生成式 AI: 學習數據的潛在分佈 P(X,Y) 或 P(X),目標是生成新的數據樣本。例如:生成一張貓的圖片。
- 鑑別式 AI: 學習決策邊界或條件機率 P(Y|X),目標是區分或分類輸入數據。例如:判斷一張圖片是貓還是狗。
#3
★★★★★
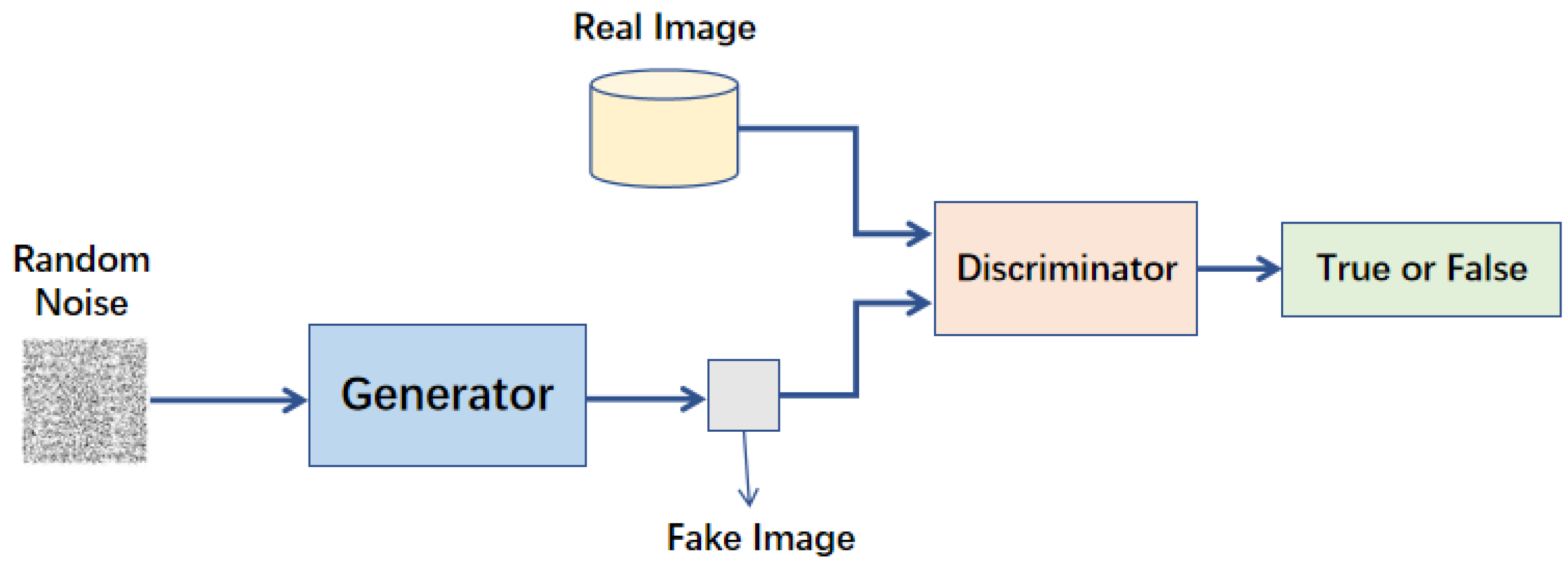
生成對抗網路 (GAN - Generative Adversarial Network)
核心生成模型 (樣題 Q11, Q22)
GAN 由兩個互相競爭的神經網路組成:
- 生成器 (Generator): 試圖生成逼真的假數據(例如圖像),以欺騙判別器。
- 判別器 (Discriminator): 試圖區分真實數據和生成器生成的假數據。
#4
★★★
GAN 的挑戰
模型限制
雖然 GAN 很強大,但也存在一些訓練挑戰:
- 訓練不穩定: 生成器和判別器的訓練需要仔細平衡,否則可能無法收斂。
- 模式崩潰 (Mode Collapse): 生成器只學會生成少數幾種特別逼真的樣本,而無法涵蓋數據的全部多樣性。
- 梯度消失 (Vanishing Gradients): 判別器過於強大時,生成器可能無法獲得有效的梯度進行學習。
#5
★★★
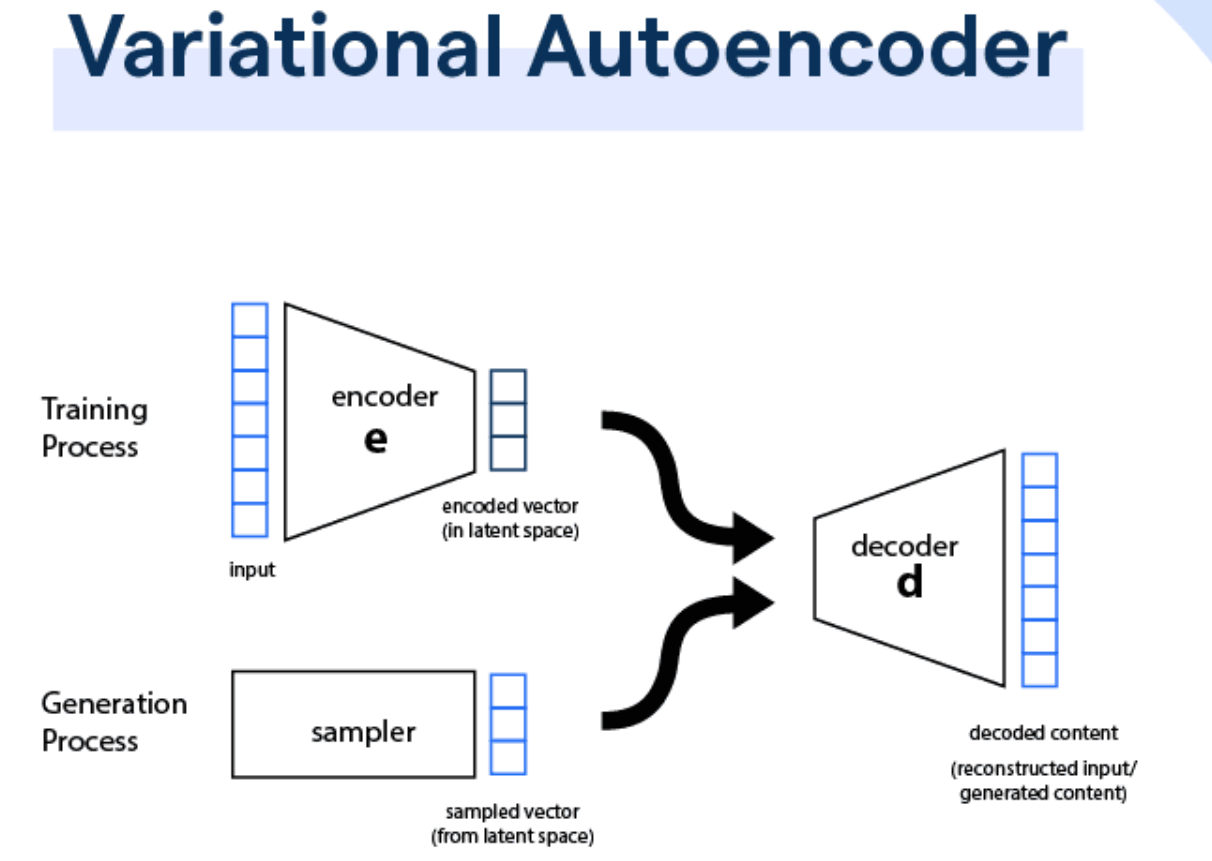
變分自動編碼器 (VAE - Variational Autoencoder)
核心生成模型
VAE 也是一種生成模型,基於自動編碼器 (Autoencoder) 架構,包含:
- 編碼器 (Encoder): 將輸入數據壓縮到一個低維度的潛在空間 (Latent Space),但輸出的是潛在分佈的參數(均值和方差)。
- 解碼器 (Decoder): 從潛在空間中採樣一個點,並將其重建回原始數據空間。
#6
★★★★★
Transformer 模型
核心生成模型 / 基礎架構
Transformer 模型最初為自然語言處理設計,其核心是自注意力機制 (Self-Attention Mechanism),能夠捕捉序列中長距離的依賴關係。它已成為許多大型語言模型 (LLM - Large Language Model) 如 GPT 的基礎架構,並被應用於圖像生成(如 ViT)和擴散模型中。
#7
★★★★
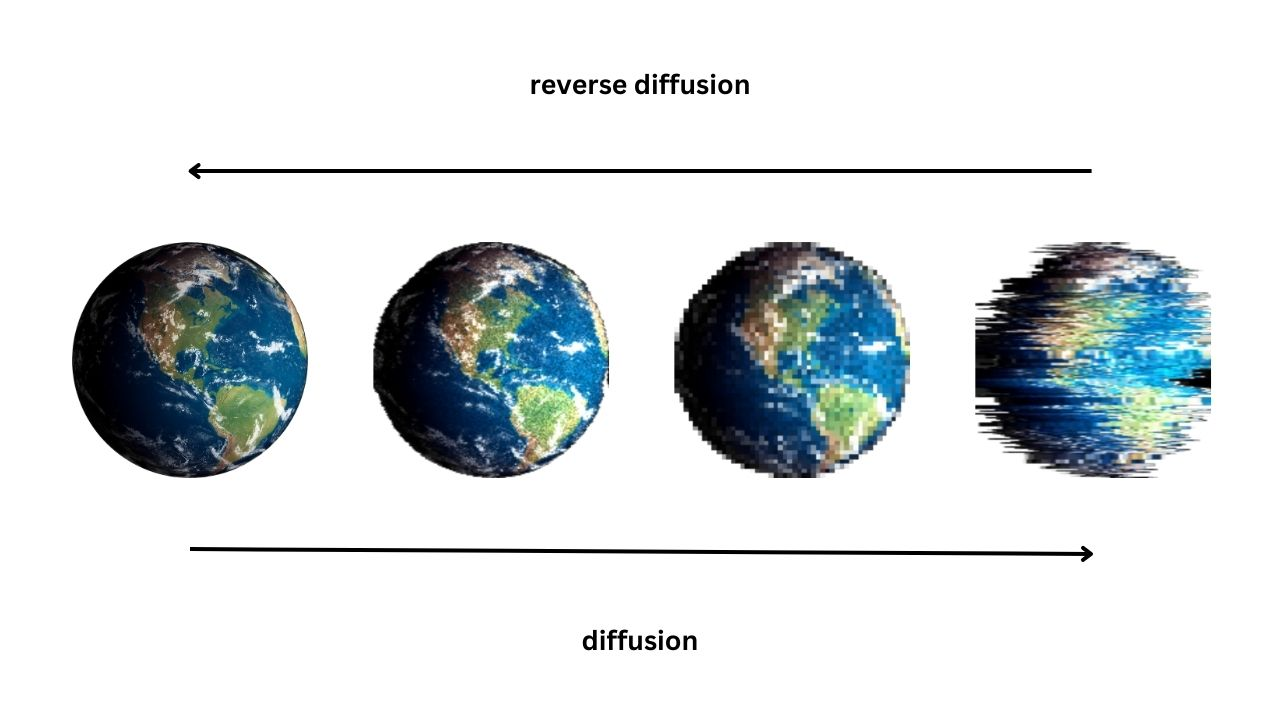
擴散模型 (Diffusion Model)
核心生成模型
擴散模型通過兩個過程生成數據:
- 前向過程 (Forward Process): 逐步向真實數據中添加高斯噪聲,直到數據變成純噪聲。
- 反向過程 (Reverse Process): 學習從純噪聲開始,逐步去除噪聲,最終還原出逼真的數據。
#8
★★★★
大型語言模型 (LLM - Large Language Model)
文本生成核心
LLM 是指在海量文本數據上訓練的、具有數十億甚至數兆參數的深度學習模型(通常基於 Transformer 架構)。它們展現出強大的自然語言理解和生成能力。代表模型包括 OpenAI 的 GPT 系列 (Generative Pre-trained Transformer)、Google 的 BERT (用於理解) 和 LaMDA/PaLM 等。ChatGPT (L12201) 是基於 GPT 的對話式應用。
#9
★★★★
文本生成應用
主要用途 (L12201, Q13)
生成式 AI 在文本處理方面應用廣泛:
- 內容創作: 寫作文章、郵件、故事、詩歌、廣告文案等。
- 對話系統 / 聊天機器人: 如 ChatGPT。
- 文本摘要: 自動生成長篇文章的摘要。
- 機器翻譯。
- 問答系統。
- 程式碼生成 (見分類 5)。
- 生成文本本身 (樣題 Q13)。
#10
★★★★★
圖像生成應用
主要用途 (L12201, Q12)
生成式 AI 能夠根據文本描述或其他輸入生成全新的圖像:
- 藝術創作與設計: 生成獨特的藝術作品、設計素材。
- 文本到圖像生成 (Text-to-Image Generation): 如 Midjourney, Stable Diffusion, DALL-E。
- 圖像編輯與修復 (Inpainting/Outpainting): 移除/替換圖像部分內容,或擴展圖像邊界。
- 風格轉換 (Style Transfer): 將一張圖像的內容與另一張圖像的風格結合。
- 超解析度 (Super-Resolution): 提高低解析度圖像的清晰度。
- 虛擬現實/元宇宙內容創建 (樣題 Q12)。
- 生成合成數據用於訓練其他模型 (樣題 Q13, Q14)。
#11
★★★★
文本到圖像模型 (Text-to-Image Models)
重要模型類型
這類模型接受自然語言描述(提示)作為輸入,並生成符合描述的圖像。通常結合了強大的語言模型(如 Transformer 的變體)來理解文本提示,以及圖像生成模型(如 GAN 或擴散模型)來合成視覺內容。代表性的工具包括 Midjourney, Stable Diffusion, DALL-E 2/3。
#12
★★★
程式碼生成 (Code Generation)
應用領域 (L12201)
利用大型語言模型根據自然語言描述或現有程式碼片段自動生成程式碼。可以提高開發效率、輔助程式設計、自動完成、除錯等。代表性工具包括 GitHub Copilot, VS Code for Copilot, Copilot Studio (L12201)。
#13
★★★
合成數據生成 (Synthetic Data Generation)
應用領域 (Q13, Q14)
使用生成式 AI 創建人工數據,這些數據在統計特性上與真實數據相似。主要用途:
- 數據增強: 擴充有限的真實訓練數據集。
- 隱私保護: 在不暴露真實敏感數據的情況下共享或使用數據。
- 填補數據空白: 生成難以獲取或不存在的數據場景(例如,模擬罕見的故障情況或極端駕駛條件 Q14)。
- 模擬數據分佈 (樣題 Q13)。
#14
★★
其他生成應用 (音樂, 影片)
應用領域
生成式 AI 的應用還擴展到:
- 音樂生成: 創作新的旋律、和聲、甚至完整樂曲。
- 影片生成: 根據文本或圖像生成短影片片段,或進行影片風格轉換、編輯等(例如 Sora)。
- 3D 模型生成: 根據描述或草圖生成三維模型。
#15
★★★★★
提示工程 (Prompt Engineering)
關鍵交互技術 (L12202)
提示工程是指設計和優化輸入提示 (Prompt),以引導生成式 AI 模型(尤其是 LLM)產生期望的、高質量的輸出。有效的提示應該清晰、具體,並可能包含上下文訊息、範例或格式要求。這是善用生成式 AI 工具的核心技能 (L12202)。
#16
★★★★
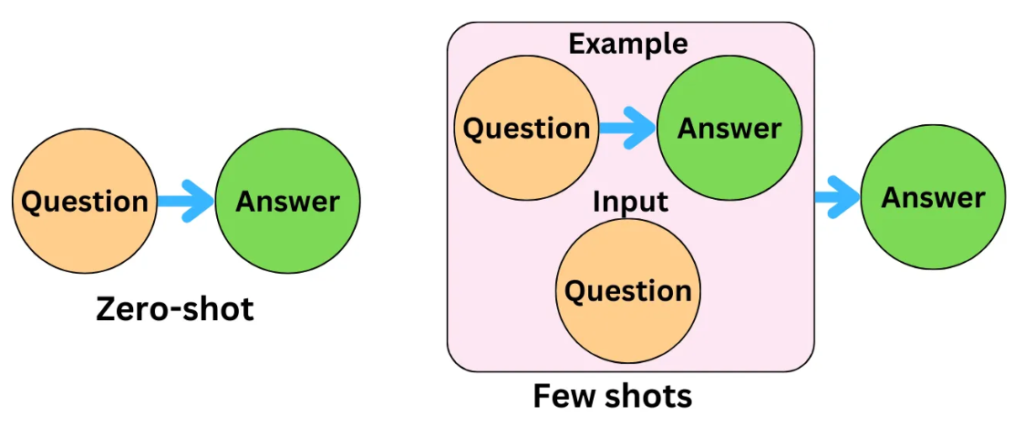
提示技巧 (Zero-shot, Few-shot, CoT)
常用 Prompting 方法
- 零樣本提示 (Zero-shot Prompting): 直接給出任務描述,不提供任何範例。
- 少樣本提示 (Few-shot Prompting): 在提示中提供少量(1 到 N 個)相關任務的範例,引導模型理解任務要求和輸出格式。
- 思維鏈提示 (CoT - Chain-of-Thought Prompting): 引導模型逐步思考,展示解決問題的中間步驟,尤其適用於需要推理的任務。
#17
★★★★
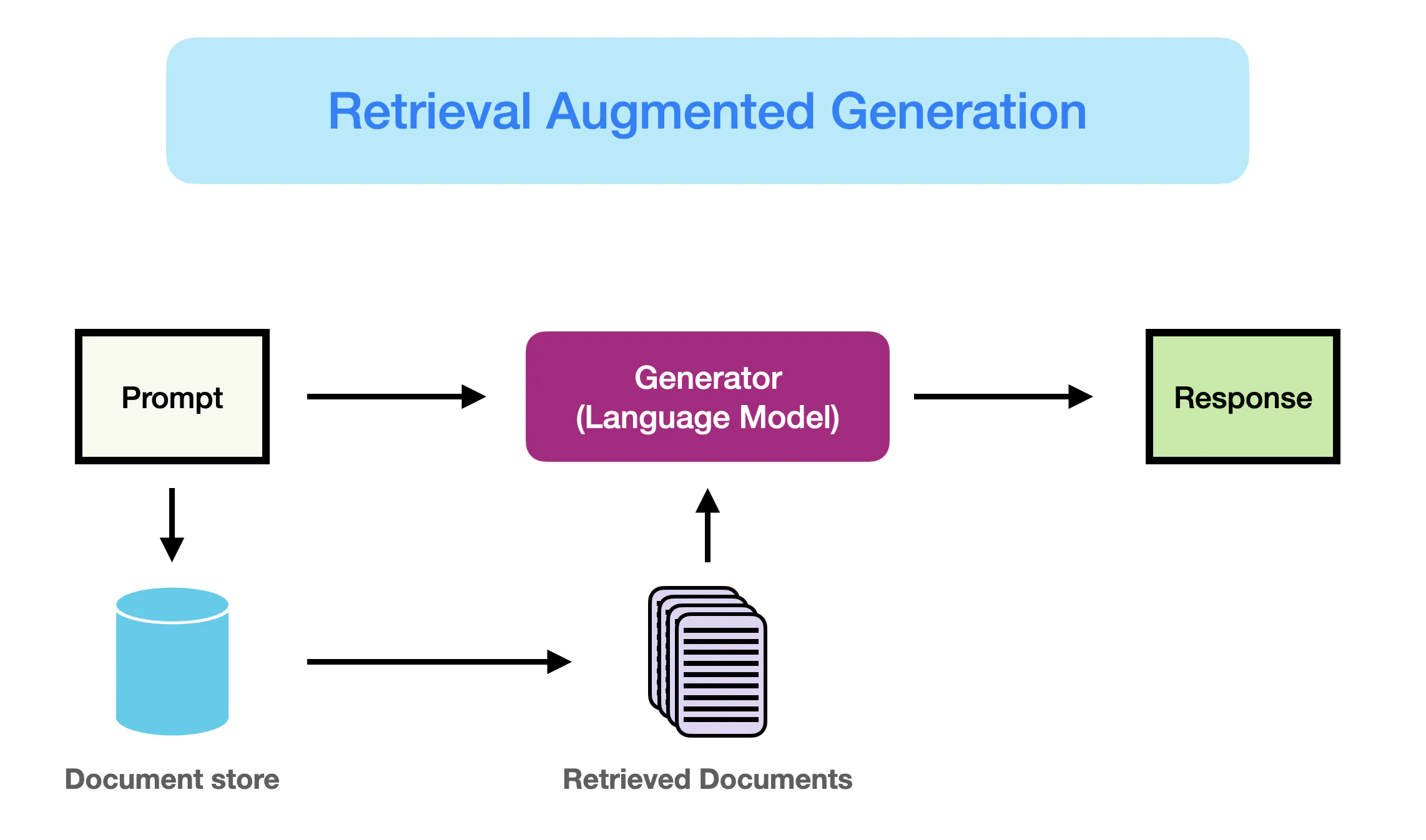
檢索增強生成 (RAG - Retrieval-Augmented Generation)
模型增強技術 (L12202)
RAG 是一種結合了資訊檢索和文本生成的技術。當收到提示時,系統首先從外部知識庫(如文件、資料庫)中檢索相關訊息,然後將這些檢索到的訊息與原始提示一起提供給生成模型,以產生更準確、更基於事實的回答。有助於解決 LLM 的知識侷限和幻覺問題。
#18
★★★
模型微調 (Fine-tuning)
模型適應化
將已經在大型通用數據集上預訓練好的模型(例如 GPT-3),在特定任務或領域的小型數據集上進行進一步訓練。這使得模型能夠適應特定任務的需求和數據特性,通常能獲得比零樣本或少樣本提示更好的性能。需要額外的數據和計算資源。
#19
★★★★
常見生成式 AI 工具
應用實例 (L12201)
考試範圍內提及的常見工具包括:
- 文本生成/對話: OpenAI API, ChatGPT
- 圖像生成: Midjourney, (Stable Diffusion, DALL-E 未明確列出但重要)
- 程式碼生成/輔助: Copilot Studio, VS Code for Copilot, Github Copilot
#20
★★★
生成式 AI 在不同產業的應用
應用場景
生成式 AI 可應用於多個產業,例如:
- 媒體與娛樂: 內容創作、特效生成、個性化推薦。
- 行銷與廣告: 廣告文案生成、圖像素材設計、個性化行銷內容。
- 軟體開發: 程式碼生成、自動測試、文檔撰寫。
- 教育: 個性化學習材料、輔助教學工具、自動評分。
- 醫療保健: 合成醫療數據、藥物發現、輔助診斷報告生成。
- 金融: 市場報告生成、風險模擬、反欺詐。
#21
★★★
生成式 AI 整合應用 (L11402)
技術結合
生成式 AI 可以與其他 AI 技術(如鑑別式 AI)整合,以實現更複雜的功能。例如:
- 使用生成模型創建多樣化的模擬場景(如交通 Q14)來訓練自動駕駛的感知模型(鑑別式)。
- 結合語音辨識(鑑別式)和文本生成(生成式)來創建語音助手。
- 利用圖像辨識(鑑別式)分析用戶上傳的圖片,再由圖像生成(生成式)模型進行風格轉換或編輯。
#22
★★★★
挑戰:幻覺 (Hallucination)
模型限制
幻覺是指生成式 AI 模型(尤其是 LLM)產生看似合理但實際上是錯誤的、不準確的或無意義的資訊。模型可能會「編造」事實、引用不存在的來源或產生與輸入提示無關的內容。這是使用生成式 AI 時需要注意的主要風險之一。RAG 技術有助於緩解此問題。
#23
★★★★
挑戰:內容質量與可控性
模型限制 (Q23)
確保生成內容的質量、一致性和準確性是一個挑戰。模型輸出可能重複、缺乏邏輯、包含偏見或不符合特定要求。如何有效控制模型的輸出風格、語氣和內容仍然是研究重點。使用生成內容時應適當標註引用來源以確保品質和學術誠信 (Q23)。
#24
★★★★
挑戰:計算資源需求
模型限制 (Q26)
訓練大型生成模型需要巨大的計算資源 (GPU/TPU)、大量的數據和長時間的訓練。即使是推理(使用模型生成內容)也可能需要相當大的計算能力,尤其對於擴散模型等。企業需要具備高效能運算資源和彈性儲存空間來有效支援 GenAI 運行 (Q26)。
#25
★★★★★
倫理考量:偏見與歧視
重要倫理議題 (L12303, Q30)
生成式 AI 模型可能從訓練數據中學習並放大社會偏見,導致生成的內容帶有歧視性(例如,針對特定性別、種族或群體的刻板印象)。在開發和部署 GenAI 時,必須識別和減輕這些偏見,確保公平性。這是 GenAI 風險管理中的倫理風險核心 (Q30)。
#26
★★★★
倫理考量:錯誤資訊與濫用 (Misinformation & Abuse)
重要倫理議題
生成式 AI 可能被惡意用於大規模製造和傳播虛假資訊、宣傳或仇恨言論。深度偽造 (Deepfake) 技術(使用 GenAI 生成逼真的假影片或音訊)尤其令人擔憂,可能被用於詐騙、誹謗或政治操縱。
#27
★★★★
倫理考量:智慧財產權與版權
重要倫理議題
生成式 AI 的訓練數據通常包含受版權保護的作品,而其生成的內容是否構成侵權,以及AI 生成內容的版權歸屬問題,目前仍在法律和倫理層面存在爭議。使用時應注意合理使用和來源標註 (Q23)。
#28
★★★
倫理考量:數據隱私與安全
重要倫理議題 (L12303, Q28)
訓練生成式 AI 需要大量數據,其中可能包含個人敏感資訊。需要確保數據的收集、儲存和使用符合隱私法規(如 GDPR)。模型本身也可能記憶並洩露訓練數據中的隱私資訊。在導入過程中,權限控管與合規要求是資料安全與隱私保護的重要考量 (Q28)。
#29
★★★
未來趨勢:多模態生成 (Multimodal Generation)
發展方向
未來的生成式 AI 將更能處理和生成多種模態的數據,實現更複雜的交互和內容創作。例如,根據文本描述生成帶有配樂的影片,或者根據圖像生成詳細的文字描述和相關音效。
#30
★★★
未來趨勢:更強的可控性與個性化
發展方向
研究方向包括開發更精確的控制機制,讓用戶能夠更細緻地指定生成內容的風格、語氣、結構等。同時,模型將更能適應個人用戶的偏好和需求,提供更個性化的生成結果。
沒有找到符合條件的重點。
↑