iPAS AI應用規劃師 考試重點
L21102 電腦視覺技術與應用
主題分類
1
電腦視覺基本概念與流程
2
圖像處理基礎技術
3
卷積神經網路(CNN)核心原理
4
常見的電腦視覺任務
5
重要電腦視覺模型與架構
6
電腦視覺模型訓練與評估
7
電腦視覺應用場景
8
電腦視覺挑戰與趨勢
#1
★★★★★
電腦視覺 (CV - Computer Vision) - 基本定義
核心概念
電腦視覺 是一門研究如何讓電腦「看懂」並理解圖像 (Image) 或 影片 (Video) 內容的科學領域。其目標是模仿人類視覺系統的功能,從視覺數據中提取、處理、分析和理解有用的資訊。
#2
★★★★
電腦視覺處理流程 (CV Pipeline)
主要階段
一個典型的電腦視覺系統通常包含以下階段:
- 圖像獲取 (Image Acquisition): 使用相機或其他感測器捕捉影像。
- 圖像預處理 (Image Preprocessing): 如去噪、增強對比度、尺寸標準化等。
- 特徵提取 (Feature Extraction): 識別圖像中的關鍵特徵,如邊緣、角點、紋理等。
- 偵測/分割/辨識 (Detection/Segmentation/Recognition): 根據任務進行物件偵測、像素級分割或模式辨識。
- 高層次處理/決策 (High-level Processing/Decision): 基於分析結果做出判斷或採取行動。
#3
★★★
灰階轉換 (Grayscale Conversion)
基礎圖像處理
將彩色圖像轉換為灰階圖像是常見的預處理步驟。它可以降低計算複雜度,因為只需要處理亮度資訊,而非紅、綠、藍三個色彩通道。常用方法是根據各通道對人眼亮度的貢獻進行加權平均。

#4
★★★
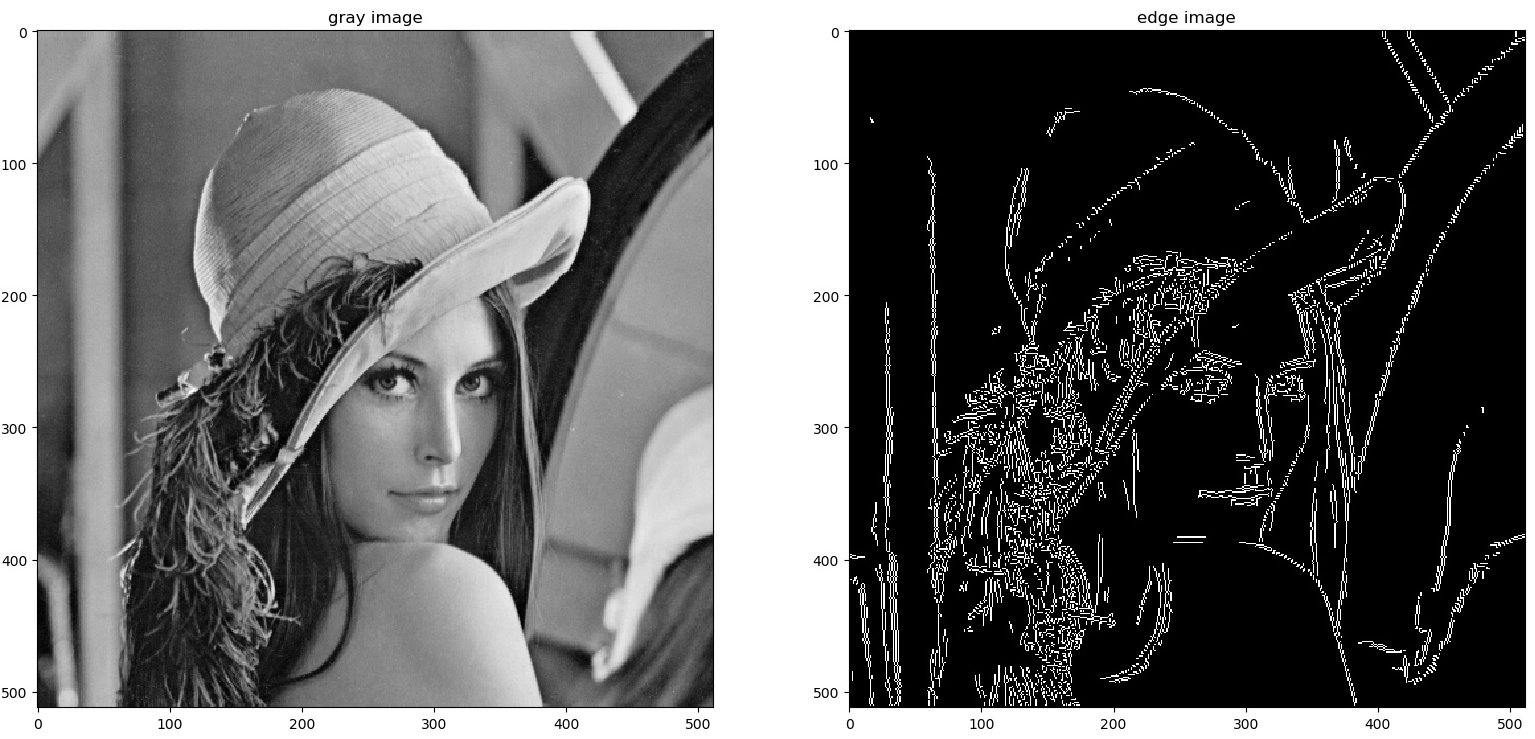
邊緣檢測 (Edge Detection)
特徵提取技術
識別圖像中亮度變化劇烈的地方,這些地方通常對應著物件的輪廓。常見的邊緣檢測算子包括 Sobel, Prewitt, 和 Canny 邊緣檢測器。Canny 因其較好的抗噪性和準確性而被廣泛使用。
#5
★★★★★
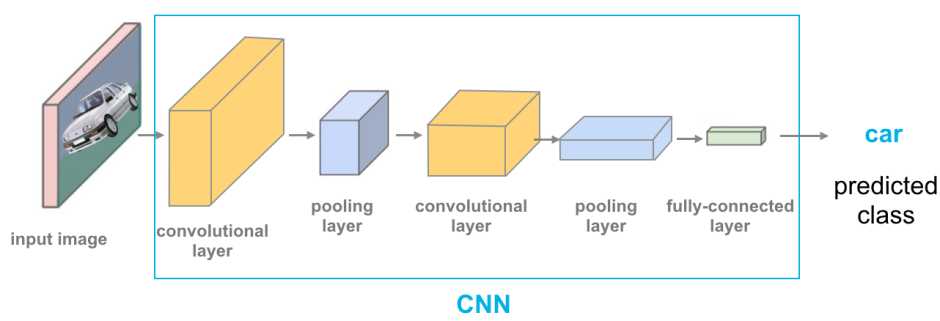
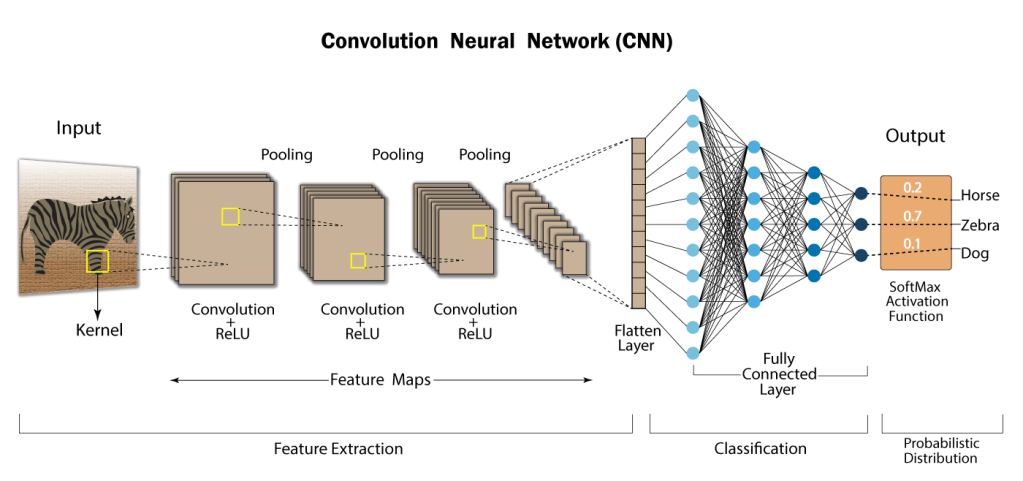
卷積神經網路 (CNN - Convolutional Neural Network)
核心模型
CNN 是一種深度學習模型,特別擅長處理具有網格結構數據(如圖像)。其關鍵在於使用卷積層 (Convolutional Layer) 來自動學習圖像的空間層次特徵。適合用於影像辨識等任務(參考樣題 Q4)。
#6
★★★★★
卷積層 (Convolutional Layer)
CNN 核心組件
卷積層使用一組可學習的濾波器(或稱卷積核 Kernel)對輸入圖像進行卷積運算,以提取局部特徵,如邊緣、紋理等。其具有權重共享 (Weight Sharing) 和局部連接 (Local Connectivity) 的特性,大大減少了模型參數數量。
#7
★★★★
池化層 (Pooling Layer)
CNN 組件
池化層通常接在卷積層之後,用於降低特徵圖的空間維度(寬和高),減少計算量,並提高模型的穩健性(對微小變化的不敏感性)。常見的池化操作有最大池化 (Max Pooling) 和平均池化 (Average Pooling)。
#8
★★★★
全連接層 (Fully Connected Layer)
CNN 組件
全連接層通常位於 CNN 的末端,將前面卷積層和池化層提取到的特徵進行整合,並映射到最終的輸出類別(例如,在分類任務中)。其連接方式與傳統神經網路相同,每個神經元都與前一層的所有神經元相連。
#9
★★★★
激活函數 (Activation Function) - ReLU
CNN 組件
激活函數為神經網路引入非線性,使其能夠學習更複雜的模式。ReLU (Rectified Linear Unit) 是 CNN 中最常用的激活函數之一,其形式為 f(x) = max(0, x)。相比於 tanh 和 Sigmoid,ReLU 可以有效緩解梯度消失問題,加速模型收斂(參考樣題 Q4)。
#10
★★★★★
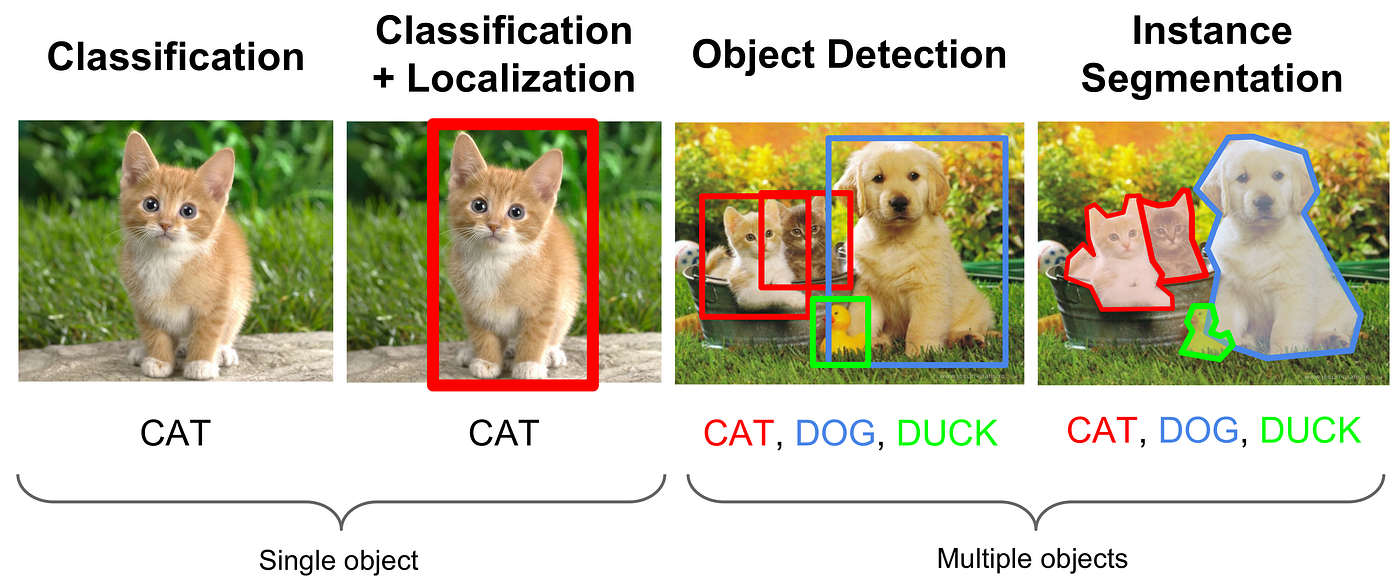
圖像分類 (Image Classification)
核心 CV 任務
任務目標是將輸入圖像分配到一個或多個預定義的類別中。例如,判斷一張圖片是貓還是狗。這是電腦視覺中最基本也最常見的任務之一。
#11
★★★★★
物件偵測 (Object Detection)
核心 CV 任務
物件偵測不僅要識別圖像中有哪些物件(分類),還需要定位這些物件的位置,通常使用邊界框 (Bounding Box) 來標示。例如,在自動駕駛中檢測行人、車輛的位置。
#12
★★★★
圖像分割 (Image Segmentation)
核心 CV 任務
圖像分割是將圖像劃分成多個區域或像素集合的過程,使得每個區域內的像素具有相似的特性(如顏色、紋理)。目標是簡化或改變圖像的表示形式,使其更易於分析。
- 語意分割 (Semantic Segmentation): 將圖像中的每個像素分配到一個類別(例如,所有屬於“汽車”的像素標記為同一類)。
- 實例分割 (Instance Segmentation): 區分同一類別的不同實例(例如,區分圖像中的每一輛不同的汽車)。

#13
★★★
影像生成 (Image Generation)
CV 相關任務
使用 AI 模型創建新的、逼真的圖像。雖然這通常與生成式 AI (Generative AI) 聯繫更緊密,但它也屬於廣義的電腦視覺領域。常見模型如 GAN (Generative Adversarial Network) 和擴散模型 (Diffusion Models)。
#14
★★★
影片分析 (Video Analysis)
CV 任務延伸
將電腦視覺技術應用於影片數據,分析連續的圖像幀以理解時間動態、行為或事件。任務包括動作識別 (Action Recognition)、物件追蹤 (Object Tracking) 等。
#15
★★★★
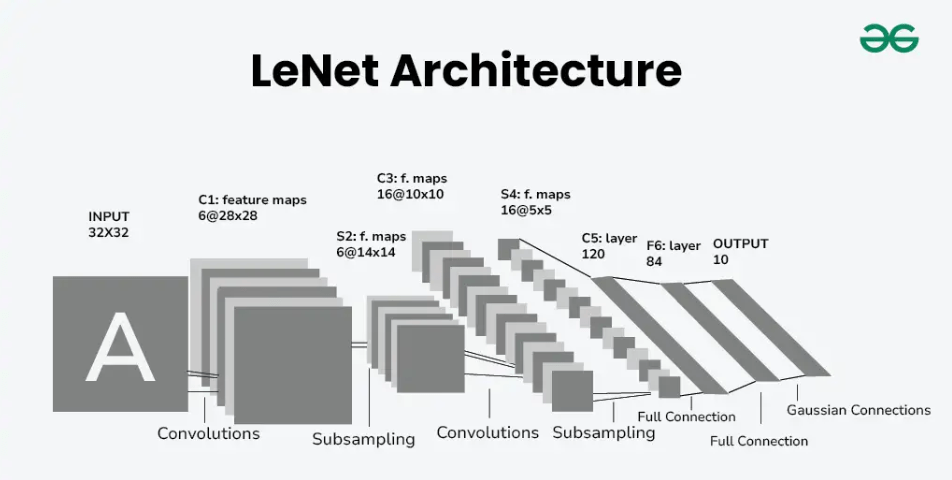
LeNet-5
早期 CNN 模型
由 Yann LeCun 等人於 1998 年提出,是最早的 CNN 之一,主要用於手寫數字辨識。它奠定了現代 CNN 的基本架構,包含卷積層、池化層和全連接層。
#16
★★★★
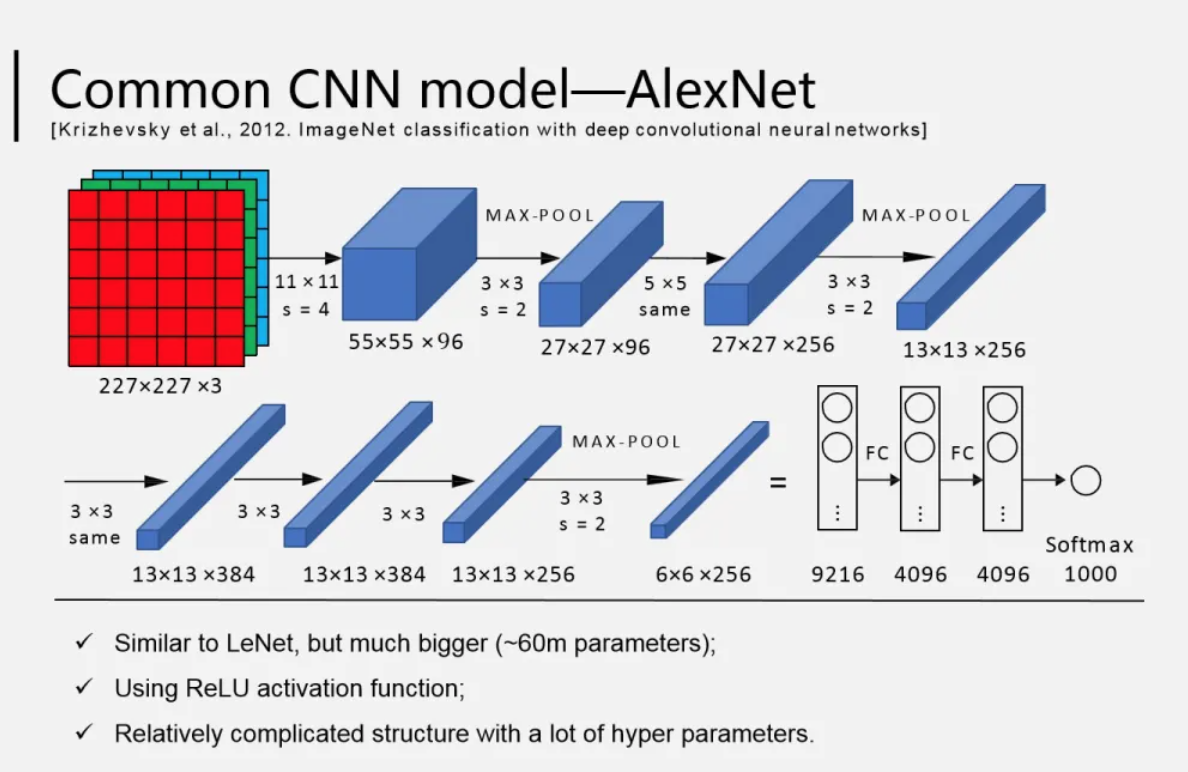
AlexNet
里程碑 CNN 模型
在 2012 年的 ImageNet 圖像辨識競賽中取得突破性成果,引發了深度學習在電腦視覺領域的熱潮。它使用了更深的網路結構、ReLU 激活函數、Dropout 技術來防止過擬合,並利用 GPU 加速訓練。
#17
★★★★★
VGGNet (e.g., VGG16, VGG19)
經典 CNN 架構
VGGNet 的主要貢獻是探索了網路深度對性能的影響。它使用了非常小的 3x3 卷積核,並通過堆疊多個這樣的小卷積核來構建更深的網路。其結構簡單且規整,易於理解和實現。樣題 Q12 提到了 VGG19。

#18
★★★★★
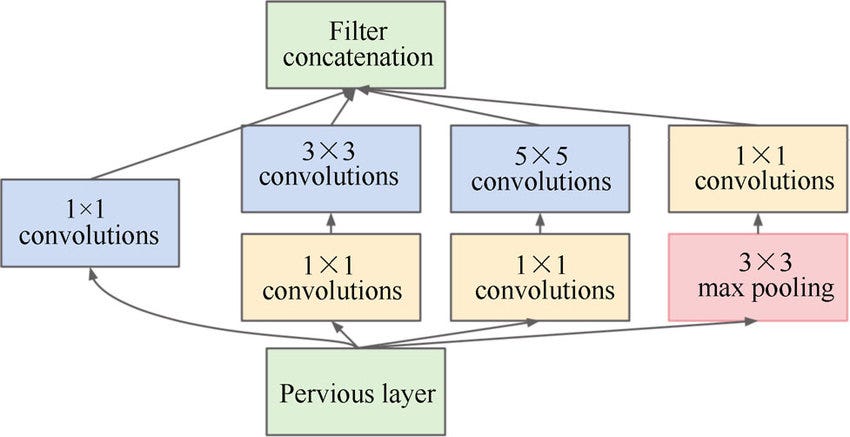
GoogLeNet (Inception)
創新 CNN 架構
GoogLeNet 的核心是引入了 Inception Module。該模塊並行使用不同尺寸的卷積核(如 1x1, 3x3, 5x5)和池化操作,然後將結果串聯起來,以捕捉不同尺度的特徵,並有效減少了計算量。樣題 Q12 提到了 Inception。
#19
★★★★★
ResNet (Residual Network)
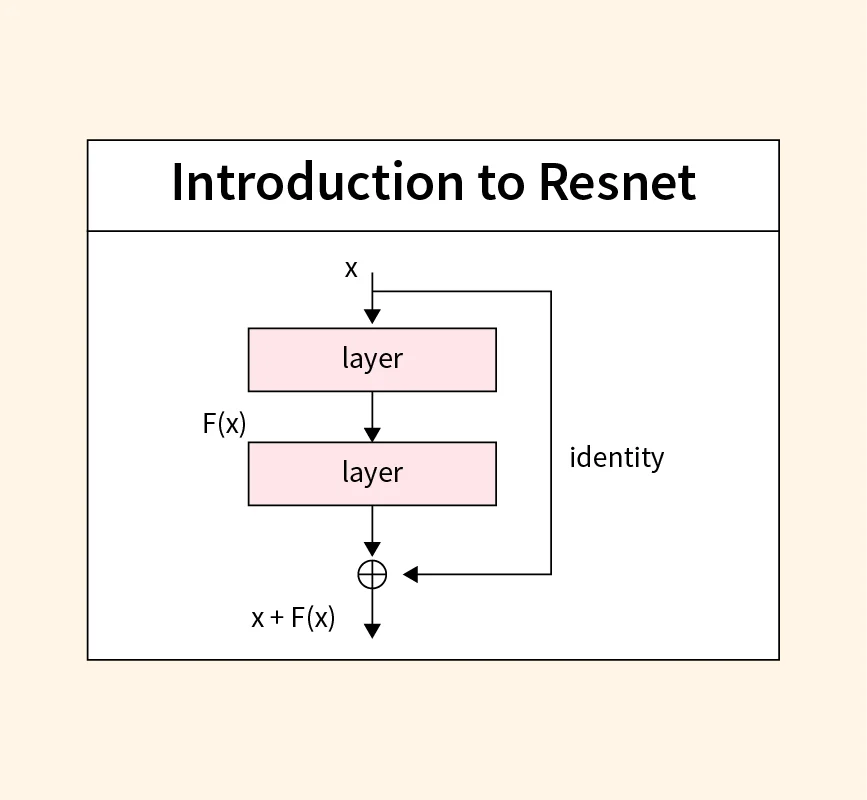
突破性 CNN 架構
ResNet 引入了殘差學習 (Residual Learning) 的概念,通過捷徑連接 (Shortcut Connection 或 Skip Connection) 解決了深度神經網路訓練中的梯度消失和網路退化問題,使得訓練非常深的網路(如超過 100 層)成為可能。樣題 Q12 提到了 ResNet。
#20
★★★★
物件偵測模型 (Object Detection Models)
主要類型
物件偵測模型大致可分為兩類:
- 單階段 (One-Stage) 方法: 直接在圖像上預測物件類別和邊界框,無需生成候選區域。代表模型:YOLO (You Only Look Once), SSD (Single Shot MultiBox Detector)。速度快,適合實時應用。
- 兩階段 (Two-Stage) 方法: 先生成候選區域 (Region Proposals),再對這些區域進行分類和邊界框回歸。代表模型:R-CNN, Fast R-CNN, Faster R-CNN。準確率通常較高,但速度較慢。
#21
★★★
圖像分割模型 (Image Segmentation Models)
代表性模型
- FCN (Fully Convolutional Network): 將傳統 CNN 末尾的全連接層替換為卷積層,實現端到端的像素級預測。
- U-Net: 具有對稱的編碼器-解碼器 (Encoder-Decoder) 架構,並包含跳躍連接,特別適用於醫學圖像分割。
- Mask R-CNN: 在 Faster R-CNN 基礎上增加了一個分支,用於預測物件的像素級掩碼 (Mask),實現實例分割。
#22
★★★★
資料增強 (Data Augmentation)
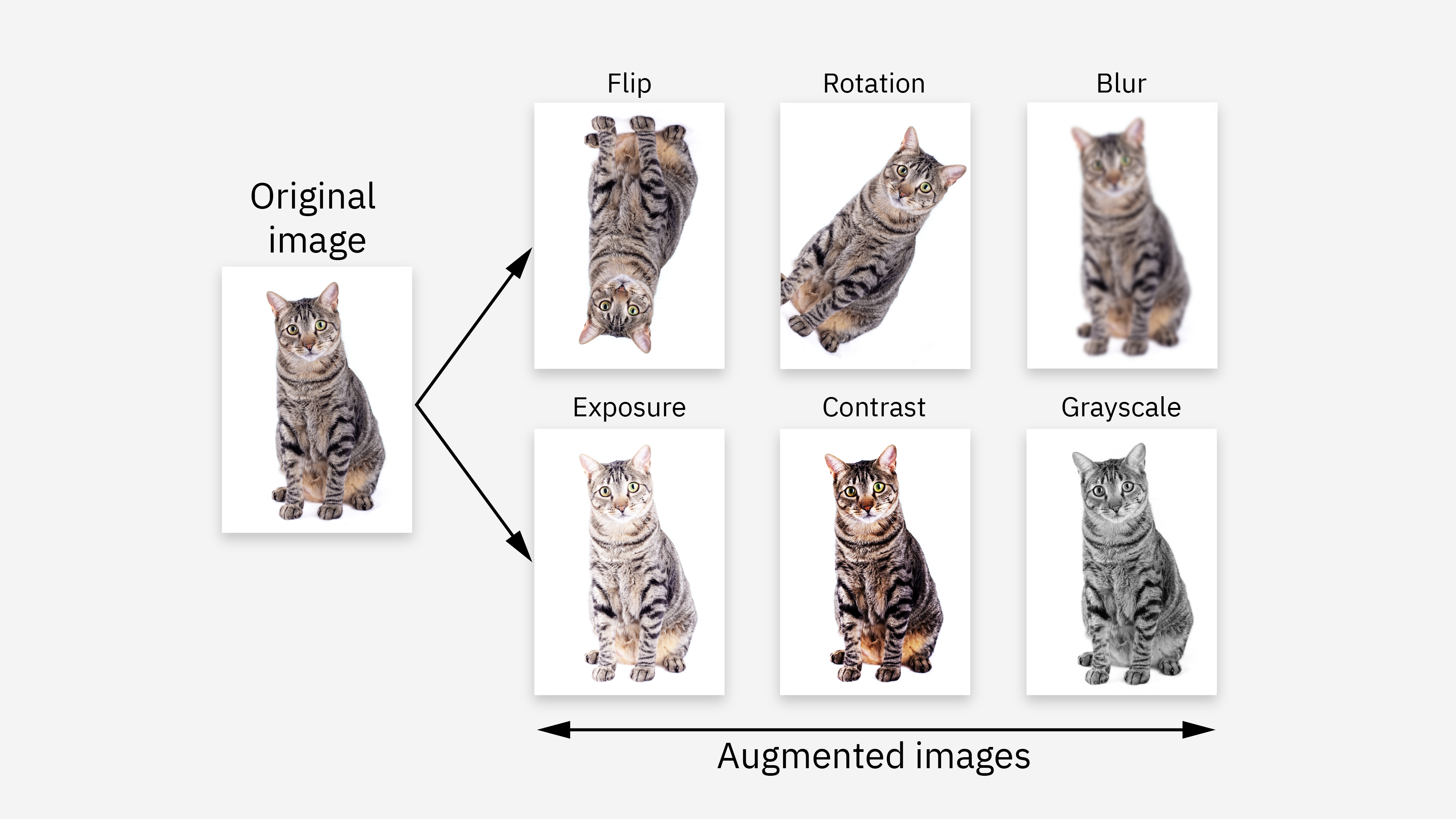
模型訓練技巧
在訓練數據有限的情況下,通過對現有圖像進行隨機變換(如旋轉、平移、縮放、翻轉、改變亮度/對比度等)來人工增加訓練樣本的數量和多樣性。這有助於提高模型的泛化能力,減少過擬合。
#23
★★★★
遷移學習 (Transfer Learning)
模型訓練策略
利用在大型數據集(如 ImageNet)上預先訓練好的模型(稱為預訓練模型 Pre-trained Model)作為初始模型,然後在目標任務的小型數據集上進行微調 (Fine-tuning)。這樣可以顯著減少訓練所需的時間和數據量,並通常能獲得較好的性能。
#24
★★★★★
過擬合 (Overfitting) 與 欠擬合 (Underfitting)
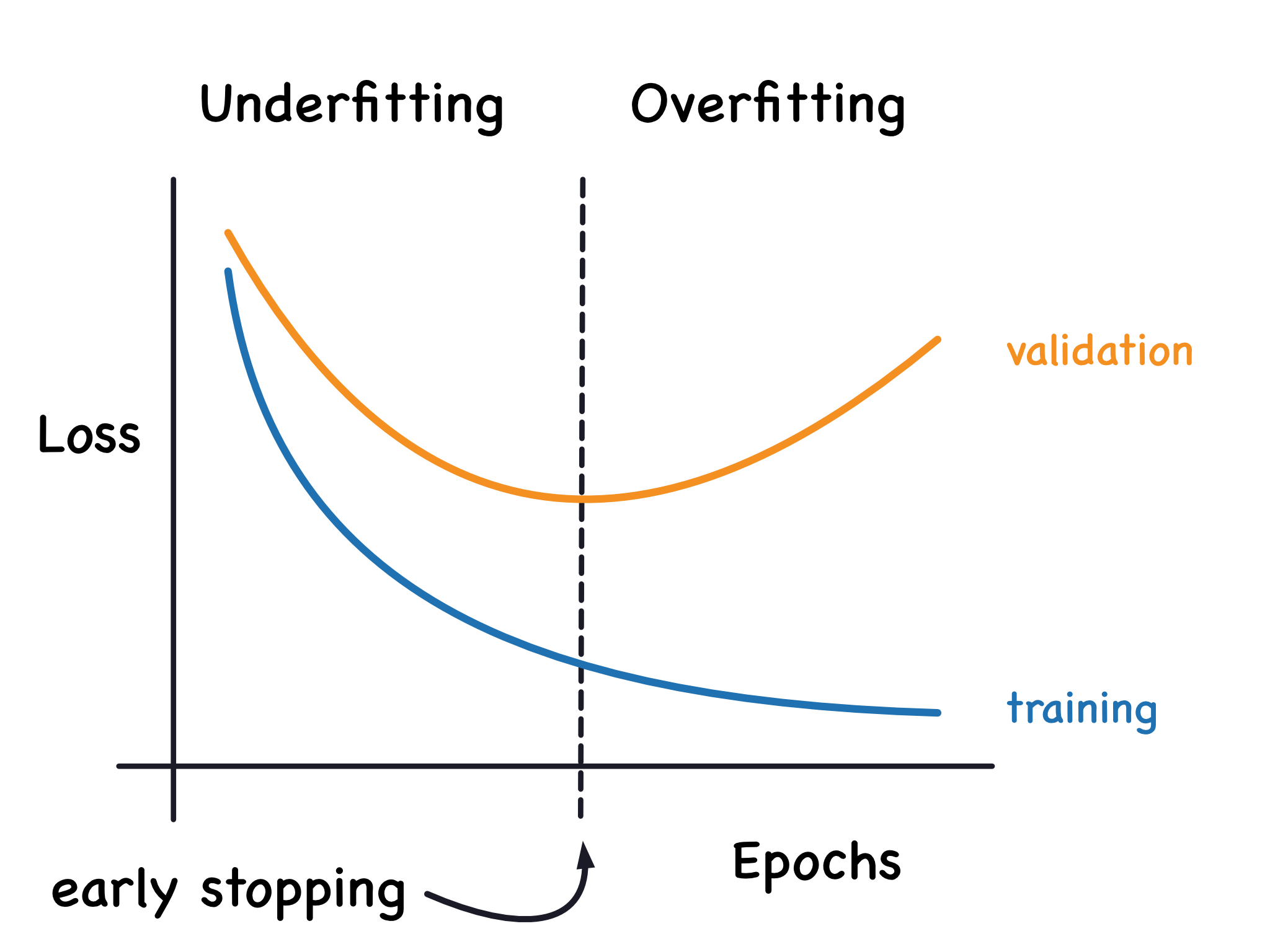
模型訓練問題
- 過擬合: 模型在訓練數據上表現很好,但在未見過的測試數據上表現很差。模型過於複雜,學習到了訓練數據中的噪聲和細節。樣題 Q13 的情況(訓練誤差低,測試誤差高)即為過擬合。
- 欠擬合: 模型在訓練數據和測試數據上表現都不好。模型過於簡單,未能捕捉到數據中的基本模式。
#25
★★★★
分類任務評估指標 (Classification Metrics)
性能衡量
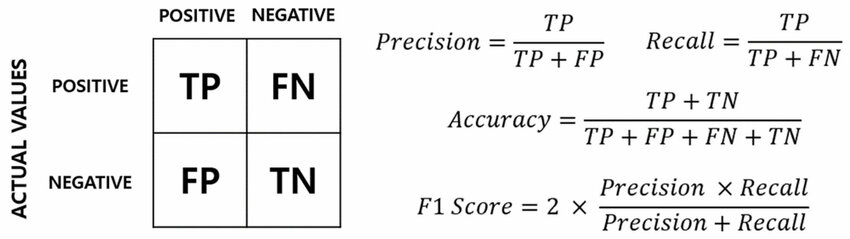
常用的圖像分類評估指標包括:
- 準確率 (Accuracy): 正確分類的樣本數 / 總樣本數。但在類別不平衡時可能具有誤導性。
- 精確率 (Precision): 預測為正類的樣本中,實際為正類的比例 (TP / (TP + FP))。
- 召回率 (Recall or Sensitivity): 實際為正類的樣本中,被正確預測為正類的比例 (TP / (TP + FN))。
- F1 分數 (F1-Score): 精確率和召回率的調和平均數 (2 * Precision * Recall / (Precision + Recall)),綜合考慮兩者。
- 混淆矩陣 (Confusion Matrix): 視覺化模型預測結果與實際類別的對應關係。
#26
★★★★
物件偵測評估指標 (Object Detection Metrics) - IoU, mAP
性能衡量
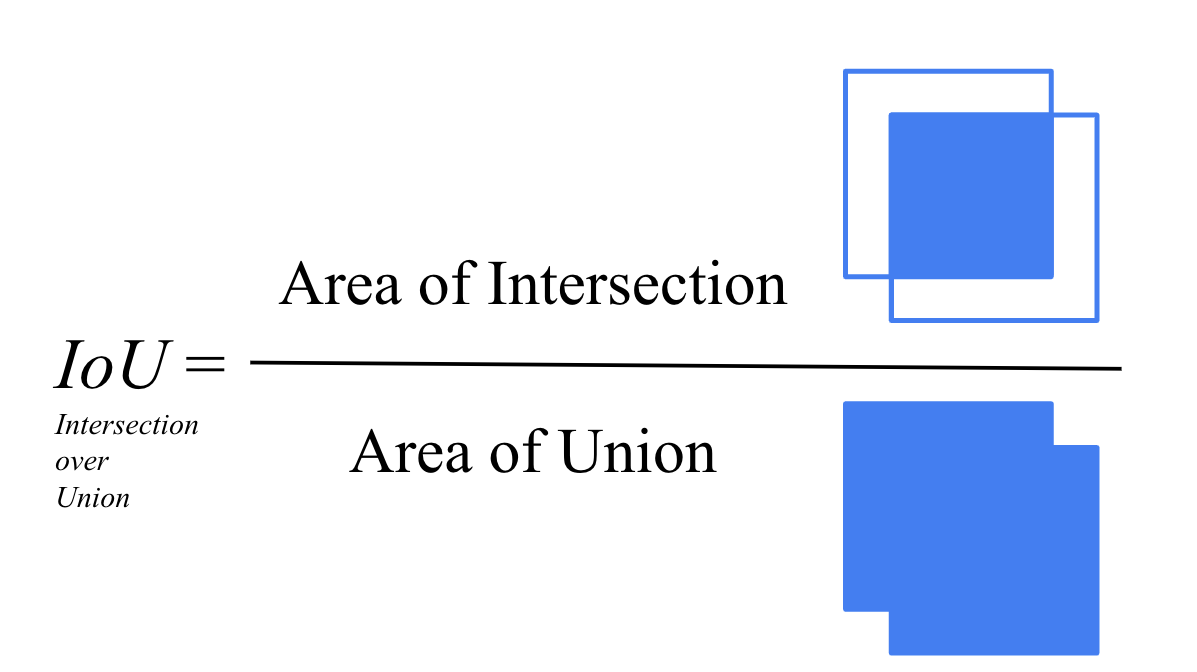
- 交併比 (IoU - Intersection over Union): 衡量預測邊界框與實際邊界框重疊程度的指標。計算方式為兩者交集面積 / 聯集面積。通常設定一個閾值(如 0.5),IoU 超過閾值才算偵測正確。
- 平均精度均值 (mAP - mean Average Precision): 物件偵測中最常用的綜合評估指標。它計算每個類別的平均精度 (AP),然後再對所有類別的 AP 取平均值。

#27
★★★★
醫療影像分析 (Medical Image Analysis)
應用場景
電腦視覺在醫療領域應用廣泛,例如:
- 腫瘤檢測與分割 (如樣題 Q14 提到的 CNN 分類腫瘤)
- 病理切片分析
- 眼底圖像分析 (診斷糖尿病視網膜病變等)
- 輔助診斷系統
#28
★★★★
自動駕駛 (Autonomous Driving)
應用場景
電腦視覺是實現自動駕駛的關鍵技術之一,用於感知周圍環境。主要任務包括:
- 車道線檢測
- 行人與車輛偵測/追蹤
- 交通標誌識別
- 可通行區域分割
- 3D 場景理解 (結合 LiDAR, Radar 等感測器)
#29
★★★
安防監控 (Security and Surveillance)
應用場景
利用電腦視覺技術分析監控攝影機畫面,實現:
- 人臉辨識 (Face Recognition)
- 異常行為偵測
- 人群計數與密度分析
- 車輛追蹤與車牌辨識

#30
★★★
工業自動化與品質檢測 (Industrial Automation & Quality Inspection)
應用場景
在製造業中,電腦視覺可用於:
- 產品瑕疵檢測
- 機器人引導與定位
- 零件計數與分類
- 尺寸量測
#31
★★★
挑戰:資料依賴性與標註成本
CV 面臨挑戰
深度學習模型通常需要大量的標註數據才能達到良好性能。獲取和標註這些數據(尤其是像素級標註)成本高昂且耗時。樣題 Q15 提到數據標註品質直接影響模型性能。
#32
★★★
挑戰:模型泛化能力與穩健性
CV 面臨挑戰
模型在訓練數據上表現良好,但在面對真實世界中光照變化、遮擋、視角變化、不同背景等情況時,性能可能會顯著下降。提高模型的泛化能力 (Generalization) 和穩健性 (Robustness) 是一個持續的挑戰。
#33
★★
挑戰:模型可解釋性 (Interpretability)
CV 面臨挑戰
深度學習模型通常被視為「黑盒子」,難以理解其做出特定預測的原因。在醫療、金融等高風險領域,模型的可解釋性至關重要。
#34
★★★
趨勢:自監督學習 (Self-Supervised Learning)
CV 未來趨勢
旨在利用大量未標註數據進行模型預訓練,通過設計代理任務 (Pretext Task)(如預測圖像旋轉角度、圖像修復等)來學習有用的視覺表示,以減少對標註數據的依賴。

#35
★★★
趨勢:多模態學習 (Multimodal Learning)
CV 未來趨勢
結合視覺資訊與其他模態的資訊(如文字、聲音)進行學習,以獲得更全面的理解。例如,視覺問答 (Visual Question Answering, VQA)、圖像描述生成 (Image Captioning) 等。
#36
★★
趨勢:Transformer 在視覺領域的應用
CV 未來趨勢
最初在自然語言處理 (NLP) 領域取得巨大成功的 Transformer 模型,近年來也被應用於電腦視覺任務,如 Vision Transformer (ViT),在某些任務上展現出與 CNN 相媲美甚至超越的性能。
#37
★★
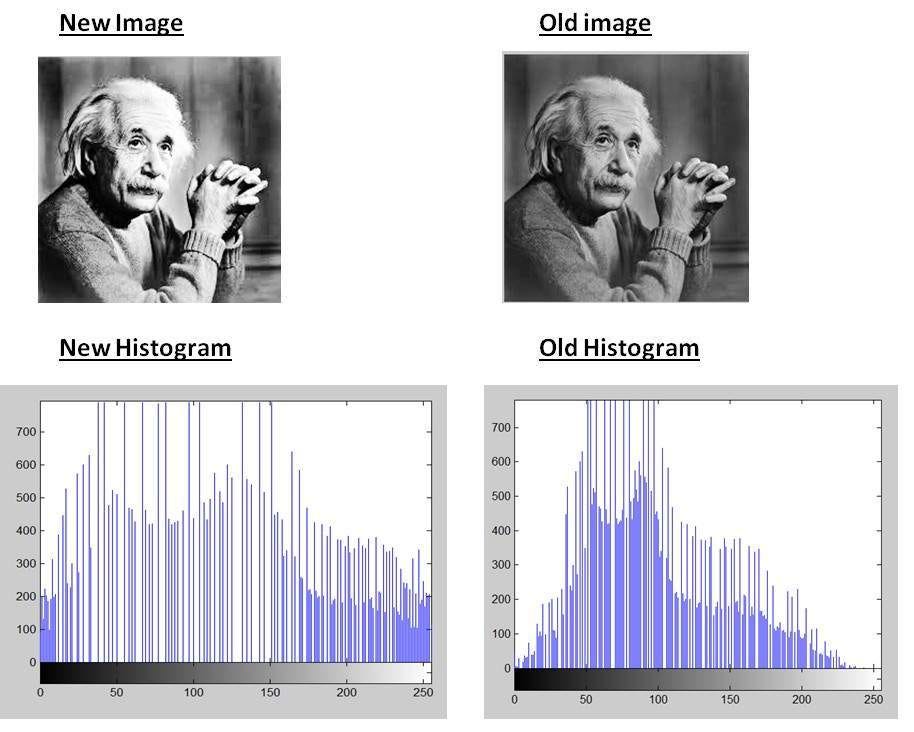
圖像直方圖 (Image Histogram)
基礎圖像分析
圖像直方圖是圖像像素強度分佈的圖形表示。它統計了圖像中每個像素強度級別出現的頻率。可用於圖像對比度分析、亮度調整、閾值選擇等。
#38
★★★
圖像濾波 (Image Filtering)
圖像預處理
應用濾波器(卷積核)來修改或增強圖像。常見應用包括:
- 平滑濾波 (Smoothing Filtering): 去除噪點,如均值濾波、高斯濾波。
- 銳化濾波 (Sharpening Filtering): 增強邊緣,使圖像更清晰。
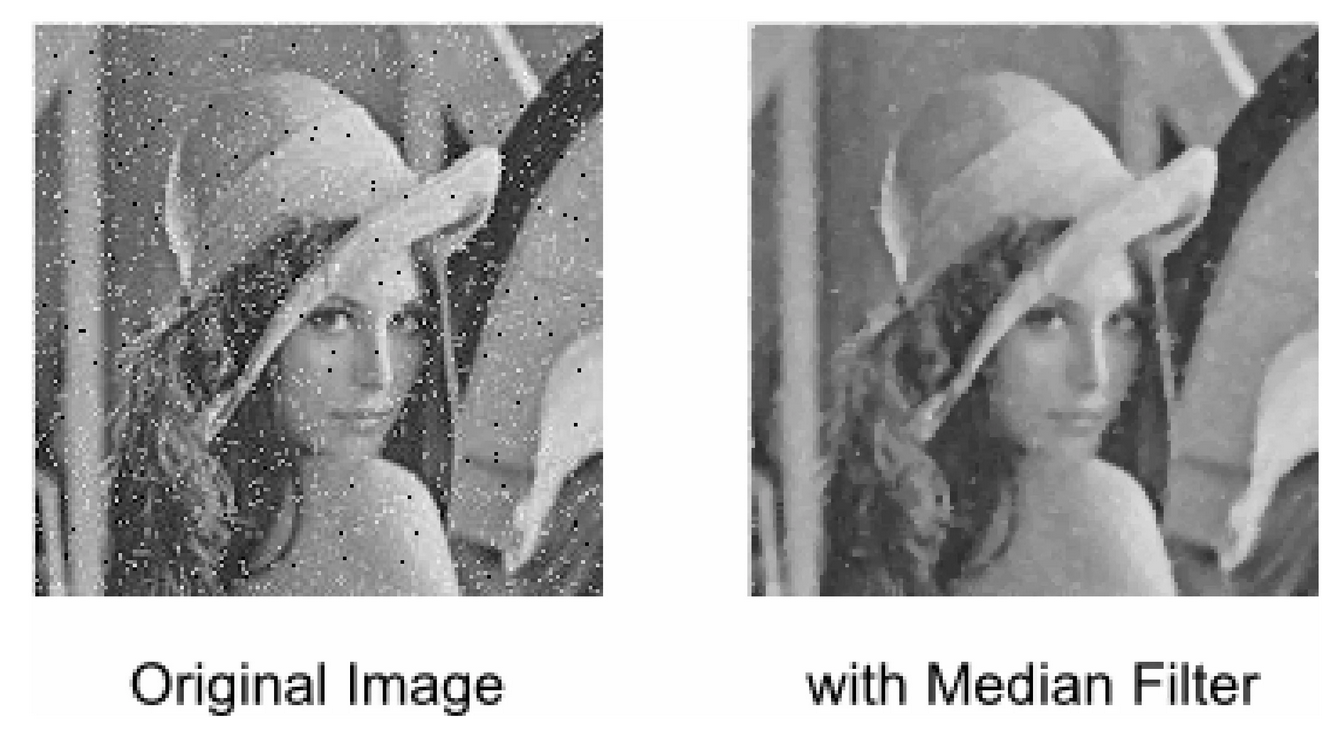
#39
★★★
損失函數 (Loss Function)
模型訓練關鍵
損失函數用於衡量模型預測結果與實際標籤之間的差異。模型訓練的目標是最小化損失函數。
- 分類任務常用:交叉熵損失 (Cross-Entropy Loss)。
- 回歸任務常用:均方誤差 (Mean Squared Error, MSE)。
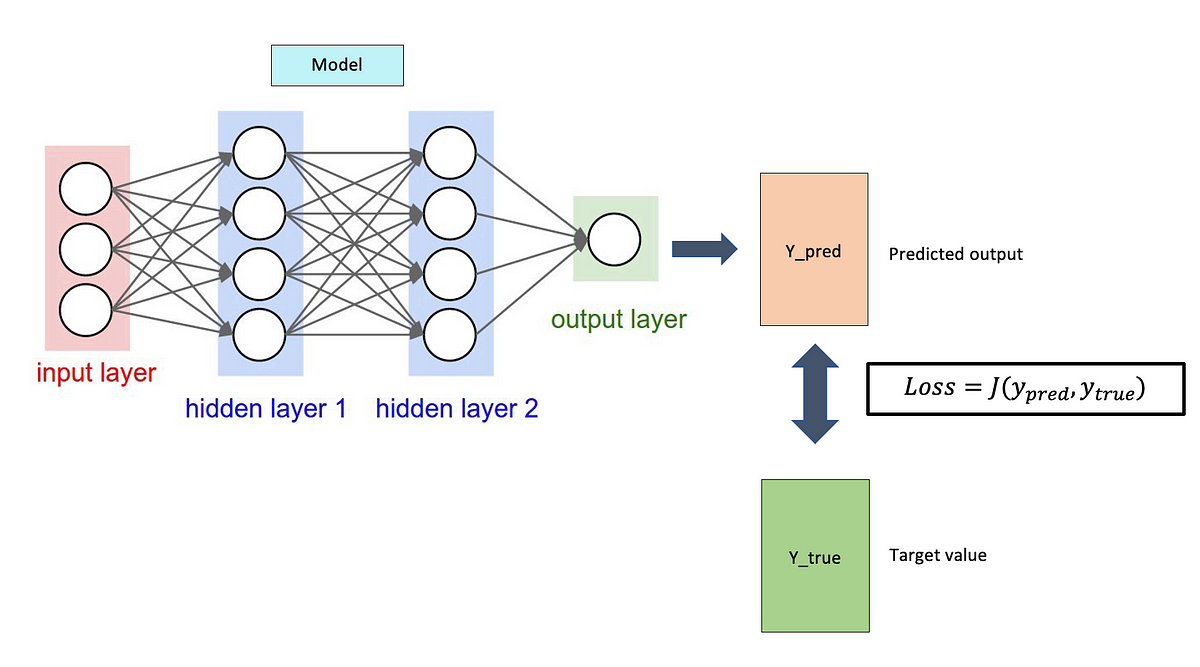
#40
★★★
優化器 (Optimizer)
模型訓練關鍵
優化器根據損失函數計算出的梯度來更新模型的權重參數,以逐步最小化損失。常見的優化器包括:
- SGD (Stochastic Gradient Descent)
- Adam (Adaptive Moment Estimation)
- RMSprop
#41
★★
像素 (Pixel) 與 解析度 (Resolution)
圖像基本單位
- 像素: 構成數位圖像的最小單位,每個像素具有特定的顏色或灰度值。
- 解析度: 圖像包含的像素數量,通常表示為寬度 x 高度(例如,1920x1080)。解析度越高,圖像包含的細節越多,但檔案大小和處理所需資源也越大。
#42
★★
色彩空間 (Color Space)
圖像表示方式
色彩空間定義了如何表示顏色。常見的色彩空間包括:
- RGB (Red, Green, Blue): 加色模型,常用於顯示器。
- HSV (Hue, Saturation, Value): 更符合人類對顏色的感知方式,將色調、飽和度、明度分開。
- 灰階 (Grayscale): 只包含亮度資訊。
#43
★★
擴增實境 (AR - Augmented Reality)
應用場景
AR 將虛擬物件疊加到真實世界場景中。電腦視覺在 AR 中扮演關鍵角色,用於理解真實場景的結構、追蹤相機位置和姿態 (SLAM - Simultaneous Localization and Mapping),以便準確地放置虛擬物件。
#44
★★
光學字元辨識 (OCR - Optical Character Recognition)
應用場景
從圖像中辨識並提取文字資訊。例如,掃描文件、辨識車牌、從圖片中讀取文字等。這通常結合了電腦視覺(文字區域偵測)和序列模型(文字辨識)。
#45
★★
圖像標註工具 (Image Annotation Tools)
數據準備
為了訓練監督式學習模型,需要使用工具對圖像數據進行標註。根據任務不同,標註形式也不同:
- 分類任務:標註圖像級別的類別標籤。
- 物件偵測任務:標註物件的邊界框和類別標籤。
- 分割任務:標註像素級別的掩碼和類別標籤。
#46
★★★
圖像尺寸調整 (Image Resizing)
圖像預處理
將不同大小的輸入圖像調整為統一的尺寸,以符合 CNN 等模型的輸入要求。常用的插值方法包括最近鄰插值、雙線性插值和雙立方插值。選擇何種方法會影響圖像品質和計算速度。
#47
★★★
圖像標準化 (Image Normalization)
圖像預處理
將圖像的像素值縮放到一個特定的範圍(例如 [0, 1] 或 [-1, 1])或使其具有零均值和單位方差。這有助於加速模型訓練的收斂速度,提高模型的穩定性。
#48
★★
姿態估計 (Pose Estimation)
常見 CV 任務
從圖像或影片中檢測人體關鍵點(如關節位置)的位置和方向,以推斷人體的姿態。應用於人機互動、運動分析、動畫製作等領域。

#49
★★
人臉關鍵點偵測 (Facial Landmark Detection)
常見 CV 任務
定位人臉上的關鍵點,如眼睛角落、鼻尖、嘴角等。應用於人臉辨識、表情分析、臉部動畫、美顏濾鏡等。

#50
★★★
模型部署 (Model Deployment) - 雲端 vs. 邊緣
應用考量
將訓練好的電腦視覺模型應用到實際場景中。部署方式主要有:
- 雲端部署 (Cloud Deployment): 模型部署在伺服器上,通過網路接口提供服務。優點是計算資源強大,易於管理;缺點是依賴網路連接,可能有延遲。
- 邊緣部署 (Edge Deployment): 模型直接部署在終端設備(如手機、嵌入式系統、攝影機)上。優點是低延遲、不依賴網路、保護數據隱私;缺點是設備計算資源有限,需要進行模型優化(如量化、剪枝)。
#51
★★
倫理考量:偏見與隱私
CV 倫理議題
- 偏見 (Bias): 訓練數據的不平衡或偏差可能導致模型對某些群體(如特定膚色、性別)產生歧視性結果,例如人臉辨識系統對特定族群的準確率較低。
- 隱私 (Privacy): 安防監控、人臉辨識等應用可能侵犯個人隱私,數據的收集、儲存和使用需要符合法規並尊重個人權利。
#52
★★★
常用電腦視覺資料集
數據資源
一些公開的大型資料集對電腦視覺研究和模型評估至關重要:
- MNIST: 手寫數字資料集,常用於入門級圖像分類。
- CIFAR-10 / CIFAR-100: 小型自然圖像資料集,包含 10/100 個類別。
- ImageNet: 大型圖像分類資料集 (ILSVRC),包含上千個類別,對深度學習發展影響深遠。
- COCO (Common Objects in Context): 大型物件偵測、分割和圖像描述資料集。
- Pascal VOC: 常用的物件偵測和分割資料集。
#53
★★★
常用電腦視覺函式庫/框架
開發工具
- OpenCV (Open Source Computer Vision Library): 最流行的開源電腦視覺函式庫,提供大量傳統圖像處理和電腦視覺演算法。
- TensorFlow / Keras: Google 開發的深度學習框架,廣泛用於構建和訓練 CNN 等模型。
- PyTorch: Facebook 開發的深度學習框架,以其靈活性和易用性在學術界和研究領域非常受歡迎。
#54
★★
超參數調優 (Hyperparameter Tuning)
模型優化
超參數是在模型訓練開始前手動設定的參數,例如學習率 (Learning Rate)、批次大小 (Batch Size)、卷積核數量、網路層數等。選擇合適的超參數對模型性能至關重要,常用的調優方法包括網格搜索 (Grid Search)、隨機搜索 (Random Search) 和貝葉斯優化 (Bayesian Optimization)。
#55
★★
模型壓縮與加速 (Model Compression & Acceleration)
部署優化
為了將深度學習模型部署到資源受限的邊緣設備,通常需要進行模型壓縮和加速。常用技術包括:
- 權重剪枝 (Weight Pruning): 移除模型中不重要的權重。
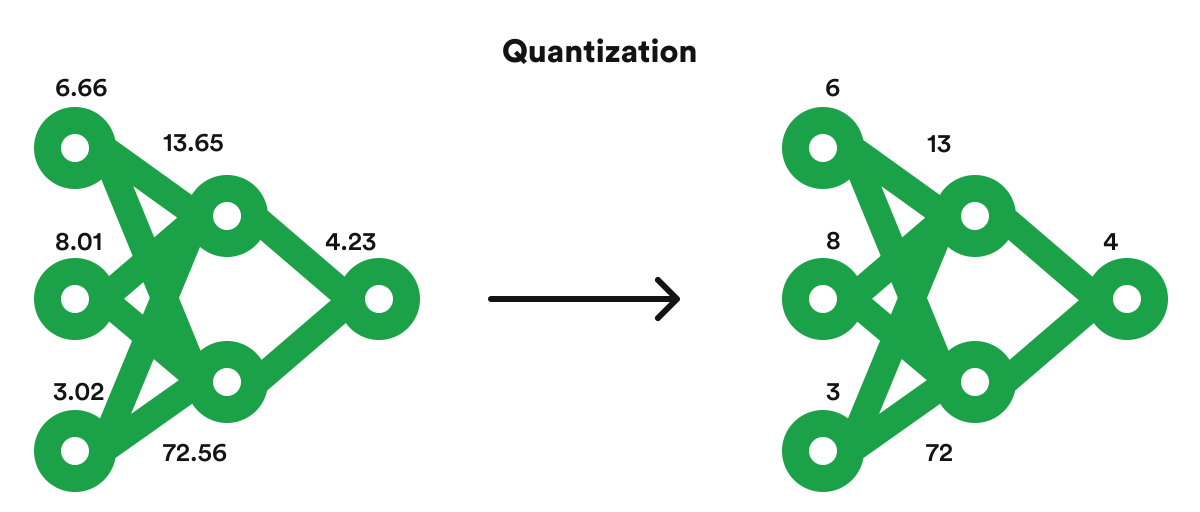
- 權重量化 (Weight Quantization): 降低權重表示的精度(如從 32 位浮點數降到 8 位整數)。
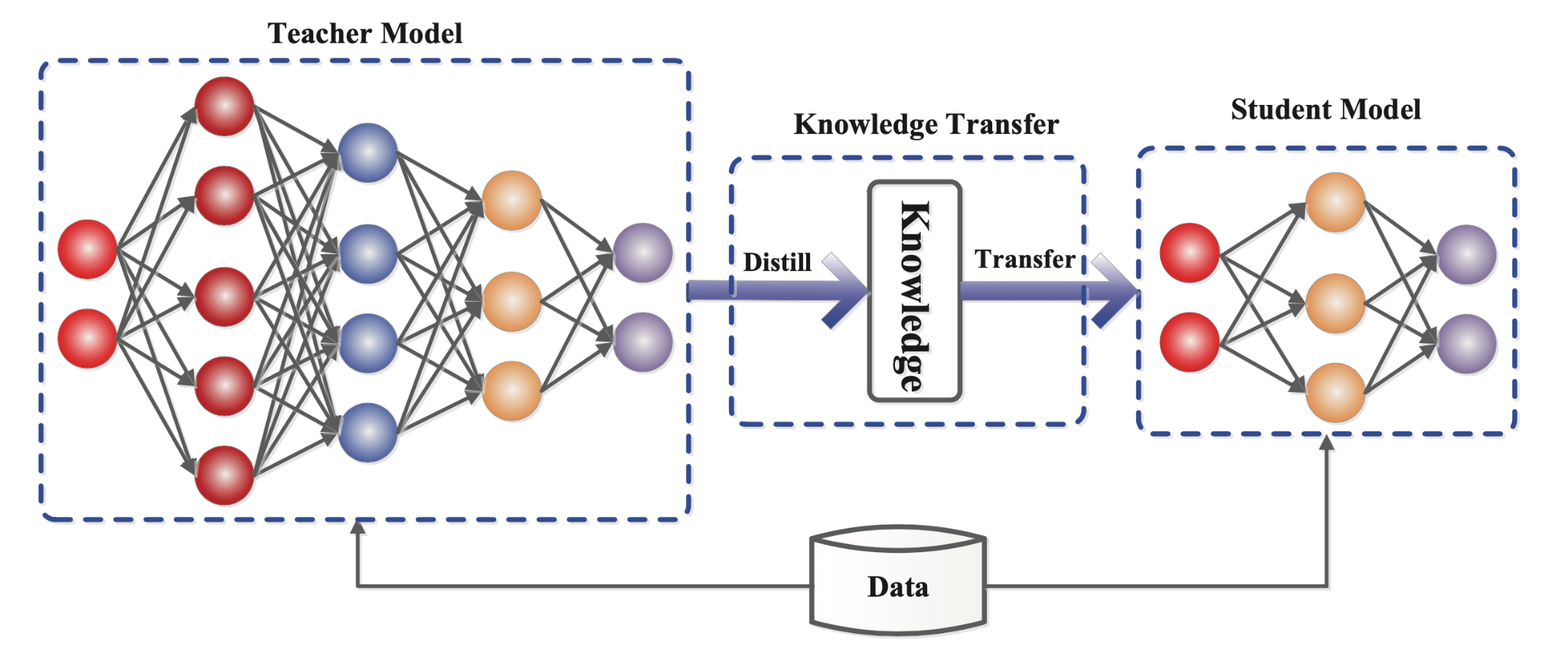
- 知識蒸餾 (Knowledge Distillation): 用一個大型複雜模型(教師模型)來指導一個小型簡單模型(學生模型)的訓練。
- 設計輕量化網路: 如 MobileNet, SqueezeNet。
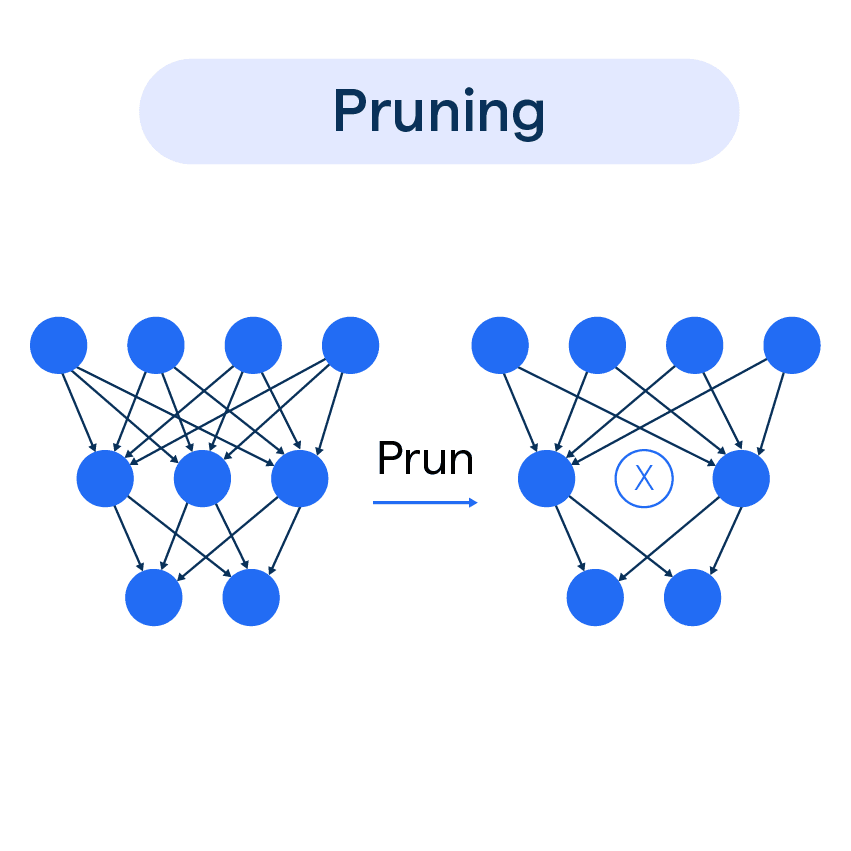
#56
★★★
批次標準化 (BN - Batch Normalization)
CNN 訓練技巧
批次標準化是一種加速深度神經網路訓練並提高其穩定性的技術。它通過對每個小批次 (mini-batch) 的數據在進入激活函數之前進行標準化處理(使其均值為0,方差為1),緩解了內部協變量偏移 (Internal Covariate Shift) 問題,允許使用更高的學習率,並具有一定的正則化效果。
#57
★★★
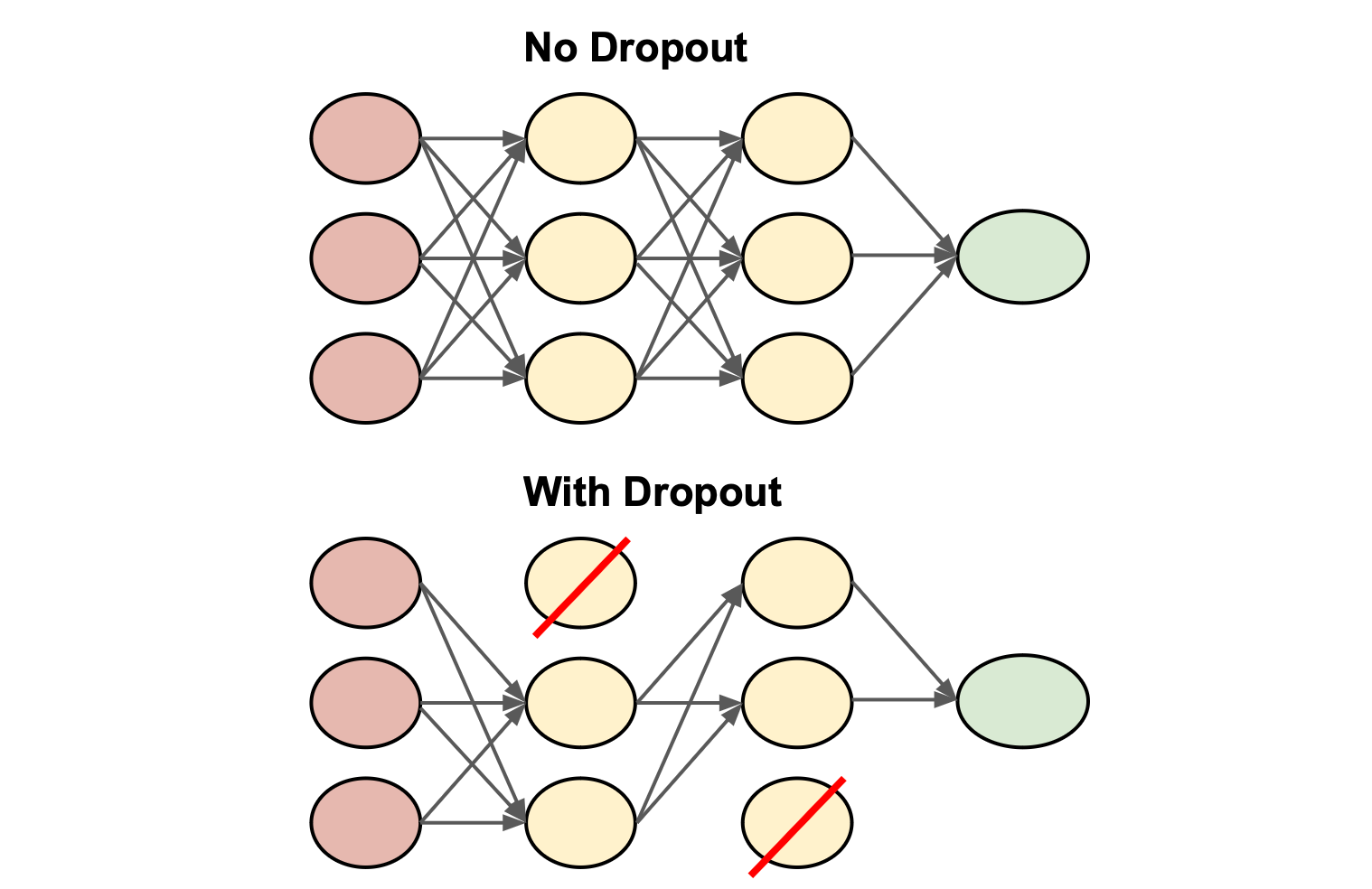
Dropout
CNN 正則化技巧
Dropout 是一種常用的防止過擬合的正則化技術。在訓練過程中,它會以一定的機率隨機地「丟棄」(即暫時禁用)網路中的一部分神經元及其連接。這迫使網路學習更魯棒的特徵,減少了神經元之間的共適應性。在測試階段,則使用所有神經元。
#58
★★
分割任務評估指標 (Segmentation Metrics)
性能衡量
除了像素級準確率外,圖像分割常用的指標還包括:
- 交併比 (IoU): 同物件偵測,衡量預測分割區域與實際分割區域的重疊程度。
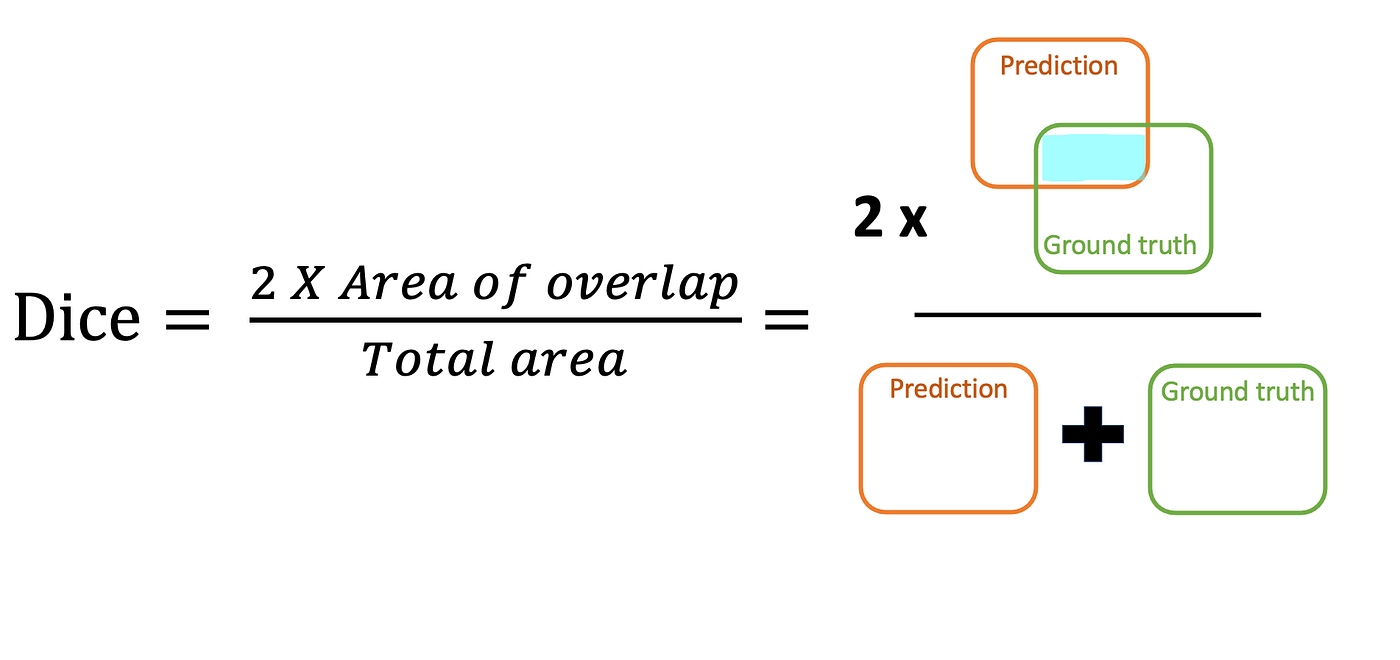
- Dice 係數 (Dice Coefficient): 類似 IoU,計算公式為 2 * |Intersection| / (|Prediction| + |Ground Truth|),常用於醫學影像分割。
#59
★
遙感影像分析 (Remote Sensing Image Analysis)
應用場景
利用電腦視覺技術分析衛星或航空影像,應用於土地覆蓋分類、環境監測、農業估產、城市規劃、災害評估等。
#60
★★
對抗性攻擊 (Adversarial Attacks)
CV 安全性挑戰
深度學習模型容易受到對抗性攻擊的影響。攻擊者可以通過對輸入圖像添加人眼難以察覺的微小擾動,導致模型做出錯誤的預測。這在安防、自動駕駛等安全關鍵應用中構成了嚴重威脅。研究如何提高模型的對抗穩健性是一個重要的方向。

沒有找到符合條件的重點。
↑