iPAS AI應用規劃師 經典題庫
L21102 電腦視覺技術與應用
出題方向
1
電腦視覺基本概念與範疇
2
圖像獲取與前處理
3
圖像特徵提取與描述
4
核心電腦視覺任務
5
深度學習在電腦視覺的應用
6
常見電腦視覺模型架構
7
電腦視覺應用場景
8
電腦視覺評估指標與挑戰
#1
★★★★★
電腦視覺 (Computer Vision, CV) 的主要目標是什麼?
答案解析
電腦視覺是一個跨學科領域,旨在使電腦能夠從數位圖像或影像中獲取高層次的理解。其目標是模仿人類視覺系統的功能,讓機器能夠「看見」和解釋視覺世界,進而執行諸如物體識別、場景理解、活動識別等任務。選項 A 更接近電腦圖學 (Computer Graphics) 的目標。選項 C 和 D 分別涉及圖像處理和光學工程。
#2
★★★★
在電腦視覺中,將彩色圖像轉換為灰階圖像 (Grayscale Conversion) 的主要目的是什麼?
答案解析
彩色圖像通常包含三個顏色通道(如 RGB:紅、綠、藍),而灰階圖像只有一個亮度 (Intensity) 通道。將彩色圖像轉換為灰階圖像是一種常見的圖像前處理步驟,主要有以下原因:
- 降低複雜度:處理單一通道比處理三個通道更簡單,計算量更小。
- 減少維度:減少了需要處理的數據量。
- 任務不敏感:許多電腦視覺任務(如邊緣檢測、早期物體識別的某些特徵提取)主要依賴於圖像的亮度變化,而對顏色資訊相對不敏感。

#3
★★★★★
SIFT (Scale-Invariant Feature Transform) 是一種著名的圖像特徵描述子,它具有對哪些變換保持不變性的特點?
答案解析
SIFT 是一種用於偵測和描述圖像局部特徵的演算法。其設計目標是使提取出的特徵(關鍵點及其描述子)在圖像發生某些幾何或光學變換時仍能保持穩定和可匹配。SIFT 特徵具有以下主要不變性:
- 尺度不變性 (Scale Invariance): 無論物體在圖像中放大或縮小,都能偵測到相似的關鍵點。
- 旋轉不變性 (Rotation Invariance): 即使圖像被旋轉,也能偵測到相似的關鍵點並生成一致的描述子。
- 亮度變換不變性 (Illumination Invariance): 對光照強度的變化具有穩健性。
- 視角變換部分不變性 (Affine/Viewpoint Invariance): 對於一定程度的視角變化(仿射變換)也能保持穩定。
#4
★★★★★
在電腦視覺任務中,「圖像分割」(Image Segmentation) 的目標是什麼?
答案解析
圖像分割是電腦視覺中的一項基礎且重要的任務,其目標是將圖像劃分成多個不同的區域或片段 (segments),每個區域對應圖像中的一個特定物體或部分。與圖像分類(判斷整張圖像的類別)和物體偵測(用邊界框定位物體)不同,圖像分割旨在實現像素級別的理解,即為圖像中的每個像素分配一個語意標籤(例如,「貓」、「狗」、「天空」、「道路」)。常見的圖像分割類型包括:
- 語意分割 (Semantic Segmentation): 將屬於同一物體類別的所有像素標記為相同類別(不區分同類物體的個體)。
- 實例分割 (Instance Segmentation): 在語意分割的基礎上,進一步區分同類物體的個體實例(例如,標記出圖中的「貓1」、「貓2」)。
- 全景分割 (Panoptic Segmentation): 結合語意分割和實例分割,為圖像中的每個像素分配一個語意標籤和一個實例 ID。

#5
★★★★★
卷積神經網路 (Convolutional Neural Network, CNN) 在電腦視覺領域取得巨大成功的主要原因是?
答案解析
CNN 的設計借鑒了生物視覺皮層的處理機制,其核心優勢在於:
- 局部感受野 (Local Receptive Fields): 卷積核(濾波器)只關注輸入圖像的一小塊區域,提取局部特徵。
- 權重共享 (Weight Sharing): 同一個卷積核在圖像的不同位置滑動,使用相同的權重參數。這大大減少了模型的參數數量(相比全連接網路),降低了過擬合風險,並使得模型對物體的平移具有一定的不變性。
- 池化層 (Pooling Layers): 通常在卷積層之後使用,通過降採樣(如最大池化 Max Pooling 或平均池化 Average Pooling)來降低特徵圖的空間維度,進一步減少計算量和參數,同時增強模型對微小位移和形變的穩健性。
- 階層式特徵學習 (Hierarchical Feature Learning): 淺層卷積層通常學習邊緣、角點等低階特徵,深層卷積層則基於低階特徵組合出更複雜、更抽象的高階特徵(如物體部件、完整物體)。
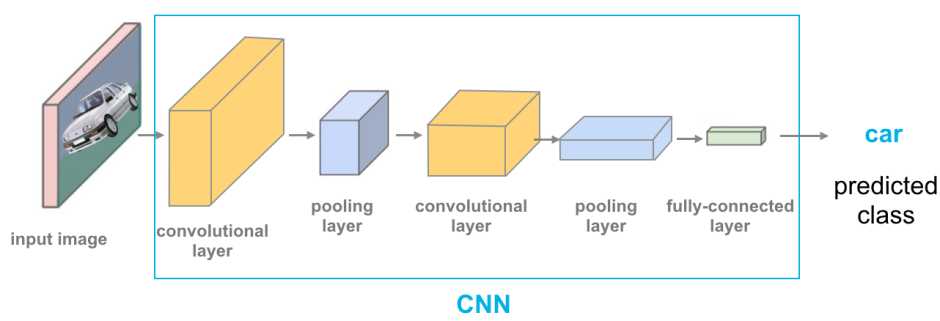
#6
★★★★
在 CNN 架構中,卷積層 (Convolutional Layer) 的主要作用是什麼?
答案解析
卷積層是 CNN 的核心組件。它包含多個可學習的濾波器(也稱為卷積核 Kernels)。每個濾波器是一個小的權重矩陣,它在輸入數據(如圖像或上一層的特徵圖)上按指定步長滑動,與滑動窗口內的數值進行逐元素相乘再求和(卷積運算),得到輸出特徵圖 (Feature Map) 上的一個值。每個濾波器負責偵測一種特定的局部模式或特徵(如邊緣、角點、紋理等)。通過使用多個不同的濾波器,卷積層可以提取出輸入數據的多種局部特徵。選項 B 描述的是池化層 (Pooling Layer) 的作用。選項 C 描述的是激活函數 (Activation Function) 的作用(通常跟在卷積層或全連接層之後)。選項 D 描述的是全連接層 (Fully Connected Layer) 或輸出層的作用。
#7
★★★★
以下哪項是電腦視覺在自動駕駛 (Autonomous Driving) 領域的關鍵應用?
答案解析
電腦視覺是實現自動駕駛的關鍵技術之一,主要用於感知和理解車輛周圍的環境。其應用包括:
- 車道線偵測 (Lane Detection): 識別道路上的車道標線,輔助車輛保持在車道內行駛。
- 交通號誌/標誌識別 (Traffic Sign/Light Recognition): 識別紅綠燈、速限標誌、停止標誌等交通控制信號。
- 物體偵測與識別 (Object Detection and Recognition): 偵測並識別周圍的其他車輛、行人、自行車騎士、障礙物等。
- 可通行區域分割 (Drivable Area Segmentation): 判斷哪些區域是車輛可以安全行駛的。
- 深度估計/3D 場景理解 (Depth Estimation / 3D Scene Understanding): 估計物體的距離和場景的 3D 結構。
#8
★★★★
在評估物體偵測 (Object Detection) 任務的模型效能時,常用的指標 mAP (mean Average Precision) 是如何計算的?
答案解析
mAP (mean Average Precision) 是物體偵測領域最常用的標準評估指標。其計算步驟如下:
- 對於每一個物體類別,根據模型輸出的偵測框(按置信度排序)和真實標註框 (Ground Truth),計算其 Precision-Recall 曲線。通常通過設定不同的 IoU (Intersection over Union) 閾值(如 0.5)來判斷偵測是否為 True Positive。
- 計算該類別下的平均精確率 (Average Precision, AP)。AP 通常是 Precision-Recall 曲線下的面積。具體計算方法有多種(如 11 點插值法、所有點插值法),PASCAL VOC 和 COCO 競賽有不同的標準。
- 對所有物體類別的 AP 值取算術平均數,得到最終的 mAP。

#9
★★★
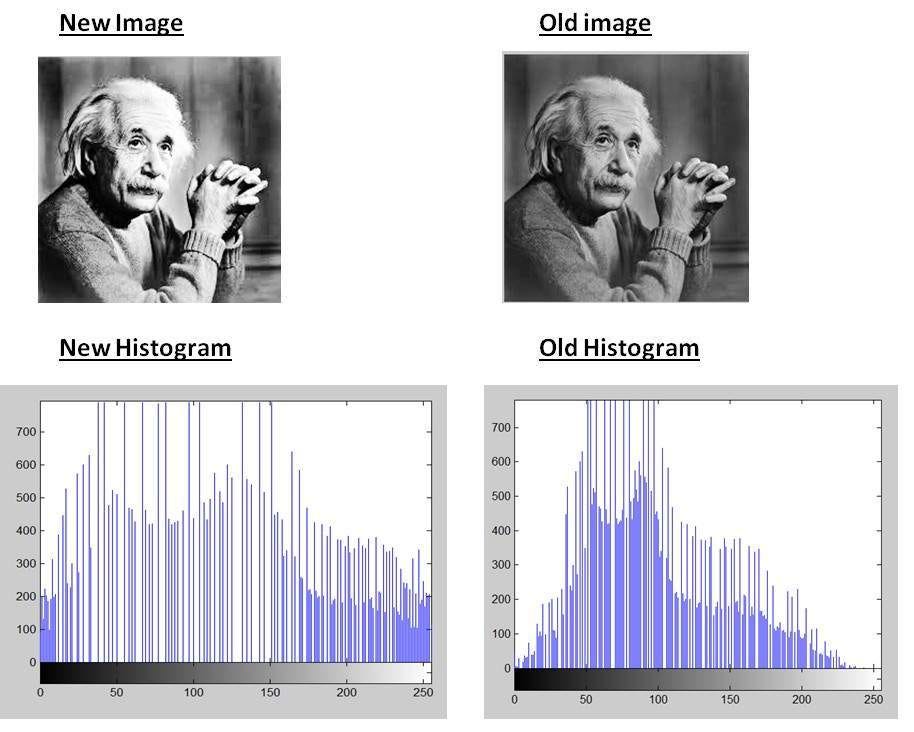
圖像增強 (Image Enhancement) 技術,如直方圖等化 (Histogram Equalization),其主要目的是?
答案解析
圖像增強是圖像處理的一個分支,旨在通過修改圖像的像素值來改善其視覺效果,或使其更適合於特定的應用。直方圖等化是一種常用的對比度增強技術,它通過重新分佈圖像的像素強度值,使得強度值的直方圖盡可能平坦,從而擴展圖像的動態範圍,使原本過暗或過亮的區域細節更清晰。其他的圖像增強技術還包括對比度拉伸、伽馬校正、銳化濾波等。
#10
★★★
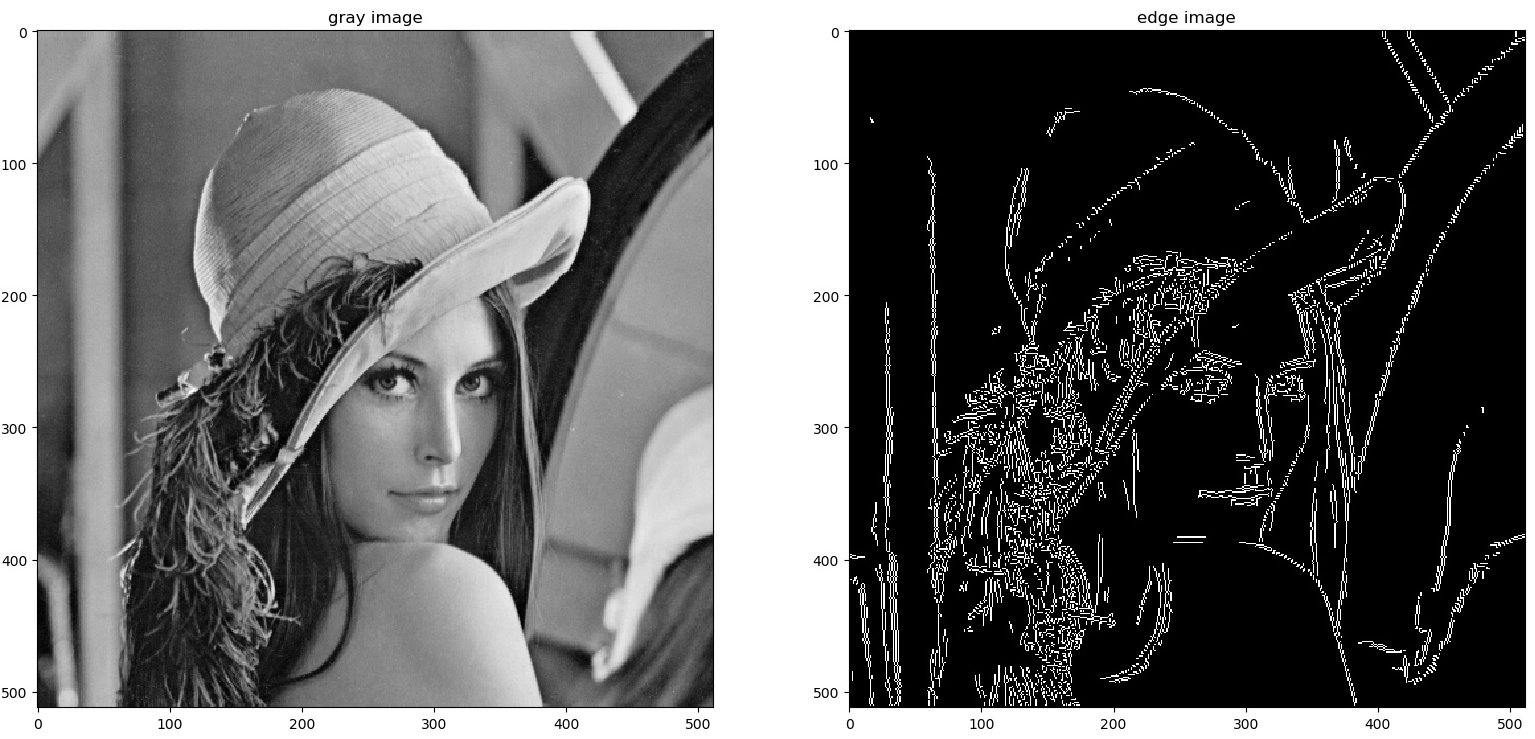
邊緣偵測 (Edge Detection) 在電腦視覺中的主要作用是?
答案解析
邊緣是圖像中像素強度(亮度、顏色或紋理)發生急遽變化的位置,通常對應於物體的輪廓或不同區域的分界線。邊緣偵測旨在識別並定位這些邊緣像素,生成邊緣圖 (Edge Map)。邊緣包含了圖像重要的結構資訊,是許多後續視覺任務(如物體識別、圖像分割、特徵提取)的基礎。常用的邊緣偵測算子包括 Sobel、Prewitt、Laplacian 和 Canny 等。Canny 算子因其較好的偵測效果和對雜訊的抑制能力而被廣泛使用。
#11
★★★★
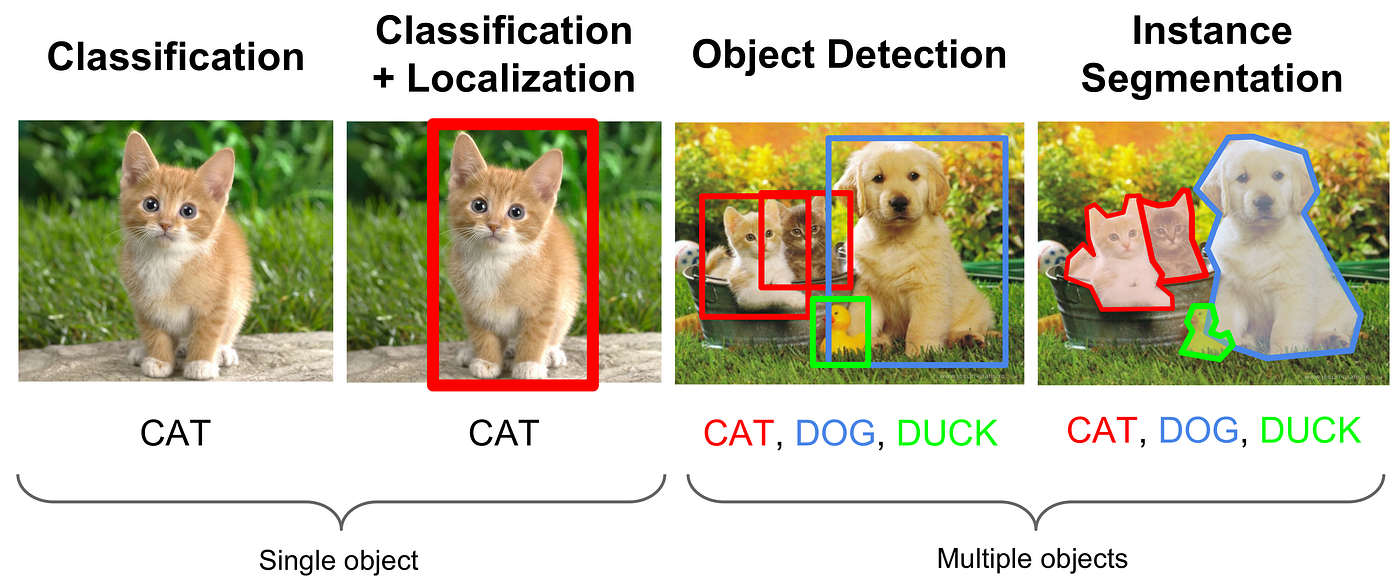
物體偵測 (Object Detection) 與圖像分類 (Image Classification) 的主要區別在於?
答案解析
圖像分類旨在為整張圖像分配一個類別標籤(例如,這是一張「貓」的圖片)。而物體偵測是一個更複雜的任務,它需要在圖像中找出所有感興趣的物體實例,並為每個實例提供兩個資訊:1. 物體類別(例如,「貓」、「狗」、「汽車」);2. 物體位置,通常用一個緊密包圍該物體的邊界框 (Bounding Box) 來表示。因此,物體偵測不僅要知道圖像裡有什麼,還要知道它們在哪裡。
#12
★★★★
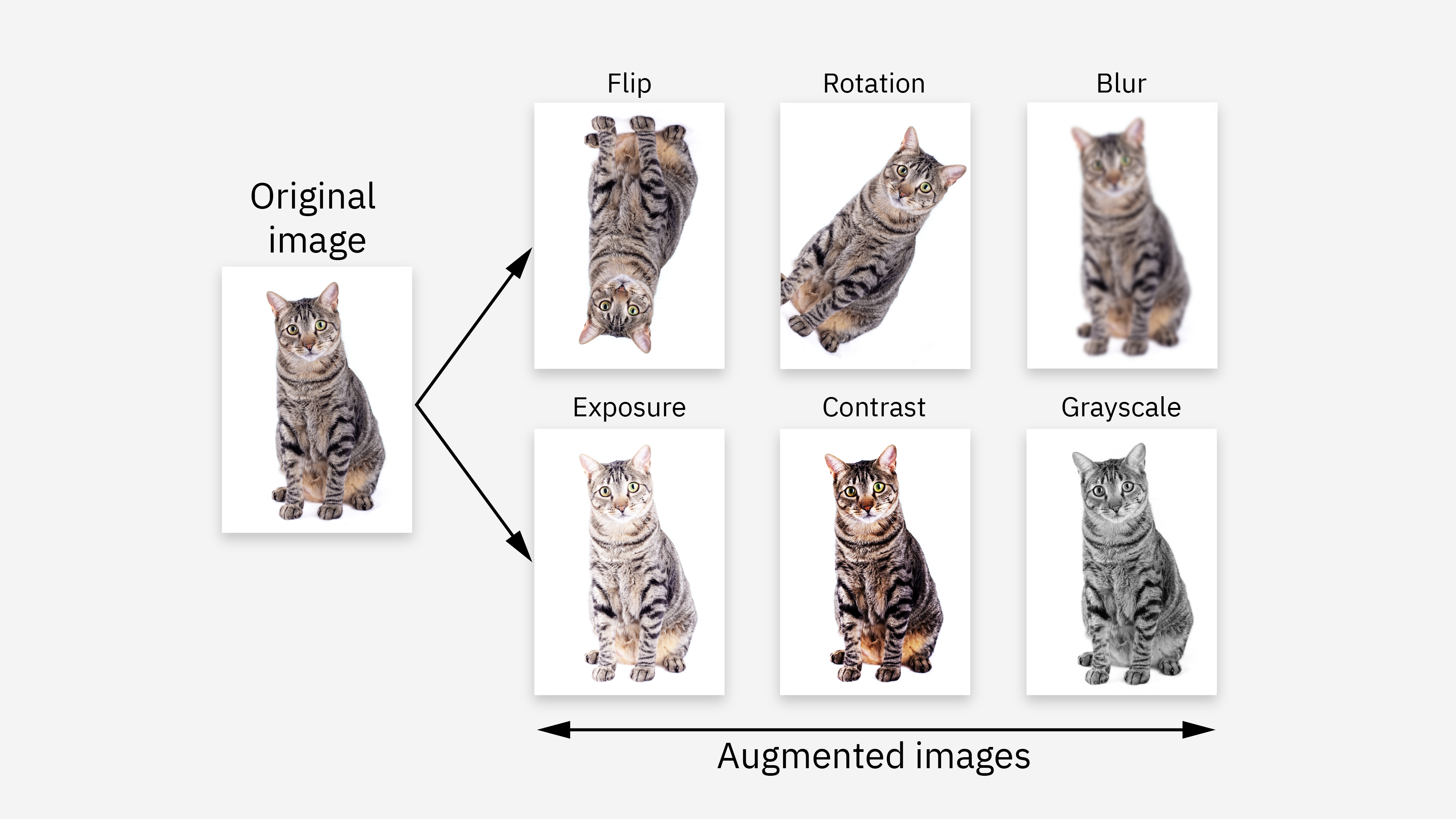
資料增強 (Data Augmentation) 在訓練深度學習電腦視覺模型時的作用是?
答案解析
深度學習模型通常需要大量的標註數據才能達到良好的效能。在數據量有限的情況下,模型容易產生過擬合 (Overfitting),即模型過度學習了訓練數據的特性,但在未見過的測試數據上表現不佳。資料增強是一種常用的正則化 (Regularization) 技術,通過對原始訓練圖像應用一系列隨機的、保持標籤不變的幾何或光學變換(例如,水平翻轉、隨機裁剪、小角度旋轉、亮度/對比度/飽和度調整),來生成新的、看似不同的訓練樣本。這相當於人工地增加了訓練數據的多樣性,迫使模型學習對這些變換具有不變性的更魯棒的特徵,從而提高模型的泛化能力 (Generalization Ability) 並減輕過擬合。
#13
★★★★
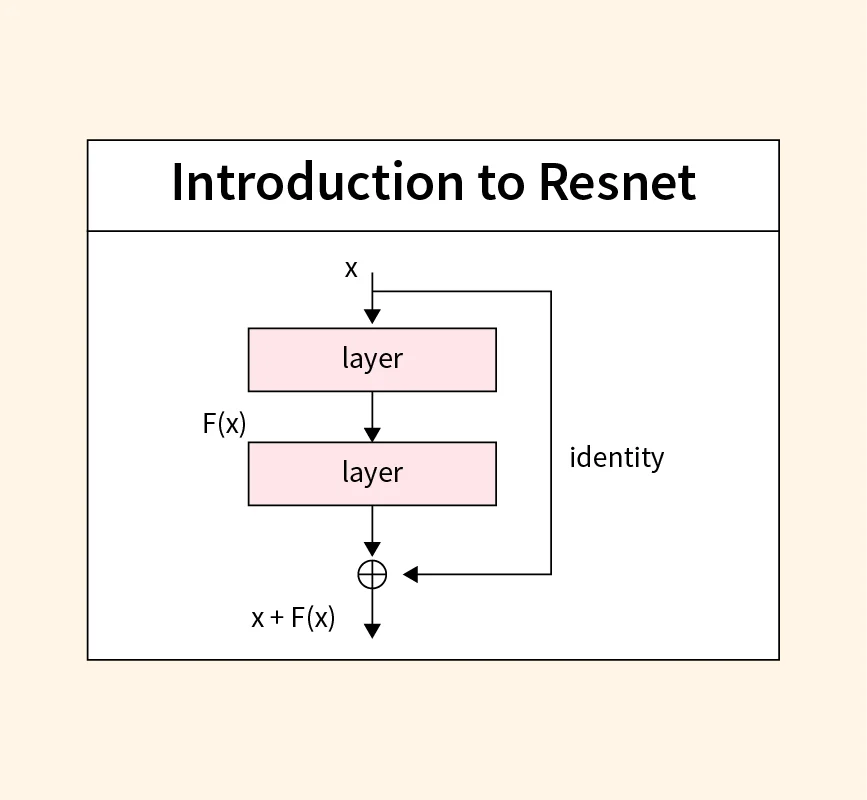
ResNet (Residual Network) 模型架構引入的主要創新是?
答案解析
在 ResNet 出現之前,人們發現簡單地堆疊更多層數的深度神經網路,在達到一定深度後,訓練誤差和測試誤差反而會增加,這種現象稱為網路退化 (Degradation Problem),這並非由過擬合引起。ResNet 的核心思想是引入殘差學習 (Residual Learning)。它不再讓網路層直接學習目標映射 H(x),而是學習一個殘差映射 F(x) = H(x) - x,然後目標映射變為 H(x) = F(x) + x。這個 " + x " 的操作通過一個跳躍連接 (Skip Connection) 來實現,即將輸入 x 直接添加到 F(x) 的輸出上。這種結構使得梯度更容易回傳到淺層網路,極大地緩解了梯度消失問題,並使得訓練非常深的網路(如幾十層甚至上百層)成為可能,有效解決了退化問題。選項 A 是 GoogLeNet/Inception 的特點。選項 B 是 Vision Transformer (ViT) 的特點。選項 D 是 AlexNet 和後續一些輕量化網路的特點。
#14
★★★
人臉辨識 (Face Recognition) 技術通常包含哪兩個主要步驟?
答案解析
典型的人臉辨識系統流程通常包括:
- 人臉偵測 (Face Detection): 在輸入的圖像或影像中找到人臉的位置和範圍(通常是用邊界框標出)。這是第一步,確定哪裡有人臉。
- (可選)人臉對齊 (Face Alignment): 根據偵測到的人臉關鍵點(如眼睛、鼻子、嘴角)進行幾何校正,將人臉旋轉、縮放到一個標準的姿態,以減少姿態變化對後續識別的影響。
- 人臉特徵提取 (Face Feature Extraction): 從對齊後的人臉圖像中提取具有區分性的特徵向量(也稱為人臉嵌入 Face Embedding)。現代方法通常使用深度學習模型(如 FaceNet, ArcFace)來學習這種表示。
- 人臉比對/識別 (Face Matching/Identification):
- 人臉驗證 (Verification, 1:1 比對): 判斷兩張人臉圖像是否屬於同一個人(例如,人臉解鎖)。通常計算兩個人臉特徵向量的相似度,並與閾值比較。
- 人臉識別 (Identification, 1:N 比對): 將輸入的人臉特徵向量與資料庫中儲存的多個已知人臉特徵向量進行比對,找出最相似的匹配項(例如,在人群中尋找某個人)。
#15
★★★
交併比 (Intersection over Union, IoU) 是評估物體偵測和圖像分割常用的指標,它計算的是?
答案解析
交併比 (IoU),也稱為 Jaccard index,是衡量兩個區域重疊程度的指標。計算公式為:
IoU = Area(Intersection) / Area(Union)
其中,Area(Intersection) 是預測區域(例如模型輸出的邊界框或分割掩碼)和真實標註區域(Ground Truth)的交集面積,Area(Union) 是它們的併集面積。IoU 的值域在 0 到 1 之間,值越接近 1 表示兩個區域重疊度越高,預測越準確;值為 0 表示兩個區域完全沒有重疊。在物體偵測中,通常會設定一個 IoU 閾值(例如 0.5 或 0.7),只有當預測框與真實框的 IoU 大於該閾值時,才認為該偵測是正確的 (True Positive)。
IoU = Area(Intersection) / Area(Union)
其中,Area(Intersection) 是預測區域(例如模型輸出的邊界框或分割掩碼)和真實標註區域(Ground Truth)的交集面積,Area(Union) 是它們的併集面積。IoU 的值域在 0 到 1 之間,值越接近 1 表示兩個區域重疊度越高,預測越準確;值為 0 表示兩個區域完全沒有重疊。在物體偵測中,通常會設定一個 IoU 閾值(例如 0.5 或 0.7),只有當預測框與真實框的 IoU 大於該閾值時,才認為該偵測是正確的 (True Positive)。

#16
★★
高斯濾波 (Gaussian Filtering) 在圖像處理中常用於?
答案解析
高斯濾波是一種線性平滑濾波器,其權重(卷積核)由高斯函數確定。中心像素的權重最大,距離中心越遠的像素權重越小。高斯濾波的主要作用是圖像平滑 (Image Smoothing) 和 雜訊抑制 (Noise Reduction)。由於高斯函數在頻域上是低通濾波器,它可以有效地衰減圖像中的高頻成分,而高頻成分通常對應於圖像的細節和雜訊。因此,高斯濾波常用於預處理步驟中,以減少雜訊對後續處理(如邊緣偵測)的影響。但過度平滑會導致圖像模糊,損失細節。

#17
★★★★
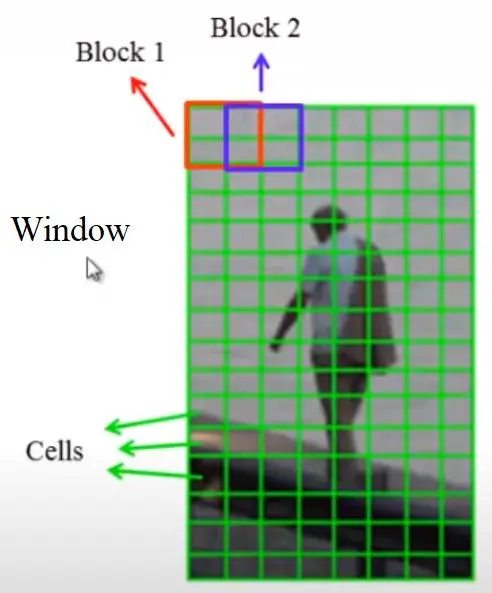
HOG (Histogram of Oriented Gradients) 是一種常用於什麼任務的特徵描述子?
答案解析
方向梯度直方圖 (HOG) 是一種用於物體偵測的特徵描述子。它通過計算圖像局部區域中梯度的方向和強度分佈來捕捉物體的形狀和外觀資訊。HOG 特徵對光照變化和小的幾何變換具有一定的穩健性。HOG 最成功的應用之一是在行人偵測領域,它與線性 SVM (Support Vector Machine) 分類器結合,在相當長一段時間內是行人偵測的基準方法,取得了非常好的效果。雖然深度學習方法現在更為流行,但 HOG 仍然是一種重要的、值得了解的傳統特徵描述方法。
#18
★★★
實例分割 (Instance Segmentation) 與語意分割 (Semantic Segmentation) 的主要區別是什麼?
答案解析
兩者都是像素級別的圖像分割任務,但目標不同:
- 語意分割 (Semantic Segmentation): 為圖像中的每個像素分配一個物體類別標籤。它只關心像素屬於哪個類別(如貓、狗、樹),不區分這個類別下的不同個體。例如,圖像中有三隻貓,語意分割會將所有屬於貓的像素標記為「貓」。
- 實例分割 (Instance Segmentation): 在語意分割的基礎上,進一步區分同一類別的不同實例 (Instances)。例如,圖像中有三隻貓,實例分割會將它們分別標記為「貓1」、「貓2」、「貓3」。

#19
★★★
遷移學習 (Transfer Learning) 在電腦視覺中的常見做法是?
答案解析
由於訓練大型深度學習模型(尤其是 CNN)需要大量的標註數據和計算資源,從頭開始訓練往往不切實際,特別是當目標任務的數據量有限時。遷移學習提供了一種有效的解決方案。常見做法是:
- 選擇一個在大型、通用的圖像數據集(如 ImageNet,包含上百萬張圖片和上千個類別)上預訓練 (Pre-trained) 好的模型(如 ResNet, VGG, Inception)。這些預訓練模型已經學會了通用的、具有層次結構的視覺特徵。
- 將這個預訓練模型作為特徵提取器或初始模型。
- 針對具體的目標任務(可能只有少量標註數據),對預訓練模型的全部或部分層(通常是後面的全連接層或最後幾層卷積層)進行微調 (Fine-tuning),使其適應新任務的數據分佈和特定要求。
#20
★★★
在 CNN 模型中,池化層 (Pooling Layer) 的主要作用是?
答案解析
池化層(也稱下採樣層 Subsampling Layer)通常插入在連續的卷積層之間。它對輸入的特徵圖進行降維操作。常見的池化操作有:
- 最大池化 (Max Pooling): 在一個局部窗口內,取特徵值的最大值作為輸出。
- 平均池化 (Average Pooling): 在一個局部窗口內,取特徵值的平均值作為輸出。
- 降低維度/減少計算量: 顯著減小特徵圖的空間尺寸(寬和高),從而減少後續層的參數數量和計算量。
- 增大感受野: 間接增大後續卷積層的感受野。
- 提高穩健性/不變性: 使模型對輸入的微小位移、形變或失真不那麼敏感,提高模型的泛化能力(例如,最大池化對局部平移具有一定的不變性)。
#21
★★
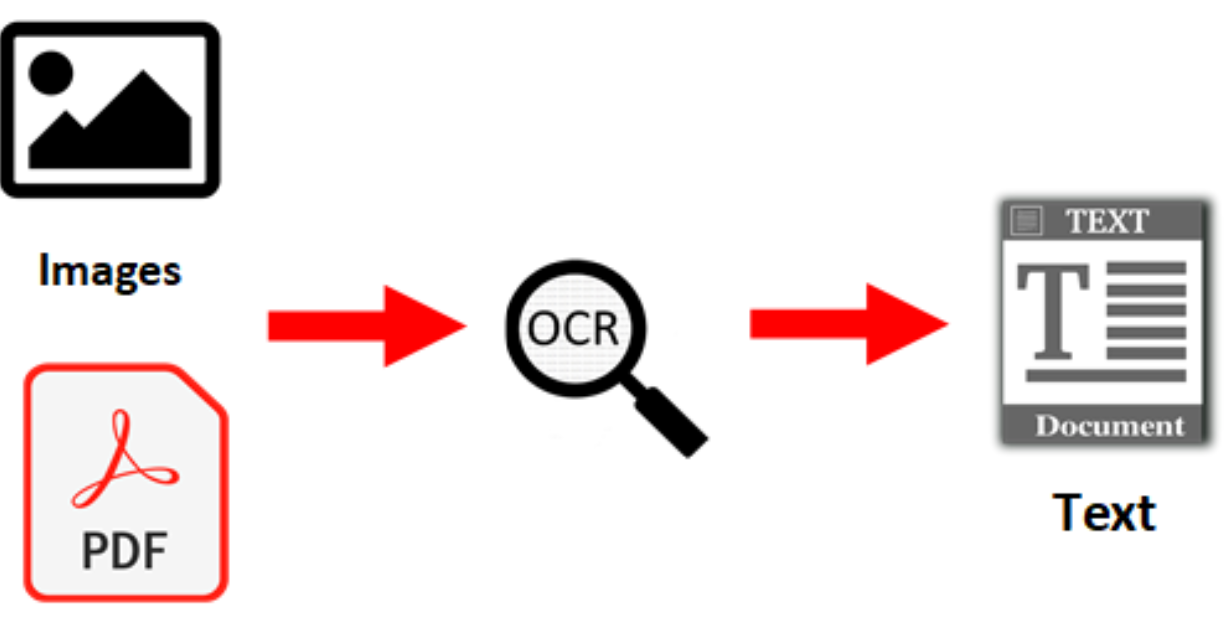
光學字元辨識 (Optical Character Recognition, OCR) 技術可以應用於以下哪個場景?
答案解析
OCR 的核心功能是將圖像中的文字轉換為機器可讀的文本格式。因此,它的典型應用場景包括:
- 文件數位化: 將掃描的紙質文件、書籍、報紙等轉換為可搜索、可編輯的電子文本。
- 車牌辨識: 識別車輛牌照上的字元。
- 名片辨識: 自動提取名片上的聯絡資訊。
- 票據/表單辨識: 自動讀取發票、收據、表格中的文字和數字。
- 場景文字辨識: 識別照片或影片中自然場景裡的文字(如路牌、招牌)。
#22
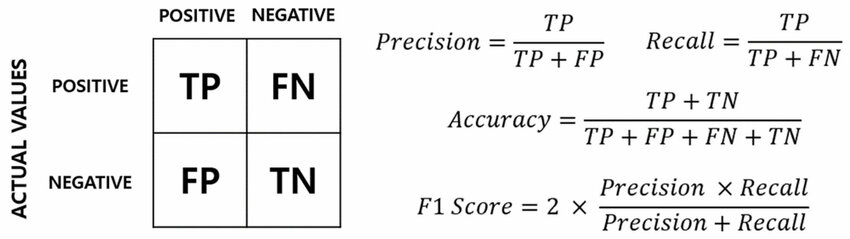
★★
在評估圖像分類模型時,準確率 (Accuracy) 可能不是一個好的指標,尤其是在什麼情況下?
答案解析
準確率 (Accuracy) = (TP + TN) / (TP + TN + FP + FN),即預測正確的樣本數佔總樣本數的比例。在類別分佈均衡的情況下,準確率是一個直觀的指標。但是,當數據集存在嚴重類別不平衡時(例如,99% 的樣本屬於 A 類,只有 1% 的樣本屬於 B 類),準確率就可能具有誤導性。一個簡單地將所有樣本都預測為多數類(A 類)的模型,其準確率可以達到 99%,但它對於少數類(B 類)的識別能力完全為零,這在很多實際應用(如欺詐檢測、罕見病診斷)中是不可接受的。在這種情況下,需要關注其他指標,如精確率 (Precision)、召回率 (Recall)、F1-score 或 AUC (Area Under the ROC Curve)。
#23
★
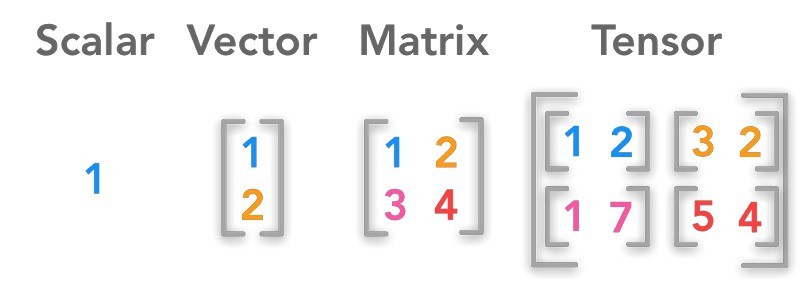
圖像在電腦中通常如何表示?
答案解析
數位圖像在電腦中是以離散的像素 (Pixel, Picture Element) 陣列來表示的。每個像素代表圖像上一個點的顏色或亮度資訊。
- 灰階圖像 (Grayscale Image): 每個像素用一個數值表示其亮度(通常是 0 到 255 之間的整數),可以看作是一個二維矩陣(高度 x 寬度)。
- 彩色圖像 (Color Image): 每個像素通常由多個顏色通道的值組成,最常見的是 RGB 模型,即每個像素包含紅色 (R)、綠色 (G)、藍色 (B) 三個通道的值。因此,彩色圖像可以看作是一個三維張量(高度 x 寬度 x 通道數)。
#24
★★★★
YOLO (You Only Look Once) 是一種流行的物體偵測模型,其主要特點是?
答案解析
YOLO 是單階段 (One-stage) 物體偵測器的代表。與 R-CNN 系列(如 Fast R-CNN, Faster R-CNN)等兩階段 (Two-stage) 方法不同(兩階段方法通常先生成一系列可能包含物體的候選區域 Proposals,然後再對這些區域進行分類和邊界框回歸),YOLO 將物體偵測看作是一個單一的回歸問題。它將輸入圖像劃分成網格 (Grid),並直接在每個網格單元預測包含的物體邊界框、置信度(是否包含物體)以及類別機率。這種端到端的設計使得 YOLO 的偵測速度非常快,能夠達到實時處理的要求,同時在準確率上也能保持較好的水準(尤其是在後續版本如 YOLOv3, YOLOv4, YOLOR, YOLOv7, YOLOv8 等不斷改進)。

#25
★★
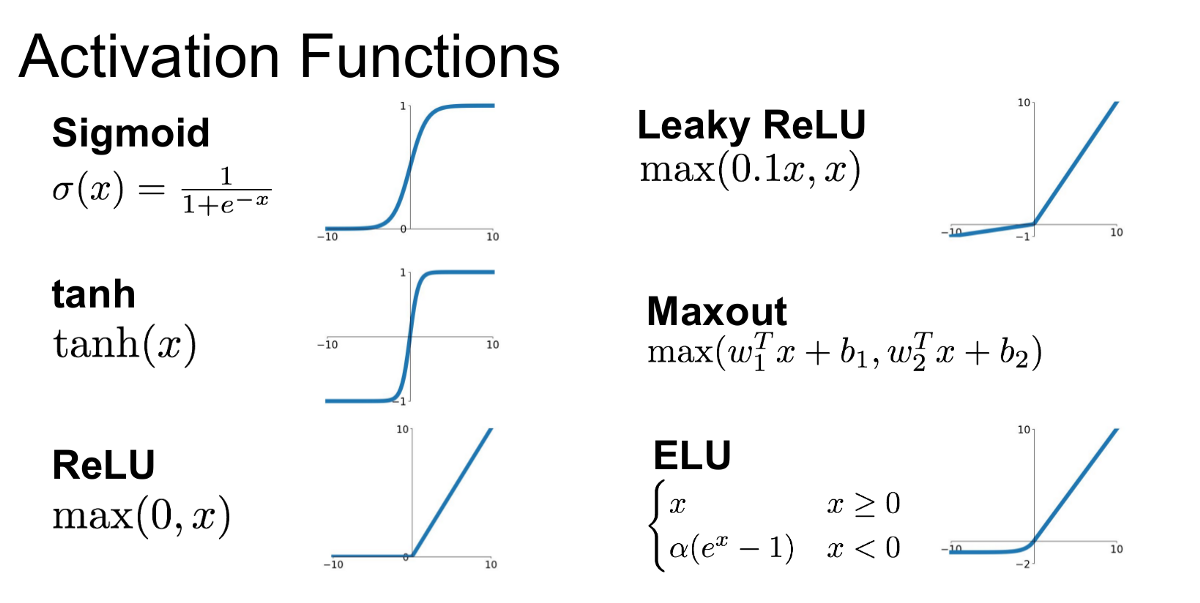
在深度學習中,激活函數 (Activation Function),如 ReLU (Rectified Linear Unit),在 CNN 中的主要作用是?
答案解析
卷積運算和全連接層的仿射變換本身都是線性操作。如果神經網路只由線性層堆疊而成,那麼整個網路無論多深,其表達能力也等價於一個單層的線性模型,無法學習複雜的模式。激活函數(如 Sigmoid, Tanh, ReLU 及其變體 Leaky ReLU, PReLU 等)被應用在線性層的輸出之後,引入非線性 (Non-linearity) 變換。這使得神經網路能夠擬合非線性的複雜函數,從而可以處理現實世界中複雜的模式識別任務,如圖像分類、物體偵測等。ReLU (f(x) = max(0, x)) 因其計算簡單、能有效緩解梯度消失問題(在正區間梯度為 1)而成為 CNN 中最常用的激活函數之一。
#26
★★★
光流 (Optical Flow) 估計的主要目標是?
答案解析
光流是電腦視覺中用於描述運動的概念。它指的是在連續的兩幀(或多幀)影像之間,圖像上物體或像素點的視在運動模式。光流估計的目標是計算一個運動向量場,其中每個向量表示對應像素在相鄰幀之間的位移。光流資訊對於理解影片內容、物體追蹤、動作識別、視訊壓縮、機器人導航等應用非常重要。例如,通過分析光流可以判斷物體的運動方向和速度。

#27
★★★
電腦視覺技術在醫療影像分析 (Medical Image Analysis) 中有哪些應用?
答案解析
電腦視覺在醫療領域的應用潛力巨大,可以輔助醫生提高診斷效率和準確性。常見應用包括:
- 醫學影像分割: 在 CT、MRI、X 光等影像中自動分割出感興趣的器官、組織或病灶區域(如腫瘤、血管)。
- 病灶偵測與分類: 自動偵測影像中可能的異常區域(如肺結節、乳腺癌腫塊),並輔助判斷其良惡性。
- 影像配準 (Image Registration): 對齊來自不同時間、不同模態或不同病人的醫學影像,以便比較或融合資訊。
- 電腦輔助診斷 (Computer-Aided Diagnosis, CAD): 提供量化分析結果或視覺提示,輔助醫生做出診斷決策。
- 手術導航與規劃: 利用術中影像或術前影像進行 3D 重建和定位,輔助醫生精確操作。
#28
★★
尺度空間理論 (Scale-Space Theory) 在電腦視覺中的主要目的是?
答案解析
尺度空間理論提出,圖像分析不應只在單一尺度(解析度)下進行,而應在一個連續的尺度範圍內進行。通過使用不同大小的高斯核對圖像進行卷積(平滑),可以生成一系列不同模糊程度(尺度)的圖像表示,構成尺度空間。在不同尺度下提取和分析圖像特徵(如斑點 Blob、角點 Corner),可以使得特徵偵測結果對物體在圖像中的實際大小變化不敏感。例如,一個小的斑點可能在較小尺度下被偵測到,而一個大的斑點可能在較大尺度下才被偵測到。SIFT 演算法中的關鍵點偵測就應用了尺度空間理論(通過高斯差分 DoG 近似拉普拉斯算子)。
#29
★★★
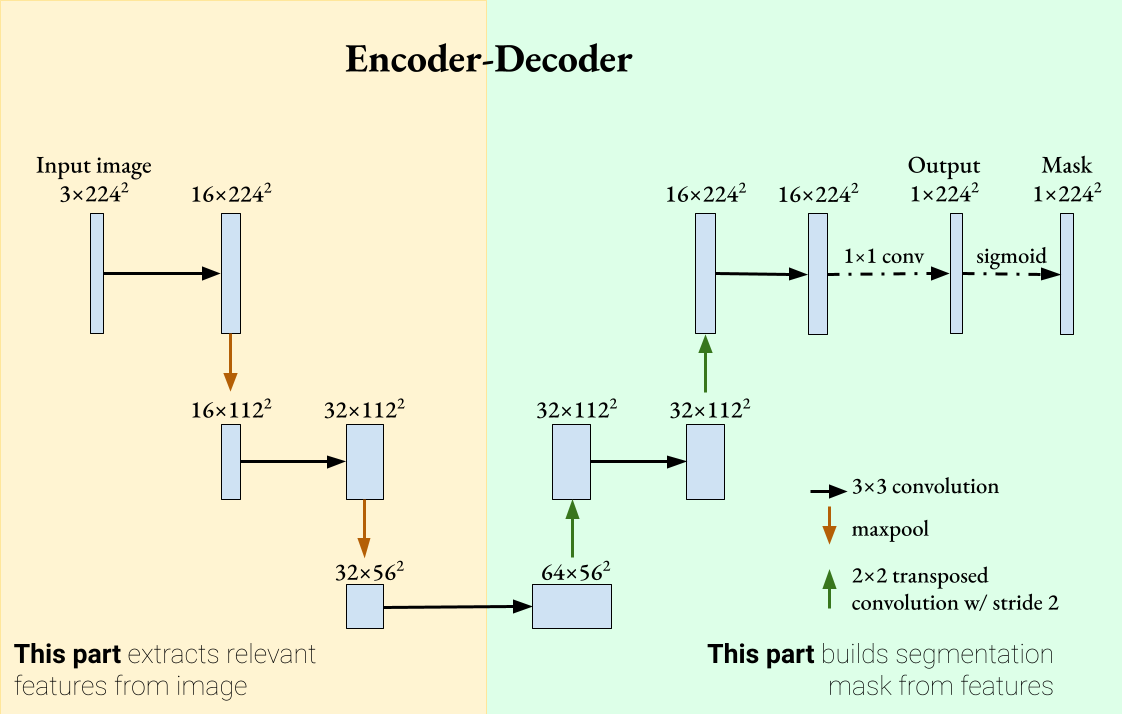
U-Net 是一種常用於什麼電腦視覺任務的 CNN 架構?
答案解析
U-Net 最初是為了解決生物醫學圖像分割問題而設計的。其架構呈 U 形,包含兩條路徑:
- 收縮路徑 (Contracting Path / Encoder): 類似典型的 CNN,通過重複應用卷積和最大池化來捕捉上下文資訊,同時降低空間解析度。
- 擴張路徑 (Expanding Path / Decoder): 通過上採樣(如轉置卷積 Transposed Convolution)逐步恢復空間解析度,同時將來自收縮路徑的對應層的高解析度特徵圖通過跳躍連接 (Skip Connection) 拼接過來。
#30
★★★
對抗性攻擊 (Adversarial Attack) 在電腦視覺領域指的是什麼?
答案解析
對抗性攻擊利用了深度學習模型(尤其是視覺模型)的脆弱性。攻擊者可以精心設計一種對抗樣本 (Adversarial Example),它是在原始、乾淨的圖像上添加了非常微小的、人眼幾乎無法分辨的擾動 (Perturbation),但這種擾動卻能導致模型(例如圖像分類器)以高置信度將其誤分類為其他類別。例如,一張貓的圖片經過微小擾動後,可能被模型高度確信地識別為狗。對抗性攻擊揭示了深度學習模型在穩健性和安全性方面的隱患,是當前電腦視覺和 AI 安全領域的重要研究方向。了解和防禦對抗性攻擊對於在安全攸關場景(如自動駕駛、醫療診斷)中部署 AI 模型至關重要。

#31
★★
圖像修復 (Image Inpainting) 的目標是?
答案解析
圖像修復,也稱為圖像補全 (Image Completion),旨在修復圖像中存在缺失、損壞或被遮擋的區域。其目標是利用圖像中可用(未損壞)部分的資訊,推斷並生成缺失區域的內容,使得修復後的圖像看起來自然、合理、與周圍環境協調一致。這項技術可用於去除照片中的多餘物體、修復老舊照片的劃痕或破損、填補視訊中被移除的標誌等。傳統方法包括基於擴散或紋理合成的方法,而現代方法則廣泛使用深度學習(特別是生成對抗網路 GAN)來生成更逼真的修復結果。

#32
★★
姿態估計 (Pose Estimation) 在電腦視覺中的目標是?
答案解析
姿態估計旨在從圖像或影像中推斷物體的姿態資訊。這可以分為幾種類型:
- 人體姿態估計 (Human Pose Estimation): 定位人體主要關節點(如頭、肩、肘、腕、髖、膝、踝)的 2D 或 3D 坐標。
- 物體姿態估計 (Object Pose Estimation): 估計剛性物體(如汽車、工業零件)相對於相機的 6D 姿態(3D 位置和 3D 旋轉)。
- 手部姿態估計、臉部姿態估計等。

#33
★★★
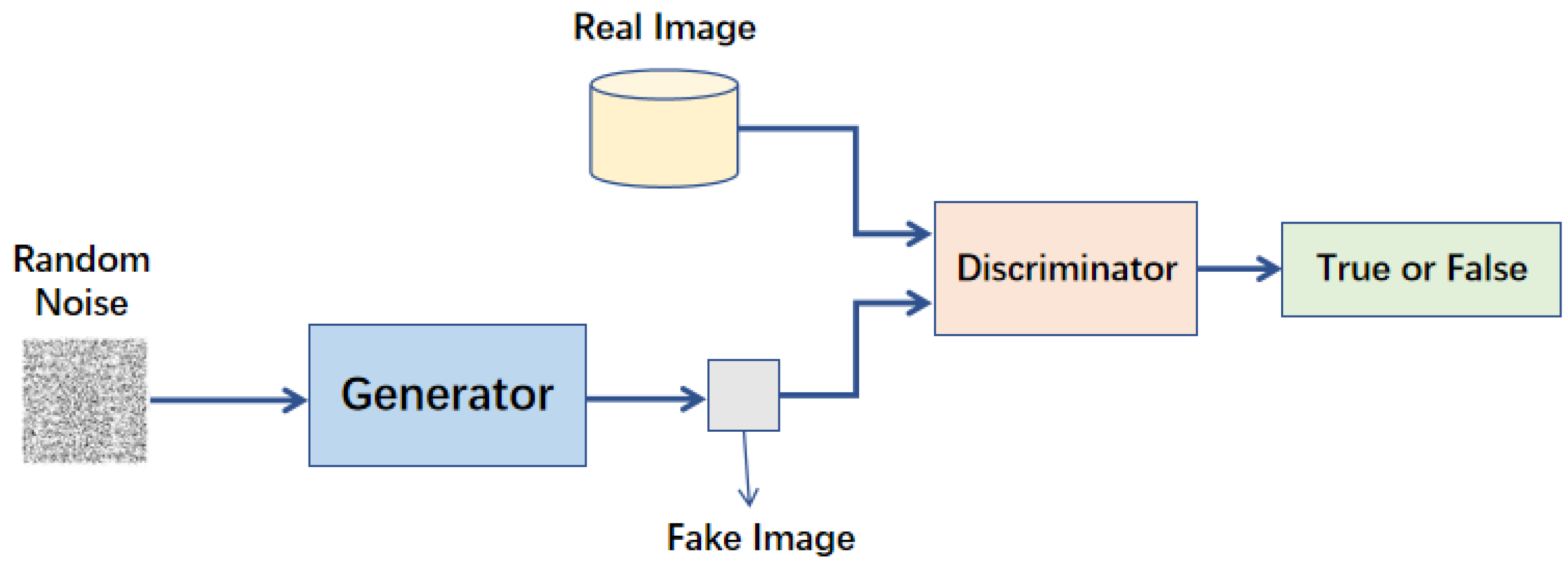
生成對抗網路 (Generative Adversarial Network, GAN) 在電腦視覺中有哪些應用?
答案解析
GAN 是一種強大的生成模型,它由一個生成器 (Generator) 和一個判別器 (Discriminator) 組成,通過對抗訓練的方式學習生成逼真的數據。在電腦視覺領域,GAN 被廣泛應用於各種生成和轉換任務:
- 圖像生成: 生成新的、看似真實的人臉、風景、動漫角色等。
- 圖像風格轉換: 將一張圖像的內容與另一張圖像的風格相結合。
- 圖像超解析度: 將低解析度圖像轉換為高解析度圖像。
- 圖像修復 (Inpainting): 填補圖像的缺失部分。
- 圖像到圖像翻譯 (Image-to-Image Translation): 將一種域的圖像轉換為另一種域的圖像(如將衛星圖轉為地圖,將線稿轉為彩色圖)。
- 數據增強: 生成合成數據來擴充訓練集。
#34
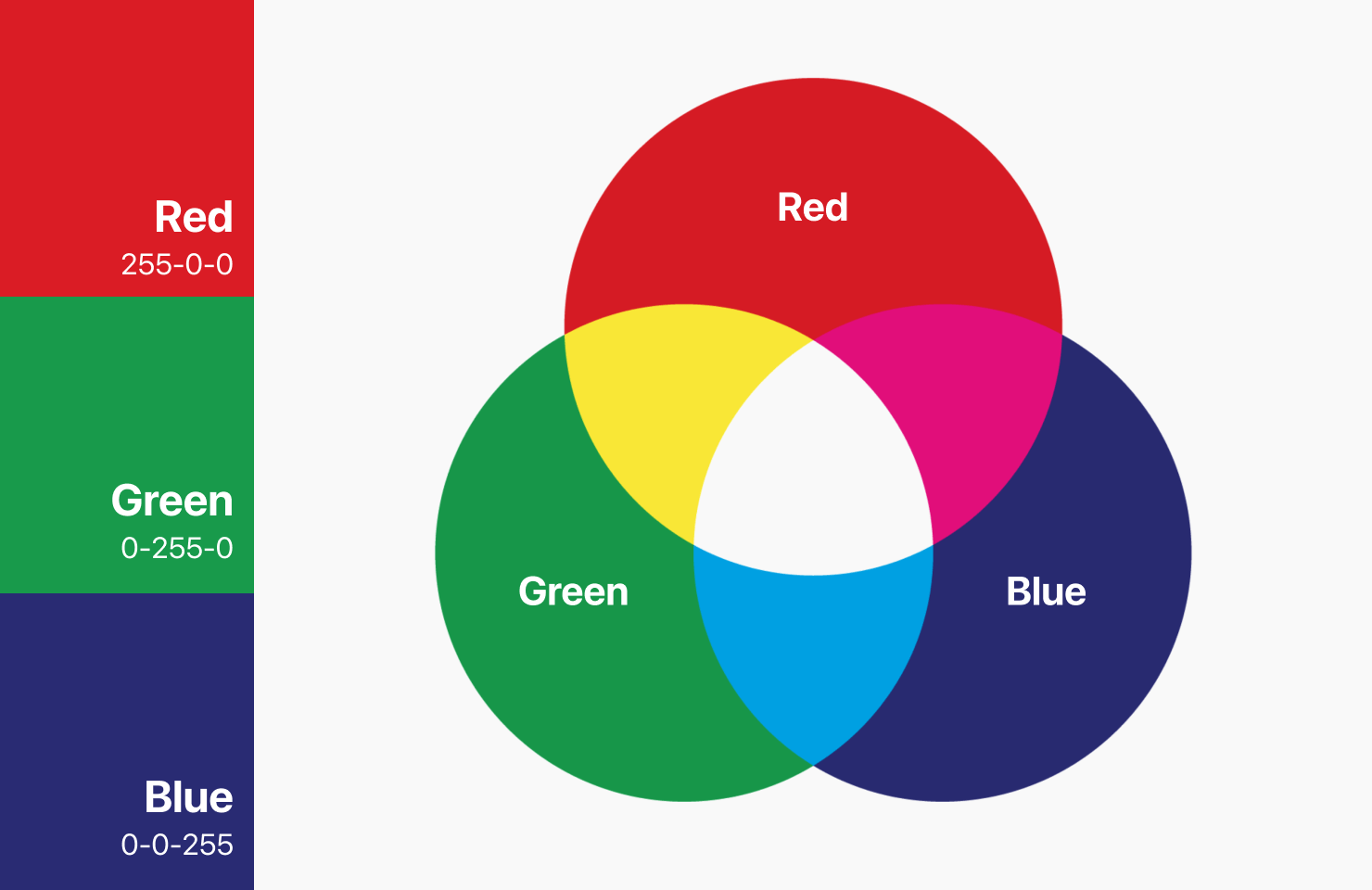
★★
RGB 色彩模型是電腦視覺中最常用的色彩模型之一,它使用哪三種基色來表示顏色?
答案解析
RGB 是一種加色模型 (Additive Color Model),廣泛應用於顯示器、相機等發光設備。它基於三原色光混合原理,通過混合不同比例的紅色 (R)、綠色 (G) 和藍色 (B) 光線來產生各種顏色。每個顏色通道通常用一個 8 位元(0-255)的數值表示強度。選項 B 是 CMY(K) 模型,用於印刷,是減色模型。選項 C 是 HSV 或 HSB 模型,更符合人類對顏色的感知方式。選項 D 是 YCbCr 模型,常用於視訊壓縮,將亮度與色度分離。
#35
★★
全連接層 (Fully Connected Layer) 在 CNN 模型中通常位於哪個部分?其作用是什麼?
答案解析
在典型的 CNN 架構中,前面通常是多個卷積層和池化層堆疊,負責從輸入圖像中提取具有空間階層結構的特徵圖。這些特徵圖在輸入到全連接層之前,通常會被展平 (Flatten) 成一個一維向量。全連接層的作用類似於傳統的多層感知器 (Multilayer Perceptron, MLP),其每個神經元都與前一層的所有神經元相連。它的主要功能是:
- 整合特徵: 將前面卷積/池化層提取到的局部、抽象特徵進行整合。
- 映射到輸出: 將整合後的特徵映射到最終的輸出空間,例如,在圖像分類任務中,映射到各個類別的得分或機率。
#36
★★
電腦視覺模型在訓練和部署時面臨的挑戰之一是光照變化,這會導致什麼問題?
答案解析
光照變化是電腦視覺應用中常見且棘手的問題。不同的光照條件(如白天/夜晚、室內/室外、晴天/陰天、不同光源方向和強度)會顯著改變物體在圖像中的外觀,即使是同一個物體。這包括亮度、對比度、陰影和顏色的變化。如果模型在訓練時只接觸了有限的光照條件,那麼在實際應用中遇到未見過的光照時,其效能可能會急遽下降,導致識別錯誤或失敗。因此,提高模型對光照變化的穩健性 (Robustness) 是電腦視覺研究中的一個重要挑戰。常用的應對方法包括資料增強(模擬光照變化)、使用對光照不敏感的特徵、光照歸一化等。
#37
★★★
霍夫變換 (Hough Transform) 是一種常用於偵測圖像中特定形狀的技術,它最常用於偵測什麼?
答案解析
霍夫變換是一種特徵提取技術,通過一種投票機制在參數空間中尋找特定形狀的實例。其基本思想是將圖像空間中的點變換到參數空間,參數空間中的每個點代表圖像空間中的一條曲線(或形狀)。圖像空間中共線或共圓的點,其對應到參數空間的曲線會交於一點。通過在參數空間中尋找累積投票數最多的點,就可以反推出圖像空間中存在的直線或圓。標準霍夫變換主要用於偵測直線,後來也發展出了偵測圓形和其他參數化形狀的變體。它通常作用於邊緣偵測後的二值圖像。
#38
★
圖像分類 (Image Classification) 任務的輸入和輸出通常是什麼?
答案解析
圖像分類是電腦視覺中最基礎的任務之一。它的目標是接收一張輸入圖像,並從一組預先定義好的類別中,為該圖像分配一個最能描述其主要內容的單一類別標籤。例如,給定一張圖片,模型需要判斷它是屬於「貓」、「狗」、「汽車」還是「飛機」等類別。輸出通常是每個類別的機率分佈,其中機率最高的類別被選為最終的預測結果。選項 B 是物體偵測。選項 C 是圖像描述生成 (Image Captioning)。選項 D 是圖像相似度匹配或檢索。
#39
★
深度學習方法與傳統電腦視覺方法在特徵提取上的主要區別是什麼?
答案解析
傳統的電腦視覺流程通常分為兩步:1. 人工設計特徵提取: 研究人員根據對問題的理解和專業知識,手動設計特徵提取演算法(如 SIFT, SURF, HOG)來獲取圖像的關鍵資訊。2. 分類器訓練: 使用提取出的特徵來訓練一個分類器(如 SVM, Random Forest)。這種方法的效能很大程度上取決於人工設計特徵的好壞。而深度學習方法(特別是 CNN)則採用端到端 (End-to-End) 的學習方式,將特徵提取和分類(或其他任務)整合在一個統一的網路中。網路能夠自動地、層次化地從原始像素數據中學習到適合當前任務的特徵表示,無需人工干預。這種自動學習特徵的能力是深度學習在電腦視覺領域取得突破的關鍵原因。
#40
★★★
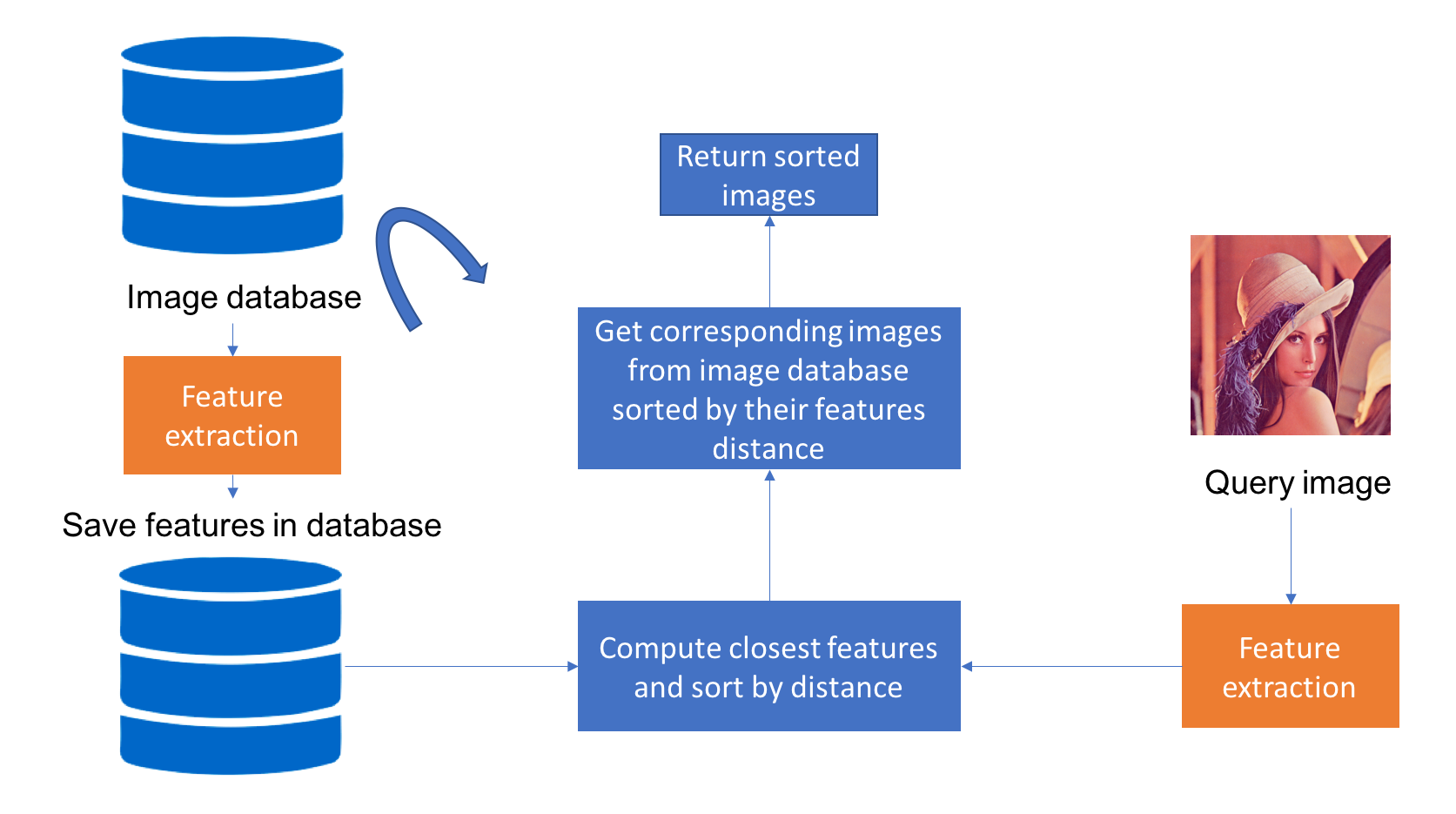
圖像檢索 (Image Retrieval) 的目標是?
答案解析
圖像檢索旨在根據圖像的內容或語意相似性來查找圖像。常見的圖像檢索類型是基於內容的圖像檢索 (Content-Based Image Retrieval, CBIR)。其流程通常是:
- 為資料庫中的所有圖像和查詢圖像提取特徵向量(可以使用顏色直方圖、紋理特徵、SIFT 等傳統特徵,或使用深度學習模型提取的深度特徵)。
- 計算查詢圖像特徵向量與資料庫中所有圖像特徵向量之間的相似度(如歐氏距離、餘弦相似度)。
- 根據相似度對資料庫圖像進行排序,返回最相似的圖像作為檢索結果。
#41
★
像素 (Pixel) 是組成數位圖像的最小單位,它通常包含什麼資訊?
答案解析
Pixel 是 Picture Element 的縮寫,是數位圖像的基本組成單元。每個像素代表了圖像在某個離散位置點上的資訊。對於灰階圖像,這個資訊是單一的亮度值。對於彩色圖像,這個資訊通常是多個顏色通道的值(如 RGB 值)。像素值決定了該點在螢幕上顯示的顏色和亮度。圖像的空間解析度就是由像素的數量(寬度 x 高度)決定的。
#42
★★
仿射變換 (Affine Transformation) 在圖像處理中可以實現哪些操作?
答案解析
仿射變換是一種線性變換(通過矩陣乘法實現)與平移(向量加法)的組合。在二維圖像處理中,它可以表示為 `x' = Ax + b`,其中 x 是原始坐標,x' 是變換後坐標,A 是一個 2x2 的線性變換矩陣,b 是一個 2x1 的平移向量。仿射變換可以實現多種幾何操作,包括:
- 平移 (Translation): 移動圖像位置。
- 旋轉 (Rotation): 繞某點旋轉圖像。
- 縮放 (Scaling): 放大或縮小圖像(可以沿不同軸進行不同比例縮放)。
- 錯切 (Shear): 使圖像沿某個方向傾斜(像推倒長方形)。
#43
★★★
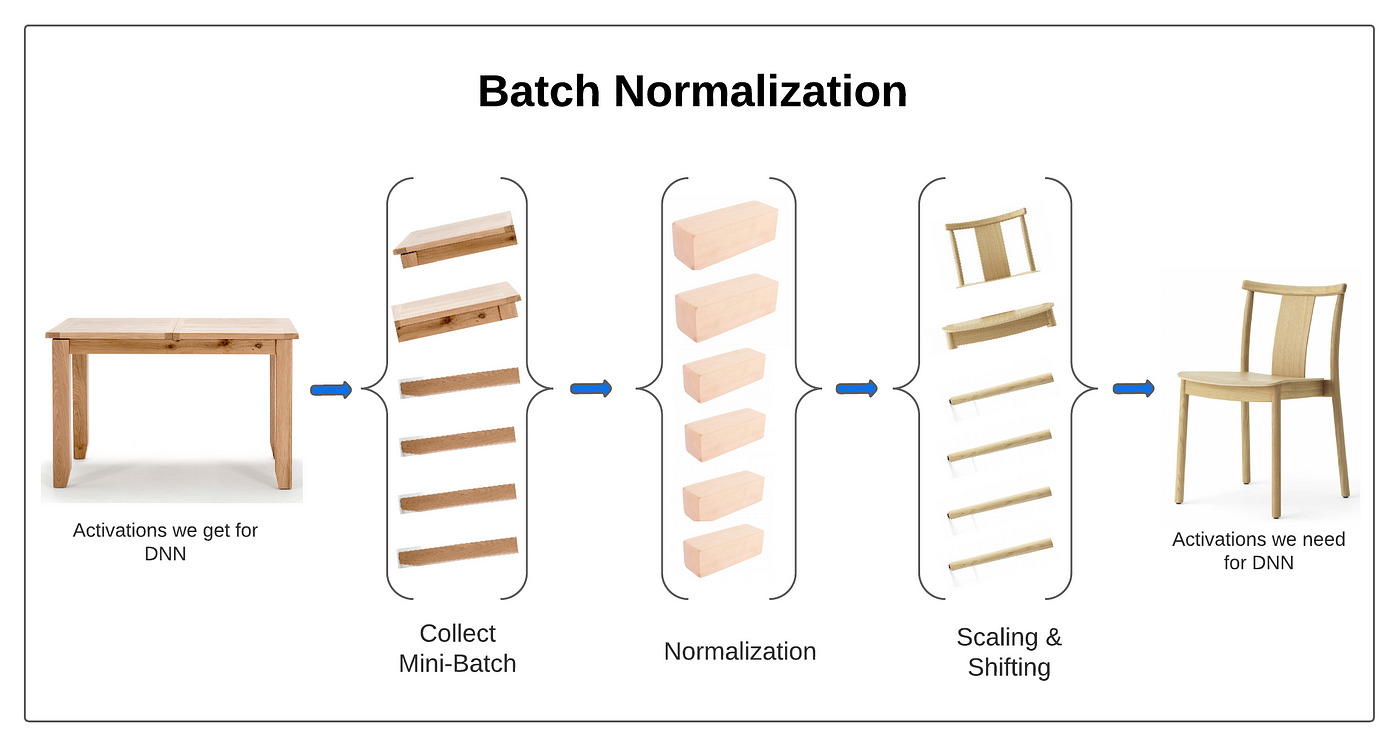
批次歸一化 (Batch Normalization, BN) 在深度神經網路訓練中的主要作用是?
答案解析
批次歸一化是深度學習中常用的一種技巧,通常應用在線性層(卷積層或全連接層)和激活函數之間。它對一個 mini-batch 內每個特徵通道的數據進行歸一化處理,使其均值接近 0,方差接近 1。然後,通過兩個可學習的參數(縮放因子 γ 和偏移因子 β)對歸一化後的數據進行線性變換。BN 的主要好處包括:
- 加速收斂: 通過穩定各層輸入的分佈,允許使用更大的學習率,加快模型訓練速度。
- 穩定訓練: 減少了內部協變量偏移 (Internal Covariate Shift) 問題,使得模型對參數初始化不那麼敏感,訓練過程更穩定。
- 正則化效果: BN 在 mini-batch 上計算統計量,引入了一定的隨機性,可以起到類似 Dropout 的正則化作用,有助於防止過擬合。
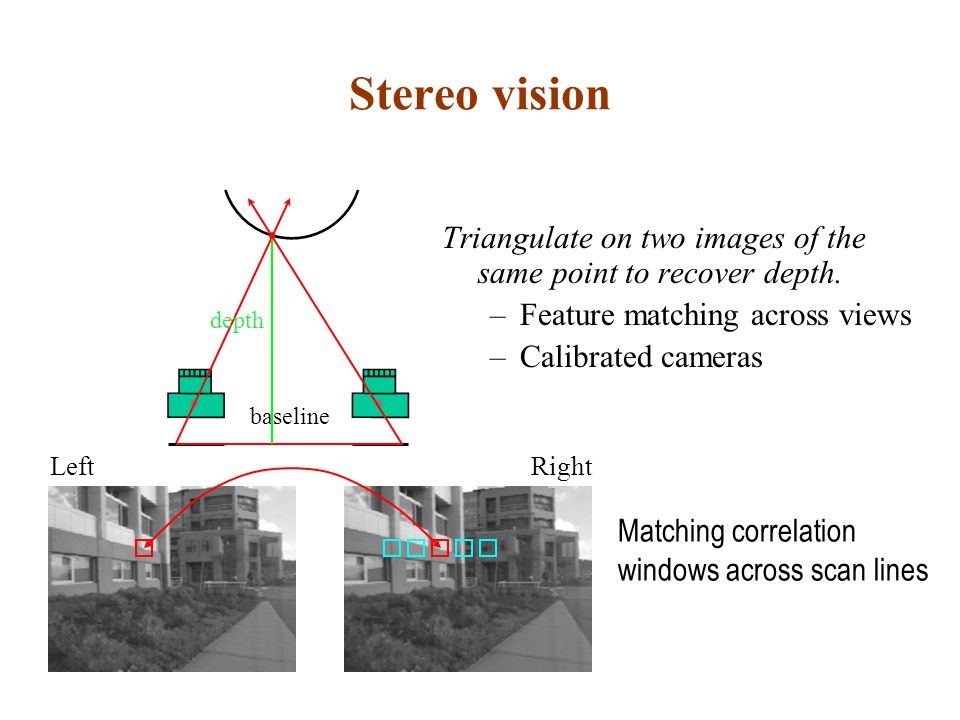
#44
★
電腦視覺中的「立體視覺」(Stereo Vision) 主要利用什麼原理來推斷場景的深度資訊?
答案解析
立體視覺模仿人類雙眼視覺系統。它使用兩個(或多個)在不同位置拍攝的相機來捕捉同一場景的圖像。由於相機位置不同,同一個三維空間點在兩張圖像上的投影位置會存在差異,這個差異稱為視差 (Disparity)。視差的大小與該點的深度(距離相機的遠近)成反比:距離越近的點,視差越大;距離越遠的點,視差越小。通過找出兩張圖像中對應點(稱為同名點匹配 Stereo Matching)並計算它們之間的視差,就可以利用三角測量原理推斷出該點的三維深度資訊,進而重建場景的三維結構。
#45
★★
擴增實境 (Augmented Reality, AR) 技術的核心之一是將虛擬物體疊加到真實世界場景中,這需要電腦視覺技術來實現什麼?
答案解析
為了讓虛擬物體能夠逼真地、穩定地疊加在真實世界的視圖中,AR 系統需要解決幾個關鍵的電腦視覺問題:
- 即時定位與地圖構建 (Simultaneous Localization and Mapping, SLAM) 或視覺慣性里程計 (Visual-Inertial Odometry, VIO): 系統需要實時地追蹤相機(例如手機攝像頭或 AR 眼鏡)在三維空間中的精確位置和姿態(6DoF: 3D 位置 + 3D 旋轉)。
- 場景理解與重建 (Scene Understanding and Reconstruction): 系統需要理解真實環境的幾何結構,例如偵測平面(如桌面、地面、牆壁)、識別物體、估計深度等,以便將虛擬物體正確地放置在真實場景中(例如,讓虛擬茶杯「放」在真實桌面上)。

#46
★
以下哪個不是電腦視覺面臨的常見挑戰?
答案解析
電腦視覺在實際應用中面臨許多挑戰,使得從圖像中可靠地提取資訊變得困難。常見挑戰包括:
- 視角變化: 同一物體從不同角度看外觀差異很大。
- 光照變化: 光照條件影響物體的亮度、顏色和陰影。
- 尺度變化: 物體在圖像中的大小可能變化很大。
- 遮擋: 物體可能被其他物體部分或完全遮擋。
- 形變 (Deformation): 非剛性物體(如衣服、人體)的形狀會變化。
- 背景混淆 (Background Clutter): 物體與背景難以區分。
- 類內差異 (Intra-class Variation): 同一類別的物體外觀可能差異很大(如不同品種的狗)。
- 運動模糊 (Motion Blur): 相機或物體快速運動導致圖像模糊。
#47
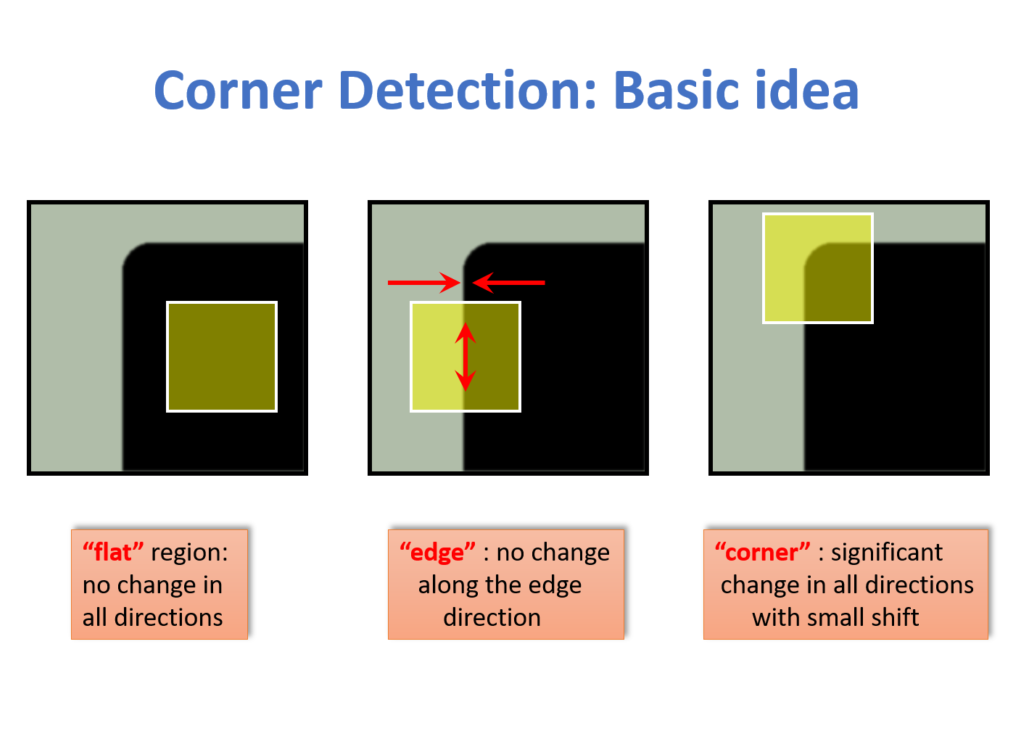
★★★
角點偵測 (Corner Detection) 演算法(如 Harris Corner Detector)主要尋找圖像中的什麼區域?
答案解析
角點是圖像中重要的局部特徵點。直觀地說,角點是兩條或多條邊緣的交匯處。從數學上看,角點通常被定義為:如果以該點為中心取一個小的圖像窗口,當這個窗口向任何方向移動時,窗口內的圖像內容都會發生顯著變化。相比之下,平坦區域的窗口移動時內容基本不變,邊緣區域的窗口沿邊緣方向移動時內容變化不大,只有垂直於邊緣方向移動時才顯著變化。Harris 角點偵測器就是基於這種思想,通過計算圖像梯度矩陣的特徵值來判斷某個點是否為角點(角點處兩個特徵值都較大)。角點是穩定且資訊豐富的特徵,常用於圖像匹配、追蹤、拼接等任務。
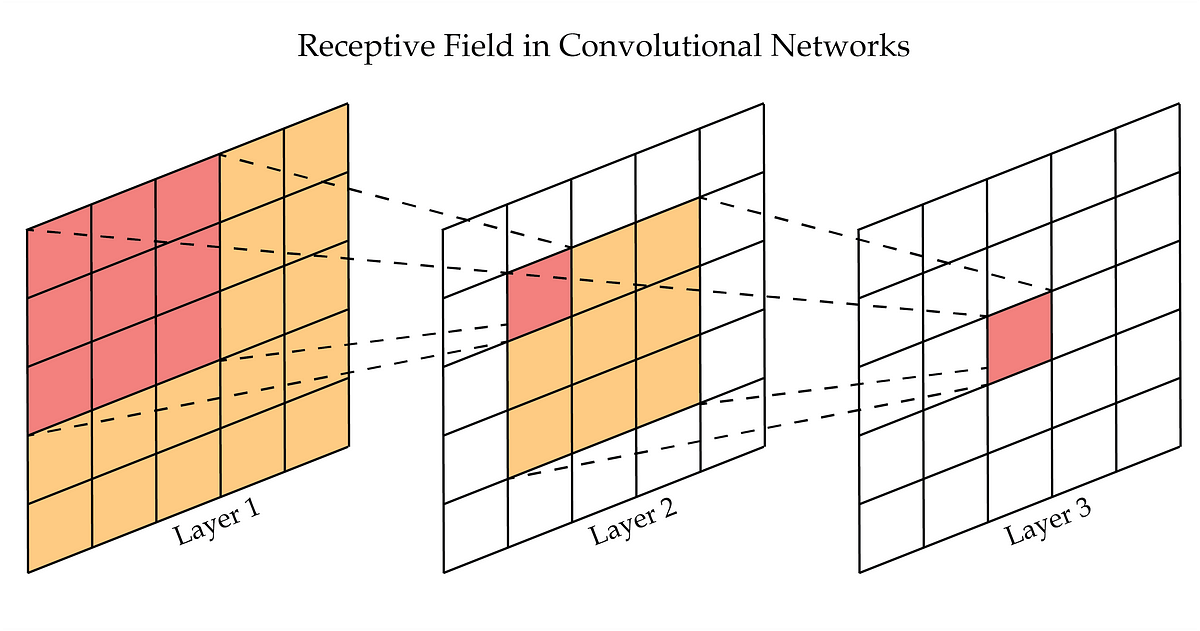
#48
★★
卷積神經網路 (CNN) 中的「感受野」(Receptive Field) 指的是什麼?
答案解析
在 CNN 中,每一層的輸出特徵圖上的每個像素值,都是由前一層特徵圖(或原始輸入圖像)的一個局部區域計算得到的。這個局部區域的大小就被稱為該輸出像素的感受野。隨著網路層數的加深,感受野會逐漸增大。例如,第一層卷積核大小為 3x3,則第一層輸出特徵圖上每個像素的感受野是輸入圖像上的 3x3 區域;如果第二層卷積核也是 3x3,則第二層輸出特徵圖上每個像素的感受野對應到輸入圖像上就是 5x5 的區域(假設步長為 1)。理解感受野的大小對於分析 CNN 模型如何捕捉不同尺度的資訊以及設計網路結構非常重要。深層的單元具有更大的感受野,能夠捕捉更全局、更抽象的特徵。
#49
★
工業自動化中的「瑕疵檢測」(Defect Detection) 經常利用電腦視覺技術來?
答案解析
在工業生產線上,利用電腦視覺進行自動化的瑕疵檢測是提高產品質量和生產效率的重要手段。系統通過攝像頭拍攝產線上的產品圖像,然後利用圖像處理和機器學習(包括深度學習)演算法來分析圖像,自動識別產品表面或內部是否存在各種預定義的缺陷,如劃痕、凹坑、氣泡、顏色異常、尺寸偏差等。相比人工目檢,自動化檢測速度更快、更穩定、不易疲勞,能夠實現 100% 全檢。這屬於電腦視覺在品質控制方面的典型應用。
#50
★★★
混淆矩陣 (Confusion Matrix) 在評估分類模型時提供了哪些資訊?
答案解析
混淆矩陣是一個 N x N 的矩陣(N 為類別數量),用於視覺化和量化分類模型的效能。矩陣的行通常代表真實類別 (Actual Class),列代表預測類別 (Predicted Class)。矩陣中的每個元素 C(i, j) 表示實際屬於類別 i 的樣本被模型預測為類別 j 的數量。
對於二元分類:
對於二元分類:
- TP (True Positive): 實際為正,預測為正。
- FP (False Positive): 實際為負,預測為正(第一型錯誤 Type I Error)。
- TN (True Negative): 實際為負,預測為負。
- FN (False Negative): 實際為正,預測為負(第二型錯誤 Type II Error)。
↑